超算環境科學工作流應用的容錯*
2020-12-07 09:19:10李于鋒莫則堯肖永浩趙士操段博文
國防科技大學學報 2020年6期
關鍵詞:系統
李于鋒,莫則堯,肖永浩,趙士操,段博文
(1. 中國工程物理研究院 計算機應用研究所, 四川 綿陽 621900; 2. 北京應用物理與計算數學研究所, 北京 100094)
在科學發現和工程仿真中,使用一系列相關軟件完成數據收集、建模、模擬、分析成為普遍現象。各步驟間可能有數據依賴或控制依賴關系,這些軟件相互協作才能獲得最終結果。科學工作流管理系統對這些軟件及其數據依賴關系進行組合,并控制各部分在時間、空間以及資源等約束條件下按序完成,已經成為復雜科學計算流程管理的必要手段,有效推動了科研進展[1]。面向大規模數據集和復雜計算流程的超算環境科學工作流技術提供了自動化、流程化的方法,并為用戶屏蔽作業投遞和數據傳遞轉換等細節,極大地促進了超算環境和應用平臺的協同發展。
在超算環境中,資源失效是常見現象,如計算結點死機或網絡模塊出現故障等問題造成無法正常工作等。據估計E級計算的平均無故障時間(Mean Time Between Failure, MTBF)已縮短為數分鐘[2]。資源失效會造成任務和流程中斷執行。另外,在復雜流程(通常表現為稠密大規模有向圖)中組件數量大、配置煩瑣,對系統環境變量及運行參數有嚴格要求,用戶使用易出現配置錯誤導致軟件組件運行異常,也同樣造成任務運行失敗和流程中斷執行。如何對任務運行失敗進行預防或者失敗后進行自動恢復,以保證流程整體自動持續運行,是工作流容錯研究的重點問題。
容錯作為科學工作流管理系統的重要組成部分,隨著科學工作流運行環境從單機、集群、異構多集群到云的變遷,涌現出多種容錯策略,在不同的運行模式下,為工作流平臺的穩定運行提供了有力保障。特別是對于長時間運行的科學工作流,或者數據處理步驟繁多的流程,提供錯誤自動恢復機制尤為重要。
國內外已經出現了很多工作流系統平臺,這些工作流系統都提供了容錯相關的功能。比如美國加州大學研究者基于Ptolemy II[3]系統開發的Kepler[4]系統,廣泛應用于包括生態學、分子生物學、化學、計算機科學、電子工程和海洋學等領域;美國南加州大學信息科學研究所開發的系統Pegasus[5],已應用于地震及災害模擬,引力波探索(Laser Interferometer Gravitational-wave-Observatory, LIGO)等領域;英國曼切斯特大學計算機科學學院開發的Taverna[6]工作流套件,廣泛應用于生命科學等領域;英國加地夫大學開發的Triana[7]網格集成計算環境,可用于天文學計算和網絡數據處理等領域。這些工作流管理系統的容錯功能將在本文第二部分進行闡述。
為了支持超算環境下科學和工程計算領域數值模擬流程的高效設計與自動執行,中國工程物理研究院計算機應用研究所自主研發了HSWAP工作流應用平臺[8-9],以高性能應用軟件作為組件封裝的基本單位,配置簡單,部署便捷,支持跨平臺應用的協作。本文設計的容錯模型和方法將以HSWAP系統為驗證平臺,基于日志分析,利用數據驅動的方式實現了容錯功能,為錯誤自動恢復、工作流無間斷運行提供了重要支撐。
1 科學工作流容錯的分類
工作流系統的容錯分為任務級和工作流級[10-11],其中任務級又可分為任務重試、檢查點/重啟動、替換資源、多副本運行等,工作流級可分為替換任務、冗余多任務、用戶定義的異常處理、基于修復工作流等。具體分類如圖1所示。任務重試是在任務出錯后,簡單地重新執行該任務,通常會設置一個最大重試次數,即超過該重試次數后若還沒有恢復成功,則放棄重試。檢查點重啟動機制[12]需要任務本身支持檢查點重啟動功能,在任務運行過程中進行一定間隔的檢查點信息保存,在任務異常出錯后能夠從最近的檢查點恢復執行。替換資源方式是指在任務運行失敗后,切換到其他資源繼續運行該任務,以應對資源失效造成的異常。任務多副本運行是指同一個任務(同一實現)在多種資源上同時運行,確保至少有一個運行成功,這是一種預防失效的方式。工作流級容錯的替換任務方式是指任務運行失敗后,會執行任務的另一種實現,該實現同樣完成原來任務的目標;冗余多任務是指會同時運行多個替換任務,也是預防失效的方式;用戶定義的異常處理機制通常是在組件級別對出錯情況進行處理。基于修復工作流是指工作流執行過程中異常發生后記錄失敗的任務信息,生成新的工作流以備后續提交重新運行。
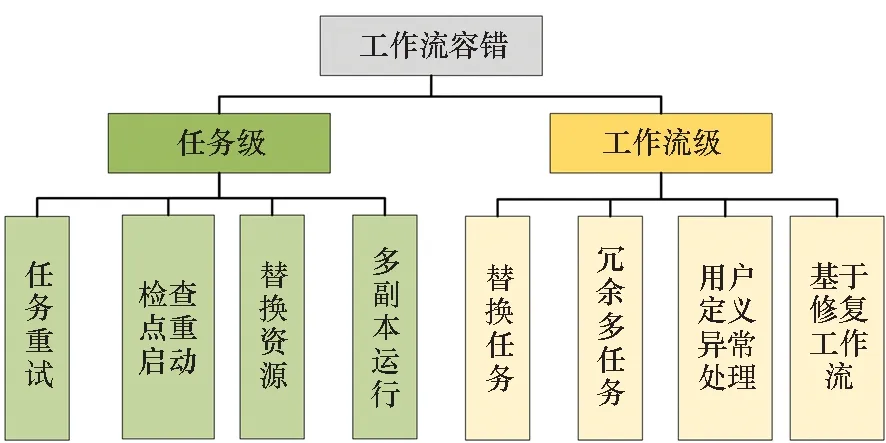
圖1 工作流容錯的分類Fig.1 Taxonomy of fault tolerance
面向基于數據流的科學工作流管理系統,Ustun等[13]提出了多數據實例相關的容錯框架。首先識別出數據處理管線(pipeline)中的錯誤模式,提出的恢復方法包括容許限定次數的失敗項、以啞數據代替因錯誤數據而不能執行的任務輸出、立即重執行錯誤任務(需考慮數據實例依賴關系)、依賴工作流實例的恢復(考慮中間數據的存儲代價和生成代價)等。另外,文獻中利用編程語言模型中的異常處理等技術[14]或研發新的異常處理語言[15]給容錯研究帶來了新技術路線,但由于和原工作流系統的緊耦合性,不易推廣。
2 典型工作流系統的容錯設計
Taverna科學工作流管理系統中的容錯采用了任務重試和替換任務兩種策略,任務重試中工作流設計者可定義最大重試次數,該策略也可應用于子工作流容錯;替換任務允許在任務重試達到最大次數后選擇執行一個不同的任務。
Triana工作流系統的容錯是面向用戶的,如錯誤發生時,會產生警告信息,并允許用戶修改后繼續執行;在工作流級支持輕量級的檢查點/重啟動和工作流服務的選擇。在中間件級和任務級,所有預定義的異常會被Triana引擎感知(死鎖、活鎖和內存泄露除外);在最底層的資源失效方面,借助GridLab GAT工具可以識別資源失效,但是錯誤恢復機制還未完善。
Pegasus的容錯是基于DAGMan和HTCondor開展的。例如,在作業運行錯誤后進行重試或重新提交處理,通常可以在作業文件中設置作業重試次數。針對數據傳輸的可靠性問題,Pegasus傳輸服務會首先嘗試高性能的并行傳輸,失敗后會進行更安全的低速單連接傳輸。如果重試次數已達最大,將生成修復工作流待后續重新運行。另外,Pegasus還支持進行重新資源規劃以重用失敗時已生成的數據,并通過調度任務到不同資源來實現容錯。
Kepler科學工作流系統中的容錯是通過一個稱為Checkpoint的復合actor實現的。actor是Kepler中的專有概念,表示一個執行組件。檢查點復合組件包括一個子工作流和若干可替換的子工作流,當錯誤發生后,發出錯誤時間信息,檢查點內所有工作流停止執行并處理錯誤,決定是否重運行該子工作流或者運行一個可替換的具有同樣功能的子工作流。
已有工作流系統的容錯存在的問題有:容錯生命周期管理不健全,如Taverna、Triana等;容錯處理與執行任務緊耦合,擴展方式不靈活,如Kepler、Taverna等;沒有獨立的容錯機制,依賴其他(網格基礎設施提供的)資源管理工具實現,如Pegasus、Triana等。
容錯的設計需要考慮可靈活配置的錯誤恢復策略、與工作流執行引擎的解耦模型、容錯處理的全生命周期管理等問題。如此設計方可將容錯服務功能方便集成到多種科學工作流系統。HSWAP是面向高性能計算領域的工作流系統平臺,其以封裝數值模擬軟件和應用形成松耦合、粗粒度的工作流為特色,下文提出的容錯模型和方法設計在該類平臺上的實現十分便捷。
3 容錯模型和方法設計
3.1 容錯全生命周期管理
工作流執行異常出現后,對異常的發生、消息的流轉以及針對異常的處理進行全面的分析,有助于給出全面系統的容錯方案。容錯的生命周期如圖2所示,首先是錯誤發生,生成錯誤事件,然后錯誤被監控工具識別監測,最后進入錯誤處理流程,包括錯誤恢復策略以及相關的恢復動作。

圖2 容錯全生命周期管理Fig.2 Full period management of fault tolerance
為支持容錯,工作流系統在設計時應考慮異常狀態管理以及錯誤信息的傳遞,比如錯誤發生后,流程執行中斷進入待恢復狀態,還要考慮錯誤事件的描述,事件消息的發出和相應的消息跟蹤。容錯處理流程的過程如圖3所示,包括異常信息監測、錯誤信息識別、錯誤信息分類、錯誤恢復處理四種主要的功能步驟。

圖3 容錯處理流程Fig.3 Fault handling process
異常信息監測是指異常事件消息發出后,容錯模塊能夠感知和探測到異常;錯誤信息識別則是從工作流系統日志等記錄中有效識別出錯誤信息;錯誤信息分類則是為了進一步的容錯處理縮小處理方式范圍;錯誤恢復處理則是采取相應的執行動作,以使得工作流從中斷暫停狀態轉移至繼續執行或等待用戶救援狀態。
3.2 基于決策樹的ECA容錯模型
異常處理可以采用基于事件-條件-動作(Event-Condition-Action,ECA)的模型[10]構建。ECA模型如圖4所示,針對不同的錯誤事件,在不同的條件下執行相應的動作。

圖4 ECA模型Fig.4 ECA model
在ECA模型中,事件集表示所有發生的事件,每類事件都有一個明確的標識,表明相應的信息,比如任務運行失敗、網絡服務超時等異常信息。條件集里的條件表明當前工作流系統的運行狀態和運行環境,比如工作流引擎是否停止響應、資源是否可用等。動作集里的動作表明實現錯誤恢復需要執行的命令,可以是單個命令,也可以是多步驟的多條命令組合成的復合動作。ECA模型具有很好的靈活性,針對同一事件,對應不同的條件下,則可執行不同的動作指令;在相同條件下,不同事件也可對應不同的動作指令。
在異常事件和環境條件可監測、可探察的前提下,靈活配置錯誤恢復動作是ECA模型的特色。本文擴展了簡單的ECA模型,使得事件發生后,可以結合多個條件來最終選擇相應的動作執行。具體地,引入決策樹算法,基于決策樹高效實現事件-條件集合到動作集合的映射。基于決策樹的錯誤恢復動作選擇示例如圖5所示。

圖5 基于決策樹的錯誤恢復Fig.5 Failure recovery based on decision tree model
基于決策樹模型設計的錯誤恢復針對每個事件都有一顆不同的決策樹。允許不同的事件有不同的處理邏輯,比如圖5中事件1的處理邏輯必須判斷兩個條件才能給出最終的恢復動作,而事件2在條件3滿足的前提下只需判斷一個條件就可以決定恢復動作。另外,不同事件的決策順序也不相同,圖5中事件1需要先判斷條件1,然后判斷條件2或條件3;而事件2則先判斷條件3,然后視結果可能判斷條件1。如此設計有助于減少環境探查,快速決定錯誤恢復動作。具體的執行動作決策如算法1所示。
算法1中決策變量是指某一個條件的布爾值,即對任一條件,都有兩個狀態表示是否滿足。比如計算結點網絡故障不可達(無法連接)、計算結點可連接兩個狀態,每個狀態下都有后續不同的處理邏輯。

算法1 容錯動作決策
3.3 錯誤信息和恢復動作
針對超算環境科學工作流系統的執行特征,設計了錯誤事件信息的要素,如圖6所示。錯誤信息包括錯誤信息的發出位置、出錯模塊、引入環境、產生時間、發生頻率、嚴重等級、造成影響等七個維度。

圖6 錯誤信息要素Fig.6 Elements of fault information
雖然錯誤信息包含的要素較多,但在實際工作流執行過程中能夠獲得的信息卻是有限的,需要建立日志系統來存儲和分析歷史錯誤信息,補充相對完整的錯誤信息,方便后續的錯誤恢復策略選擇決策。

圖7 錯誤恢復處理方式Fig.7 Failure recovery methods
容錯設計考慮了在發生異常事件后可配置不同的處理方式。支持的處理方式如圖7所示,有重試、替換、重啟動、錯誤傳播、忽略、標注和用戶介入七類。重試又包括任務重試和子流程重試,任務重試表示僅重運行出錯任務,子流程重試則重運行出錯任務所在的子流程(工作流的一個子結構)。替換類的處理包括替換資源、替換任務和替換子流程。替換資源表示同一任務在不同的資源上重運行;替換任務表示選擇執行另一個具有同樣功能但不同實現的任務;替換子工作流則表示選擇執行另一個具有相同功能的子工作流執行。重啟動(或稱檢查點-重啟動)方式一般需要任務實現支持,在任務運行過程中,會以一定間隔保留后續恢復時所需的數據信息(檢查點信息記錄),在錯誤恢復時,會從檢查點處重新加載信息繼續執行而不會從頭開始計算。錯誤傳播是指將錯誤信息從出錯任務所在的執行模塊傳遞到工作流系統引擎、用戶界面以及日志系統(將來可能通過網絡遠程傳輸給客戶端或其他系統)。對于一些不影響流程主要功能完成度的異常信息,可采取忽略的處理措施。對于未知異常,可采取標注的方式記錄異常出現的場景及其造成的影響等信息。當任務配置參數出現錯誤引發異常時,通常需要用戶介入,以用戶的專業知識修正任務配置參數,才能夠達到錯誤恢復的目的,這可通過科學工作流的“人在回路”(human in the loop)等技術實現。
3.4 容錯與科學工作流系統的關系
異常信息和處理方法、處理策略設計好之后,應該考慮如何將容錯與科學工作流系統進行有效融合,既能有效發揮出容錯的重要作用,又不影響原有工作流系統的設計。本文提出如圖8所示的設計架構來確定各子系統間的關系。容錯服務和科學工作流引擎獨立開發和部署,基于遠程過程調用(Remote Procedure Call,RPC)和日志服務及消息來進行交互。

圖8 容錯與科學工作流系統的關系Fig.8 Fault tolerance architecture in HSWAP
異常事件發生后,由監控模塊探測到錯誤信息,生成錯誤事件傳遞給科學工作流引擎,進而形成錯誤事件信息,并將該信息發送至日志服務器(可基于 Elastic Search-Logstash構建)。容錯服務會間隔輪詢日志服務獲得所有出錯事件,并用預先配置好的錯誤恢復準則進行錯誤分析,然后觸發錯誤恢復動作,完成錯誤恢復。
如此的容錯架構設計有三方面的優點:一是模塊化,將容錯服務與工作流管理系統和日志系統解耦,實現了松耦合以及容錯模塊可插拔、可替換的目的;二是服務化,將所有錯誤統一集中管理,并實現了高并發的處理邏輯,可同時處理不同用戶、不同工作流實例的錯誤恢復;三是單向消息機制,數據傳輸代價小、效率高、邏輯清晰,在實際系統開發中簡單實用。
4 容錯在HSWAP系統的實現與驗證
4.1 HSWAP簡介
HSWAP是中國工程物理研究院計算機應用研究所開發的超算連貫計算引擎[8-9],旨在HPC環境中使用科學工作流技術提供集成的超算服務模式助力科研人員提高工作效率。基于HSWAP開發的石油地震勘探平臺以及材料高通量計算平臺等行業計算平臺,已在實際項目中得到應用并發揮了重要作用。
HSWAP的主要特色是為超算用戶屏蔽使用超算系統的復雜性,以計算軟件為基本封裝單位形成可復用組件,進而實現靈活可定制業務流程的功能。流程以有向無環圖(Directed Acyclic Graph, DAG)表達,實現流程中結點間依賴管理和數據自動傳遞和轉換功能。平臺的架構和相關模型如圖9所示。
4.2 HSWAP的容錯實現和驗證
HSWAP平臺提供了日志系統,這為實現上文提出的容錯架構提供了方便。引擎執行過程中,會通過Logstash服務將運行時相關信息寫入Elastic Search數據庫,相關信息在容錯模塊可以用來進行容錯動作決策。

(a) HSWAP的模塊架構(a) Architecture of HSWAP

(b) HSWAP的流程和組件模型(b) Workflow and component models of HSWAP圖9 HSWAP平臺的架構和業務模型Fig.9 Architecture and models of HSWAP
在HSWAP中提供了基于數據完整性校驗的兩類錯誤識別和恢復方法。在超算系統中,任務作業退出后,是否正常完成任務目標需要多方面的考慮,其中數據完整性是最常見的判別標準之一,特別是對于數值模擬仿真類任務,生成完整而正確的數據文件幾乎是唯一的標準。基于數據判別的容錯流程如圖10所示,分為三個步驟,即出錯標識、信息收集、錯誤恢復。

圖10 基于數據完整性校驗的容錯流程Fig.10 Fault tolerance based on integrity of data
基于數據完整性校驗的出錯標識在HSWAP工作流引擎中完成,主要是利用工作流組件的自定義配置功能,對不同的任務配置不同的數據完整性校驗策略,比如數據體量、數據結束標識監測等,當數據完整性不達標時,發出錯誤信息。日志信息會收集所有任務運行上下文信息,以便容錯模塊對錯誤進行分析定位。容錯服務根據出錯事件,基于可配置的ECA規則(如圖11所示),執行錯誤恢復邏輯,最后通過HSWAP引擎接口調用自動恢復流程執行。

圖11 錯誤恢復策略配置文件示例Fig.11 Example for fault tolerance strategy
面向單個數值模擬任務的檢查點-重啟動錯誤恢復方式在HSWAP的實現流程如圖12所示。流程執行監控、結果文件正確性校驗、重啟動參數配置和輸入文件準備、重投遞運行等一系列過程自動化執行,無須人工干預。實際使用中結合重試、重啟動兩種方式,解決了資源不穩定等問題引起的執行中斷問題。

圖12 基于檢查點-重啟動的容錯Fig.12 Fault tolerance based on checkpoint-restart
HSWAP平臺針對材料計算等領域高通量計算模式提供了特有支持,功能包括數百上千并行任務的并發投遞、監控和容錯。高通量計算模式如圖13(a)所示,一般表現為大量并發執行的相似任務,用于材料分子篩選等參數掃描類計算或大數據分析等領域。在容錯設計上,用戶可定義高通量計算出錯的判別標準,如以計算完成百分比作為失敗閾值(fail_threshold)。當高通量并發任務失敗比例(fail_ratio)超過此閾值,標識任務失敗,并重啟動失敗部分的任務計算,完成容錯恢復執行。高通量計算的失敗比例定義為式(1),其中num_all為該高通量所并發執行的所有子任務(或稱計算實例)數,num_failed為其中運行失敗的子任務數。
(1)
例如,若對某高通量計算任務,需要并發執行100次不同的通量計算(可能為不同參數運行同一軟件組件),設失敗閾值為20%,若100個計算實例中失敗數為20以下,則認為該高通量計算成功運行,不進入容錯處理;若失敗數為30,此時失敗比例大于失敗閾值,進入容錯處理過程,只需要重試或重啟動運行失敗的30個計算子任務,運行完畢重復容錯過程,直到滿足高通量計算任務的成功運行閾值標準,或者達到最大重試次數并報告錯誤信息。
HSWAP平臺針對高通量計算的容錯過程如圖13(b)所示,其中失敗閾值設為20%,每個圖標表示同一高通量計算任務在不同時刻的狀態,圖標上部表示子任務數目及狀態,藍色為正在運行,紅色為失敗,灰色為成功結束。實測結果表明容錯模塊能夠正確識別錯誤,并按要求重運行失敗的任務,滿足自動恢復運行的需求。
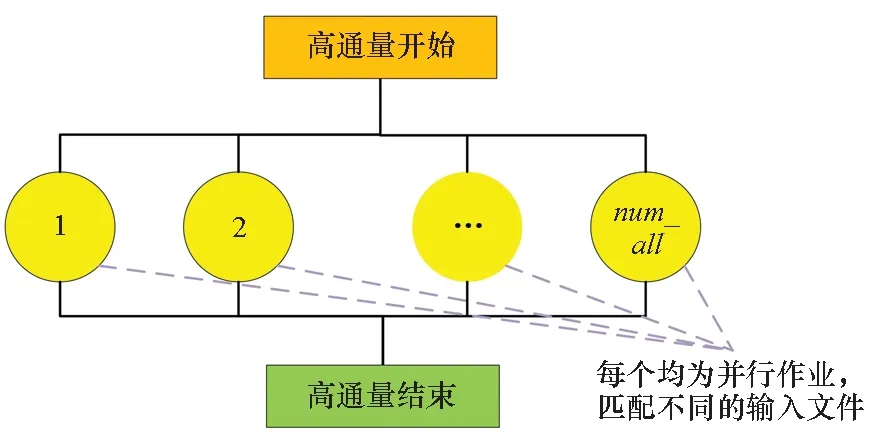
(a) 高通量計算模式(a) High throughput computing pattern
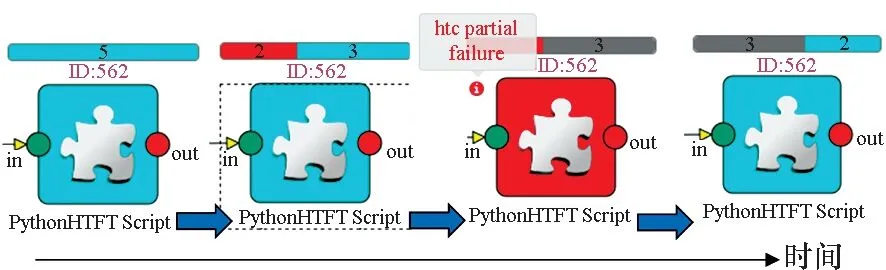
(b) 高通量計算的容錯(b) Fault tolerance of high throughput computing圖13 高通量計算及其容錯Fig.13 High throughput computing and fault tolerance
復雜超算應用具有計算規模大、運行時間長等特征,高通量計算等復雜流程也愈加普遍。由于機器故障,程序參數配置錯誤等異常造成運行中斷現象常常出現。依靠人工查看、修改配置、重新投遞作業的方式進行錯誤恢復,會嚴重影響執行效率。在某百萬億次超算平臺上,某工程項目中沖擊波計算程序的實際運行情況統計如表1所示。
表1中人工重啟動間隔是指在任務失敗后開始計時,直到人工發現錯誤并投遞作業,再次投遞排隊后繼續運行的時間。由于作業可能在深夜或凌晨中斷運行而用戶無法及時發現,加之重投作業造成再次排隊等待時間,實際應用的完成時間就會大幅增長,自動容錯技術能夠縮減人工重啟動間隔時間,顯著縮短工程仿真或其他科學研究領域的計算周期。

表1 某沖擊波計算任務的容錯效率Tab.1 Performance and fault tolerance of some shock computing software
5 結論
本文針對超算環境中工作流應用的容錯機制展開討論,調研了容錯在典型科學工作流系統的實現方式以及容錯的分類。提出了完整的容錯生命周期模型;在事件-條件-動作的處理邏輯基礎上,提出了可配置的基于決策樹的錯誤恢復模型;設計并實現了模塊化、可擴展的科學工作流系統容錯架構。本文提出的容錯模型已在自主研發的超算環境工作流管理系統HSWAP中實現。面向單個任務和高通量任務應用場景分別給出了容錯實現策略,并通過實際算例在超算平臺上驗證了容錯對于提高流程執行效率的作用。目前實現的工作流系統和容錯模塊并沒有系統軟件的權限,作為應用級系統,無須系統管理員權限就可方便部署,助力加速科研和工程實踐過程;但是未能進行超算平臺軟硬件基礎設施的健康信息探查,提供給錯誤信息分析模塊的信息還不夠全面,僅從應用的視角實現了錯誤日志分析功能。下一步的工作將包括全面探測底層軟硬件系統和應用各模塊的運行信息,給出更準確的出錯原因分析。另外,基于可靠性感知的調度方案設計以及云上容錯[16-18]也是值得深入研究的技術方向。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
