人工智能音樂發展現狀與面臨的挑戰
2020-12-02 01:15:40劉奡智韓寶強
人民音樂 2020年9期
■劉奡智 韓寶強
20 19 年由中國平安人工智能研究院推出的由AI 創作的《我和我的祖國交響變奏曲》在深圳音樂廳首演。作品通過自動變奏模型,對歌曲《我和我的祖國》的旋律進行變奏,并在變奏的同時融入其他經典歌曲的元素。全曲總共分為五個段落,通過對《我和我的祖國》歌曲主題的變奏,表現了新中國發展歷程的宏大畫卷。這部作品由深圳交響樂團演出,樂團音樂總監林大葉對音樂品質表示了肯定,并提出了未來5—10 年AI能創作傳世作品的期許,這次的演出也引起了社會各界對人工智能音樂的注意。實際上人工智能音樂并非一個全新的領域,該領域已有若干年的發展歷史,而在近些年人工智能音樂則掀起了一波熱潮,受到了前所未有的關注。
“人工智能”(Artificial Intelligence)通常界定為“機器展示的智能”,“人工智能音樂”(AI Music)則特指由計算機神經網絡等算法生成的音樂。雖然當前人工智能技術仍處于初級階段,距成熟還有較長的路要走。但其在某些領域達到的智慧水平已讓人刮目相看,眾所周知的例證便是谷歌公司的阿爾法狗(AlphaGo)完勝世界著名圍棋大師。
作為音樂人自然會問這個問題:人工智能會不會擊敗人類作曲大師?根據現實已有的答案是:還不能。因為音樂屬于藝術范疇,不像圍棋這種競技項目有客觀的勝負標準,音樂取勝的標準由人類審美習慣來判定,雖然機器可在1 分鐘內生成上千首樂曲,但很可能被聽賞者一句“不好聽”而拋棄。目前國際上較為成功的人工智能技術也只能模仿一些規律性較強的音樂風格,如巴赫、披頭士等,且未達到逼真程度,更遑論超越音樂大師的創作。那么這種情況是否就意味著神經網絡永遠產生不出大師之作,注定要與平庸為伍呢?本文旨在通過觀察前期人工智能音樂演化歷程和當前應用發展趨勢,來探討人工智能音樂未來發展的前景與挑戰。
一、人工智能在音樂生成上的演化歷程
1.基于馬爾科夫模型的音樂自動生成
馬爾科夫模型是以俄羅斯數學家馬爾科夫命名的一種模型方案。通常來說馬爾科夫模型用來解決眾多序列問題,比如天氣的預測、股票的預測等等。音樂的創作,也可以被看作是一個序列問題,這也是馬爾科夫模型廣泛用于音樂生成的重要原因。馬爾科夫模型時至今日仍是用于音樂生成的有力工具,而這個模型早在1950 年就已經被美國聲學工程的大師哈里·費迪南德·奧爾森(Harry F.Olson)用于音樂結構的生成。
2.基于規則:語法系統
語法系統起源于語言生成系統。早在1957 年,語言學家諾姆·喬姆斯基(Noam Chomsky)便提出了最為基礎的語言模型。里多夫(Lidov)和加布勒(Gabura)是較早采用語法系統生成音樂的研究者,他們在1973 年,通過語法系統生成了簡單的節奏,取得了基礎性的突破。一般來說,語法系統包含了起始符號、終止符號、非終止符號及生成過程的一系列規則。這種基于語法系統的生成方案,在音樂生成的研究上非常流行,因為音樂也有音樂的語法,如和聲、復調、曲式、配器的作曲理論規則。而研究這種生成方法的也往往是具備強音樂背景的音樂與計算機復合型人才。
3.基于遺傳算法的音樂自動生成
所謂物競天擇,適者生存。遺傳算法是一種類似于達爾文進化論的機器學習算法,屬于機器學習五大流派中的進化學派。遺傳算法中的適應性函數,用于評價大量生成的“種群”當中適合存活的對象,對種群中的個體進行優勝略汰。霍納·安德魯(Horner Andrew)以及大衛·戈德堡(David Goldberg)是較早研究遺傳算法與音樂生成的研究員。他們通過自己定義的適應性函數,來不斷優化生成的旋律。適應性函數的設計方法很多,其中也有不少的研究引入作曲理論規則,如四部和聲理論、對位規則等,進行適應性篩選,盡可能讓能“存活”的音樂片段符合規則,增加可聽性。由于遺傳算法可以通過引入作曲規則提高音樂的悅耳程度,至今仍有少數研究機構致力于遺傳算法進行音樂生成的研究。
(四)基于深度生成式模型的音樂自動生成
1.循環神經網絡
循環神經網絡是深度神經網絡模型的一種,常用于解決序列問題,比如機器翻譯、文本生成、語音識別。由于基礎的循環神經網絡中,反向傳播過程有梯度消失的問題,現代一般采用改進的循環神經網絡模型:長短記憶網絡(LSTM)。這種神經網絡的輸入可以是一個序列,輸出也可以是一個序列。對于音樂生成的任務而言,用戶輸入若干個音符作為動機,一個訓練好的循環神經網絡模型會自動幫助機器進行續創,較早的例子有道格拉斯·艾爾克(Douglas Eck)通過LSTM模型進行的藍調音樂生成研究。

圖1 循環神經網絡
2.Transformer
Transformer 是谷歌大腦在2017 年提出的一種序列模型,該模型最早應用于機器翻譯。這個模型的出現也撼動了循環神經網絡在深度學習中的地位。甚至在很多的研究測試中,Transformer 的表現均優于循環神經網絡。2018 年谷歌大腦亦把Transformer 模型應用于音樂生成的問題,發表了music transformer 的論文,曾名噪一時。

圖2 Transformer 模型機制
3.變分自編碼器(VAE)
自編碼器(AE),即通過一個神經網絡,將一張圖片或者一段語音變成一串數字,目的是增加圖片或語音的可搜索性,并且通過該數字重建圖片或者語音。變分自編碼器(VAE)是自編碼器的一種,是自編碼器的升級版本,結構與自編碼器類似,亦由編碼器和解碼器構成。與單純的自編碼器相比,變分自編碼器強制編碼得到的隱含向量需要遵循一個標準正態分布。早期將VAE 模型用于音樂生成的,則是谷歌的MusicVAE 模型,用戶輸入兩段音樂片段,模型為用戶進行插值,生成連續的過渡性片段。
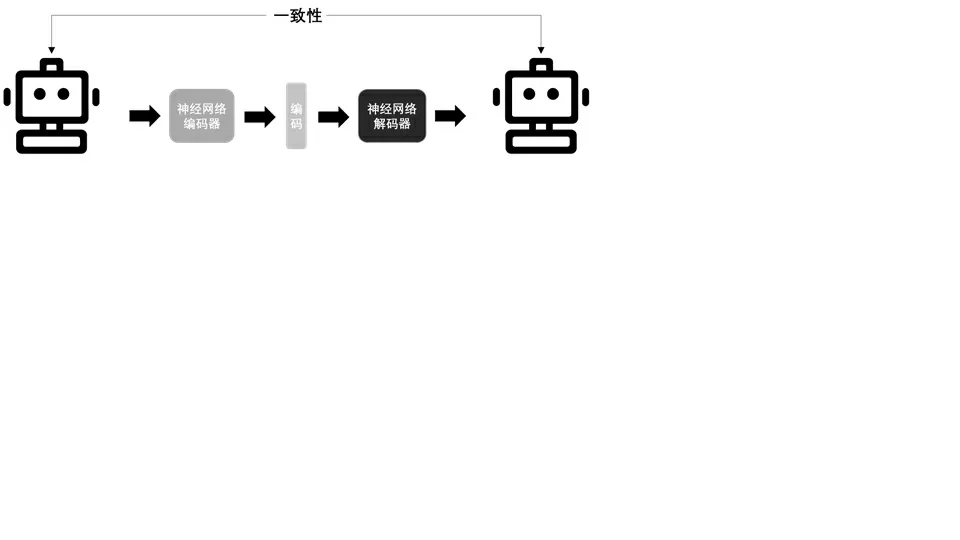
圖 3 自編碼器(AE)
d.生成對抗網絡(GAN)
生成對抗網絡,顧名思義,該模型包含生成器以及判別器兩個部分。生成器與判別器的關系,則好比印假鈔團伙與警察的關系。生成器與判別器互相博弈,兩者不斷升級,
經過了多輪博弈,訓練出的生成器則可以假亂真。近些年生成對抗網絡成為了計算機視覺生成領域的主流模型。在音樂生成領域,MIDI-Net 是最早用GAN 來生成音樂的模型,該模型最核心的一個思想即把鋼琴窗的矩陣類比成圖片,如此一來在一定的時間內,多聲部的音樂便可表示為一張圖。如此,在計算機視覺領域流行的生成對抗網絡,便可用于音樂的生成。

圖4 生成對抗網絡機制
二、人工智能音樂的應用現狀
人工智能音樂是近些年的一大噱頭,許多初創公司也在這一波風口浪尖上,持續地拿到了融資。自2014 年Jukedeck在巴黎的Le Web 會議高調亮相以后,人工智能音樂領域掀起了一波融資浪潮,在國際上較為高調的尤數Amper Music①、Jukedeck②以及AIVA③。Amper Music 是一家由三位好萊塢制作人創立的,聲稱以人工智能提供音樂內容服務的公司。Amper的交互十分簡單,用戶只需要選擇一種風格、一種情緒以及對應時長,就可以得到一首樂曲,這種交互簡明、低門檻、容易操作。Jukedeck 的產品邏輯與Amper 類似,以為客戶定制音樂作為商業模式進行探索。2019 年7 月,Jukedeck 被Tiktok 收購。Jukedeck 的音樂生成內容庫也成為了Tiktok 這個大流量短視頻平臺的助推器。
相較之下,AVIA 系統則更注重通過高品質作品來博取眼球并吸引投資。一方面,AVIA 推出由人工智能生成的樂隊作品,并交由樂團來演奏。另一方面,AVIA 也出版了多張專輯,并表示專輯中的音樂都是人工智能生成的。最近,AVIA 在對外網站中上線了輔助音樂人創作的工具,欲另辟蹊徑避免與Amper 及Jukedeck 的業務高度一致。
除了這三家較為高調的公司以外,諸如Popgun、Amadues Code、Melodrive、Ecrett Music 等,都是這個領域的初創玩家,均聚焦于音樂生成或音樂生成的一些子任務,如自動配和聲、節奏生成等等。然而眾多的初創企業中,尚未有任何一家能體現出顯著的技術優勢。因而人工智能音樂行業也一直被認為處于起步階段,這與行業的產品化現狀不無關系。
三、人工智能音樂面臨的困難與挑戰
人工智能音樂生成,本質上就是一個極具挑戰性的任務。培養一個作曲家尚需要漫長的時間,培養一個人工智能又談何容易。在人工智能音樂生成的研究當中,有諸多技術上的挑戰,其中有一些挑戰,似乎也決定了人工智能難以超越人類的宿命。
(一)人工智能音樂生成的評價體系問題
音樂為什么好聽?事實上人類大腦對音樂的感知機制,至今仍未有高度定量化的結論。換句話說,我們不是不懂音樂,而是不懂我們自己。再則,對音樂的喜好,不僅僅是“好聽”與“不好聽”的問題。音樂的審美往往受諸多因素影響,例如人的個性、音樂學習經歷以及文化背景等等,是個體生活經歷的衍生品。如果希望人工智能真正能創作音樂,那首先需要教會人工智能審美,而教會人工智能審美本身就已經是一個極限挑戰。
(二)人工智能音樂生成技術構思的現存問題
1.結構缺失問題
人工智能音樂的生成模型有很多,然而大多數在設計階段就沒有考慮到生成的音樂是需要具備一定結構的。這種問題的出現,一方面是通用人工智能領域并沒有十分合適的工具,能讓音樂的結構被學進去。另一方面,許多人工智能音樂生成的研究者,本身音樂背景略為單薄,對曲式結構的理解十分有限。人類在訓練人工智能過程不重視結構,就好比在作曲的教學當中,略去了曲式分析的課程,讓學生在這方面能力有所缺失,大大減弱了學生創作完整作品的能力。
2.深度學習的過擬合問題
深度學習極其容易有過擬合問題。如果深度學習模型過擬合到特定數據集上,則會出現了單純記憶的情況,即在生成的過程中形成大塊片段的抄襲。這是諸多深度學習模型都具有的通病,其中尤以序列模型為嚴重。一般認為,人工智能音樂生成是為了解決版權制約的問題,但技術所面臨的挑戰卻暴露了另外一個現實,基于深度學習模型生成的音樂可能是在抄。這個問題如果不能妥善解決,那用深度學習去做人工智能音樂生成,可能已經違背了人工智能生成的初衷,并且引發了新的侵權風險。
3.統計模型的理念問題
機器學習模型中,有相當一部分本質上是統計模型。統計模型是不是適合藝術創作呢?藝術創作是具備一定頂端優勢的,有了一個梵高,也許不需要第二個。但我們用統計模型去做生成,往往結果是從大量數據中統計出分布聚集的部分,企圖用這種方式讓人工智能去超越數據中的優秀作品,是未必現實的。統計模型是否適合用于藝術創作,也是一個需要理性審視的問題。現今深度學習大量用于音樂生成問題的研究,或有跟風之嫌。
(三)人工智能音樂生成的輔助角色探索
如果假定了評價音樂的核心是人,那么人工智能挑戰人類的命題將無從說起。根本上說,既然人工智能不具備審美,那就沒有人工智能創作的音樂,只有人創作的音樂。人工智能不會取代人類,更不會超越人類。然而,人類也并不是要排斥人工智能。從音樂發展的歷史長河看來,音樂創作并不只是遵照前人技法的繼承,推陳出新同樣重要。總有一些音樂,引領著時代,也總有一些音樂,試圖打破前人的思想局限,尋覓新的音響效果。也許人工智能是一種很好的實驗工具,加快新作品的誕生,偶爾的打破想象力的局限,帶來一絲絲的新鮮感。
(四)人工智能音樂的知識產權
假定人工智能生成的音樂已經比較成熟,那人工智能生成的音樂如何歸屬,則是一個無法繞開的議題。實際上,以計算機作為工具創作音樂并非新鮮事。但人工智能的發展還是帶來了新的問題。人工智能生成的音樂,無論品質如何,在形式或體裁上可以做到與人類創作的一致,比起純粹的工具而言有更高的自動化程度,這也不可避免了引發了人工智能音樂歸屬權的討論,尤其受到關注的討論則是,人工智能音樂應該屬于人工智能的編程者(設計者),還是人工智能音樂系統的操作者?從現實情況來看,人工智能音樂尚未發展到有足夠自主意識的程度,人機交互或是目前輸出作品的主流形式。這個過程,人工智能音樂的操作者舉足輕重,從學理上,版權屬于操作者的論斷得到了不少支持。
但從另一個角度來看,這種論斷也有站不住腳的地方。人工智能音樂的生成,尤其是基于數據驅動的人工智能解決方案,是依賴于數據的。一方面,這些數據,作為作品,本身就可能具有版權。另一方面,這些數據的收集與篩選也是基于人工智能設計師的邏輯。從這個角度來講,將版權歸屬于操作者的做法,也必然受到質疑。在目前的行業技術現狀之下,通過版權法對人工智能音樂的操作者進行激勵,可以為這些操作者的創作行為提供驅動力。但在未來,如果操作者已經無需深度參與創作,僅僅需要按下一個按鈕,或者插上電源,對操作者的激勵可能就不再具有必要性。
(五)人工智能音樂的教育模式
人工智能音樂的教學在我國剛剛起步。中央音樂學院已建立人工智能與音樂信息科技系,招收相關專業博士研究生。四川音樂學院設立了人工智能音樂碩士專業,疫情期間在線上舉辦8 次人工智能音樂專題講座,研究生反響強烈。還有一些理工科大學教授出于個人對音樂的愛好,建立了與人工智能音樂相關的研究項目,培養音樂科技兩棲人才。
人工智能音樂在我國的教育模式建設,可以說是經歷著一個從0 到1 的過程。這個過程的建設,也必然有些問題需要思考。需要深入探討的一點是,人工智能音樂,重點是人工智能還是音樂?這個問題或許會有不同的理解。假設人工智能音樂的教育模式中,人工智能是重點,那么在課程的設計上,應該借鑒現今高校開設的人工智能專業課程體系,從編程基礎入手,循序漸進,首先把人工智能理論知識掌握透徹,再著手把理論知識應用至音樂當中。另一種理解則是,“人工智能音樂”更應該調整語序為“音樂人工智能”,強調教學過程中音樂的地位。這種觀點很重要的一個論點是,技術是服務于藝術的。音樂是一門聽覺藝術,需要用聲音來傳遞情感,喚起人們內心的共鳴。因此無論是用何種方法創造的音樂,都不應該忽視人的審美。倘若人工智能音樂的側重點在于技術,興許有本末倒置之嫌。
然而,如果有足夠多的學生,既懂音樂又懂計算機,這種方向之爭大可淡化。現實情況是,音樂與計算機的跨域人才十分稀缺。因而推動人工智能音樂這個領域的發展,人才培養是一大關鍵要素。有更多的人才進入人工智能音樂這個交叉學科領域,深耕技術,潛心科研,不斷尋求創新與突破,才會讓這個學科不斷進步,走向成熟。
結 語
縱觀音樂發展史可知,科技一直在音樂中擔當基本發展動力的角色,從春秋時期的管子、古希臘的畢達哥拉斯對樂音和音階構成的數理解釋,到當今飛速發展的網絡技術對音樂全球一體化的影響,種種事例無一不在提示我們:科技自身不會產生藝術,但可以激發人類以形式創新的方式來推動整體音樂藝術的發展。這也正是我們堅信人工智能音樂具有光明發展前景的基本理念所在。
①Amper Music 詳情見網站https://ampermusic.com/
②Jukedeck 公司目前已被字節跳動收購
③AVIA 詳情見網站https://www.aiva.ai/
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
兒童繪本(2017年24期)2018-01-07 15:51:37
小康(2017年16期)2017-06-07 09:00:59
光學精密工程(2016年6期)2016-11-07 09:07:19
南風窗(2016年19期)2016-09-21 16:51:29
東方藝術·大家(2016年6期)2016-09-05 07:30:56
