基于數據挖掘的灌溉渠道運行狀況健康度檢測研究
2020-11-28 07:16:08趙鐘聲許景輝王一琛
灌溉排水學報 2020年11期
趙鐘聲,許景輝,*,王 雷,王一琛
(1.西北農林科技大學 旱區農業水土工程教育部重點實驗室,陜西 楊凌 712100; 2.西北農林科技大學 水利與建筑工程學院,陜西 楊凌 712100; 3.西北農林科技大學 機械與電子工程學院,陜西 楊凌 712100)
0 引 言
灌區渠道工程主要包括總干、干、支、斗、農渠及其相關輸擋水建筑物[1],各渠道運行健康狀況跟灌區水資源利用效率密切相關[2]。傳統渠系滲漏等健康狀態判別主要通過人工巡視的方法進行[3],此方法不但費時費力,無法判明水下建筑物狀況,還因巡檢人員經驗不同而造成誤判或漏判,導致灌區水資源嚴重浪費。當前現代化灌區已基本實現渠道流量、流速、水位變化等數據自動采集記錄[4-6]。【研究意義】但灌區僅對周期性水量進行統計[7],如果能通過數據挖掘等先進技術,揭示渠系用水規律,發現并提取渠系運行健康評測指標,這將對提高水資源利用效率以及灌區生產、管理起到積極作用并產生重要意義。
數據挖掘是指根據特定業務目標從海量數據中提取潛在有效且可以理解的、模式的高級過程[8-10]。【研究進展】常占峰[11]采用Geodatabase 地理數據庫技術對特定灌區水文數據進行組織研究,提出昌馬灌區水文數據組織建模思路框架。宋海瑞等[12]基于都江堰灌區數據中心建立了相應數據挖掘模型。趙麗華[13]對灌區渠系數據中水情監測判別方法進行了相關探討研究。Moavenshahidi 等[14]利用灌區自動通道控制的水位數據研發了一種計算機模型,用于估算灌區不同通道河段的滲流率。李釗等[15]通過數據挖掘并引進機器學習思想,提出一種渠道糙率直接反演方法。【切入點】以上研究都是通過數據挖掘對灌區水文水情、規劃設計、渠道糙率等的探討,而對數據挖掘技術在檢測灌區渠系建筑物運行健康方面研究較少。
本文基于陜西關中地區某灌區總干、干、支、斗渠道2014 年10 月—2018 年10 月流量數據以及灌區渠道輸水灌溉發生運行不良狀況的各項異常終端報警信息,提取渠道運行不良關鍵特征指標。【擬解決的關鍵問題】通過LM(Levenberg Marquard)神經網絡構建灌區渠道運行健康檢測模型,并與傳統BP(Back-ProPagation Network)神經網絡、CART(Classification and Regression Tree)決策樹識別模型進行對比,探究LM 網絡模型在渠系運行健康識別方面效果,為灌區合理判別渠道運行健康狀態提供理論研究與技術支持。
1 材料與方法
1.1 研究區概況
選取灌區位于陜西關中地區,類型為大型(Ⅱ)灌區,主要種植作物為玉米、棉花、冬小麥等。2010年灌區進行了現代化建設改造,在灌區總干、干、支、斗各級渠道渠首設水量測控裝置,其數據以1 h 為間期回傳管理中心。在總干、干、支渠道區段內設水位、流速、淤積度監測報警裝置。
灌區渠系分布主要為:3 個總干渠(總南干渠(S)、總中干渠(M)、總北干渠(N));7 個干渠(南干渠Ⅰ(S-A)、南干渠Ⅱ(S-B)),中干渠Ⅰ(M-A)、中干渠Ⅱ(M-B)、中干渠Ⅲ(M-C),北干渠Ⅰ(N-A)、北干渠Ⅱ(N-B));40 個支渠(例:S-A1、S-B1等)以及若干斗渠等。
1.2 數據抽取與探索分析
與灌區渠道運行健康狀態相關的原始數據主要為實時流量,水位、流速超警戒或低警戒報警數據、淤積度報警數據以及渠道發生運行不良記錄數據等。本模型所用數據為2014 年10 月—2018 年10 月灌區內總干、干、支渠道運行不良相關數據以及主要灌溉時期內部分運行良好的總干、干、支、斗渠道數據,并應用周期性分析方法對流量數據進行數據探索分析。
如圖1 所示,當渠道運行健康時,上級渠道渠首引水平均流量減去運行正常下級各渠道渠首引水平均流量總和在一定范圍內比較平穩,波動不大;而當渠道運行不健康時,非正常運行渠道上,其上級渠道渠首引水平均流量減去運行不正常下級各渠道渠首引水平均流量總和的差值隨時間變大,而后在一定波動范圍趨于穩定。
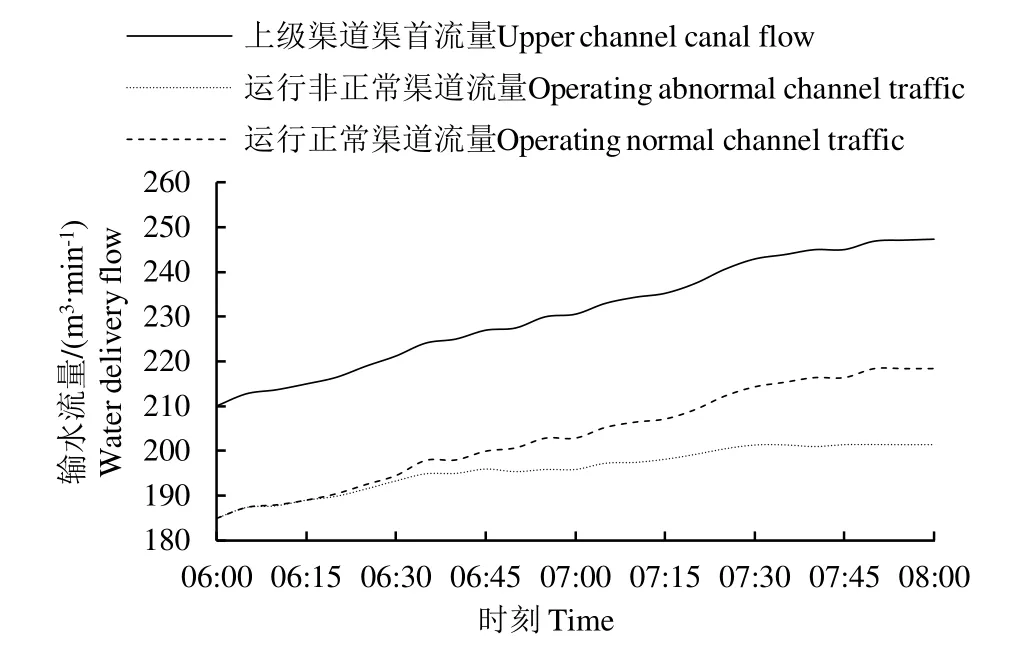
圖1 渠道運行正常與非正常時流量趨勢變化對比圖 Fig.1 Comparison of traffic trends during normal and abnormal channel operation
1.3 特征指標提取
從數據庫得到的渠道流量數據雖在一定程度上能反應出渠道運行不健康規律特征,但要作為構建模型專家樣本輸入項,在特征表現上不夠明顯。本文基于數據變換,得到新的特征評價指標來反映渠道運行健康狀況特征規律。
渠道運行狀況特征指標評價體系主要為:
1)單位時間流量損失率增長趨勢指標
假設在灌水周期幾天或幾周內灌區渠道沿程水量損失(水分蒸發、渠道滲漏等)隨外界變化波動不大,q損定值。對運行狀況良好渠道有q進=q出+q沿損;當渠道運行不良,發生事故造成水量損失q損時,有q進= q出+q沿損+q損。
同一個渠道同一時間段內單位時間流量損失率為wi=(q損/q進)×100%。若wi增大,說明單位時間流量損失占q進比重越來越大。對同一個渠道來說,在q損不變情況下,表明渠道有其他水量損失,說明渠道運行出現漏水等不健康狀況。
當渠道運行不良時,在短時間內其單位流量損失率急劇增加,而后趨于平緩。但由于渠道單位時間流量損失率存在波動,單純以前一個單位時間流量損失率與后一流量損失率相比誤差過大。通過對該灌區渠道流量損失率誤差數據分析發現,當2 個流量損失率誤差大于0.9%以上時,渠道流量損失會產生較大變化。本研究考慮后一個單位時間流量損失率比前一個損失率的增長率是否大于1%。若增長率大于1%,則渠道運行狀況可判為不健康。
設在一個統計周期內單位時間流量損失率統計為:
2)輸水量損失增長趨勢指標
同單位時間流量損失率增長趨勢指標假設一樣,w沿損為定值。則在統計周期單位時間步長內渠道進水量w進、出水量w出和輸水損失ki關系式為ki=w進-w出-w損,其中i 為第幾單位時間步長序號,i=1、2、3、4、…m。
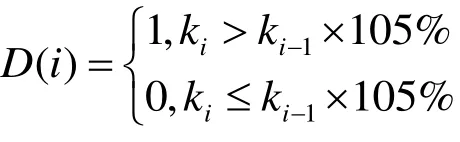
3)測控告警類指標
與灌區渠道輸水運行非健康相關報警主要有渠道水位超警戒線、低警戒線,流速過大、過小報警以及渠道淤泥度監測報警等,本研究以計算發生與灌區渠道輸水灌溉期間運行非健康相關報警次數總和為測控告警類指標。
1.4 構建專家樣本
對2014 年10 月—2018 年10 月該灌區內運行非健康渠道以及灌水期內部分運行良好渠道的流量、告警數據和該渠道在統計步長周期內運行是否健康標志,按渠道運行狀況特征評價指標進行處理并選取其中915 個樣本數據,得到專家樣本數據庫。
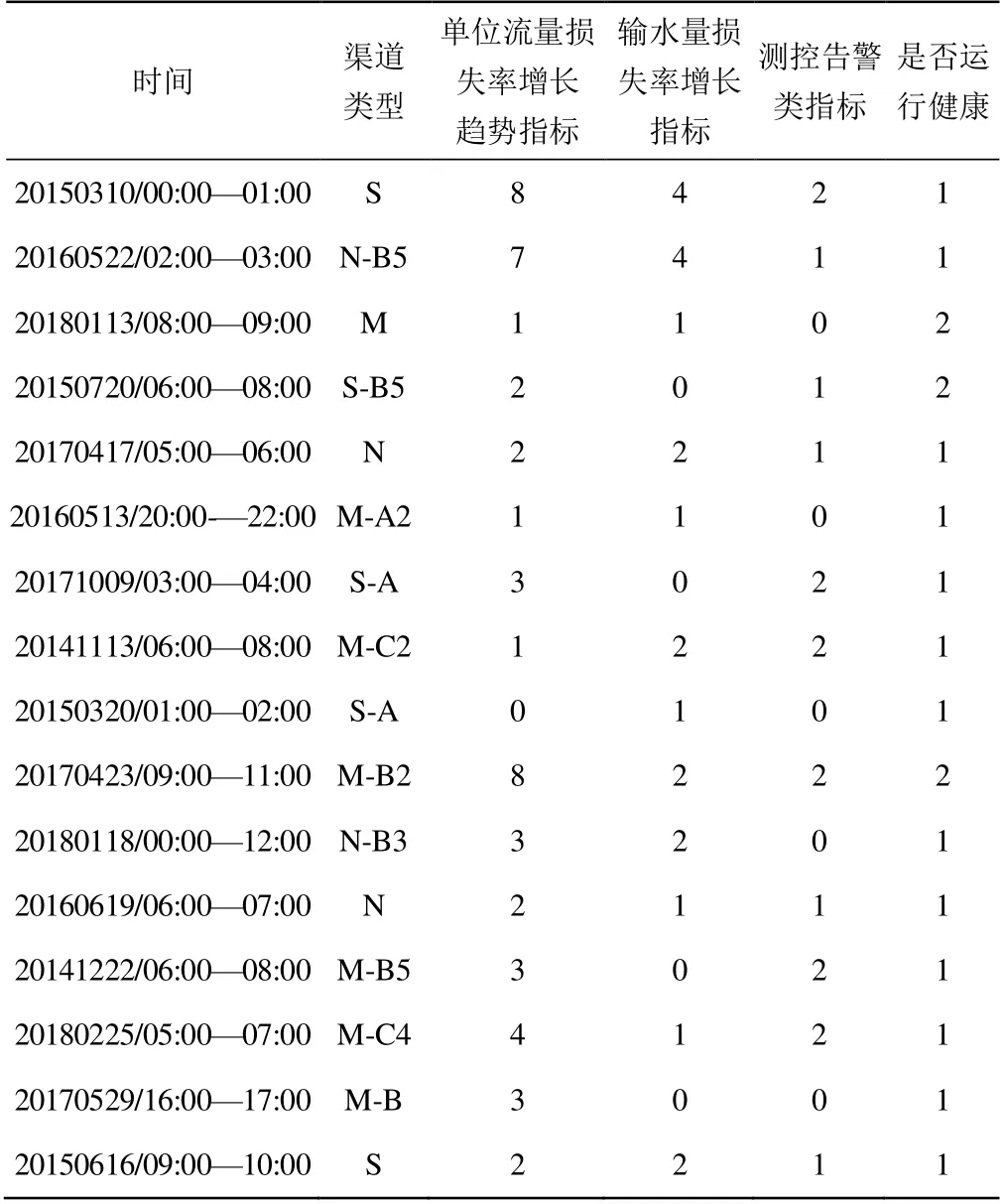
表1 專家樣本數據示例 Table 1 The expert sample data example
在構建專家樣本數據中,對總干渠、干渠以1 h為1 個統計周期,其中單位時間流量步長以5 min 為1 個時間段計,單位時間輸水量步長以10 min 為1 個時間段計;對支渠以2 h 為1 個統計周期,單位時間流量步長以10 min 為1 個時間段計,單位時間輸水量步長以20 min 為1 個時間段計。
1.5 模型構建
灌區渠道運行是否健康的識別可通過構建分類預測模型來實現。本文選用LM 神經網絡模型構建灌區渠道運行健康狀況識別,并與傳統BP網絡和CART決策樹模型進行對比,以評價LM 神經網絡模型對渠道運行是否健康識別的適應性。3 種模型中輸入項分別為“單位流量損失率增長趨勢指標”、“輸水量損失率增長趨勢指標”、“測控告警類指標”,輸出項為是否健康標志“1”或“2”(“1”代表渠道在統計周期內運行狀況正常,“2”表示不正常)。
采用信賴域算法模擬目標函數f(x)的二次模型,計算式為:

式中:s 為自變量;gTk為梯度;Gk為H 矩陣;hk為第k 次迭代的信賴域上界,其范數沒有指定。
高斯-牛頓公式、牛頓數學公式、LM 算法分別為:

式中:g=JTf,u≥0。當u=0 時,LM 算法退化為高斯牛頓法;當u 很大時,LM 算法變為:

LM 算法重點是確定u 值,引入一評價量δ,計算式為:
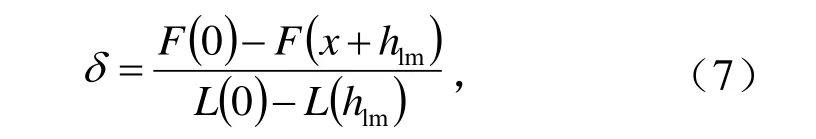
δ 描述使用L 的下降量對F 下降量的近似程度。若δ 較大,說明近似效果較好,u 可以繼續減小使LM更接近于高斯-牛頓法;若δ較小,則近似效果較差,因此可以增大u 使得LM 更接近梯度法[17]。在LM 算法中迭代結束條件只要滿足以下3 條之一即可:①下降梯度g 小于某一設定閥值;②前后2 次x 的差小于某一閥值;③達到最大迭代次數kmax。
本模型迭代結束條件為設定達到最大迭代次數kmax=1 000,同時依據樣本數據輸入項建立LM 神經網絡模型設定輸入節點為3 個、隱層節點數12、輸出節點2 個,顯示間隔次數為25、目標誤差為0、最大校驗失敗次數為7、最大誤差梯度1e-7,初始u 為0.001,增長比率為10、減少比率為0.1、最大值為1010。
2 結果與分析
2.1 模型分析與評價
構建模型時將915個專家樣本隨機抽取83%作為訓練樣本,17%為測試樣本。對3 個模型均重復訓練,取最優分類結果。
研究發現,759 個訓練樣本分類中3 個模型綜合最優分類準確率幾乎相差不大,都達到98%以上。其中,對運行正常渠道分類,3 個模型準確率均高于99%,LM 神經網絡模型的準確率最高,BP 神經網絡模型與CART 決策樹模型準確率相等;誤判比例均小于0.5%。對運行不正常渠道分類,3 個模型準確率都在90%以上,BP 神經網絡模型與LM 神經網絡模型相等并高于CART 決策樹模型;誤判比例均小于1.0%。3 種模型混淆矩陣結果如圖2 所示(圖中運行正常渠道標志為類“1”,運行不正常渠道標志為類“2”)。

圖2 3 種模型混淆矩陣 Fig.2 Confusion matrix of three models training data classification results
對比156 個測試樣本輸出類與實際類發現,3 個模型綜合預測分類準確率都在94%以上。其中,BP神經網絡模型與LM 神經網絡模型的分類綜合準確率均為96.2%,高于CART 決策樹模型。對運行正常渠道分類,3 個模型準確率均為100%;對運行不正常渠道分類,BP 神經網絡模型與LM 神經網絡模型準確率同為76%,高于CART 決策樹模型。3 個模型測試輸出類與實際類對比分析結果如表2 所示。

表2 3 個模型測試輸出類與實際類對比 Table 2 The output and actual class proportion results of three models

圖3 3 種模型測試樣本分類ROC 曲線對比 Fig.3 The comparison of ROC curves of three model test samples
為進一步評估模型分類性能,本文同時用156 個測試樣本對3 個模型進行ROC(Receiver operating characteristic curve)曲線評估。3 個模型測試ROC 曲線如圖3 所示。一個優秀分類模型所對應ROC 曲線應是盡可能靠近左上角完美曲線。通過圖3 比較發現,LM 神經網絡模型比傳統BP 網絡、CART 決策樹模型表現更優。LM 神經網絡模型中運行正常渠道分類準確度折線與運行不正常渠道預測分類準確度折線下的面積更大,說明LM 神經網絡模型分類性能更優,可實際應用于渠道運行健康狀況識別檢測。
2.2 實際應用
灌區渠道運行狀況識別,在實際生產中主要是對運行狀況不健康渠道進行判別。為探究LM 神經網絡模型在實際應用中的適應性,選取該灌區2018 年12月—2019 年7 月灌水周期內總北干渠(N)、中干渠Ⅱ (M-B)、北干渠Ⅰ(N-A)、南干渠Ⅱ(S-B)以及支渠(N-A1、N-A3、N-A5、N-A6、M-B1、M-B2、M-B4、M-B6、S-B1、S-B4、S-B6、S-A1、S-A3、M-C3、M-C5、N-B5、N-B3、S-A4、M-C1)流量數據和終端報警數據。通過Matlab 編程對原始數據預處理并提取相應特征指標,得到模型輸入項數據實現對灌區渠道運行不健康狀況識別檢測,結果見表3。
分析表3 可知,LM 神經網絡模型正確識別出在統計灌水周期內該灌區運行不健康渠道共21次中的17次,錯誤判斷2 次,漏判2 次,準確率為80.95%;其中對3 條干渠判斷中1 個漏判,1 個錯判。進一步分析發現,由于干渠中流量數據較大并且對干渠本研究以1 h 為統計周期,其統計時間周期較長,造成了模型對干渠運行健康狀況識別不夠敏感。本次統計灌水周期內總北干渠(N)無發生渠道運行不正常狀況。對表3 總體分析來看,LM 神經網絡模型對該灌區渠道運行不正常識別準確率在80%以上,達到實際應用要求。

表3 模型識別結果與實際稽查結果比較 Table 3 The comparison of model recognition results with actual audit results
3 討 論
灌區渠道運行檢測一直是灌區生產管理中的重點與難點[18],對其運行健康狀況的檢測當前基本上采用傳統的人工檢測方法[19],而基于數據挖掘技術以及神經網絡分析方法對灌區渠道輸水健康狀況檢測目前鮮有研究。本文通過對特定灌區流量數據以及各項異常終端報警信息數據分析與處理,提取出渠道運行狀況特征指標并構建專家樣本數據,通過模型分類可以良好地反映出渠系運行健康狀況。研究結果與劉恒[20]基于神經網絡模型對洪水分類預測準確度相似。應用ROC 曲線評估三模型分類準確度,發現LM網絡模型的分類準確度折線均比傳統BP 網絡[21]、CART 決策樹模型更靠近左上角,研究結果與趙文倉等[22]基于LM 算法對用戶竊漏電行為預測結論基本一致。說明LM 神經網絡模型最優,可以應用于實際灌區渠道運行健康狀況檢測識別。
4 結 論
本文構建的LM 神經網絡模型與傳統CART 決策樹模型、BP 網絡模型相比,對灌區灌溉渠道運行狀況健康識別準確率表現更優,對759 個訓練樣本與156個測試樣本的綜合識別準確率分別為98.6%、96.2%,并且測試樣本中ROC 曲線更靠左上角。在實際應用中,LM 神經網絡模型對該灌區統計周期內運行不正常渠道正確識別率達到80%以上,滿足實際應用要求。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
