一種基于k近鄰的密度峰值聚類算法
2020-12-24 08:01:42羅軍鋒鎖志海郭倩
軟件 2020年7期
關鍵詞:實驗
羅軍鋒 鎖志海 郭倩

摘? 要: 密度峰值聚類算法(DPC算法)雖然具有簡單高效的優點,但存在著需要人為確定截斷距離的不足,從而造成聚類結果出現不準確。為解決這一問題,本文提出了一種基于K近鄰的改進算法。該算法引入信息熵,采用屬性加權的距離公式進行聚類,這樣就解決了不同屬性的權重影響問題;在聚類過程中通過計算數據點的近鄰密度,再利用KNN近鄰算法實現自動求解截斷距離,據此得到聚類中心再進行聚類,通過實驗證明,該算法在準確性、運行效率上均有不同程度的提升。
關鍵詞: 聚類;密度峰值;局部密度;聚類中心;信息熵;K近鄰;截斷距離;相對距離
中圖分類號: TP311 ???文獻標識碼: A??? DOI:10.3969/j.issn.1003-6970.2020.07.037
本文著錄格式:羅軍鋒,鎖志海,郭倩. 一種基于k近鄰的密度峰值聚類算法[J]. 軟件,2020,41(07):185-188
A Peak Density Clustering Algorithm Based on K-nearest Neighbor
LUO Jun-feng, SUO Zhi-hai, GOU Qian*
(Net&Information center, xian jiaotong University, Xian 710049, China)
【Abstract】: Although DPC algorithm is simple and efficient, it needs to determine the truncation distance manually, which results in inaccurate clustering results. To solve this problem, an improved algorithm based on K-nearest neighbor is proposed. In this algorithm, information entropy is introduced, and attribute weighted distance formula is used to cluster, which solves the problem of weight influence of different attributes. In the process of clustering, the nearest neighbor density of data points is calculated, and then KNN algorithm is used to automatically solve the truncation distance, and then clustering is obtaine.
【Key words】: Clustering; Density peak; Local density; Clustering center; Information entropy; K-nearest-neighbor; Truncation distance; Relative distance
0? 引言
聚類是數據挖掘中重要的課題之一。它是將目標數據對象分組為由類似的對象組成的多個族的過程。其目標是同一個族的對象是最大可能的相似,不同族的對象最大可能的不相似。
2014年6月,ARodriguez 和Laio等提出了一種新型密度峰值聚類算法(Density Peaks Clustering,DPC)[1],這個算法的主要優勢在于其的算法簡單又高效、所需參數少、能解決各種形狀的簇聚合等。因此該算法得到研究者廣泛關注,已經在多個領域 得到成功應用,但DPC算法還存在某些缺點:如需要人工輸入截斷距離、需要依據決策圖人工選取聚類中心這兩個關鍵不足。
針對DPC算法的改進,研究者提出了許多的改進方法:賈培靈等[2]針對某個類存在多個密度峰值導致聚類不理想問題,提出一種基于簇邊界劃分的 DPC 算法,來解決多個密度峰值問題導致的聚類不理想問題;薛小娜等[3]提出了結合k近鄰來改進密度峰值聚類算法;WangSL等[4]提出了一種利用數據場的潛在熵來自動提取最優值的新方法;Mehmood R等[5]提出了一種采用非參數估計給定數據集的概率分布,對截斷距離的選擇進行校正。
目前,DPC算法研究雖取得了一定的成效,但截斷距離需要人工輸入、簇心選取及未分配點分配準確率仍然不高,針對這些問題,因此本文提出一種基于K近鄰的密度峰值聚類算法,引入距離信息熵,自動計算截斷距離,優化了聚類中心點的選擇算法. 通過實驗證明,該算法具有更好的聚類效果和聚類準確率.
1 ?DPC算法
密度峰值聚類算法[6-11]是基于以下兩個重要原理:(1)其聚類中心的密度高于其鄰近的樣本點密度;(2)聚類中心與比其密度高的數據點的距離相對較遠。
DPC算法的具體步驟描述如下:
步驟1 根據上述公式和輸入的參數截斷距離分別計算所有數據點的局部密度和相對距離;生成關系決策圖;
步驟2 根據關系決策圖手動選取聚類中心點。
步驟3 將其他數據點按照距離最近原則分配到對應的聚類中心點。。
步驟4 對聚類結果進行除噪處理,最后完成聚類。
從上述算法描述中可以看到,參數![]() 對算法的聚類效果影響很大,同時算法在聚類過程中,沒有考慮到數據點屬性間的權重問題,這樣會造成聚類效果出現偏差,本文就是試圖改進DPC算法中的距離公式,同時引入基于k近鄰的
對算法的聚類效果影響很大,同時算法在聚類過程中,沒有考慮到數據點屬性間的權重問題,這樣會造成聚類效果出現偏差,本文就是試圖改進DPC算法中的距離公式,同時引入基于k近鄰的![]() 的計算方法,以達到改善聚類效果的目的。
的計算方法,以達到改善聚類效果的目的。
2? 基于K近鄰的密度峰值聚類算法(KDPC)
本文針對DPC算法的改進主要包括:引入距離熵,改善距離計算公式;借鑒文獻[11]中的思想引入K近鄰,來計算截斷距離。下面從算法的基本概念,思想,步驟等分別加以描述。
2.1? 算法基本概念
定義1 對象p的k距離
對于任意一個正整數k,數據對象p的k距離我們記作k-distance (p).
在數據集D中, 數據對象o距離數據對象p之間的距離,我們記為:d(p,o)。
當同時滿足以下條件時,k-dist(p)等于d(p,o):
(1)至少存在k個數據對象滿足
(2)至多存在k-1個數據對象滿足
定義2 對象p的k近鄰鄰居
如果已知數據對象p的k距離,那么,數據對象p的k近鄰鄰居則就為數據集中所有到p的距離小于等于k的數據對象的集合,定義如下:![]()
![]()
定義3 對象p關于對象o的近鄰距離
假設d(p,o)表示數據對象d和數據對象o之間的距離,那么對象p關于對象o的近鄰距離計表示為:
定義4基于k近鄰的截斷距離如下:
2.2 ?算法的思想
首先為提高算法聚類的效果,我們對數據集中計算數據對象距離時采用加權距離,權重值的計算使用信息熵來確定。
其次,我們引入K近鄰以此來計選截斷距離,以防止認為指定的不足。
下面是算法的詳細介紹。
一般來說,數據集中的各維屬性對聚類結果的影響程度肯定不同。于是,本文借鑒文獻[12],引入信息熵的概念以度量屬性權重的大小,并進一步求得數據對象之間的權重系數,最終得到基于熵權重的距離計算公式。
具體步驟如下:
(1)假設某個數據集X有以下屬性值矩陣,不失一般性,其具有n個對象,m維屬性:
(2)構造屬性對應的比重矩陣
由于屬性值單位的不同無法直接比較,為了方便比較,我們對屬性值進行了歸一化處理。處理方法如下:
從上述公式中可以得出,相鄰數據對象的權重系數取決于該對象的所有屬性,由其所有鄰居的屬性共同決定的,因此,在接下來計算數據對象間的距離時就盡最大可能、最大限度的考慮了相鄰數據對象之間的相互影響及其自身所有屬性的影響。
根據以上分析,最終不難得出,基于信息熵的加權距離計算公式為:
利用改進的距離計算公式可以更為準確的計算出各個數據對象之間的差距程度,在一定程度上提高了聚類的精確度。
2.3 ?算法步驟
改進后的算法分三大步驟:
(1)根據公式3的加權距離公式來計算所有數據點的近鄰密度距離矩陣;
(2)根據公式1計算截斷距離;
(3)計算局部密度![]() 和相對距離,同時進行歸一化處理后生成關系決策圖;
和相對距離,同時進行歸一化處理后生成關系決策圖;
(4)確定聚類中心數量及聚類中心;
(5)按密度的降序對其余數據點進行分配。
3? 實驗結果與分析
為了驗證本算法的性能,我們分別在人工數據集和UCI數據集上進行了對比實驗。
3.1 ?人工數據集實驗結果分析
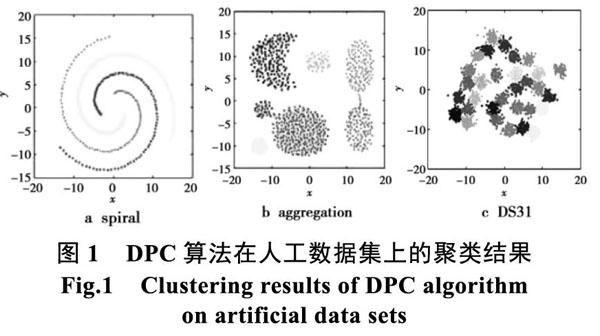
在我們的仿真實驗中,使用的數據集為如表1所示,實驗的最終效果如圖1所示。
圖1為DPC算法在人工數據集上的聚類結果,圖2為KDPC 算法在人工數據集上的聚類結果。從結果上看,DPC 算法要得到理想狀態下的聚類結果,需要人工的多次嘗試,這是因為截斷距離的合適與否直接影響聚類的效果,因此算法不夠穩定。而KDPC算法,自動解決截斷距離的計算問題,能夠較快的得到理想的聚類效果。
上述實驗證明, KDPC算法避免了 DPC 算法需要手動經驗選取合適的截斷距離的不足, 能夠更準確地選取數據集的聚類中心。
3.2 ?UCI數據集實驗結果分析
實驗二選取UCI機器學習數據庫中的Test,Wine,Seeds作為實驗數據。
實驗方法:分別采用DPC算法,本文算法進行實驗。
實驗指標:采用調整蘭德系數(adjusted rand index)ARI聚類評價指標[13-14],該指標結果值在[-1,1]之間,值越大說明聚類效果越好,其計算公式為:
3.3? RI表示蘭德系數
實驗結果:由于傳統的k-means算法對初始點的選取比較敏感,初始聚類中心的隨機性導致聚類準確率不穩定,因此采用運算8次后所求的平均準確率來判斷,實驗結果的精確度如表2所示。
從表中可以看到,改進后的DPC算法準確度比傳統算法提高了接近10個百分點。
4 ?結束語
本文針對DPC算法的不足,引入信息熵,采用屬性加權的距離公式進行聚類,這樣就解決了不同屬性的權重影響問題;在聚類過程中通過計算數據點的近鄰密度,再利用KNN近鄰算法實現自動求解截斷距離,據此得到聚類中心再進行聚類,通過實驗證明,該算法在準確性、運行效率上均有不同程度的提升。
參考文獻
-
Rodriguez A, Laio A. Clustering by fast search and find of density peaks[J]. Science, 2014, 344(6191): 492-1496.
-
賈培靈, 樊建聰, 彭延軍. 一種基于簇邊界的密度峰值點快速搜索聚類算法[J]. 南京大學學報(自然科學), 2017, 53(2): 368-377 .
-
薛小娜, 高淑萍, 彭弘銘, 等. 結合K近鄰的改進密度峰值聚類算法[J]. 計算機工程與應用, 2018, 54(7): 36-43.
-
Wang S L, Wang D K, Li CY et al. Clustering by fast search and find of density peaks with data field[J]. chinese Journal of Elec-tronics, 2015, 25(3): 397-402.
-
Mehmood R, Bie R, Dawood H, et al. Fuzzy clustering by fast search and find of density peaks[C]//International Conference on Identification, Information and Knowledge in the Internet of Things( IIKI), Beijing, China, 2016: 258-261.
-
趙燕偉, 朱芬, 桂方志, 等. 融合可拓關聯函數的密度峰值聚類算法[J]. 小型微型計算機系統, 2019, 12(12): 2512-2518.
-
丁志成, 葛洪偉, 周競. 基于KL散度的密度峰值聚類算法[J]. 重慶郵電大學學報, 2019, 31(3): 367-374.
-
王萬良, 吳菲, 呂闖。自動確定聚類中心的快速搜索和發現密度峰值的聚類算法[J]. 模式識別與人工智能, 2019, 32(11): 1032-1041.
-
王軍華, 李建軍, 李俊山, 等. 自適應快速搜索密度峰值聚類算法[J]. 計算機工程與應用. 2019, 55(24): 122-127.
-
王洋, 張桂珠. 自動確定聚類中心的密度峰值算法[J]. 計算機工程與應用, 2018, 54(8): 137-142.
-
伏坤, 王珣, 劉勇, 等. 基于K近鄰改進密度峰值聚類分析法的巖體結構面產狀優勢分組[J]. 水利水電技術, 2019, 50(11): 124-130.
-
唐波. 改進的K-means 聚類算法及應用[J]. 軟件, 2012, 3: 036.
-
Vinh N X.Epps J.Bailey J.Information theoretic measures for? clusterings comparison: Is a correction for chance necessary[C]// Proc of the 26th Annual International Conference on Machine Learning. New York: ACM Press, 2009: 1073-1080.
-
Vinh N X.Epps J, Bailey J.Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance[J]. Journal of Machine Learning Research, 2010, 11(1): 2837-2854.
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
