基于人工智能干預措施的臨床試驗方案指南:SPIRIT-AI擴展
2020-11-28 02:37:24譯者熊云云李子孝丁玲玲谷鴻秋王春娟王春雪趙性泉王擁軍
中國卒中雜志 2020年11期
關鍵詞:研究
譯者:熊云云,李子孝,3,丁玲玲,谷鴻秋,王春娟,3,王春雪,趙性泉,3,王擁軍,3
臨床試驗方案是研究人員必須撰寫的文件,應詳細介紹臨床試驗的基本原理、研究方法和執行計劃。外部審稿人(供資機構、監管機構、研究倫理委員會、期刊編輯、同行評審、機構審查委員會以及更廣泛的公眾)將通過此關鍵文件來理解該研究的原理、評估方法學的嚴謹性和倫理考量。此外,試驗方案也提供了一個共享的參考,以支持研究團隊進行高質量的研究。
盡管如此重要,目前已發表的試驗方案的質量和完整性仍然參差不齊。因此,在2013年發布了《干預試驗方案報告標準》(Standard Protocol Items:Recommendations for Interventional Trials,SPIRIT)聲明,旨在為臨床試驗方案的最低報告內容提供指導,目前被廣泛認可并成為國際標準。SPIRIT 2013提供了適用于所有臨床試驗干預措施的最低指導,但同時也認識到針對某些干預措施需要進行條目上的擴展或細化。人工智能(artificial intelligence,AI)領域備受關注,它具有強大的驅動力,通過出版、實施和市場推廣可加速新的AI干預措施。AI系統的相關研究已開展了一段時間。近期,由于在衛生領域的應用潛力,其在深度學習和神經網絡方面的進展引起了極大的關注。這些應用的例子范圍很廣,包括用于篩查和分診、診斷、預后、決策支持和治療推薦的AI系統。然而,目前大多數公開證據只有計算機模擬和早期驗證。AI研究報告的不充分,以及現有的報告指南并未完全涵蓋AI系統特有的偏移潛在來源已經成為了一個公認的事實。旨在評估基于或包含有AI成分(本文中為“AI干預”)的新型干預措施的臨床療效的隨機對照試驗也同樣存在設計和報告方面的擔憂。這凸顯了制訂AI領域內“目的導向”報告指南的必要性。
SPIRIT-AI擴展[作為SPIRIT-AI和《人工智能試驗報告統一標準》(Consolidated Standards of Reporting Trials-Artificial Intelligence,CONSORT-AI)倡議的一部分]是由SPIR I T 和提高健康研究的質量和透明度(Enhancing the Qualit y and Transp are nc y of Health Res earch,EQUATOR)網共同支持的國際倡議,用于擴展或詳細闡述現有的SPIRIT 2013聲明,以制訂基于共識的針對AI的研究方案指南,是對旨在促進高質量AI試驗報告的CONSORT-AI聲明的補充。這個共識聲明描述了用于識別和評估候選條目并取得共識的方法。此外,它還提供了包括新的條目及其相應的解釋在內的完整的SPIRIT-AI條目清單。
1 方法學
SPIRIT-AI和CONSORT-AI擴展同時被開發用于臨床試驗方案和試驗報告。SPIRITAI和CONSORT-AI倡議于2019年10月發布。這兩個指南均根據EQUATOR網的方法學框架制定,并于2019年5月在EQUATOR報告指南庫中注冊為正在制訂中的指南。SPIRIT-AI和CONSORT-AI指導小組由15名國際專家組成,以監督研究的進行和審查研究的方法。術語表中提供了關鍵術語的定義(表1)。
2 倫理批準
該研究獲得了英國伯明翰大學倫理審查委員會的批準(ERN_19-1100)。在調查完成前和共識會議前,參與者的信息以電子方式提供給德爾菲參與專家。德爾菲參與專家提供了電子知情同意書,并獲得共識會議參與者的書面同意。。

表1 術語定義
3 文獻綜述和候選條目生成
通過審查已發表的文獻,并與指導小組和知名國際專家進行磋商,生成了SPIRIT-AI和CONSORT-AI候選條目的初始列表。文獻搜索工作于2019年5月13日進行,使用關鍵詞“artificial intelligence”“machine learning”和“deep learning”搜索美國國家醫學圖書館臨床試驗登記(ClinicalTrials.gov)中列出的涉及AI干預措施的現有臨床試驗。在316項注冊試驗中,62項已完成,7項已發表試驗結果。有兩項研究與CONSORT聲明有關,其中一項研究提供了一項未發表的試驗方案。工作小組從這些研究中確定了針對AI的考慮因素,并將它們重新設計構建為候選條目。這些候選條目也從既往一項評估醫學成像深度學習診斷準確性的系統綜述中找到依據。在咨詢了指導小組和其他國際專家(n=19)之后,研究生成了29項候選條目,其中26項與SPIRIT-AI和CONSORT-AI皆相關,3項僅與CONSORTAI相關。工作小組將這些條目規劃到相應的SPIRIT和CONSORT條目,修改措辭,并根據需要提供說明文本,以將條目置于上下文。這些條目被列入隨后的德爾菲調查。
4 德爾菲共識流程
2019年9月,169位國際專家被邀請參加在線德爾菲調查,對候選條目進行投票并提出其他條目。項目指導小組確定并聯系專家,聯系的專家可以舉薦其他專家以便進行一輪“滾雪球式”專家招募。此外,還包括在公告發布后聯系的個人。指導小組一致認為,本次咨詢應廣泛地代表臨床試驗、AI和機器學習(machine learning,ML)專業人士以及該技術的主要用戶的意見。利益相關者包括醫療保健專業人員、方法學家、統計學家、計算機科學家、行業代表、期刊編輯、政策制定者、衛生信息學家、法律和道德專家、監管者、患者和資助者等。本研究進行了兩次在線德爾菲調查。使用的軟件DelphiManager(版本4.0)由有效性試驗的核心結果測量(Core Outcome Measures in Effectiveness Trials,COMET)開發和維護。參與者獲得了有關該研究的書面信息,并被要求提供他們在以下領域的專業水平:①AI/ML和②臨床試驗。每項候選條目都需要參與咨詢的專家進行仔細考慮(SPIRIT-AI為26項,CONSORT-AI為29項)。參與者對每項條目進行9分制投票,評分標準如下:1~3分:不重要;4~6分:重要但不關鍵;7~9分:重要且關鍵。受訪者分別對SPIRIT-AI和CONSORT-AI進行了評級。針對每項條目的投票,可以選擇棄權,并且每項投票條目下都有編輯功能,方便參與者提出建議。在德爾菲調查的最后,參與者有機會提出新建議。第一輪德爾菲調查收到103份回應,第二輪收到91份回應(占第一輪參與者的88%)。德爾菲調查的結果為隨后的國際共識會議提供了依據。德爾菲研究參與專家提出了12項新條目,并在共識會議上進行了討論。對在德爾菲調查中收集的數據進行匿名處理,并將條目級別的結果提交共識會議進行討論和投票。
為期兩天的共識會議于2020年1月舉行,由英國伯明翰大學主辦,旨在就SPIRIT-AI和CONSORT-AI的內容達成共識。邀請了來自德爾菲調查參與者中的31個國際利益相關者討論這些條目,并對其進行投票。選擇的參與專家能恰當地代表各利益相關團體。依次討論了38項條目,其中包括在初始文獻綜述和條目產生階段生成的26項條目(這26項條目與SPIRIT-AI和CONSORT-AI相關;同時討論了僅與CONSORT-AI相關的3項條目)以及參與專家在進行德爾菲調查期間提出的12項新條目。每項條目的德爾菲調研得分(中位數和四分位間距)以及德爾菲參與專家關于該條目的評論均被提交給共識小組。共識會議參與專家評論每項條目的重要性以及該條目是否應包括在AI擴展建議中。此外,共識會與會人員討論每一項附帶的解釋性文字措辭以及每項相對于SPIRIT 2013和CONSORT 2010清單的位置。在公開討論每項條目以及調整措辭之后進行電子表決,以選擇包含或排除該條目。指導小組預先設定了80%的納入門檻,可以代表多數參會專家的共識。每個利益相關者都使用轉折點(Turning Point)投票設備(Turning Technologies,版本8.7.2.14)進行匿名投票。
5 條目清單預試驗
在共識會結束后,參會者將對SPIRIT-AI和CONSORT-AI的更新條目的措辭給出最終的意見,并確保更新的內容忠實地反映共識會議討論的結論。
工作小組根據決策樹將每項條目分配為擴展或詳細說明項,并生成了SPIRIT-AI和CONSORT-AI條目清單的倒數第二份草案。一項預試驗對倒數第二輪草案的條目清單進行了測試,用于確保更新內容的措辭是清晰無歧義的。共有34位專家參與該試驗,包括:①參與德爾菲研究,但是未參加共識會的專家,以及②未參加開發過程但在德爾菲研究開始后聯系的外部專家。工作小組對文字進行了最終更改,目的僅為讓讀者閱讀時更加清晰明確。
6 指南推薦
6.1 SPIRIT-AI清單條目和說明
SPIRIT-AI擴展應與現有SPIRIT 2013原有條目結合在一起使用,SPIRIT-AI擴展推薦AI干預措施相關的試驗方案應符合15項新的條目(12項擴展和3項闡釋說明)。這些條目對AI干預相關的臨床試驗方案極為重要,因此除了SPIRIT 2013清單核心條目外,還應常規報告這些新的條目。表2列出了SPIRIT-AI條目。
SPIRIT-AI擴展中納入的15項新條目都在共識會上通過了80%贊成票的納入門檻。SPIRIT-AI 6a(i)、SPIRIT-AI 11a(v)和SPIRIT-AI 22是由兩個候選條目經過討論后合并而成。SPIRIT-AI 11a(iii)最初并不符合列入標準(73%的投票贊成),但經過廣泛討論和修改后,共識小組一致支持重新表決,并最終通過了納入門檻(97%投票贊成)。
6.2 管理信息
(1)SPIRIT-AI 1(i)說明:表明AI/機器學習相關的干預措施并指明模型類型。
解釋:鼓勵在方案標題和(或)摘要中指出干預措施涉及AI,以便可以立即將其確定為AI/ML干預類別,并有助于在文獻數據庫、登記數據庫和其他在線資源中對試驗方案進行索引和搜索。標題應該能被廣大讀者理解,因此鼓勵使用接受度更為廣泛的術語,如“人工智能”或“機器學習”。
應該在摘要中使用更精確的術語,而不是標題,除非它們被廣泛地認為是作為AI/ML的一種形式。與模型類型和架構相關的具體術語應在摘要中詳細說明。
(2)SPIRIT-AI 1(ii)說明:陳述AI干預的預期用途。
解釋:AI干預的預期用途應在方案標題和(或)摘要中明確。這應該描述AI干預的目的和疾病背景。一些AI干預措施可能有多項預期用途,或者預期用途可能隨著時間的推移而演變。因此,記錄這一點可以讓讀者了解在試驗時該算法的預期用途。
6.3 引言
(1)SPIRIT-AI 6a(i)擴展:解釋人工智能干預在臨床路徑中的預期用途,包括其目的和預期用戶(如醫療保健專業人員、患者、公眾)。
解釋:為了闡明AI干預將如何適應臨床路徑,應在方案背景中詳細描述其作用。AI干預可以設計為與不同的用戶交互,包括醫療專業人員、患者和公眾,他們的角色可以是廣泛的(如相同的AI干預理論上可以取代、增強或判定臨床決策的部分內容)。闡明AI干預的預期用途及其預期使用者有助于讀者理解在試驗中評估AI干預的目的。
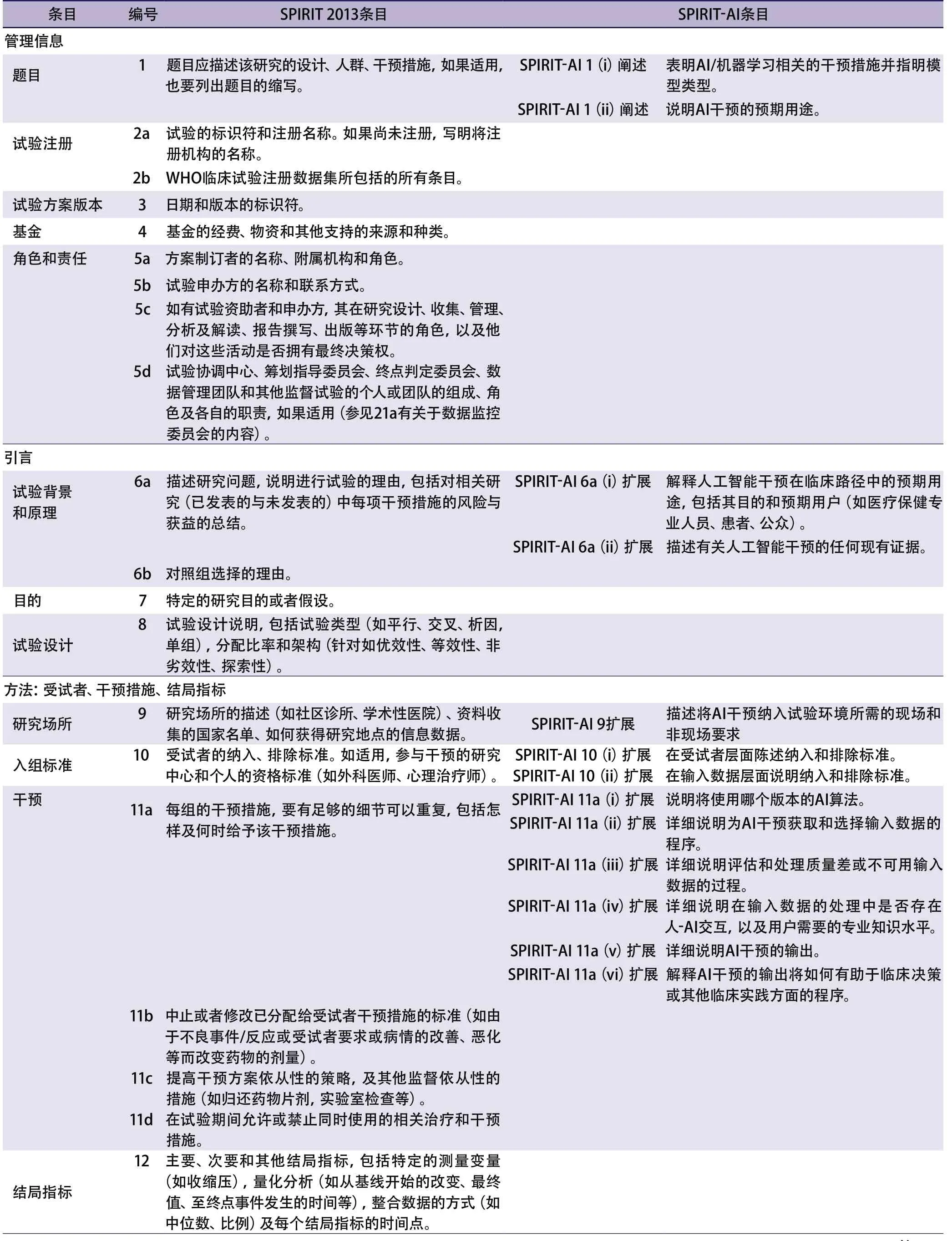
表2 SPIRIT-AI條目清單
(2)SPIRIT-AI 6a(ii)擴展:描述有關AI干預的任何現有證據。
解釋:作者應在研究方案中描述任何與AI干預的有效性相關的已發表證據(支持性參考文獻)或未發表的證據,或AI干預相關方面缺乏的說明。應考慮證據是否用于與計劃的試驗相似的用途、設置和目標人群。這可能包括AI模型的前期開發、內部和外部驗證以及試驗前所做的任何修改。
6.4 受試者、干預措施和結局
(1)SPIRIT-AI 9擴展:描述將AI干預納入試驗環境所需的現場和非現場要求。
解釋:AI算法的泛化存在局限性,其中之一是當它們在開發環境之外使用時。AI系統依賴于其運行環境,研究方案應提供硬件和軟件要求的詳細信息,以便在每個研究場所對AI干預進行技術整合。例如,應該說明AI干預是否需要與供應商的設備綁定,是否每個研究場所需要有專有計算硬件,或者研究場所是否必須支持云集成,特別是這些設備是否需要特定的供應商。如果在實施過程中需要在每個研究場所對算法進行任何更改(如根據本地數據對算法進行微調),則還應清楚地描述此過程。
(2)SPIRIT-AI 10(i)說明:在受試者層面陳述納入和排除標準。
解釋:納入和排除標準應根據非AI干預試驗方案中的慣例在受試者層面進行定義。這不同于在數據輸入層面制定的納入和排除標準,后者在條目10(ii)中作了說明。
(3)SPIRIT-AI 10(ii)擴展:在輸入數據層面說明納入和排除標準。
解釋:“輸入數據”是指AI干預為實現其預期用途目標所需的數據(如對于乳腺癌診斷系統,輸入數據可以是未經處理或特定廠商的提供的乳腺癌鉬靶X線掃描后處理數據,據此進行診斷;對于預警系統,輸入數據可以是電子病歷中的生理指標或實驗室結果)。試驗方案應預先規定是否對輸入數據(如圖像分辨率、質量指標或數據格式)有最低要求,以確定隨機化前的合格性。它應具體說明評估的時間、方式和人員。例如,如果受試者符合第10(i)項所述的CT掃描平躺的標準,但掃描質量(出于任何特定原因)降低到不再適合AI系統使用,則應將其視為輸入數據級別的排除標準。請注意,如果輸入數據是在隨機分組后獲得的(由SPIRIT-20c解決),任何排除都被認為是來自分析層面,而不是來自入組標準(圖1)
(4)SPIRIT-AI 11a(i)擴展:說明將使用哪個版本的AI算法。
解釋:與其他形式的醫療設備軟件類似,AI系統在其生命周期內可能經歷多次修改和更新。研究方案應說明將在臨床試驗中使用哪種版本的AI系統,以及該版本是否與先前用于證明研究理由的研究中使用的版本相同。在可行的情況下,研究方案應說明相關版本之間發生了什么變化以及變更的理由。在適用的情況下,研究方案應包括市場監管機構備案,例如唯一設備標識符,它要求設備更新版本的新標識符。
(5)SPIRIT-AI 11a(ii)擴展:詳細說明AI干預中獲取和選擇輸入數據的程序。
解釋:任何AI系統的測量性能可能嚴重依賴于輸入數據的性質和質量。應提供如何處理輸入數據的程序,包括AI系統分析前的數據采集、選擇和預處理。這個過程的完整性和透明性是可行性評估和未來將該干預措施推廣的重要保障。它還將有助于確定輸入數據處理流程是否將在不同的試驗場所進行標準化處理。
(6)SPIRIT-AI 11a(iii)擴展:詳細說明評估和處理質量差或不可用輸入數據的程序。
解釋:與SPIRIT-AI 10(ii)類似,“輸入數據”是指AI實現預期用途所需的數據。如第10(ii)項所述,AI系統的性能可能受輸入數據質量差或缺失(如心電圖上的異常運動偽影)影響。研究方案應規定是否以及如何識別和處理質量差或不可用的輸入數據。方案還應規定輸入數據所需的最低標準,以及未達到最低標準時的處理流程(包括對受試者管理路徑的影響或其他任何變化)
質量差或不可用的數據也同樣會影響非AI的干預效果。例如,較差的掃描質量可能會影響放射學家診斷的結果。因此,輸入數據在AI干預組和對照組應保持一致。如果該最低質量標準與隨機化前評估的合格輸入數據的納入標準不同,則應予以說明。
(7)SPIRIT-AI 11a(iv)擴展:詳細說明在輸入數據的處理中是否存在人-AI交互,以及用戶需要什么專業知識水平。
解釋:當處理輸入數據時,應提供人-AI界面的描述和良好人-AI交互的要求。例如臨床醫師引導從組織切片中選擇感興趣的區域,并可由AI診斷系統解釋,或者由內科醫師選擇的結腸鏡檢查視頻片段作為用于檢測息肉的算法的輸入數據。對即將使用AI干預措施的用戶培訓的描述以及用戶如何處理輸入數據的說明應該是清晰的,并且在試驗流程中是可重復的。人-AI交互不清楚可能導致用戶無法做到標準化操作,并可能帶來倫理影響,尤其是在發生危害的情況下。例如,一旦發生錯誤,將很難界定是由于人為偏離操作流程,還是由AI系統造成的錯誤。
(8)SPIRIT-AI 11a(v)擴展:詳細說明AI干預的輸出。
解釋:AI干預的輸出應在研究方案中明確規定。例如,AI系統可以輸出診斷分類或概率、建議的操作、對事件發出警報(如輸注藥物的滴定)或其他輸出。AI干預輸出的性質直接說明了它的可用性以及它如何導致下游行動和結果。
(9)SPIRIT-AI 11a(vi)擴展:解釋AI干預的輸出將如何有助于臨床決策或其他臨床實踐方面的程序。
解釋:由于受試者的健康結果也可能很依賴用戶如何與AI干預進行交互,試驗方案應解釋AI系統的輸出結果如何用于臨床決策或臨床實踐。應該詳細描述能夠影響受試者結局的下一步干預措施。與SPIRIT-AI 11a(iv)類似,應詳細描述人-AI交互對輸出結果的各種影響,包括理解輸出結果所需的專業知識水平以及為此目的提供的任何培訓和(或)說明。例如,以概率可能性作為輸出的皮膚癌檢測系統應附有解釋,說明輸出結果如何解釋和用戶如何行動,并指定兩種預期途徑(如果診斷為陽性,則行皮膚病變切除術)和進入這些路徑的閾值(如果診斷為陽性且概率大于80%,則進行皮膚病變切除)。參照性的干預措施產生的信息應類似地描述,并解釋如何使用這些信息進行患者管理的臨床決策,以及它們之間在哪兒相關。
6.5 監控方法
(1)SPIRIT-AI 22擴展:闡述識別和分析性能錯誤的任何計劃。如果沒有計劃,請說明理由。
解釋:性能錯誤的報告和失敗案例的分析對AI干預尤其重要。AI系統可能會犯一些難以預見的錯誤,忽視這些問題而進行大規模部署,可能會造成嚴重后果。因此,識別錯誤問題并確定風險控制策略對確定何時進行安全實施干預措施以及針對哪些人群使用是極為關鍵的。研究方案中應該詳細說明是否有分析性能錯誤的規劃。如果沒有這方面的規劃,應在研究方案中說明理由。
6.6 倫理與宣傳
(1)SPIRIT-AI 29擴展:說明是否能以及如何訪問AI干預和(或)其代碼,包括訪問或重復使用的任何限制。
解釋:研究方案應明確是否能以及如何訪問或重復使用AI干預和(或)其代碼。應包括相關許可證和訪問限制的詳細信息。
7 討論
SPIRIT-AI擴展與SPIRIT 2013及其他相關的SPIRIT擴展一起,為臨床試驗方案中應報告的AI特定信息提供了基于國際共識的指導。它包括了15項條目:3項是在AI試驗背景下對現有SPIRIT 2013指南的闡述,以及12項新的擴展。該指南的目的不是規定AI試驗的研究方法,相反,它旨在提高在報告臨床試驗設計和方法時的透明度,以更易于理解、解釋和同行評議。
許多擴展條目涉及干預措施[條目11(i)~11(vi)]、設置(條目9)和預期效果[條目6a(i)]。針對AI系統的相關方面提出了具體建議,包括算法版本、輸入輸出數據、整個試驗設置、用戶的專業知識以及根據AI系統的建議可采取的執行研究方案等。專家一致認為,這些細節對于獨立評估研究方案至關重要。期刊編輯指出,盡管這些條目很重要,但目前它們在提交用于發表的試驗方案和報告中經常被遺漏,這一現象更加突出了將它們加入特定擴展條目的必要性。
德爾菲評論和共識小組討論的一個共同的焦點是AI系統的安全性。與其他衛生干預措施不同,AI系統可能產生無法預測的錯誤,而這些錯誤通過人類判斷不易被檢測或解釋。例如,對人眼來說,不可見的或隨機出現的醫學影像變化可能會完全改變診斷結果的可能性。令人擔憂的是,鑒于AI系統在理論上可以輕易大規模部署,任何意想不到的有害后果都可能是極其嚴重的。為此添加了兩個擴展項。SPIRIT-AI第6a(ii)項要求說明驗證AI干預證據的等級水平。SPIRIT-AI第22項要求對所有分析性能錯誤的計劃進行說明,以強調預測算法所產生的系統性錯誤及其后果的重要性。
德爾菲調查和共識會議提出了一個未包括在最終指南中的主題,即“持續進化”AI系統(也被稱為“持續適應”或“持續學習”AI系統)。這些AI系統能夠不斷地對新數據進行訓練,使其性能可能會隨著時間的推移而發生變化。專家組注意到,雖然這很有趣,但這一領域尚處在相對早期的發展階段,在醫療應用中缺乏實例,因此目前不適宜在SPIRIT-AI指南中強調。這一主題將在SPIRIT-AI的未來迭代中被觀察和重新討論。值得注意的是,軟件的逐步更新,無論是連續的還是迭代的,有目的性還是無目的性,都可能對部署后的安全性能產生嚴重的后果。因此,至關重要的是,應按軟件版本記錄和確定這些變更,并制訂強有力的部署后監督計劃。
本研究是在當前健康領域中的AI背景下進行的,因此,需要注意幾個局限性。首先,在SPIRIT-AI提出時,醫療AI領域只有7項已發表的試驗,尚無已發表的試驗方案。因此,在SPIRIT-AI的開發過程中所做的討論和決定并不是都有現有實例的支持。這源于我們聲明的目標,即盡早解決AI領域試驗方案設計較差的問題,認識該領域強大的驅動因素,以及AI研究設計和報告的具體挑戰。隨著科學和AI研究的發展,我們歡迎研究人員合作,共同發展這些報告標準,以確保其持續的相關性。其次,AI隨機對照試驗的檢索使用了“人工智能”“機器學習”和“深度學習”等術語,但沒有使用“臨床決策支持系統”和“專家系統”等術語,這些術語在20世紀90年代更常用于基于AI系統的技術,其風險與最近的案例類似。這類系統如果今天發表,很可能會被編入“人工智能”或“機器學習”的索引。然而,臨床決策支持系統在這個共識過程中并沒有得到積極的討論。第三,最初的候選條目列表是由范圍相對較小的專家組提出,該專家組由指導小組成員和其他的國際專家組成。但是,由規模更大的德爾菲專家小組提出的新項目在共識小組進行了討論,共識會議期間或會后評估期間沒有新項目提出。
與SPIRIT聲明一樣,SPIRIT-AI擴展旨在作為最低限度的AI試驗報告指南,對于試驗方案,還有AI相關的其他注意事項可能值得考慮。此擴展特別針對已經計劃或正在進行臨床試驗的研究者,不過,它也可以在AI系統的早期驗證階段為AI干預的開發者提供有用的指導。研究人員若想報告研究進展以及驗證AI模型的診斷和預測性能應參考“基于機器學習的個體化預后或診斷的多變量預測模型透明報告”(Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis-Machine Learning,TRIPODML)和“基于人工智能診斷準確性研究的報告標準”(Standards for Reporting Diagnostic Accuracy Studies-Artificial Intelligence,STARD-AI),這兩者目前均在開發中。其他潛在相關的指導原則(對研究設計不確定)已在EQUATOR網站注冊。SPIRIT-AI擴展的推出希望可以鼓勵對AI干預的臨床試驗進行謹慎的早期規劃,與CONSORT-AI結合起來,將有助于提高AI干預試驗的質量。
人們普遍認為AI是一個快速發展的領域,隨著技術和新的應用方向的發展,將有必要對SPIRIT-AI進行更新。目前,AI/ML的多數應用涉及疾病檢測、診斷和分診,這可能會影響SPIRIT-AI條目的性質和優先順序。隨著“AI成為治療手段”的廣泛應用,根據這些研究重新評估SPIRIT-AI將是非常重要的。此外,計算機技術的進步以及將其整合到臨床工作流程中的能力將為醫療創新帶來新的機遇,從而使患者受益。然而,研究設計和報告也可能伴隨新的挑戰,以確保透明度,最大限度地減少潛在偏倚,并確保此類研究的結果值得信賴,以及它們可能在多大的程度上可推廣。SPIRITAI和CONSORT-AI 指導小組將會持續關注更新的需要。
數據獲取:可向通信作者提出數據請求,由SPIRIT-AI和CONSORT-AI指導小組考慮是否提供。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
遼金歷史與考古(2019年0期)2020-01-06 07:45:20
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年11期)2018-08-04 03:26:04
汽車工程學報(2017年2期)2017-07-05 08:13:02
國際商務財會(2017年8期)2017-06-21 06:14:14
電子制作(2017年23期)2017-02-02 07:17:19
