地質數據湖構建方法淺析
2020-12-28 12:07:08黃家凱
數字技術與應用 2020年11期
黃家凱
(湖北省地質調查院,湖北武漢 430034)
在云計算、大數據技術快速發展的背景下,隨著Hadoop等海量分布式存儲技術、分布式計算技術的快速普及,數據湖已被廣泛用于大數據平臺的存儲與使用。盡管目前對數據湖的定義尚有許多分歧,但其核心理念已得到接受。地質大數據具有海量、異構以及快速增長的特點,天然符合數據湖的特點。目前包括“地質云”“自然資源云”等地質大數據平臺的構建過程中,對“地質數據湖”的概念涉及較少,尚未對地質數據湖做出完整的定義,更未對地質數據湖的構建方法做出闡釋。本文將從地質數據湖的定義出發,淺析地質數據湖的構建方法,以期為湖北省地質局地質大數據平臺的下一步建設方向開闊技術思路。
1 地質數據湖的定義
搞清數據湖的定義后,將其數據的邊界限定在地質領域,也就搞清了地質數據湖的定義。數據湖是目前比較熱的一個概念,業內對于其的定義尚未完全達成一致,比較具有代表性的觀點如下:
1.1 維基百科(Wikipedia)的數據湖定義
數據湖是一類存儲數據自然/原始格式的系統或存儲,通常是對象塊或者文件。數據湖通常是企業中全量數據的單一存儲。全量數據包括原始系統所產生的原始數據拷貝以及為了各類任務而產生的轉換數據,各類任務包括報表、可視化、高級分析和機器學習。數據湖中包括來自于關系型數據庫中的結構化數據(行和列)、半結構化數據(如CSV、日志、XML、JSON)、非結構化數據(如email、文檔、PDF等)和二進制數據(如圖像、音頻、視頻)。
1.2 亞馬遜(AWS)的數據湖定義
數據湖是一個集中式存儲庫,允許用戶以任意規模存儲所有結構化和非結構化數據。用戶可以按原樣存儲數據(無需先對數據進行結構化處理),并運行不同類型的分析—從控制和可視化到大數據處理、實時分析和機器學習,以指導做出更好的決策[1]。
1.3 微軟(Azure)的數據湖定義
Azure的數據湖包括一切使得開發者、數據科學家、分析師能更簡單地存儲、處理數據的能力,這些能力使得用戶可以存儲任意規模、任意類型、任意產生速度的數據,并且可以跨平臺、跨語言的做所有類型的分析和處理。
1.4 小結
從上述業內關于數據湖的具有代表性的定義可以看出,雖然觀點不盡相同,對數據的內容、數據的應用能力略有差別,但可以總結出數據湖具有以下特性:
(1)數據湖需要提供足夠用的數據存儲能力,這個存儲保存了一個企業/組織中的所有數據。(2)數據湖可以存儲海量的任意類型的數據,包括結構化、半結構化和非結構化數據。(3)數據湖中的數據是原始數據,是業務數據的完整副本。數據湖中的數據保持了它們在業務系統中原來的樣子。(4)數據湖需要具備完善的數據管理能力(完善的元數據),可以管理各類數據相關的要素,包括數據源、數據格式、連接信息、數據schema、權限管理等。(5)數據湖需要具備多樣化的分析能力,包括但不限于批處理、流式計算、交互式分析以及機器學習;同時,還需要提供一定的任務調度和管理能力。(6)數據湖需要具備完善的數據生命周期管理能力。不光需要存儲原始數據,還需要能夠保存各類分析處理的中間結果,并完整地記錄數據的分析處理過程,能幫助用戶完整詳細追溯任意一條數據的產生過程。(7)數據湖需要具備完善的數據獲取和數據發布能力。數據湖需要能支撐各種各樣的數據源,并能從相關的數據源中獲取全量/增量數據;然后規范存儲。數據湖能將數據分析處理的結果推送到合適的存儲引擎中,滿足不同的應用訪問需求。(8)對于大數據的支持,包括超大規模存儲以及可擴展的大規模數據處理能力。
綜上,地質數據湖是一種不斷演進中、可擴展的大數據存儲、處理、分析的基礎設施;以數據為導向,實現任意來源、任意速度、任意規模、任意類型數據的全量獲取、全量存儲、多模式處理與全生命周期管理;并通過與各類外部異構數據源的交互集成,支持各類企業級應用[2]。
2 云計算廠商的數據湖構建方案
2.1 亞馬遜(AWS)的數據湖構建方案
亞馬遜的數據湖基于AWS Lake Formation構建,它與其他AWS服務互相配合,來完成整個企業級數據湖構建功能(如圖1所示)。包含數據流入、數據沉淀、數據計算、數據應用四個步驟。
2.1.1 數據流入
數據流入是整個數據湖構建的起始,包括元數據的流入和業務數據流入兩個部分。元數據流入包括數據源創建、元數據抓取兩步,最終會形成數據資源目錄,并生成對應的安全設置與訪問控制策略。業務數據的流入通過ETL來完成的。AWS提供的數據湖解決方案,支持S3、AWS關系型數據庫、A W S N o S Q L 數據庫,A W S 利用G L U E、EMR、Athena等組件支持數據的自由流動。
2.1.2 數據沉淀
采用Amazon S3作為整個數據湖的集中存儲,按需擴展/按使用量付費。
2.1.3 數據計算
采用A W S G L U E 來進行基本的數據處理。G L U E 基本的計算形式是各類批處理模式的ETL任務,任務的出發方式分為手動觸發、定時觸發、事件觸發三種。事件觸發模式上,利用AWS Lambda進行擴展開發,同時觸發一個或多個任務;各類ETL任務通過CloudWatch進行監控。
2.1.4 數據應用
在提供基本的批處理計算模式之外,AWS通過各類外部計算引擎,來提供豐富的計算模式支持,例如通過Athena/Redshift來提供基于SQL的交互式批處理能力;通過EMR來提供各類基于Spark的計算能力,包括Spark能提供的流計算能力和機器學習能力。
2.1.5 權限管理
通過Lake Formation來提供相對完善的權限管理,粒度包括“庫-表-列”。
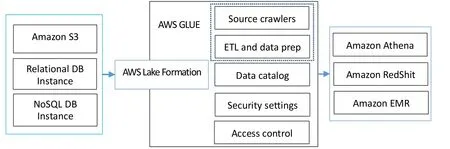
圖1 AWS 數據湖解決方案示意圖
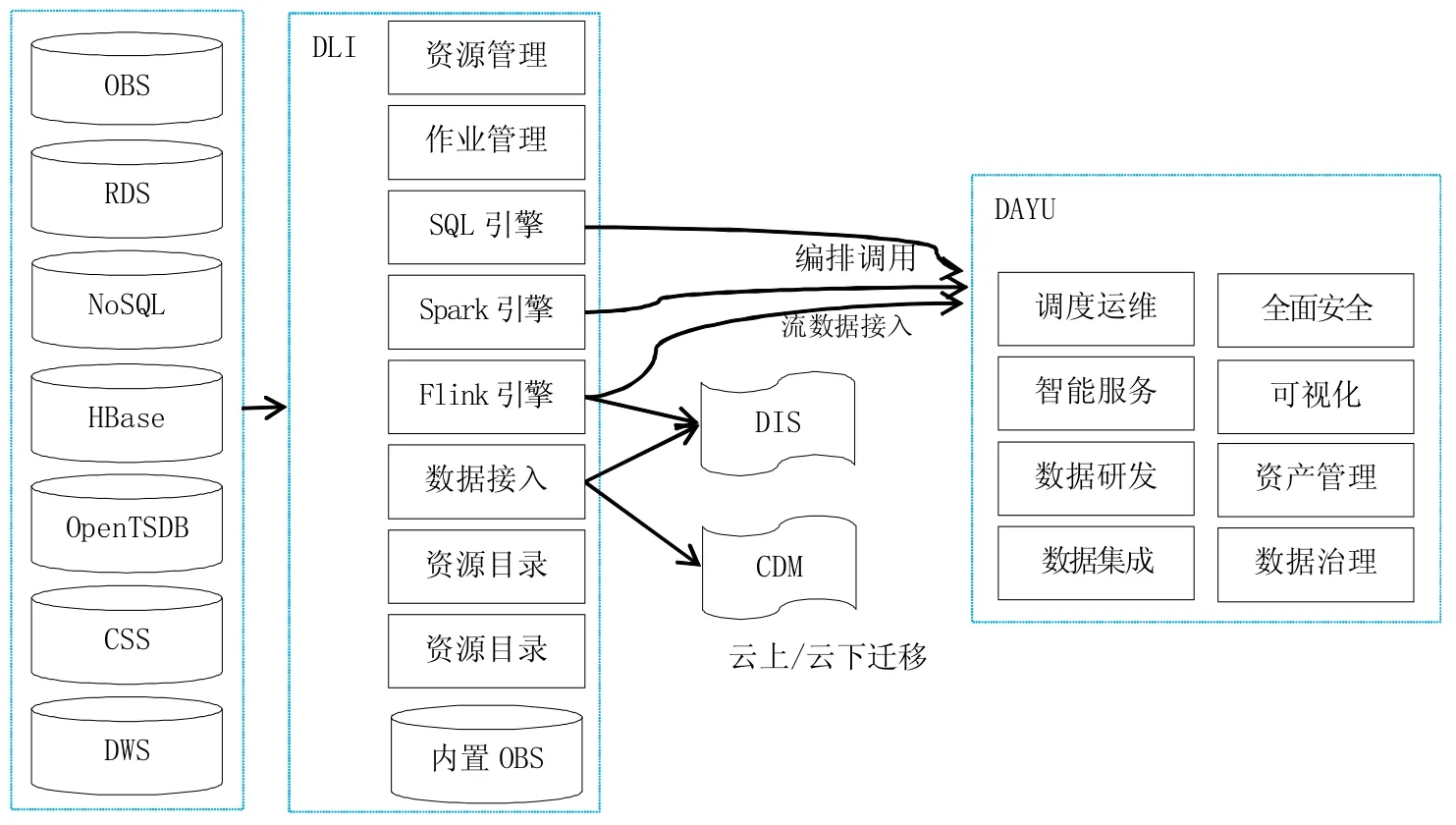
圖2 華為數據湖解決方案示意圖
2.1.6 數據治理
數據治理屬于數據所有者的責任,AWS的通用解決方案不囊括這塊內容,用戶可以通過開源組件(如Apache Griffin)針對數據治理自行定制開發。
2.2 華為的數據湖構建方案
華為的數據湖解決方案包括數據湖探索(Data Lake Insight,DLI)和智能數據湖運營平臺(DAYU)(如圖2所示)。其中DLI相當于是AWS的Lake Formation、GLUE、Athena、EMR(Flink&Spark)的集合。
2.2.1 華為云數據湖探索(DLI)
華為的數據湖解決方案比較完整,DLI承擔了數據湖構建、數據處理、數據管理、數據應用的核心功能。DLI具有完備的分析引擎,包括基于SQL的交互式分析以及基于Spark+Flink的流批一體處理引擎。DLI通過OBS來提供核心存儲引擎,和AWS S3的能力基本對標。華為數據湖幾乎支持所有目前華為云上提供的數據源服務。
DLI可以與華為的CDM(云數據遷移服務)和DIS(數據接入服務)對接:借助DIS,DLI可以定義各類數據點,并可以在Flink作業中被使用,作為source或者sink;借助CDM,DLI甚至能接入IDC、第三方云服務的數據。
2.2.2 華為云數據湖智能運營平臺(DAYU)
為了更好地支持數據集成、數據開發、數據治理、質量管理等數據湖高級功能, 華為云提供了D A Y U 平臺。DAYU涵蓋了整個數據湖治理的核心流程,并對其提供了相應的工具支持。可以看到,本質上DAYU數據治理的方法論其實是傳統數據倉庫治理方法論在數據湖基礎設施上的延伸:從數據模型來看,依然包括貼源層、多源整合層、明細數據層,這與數據倉庫完全一致。
2.3 阿里云數據湖構建方案
阿里云采用OSS作為數據湖的集中存儲。在數據源的支持上,支持所有的阿里云數據庫,包括OLTP、OLAP和NoSQL等各類數據庫。核心關鍵點如下:
2.3.1 數據接入與搬遷
在建湖過程中,DLA組件具備元數據發現和一鍵建湖的能力。
2.3.2 數據資源目錄
DLA提供Meta data catalog組件對于數據湖中的數據資產進行統一的管理,無論數據是在“湖中”還是在“湖外”。
2.3.3 數據計算分析
DLA提供SQL計算引擎和Spark計算引擎兩種,并與Meta data catalog深度集成,能方便地獲取元數據信息。基于Spark的能力,DLA解決方案支持批處理、流計算和機器學習等計算模式。
2.3.4 異構數據管理
DLA除了支持各類異構數據源做數據接入與匯聚之外,還能與云原生數據倉庫(原ADB)深度整合。
2.3.5 數據集成和開發
阿里云的數據湖解決方案提供兩種選擇:一種是采用dataworks完成;另一種是采用DMS來完成。兩種都能對外提供可視化的流程編排、任務調度、任務管理能力。
2.3.6 數據管理和數據安全
D M S 提供了強大的能力。D M S 的數據管理粒度分為“庫-表-列-行”,完善的支持企業級的數據安全管控需求。DMS把原來基于數據庫的devops理念擴展到了數據湖,使得數據湖的運維、開發更加精細化。
2.4 微軟的數據湖構建方案
Azure的數據湖解決方案包括數據湖存儲、接口層、資源調度與計算引擎層。存儲層是基于Azure object Storage構建的,是對結構化、半結構化和非結構化數據提供支撐。接口層為WebHDFS,在Azure object Storage實現了HDFS的接口。在資源調度上,Azure基于YARN實現。計算引擎上,Azure提供了U-SQL、hadoop和Spark等多種處理引擎。限于篇幅,本文不再對其做深入剖析。
3 構建地質數據湖的主要技術方法
地質數據湖的建設過程應該與地質信息化工作緊密結合。但是地質數據湖的建設過程與傳統的數據倉庫,甚至是當前大熱的數據中臺應該是有所區別的。區別在于,數據湖應該以一種更敏捷的方式去構建,“邊建邊用,邊用邊治理”。
3.1 數據摸底
摸清楚數據的基本情況,包括數據來源、數據類型、數據形態、數據模式、數據總量、數據增量。數據湖是對原始數據做全量保存,因此無需事先進行深層次的設計。
當前我局地質大數據平臺中,圍繞成果地質資料、地質數據庫形成了完整的半結構化、非結構化地質大數據中心(地質資料中心)。在MySQL、達夢數據庫等關系數據庫管理平臺基礎上,對財務、項目、質量等管理業務形成了結構化的業務數據。今后還將持續入云增量數據,以及增加地質工作全業務、全流程的其它數據內容。
3.2 技術選型
根據數據摸底的情況,確定地質數據湖建設的技術選型。事實上,關于數據湖的技術選型,業界有很多的通行的做法,基本原則是:“計算與存儲分離”“彈性”“獨立擴展”。存儲選型是分布式對象存儲系統(如S 3/O S S/O B S/HDFS等);計算引擎上建議重點考慮批處理需求和SQL處理能力,因為在實踐中,這兩類能力是數據處理的關鍵。無論是計算還是存儲,優先考慮serverless的形式;后續可以在應用中逐步演進,需要獨立資源池的時候再考慮構建專屬集群。
3.3 數據接入
確定要接入的數據源,完成數據的全量抽取與增量接入。
當前局地質大數據平臺的數據還是分散在各業務系統中,數據接入過程中要重點考慮數據產權、數據模式沖突、異構數據的兼容性等技術問題。
3.4 應用治理
這一步是構建地質數據湖的關鍵,從數據湖的角度來看,數據應用和數據治理應該是相互融合、密不可分的。從數據應用入手,在應用中明確需求,在數據ETL的過程中,逐步形成業務可使用的數據;同時形成數據模型、指標體系和對應的質量標準。數據湖強調對原始數據的存儲,強調對數據的探索式分析與應用,但這絕對不是說數據湖不需要數據模型;恰恰相反,對業務的理解與抽象,將極大地推動數據湖的發展與應用,數據湖技術使得數據的處理與建模,保留了極大地敏捷性,能快速適應業務的發展與變化。
從技術視角來看,地質數據湖不同于大數據平臺之處,還在于地質數據湖為了支撐數據的全生命周期管理與應用,需要具備相對完善的數據管理、類目管理、流程編排、任務調度、數據溯源、數據治理、質量管理、權限管理等能力。在計算能力上,需要支持SQL和可編程的批處理兩種模式(對機器學習的支持,可以采用Spark或者Flink的內置能力);在處理范式上,可以采用基于有向無環圖的工作流的模式,并提供集成開發環境。
4 總結
地質數據湖作為新一代大數據分析處理的基礎設施,需要超越傳統的大數據平臺[3]。今后在適當時機,有必要將地質大數據中心拓展升級,真正形成地質數據湖。未來地質數據湖可能會朝以下方向發展:
4.1 云原生架構
基于地質數據湖實現存儲和計算分離,計算能力和存儲能力均可獨立擴展;多模態計算引擎支持,SQL、批處理、流式計算、機器學習等;提供serverless態服務,確保足夠的彈性。
4.2 足夠用的數據管理能力
通過數據湖提供更為強大的數據管理能力,包括但不限于數據源管理、數據類目管理、處理流程編排、任務調度、數據溯源、數據治理、質量管理、權限管理等。
4.3 大數據的能力,數據庫的體驗
目前絕大多數數據分析人員都只有數據庫的使用經驗,大數據平臺的能力雖強,但是對于用戶來說并不友好,數據科學家和數據分析師應該關注數據、算法、模型及其與業務場景的適配,而不是花大量的時間精力去學習大數據平臺的開發。
4.4 完善的數據集成與數據開發能力
對各種異構數據源的管理與支持,對異構數據的全量/增量遷移支持,對各種數據格式的支持都是需要不斷完善的方向。同時,需要具備一個完備的、可視化的、可擴展的集成開發環境。
4.5 與業務的深度融合與集成
典型數據湖架構的構成基本已經成為了業界共識:分布式對象存儲+多模態計算引擎+數據管理[4]。決定數據湖構建成敗的關鍵在于數據管理,無論是原始數據的管理、數據類目的管理、數據模型的管理、數據權限的管理還是處理任務的管理,都離不開與業務的適配和集成;地質數據湖與地質數據科學家和地質數據分析師形成良性發展與互動。如何在地質數據湖預置地質行業數據模型、ETL流程、分析模型和定制算法,可能是未來地質數據湖競爭力的一個關鍵點。
猜你喜歡
發明與創新(2022年30期)2022-10-03 08:40:56
今日農業(2022年15期)2022-09-20 06:56:20
人大建設(2018年6期)2018-08-16 07:23:10
文理導航·科普童話(2017年5期)2018-02-10 19:42:14
商周刊(2017年22期)2017-11-09 05:08:31
雜文月刊(2016年1期)2016-02-11 10:35:51
小星星·閱讀100分(低年級)(2015年10期)2015-10-22 08:30:04
河南電力(2015年5期)2015-06-08 06:01:46
現代企業(2015年8期)2015-02-28 18:54:47
皖西學院學報(2015年5期)2015-02-28 17:52:46
