一種古籍漢字圖像的多屬性模糊檢索模型
2020-12-28 02:24:48齊艷媚田學東張充李亞康
河北大學學報(自然科學版) 2020年6期
關鍵詞:特征
齊艷媚,田學東,張充,李亞康
(1. 河北大學 網絡空間安全與計算機學院,河北 保定 071002;2. 河北大學附屬醫院 信息中心,河北 保定 071000)
漢語言文字研究的深入帶來了對文獻數字化、信息化處理的更高要求.古籍漢字多為結構復雜、書寫風格多樣的繁體字,加之年代久遠對字形存在形態所帶來的影響,如噪聲和斷筆等情況,導致傳統的基于內容的圖像檢索技術和文字識別技術在對古籍漢字圖像進行檢索時,難以取得理想的結果.因此,根據古籍漢字的特點,研究、提取有效的古籍漢字圖像特征并建立相應的匹配算法,是古籍漢字圖像檢索研究中的重點和難點.
近年來,針對古籍漢字圖像檢索的研究相對較少,可供參考的主要有脫機手寫漢字圖像的檢索與識別方法.張睿[1]和姜文[2]等介紹了方向線素法,通過抽取漢字輪廓,考察像素點的8鄰域內像素在0°、±45°、90°4個方向上的分布情況,雖然方向線素特征同時兼顧了統計特征和結構特征的優勢,但其維數較多增加了識別難度.冉耕等[3]介紹了一種彈性網格法,利用彈性網格對圖像進行分塊,獲取彈性網格特征,能較好地反映漢字的結構細節和字符特征,克服手寫漢字由于書寫風格多樣造成的字體變形和數據采集造成的樣本變形等問題.
除了傳統特征提取方法,卷積神經網絡也被引入到漢字識別領域中來.毛曉波等[4]提出一種新的卷積結構,將當前層與前一層特征圖疊加,用于對脫機手寫漢字的識別,不但減少了參數數量,對梯度消失的問題也有所緩解.劉虹等[5]提出將余弦相關性加入卷積神經網絡的算法,使卷積神經網絡的特征提取能力增強,能夠在惡劣環境下達到較高的識別效率,增強了網絡結構的模式檢測能力,獲得了更快的收斂速度.郭利敏等[6]利用卷積神經網絡的分類問題替代古籍漢字識別問題,通過深度學習構建分類器,用于漢字圖像與漢字字符的分類,進而提升古籍漢字的識別率.
由于手寫漢字大多存在字體復雜多變、風格多樣等問題,因此,在漢字圖像檢索時引入了模糊特征理論.Zhou等[7]針對筆觸的交集和交集之類的含糊區域會給手寫漢字的筆畫提取帶來困難的問題,設計了一種借助模糊區域信息來進行漢字筆畫提取的方法,首先獲取漢字骨骼上模糊區域的筆畫子段間的連接系數,然后修改骨骼上的變形,檢測突然的轉折點,獲得最終行程:該方法提取的筆畫保持良好的形狀,能正確反映筆畫之間的位置關系,可用于手寫漢字的相關研究.魏瑋等[8]提出了一種模糊雙彈性網格的特征提取方法,在特征提取時加入了模糊特征和雙彈性網格劃分,能夠更有效地提取漢字“撇”和“捺”方向的特征.Mapari等[9]針對手寫化學結構或符號難以被有效識別的問題,提出了一種基于模糊規則和SOM(self organization map)的模型,在進行模糊圖像分割時運用低模糊規則和高模糊規則方法,提高了手寫體化學符號和結構的識別率.柴彥立[10]在模糊特征基礎上引入猶豫模糊集理論,融合結構與統計特征,提出一種面向古籍漢字圖像檢索的猶豫模糊特征提取算法,提升了古籍漢字圖像的檢索查全率和查準率.
由于古籍漢字具有結構繁雜多變、筆畫風格多樣、年代久遠等特點,導致上述方法在處理古籍漢字圖像檢索時難以取得理想效果.鑒于模糊集理論的單一隸屬度導致其無法完整有效地處理古籍漢字在筆畫以及結構特征方面的信息,本文在對古籍漢字圖像檢索時引入猶豫模糊集理論[11],利用其在處理多隸屬度方面的優勢,來適應古籍漢字風格多樣、結構多變的特點,充分考慮漢字筆畫和角點的構成特征,從多角度出發,建立融合古籍漢字圖像筆畫特征和角點特征的多屬性模糊檢索模型,更好地滿足古籍漢字研究過程中專家對古籍漢字圖像檢索的實際需求.
1 古籍漢字圖像的特征分析
1.1 古籍漢字圖像的角點特征分析

1.2 古籍漢字圖像的彈性網格劃分
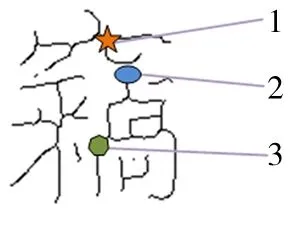
1.交叉點;2.端點;3.拐點.圖1 古籍漢字圖像的角點特征Fig.1 Corner feature map of ancient Chinese character images
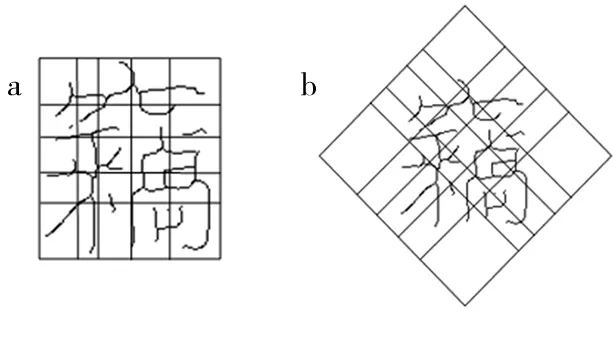
a.縱橫彈性網格劃分;b.規范化對角彈性網格劃分.圖2 古籍漢字圖像的重疊規范化雙彈性網格劃分Fig.2 Overlapping normalized bi-elastic mesh division diagram
1.3 古籍漢字圖像的筆畫方向分解
漢字大多由“橫”、“豎”、“撇”、“捺”4種筆畫組成,因此,漢字的基本特征可以用這4種筆畫進行有效地表示.F(x,y)表示細化后的二值圖像,對漢字細化后采用“OR”[12]技術進行分解的規則如表1所示.

表1 漢字筆畫分解規則
2 古籍漢字圖像的相似度評價
本文引入猶豫模糊集理論,利用其在處理多隸屬度決策方面的優勢,從古籍漢字圖像的多角度屬性出發,完成古籍漢字圖像間的匹配檢索.
2.1 猶豫模糊集
猶豫模糊集[11]是由Torra對模糊集[13]進行推廣而提出的新理論,設U是一個非空集合,則稱
F={
(1)
為U上的猶豫模糊集,hF(x)表示[0,1]上的非空集合,是x∈U對集合F的多個可能隸屬度的集合,猶豫模糊集中隸屬度是若干可能值的集合,而不是一個確定的值或者分布[11].
文獻[14]在進行距離測度計算時考慮到了權重的影響,根據評價對象屬性的重要程度,在加權平均算子的基礎上,給出了猶豫模糊加權距離測度的計算公式.
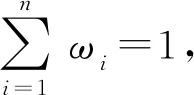
(2)
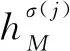
2.2 古籍漢字圖像相似度評價屬性
定義2設Ir表示輸入的古籍漢字圖像,Irj表示數據集中任一古籍漢字圖像(j= 1, 2, 3, …,m.m為數據集中古籍漢字圖像的總數).
2.2.1 筆畫屬性
下面以在規范化對角雙彈性網格下對“橫”筆畫子圖的特征分析為例,給出在縱橫彈性網格下的“橫”筆畫像素對應的隸屬度函數的定義,并求出在當前網格下的隸屬度值.
1)數量特征
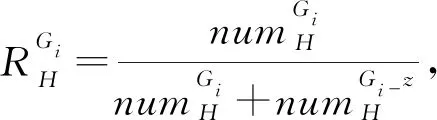
定義3“橫”筆畫像素的數量特征隸屬度函數為
(3)
其中tolH表示“橫”筆畫子圖中“橫”筆畫像素的總數.分別計算Gi內(k=H、S、P、N)(分別表示“橫”“豎”“撇”“捺”像素)的隸屬度,加權平均即為當前網格在筆畫數量特征下的隸屬度值.
2)位置特征
利用Gi內的筆畫像素與其周圍網格的相交情況,作為評估2幅古籍漢字圖像相似程度的標準.如果網格Gi內的所有筆畫均不存在與周圍網格相交的情況,則筆畫像素在Gi內的位置特征對應的隸屬度值為1.
橫筆畫像素在縱橫彈性網格下的位置特征圖如圖3a所示,Gi內筆畫1和筆畫2皆與周圍網格有相交情況,筆畫3與任何網格均無相交情況,因此橫筆畫像素在Gi內的位置特征對應隸屬度值為(m1+m2+l3)/(l1+l2+l3).
橫筆畫像素在規范化對角彈性網格下的位置特征圖如圖3b所示,Gi內的所有筆畫皆與鄰接網格有相交情況,因此橫筆畫像素在Gi內的位置特征對應隸屬度值為(m1+m2+m3)/(l1+l2+l3).如果2幅圖像在網格Gi內所有筆畫像素點與同本網格有交叉的所有筆畫長度總和的比值越接近,說明它們的相似程度越大.
定義4“橫”筆畫像素的位置特征隸屬度函數為
(4)
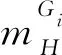
3)距離特征
將Gi內筆畫像素到鄰近網格的最短距離作為評估不同古籍漢字圖像間相似程度的標準.
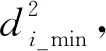
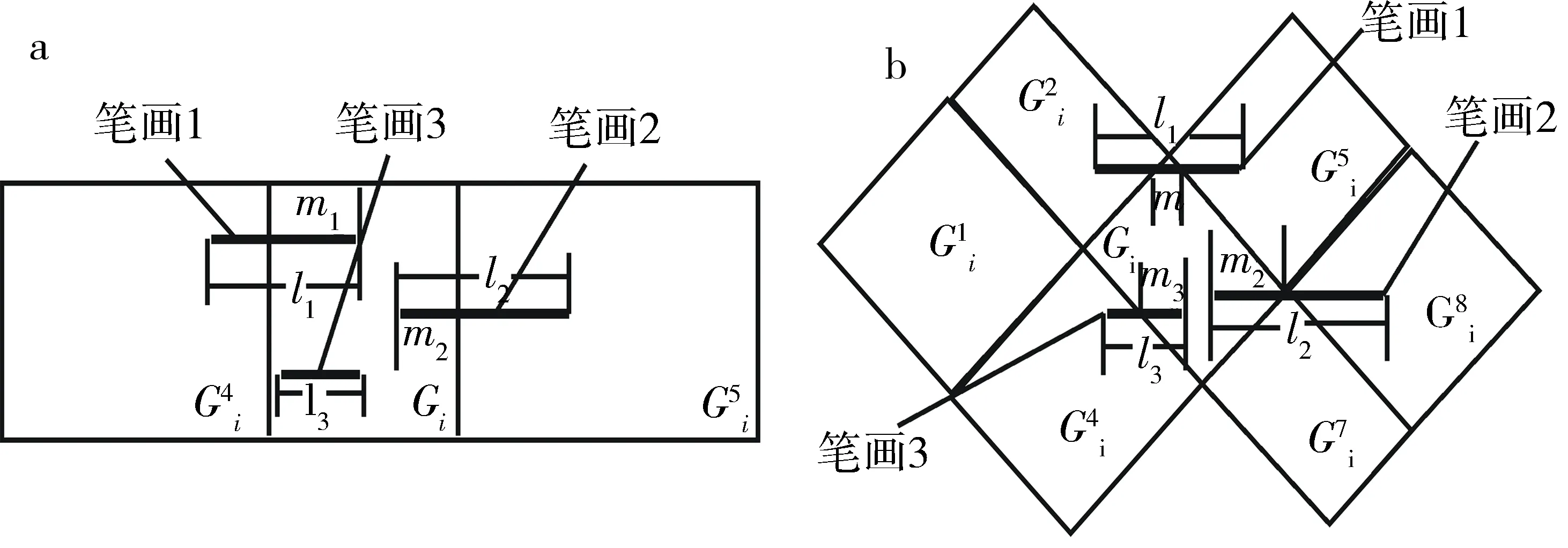
a.縱橫彈性網格;b.規范化對角彈性網格.圖3 彈性網格下“橫”筆畫像素的位置特征Fig.3 Location feature map of “horizontal” stroke pixels under elastic grid

a.縱橫彈性網格;b.規范化對角彈性網格.圖4 彈性網格下的“橫”筆畫像素的距離特征Fig.4 Distance feature map of “horizontal” stroke pixels under elastic grid

定義5“橫”筆畫像素的距離特征隸屬度函數為
(5)
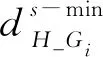
2.2.2 角點屬性
組成漢字的元素除了筆畫外,角點也占了很高的比重,古籍漢字的結構信息能夠通過角點得到很好的展現,因此本文將漢字筆畫的交叉點、拐點、端點在漢字圖像中的數量分布以及位置信息作為古籍漢字的角點特征.
1)角點距離特征
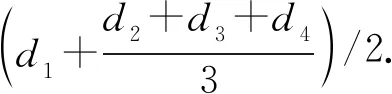
定義6角點的距離特征隸屬度函數定義為
(6)
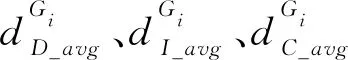
2)角點分布特征
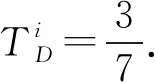
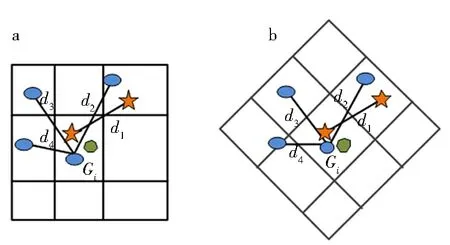
a.縱橫彈性網格;b.規范化對角彈性網格.圖5 彈性網格下的古籍漢字圖像角點距離特征圖Fig.5 Corner distance feature map of ancient Chinese character images based on elastic grid
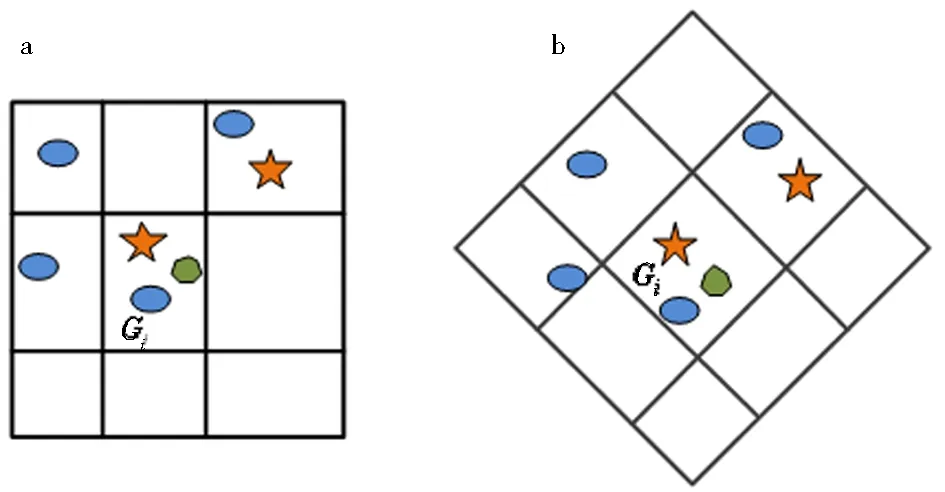
a.縱橫彈性網格;b.規范化對角彈性網格.圖6 彈性網格下的古籍漢字圖像角點分布圖Fig.6 Distribution characteristics of corner points in ancient Chinese character images under elastic grid
定義7角點的分布特征隸屬度函數定義為
(7)
2.3 基于猶豫模糊集的古籍漢字圖像檢索
對古籍漢字圖像Ir和Irj經過多隸屬度評價后,形成猶豫模糊集合fr和frj,其中f由隸屬度集合Ufn、Ufp、Ufd、UfT_J、UfT_F構成,任一評價屬性Ew(w=1,2),w=1和2分別表示筆畫屬性和角點屬性,猶豫模糊集合對應的猶豫模糊元素集合為hfr和hfrj,hfr和hfrj中元素為Ir和Irj在屬性Ew包含的各個特征下的隸屬度值的集合,利用猶豫加權測度公式進行處理,如式(8)~(10)所示.
(8)
(9)
sim(Ir,Irj)=1-d(Ir,Irj),
(10)
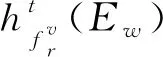
(11)
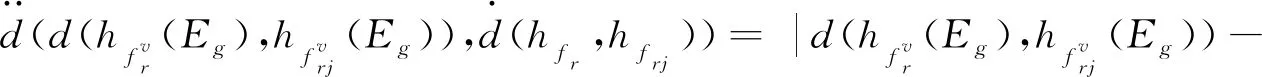
(12)
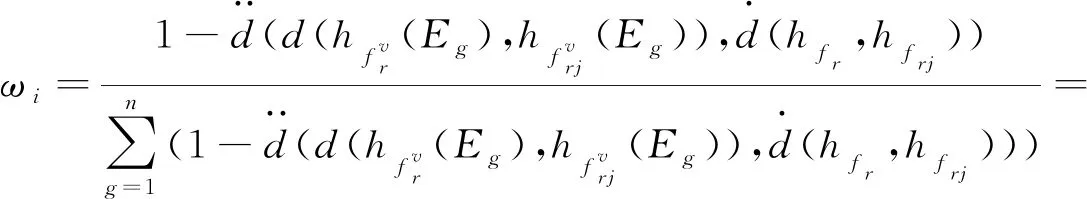
.
(13)
3 實驗結果及分析
3.1 數據集介紹
為了驗證古籍漢字圖像的多屬性模糊檢索方法的有效性,本文從已實現數字化的四庫全書文淵閣中的經、史、子、集中共選取92幅版面圖像,對其切分獲得11 574幅單字圖像作為古籍漢字圖像檢索的實驗樣張,采用13位編碼進行標注,如表2所示(例如:GJHZ_0000030011012表示文淵閣經部第0003冊001頁下第012個單字圖像).
將數據集中所有單字圖像按字形結構劃分為左右結構(A)、上下結構(B)、獨體結構(C)、包圍結構(D)4大類,部分實驗樣張如表3所示.

表2 古籍漢字圖像數據集編碼格式

表3 古籍漢字圖像檢索實驗樣張
3.2 隸屬度函數中的參數設置
為了確定公式(7)中的權重系數α和β,歸納總結11 574幅單字圖像在每個彈性網格和其八鄰域情況下的角點分布對檢索結果的影響程度,得出α的值為0.465,β的值為1.625.
為了分析古籍漢字圖像的多屬性模糊檢索方法的有效性,選擇查全率和查準率對圖像的檢索結果進行評價.
定義8查全率(recall rate,簡稱R),表示檢索結果中與輸入圖像相似的圖像數量NS占數據集中所有相似圖像數量NT的百分數.
(14)
定義9查準率(precision ratio,簡稱P),表示檢索結果中與輸入圖像相似的圖像數量NS占全部檢索結果圖像數量NR的百分數.
(15)
3.3 古籍漢字圖像檢索性能分析
通過歸納重疊規范化雙彈性網格下古籍漢字圖像的筆畫屬性和角點屬性的猶豫模糊集合,從多角度出發考察古籍漢字特征,同時引入猶豫模糊加權距離測度,考慮了不同屬性所占比重不同的問題.為了驗證本文方法的可行性,構造傳統特征提取算法中的基于重疊規范化雙彈性網格的梯度特征提取方法[3]作為對比算法1,基于手寫體漢字雙彈性網格模糊特征算法[8]作為對比算法2;構造卷積神經網絡類檢索算法中的基于卷積神經網絡的古籍漢字識別算法[6]作為對比算法3,結合余弦相關性的卷積網絡識別漢字的算法[5]作為對比算法4,對其網絡模型稍作修改,使其能更加適用于古籍漢字圖像檢索.
設NS為與待檢索圖像相似度高于某一閾值T/%時檢索出的圖像數量;NR為檢索出的所有圖像的數量.以常見的左右結構圖像“”(編碼為GJHZ_0000010100161)為例,根據查準率計算法則(例如,當閾值設置為90%時,其輸出圖片數量為11,其中相似圖片為9幅,則查準率為9/11=0.818)計算相應的P(查準率)值,如表4所示.

表4 本文與模擬實驗算法在不同閾值下的參數統計結果
從表4可知,相比傳統檢索類算法中的梯度特征(算法1)和模糊特征(算法2)方法,本文方法在面對古籍漢字圖像檢索時能達到更高的查準率和查全率,這是由于本文利用猶豫模糊集理論在處理多屬性決策方面的優勢,從多角度出發提取古籍漢字圖像的特征,定義相應的隸屬度函數,并且通過相應權重更新算法考察了不同特征所占比重不同的問題,更加適用于古籍漢字圖像檢索;在不同閾值下本文方法與卷積神經網絡類方法的查準率基本保持在80%左右,當閾值T為85%和80%時本文方法略顯優勢,但是在其他情況下出現了本文參數略低于模擬系統的情況,這是由于古籍漢字圖像大多結構繁雜多變、存在狀態較差等因素,導致本文算法在對古籍漢字圖像進行特征提取時較卷積類算法略顯劣勢,造成了本文算法的查準率出現略低于模擬系統的情況.但是,總體來說本文方法在對古籍漢字圖像檢索時,能夠取得較好的效果.
為進一步驗證本文實驗的有效性,考察本文算法與模擬實驗算法在不同漢字字形結構下的查全率與查準率間的差異.不同字形結構下的查全率和查準率的值由組內全部圖像(20幅圖像)的平均值得出,幾種方法的平均查全率和平均查準率對比結果如表5所示.
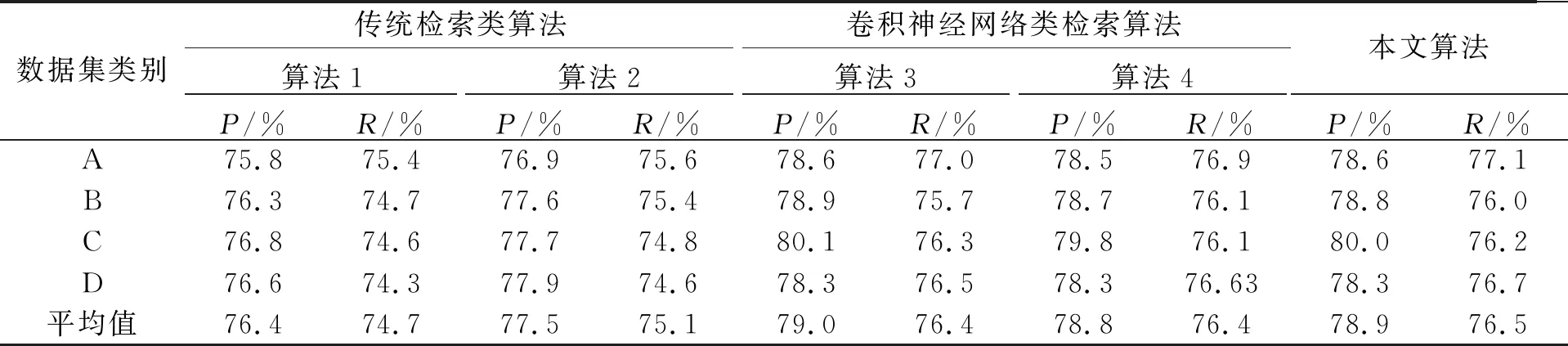
表5 本文與模擬實驗算法在不同字形結構下的檢索結果對比
表5中的平均查全率和平均查準率表示了整個測試數據集的最終評價值,由表4可知,無論在何種情況下,本文算法的查全率、查準率均高于算法1和算法2 兩種傳統檢索類算法;本文算法的平均查全率分別比算法3和算法4高0.1%和0.1%,平均查準率比算法3低了0.1%,比算法4高了0.1%.在類別B和類別C下算法3的查準率略高于本文算法,類別C下算法3的查全率略高于本文算法,這是由于在進行特征提取時,基于猶豫模糊集的圖像檢索算法與基于卷積的圖像檢索算法的側重點不同,導致了在面對古籍圖像書寫質量較差以及紙張破損嚴重等問題時,本文算法的查準率和查全率存在略低于對比算法的情況.綜合實驗結果,本文算法的總體效果基本達到了預期目標.
3.4 古籍漢字圖像檢索結果分析

a.本文檢索結果top10;b.算法1檢索結果top10;c.算法2檢索結果top10; d.算法3檢索結果top10;e.算法4檢索結果top10.圖7 古籍漢字圖像檢索結果Fig.7 Image retrieval results of ancient Chinese characters
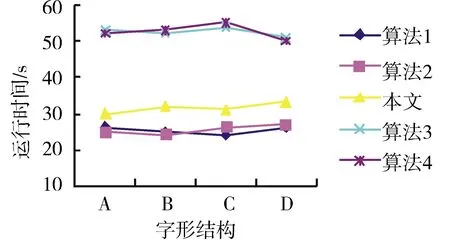
圖8 5種算法檢索時間對比Fig.8 Five algorithms retrieve time comparison
由圖7可知,5種算法檢索結果前8張圖像均與目標圖像有較高的相似度,且圖7a中的后2張圖像相似度明顯高于圖7b和圖7c,說明本文古籍漢字圖像的多屬性模糊檢索算法能達到相對較好的檢索效果.
3.5 古籍漢字圖像檢索速度分析
對算法運行時間進行統計,結果如圖8所示.由圖8可知,雖然由于本文引入猶豫模糊集理論,從多角度出發進行圖像檢索相似度的計算,造成了時間復雜度略高于算法1和算法2的結果,但在可接受范圍之內;本文方法運行時間明顯優于算法3和算法4 2種卷積神經網絡類方法,原因是卷積神經網絡在對圖像進行檢索時需要提取自適應特征并不斷訓練數據集圖像,導致其運行時間較長.
綜上所述,本文算法在運行速度上相比傳統特征提取算法雖有一定劣勢,但是由3.3可知本文算法在查全率和查準率上均有一定程度的提高;此外,從3.3和3.4可以看出本文方法與卷積神經網絡類特征提取算法在檢索準確率和檢索結果上無明顯差異.雖然卷積神經網絡算法對手寫漢字識別與檢索能夠達到較好的效果,但其無法滿足漢字研究專家需要實時獲得古籍漢字研究時出現的新字形的需求,且卷積神經網絡不僅需要高配置的硬件,還需要搭建復雜的網絡模型,因此,在查全率、查準率無明顯差異的情況下,本文算法更加適用于古籍漢字圖像檢索.
4 結束語
古籍漢字圖像檢索是輔助古籍漢字研究的重要手段,為了更好地滿足古籍漢字研究的需求,本文采用融合結構與統計特征的圖像檢索,設計了一種多屬性模糊的古籍漢字圖像檢索方法.首先提取漢字圖像的筆畫和角點等多特征信息,存入特征數據庫;然后利用猶豫模糊加權距離測度公式計算圖像間的距離測度,并按相似度進行初步排序,得到最終檢索結果.實驗結果表明,所提出的算法在對古籍漢字圖像檢索中取得了較好的效果.
鑒于古籍漢字結構多變、風格多樣的特點,本文方法還有很多有待改進之處.首先,需進一步完善權重模型,使其能更加適用于古籍漢字圖像檢索;其次,隸屬度函數的定義和相應評價屬性的選擇需要優化,通過建立更加適合古籍漢字的特征索引來減小時間復雜度,進一步提高檢索系統性能.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
