基于MATLAB的字符識別及其在化探野外資料整理中的應(yīng)用
2021-01-08 05:30:36聶小力羅敏玄戴亮亮
資源信息與工程 2020年6期
聶小力, 張 濤, 羅敏玄, 吳 豐, 戴亮亮, 李 新
(中國地質(zhì)調(diào)查局長沙自然資源綜合調(diào)查中心,湖南 長沙 410600)
0 引言
在物化探野外工作中,常需將手寫的記錄表轉(zhuǎn)化為電子文檔以便入庫管理,但現(xiàn)階段尚無此類專業(yè)軟件,因此開發(fā)能實現(xiàn)這一功能的程序很有必要。本文選用MATLAB來做圖像處理[1],將圖片文件轉(zhuǎn)化為與之對應(yīng)的矩陣,通過對矩陣進行處理運算便可起到處理圖像的效果,這把字符識別問題轉(zhuǎn)化成了數(shù)學(xué)問題,極大程度簡化了研究內(nèi)容。
研究過程中首先對圖片進行預(yù)處理,將需提取信息的部分識別出來并進行剪裁,將彩色圖像灰度化轉(zhuǎn)為灰度圖像,再對圖像中的無用信息進行去噪處理。然后將灰度圖轉(zhuǎn)為二值圖像,進行切割后得到單個字符的特征矩陣。最后利用模板比對法,通過相關(guān)性大小最終確定字符信息。
1 字符識別原理及算法流程
本文采用光學(xué)字符識別(OCR)的方法來進行字符識別,主要分為圖像預(yù)處理、圖像分割、文字識別三個步驟。圖像預(yù)處理即將原始圖像轉(zhuǎn)化為非黑即白的二值圖,并去除噪聲,然后分割剪裁得到單個字符特征矩陣,最后利用模板比對法確定字符信息。
具體算法流程圖如圖1所示。
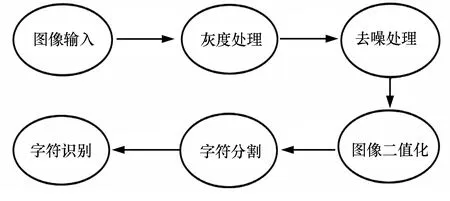
圖1 算法流程圖
2 字符識別的MATLAB實現(xiàn)
考慮到字符識別的一些處理步驟可合并到一起,故從三個環(huán)節(jié)來說明字符識別的MATLAB實現(xiàn)方法,分別是圖像預(yù)處理、圖像切割和字符識別[2]。
2.1 圖像預(yù)處理
圖像預(yù)處理主要包括去噪和二值化,通過預(yù)處理后的圖像便可得到待識別字符的特征矩陣。對圖像而言,常見噪聲有兩種,一種是高斯噪聲,即概率密度函數(shù)服從高斯分布的噪聲;另一種是隨機出現(xiàn)的脈沖噪聲,在圖像上表現(xiàn)為無規(guī)律分布的白點或黑點。首先利用imnoise函數(shù)對示例圖像分別加入這兩種噪聲。imnoise(f,′gaussian′,m,v)為加入高斯噪聲的程序語句,其中f為輸入圖像,單引號內(nèi)部為所需添加噪聲的類型,m和v分別為所加高斯噪聲的均值和方差。imnoise(f,′salt&pepper′,d)為加入脈沖噪聲的程序語句,其中d為脈沖噪聲的噪聲密度。對每種噪聲都采用中值濾波和算術(shù)均值濾波兩種方法做去噪處理,并對比效果,如圖2所示。核心程序語句及去噪效果如下:
img=imread(′程序?qū)崿F(xiàn)方法舉例.jpg′);
I_gray=rgb2gray(img);%轉(zhuǎn)換為灰度圖
I_GaussNoise=imnoise(I_gray,′gaussian′);%加入高斯噪聲
I_SaltPepperNoise=imnoise(I_gray,′salt & pepper′,0.02);%加入脈沖噪聲
g1=medfilt2(I_GaussNoise);%中值濾波
g2=medfilt2(I_SaltPepperNoise);%中值濾波
i=[111;111;111];
i=i/9;%定義9點模板
g3=conv2(I_GaussNoise,i);%算術(shù)均值濾波
g4=conv2(I_SaltPepperNoise,i);%算術(shù)均值濾波

圖2 高斯噪聲及脈沖噪聲處理效果對比圖
由圖2可知,對高斯噪聲而言,中值濾波處理能力不及算術(shù)均值濾波,但對脈沖噪聲處理而言,中值濾波比算術(shù)均值濾波的效果好很多,故對不同類型噪聲需選取不同去噪方法,多次濾波往往效果更好。
經(jīng)去噪的圖像即可轉(zhuǎn)為二值圖以作后續(xù)處理。首先利用graythresh函數(shù),利用最大類間方差法找到二值化圖片的最佳閾值,再利用im2bw函數(shù)將原圖轉(zhuǎn)為二值圖。
img=imread(′已去噪圖像.jpg′);
I_gray=rgb2gray(img);%轉(zhuǎn)換為灰度圖
thresh=graythresh(I_gray);%最大類間方差計算閾值
I_bw=~im2bw(I_gray,thresh);%灰度圖轉(zhuǎn)二值圖
二值化后圖像如圖3(a,b)所示。

圖3 圖像預(yù)處理及圖像切割效果圖
2.2 圖像切割
圖像切割分字符切割和邊界拓展兩部分,橫縱兩方向進行。考慮到手寫習(xí)慣都是由左至右橫向書寫,因此首先按行對圖像進行遍歷后可剪裁掉不包含字符信息的空白行,然后利用bwlabel函數(shù),按8連通來識別連通區(qū)域,再分別對各連通區(qū)域進行切割,以得到單字符圖像。
由于切割是沿字符邊緣進行的,為提高后續(xù)模板比對的準(zhǔn)確率,我們對切割后的圖像做邊界拓展,使字符信息位于圖像正中并沿上下左右四個方向分別外延相同像素點,再用imresize函數(shù)對圖像尺寸做歸一化處理。具體程序語句如下:
[a,b]=size(I_bw);
k=1;
for i=1:a
temp=sum(I_bw(i,:));
if temp==0
backline(k)=i; k=k+1; %橫向切割去除上下白邊
end
end
I_bw2=I_bw;
I_bw2(backline,:)=[];
[L,Ne]=bwlabel(I_bw2);
for n=1:Ne%縱向切割分割單一字符
[r,c]=find(L==n);
n1=I_bw2(min(r):max(r),min(c):max(c));
[height,width]=size(n1);
h=fix(height/3);w=fix(width/3);
n2=zeros(2*h+height,2*w+width);
for i=1:height%邊界拓展及尺寸歸一化
for j=1:width
n2(h+i,w+j)=n1(i,j);
end
end
strname1=[′num′,num2str(n),′1′]; strname2=[′num′,num2str(n),′2′];
strname1=imresize(n1,[50 50]); strname2=imresize(n2,[50 50]);
end
程序運行結(jié)果如圖3(c,d,e)所示。
2.3 字符識別
經(jīng)圖像預(yù)處理、切割及尺寸歸一化后便可得到單一字符的特征矩陣。特征矩陣中只有0和1兩種元素,再利用corr2函數(shù)逐一對特征矩陣及字庫模板做相關(guān)性分析,相關(guān)性最高的模板便為字符信息。
3 字符識別在物化探資料整理中的應(yīng)用
本文借助以上基于MATLAB編寫的字符識別程序,以大別山區(qū)某項目土地質(zhì)量地球化學(xué)調(diào)查中的野外采樣記錄卡為處理對象,從手寫區(qū)范圍標(biāo)記、識別區(qū)剪裁、文字識別以及電子表格自動填寫四個步驟,系統(tǒng)編寫了由原始表格到電子表格的自動轉(zhuǎn)化程序,大大提高了資料整理的工作效率。
3.1 手寫區(qū)范圍標(biāo)記、識別區(qū)剪裁及文字識別
由于野外記錄表格式固定,首先利用鼠標(biāo)交互方式,調(diào)用getPosition函數(shù)獲取手寫區(qū)的范圍及其坐標(biāo)位置,并保存至模板文件。具體語句如下:
Mat=imread(′表格模板.jpg′);
imshow(Mat);
for i=1:43
mouse=imrect;
pos(i,:)=getPosition(mouse);% x1 y1 w h
ROI.pos(i,:)=[pos(i,1) pos(i,2) pos(i,3) pos(i,4)];
CutPic=imcrop(Mat,ROI.pos(i,:));
imwrite(CutPic,[′./temp/num′,num2str(i),′.jpg′]);
end
獲得了手寫區(qū)范圍模板文件后便可利用CutPic函數(shù)對識別區(qū)進行剪裁,圖4上方為手寫的野外記錄表,下方為通過程序自動剪裁得到的單個單元格的圖像。保存單個單元格圖像,依次進行識別即可得到表格中各記錄屬性的內(nèi)容。

圖4 識別區(qū)剪裁效果圖
以輸水方式屬性為例,切割后的圖片經(jīng)上述各過程后可得到單個字符的特征矩陣,其中紅色標(biāo)記的位置即為二值化處理后賦有文字信息的像素點,可看到單個字符的特征矩陣能很好地反應(yīng)字符信息,具體效果如圖5所示。在此基礎(chǔ)上進行模板比對即可得到對應(yīng)字符內(nèi)容。

圖5 文字剪裁及特征矩陣獲取
3.2 電子表格填寫
通過以上字符識別已得到各屬性的內(nèi)容,將其寫入電子表格中即可完成手寫表格到電子表格的轉(zhuǎn)換。利用xlswrite函數(shù)即可完成這一過程,具體程序代碼如下:
samplename=[′化探表格模板.xls′];
pointNum=cellstr(ROI.text(7));
newfilename=[pointNum,′.xls′];
copyfile(samplename,newfilename);
for i=1:size(ROI,1)
a=floor(i/3);
b=mod(i/3);
c=[′A′,′B′,′C′,];
position=[c(b),num2str(a)];
xlswrite(newfilename,cellstr(ROI.text(i)),′Sheet1′,position);
end
4 結(jié)論及討論
MATLAB因其強大的數(shù)據(jù)處理功能在各行業(yè)得到了廣泛應(yīng)用。本文以MATLAB編程語言為基礎(chǔ),利用光學(xué)字符識別(OCR)的方法實現(xiàn)了字符識別這一過程。以土地質(zhì)量地球化學(xué)調(diào)查的野外記錄表為例,證明通過MATLAB實現(xiàn)手寫表格到電子表格的快速轉(zhuǎn)化。但是由于不同作業(yè)人員字跡的多樣性,使得字符識別的準(zhǔn)確性受到了一定影響,可進一步優(yōu)化字符識別算法以及擴大模板字庫量兩個方面來解決識別準(zhǔn)確率不夠高的問題。
