深度擴(kuò)展網(wǎng)絡(luò)在圖像識(shí)別中的應(yīng)用
2020-12-04 07:50:46錢(qián)淑娟
計(jì)算機(jī)技術(shù)與發(fā)展 2020年11期
關(guān)鍵詞:結(jié)構(gòu)模型
錢(qián)淑娟
(上海理工大學(xué) 理學(xué)院,上海 200093)
0 引 言
近幾年來(lái),卷積神經(jīng)網(wǎng)絡(luò)(CNN)[1]在各種機(jī)器學(xué)習(xí)應(yīng)用中展現(xiàn)出巨大的價(jià)值,尤其是圖像識(shí)別這一領(lǐng)域。但這一類結(jié)構(gòu)復(fù)雜程度高,需要消耗大量的計(jì)算時(shí)間和CPU資源。2015年牛津大學(xué)的視覺(jué)幾何組和Google DeepMind公司提出了VGG[2]結(jié)構(gòu),VGG結(jié)構(gòu)簡(jiǎn)單緊湊,參數(shù)量大,具有廣泛的應(yīng)用價(jià)值,因此緊湊型神經(jīng)網(wǎng)絡(luò)體系結(jié)構(gòu)受到廣泛的關(guān)注。緊湊型網(wǎng)絡(luò)結(jié)構(gòu)在一定程度上能夠解決深度卷積神經(jīng)網(wǎng)絡(luò)中參數(shù)多、模型大的問(wèn)題。
對(duì)于卷積層的設(shè)計(jì),ResNet[3]和DenseNet-BC[4]注重結(jié)構(gòu)間的連通性,具有較強(qiáng)的參數(shù)共享能力,保證網(wǎng)絡(luò)中層與層之間高效的信息交互。Google提出的深度可分離結(jié)構(gòu)MobileNet[5],引入傳統(tǒng)結(jié)構(gòu)中的分組設(shè)計(jì),將卷積分成深度卷積以及點(diǎn)卷積,計(jì)算規(guī)模上比傳統(tǒng)結(jié)構(gòu)減少了數(shù)倍。這些模型從網(wǎng)絡(luò)中刪除影響較小的幾個(gè)連接,降低了訓(xùn)練過(guò)程中的資源消耗。從圖1中可以看出,傳統(tǒng)的模型壓縮方法,例如剪枝[6],會(huì)使不同層間的相關(guān)信息難以交互,它們?nèi)コW(wǎng)絡(luò)中大量的神經(jīng)元連接,造成模型全局連通性較差。網(wǎng)絡(luò)中的連通性適合利用常規(guī)的圖形來(lái)分析,它是構(gòu)造良好的連通性的一種高效處理方式。該文提出利用擴(kuò)展圖[7]有關(guān)的結(jié)構(gòu)來(lái)設(shè)計(jì)各層間的連接,擴(kuò)展圖是理論計(jì)算機(jī)科學(xué)中的基礎(chǔ)內(nèi)容,是一種結(jié)構(gòu)稀疏但連通性強(qiáng)的圖,在網(wǎng)絡(luò)通信和區(qū)塊鏈技術(shù)中得到了廣泛的應(yīng)用。
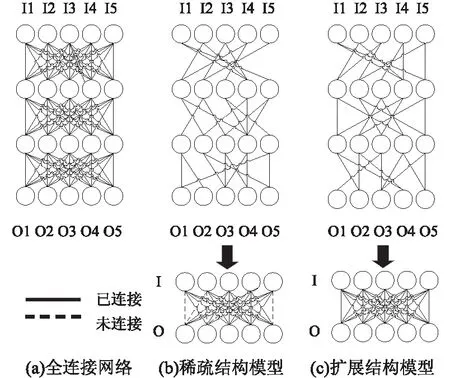
圖1 三種網(wǎng)絡(luò)模型結(jié)構(gòu)
該文使用擴(kuò)展圖來(lái)表示深層網(wǎng)絡(luò)中的神經(jīng)元連接,并且驗(yàn)證提出的結(jié)構(gòu)在圖像識(shí)別中產(chǎn)生的效果。使用稀疏矩陣以及快速卷積設(shè)計(jì)卷積層(Expander-Conv)的高效結(jié)構(gòu),將擴(kuò)展卷積與連通性較差的分組卷積[8]進(jìn)行性能比較。當(dāng)這兩種卷積方式都應(yīng)用于ImageNet數(shù)據(jù)集上訓(xùn)練時(shí),Expander-Conv層實(shí)現(xiàn)的準(zhǔn)確度更高。同時(shí)還在CIFAR-100、MNIST多個(gè)數(shù)據(jù)集進(jìn)行訓(xùn)練,來(lái)驗(yàn)證該設(shè)計(jì)具有良好的圖像識(shí)別能力。與修剪技術(shù)相比,Deep-ExpanderNet模型具有更強(qiáng)的連通性和更快的訓(xùn)練速度,展示出了更高的網(wǎng)絡(luò)性能。
1 相關(guān)工作
文中方法是將神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)和網(wǎng)絡(luò)壓縮技術(shù)結(jié)合起來(lái),通過(guò)研究相關(guān)文獻(xiàn)對(duì)這兩種技術(shù)進(jìn)行了詳細(xì)的介紹。
1.1 高效層設(shè)計(jì)
近年來(lái),神經(jīng)網(wǎng)絡(luò)的研究得到較大的發(fā)展,廣泛應(yīng)用于模式識(shí)別、推薦系統(tǒng)、語(yǔ)音識(shí)別、計(jì)算機(jī)視覺(jué)等諸多領(lǐng)域,但是神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的選取與設(shè)計(jì)會(huì)對(duì)應(yīng)用效果產(chǎn)生重大影響。神經(jīng)網(wǎng)絡(luò)的性能與結(jié)構(gòu)有著密切的關(guān)聯(lián),但是目前缺乏科學(xué)的理論指導(dǎo)。大多數(shù)是利用已有的較為成熟的結(jié)構(gòu),但是每個(gè)結(jié)構(gòu)有其應(yīng)用的獨(dú)特性,最終導(dǎo)致模型的計(jì)算量大、效率低,這種盲目的選擇方法嚴(yán)重制約了神經(jīng)網(wǎng)絡(luò)的應(yīng)用。目前,人們對(duì)設(shè)計(jì)新的結(jié)構(gòu)以及高效地利用它們進(jìn)行圖像識(shí)別進(jìn)行了深入研究。該文的研究方向就是基于已有的結(jié)構(gòu)進(jìn)行改進(jìn)。
近幾年結(jié)構(gòu)設(shè)計(jì)的研究方向之一是架構(gòu)搜索[9],架構(gòu)搜索根據(jù)已有效果較好的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),找到更高效的結(jié)構(gòu),一般通過(guò)替換當(dāng)中的一層,增添一層或者減少一層來(lái)實(shí)現(xiàn)。架構(gòu)搜索主要分為三個(gè)步驟:首先確定搜索空間;然后確定所采用的優(yōu)化算法;最后設(shè)計(jì)合理的評(píng)估方案。Deep-ExpanderNet結(jié)構(gòu)也利用了網(wǎng)絡(luò)架構(gòu)搜索的思想。
另一種高效的架構(gòu)設(shè)計(jì)是分組卷積,它最初是在AlexNet[10]中提出的,當(dāng)時(shí)處理設(shè)備的計(jì)算能力有限,AlexNet卷積運(yùn)算不能由單個(gè)GPU處理,需要將降維操作交由多個(gè)GPU并行處理,最后合并多個(gè)GPU運(yùn)行的結(jié)果。假設(shè)常規(guī)卷積中輸入特征映射的尺寸為L(zhǎng)*H*W,卷積核的數(shù)量為N個(gè),單個(gè)卷積核的大小均為L(zhǎng)*K*K,那么N個(gè)卷積核的參數(shù)總量為N*L*K*K。當(dāng)利用分組卷積進(jìn)行操作時(shí),輸入特征映射的尺寸以及卷積核數(shù)與常規(guī)卷積時(shí)相同,劃分為G組,單個(gè)卷積核的大小為L(zhǎng)/G*K*K,卷積核數(shù)為N/G,卷積核的總參數(shù)量為N*L/G*K*K,分組卷積后的參數(shù)量縮小為原先的1/G。分組卷積主要用于減少參數(shù)規(guī)模以及結(jié)構(gòu)稀疏。近幾年,設(shè)計(jì)深層網(wǎng)絡(luò)主要是通過(guò)增強(qiáng)層間的連通性,實(shí)現(xiàn)信息在深層網(wǎng)絡(luò)中的高效流動(dòng),使得圖像識(shí)別的精度得到更大的提高。
在2014年ILSVRC的比賽中,Google Inception Net[11]以巨大的優(yōu)勢(shì)取得第一名的成績(jī)。InceptionNet設(shè)計(jì)的Inception Module,先將前一層產(chǎn)生的特征圖作為1×1、3×3和5×5的卷積層和一個(gè)最大池化層的輸入,然后各個(gè)分支在輸出通道上堆疊到一起,作為下一個(gè)模塊的輸入。這種深層網(wǎng)絡(luò)結(jié)構(gòu)限制了計(jì)算量和參數(shù)量,提高了準(zhǔn)確率并且降低了過(guò)擬合的可能性。
1.2 網(wǎng)絡(luò)壓縮
神經(jīng)網(wǎng)絡(luò)模型在圖像識(shí)別領(lǐng)域取得了顯著的成果,但是通常有幾百萬(wàn)的參數(shù)和幾十層的網(wǎng)絡(luò),結(jié)構(gòu)相當(dāng)復(fù)雜,需要大量的計(jì)算成本和存儲(chǔ)空間。股票行情分析、遠(yuǎn)程醫(yī)療監(jiān)控以及自動(dòng)駕駛等實(shí)時(shí)應(yīng)用的網(wǎng)絡(luò)結(jié)構(gòu),首要目標(biāo)就是降低其存儲(chǔ)和計(jì)算成本,減少結(jié)構(gòu)的層數(shù)和參數(shù)。目前移動(dòng)設(shè)備占據(jù)重要的市場(chǎng),如何讓神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)模型在移動(dòng)設(shè)備上發(fā)揮作用,也是網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)的一項(xiàng)重要任務(wù)。學(xué)者們提出了神經(jīng)網(wǎng)絡(luò)壓縮[12]的思想,對(duì)結(jié)構(gòu)進(jìn)行一定程度的簡(jiǎn)化。神經(jīng)網(wǎng)絡(luò)壓縮指的是改變網(wǎng)絡(luò)結(jié)構(gòu)或利用量化的方式來(lái)縮減結(jié)構(gòu)的參數(shù)量,在保證運(yùn)行精度不受影響的同時(shí),降低網(wǎng)絡(luò)計(jì)算成本和內(nèi)存消耗。神經(jīng)網(wǎng)絡(luò)壓縮大體上包含參數(shù)修剪和共享,低秩因子分解,壓縮卷積濾波器以及知識(shí)蒸餾這四類方法。
基于剪枝和共享的方法剔除對(duì)精度影響甚微的數(shù)據(jù),需要預(yù)先訓(xùn)練模型。該方法包含以下三類:模型量化和二進(jìn)制化、參數(shù)共享和結(jié)構(gòu)化矩陣。量化方式削減每個(gè)權(quán)重所占用的數(shù)據(jù)量來(lái)達(dá)到壓縮網(wǎng)絡(luò)的效果,參數(shù)共享常用于降低網(wǎng)絡(luò)結(jié)構(gòu)復(fù)雜度,結(jié)構(gòu)化矩陣是指少于m×n個(gè)參數(shù)組成的一個(gè)m×n階矩陣。低秩分解方式利用矩陣計(jì)算神經(jīng)網(wǎng)絡(luò)模型的參數(shù),需要預(yù)先訓(xùn)練模型。基于遷移/壓縮卷積濾波器的方法采用特定的卷積核來(lái)存儲(chǔ)參數(shù),能夠減少參數(shù)規(guī)模和計(jì)算復(fù)雜度,通常可以取得較好的結(jié)果。該方法依據(jù)Cohen[13]的群等變卷積的思想,利用變換矩陣T(.)轉(zhuǎn)變輸入x,然后提交給層Φ(.)處理,其結(jié)果和轉(zhuǎn)換這兩個(gè)步驟的結(jié)果是相同的。
其公式可以表示為:
Φ(x)=Φ(Tx)
其中,x為輸入,Φ(.)為網(wǎng)絡(luò)或?qū)拥奶幚聿僮鳎琓(.)為變換矩陣。
Φ(.)采用變換的方式來(lái)縮減網(wǎng)絡(luò)結(jié)構(gòu),能夠直接降低參數(shù)規(guī)模。知識(shí)蒸餾方法學(xué)習(xí)softmax函數(shù)產(chǎn)生的概率分布,產(chǎn)生一個(gè)更緊湊的神經(jīng)網(wǎng)絡(luò)來(lái)模擬最初復(fù)雜的模型,模型的學(xué)習(xí)能力受網(wǎng)絡(luò)結(jié)構(gòu)的影響,只能從零開(kāi)始訓(xùn)練。這幾種網(wǎng)絡(luò)壓縮方法[14]可用于卷積層和全連接層的結(jié)構(gòu)設(shè)計(jì),遷移/壓縮卷積濾波器一般情況下不用于全連接層的設(shè)計(jì)。該文利用擴(kuò)展圖結(jié)構(gòu)設(shè)計(jì)神經(jīng)網(wǎng)絡(luò)各層間的連接,減少結(jié)構(gòu)的參數(shù)規(guī)模,并在圖像識(shí)別數(shù)據(jù)集中取得較好的效果。
2 二部圖與結(jié)構(gòu)化稀疏
近幾年諸如ResNet和DenseNet等卷積神經(jīng)網(wǎng)絡(luò)成熟的結(jié)構(gòu),其原理都是不斷增強(qiáng)神經(jīng)元的連接性,達(dá)到更高的精度。這些研究結(jié)果表明,連通性是提高深層網(wǎng)絡(luò)結(jié)構(gòu)性能的一個(gè)重要因素。該文研究了在保持神經(jīng)元之間連通性的同時(shí),顯著地減少神經(jīng)元之間的冗余連接。這樣的結(jié)構(gòu)不但可以保持準(zhǔn)確性,也能夠降低參數(shù)規(guī)模。
2.1 二部圖與深度卷積神經(jīng)網(wǎng)絡(luò)
該文利用擴(kuò)展圖來(lái)優(yōu)化神經(jīng)元間的連接,并將闡述擴(kuò)展圖和深度卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)之間的關(guān)聯(lián)。
給定一個(gè)頂點(diǎn)集為U,V的二部圖G,二部圖[15]是圖論中的基礎(chǔ)內(nèi)容。G是一個(gè)無(wú)向圖,頂點(diǎn)集由兩個(gè)完全不同的子集組成,圖中的每條邊(i,j)所關(guān)聯(lián)的兩個(gè)頂點(diǎn)i和j處于這兩個(gè)不同的頂點(diǎn)集中。G所定義的線性層,是一個(gè)包含|U|個(gè)輸入神經(jīng)元,V個(gè)輸出神經(jīng)元的層,每個(gè)輸出神經(jīng)元只接收G給出的神經(jīng)元的輸入。圖G是結(jié)構(gòu)稀疏的,只存在M條邊。線性層中有M個(gè)參數(shù),|V|×|U|是較為常見(jiàn)的尺寸大小。卷積層表示成頂點(diǎn)為U和V、卷積核大小為c×c的二部圖G。卷積層接收|U|個(gè)通道的輸入,并生成帶有|V|個(gè)通道的輸出。該結(jié)構(gòu)的卷積核有M×c×c個(gè)參數(shù),而普通神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)卷積核的參數(shù)數(shù)量為|V|×|U|×c×c,參數(shù)的規(guī)模得到一定程度的減少。
2.2 結(jié)構(gòu)化稀疏
文中模型通過(guò)稀疏圖G[16]來(lái)創(chuàng)建卷積層的結(jié)構(gòu)。在沒(méi)有任何數(shù)據(jù)分布的情況下,從所有輸入通道的集合中隨機(jī)地選擇每個(gè)輸出通道的鄰域,利用這種方式產(chǎn)生的圖G被稱為擴(kuò)展圖,其階數(shù)為D、譜隙為γ,具有稀疏和連通兩大特性。且擴(kuò)展圖G=(U,V,E),其中E是邊的集合,E?U×V。與稠密圖中|U|×|V|條邊相比,該圖只有D×|V|條邊,具備稀疏性這一特點(diǎn)。對(duì)于每個(gè)頂點(diǎn)v∈V,D個(gè)鄰域是從U中隨機(jī)且不重復(fù)地篩選出來(lái)的。擴(kuò)展線性層(Expander-Linear)是由一個(gè)D階隨機(jī)二部擴(kuò)展圖G定義的層,其中系數(shù)D較小,而擴(kuò)展因子K與D大致相等,使得該層仍有良好的學(xué)習(xí)能力。擴(kuò)展卷積層(Expander-Conv)是由一個(gè)D階的隨機(jī)二部擴(kuò)展圖G定義的卷積層,其中系數(shù)D較小。對(duì)于擴(kuò)展圖G1=(V0,V1,E1),G2=(V1,V2,E2),…,Gm=(Vm-1,Vm,Em),將卷積網(wǎng)絡(luò)定義為m層深度網(wǎng)絡(luò),其中卷積層使用上述定義的Expander-Conv層,線性層使用上述定義的Expander-Linear層。擴(kuò)展圖中的隨機(jī)游走[17]快速收斂于圖節(jié)點(diǎn)上的均勻分布。Deep-ExpanderNet有多層,每個(gè)層都有從擴(kuò)展圖中得到的連接,有著強(qiáng)大的連通性。
3 Deep-ExpanderNet模型
Deep-ExpanderNet模型利用擴(kuò)展圖的結(jié)構(gòu)稀疏性以及快速密集卷積來(lái)設(shè)計(jì)算法,降低了參數(shù)規(guī)模,提高了運(yùn)行速度,并在訓(xùn)練過(guò)程中大大地節(jié)省了內(nèi)存。在給定內(nèi)存和運(yùn)行時(shí)間有限的情況下,該結(jié)構(gòu)可以獲得高效的性能。
3.1 稀疏卷積模型
稀疏連接可以達(dá)到較高的壓縮率,但可能會(huì)產(chǎn)生雜亂的卷積核,需要結(jié)合稀疏矩陣來(lái)加快計(jì)算。當(dāng)D較小時(shí),擴(kuò)展圖的鄰接矩陣是高度稀疏的。模型可以使用與擴(kuò)展圖的邊緣相對(duì)應(yīng)的非零項(xiàng)來(lái)初始化稀疏矩陣。與大多數(shù)壓縮模型不同,稀疏連接是在訓(xùn)練階段之前結(jié)構(gòu)就能夠確定,并且比較穩(wěn)定[18]。在模型訓(xùn)練結(jié)束后,將所有卷積核轉(zhuǎn)換為稀疏矩陣存儲(chǔ),防止每次前向傳播進(jìn)行重構(gòu)。稀疏卷積達(dá)到了很高的壓縮率[19],提高了統(tǒng)計(jì)效率,并且大多數(shù)深度學(xué)習(xí)庫(kù)提供了相關(guān)實(shí)現(xiàn)。
3.2 密集卷積結(jié)構(gòu)
在Expander-Conv層中,每個(gè)輸出通道只與外部輸入通道相關(guān)。Expander-Conv使用初始化模型時(shí)產(chǎn)生的掩碼從輸入中篩選出D個(gè)通道,然后與一個(gè)尺寸為k×k×D×1的卷積核進(jìn)行卷積操作,輸出層為filter遍歷輸入層的計(jì)算結(jié)果。從1至輸入通道數(shù)間的數(shù)字中隨機(jī)且不重復(fù)選取D個(gè)樣本得到掩碼。所篩選的D個(gè)通道的掩碼為1,其他通道的掩碼為0。該模型將Expander-Conv層權(quán)值矩陣中的非零權(quán)值系數(shù)表示為D通道的壓縮密集矩陣,輸出是選定的通道與壓縮權(quán)值矩陣卷積后的結(jié)果。Expander-Conv層的基本原理如圖2所示。
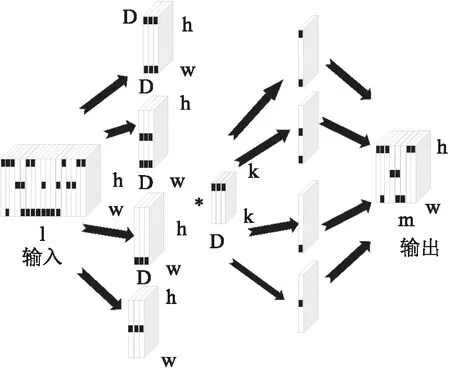
圖2 Expander-Conv層的基本原理
3.3 Deep-ExpanderNet架構(gòu)
圖3是設(shè)計(jì)的深度擴(kuò)展網(wǎng)絡(luò)Deep-ExpanderNet架構(gòu)圖。在擴(kuò)展卷積結(jié)構(gòu)之前,增加了一般卷積和最大池化,實(shí)現(xiàn)了不同通道間的特征組合。為了降低網(wǎng)絡(luò)的參數(shù)規(guī)模,在擴(kuò)展卷積結(jié)構(gòu)后面采用了多個(gè)1×1的標(biāo)準(zhǔn)卷積,對(duì)同一位置、不同通道的特征圖進(jìn)行融合。當(dāng)輸出通道數(shù)量一致時(shí),3×3卷積能夠?qū)崿F(xiàn)相同的功能,但3×3卷積參數(shù)量是1×1卷積的參數(shù)量的9倍。
在最后的擴(kuò)展卷積結(jié)構(gòu)之后是增加了多個(gè)尺寸較小的卷積層,這些卷積層替代全連接的輸出層,用于實(shí)現(xiàn)特征提取。增加多個(gè)小型卷積層是將特征圖的寬度和高度不斷縮小、使通道數(shù)量與圖像數(shù)據(jù)集中的類別數(shù)目大致相同。2×2等尺寸的卷積核獲得較大的感受野需要更多網(wǎng)絡(luò)的層數(shù),增加網(wǎng)絡(luò)訓(xùn)練難度,容易出現(xiàn)過(guò)擬合,5×5、7×7尺寸的卷積核各層的參數(shù)規(guī)模大,導(dǎo)致訓(xùn)練速度慢,且5×5尺寸的卷積核能用兩個(gè)3×3卷積代替。經(jīng)實(shí)驗(yàn)證明,3×3卷積最為合適,能使網(wǎng)絡(luò)的參數(shù)數(shù)量和計(jì)算量少并且分類準(zhǔn)確率高。

圖3 Deep-ExpanderNet架構(gòu)
4 實(shí)驗(yàn)和結(jié)果
為了驗(yàn)證提出的深度擴(kuò)展網(wǎng)絡(luò)架構(gòu)的性能,本節(jié)將在CIFAR-100、MNIST多個(gè)數(shù)據(jù)集中進(jìn)行測(cè)試和驗(yàn)證。實(shí)驗(yàn)采用python語(yǔ)言,并且使用了Tensorflow學(xué)習(xí)庫(kù)。CIFAR-10數(shù)據(jù)集共有60 000張圖像,圖像的尺寸為32×32,由50 000張訓(xùn)練樣本和10 000張測(cè)試樣本組成,對(duì)圖像隨機(jī)剪切成為28×28的大小。MNIST數(shù)據(jù)集是由60 000張訓(xùn)練樣本和10 000張測(cè)試樣本組成的圖像數(shù)據(jù)集,每個(gè)樣本為28×28大小的灰度手寫(xiě)數(shù)字圖像,是機(jī)器學(xué)習(xí)領(lǐng)域中比較常用的一個(gè)數(shù)據(jù)集。
4.1 與分組卷積比較
本節(jié)將擴(kuò)展卷積(Expander-Conv)與分組卷積(G-Conv)進(jìn)行比較。分組卷積是目前較為常用的方法,具有與擴(kuò)展卷積網(wǎng)絡(luò)相同的稀疏性,但缺乏連通性。實(shí)驗(yàn)選擇MobileNet作為基礎(chǔ)模型,它是高效的神經(jīng)網(wǎng)絡(luò)架構(gòu)。實(shí)驗(yàn)中將MobileNet-0.5中的尺寸大小為1×1卷積層替換為Expander-Conv層,形成Expander-MobileNet-0.5。同樣,將它們替換為G-Conv層,以形成Group-MobileNet-0.5。對(duì)比結(jié)果如圖4所示。

圖4 Group-MobileNet-0.5與Deep-ExpanderNet-0.5損失率對(duì)比
E-m或G-m表示使用Expander-Conv或G-Conv將1×1轉(zhuǎn)換層壓縮m次。當(dāng)增加稀疏性時(shí),Expander-MobileNets的準(zhǔn)確率比Group-MobileNets高出4%以上。實(shí)驗(yàn)表明Expander-Conv可以用來(lái)進(jìn)一步提高性能。
4.2 與剪枝技術(shù)的比較
與ResNets相比,文中模型實(shí)現(xiàn)了更好的性能,Expander-ResNets的計(jì)算量減少一半,而準(zhǔn)確率僅降低2%左右。為了進(jìn)一步證明文中模型在DenseNet-BC上的高效性,在CIFAR100數(shù)據(jù)集上對(duì)其進(jìn)行了測(cè)試,并在圖5中繪制了對(duì)比曲線。
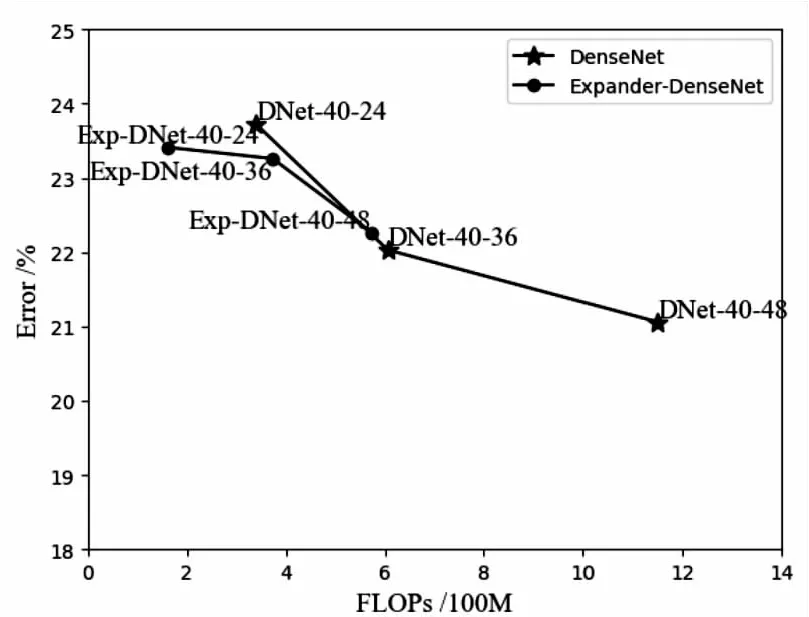
圖5 DenseNet以及Expander-DenseNet性能對(duì)比曲線
文中方法的思想是在訓(xùn)練開(kāi)始之前,用一個(gè)經(jīng)過(guò)充分研究的稀疏連接模式來(lái)約束權(quán)重矩陣,這樣就可以對(duì)Expander-Conv模型進(jìn)行快速訓(xùn)練。在VGG16架構(gòu)上進(jìn)行了性能測(cè)試。將兩種Expander-VGG-16模型與現(xiàn)有修剪技術(shù)進(jìn)行了比較。在減少50%的參數(shù)和計(jì)算量的情況下,Expander-VGG-16達(dá)到與VGG16模型相似的精度,達(dá)到了最先進(jìn)的剪枝技術(shù)相等的水平。
4.3 模型的穩(wěn)定性
在ImageNet數(shù)據(jù)集上與分組卷積進(jìn)行比較,以證明基于擴(kuò)展的模型在多次運(yùn)行中的精度與普通神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的訓(xùn)練結(jié)果相似。用MobileNet0.5進(jìn)行了多次分組和擴(kuò)展方法的實(shí)驗(yàn)。從表1可以看出,兩個(gè)模型之間的精度變化相當(dāng),差值小于1%,證明文中模型不會(huì)降低穩(wěn)定性。因此,即使選擇了效果較差的連接圖,精度受到影響的可能性較小。
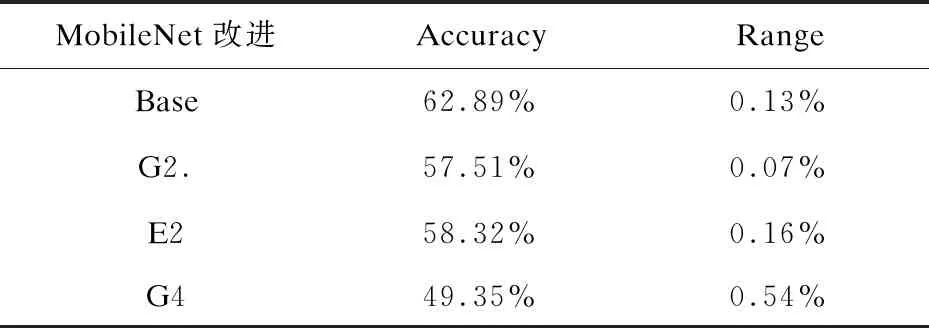
表1 ImageNet數(shù)據(jù)集上MobileNet0.5改進(jìn)結(jié)構(gòu)的準(zhǔn)確度和變化范圍
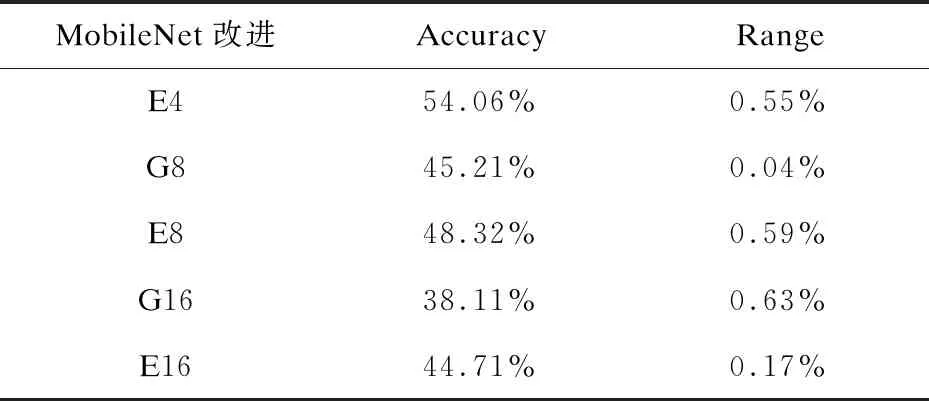
續(xù)表1
4.4 訓(xùn)練更廣泛和更深入的網(wǎng)絡(luò)
Expander-DenseNet在訓(xùn)練之前將權(quán)重矩陣約束為稀疏連接模式,可以在訓(xùn)練階段充分利用內(nèi)存和運(yùn)行時(shí)間,這樣能夠訓(xùn)練出更高效的網(wǎng)絡(luò)。文中測(cè)試了Expander-DenseNet不同的寬度以及深度對(duì)精度的影響。實(shí)驗(yàn)中調(diào)整了DenseNet-BC-40-60的結(jié)構(gòu),分別將增長(zhǎng)率從60提高到100和200,并比較了不同的網(wǎng)絡(luò)寬度對(duì)這些模型的影響。同樣,將深度從40增加到58和70,比較各項(xiàng)訓(xùn)練后的數(shù)據(jù)。實(shí)驗(yàn)使用CIFAR-100數(shù)據(jù)集對(duì)這些方法進(jìn)行性能對(duì)比,結(jié)果如圖6所示。實(shí)驗(yàn)結(jié)果表明,結(jié)構(gòu)更深的Expander-DenseNet-BC-70-60的性能明顯優(yōu)于Expander-DenseNet-BC-58-60,而結(jié)構(gòu)更寬的Expander-DenseNet-40-200比Expander-DenseNet-BC-40-100表現(xiàn)出更好的性能。曲線斜率的減小表明Expander-DenseNet模型隨著深度和寬度壓縮的增加而受到的損失較小。
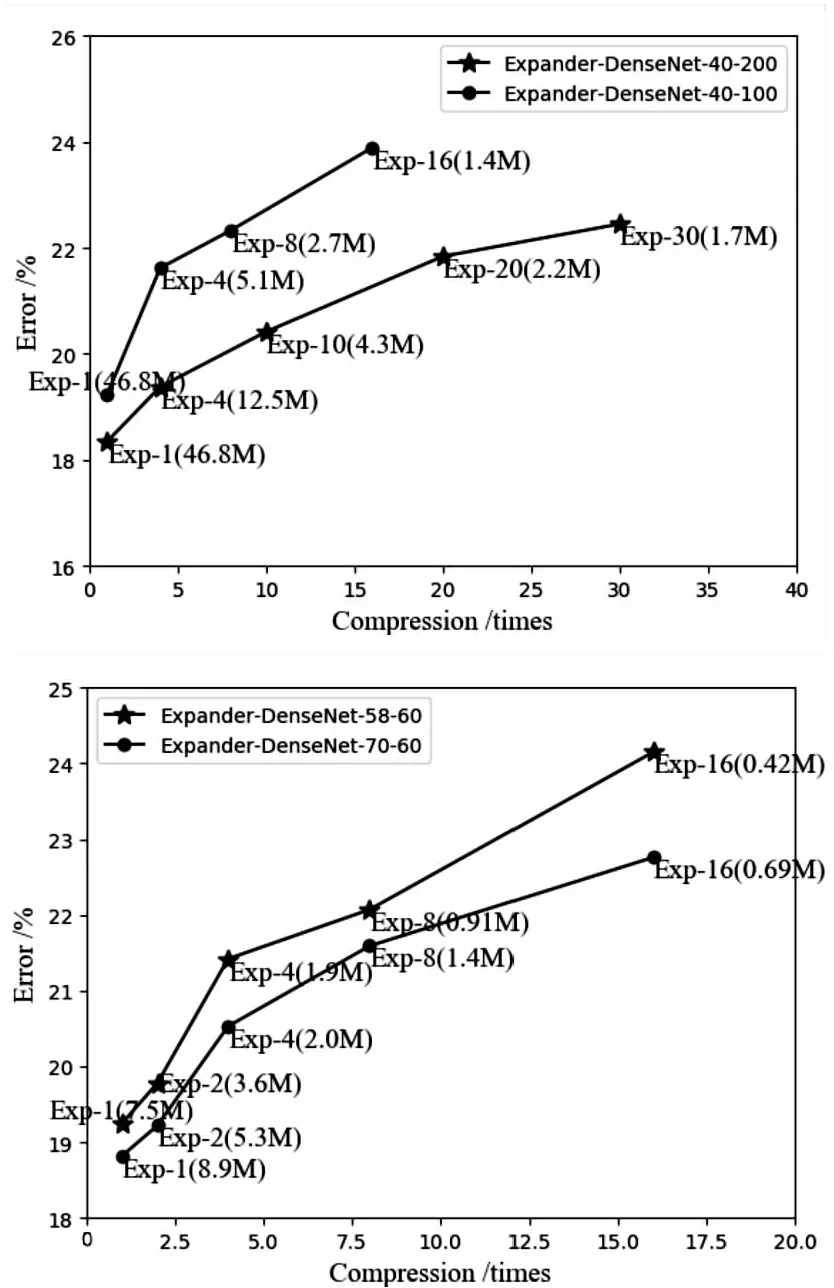
圖6 Expander-DenseNet寬度與深度的性能對(duì)比曲線
4.5 識(shí)別對(duì)比實(shí)驗(yàn)結(jié)果
表2中使用MNIST測(cè)試集上的錯(cuò)誤率作對(duì)比,有著更直觀的比較。實(shí)驗(yàn)表明,Deep-ExpanderNet在參數(shù)數(shù)量較少的情況下,有更高的識(shí)別率。在參數(shù)規(guī)模遠(yuǎn)低于其他網(wǎng)絡(luò)結(jié)構(gòu)的情況下,依然可以達(dá)到更高的準(zhǔn)確率。
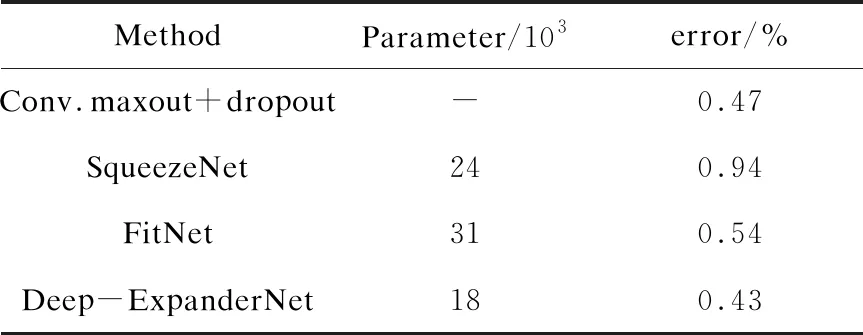
表2 MNIST對(duì)比實(shí)驗(yàn)結(jié)果
5 結(jié)束語(yǔ)
使用擴(kuò)展圖提出了一種新的深層網(wǎng)絡(luò)結(jié)構(gòu),該結(jié)構(gòu)在圖像識(shí)別中有著高效的性能。在準(zhǔn)確性未受影響的情況下,改進(jìn)的結(jié)構(gòu)Deep-ExpanderNet減少了結(jié)構(gòu)上的冗余。強(qiáng)大的網(wǎng)絡(luò)連接性使改進(jìn)后的結(jié)構(gòu)在參數(shù)數(shù)量或計(jì)算成本比目前的體系結(jié)構(gòu)有了顯著的改善。在保證參數(shù)交互的同時(shí),使用高效的方法來(lái)稀疏模型,有助于開(kāi)發(fā)高效的深層網(wǎng)絡(luò)。實(shí)驗(yàn)結(jié)果表明,Deep-ExpanderNet在參數(shù)規(guī)模低于其他網(wǎng)絡(luò)結(jié)構(gòu)的情況下,取得了更好的識(shí)別效果。未來(lái)深層擴(kuò)展網(wǎng)絡(luò)可以在其他領(lǐng)域中得到廣泛應(yīng)用。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學(xué)評(píng)論(2021年2期)2021-08-22 01:53:34
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中華詩(shī)詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評(píng)論(2016年0期)2016-11-23 05:26:01
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
現(xiàn)代企業(yè)(2015年9期)2015-02-28 18:56:50
