基于師門關系的研究團隊挖掘算法
2020-11-30 05:47:36李莎莎梁冬陽譚郁松吳慶波
計算機應用 2020年11期
關鍵詞:研究
李莎莎,梁冬陽,余 杰,紀 斌,馬 俊,譚郁松,吳慶波
(國防科技大學計算機學院,長沙 410073)
(?通信作者電子郵箱jibin@nudt.edu.cn)
0 引言
科研院校是科學研究和技術開發的基地。研究團隊是院校中最基本的科研單元。同一個研究團隊,研究人員的研究內容一般是相同、相近或者互為補充的。現實世界中,挖掘出合作緊密的研究團隊對國家和軍隊的科技戰略規劃和人才評價體系建設都具有較大的意義。
具體而言,研究團隊是指由研究者組成的集合,這個集合內部研究者之間存在很強的關系,而這個集合的研究者與其他集合的研究者之間的關系則相對較少。現有的研究工作大多把研究團隊挖掘形式化為基于論文合作網絡的社區發現問題。社區發現算法大體上分為重疊社區發現算法和不相交的社區發現算法[1-2]。重疊社區發現算法允許發現的社區之間存在相同節點;而不相交社區發現算法則不允許這種節點存在。常見的重疊社區發現算法有:標記傳播算法[3]、主成分分析[4-5]等。不相交的社區發現算法有:魯汶算法[6]、GN(Girvan-Newman)算法[7]、基因算法[8]、基于模塊度的算法[9-11]等。利用上述社區發現算法,可以從學術論文中挖掘有緊密研究聯系的研究者社區,然而這種學術合作的社區往往基于研究興趣的聚合,研究團隊中的研究者在研究興趣點上的同質性較高,但組織連接較低,難以合作完成大規模的項目。相對的,大規模項目往往依賴于那些隸屬同一組織并且有不同研究興趣點,而興趣點之間又相互關聯的研究團隊。
針對上述問題,本文利用學位論文中隱藏的師門和同門關系,提出了一種基于師門關系的研究團隊發現算法,該算法在保證發現研究團隊合理性的同時,提升了魯汶算法的運行效率。該算法基于從學位論文致謝部分抽取出的教師和學生信息,構建師生之間的指導合作關系網絡。構建過程中,將魯汶算法中需要加入的老師節點的鄰居節點,改為加入同門其他學生的指導老師節點。實驗結果表明,該算法既保證了挖掘的研究團隊的質量,又較大地提高了算法的運行效率。
1 理論與算法
1.1 術語定義
目前,精準的社區定義是不存在的,現階段被廣泛接受和使用的定義是由Newman 在文獻[12]中提出來的:同一個社區內的節點之間的鏈接很緊密,而社區之間的鏈接比較稀疏。其數學描述為:假設G=G(V,E),社區發現就是指在圖G中確定nc(大于1)個社區,C={C1,C2,…,Cnc}使得各社區的頂點集合構成V的一個覆蓋。
師門在本文中指的是同一研究團隊指導老師的集合,同門指的是同一研究團隊學生的集合。
1.2 BiLSTM-CRF命名實體識別模型
BiLSTM-CRF[13]模型結合雙向長短時記憶神經網絡(Long Short-Term Memory,LSTM)與條件隨機場(Conditional Random Field,CRF)實現命名實體識別。如圖1所示,該模型自上向下分別是Embedding 層、雙向LSTM 層和CRF 層。Embedding 層是句子中字符的向量表示,通過預訓練語言模型獲得,字符向量作為雙向LSTM 層的輸入。雙向LSTM 層通過一個正向LSTM 和一個反向LSTM,分別計算每個字的上文與下文信息,然后將前向和后向LSTM 的隱狀態輸出進行拼接,形成字符的編碼表示;最后,CRF 層以雙向LSTM 獲取的字符編碼作為輸入,對句子中的字符進行序列標注進而獲取命名實體。
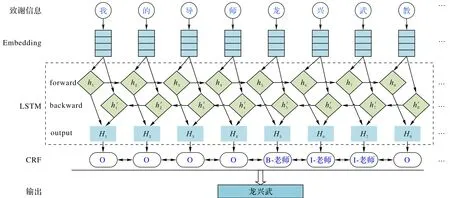
圖1 BiLSTM-CRF模型Fig.1 BiLSTM-CRF model
1.3 基于模塊度的魯汶算法

模塊度是Newman[12]提出來用于描述社區劃分質量的一個度量,并在實際應用中驗證了它的有效性。它的計算方法如式(1)所示:其中:m 為圖中邊的總數量;ki表示所有指向節點i 的權重之和,kj同理;表示節點i,j之間的權重,沒有設置權重則默認為1;Ci為節點i所在的社區編號,函數δ(Ci,Cj)中,當節點i和j處于同一個社區時取1,否則取0。
在基于模塊度的社區發現算法中,最直接的方法就是列舉出所有的社區劃分情況,然后計算每一種情況的模塊度來選取最好的社區劃分。但是當數據規模較大時,這種方式所需要的計算量太大,因此需要優化模塊度的計算來降低計算量。基于模塊度的社區發現算法的主要優化策略有:基于貪心策略、基于層次聚類和融合多策略的方法等。魯汶算法就是一種融合多策略的社區發現算法。Fortunato等[14]認為魯汶算法是當前最好的模塊度優化算法,而且很多大型的復雜網絡劃分軟件都使用了魯汶算法。
魯汶算法的計算過程是首先將所有的節點當成一個獨立的社區,然后針對每個節點遍歷它的所有鄰居節點,計算加入每個鄰居節點后的模塊度收益,選擇收益最大的鄰居節點加入該節點,重復這一計算過程,直到社區趨于穩定。
2 本文算法
本章將從學位論文致謝部分師門信息的抽取形式化為命名實體識別任務,使用BiLSTM-CRF 模型抽取師門和同門命名實體,構建師生之間的指導合作關系網絡,并基于師門關系改進魯汶算法,提高算法運行效率。
2.1 師門信息抽取
在學位論文中,封面上的老師信息大多只包含導師和一個協作導師,但是大部分學生都是由隸屬于一個研究團隊的多個導師一起指導出來的,學位論文的致謝部分比較完整地包含了這種師生信息。學位論文作者在致謝部分對學習期間的指導老師、同學表達感謝,本文需要抽取的是師門和同門信息,這些信息一般都會有較為明顯的標簽,如圖2 所示。其中淺黃色標簽表示標注的老師信息,深紅色標簽表示標注的學生的信息。雖然標簽特征比較明顯,但因為致謝書寫不規范,使得基于規則的方法難以準確地抽取師生信息。本文使用BiLSTM-CRF模型抽取師生信息。

圖2 人工標注師門關系Fig.2 Manual labeling of teacher-student relationship
本文使用500 份人工標注的訓練數據進行模型訓練,100份人工標注的測試數據驗證模型的性能,實驗結果如表1 所示。從表中可以看出師門和同門信息抽取性能雖然不是很理想,但基本可以滿足后續研究要求。

表1 師門和同門關系抽取實驗結果 單位:%Tab.1 Results of teacher relationship and classmate relationship extraction unit:%
2.2 師生指導合作關系網絡挖掘
本文通過規則抽取了封面上的導師信息,使用BiLSTMCRF模型抽取了致謝部分的師門和同門信息。師門中的指導老師和封面導師同時指導同一個學生,他們之間有著指導學生的合作關系。本文把每一個學生的指導老師和封面導師之間都用邊互相鏈接,構建師生之間指導合作關系網絡。在該網絡中部分老師有著相同的名字,本文假設各個學院之間沒有交叉合作的研究團隊以及同一個學院中相同姓名的老師是同一個人,本文依據上述假設執行重復人名去重操作。
2.3 基于師門關系的魯汶算法
由上文可知,魯汶算法是一種性能優異社區發現算法,但是仍有較大的改進空間。例如de Meo 等[15]通過改善魯汶算法的結束條件,大幅提高了算法的運行速度。
魯汶算法的計算是遍歷節點的所有鄰居節點,選擇最大的模塊度收益,加入該節點所在社區。而在獲取到師門和同門關系之后,不需要再遍歷所有的鄰居節點,可以通過老師節點得到所指導學生的同門學生,通過遍歷同門學生指導老師節點即可。本文假設在院校中同一個研究團隊的老師,會一起合作共同指導學生或者同門的其他學生,因此若老師沒有共同指導的學生本文則假設兩個老師不屬于同一個研究團隊。基于上述假設,本文改進魯汶算法,改進后的魯汶算法犧牲了一部分精度,但是運行效率得到了較大的提升,同時挖掘出的研究團隊也更加合理,其算法偽代碼如下所示。
算法1 基于師門關系的魯汶算法。

3 實驗分析
由于基于師門關系的魯汶算法是針對特定場景對魯汶算法的改進,本文通過兩組實驗對算法的性能和運行效率進行驗證:實驗1 通過將魯汶算法和標簽傳播算法、聚集系數算法在公開的真實網絡數據集進行性能對比實驗,驗證魯汶算法的性能;實驗2 通過比較原始魯汶算法和基于師門關系的魯汶算法在不同規模的學位論文數據集上的性能和運行效率,證明了基于師門關系的魯汶算法具有較好的性能和運行效率。
3.1 實驗環境
本文實驗環境如下所示:硬件環境為Inter Core i7-5930K CPU,64 GB 內存,2 塊GeForce GTX TITAN X 圖形顯卡。操作系統為Ubuntu Kylin 16.04。編程語言為Python 2.7.12。
3.2 公開數據集
實驗1在American College football、Zachary karate club[16]、Dolphin social network[17]三個真實網絡數據集上進行,它們分別是美國大學生足球聯賽、美國大學空手道俱樂部和海豚社會關系數據集,其數據規模如表2所示。
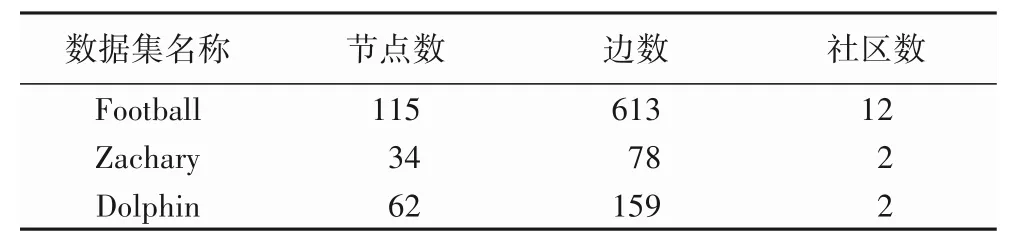
表2 真實網絡數據集規模Tab.2 Real network dataset scales
3.3 評價指標
社區發現的質量需要評價指標來衡量,下面主要介紹標準化互信息(Normalized Mutual Information,NMI)和蘭德指數(Adjusted Rand Index,ARI)兩種評價指標。
NMI 是用來比較兩個社區劃分結果的相似程度,可以用來比較社區發現算法的社區劃分結果與真實社區的相似程度,以此來判斷社區發現算法的有效性。其計算方法如式(2)所示,其中:N 表示節點的數量;Ca(Cb)表示在A(B)劃分中總的社區數量;Ci(C·j)表示在矩陣C 中第i 行(第j 列)所有元素的求和;Cij表示在A 的劃分中屬于i 社區,而在B 劃分中屬于j社區的節點數量。NMI 的值域是0 到1,越高代表劃分得越準。
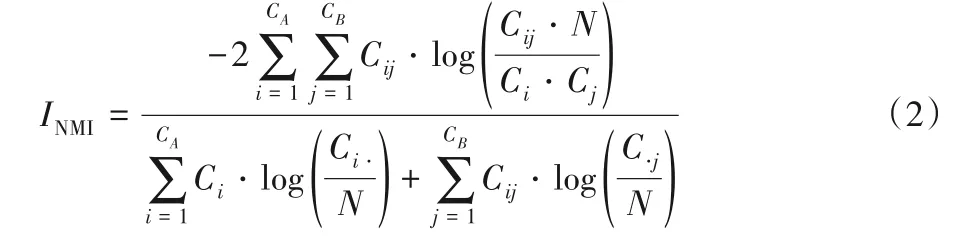
ARI 是用來衡量社區劃分結果的另一個重要指標,該指標不考慮使用的聚類方法,把方法當作一個黑盒,只注重結果。計算公式如式(3)所示,其中a11、a00、a10、a01表示節點對的數量。假設A 和B 是兩個節點,則a11中的第一個數字1 表示A、B 兩個節點在真實的社區劃分中屬于同一個社區,反之則第一個數字為0;a11中的第二個數字1表示A、B兩個節點在社區發現算法中劃分在同一個社區,反之則第二個數字為0。所以a11、a00、a10、a01代表滿足上述條件的節點對的數量。
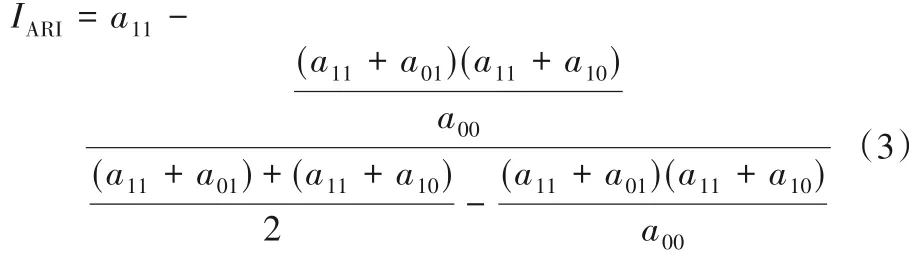
3.4 實驗分析
為驗證原始魯汶算法在社區發現中的性能,執行實驗1。實驗結果如表3所示。
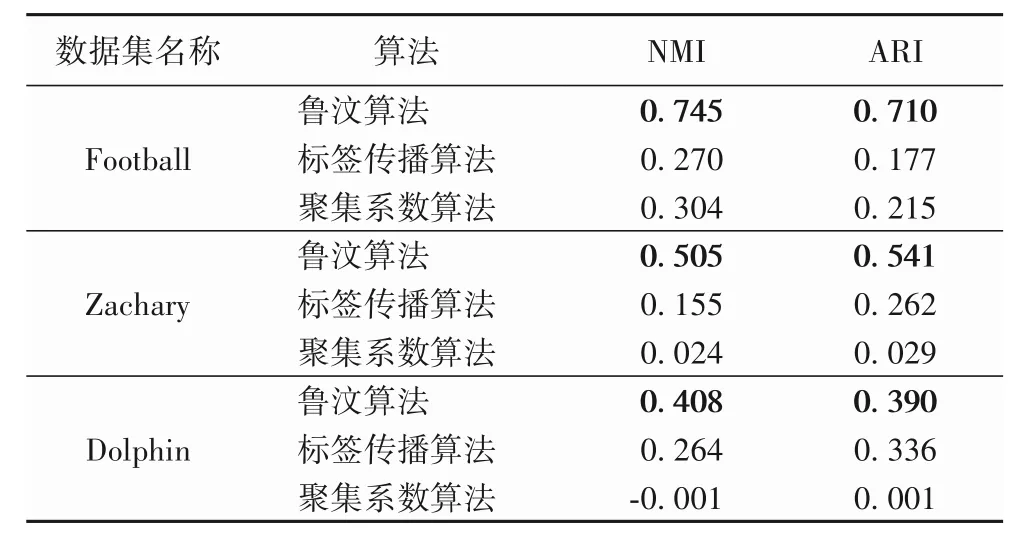
表3 社區發現算法性能對比實驗Tab.3 Community detection algorithm performance comparison experiment
從表3 中可以得知,在三個數據集上,原始魯汶算法性能均為最優,無論是只有2 個社區的Zachary 數據集和Dolphin數據集,還是有12 個社區的Football 數據集,都得到了最佳的結果,這也證明了原始魯汶算法的魯棒性和容錯性比較強。
為了驗證改進后的基于師門關系的魯汶算法在社區發現中的運行效率,本文使用國防科技大學計算機學院學位論文、國防科技大學學位論文和軍內院校學位論文三個不同規模的數據集對比原始魯汶算法和基于師門關系的魯汶算法的運行效率(實驗2),實驗結果如表4 所示,從表中可以看出數據規模越大,改進后的魯汶算法的效率提升得越明顯。
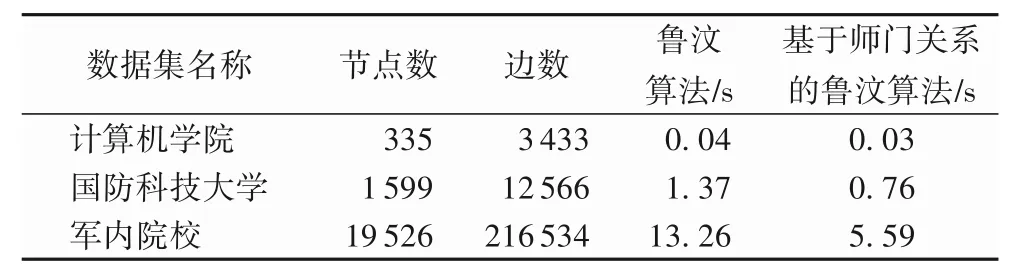
表4 社區發現算法效率對比實驗Tab.4 Community detection algorithm efficiency comparison experiment
本文以國防科技大學學位論文數據集為例,以原始魯汶算法為參照標準,驗證基于師門關系的魯汶算法在學位論文數據集上挖掘研究團隊的性能,最終得到國防科技大學的研究團隊信息如圖3所示。
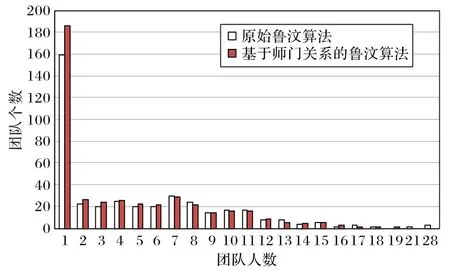
圖3 國防科技大學研究團隊信息Fig.3 Research teams in National University of Defense Technology
由圖3 可知,使用原始魯汶算法挖掘國防科技大學研究團隊總數為409,而基于師門關系的魯汶算法挖掘得到的總數為441。基于師門關系的魯汶算法挖掘出的研究團隊人數均在20以下,而原始魯汶算法得到的結果中有多個超過20人的研究團隊,從團隊規模的角度評估,基于師門關系的魯汶算法更為合理。在團隊人數的整體分布中,兩個算法基本上呈現大致相同。總的來說,基于師門關系的魯汶算法劃分的研究團隊更為細致合理,合作關系更為緊密,而且劃分出的研究團隊整體分布與原始魯汶算法挖掘的研究團隊類似,也可以說明基于師門關系的魯汶算法的性能與魯汶算法類似。
目前,科研團隊的挖掘大部分都是基于論文合作網絡進行挖掘,這種挖掘方式有以下幾個不足:一是跨學科、跨領域、跨學校的論文合作越來越多,合作作者的研究方向千差萬別,甚至完全不相關的研究方向也可能是合作作者;二是在合作作者中要分辨出老師和學生也具有一定的難度,學生對于一個研究團隊來說,流動性太大,畢業后就不再屬于研究團隊成員,導致研究團隊不夠穩定;三是部分論文存在合作作者可能并沒有實際參與論文工作的情況。這些對于挖掘緊密合作的研究團隊都會產生一定的影響。
而基于師門關系挖掘研究團隊相對來說更容易得到合作緊密的研究團隊。首先,同一個師門的老師需要共同完成科研任務,所以老師的研究方向基本上是一致或者相關的,此外也更容易對老師和學生進行區分。對于基于論文合作網絡與基于師門關系的研究團隊挖掘方法對比如表5 所示,主要從合作緊密程度、團隊規模、團隊內部聯系和團隊穩定性4 個方面進行了對比。從表中可以看出,基于師門關系的研究團隊挖掘算法在上述四個方面性能更為優異。
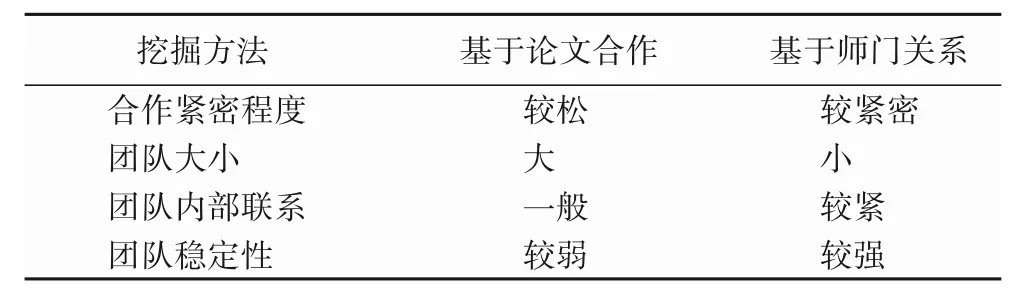
表5 研究團隊挖掘方法對比Tab.5 Research team mining method comparison
4 結語
研究團隊的精確挖掘對國家和軍隊的科技戰略規劃和人才評價體系建設都具有較大的意義。本文針對現有研究團隊挖掘算法存在的問題,基于學位論文相關內容,提出了一種基于師門關系的研究團隊挖掘算法。實驗表明,相較于其他算法,該算法在運行效率、研究團隊挖掘質量等方面有較明顯提升。
本文提出的算法在實際應用中有一定的局限性,即無法進行深入信息挖掘進而發現研究團隊的核心。將來的工作從研究團隊實力分析入手,通過分析研究團隊的實力來反映當前整個研究領域的現狀,增強對研究領域的把握,幫助科研工作者更好地研究創新。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
遼金歷史與考古(2019年0期)2020-01-06 07:45:20
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年11期)2018-08-04 03:26:04
汽車工程學報(2017年2期)2017-07-05 08:13:02
國際商務財會(2017年8期)2017-06-21 06:14:14
電子制作(2017年23期)2017-02-02 07:17:19
