圖文融合在線民宿評論情感分析模型
2020-12-10 04:41:50李含宇宋文廣張秋娟
湖北工程學院學報 2020年6期
李含宇,宋文廣,李 婉,張秋娟
(長江大學 計算機科學學院,湖北 荊州 434023)
在共享經濟背景下,民宿的地理優勢、主題化設計、個性化服務等特色很大程度地滿足了消費者的住宿體驗和需求[1]。一方面,用戶的反饋是影響消費者決策的重要因素,另一方面,商家也能從這些反饋中獲取有價值的信息,改善不足,提升服務質量[2]。反饋信息包括用戶打分和評論,它不僅包含文字,還有圖片、視頻、音頻、網頁鏈接等,多以圖文為主。
基于文本進行情感分析來改進需求方法有很多[3],也有研究對圖片進行了情感分析[4]。文獻[5]提出跨模態一致回歸模型(Cross-modality Consistent Regression,CCR),在微調卷積神經網絡的基礎上訓練文本情感分析的段落向量模型和多模態回歸模型,使不同模態特征能夠達到一致性;文獻[6] 提出基于簡單多核學習(Simple Multiple Kernel Learning ,SimpleMKL)的情感分析方法,利用文本信息來提高通過SimpleMKL對圖像進行分類的能力,指出得到圖像分類器,可以直接預測其他未標記的圖像;文獻[7]針對單一文本或圖像的情感不明顯問題,提出了一種圖文融合媒體情感預測方法,該方法融合了圖像特征與文本特征以分析語義特征對情感預測的影響,通過分析文本情感特征和圖像情感特征之間的聯系,能夠更準確地實現對圖文融合媒體情感的預測。但在圖文融合的情感分析中,僅僅通過文本或者圖片,情感極性得不到充分挖掘。為此,筆者以用戶打分與評論表達的情感不一致的現象為出發點,考慮到評論的內容具有多樣化的特點,提出了一種基于在線民宿評論的圖文融合的情感分析方法。
1 模型設計
情感分析又稱情感分類或者意見挖掘,針對某個對象進行研究,分析其中隱含的情感狀態, 判斷用戶的態度、觀點及意見[8]。筆者研究對象為在線民宿評論內容,主要包含用戶打分、文本和圖片。其中用戶打分和評論不一致、評論與追評不一致、用戶打分和追評不一致等,具體的不一致現象如表1所示。

表1 用戶評論、打分、追評的不一致現象
筆者先對文本評論、圖像評論分別進行分析,然后再設計方法將2種模型融合,最后分別用3個模型進行預測,將得到的情感概率值與用戶打分作比較,分析3個模型的判斷不一致現象的準確率。
1.1 文本情感分析
用于文本情感分析的方法主要有基于情感詞典和基于機器學習這2種方法。基于情感詞典的情感分析方法是按照情感強度和情感傾向對詞語進行賦權,負數代表偏負面的詞語,非負數代表偏正面的詞語,正負的程度體現于數值大小,然后計算出情感分值。這種方法難度較小,但是會存在情感字典覆蓋率不全、情感分類精度低、魯棒性不理想[9]等問題,并且同一情感詞在不同的場景下表達的意思也不一樣[10]。基于機器學習的情感分析方法分為有監督和無監督2種。有監督的方法需要人工標注樣本,然后進行特征提取,再輸入到構建好的分類模型中進行訓練,最后在測試集上進行預測。無監督的方法不需要人工標注樣本,但需要加入先驗知識提升分類效果[11]。筆者采用機器學習中有監督標注樣本進行情感分類試驗,模型設計如圖1所示。
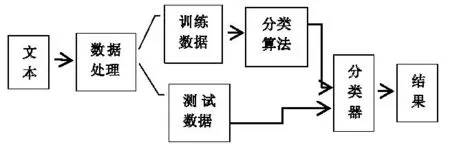
圖1 文本情感分析模型
1.2 圖片情感分析
基于卷積神經網絡建立了圖片情感分析模型,如圖2所示,模型組成及作用如下:
1) 3個卷積層:通過卷積獲取圖像的局部特征,降低參數量;
2) 2個池化層:降低緯度,提高模型訓練效率,原理就是將覆蓋區域的最大值作為主要特征輸出;
3) 2個全連接層:要求輸入必須是一維的;
4) 4個激活函數層:最后一層激活函數層是softmax層;
5) 1個Flatten層:將圖片“壓平”,將多維的輸入一維化之后進入全連接層;
6) 2個Dropout層:每次按概率隨機刪減神經元,防止過擬合。
1.3 圖文融合設計
將文本情感分類模型與圖片情感分類模型融合形成圖文融合情感分析模型。采用決策融合方法,對每個目標概率賦予權重,計算得到決策后的概率[12],具體公式如下:
P=λPt+(1-λ)Pi
(1)
式中:Pt是文本情感分析模型輸出的文本情感概率;Pi是圖片情感分析模型輸出的圖片情感概率;λ是權重,代表文本情感對最終分析結果的重要程度,通常取0.5,表示文本情感與圖像情感對最終結果的影響程度相同。各自的情感概率與權重相乘,再將乘積相加就得到模型融合后的情感概率值,情感概率值大于0.5表示是正面情感,否則就是負面情感。
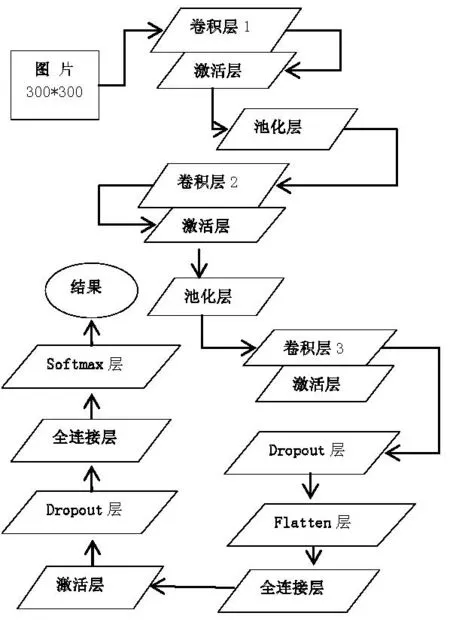
圖2 圖片情感分析模型
2 試驗與分析
2.1 數據來源
采集目標是攜程網站的在線民宿評論和美團上的榛果民宿在線評論,數據在清洗之后得到348800條評論。考慮到人工標記數據工作量巨大,項目采用了開源標注工具Doccano,該平臺支持多人合作、分配標注任務,在對文本進行了部分標注后,后臺通過學習,能自動對文本進行標注,提高標注效率。最后得到185760條正面圖文評論,163040條負面圖文評論。
由于每條評論可配多張圖,為了使圖文評論總體上達到平衡,在正面圖文評論里隨機篩選185760張圖,在負面圖文評論里隨機篩選163040張圖。
2.2 評價指標
對比分類器的分類效果,采用準確率P 、召回率 R 及F1指數作為評價指標[13]:
(2)
(3)
(4)
式中:NTP為真正例(TP,True Positive),即將好評預測為正的評論數;NFT為假正例(FT,False Positive),即將差評預測為正的評論數;NTN為真負例(TN,True Negative),即將差評預測為負的評論數;NFN為假負例(FN,False Negative),即將好評預測為負的評論數。
2.3 文本情感分類
利用機器學習方法進行文本情感分類,文本預處理階段主要包括以下步驟:
1)分詞。將句子拆分成詞語集合,首先采用jieba進行分詞,jieba分詞支持3種分詞模式(即精確模式、全模式、搜索引擎模式)[14]、繁體分詞和自定義詞典等特性,這樣,可以極大程度地滿足了中文分詞的需求。然后糾正不合理的拆分,構建領域詞典。
2)去停用詞。刪除評論中“#、¥、@、&”等對情感分析結果沒影響的特殊符號。
3)特征提取。文本情感分析就是對從文本中提取到的特征進行分析,因此提取特征非常關鍵[15]。
首先對篩選出的名詞進行詞頻統計,過濾不相關的名詞,按詞頻選取特征詞,得到評論特征詞集合{交通、位置、體驗、服務、特色、環境、設施、餐飲、價格、衛生……}。
模型的輸入是數據元組,所以要將每條數據的詞語組合轉化為一個數值向量,常見的轉化算法有:Bag of Words、TF-IDF和Word2Vec。這里選用Word2Vec[16]訓練skip-gram模型將詞轉化成向量。
通過統計高頻詞歸納出特征主題,再基于特征構建特征詞典,如表2所示。利用中心詞能找到對應的特征屬性字典,接著對其進行情感傾向識別分析[17]。

表2 特征屬性字典
4)情感分類。記錄貝葉斯、SVM、決策樹3種分類器對每個特征的準確率、召回率,結果如表3所示。貝葉斯、SVM、決策樹3種分類器的平均準確率分別為82.5%、79.8%、80.6%,其中貝葉斯分類器的準確率最高,說明更適合用該模型進行文本情感分類。
針對特征主題屬性表中的主題特征(交通、價格、體驗、服務、特色、環境、設施、餐飲),對特征提取后的文本評論進行情感分析。分別將每個特征對應的情感趨勢可視化,得到“餐飲”情感極性分布圖,通過可視化可以直觀體現每個特征的情感極性分布,如圖3所示。
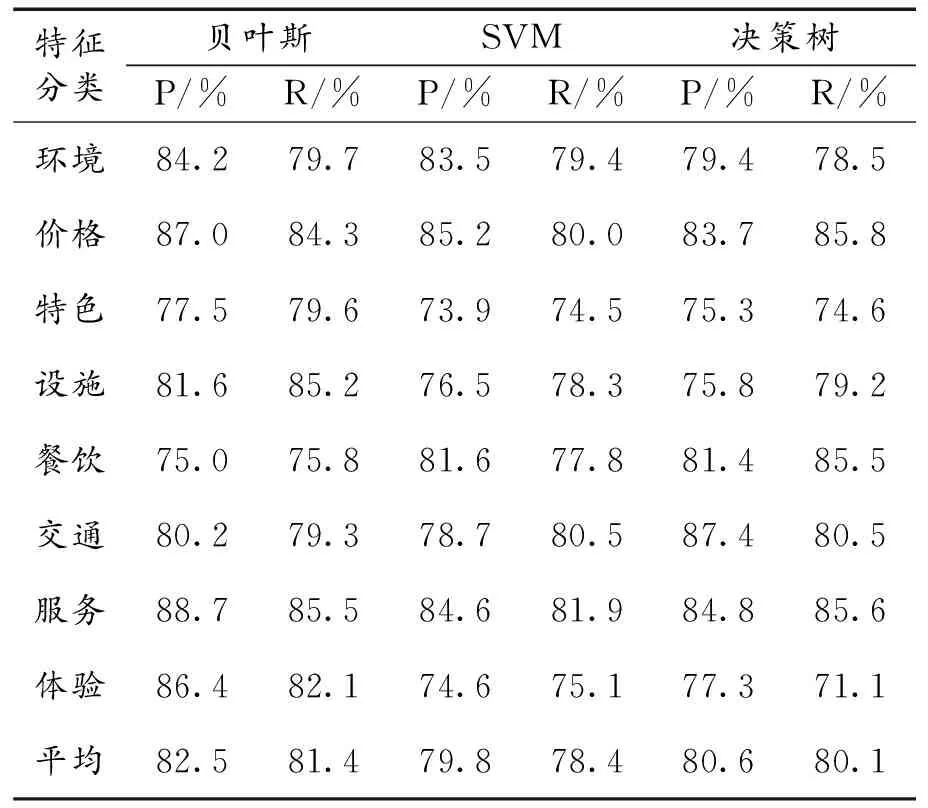
表3 不同分類器的分類效果
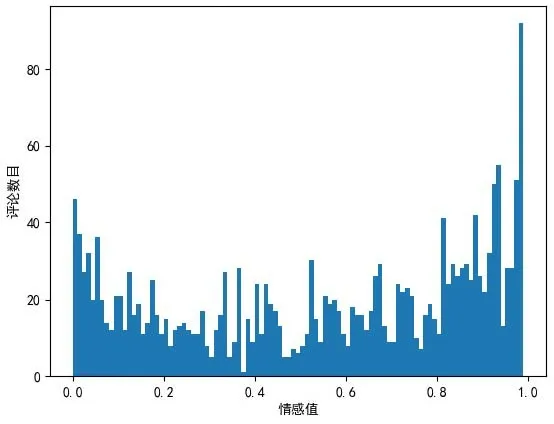
圖3 特征對應的情感趨勢分布圖
圖3中橫坐標為特征的情感得分,趨勢往右代表當前特征得分越高,評價越好;縱坐標代表當前情感得分對應的評論數量。
2.4 圖片情感分類
圖片情感分類首先要進行圖片預處理。文獻[6]的研究使用了2個數據集,分別來自Flickr網站(包含圖片和對應的文字說明)和Twitter網站,共設置了2組試驗:一組是在Flickr數據集上進行訓練,在Twitter數據集上測試;另一組是用80%的Flickr數據集進行訓練,20%用于測試。筆者用采集到的80%的數據作為訓練集,20%作為測試集,并在訓練集中預留1/4的數據為驗證集。
由于圖片情感分析模型中特征提取的關鍵在于顏色特征的提取,若消費者使用美圖軟件對圖片進行了顏色、亮度等處理,特征提取的結果將以處理后的照片為準。首先提取圖片中每個像素點的RGB參數,再將RGB參數轉換成對應的色度、飽和度和亮度,即H、S、V[18]。
H位于不同的范圍時,有不同的取值,如表4所示。
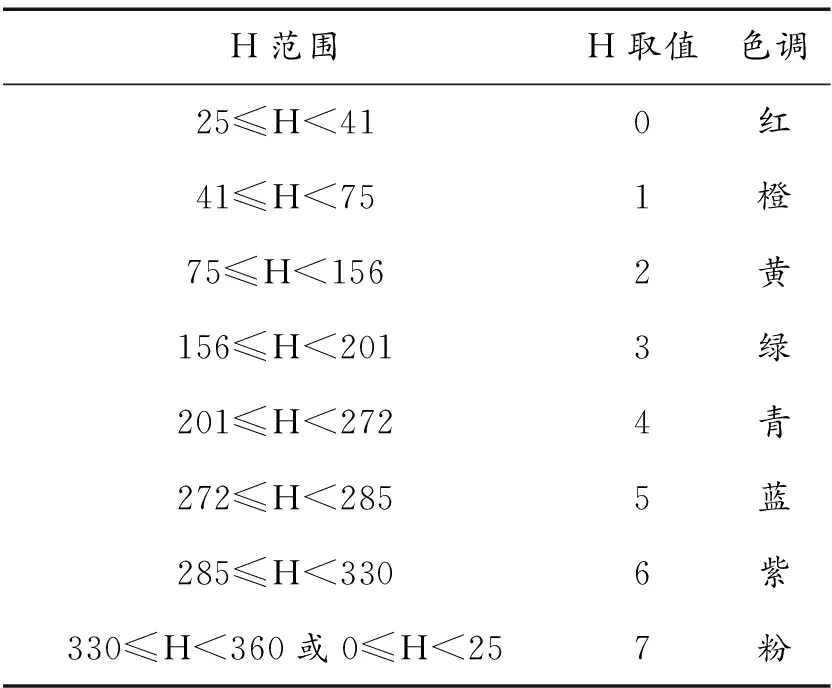
表4 H值的量化表
S經過量化之后,有2種取值:當S≤0.1時,圖像接近灰度,可以忽略H,即色度的影響;當0.1 V在經過量化之后,只有1種取值:當V<0.15時,圖像的顏色接近黑色,可以忽略H的影響;當0.15 最后根據式(5)對H、S、V值進行求和: L=H*Qs*Qv+S*Qv+V (5) 式中:Qs和Qv分別為S和V的量化級數,Qs=2,Qv=1,經過求和之后,顏色特征就可以用一個值來代表了,取值范圍是[0,15]。 基于CNN的圖片情感分類模型包括3個卷積層,每一層卷積核的個數都是32個,大小為3*3,激活函數用relu,其中第一層中border_mode設置成valid(使圖片經過卷積之后,尺寸減小);2個池化層,采用max-pooling對數據做下采樣,poolsize為(2,2);經過三層卷積和兩層池化,每張圖片處理為4*4大小;2個Dropout層,設置概率隨機將其中一些元素的值置零,剩余元素的值會被放大,防止過擬合,這里設置概率為0.5;1個Flatten層,前一層輸出的二維特征圖經過Flatten層的處理之后會被壓扁成一維的;2個全連接層,第1個全連接層指定512個神經元;一個softmax層,采用softmax激活函數;模型betch設置為4,迭代次數為20。 圖文融合在線民宿評論分析模型利用決策層融合,文本情感概率和圖片情感概率與各自的權重相乘,然后相加得到圖文融合之后的情感概率,判斷是否大于0.5,如果大于0.5,則認為是正向情感,否則為負面情感,情感分類實驗結果如圖4所示。 圖4 情感分類實驗對比結果 由圖4可知,圖文融合的情感分類模型表現出更高的準確率,這說明從整體上圖文融合在線民宿評論情感分析模型的分類效果確實比單一的文本情感分類模型、圖片情感分類模型或者用戶的打分的分類效果好,證明了筆者提出的圖文融合的情感分析方法的高效性和針對民宿評論進行分析的有效性,且圖片的存在對情感極性有較大的影響。但是從召回率分析,文本情感分類模型的召回率較高,這是因為利用機器學習有監督標記樣本的分類方法能充分提取文本評論的特征主題,能很好地識別正面情感的評論,而圖片情感分類模型的特征提取的主要在于顏色特征的提取,不能充分提取圖片特征,所以導致圖片情感分類模型和融合之后的模型的召回率都比較低。 如圖5所示,利用模型對某一家民宿的評論進行測試,選擇‘設施’主題進行分析,可以看出用戶打分為“非常滿意”,而輸出的平均情感概率值小于0.5,這與實際嚴重不符,說明用戶打分不足以作為真實有效的參考。另外,通過統計情感概率值低的主題,商家也可以知道哪些方面有待加強。 圖5 打分情感不一分布圖 以在線民宿評論為研究對象,進行圖文融合情感分析。利用機器學習方法進行文本情感分類,通過對比貝葉斯與SVM、決策樹3種方法的平均準確率,推薦貝葉斯為文本情感分類。在CNN的基礎上,訓練圖片分類模型。最后采用決策融合方法,綜合文本情感概率和圖片情感概率得到圖文情感概率,判斷情感極性,與用戶的打分作比較,能更有效地避免評論與打分不一致的問題。通過模型對比分析,得知圖文融合模型的方法具有更好的分類效果,更能挖掘到用戶的詳細意見,給出更科學合理的評分。2.5 融合模型性能分析

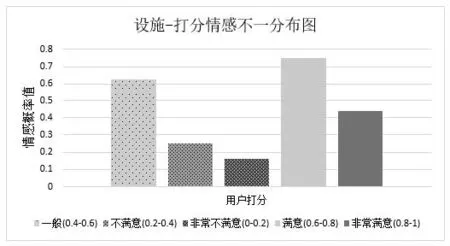
3 結語
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28制造技術與機床(2019年10期)2019-10-26 02:48:08當代陜西(2019年10期)2019-06-03 10:12:04中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32電子制作(2018年18期)2018-11-14 01:48:06中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06初中生世界·七年級(2017年9期)2017-10-13 22:27:46數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54小學教學參考(2015年20期)2016-01-15 08:44:38
