基于SPARK的大規模RDF數據上的SPARQL查詢算法
2020-12-14 09:12:44崔家奇
計算機應用與軟件 2020年12期
崔家奇 閆 威
(遼寧大學信息學院 遼寧 沈陽 110036)
0 引 言
資源描述框架(RDF)[1]是W3C提出的一種描述網絡資源的知識模型,用來表示Web中已識別的信息,利用圖模型來表示資源關系。隨著RDF數據的迅速增加,SPARQL[2]成為RDF數據的主要查詢語言。早期對RDF數據的管理主要是通過集中式系統[3-4]。隨著RDF數據集規模迅速擴大,單臺機器很難高效地存儲和查詢大規模RDF數據,因此需要使用分布式環境來提高查詢性能。
近年來,研究者們對分布式平臺上實現RDF數據的處理做了大量的研究[5-7]。其中一種基于云計算平臺的分布式RDF數據管理方法,利用現有的分布式計算平臺(Hadoop,Spark,Trinity)存儲數據以及執行SPARQL查詢,具有良好的可擴展性和容錯性。基于Hadoop平臺的主要缺點是必須將中間結果寫到磁盤,降低了查詢性能,因此基于Spark的RDF存儲查詢受到學者關注,產生了大量的研究成果[8-13]。S2RDF[10]是一種擴展垂直分區(ExtVP)的RDF數據關系分區技術,擴展了垂直分區方法以排除不必要的數據。S2RDF并不直接在Spark上運行,它將Spark查詢轉化為SQL,然后在SparkSQL上執行。SPARQLGX[11]將數據集垂直分區,三元組(s,p,o)存儲在名為p的文件中,其內容僅保留s和o。在查詢轉階段將三重模式轉換成可執行的Spark代碼,并通過優化查詢的連接順序來提高查詢效率。S2X[12]和P-Spar(k)ql[13]利用Spark 圖分析工具Graphx來回答查詢。S2X的優點是利用圖形并行和數據并行技術,但會產生大量的中間結果。P-Spar(k)ql通過圖的一些基本信息來更改SPARQL查詢的順序優化查詢。這些方法的總體目標都是通過利用數據并行化來提高查詢性能。但它們大都采用簡單的分區技術(垂直或散列分區),忽略了數據分區是高效查詢處理的關鍵性因素,影響了查詢應答的效率。
另一種基于數據劃分的分布式RDF數據管理方法[14-19]為了減少查詢處理期間的通信代價將RDF數據集進行劃分,使它們分別存儲在不同的節點上。同時每個計算節點都安裝單機的RDF數據管理系統,例如RDF-3X[3]、gStore[4]。然后將查詢圖進行劃分,每個節點并行執行子查詢,最后將子結果進行連接和合并得到最終解。這種方法可以有效地降低通信,加快查詢速度,但在數據劃分時可能會導致大量的冗余。典型的數據劃分方法是散列分區,它按照三元組主語或賓語的散列值將三元組進行劃分,將具有相同主語或賓語的三元組劃分到同一個計算節點上,被廣泛用于很多分布式RDF查詢引擎[14-15]。散列分區使得星形查詢非常容易,可以在單個分區內完成星形查詢,不需要節點間的通信,且沒有產生三元組的復制,但并不適用于復雜查詢。H-RDF-3X[16]和SHAPE[17]在劃分頂點后實現n-hop,通過復制三元組來降低節點間的通信成本,并且在執行半徑小于等于n的查詢時可以完全并行執行,而無須任何額外的通信。這兩種方法的缺點在于不能保證將頂點均勻地劃分到各分區中。文獻[18]在考慮RDF數據圖結構的同時也考慮了查詢圖結構,提出一種端到端路徑的劃分方法,執行復雜查詢時能夠減少查詢分解的子查詢數量,并通過頂點合并來減少數據冗余。文獻[19]將模式相似的實體進行聚類,在保持RDF數據語義結構的同時,也確保了各節點之間的負載均衡,并在此基礎上對查詢進行優化。該方法能夠有效地提高查詢效率,但當中間結果比較大時,需要耗費大量的通信代價。這些方法都基于Apache Hadoop上實現,查詢效率受到磁盤的讀取和寫入限制。
本文提出一種基于Apache Spark的SPARQL查詢方法。本文主要工作如下:
1)提出一種平衡的語義劃分方法,在將頂點按照URL層次結構劃分的同時考慮各分區負載的均衡性,生成n-hop語義平衡分區。
2)在查詢階段將查詢圖進行有效的分解,并優化查詢連接來減少匹配次數,提高查詢效率。
3)在Spark集群上使用合成數據集LUBM進行實驗,并與流行方法進行比較。實驗結果表明,本文方法能夠實現分區間的負載均衡,減少分區通信,加快查詢速度。
1 基本概念
定義1RDF數據圖。U、B和L(URIs、空白節點和文本信息)為任意不相交的集合,三元組(s,p,o)=(U∪B)×U×(U∪B∪L)。其中:s為主語(subject),表示現實世界的一個實體;o為賓語(object),表示一個實體或者一種概念(例如性別,家庭住址等);p為謂語(predicate),表示主語和賓語之間的關系。一個或多個三元組構成了RDF圖,實體表示圖中的頂點,謂詞表示邊。圖1為RDF數據圖示例。
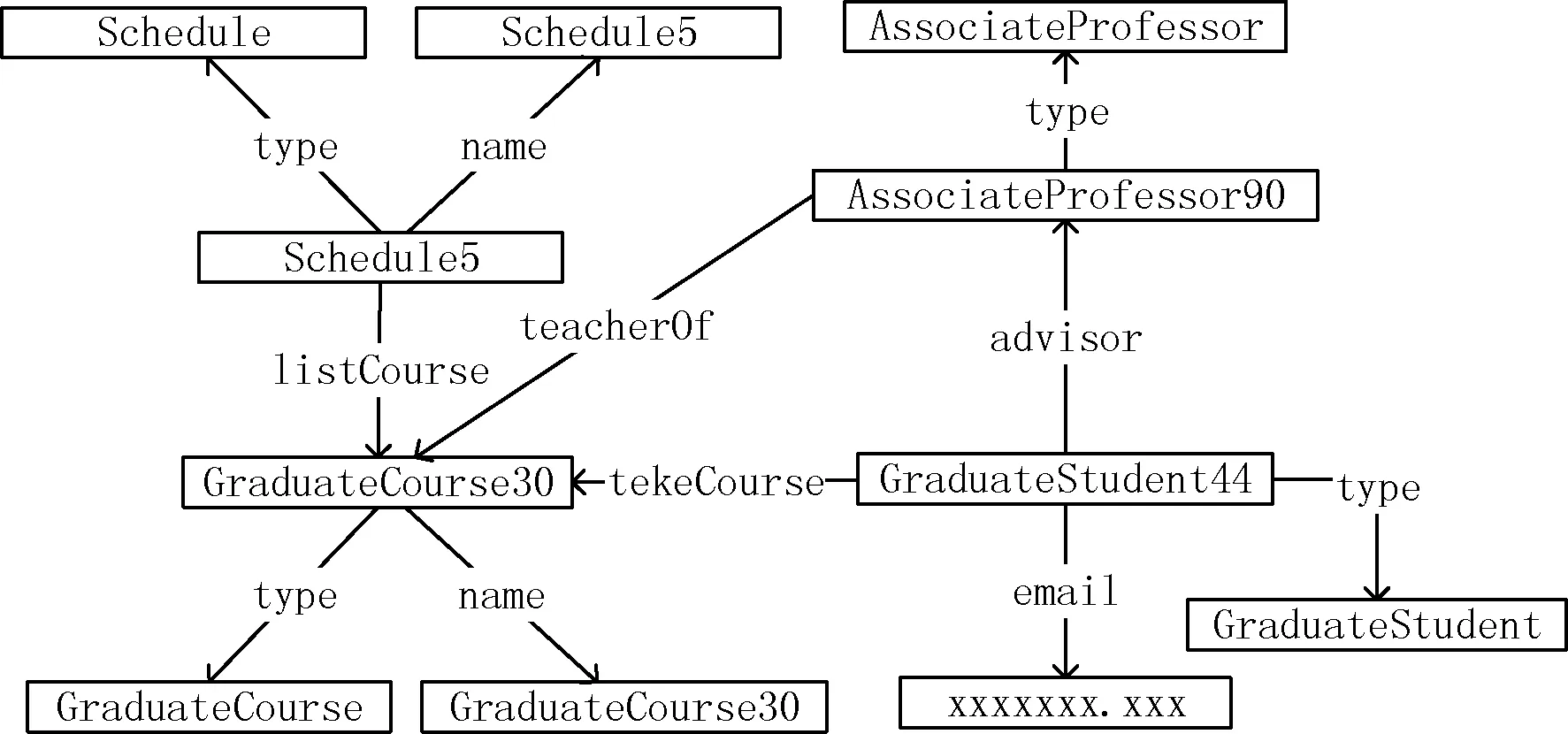
圖1 RDF數據圖
定義2SPARQL查詢。SPARQL是一種查詢和檢索RDF數據的查詢標準語言。查詢部分包括四種類型:SELECT, CONSTRUCT, ASK, DESCRIBE。SELECT是最常用的查詢,用于返回滿足設定條件的值。FROM限制數據的來源,WHERE定義包括變量的三元組模式,類似于RDF三元組結構,主語、謂語和賓語可以部分或全部替換為變量。圖2為SPARQL查詢圖。
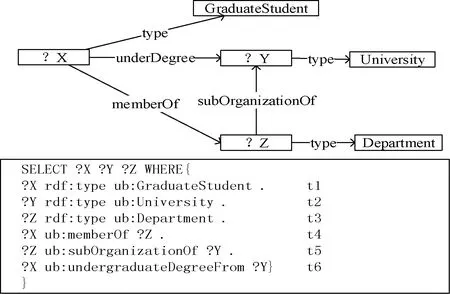
圖2 SPARQL查詢圖Q2
定義3星形結構。給定RDF圖G=(V,E,L)。星形結構表示為S=(VS,ES,LS),且VS={v}∪{vi|vi∈V,(v,vi)∈ES,1≤i≤|ES|}。LS是一組星形結構的標簽。
Apache Spark是一個專為大規模數據處理而設計的一種基于內存計算的分布式計算平臺。由于Spark基于內存計算,因此比Hadoop(基于磁盤)的計算效率更高。RDD(彈性分布式數據集)是Spark中最核心的概念,是一個分布式的、具有容錯機制的、不可變的數據集,主要包含Transformation和Action兩種類型的操作。RDD具有血統特點,當前RDD與其父RDD具有依賴關系,多個RDD之間形成有向無環圖DAG,因此具有高效率和容錯性。
2 基于散列的數據劃分方法
2.1 n-hop擴展星形結構
散列分區是按照主語的哈希值將三元組劃分,生成平衡的分區,保證星形查詢能在單個分區內完成。但對于如圖2所示的復雜查詢,在執行查詢時會將查詢圖Q2分解成三個星形結構子查詢,每個查詢子查詢會在單個分區內執行,但在子查詢執行完畢,將子查詢進行join時,會產生大量分區間通信代價,降低查詢速度。為了降低分區間的通信代價,本文實現n-hop擴展星形結構來確保n跳范圍內的查詢可以并行執行。
1-hop擴展星形結構等同于星形結構,表示分區內的每一個頂點v,通過有向邊連接的距離為1的頂點,將這組頂點與原始頂點以及它們的邊添加到分區中,如圖3(a)所示。2-hop擴展星形結構表示從1-hop擴展星形結構中的賓語開始,添加它們的1-hop擴展星形結構,如圖3(b)所示。
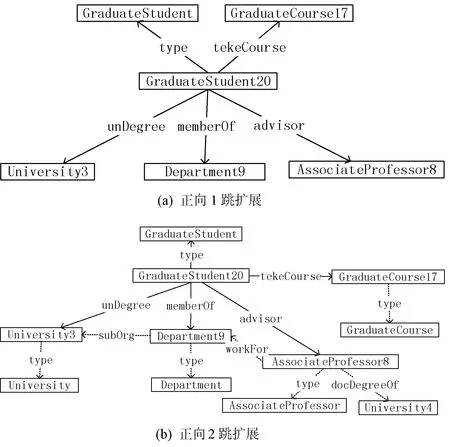
圖3 GraduateStudent20的擴展星形結構
n-hop擴展星形結構可以保證n跳范圍內的查詢可以并行執行。用2-hop后,Q2的結果可以在單個分區的內獲得,無須分區間的通信。n越大,復制的三元組數目越多,占用的存儲空間越大。實驗表明,大多數查詢都可以在2-hop擴展星形結構內完成。本文使用Spark API實現2-hop擴展星形結構,通過每個三元組的主語對其添加散列值,得到頂點的星形結構fileRDD:
val fileRDD=sc.textFile(″data.ttl″).map(x=>x.split(″ ″))
.map(t=>(t(0),t(1),(t2)))
.map(case(s,p,o)=>(s.hashCode,(s,p,o)))
之后在fileRDD的基礎上再次進行1-hop擴展得到2-hop擴展星形結構towHopRDD:
val twoHopRDD=fileRDD.map({case(k,(s,p,o))=>(o,(k,p,s))})
.join(fileRDD.map({case(k,(s1,p1,o1))=>(s1,(p1,o1))}))
.map({case(s1,((k,p,s),(p1,o1)))=>((k,(s,p,s1),(s1,p1,o1)))})
.filter({case((k,(s,p,o),(s1,p1,o1)))=>s!=s1})
.map({case(k,(s,p,o),(s1,p1,o1))=>(k,(s1,p1,o1))})
.union(fileRDD).distinct()
獲取星形結構并將其擴展為2-hop結構之后,將所有三元組劃分到不同的分區。在根據主語對每個三元組添加散列值之前,需要考慮兩個問題:1)負載均衡;2)頂點復制。數據傾斜會增加某些分區的工作負擔,嚴重影響查詢的效率。另外,頂點可能存在多個2-hop星形結構中,將具有許多公共頂點的2-hop星形結構劃分到同一個分區中,能夠有效地減少三元組的復制,節省存儲空間并減少三重模式的搜索空間,提高查詢效率。
2.2 頂點分區
文獻[11]認為URI引用通常具有路徑層次結構,將具有共同祖先的URI放在同一個分區,可以顯著減少三元組的復制量。URL的典型層次結構為“http://domainname/path1/..../pathN#fragmentId”,例如“http://www.Department17.University18.edu/FullProfessor1/Publication5”,可以獲得該URL的層次結構為edu,Unuversity,Department,FullProfessor,Publication。在層次結構的任何級別,如果共享此層次結構的不同URL的數量大于或等于分區的數量,則用從頂部到所選級別的層次結構而不是完整的URL來進行散列劃分。但當選定的層次結構的種類與分區數目相差不是非常大時可能會產生嚴重的負載不均衡。本節在三元組層次結構劃分的基礎上,通過限制每個分區的實體數目來實現各分區的負載均衡。
假設每個分區中當前實體的數量為NR,當NR≥δ時,不再往分區內劃分實體,δ為分區的數量閾值,通常設置為:
(1)
式中:NE為數據集中實體總數;NP為集群中分區個數。
先根據選定的層次結構將頂點進行分組,將每組頂點進行哈希聚類。然后按照分組依次將實體劃分到相應分區中,如果當前分區中的實體數目大于等于δ,則停止劃分。如圖4(a)所示,此時分區一和分區二中的實體數目已經達到了閾值。第一次劃分之后,將未劃分頂點按照分組劃分到未達到閾值的分區中。將u9中未劃分的實體劃分到未達到閾值的分區三中,再將u10中未劃分的實體劃分到未達到閾值的分區三中。當分區三達到閾值后,將u10中剩余實體劃分到未達到閾值的分區四中,如圖4(b)所示。在實體劃分之后實現2跳擴展星形結構,將劃分后的數據集存儲在twoHopRDD中。
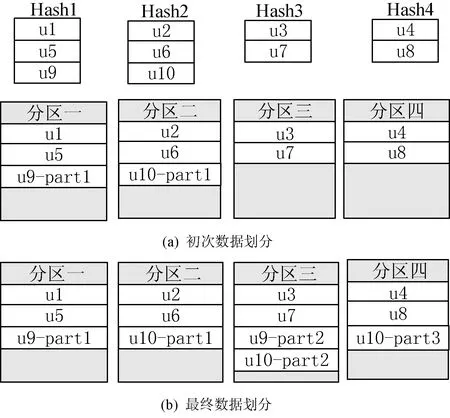
圖4 數據劃分與分布
3 查詢處理與優化
3.1 查詢分解
執行查詢操作前,需要把查詢圖Q分解成若干個子查詢Qi。每個查詢圖有多種劃分方法,為減少子查詢連接的通信代價,本文使劃分的子查詢數目最少。查詢圖Q有兩種劃分方法可以使得查詢圖僅有兩種子查詢,如圖5所示。
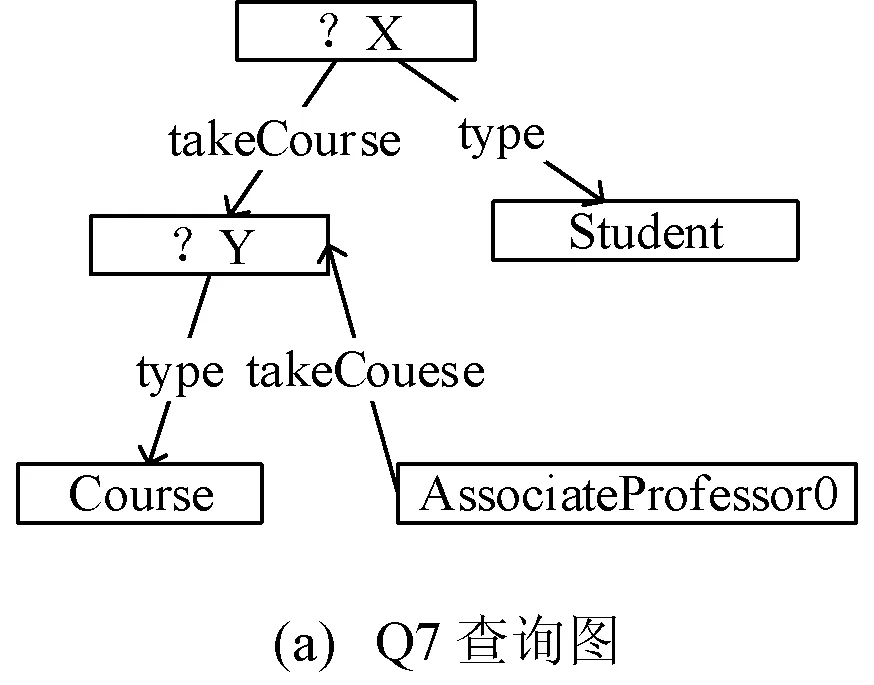
圖5 查詢圖分解
為減少子查詢連接操作的代價,需令兩個子查詢的結果數量乘積最小,即min(Num(Q1)×Num(Q2))。由于無法直接獲取每個子查詢的結果數量,本文最大化各子查詢三重模式個數的乘積φ來確定選擇的查詢分解方式:
(2)
式中:n為分解的子查詢個數;|Qi|為子查詢中三重模式的個數。圖5(b)中的子查詢三重模式的乘積φ=3×1=3,圖5(c)中的子查詢三重模式的乘積φ=2×2=4,因此本文選擇圖5(c)的分解模式。
3.2 查詢執行
每個子查詢Qi需要在每個分區內進行,得到子查詢結果之后,各子查詢間需要進行join連接,最終得到查詢圖Q在數據圖中的查詢結果。
利用filter算子實現三重模式查詢,需要遍歷每個分區內所有三元組數據。目前大多數查詢都是在已知謂詞的情況下查詢,因此為了減小查詢的搜索空間,本文創建了謂詞索引。通過謂詞來查詢結果時,可以迅速定位搜索區間。謂詞索引表如表1所示。
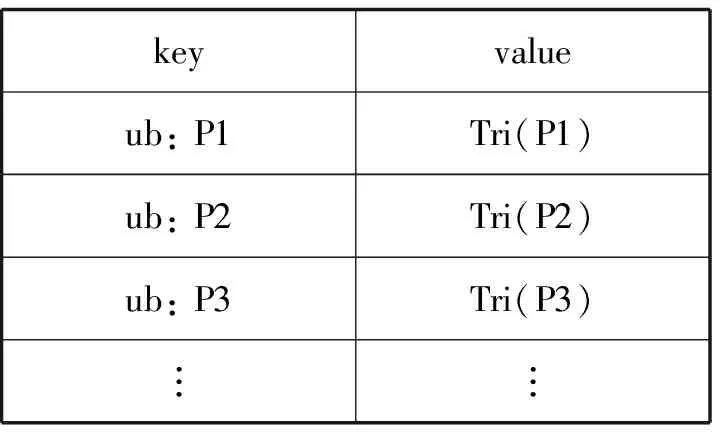
表1 謂詞索引表
如圖6所示,散列劃分將Q2分解成三個子查詢,但SSQ在分區內即可完成查詢。在執行子查詢Qi時,使用mapPartition算子對twoHopRDD中的每個分區進行操作。通過filter對每個三重模式進行查詢,將Qi中的三重模式查詢結果在分區內進行連接,避免了分區之間的通信,提高查詢效率。此外,對三重模式的查詢結果使用groupBy進行分組,能夠有效地減少連接次數,減少查詢時間。
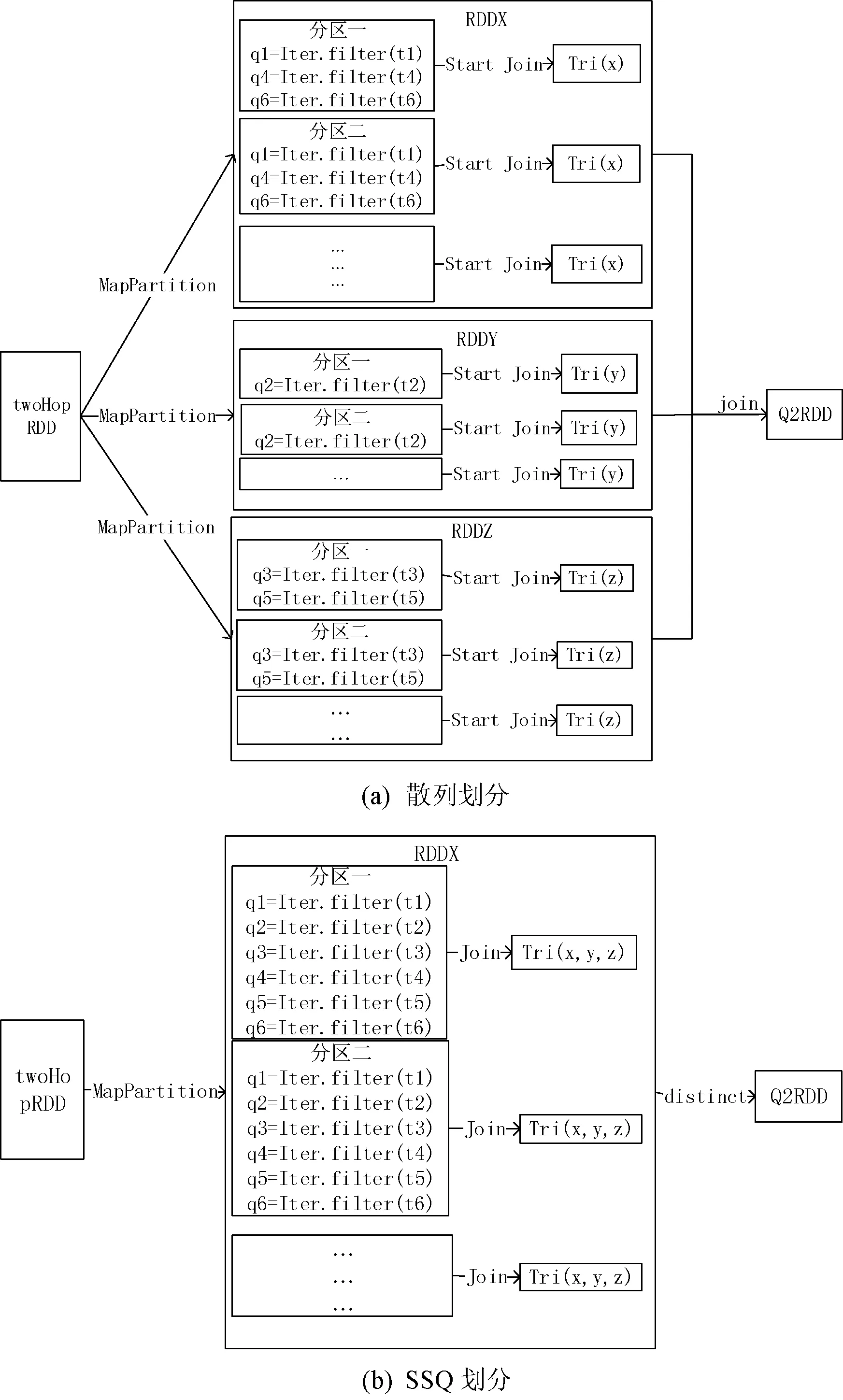
圖6 Q2查詢執行圖
三重模式連接在SPARQL查詢過程中執行代價最高,子查詢內和子查詢間的存在多種連接順序,不同的連接順序很大程度上決定了SPARQL的查詢效率。當對子查詢Qi中n個三重模式進行連接時,需要進行n-1次分區內連接操作來得到子查詢結果。不同的三重模式查詢連接順序產生不同的中間結果,中間結果的大小很大程度上影響查詢的效率。因此,本文提出了一種基于貪心選擇的優化連接方法來優化查詢。
1)通過filter對子查詢內所有三重模式進行查詢得到結果子句集SQi={Qi1,Qi2,…,Qin};
2)貪心選擇查詢相鄰的三重模式且子句集大小乘積最小的兩個子句集進行連接,得到新的子句集Qi(n+1);
3)更新查詢結果SQi。刪除連接完成的子句集并添加新的查詢子句集;
4)重復步驟2)和步驟3),直到SQi中子句集的個數為1,輸出查詢結果。
得到各子查詢后,將子查詢按照同樣的連接順序進行join連接得到最終查詢結果。
4 實 驗
4.1 實驗環境
實驗在具有5個節點的集群上進行,包含4個worker節點和1個master節點。每一個節點的CPU為雙核1.9 GHz,內存為8 GB,操作系統為CentOS7,集群環境為基于Hadoop 2.6.5上構建的Spark 2.3.0,Scala的版本為2.11.0,RDF數據被存儲在HDFS中。
實驗數據集選用目前最為常用的測試數據集LUBM。LUBM是一個以大學為本體的合成數據集,通過改變相應的參數可以得到不同大小的數據集。本文使用LUBM生成器分別生成1、10、30、50個學校。
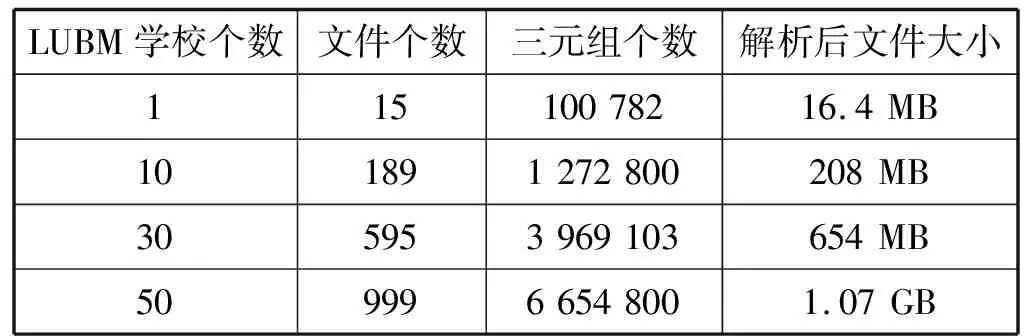
表2 LUBM數據集基本信息
4.2 性能比較
為了充分利用集群中worker節點的8個核心數,本文將數據集劃分為8個分區。分別在LUBM1、LUBM10、LUBM30、LUBM50上比較基于主語的散列劃分(Hash-s)[20]、主語散列2跳擴展星形結構(Hash-2f)、語義散列2跳擴展星形結構(SHAPE-2f)[17],以及本文基于語義平衡的2跳擴展星形結構(SSQ-2f)的分區均衡性以及數據冗余。使用SHAPE-2f和SSQ-2f劃分數據時,選定從edu到department層次結構將LUBM1進行散列劃分,edu到University層次結構將LUBM10、LUBM30、LUBM50進行散列劃分,如表3所示。其中:max(σ)和min(σ)分別表示最大分區和最小分區中三元組的個數;Ratio(ζ)表示所有分區中的三元組數量與原始數據集中的三元組數量的比率。
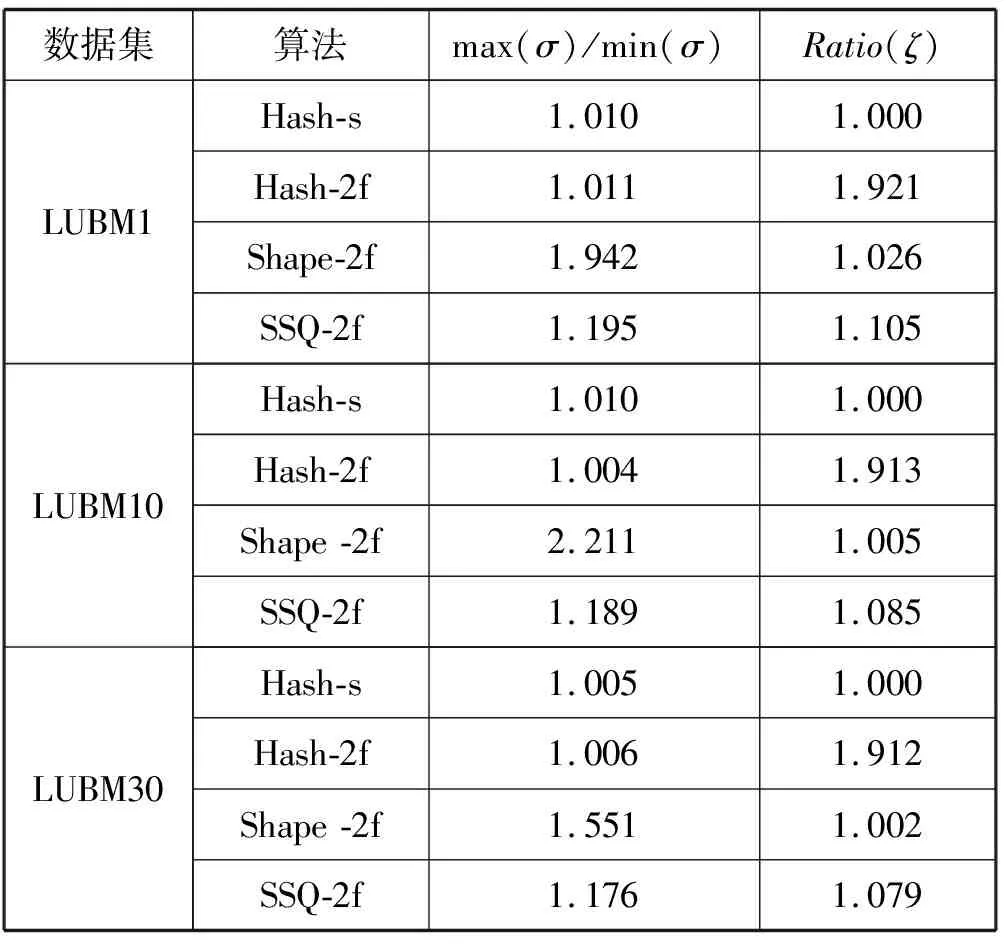
表3 分布與冗余
可以看出,Hash-s和Hash-2f數據分布平衡,但Hash-2f劃分數據后有大量三元組復制。Shape-2f將數據按照URL的部分層次結構進行散列劃分,幾乎沒有任何三元組復制,但當共享該層次結構的URL的數量和分區數目相差不是很大時,會造成嚴重的分區間負載不均衡。本文方法在按URL部分層次結構劃分的基礎上進行再次劃分,雖然會復制少量的三元組,但在具有不同學校數量的LUBM數據集下各分區的三元組數目都相對均衡。
4.3 查詢評估
本節在LUBM30上比較Hash-s、Hash-2f、Shape-2f、SSQ-2f的查詢性能。Shape-2f是基于Hadoop的分布式RDF數據管理系統,為了獲得公平的實驗結果,使用Scala API重寫相關分區算法。本文使用LUBM提供的基準查詢,將查詢分為星形查詢和復雜查詢。不同查詢的處理時間如圖7所示。
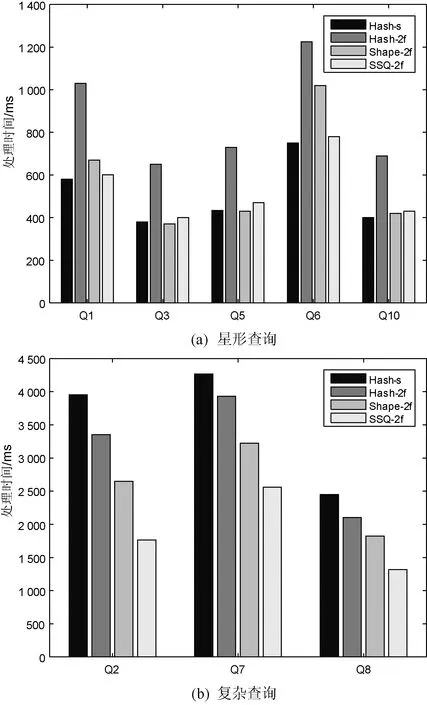
圖7 不同查詢的處理時間
圖7(a)顯示了不同方法針對星形查詢Q1、Q3、Q5、Q6、Q10的查詢性能。可以看出,SSQ-2f與Hash-s對于星形查詢效果最佳,因為星形查詢可以在單個分區內并行執行,且兩種劃分方法分區劃分均衡,僅有少數的復制量或沒有任何復制。Hash-2f具有大量的三元組復制,Shape-2f劃分后的分區不均衡,都導致查詢的效率將低。
圖7(b)顯示了不同方法針對復雜查詢Q2、Q7、Q8的查詢性能。Hash-s在執行復雜查詢時,需要將查詢分為若干個子查詢,涉及到分區間的通信。Hash-2f、Shape-2f以及SSQ-2f可以在單個分區(Q2,Q8)或兩個分區(Q7)內執行查詢,很大程度上減少了分區間的通信。SSQ-2f分布均衡,數據冗余小,并且對查詢處理進行優化,因此對于復雜查詢SSQ-2f效率最好。
4.4 可擴展性評估
本節使用Q1、Q2、Q7三個查詢來驗證SSQ-2f的可擴展性。分別改變LUBM數據集的大小以及分區個數來驗證該方法的可擴展性,如圖8所示。由圖8(a)可見,隨著數據集的增大,每個分區的工作量增加,查詢時間呈線性遞增。圖8(b)表明隨著分區數的增加,查詢的并行度增加,Q1和Q2的執行效率不斷提高。但由于Q7不能在單個分區內完成,因此各分區的通信開銷也不斷增加,導致Q7的執行時間先減少后增加。
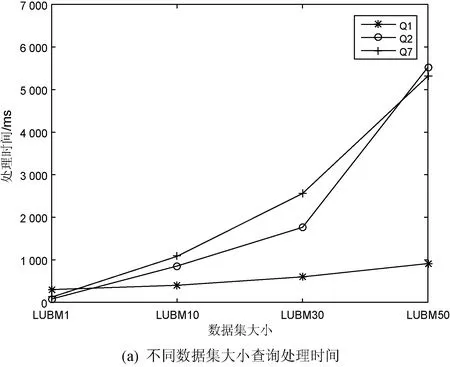
圖8 可擴展性驗證
5 結 語
本文提出一個基于Spark的RDF數據劃分方法SSQ,將SPARQL查詢轉化為Spark分布式平臺計算框架上的RDD操作。該方法在散列分區的基礎上復制必要的三元組來使得查詢可以在單個分區或者少量的分區內并行執行,減少分區間的通信。利用URL的層次結構劃分的基礎上實現再劃分,不僅降低了三元組的復制率,同時實現分區均衡。對查詢進行劃分,使每個子查詢可以在單個分區執行,并優化子查詢內和子查詢間的連接順序來減少匹配次數,提高查詢的執行效率。實驗結果表明,本文算法在查詢效率上具有明顯優勢并且具有良好的可擴展性。
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
甘肅教育(2020年14期)2020-09-11 07:57:42
中華詩詞(2019年7期)2019-11-25 01:43:04
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
時代英語·高二(2015年1期)2015-03-16 00:08:11
現代企業(2015年9期)2015-02-28 18:56:50
中國衛生(2014年11期)2014-11-12 13:11:32
