基于后悔理論及EDAS法的概率語言多屬性群決策方法
2020-11-30 05:47:22童玉珍王應明
計算機應用 2020年11期
童玉珍,王應明
(福州大學經濟與管理學院,福州 350116)
(?通信作者電子郵箱576856545@qq.com)
0 引言
決策在我們的日常生活中是非常普遍但又極其重要的一項活動。在傳統的模糊語言決策方法中,決策者僅通過一個語言術語去表達自己的偏好或者評價,然而在許多復雜的決策問題中,決策者通常很難僅用單一的語言術語來表達自己猶豫不決的定性意見。為了解決這類問題,Rodriguez 等[1]提出了猶豫模糊語言術語集,它在實際的定性決策中,可以用來表示復雜、猶豫的語言表達。需要指出的是,目前大多數關于猶豫模糊語言術語集的研究中,都默認決策者提供的語言術語具有同等的重要性,事實上決策者可能會更傾向于某個評價語言術語,這些語言術語集可能有不同的重要性程度。因此,Pang 等[2]提出了概率語言術語集(Probabilistic Linguistic Term Set,PLTS),在不丟失任何原始語言信息的前提下通過添加概率信息拓展了猶豫模糊語言術語集,概率語言術語集不僅允許決策者在決策過程中出現猶豫不定的情況,同時結合概率來表達決策者的偏好信息。概率語言術語集的提出得到了許多學者關注,Zhang等[3]提出了概率語言的偏好關系及其一致性指數,并提出一種自動優化的方法去提高一致性;Gou 等[4]提出了概率語言新的基本運算法則;Lin 等[5]提出了概率語言術語集的距離度量方法并將其運用于多屬性群決策中;Bai 等[6]運用圖解法去分析概率語言的結構并提出概率語言術語集的新的比較方法;Liao 等[7]提出了一種利用概率語言信息進行多準則決策的線性規劃方法;文獻[2,7-10]則將一些經典的決策方法如TOPSIS(Technique for Order Preference by Similarity to Ideal Solution)、ORESTE(Organísation,Rangement Et Synthèse Dedonnées Relarionnelles)、LINMAP(LINear programming technique for Multidimensional Analysis of Preference)、PROMETHEE(Preference Ranking Organization Methods for Enrichment Evaluations)、BP(Bidirectional Projection)等拓展到了具有概率語言信息的多屬性決策中。
目前越來越多學者關注到決策者心理行為對于現實決策過程及決策結果的影響。在眾多基于有界理性的方法中,運用最廣泛的是前景理論[11]和后悔理論[12]。由于后悔理論在計算過程中沒有較多的參數,計算簡便,越來越多的學者將其運用于多屬性決策問題中。Xia[13]考慮了策者的猶豫行為和后悔行為,提出豫模糊語言多準則決策以識別出不同類型的最佳選擇;Peng 等[14]結合后悔理論與ELECTRE Ⅲ(ELimination Et Choix Traduisant la REalité)法建立了能夠有效支持新能源投資決策的模型;Jiang 等[15]考慮決策者后悔規避的心理行為提出了一種新的模糊廣義后悔決策方法;Wang等[16]提出一種新的基于項目的后悔理論方法來解決區間二型模糊環境下的決策問題。Keshavarz 等[17]在2015 年提出了離平均方案(平均解)距離的評價(Evaluation based on Distance from Average Solution,EDAS)方法,它不僅在不同的權重下具有穩定性,而且與現有的一些決策方法如VIKOR(VlseK riterijumska Optimizacija I KOmpromisno Resenje)、AHP(Analytic Hierarchy Process)等有很好的一致性。EDAS 法具備的穩定性、有效性及計算過程的簡易性,使其在近幾年得到了較快的發展,Kahraman 等[18]結合直覺模糊集提出了直覺模糊EDAS 法;Keshavarz 等[19]考慮一種符合正態分布的決策屬性值提出了隨機EDAS法;Stanujkic等[20]將EDAS法拓展到了屬性值為區間灰色值的多屬性決策問題中。
基于以上分析,很多學者針對屬性值為概率語言的決策問題,提出了一些決策方法,但需要指出的是大多數的決策方法假設決策者是一個“完全理性人”。但在不確定的前提之下進行決策時,對于決策者的非理性行為因素應予以著重考慮,這也更加符合決策的實際情況;而關于后悔理論的多屬性決策問題的研究及探討,大多數是基于決策屬性值為猶豫模糊數、區間值或精確值等,而對于決策屬性值為概率語言的研究目前還較少。而在時間緊迫、信息不完全以及在決策者自身認知的局限性的情況下,決策者很難及時地對決策屬性值給出精確的評價值,而是會更加傾向于運用更符合人類思維習慣的語言術語去給出科學的符合現實的評價值。最后,EDAS作為近幾年提出的較新的多準則決策方法,一般運用于屬性值為數值的決策問題中,而對于屬性值為定性的特別是運用于屬性值為概率語言的多屬性決策問題的相關研究還較少。
針對現有研究的分析,本文考慮將后悔理論及EDAS 法拓展到概率語言信息的決策環境下:首先利用新的概率語言熵及交叉熵建立屬性權重確定模型;然后考慮決策者后悔規避的心理行為同時將群體滿意度公式拓展到概率語言信息下用于計算后悔、欣喜感知效用值;最后針對屬性值為概率語言術語集決策問題,結合EDAS 法與后悔理論,提出一種基于后悔理論及EDAS 法的概率語言多屬性群決策方法,并將其運用于突發事件的處理與決策中。
1 基本概念
1.1 概率語言術語集
定義1基于加性語言評價量表S={sα|α=-τ,…,-1,0,1,…,τ}(其中τ 是一個正整數),根據文獻[2]概率語言術語集被定義為:
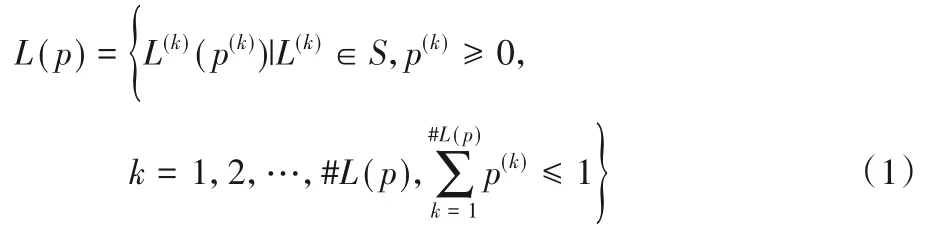
其中:L(k)(p(k))是具有概率信息為p(k)的語言術L(k);r(k)是語言術語集L(k)的下標;#L(p)是L(p)中語言術語的數量。
根據文獻[21]中提出的猶豫模糊語言熵及交叉熵、文獻[4]提出的概率語言等價變換函數,并結合概率語言性質及與猶豫模糊語言的關系,本文提出概率語言熵及交叉熵的相關定義。
定義2令S={sα|α=-τ,…,-1,0,1,…,τ}為語言評價量表,L(p)為概率語言術語集,其中L(k)(p(k))是一個具有概率信息為p(k)的語言術語L(k),#L(p)是L(p)中語言術語的數量,且#L(p)=K,則L(p)的熵需要滿足以下條件:
1)0 ≤E(L(p)) ≤1;
2)當g(L(p))=0 或g(L(p))=1 時,若 有p(k)=1,E(L(p))=0;
3)當 且 僅 當#L(p)=2,p(1)=p(2)=12 且g(L(1))+g(L(2))=1時,E(L(p))=1。
基于猶豫模糊語言熵及概率語言等價變換函數,定義概率語言熵:
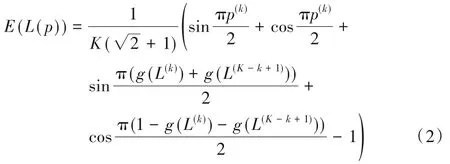
證明
1)首先對式子中的以下部分進行證明

設 π(g(L(k))+g(L(K-k+1)))=a,a ∈[0,2π],令 f(a)=所以可得-1 ≤f(a) ≤1。因此可將式(2)表示為:

即:0 ≤E(L(p)) ≤1。 證畢。
2)當g(L(p))=0,p(k)=1時,
E(L(p))=
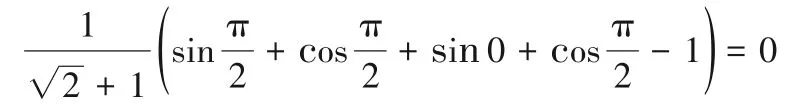
g(L(p))=1,p(k)=1時,
E(L(p))=
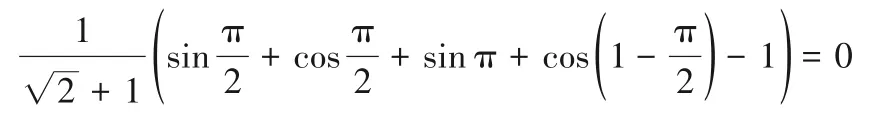
即當g(L(p))=0 或g(L(p))=1 時,若存在:p(k)=1,E(L(p))=0。 證畢。
定義3令S={sα|α=-τ,…,-1,0,1,…,τ}為一個語言術語集,L(p1)與L(p2)為兩個概率語言術語集,其中#L(p1)和#L(p2)是這兩個概率語言術語集的個數,并且#L(p1)=#L(p2)=K。那么L(p1)與L(p2)之間的交叉熵本文表示為CE(L(p1),L(p2))需要滿足以下條件:
1)CE(L(p1),L(p2)) ≥0;
2)當且僅當g(L(p1)(k))=g(L(p2)(k)),k=1,2,…,K 時,CE(L(p1),L(p2))=0。
基于猶豫模糊語言交叉熵及概率語言等價變換函數,定義概率語言交叉熵:
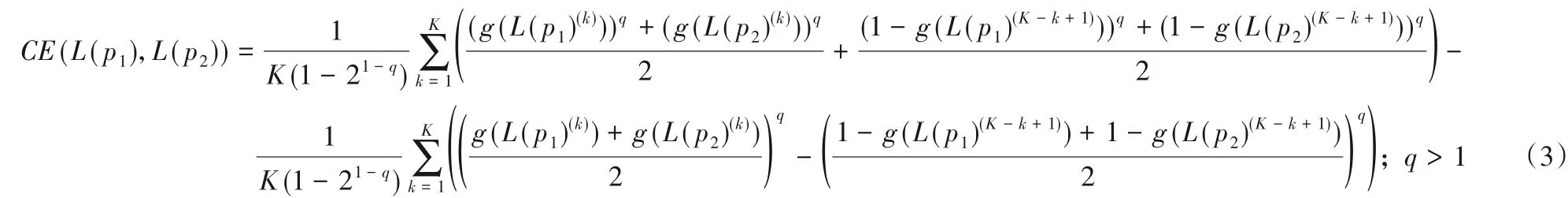
證明 令g(L(p1)(k))=x,g(L(p2)(k))=y,那么原式可表示如下:
CE(L(p1),L(p2))=
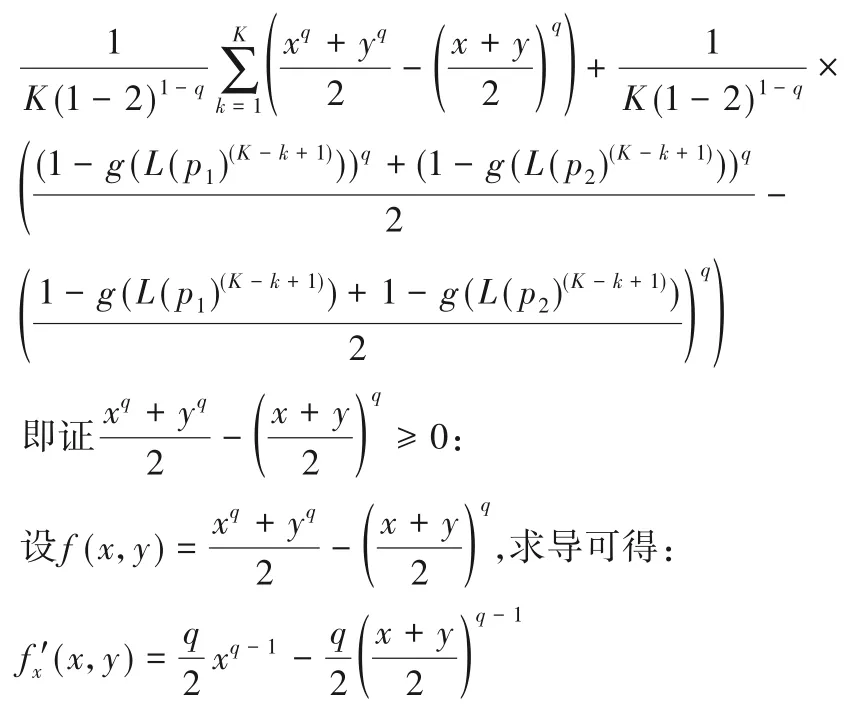
又x ∈[0,1],y ∈[0,1],所以f(x,y)在x ∈(0,y)上遞減,在x ∈(y,1)上遞增,y同理。故f(x,y) ≥f(x,x)=0,當且僅當x=y 成 立,即 g(L(p1)(k))=g(L(p2)(k)),k=1,2,…,K 時CE(L(p1),L(p2))=0成立。 證畢。
1.2 群體滿意度指數
針對后悔理論的效用函數,文獻[13]在屬性值為猶豫模糊元的多屬性決策中提出一種群體滿意度指數。本文將其拓展到屬性值為概率語言術語集的多屬性決策中。
定義4S={sα|α=-τ,…,-1,0,1,…,τ}為一個語言術集,L(p)為概率語言術語集,則稱
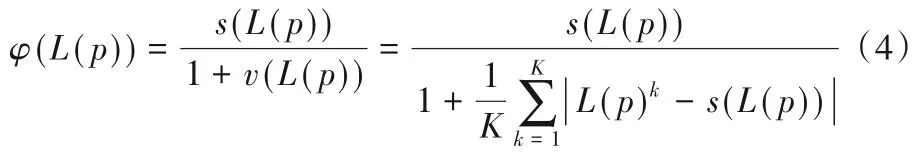
為概率語言術語的決策群體滿意度指數。其中:s(L(p))表示概率語言術語集的得分函數,按照文獻[2]中提出的得分函數公式進行計算;v(L(p))表示概率語言術語集L(p)的平均偏差函數,用來反映決策群體的分歧程度。
2 決策模型的構建
本章將在所提出的概率語言術語集的信息熵及交叉熵公式的基礎上構建概率語言指標權重確定模型,該模型將用于計算所給出各決策指標的權重值,在此基礎上,基于后悔理論的概率語言EDAS 排序模型也將在本章提出,該模型將后悔理論與EDAS 法結合,用于處理屬性值為概率語言的應急決策問題。
2.1 問題的描述
假設某城市在同一時間爆發了多個網絡輿情突發事件X={X1,X2,…,Xm},因該城市應急資源有限,因此需優先處理綜合危害性最高的突發事件,再依序處理剩余突發事件。假設應急部門選擇了n 個評價指標c={c1,c2,…,cn},且各評價指標的權重W=(w1,w2,…,wn)T未知,wj≥0(j=1,2,…,為了讓評價結果的科學性更高,挑選有專業差異的專家組成決策組d={d1,d2,…,dl}。各決策專家為各突發事件的評價指標賦予語言評價值,最后綜合各決策專家的評價矩陣,得到概率語言決策矩陣R=[Lij(p)]m×n表示如下:
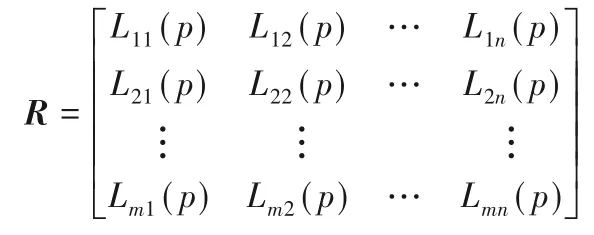
其中的概率語言評價值表示為:

2.2 評價指標權重確定模型
信息熵描述的是信息的不確定程度,若某一評價指標所獲得的熵值越小,則該評價指標所包含的信息越多,那么該指標在全局指標中也越重要,應賦予更大的權重值;若某一項決策指標上的交叉熵越大,則表示在該項指標上各備選方案的評價差異越大,那么該指標的重要性也越大,也應賦予更大的權重值。因此本文將采用各評價指標的評價值計算其信息熵及交叉熵,更加科學地計算出各評價指標的重要性程度,盡量避免人為賦權所帶來的影響,讓各評價指標最終所被賦予的權重更加合理且更加符合客觀實際。本文將運用概率語言信息熵及交叉熵建立相應的指標權重模型,具體計算步驟如下:
1)利用式(2),計算評價指標cj的總體信息熵:
2)利用式(3),計算評價指標cj的平均交叉熵:則可得評價指標cj的總體交叉熵:
3)基于概率語言信息熵及交叉熵理論可知,評價指標cj平均概率語言交叉熵越大,該指標應賦予較大的權重值;若評價指標cj的概率語言總體信息熵越小,則該指標也應被賦予更大的權重值,可以得到如下評價指標權重優化模型:
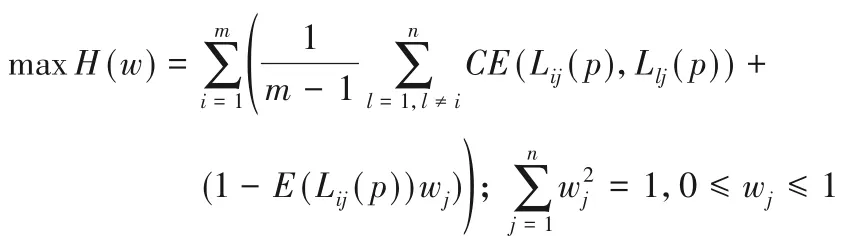
4)求評價指標權重優化模型,并進行歸一化處理,可以得到各決策指標的標準權重如下:
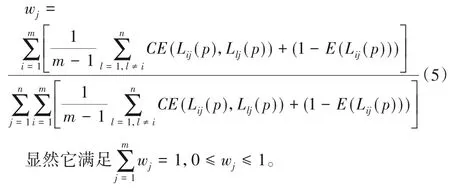
2.3 基于后悔理論的概率語言EDAS決策模型
經典的決策方法如TOPSIS、VIKOR 等,這些方法的邏輯功能是將最優解與負解的最大距離及將最優解與正理想解的最小距離作為最優解的基礎。然而,EDAS方法的最佳選擇是與平均解的距離相對應的,在EDAS 方法中,前兩個度量值分別作為與平均值的正距離和負距離的傳遞,這些度量可以顯示每個備選方案與平均解決方案之間的差異。相對于大多數其他多屬性決策方法,EDAS法在不同權值下具有較好的穩定性,簡單和較低的計算過程是也讓其更適于應急決策問題的處理。此外,在應急決策這類不確定問題中,決策者的非理性行為因素應予以著重考慮,這不僅符合應急決策的實際情況,也可以得到更加合理、科學的決策結果。因此本節將考慮決策者后悔規避的心理行為,確定概率語言信息的效用值及欣喜和后悔值,讓決策過程及結果更符合現實,然后結合EDAS法提出更適于應急決策問題的基于后悔理論的概率語言EDAS決策模型。具體步驟如下:
1)讓各專家賦予各備選方案的各屬性語言評價值,并獲得概率語言決策矩陣R=[Lij(p)]m×n:
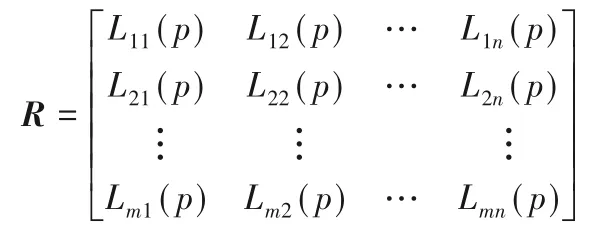
2)將概率語言決策矩陣進行標準化,根據文獻[2]所提出的概率語言標準化公式,得到標準化后的概率語言決策矩NR=[Lij(p)]m×n:
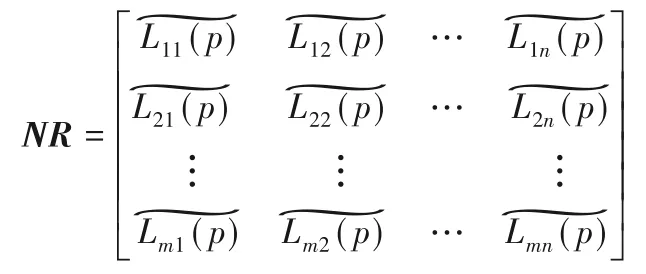
3)根據式(5),計算各評價指標的權重值:
W=(w1,w2,…,wn)T
4)根據文獻[22]提出的后悔理論的感知效用函數公式并結合式(4)計算各備選方案的后悔-欣喜值及感知效用值,并建立各方案感知效用值矩陣:
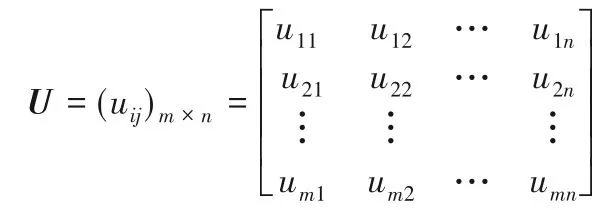
5)以感知效用值矩陣為計算目標,結合文獻[18]所給出的EDAS方法計算步驟進行計算:
①計算各屬性感知效用值的平均方案(AVerage solution,AV):
AV=[AVj]1×n
②計算各屬性感知效用值與平均值的正距離(Positive Distance from Average,PDA):
PDA=[PDAij]m×n
與平均值的負距離(Negative Distance from Average,NDA):
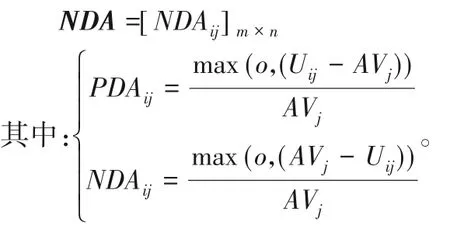
③計算加權后的PDA、NDA,可 得SPi(Weighted Summation of the Positive Distance)與SNi(Weighted Summation of the Negative Distance),其中:
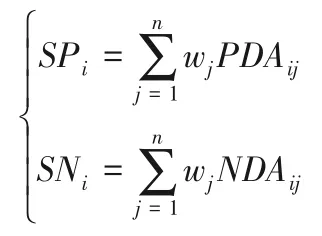
④標準化SPi與SNi,得到NSPi(Normalized Values of SPi)和NSNi(Normalized Values of SNi):
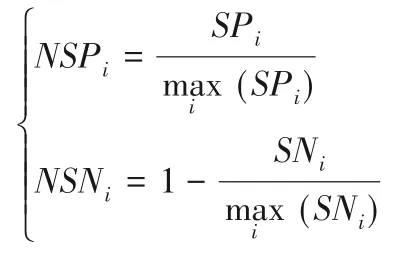
⑤得到各方案屬性下的感知效用值的最終評估得分ASi(Appraisal Score):
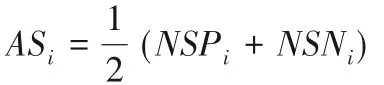
6)根據所得的各方案屬性的感知效用值的最終評估得分,對各備選方案進行排序,選擇出滿意的方案。
3 算例分析
3.1 問題的描述
城市A 的網絡輿情監測站點監測到可能爆發的3 個網絡輿情突發事件X={X1,X2,X3},因該地區應急資源有限,需優先處置綜合危害性最高的突發事件,再依序處理剩余事件。為評估各網絡輿情突發事件的綜合危害性,本文根據文獻[23-24]確定突發事件的廣度c1、易爆度c2、擴散速度c3、可能持續時間c4、次生災害發生作為評價指標c5,且評價指標的權重未知;選取5 位應急決策專家d={d1,d2,d3,d4,d5}組成應急決策委員會。
由于各決策專家受時間壓力以及對網絡輿情突發事件各信息掌握的不全面、不準確,往往難以及時地對各指標給出精確的評估值,因此允許決策專家為各突發事件的評價指標賦予語言評價值,決策者們利用S={s-3=極低,s-2=很低,s-1=低,s0=中,s1=高,s2=很高,s3=極高}來評估各網絡輿情突發事的評價指標,5 位決策專家評價各指標所得的原始矩陣如表1~5表示,其中“—”表示決策專家無法給出相應的信息,最終通過總結這五個表格可以得到概率語言決策矩陣R=[Lij(p)]m×n。

表1 決策專家d1給出的決策矩陣Tab.1 Decision matrix given by decision maker d1
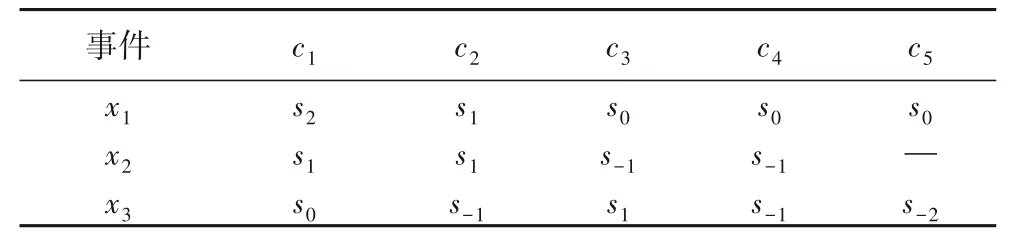
表2 決策專家d2給出的決策矩陣Tab.2 Decision matrix given by decision maker d2

表3 決策專家d3給出的決策矩陣Tab.3 Decision matrix given by decision maker d3

表4 決策專家d4給出的決策矩陣Tab.4 Decision matrix given by decision maker d4
3.2 方案的排序
1)讓各專家賦予各備選方案的各屬性語言評價值,并獲得概率語言決策矩陣R=[Lij(p)]m×n,如表6。
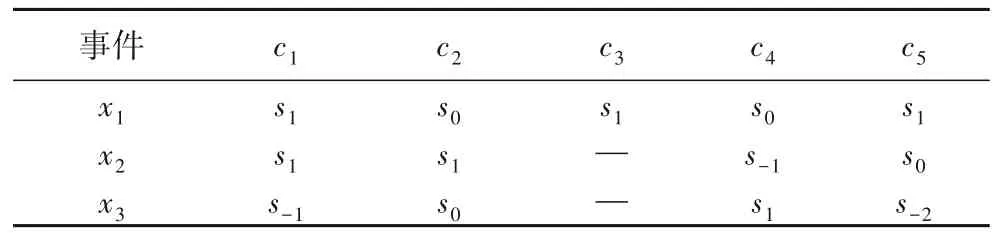
表5 決策專家d5給出的決策矩陣Tab.5 Decision matrix given by decision maker d5

表6 匯總后的概率語言決策矩陣Tab.6 Probabilistic linguistic decision matrix after summarization
2)將概率語言決策矩陣進行標準化,利用文獻[2],得到標準化后的概率語言決策矩陣NR=[Lij(p)]m×n,如表7。
3)根據式(5),計算各評價指標的權重值,得到評價指標的權重值:
W={0.128,0.246,0.327,0.145,0.154}
4)根據文獻[22]并結合式(4),計算各備選方案的后悔—欣喜值及感知效用值,如表8,并建立各方案感知效用值矩陣。
5)根據文獻[22],計算各方案的感知效用值,取α=0.3,計算結果如表9。
6)以感知效用值矩陣為計算目標,結合EDAS 方法計算步驟進行計算:
①計算各屬性感知效用值的平均方案值AV=[AVj]1×n,可得AV=[0.428 2,0.327 6,0.354,0.306 4,0.261 5];
②計算各屬性感知效用值與平均值的正負距離PDA=[PDAij]m×n、NDA=[NDAij]m×n:
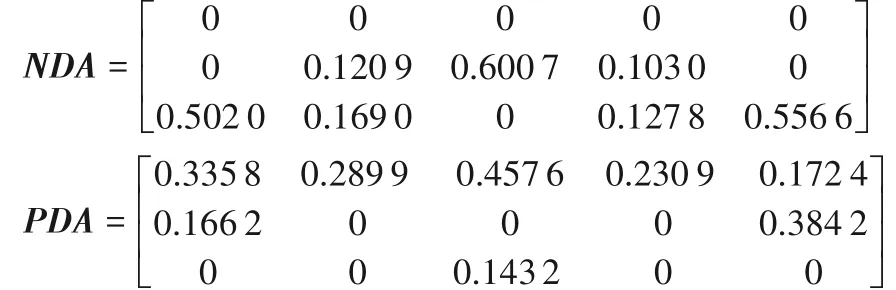
③計算加權后的PDA和NDA,分別得到SPi與SNi:
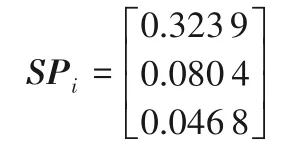

表7 標準化后的概率語言決策矩陣Tab.7 Probabilistity linguidtic decision matrix after standardization
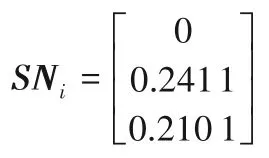
④將所獲得的SPi與SNi進行標準化,得到NSPi與NSNi:

⑤計算各方案屬性下的感知效用值的最終評估得分AS:
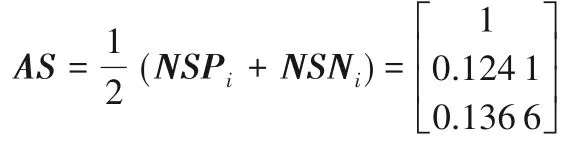
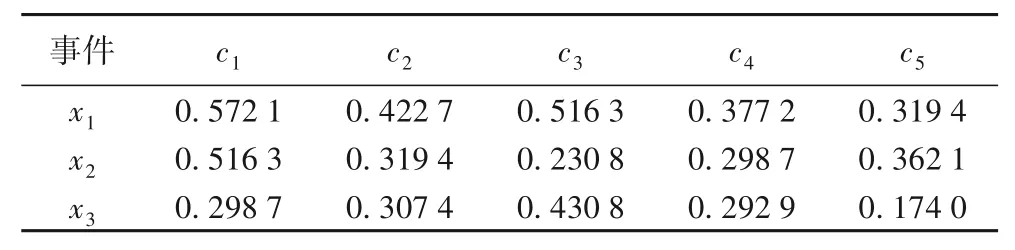
表8 各事件在不同評價屬性值下的效用值Tab.8 Utility values of different events under different evaluation attribute values
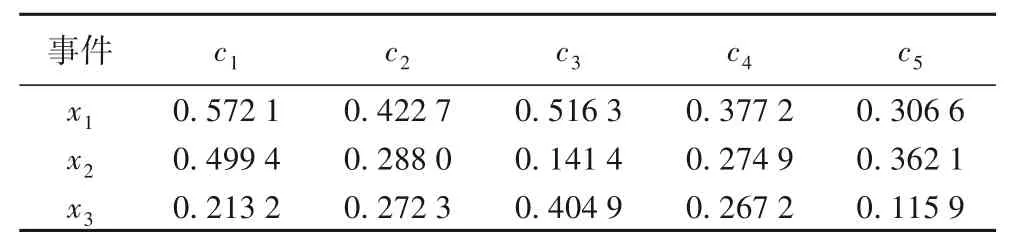
表9 各事件的感知效用值Tab.9 Perceived utility values of different events
7)根據最終的評估得分可以得到各網絡輿情突發事件的排序為:
x1?x3?x2
因此可得到優先處置的事件為網絡輿情突發事件1。
3.3 比較分析
本文將所提出的決策方法與其他文獻提出的決策方法進行比較分析,主要將其他文獻的決策方法分為兩類:一是未考慮決策者后悔規避的心理行為,使用文獻[2]方法對本文的實例進行分析;二是屬性權重的賦值方法,使用文獻[7,25]提出的權重賦值方法對本文的實例進行分析。
首先將本文所提出的決策方法與未考慮決策者后悔規避心理行為的決策方法進行比較。運用文獻[2]的決策方法對本文實例進行排序所得到的結果為x1?x3?x2,與本文所提方法的排序結果相同。文獻[2]所使用的決策方法雖然考慮了決策者對不同評價語言的不同偏好,但是卻在決策過程中假設決策者是完全理性的,這一假設會在一定程度上偏離決策的現實情況,進而導致決策結果有失合理性。
然后是根據不同的屬性權重確定方法進行對比分析。本文運用信息熵及交叉熵構建屬性權重計算模型計算得到的各屬性權重值為:
W=(0.128,0.246,0.327,0.145,0.154)
文獻[25]運用傳統熵權法計算各屬性的權重,計算得到的各屬性權重值為:
W=(0.221,0.187,0.294,0.195,0.103)
文獻[7]運用線性規劃法對各屬性進行權重的賦值,計算得到的各屬性權重值為:
W=(0.147,0.197,0.292,0.165,0.199)
那么使用文獻[25,7]獲得的屬性權重值以及本文使用信息熵及交叉熵得到的屬性權重值并分別使用EDAS 法和TOPSIS 法進行排序,使用這兩種方法進行排序分析是為了讓所得到的計算結果更具全面性,得到的最終排序結果如表10表示。

表10 使用不同權重計算方法的排序結果Tab.10 Sorting results by using different weighting methods
比較表10的三種不同賦權法產生的排序結果可知:
1)在三種賦權法下所得的最優先處置的事件都為網絡輿情突發事件1,證明了本文方法具有一定的合理性。
2)不同賦權方法所得到排序結果的不同在于事件2 和事件3 的排序。文獻[25]采用的是傳統的熵權法,運用信息熵建立屬性權重模型,造成排序結果與本文的排序結果有所差異,但最優先處置的事件都為事件1,這是因為該文獻使用的熵權法求各屬性權重時只使用各屬性的信息熵進行計算而未將交叉熵考慮在內,因此造成一定的信息損失,對最終的排序結果產生影響。本文考慮到某項指標的信息熵測度越小,該評價指標所包含的信息越多,那么該指標在全局指標中也越重要,應賦予更大的權重值;若某項指標上的交叉熵測度越大,則表示在該項指標上評價差異越大,對決策評估的作用越大,也應賦予更大的權重值。因此本文未像傳統的熵權法在求權重時只單純考慮指標值的信息熵,而是將決策指標值的信息熵及交叉熵測度同時納入權重確定模型中,不僅考慮了決策指標自身信息熵的大小對權重大小的影響,同時考慮了指標間的差異性程度信息即交叉信息熵,進而最大限度地減少原始信息的流失,使權重結果更具客觀性、合理性。
3)文獻[7]線性規劃法得到的網絡輿情突發事件的處置順序本文的排序結果完全一致,說明本研究提出的權重確定模型具有一定的合理性,但需要指出的是,本文所提出的權重確定模型能夠最大限度地保留原始信息特性,是具有一定優勢的。
4 結語
本文考慮到在信息不完備、時間緊急的情況下,決策者很難及時地對網絡輿情突發事件的各評價指標給出精確的評估值,提出一種基于概率語言的網絡輿情突發事件應急群決策法,使評估過程更加符合應急情況下的客觀實際,讓評估結果更具合理性;同時考慮多個決策專家的評價意見,進行群決策探討,使得決策過程及決策結果都不失科學性;通過概率語言信息熵及交叉熵構建指標權重確定模型,能減少信息的丟失,使權重結果更具準確性;在考慮決策者后悔規避這一心理行為下,結合EDAS 法提出一種計算更簡要高效、計算結果更符合現實情況的決策方法;此外本文所提出的決策方法還適用于如安全事故、自然災害應急預案等的應急評估,幫助決策者選擇最佳應急方案,具有一定的實用意義。最后本文所提出的決策方法僅適用于有限個決策者進行決策的決策問題,未來將對相同背景下的大型群體決策問題進行探討與分析。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
