一種基于蟻群算法的智能水上機器人的簡單仿真實現
2020-12-28 01:46:38李光輝郭銳田瑤瑤
現代計算機 2020年31期
關鍵詞:效率
李光輝,郭銳,田瑤瑤
(中南民族大學計算機科學學院,武漢430074)
0 引言
如今各種垃圾長期在水面堆積,嚴重影響水環境。于是如何進行水質監控和垃圾清理便是一個不得不解決的問題。
目前國內的水面垃圾處理措施大多為人工打撈,此種方式效率低成本高危險大,為解決以上問題,目前不少學者提出了各種水面垃圾清理系統[1-5]。綜合起來看,前人在船體構造、框架設計等方面已有較好解決方案,在一定程度上解決了小型水域的垃圾打撈問題。但是也存在著需要人工操控、巡航方式過于耗能等尚未解決的問題。
因此,在前人的研究基礎上,我們對智能水上機器人的巡航方式進行優化。通過歷史數據選取遍歷點,再使用蟻群算法[6-7]規劃機器人航行的最優路徑,在保證清潔能力的前提下減少了航行里程數,使其更加智能化。在很大程度上減少了的航行里程,使機器人更高效節能,在一定程度上解決了前人學者在此機器人研發上未解決的問題。
1 模型建立與效率計算
首先設置水上機器人的航行環境為二維平面模型,采用柵格法建模[8](圖1),避障方面由硬件實現,本文算法航行的水面為理想化的無通行障礙水面。每個單元格為水上機器人可探測垃圾的范圍。每個單元格的狀態分為三種:①環境檢測取樣點;②有垃圾點;③無垃圾點。在機器人航行過程中,垃圾產生后忽略其在水面的微小漂移。

圖1 湖面建模
在本文研究中,將單元格地圖劃分為A×A網格單元,假定每個柵格的單位長度為a(2 倍機器人掃描半徑),機器人走過一個柵格它的移動步數step加1。垃圾只會產生在柵格中,且機器人經過該柵格時會撿到垃圾,撿垃圾不增加額外步數。
假設起點在(0,0)處,則一趟全圖遍歷的移動步數:

我們設定在每次航行前產生垃圾數為n,垃圾產生范圍當然在我們規定的地圖中。我們定義一個A×A的垃圾矩陣garbage_map,通過函數garbage_input(x,n)在該矩陣中產生垃圾。有一個環境因子比較重要,那就是垃圾集中區面積與總面積之比θ1。所謂垃圾集中區,就是垃圾產生概率較大的區域。另一個重要的參數就是垃圾集中區垃圾產生數與非垃圾集中區垃圾產生數比例θ2。這兩個參數對本文算法的性能具有較大的影響,后續會對其進行分析。
我們定義撿到垃圾占比garbage_picked_ratio(記為γ1)和有效比例great_ratio(記為γ2)。其中,撿到垃圾占比為算法運行結束后撿到的垃圾占投放垃圾的比例,而有效比例則等于航行中撿到垃圾的步數占總步數的比例,后續將用于衡量算法效率的指標。假設采樣點為m,垃圾數為n,則一趟全圖遍歷的有效比例為:
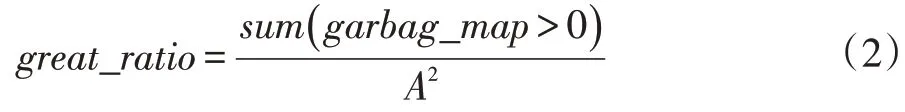
其中,sum()為Python 函數,意在統計地圖中有垃圾的點數。
2 基于蟻群算法的學習遍歷算法
2.1 蟻群算法
蟻群算法作為一種自組織群體智能優化算法,正反饋機理與較強的魯棒性使其在求解組合優化問題中得到廣泛地應用[9-10],相比于其他的路徑規劃算法[11-12],蟻群算法的啟發式的概率搜索方式不容易陷入局部最優,易于尋找到全局最優解[13]。其他傳統的非進化型算法如模擬退火算法[14],會出現結果屬于局部最優解而非全局最優解的情況,相比之下蟻群算法就不會出現此類情況,也就避免了其他算法中可能出現的搜索能力變差的情況。
蟻群算法模擬自然界中真實螞蟻的覓食行為,尋找一條從蟻巢(起始點)到食物源(終止點)的最短路徑。在尋找食物的過程中,螞蟻會在其行走路徑上釋放信息素,并根據信息素濃度大小決定下一步路徑方向。由于螞蟻傾向于選擇信息素更強的路徑,若某一路徑上螞蟻所釋放的信息素越多,則螞蟻選擇該路徑的可能性會越大。螞蟻在覓食過程中根據當前節點與下一節點的距離及信息素濃度來決定下一節點的轉移概率為:
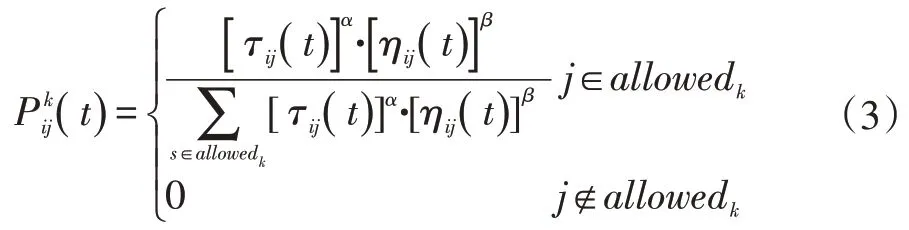
上式中:τij(t)為路徑ij上的信息素濃度,ηij(t)為與路徑ij相關的啟發式信息,α為信息素濃度啟發因子,β為能見度啟發因子,allowedk中包含螞蟻k 尚未訪問過的節點。

式(4)中:εij為節點i與下一節點j之間的歐氏距離,若兩節點間的歐氏距離越短,則所對應能見度啟發函數值越大,對應轉移概率也越大。
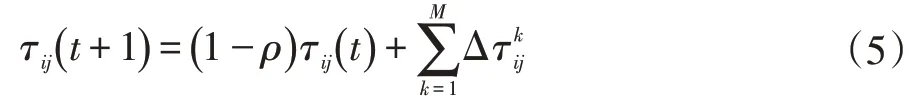
式(5)為所有螞蟻完成一次迭代后,信息素更新方式。式中:ρ為信息素揮發系數,其值越大信息素揮發得越快,M為螞蟻總數,τij(t+1)為第t+1 次迭代時路徑ij上的信息素濃度,為本次迭代中螞蟻k留在路徑ij的信息素。

式(6)中:Lk為螞蟻k 完成路徑搜索后行走的總長度;Q為一常數,表示螞蟻攜帶的信息素濃度因子。
2.2 遍歷點選取算法
使用蟻群算法對遍歷點進行遍歷是再好不過。本文算法的另一個重點是確定遍歷點,使得用蟻群算法對這些點進行遍歷時撿到的垃圾數較多,同時有效比例也較大。遍歷點由三種點組成:①水質檢測點;②垃圾集中點;③隨機垃圾點。其中,水質檢測點是用于水質取樣檢測的,是已知點。垃圾集中點是指該湖面區域內產生垃圾較為頻繁的點,隨機垃圾點則是小概率有垃圾的點。后兩種點是未知的。
本文是這樣來確定后兩種遍歷點的。初始化一個記憶矩陣Memory_map,其大小依然為A×A,初始化值為0。在一個陌生湖泊環境中進行工作時,機器人在前K次工作時會對湖面進行全圖遍歷,根據在某點是否撿到垃圾來更改Memory_map的權值。若該區域撿到垃圾,該點權值加μ,若沒有撿到,權值減去η。則根據實際情況,前K次運行完畢后的矩陣值進行如下更改:
假設撿到垃圾的次數為l1,未撿到為l2。
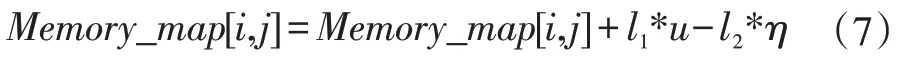
前K次運行過后,若某點的記憶矩陣值大于預選閾值γ,則將其選入垃圾集中點。之后,通過對Memory_map[i,j]進行排序,選擇其中前k 大的加入隨機垃圾點。以上三種點通過蟻群算法規劃路徑后進行下一次遍歷。
假設本文算法撿到垃圾的移動步數為get_num,其總的移動步數假設為step_2,則其有效比例為:

雖然無法確定其值,但我們可以知道他們與各種參數的關系:
(1)預選閾值γ與k共同決定了遍歷點個數t_num,在一定范圍內,get_num隨著t_num增大而增大,而step_2 也會隨著t_num增大而增大,且在一定范圍內,step_2 增大速率大于t_num。
(2)垃圾集中區垃圾產生數與非垃圾集中區垃圾產生數比例θ2。其他參數設置合理的情況下,get_num隨著θ2增大而增大,step_2 隨著θ2增大而減小。
2.3 算法流程
基于本文提出的算法的機器人路徑規劃步驟如下:
步驟1 初始化蟻群算法中的所有參數,設置螞蟻個數M,最大迭代次數N,起終點位置S等。
步驟2 初始化遍歷算法參數:全圖遍歷次數K,正反饋權值μ,負反饋權值η,以及預選閾值γ等。
步驟3 進行K次全圖遍歷。更改Memory_map的值
步驟4 根據Memory_map的值以及遍歷點數量k和環境監測點確定遍歷點,使用蟻群算法進行路徑規劃,然后進行遍歷,遍歷過程中再次更新Memory_map的值。
步驟5 判斷是否達到最大運行次數,若是則輸出運行結果,否則轉向步驟4。
2.4 算法效果展示
如圖2 所示為某一次初始化的湖面,其中帶斜杠的陰影部分代表以該點為內心的正方形區域內存在垃圾(包括新產生的垃圾和上次未清理干凈的垃圾)。圖3 為本文算法在圖2 基礎上規劃的路徑(此前算法在該湖面的運行次數已足夠充分),圓點為算法產生的遍歷點,連線部分為路徑,在路線上的垃圾已被打撈。

圖2 初始化的湖面
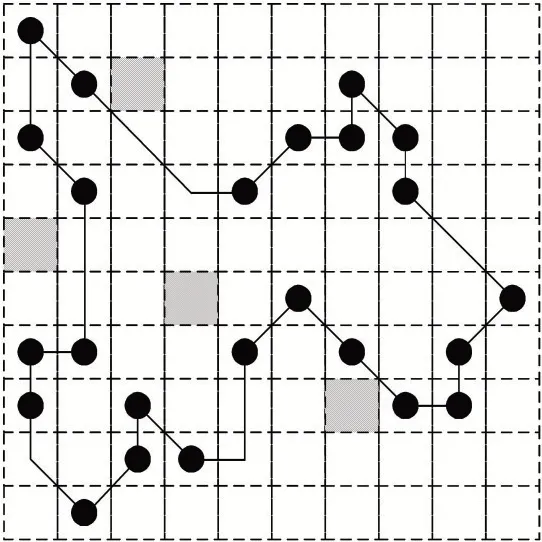
圖3 某一次垃圾打撈路線
3 實驗結果與分析
為了驗證學習遍歷算法的可行性與有效性,本文設定的垃圾分布在全局靜態10×10 的單元格中。在參數與環境完全相同的情況下,利用Python 分別對全圖遍歷方法,本文算法進行仿真對比分析。
由于本文算法受垃圾集中區面積與總面積之比θ1,垃圾集中區垃圾產生數與非垃圾集中區垃圾產生數比例θ2影響,故先得到該算法在不同環境因子下的效率后再選擇不同因子下的各個效率與全圖遍歷效率相對比。
其中,蟻群算法的參數為:螞蟻規模M=50;最大迭代次數N=150;信息素啟發因子α=1;期望啟發因子β=5;信息素增加強度系數Q=2000;信息素蒸發系數ρ=0.1 ;本文算法中全圖遍歷趟數K=0.9×travel_time,閾值γ=c_num+5,正反饋權值μ=4,負反饋權值η=2。其他參數通過控制變量法來觀察其對本文算法各個效率的影響。
根據算法在不同參數環境中運行的結果,我們選取了較為穩定和具有代表性的數據,撿到垃圾比例γ1、垃圾集中區占比θ1與垃圾產生比例θ2關系,有效比例γ2與垃圾集中區占比θ1和垃圾產生比例θ2關系分別如表1、表2 所示。
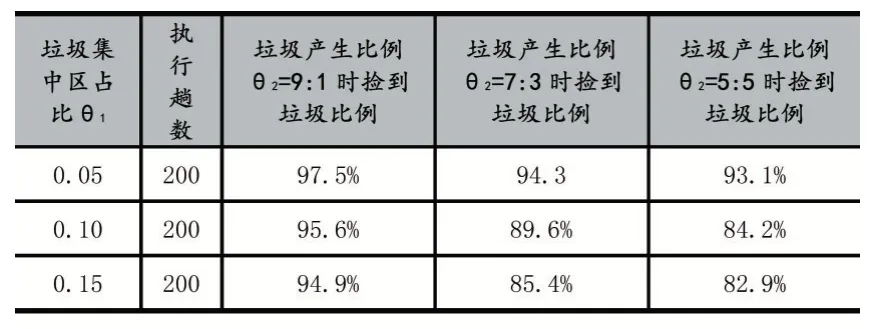
表1 撿到垃圾比例、垃圾集中區占比θ1 與垃圾產生比例θ2關系
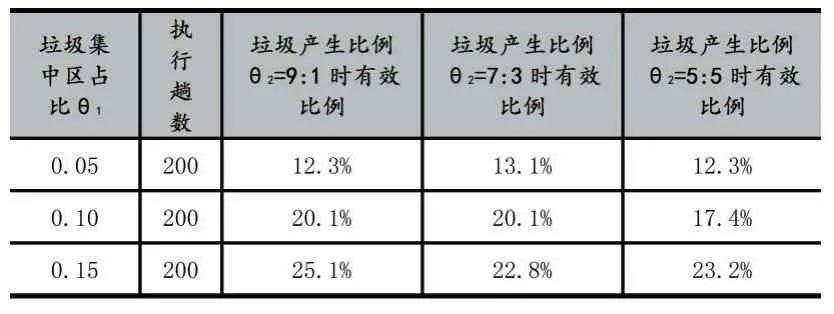
表2 有效比例與垃圾集中區占比θ1 和垃圾產生比例θ2 關系
同參數下各效率變化趨勢如圖4、圖5 所示。
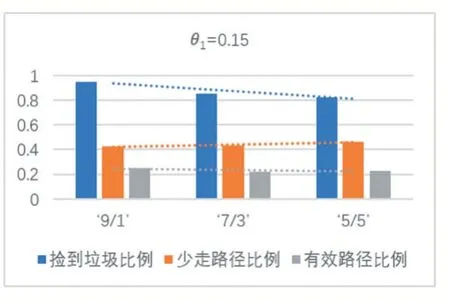
圖4 θ1=0.15時各效率隨θ2 變化情況
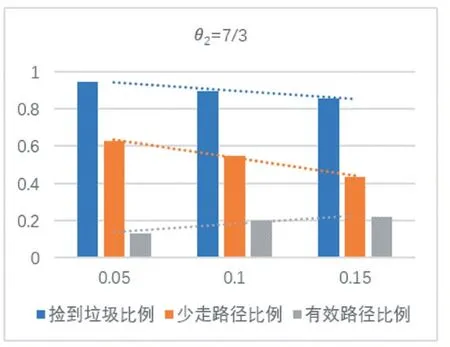
圖5 θ2=7/3時各效率隨 θ1 變化圖
從實驗結果中可以看出,θ1不變,撿到垃圾比例和有效比例都隨著θ2減小而減小,但總體而言θ2對有效比例影響不大。θ2不變,隨著θ1增大,撿到垃圾比例減小,少走路徑比例急劇減小,而有效比例則急劇增大。可以看出,在一定范圍內,垃圾集中區占總面積比例θ1和垃圾產生比例θ2越大,本文算法有效比例越大。
我們選取遍歷次數為200 時,垃圾產生比例θ2=9/1,垃圾集中區占比θ1=0.15,以及垃圾產生比例θ27/3,垃圾集中區占比θ1=0.0 5 兩種情況與全圖遍歷的效率對比,結果如表3-表4 所示。
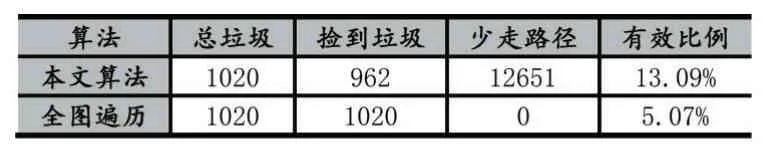
表3 θ1=0.05,θ2=7:3 情況下本文算法與全圖遍歷各項數據比較

表4 θ1=0.15,θ2=9:1情況下本文算法與全圖遍歷各項數據比較
表3-表4 中本文算法在不同環境下與全圖遍歷相比較,有效比例都比全圖遍歷要高許多,少走的路徑也意味著更低的能耗,但同時也能看到,全圖遍歷能撿到水面上幾乎所有的垃圾,而本文算法只能撿到80%-90%的垃圾,精度上還有待提高。
4 結語
本文提出的學習遍歷算法具有一定的學習能力,能夠根據歷史數據減少遍歷點的個數從而大大增加水上機器人工作的效率,相比于傳統的全圖遍歷的方法,本文的改進從垃圾集中點入手,在遍歷過程中逐漸找到垃圾集中的地區,主要遍歷這些地區,適當頻率遍歷垃圾較少出現的區域,從而較大改善了水上機器人的遍歷路徑,航行時間明顯得到減少,有效步數大幅度增加,具有更好的實用性。但是本文算法還需進一步改善,算法體現出對垃圾集中點外產生的垃圾清理效率不高,雖可通過增加遍歷點個數來提高垃圾清理效率,但如此一來有效比例卻會因此下降。改善算法之后,下一步將考慮具體實物實現。
猜你喜歡
瘋狂英語·初中天地(2021年5期)2021-07-21 02:24:28
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
遼寧經濟(2017年6期)2017-07-12 09:27:16
中國衛生(2016年9期)2016-11-12 13:27:54
時代英語·高二(2015年1期)2015-03-16 00:08:11
中國洗滌用品工業(2015年7期)2015-02-28 19:02:38
電子設計工程(2015年12期)2015-02-27 12:06:10
中國衛生(2014年11期)2014-11-12 13:11:32
