小目標檢測技術研究綜述
2021-01-11 09:12:00王慶瑋李傳秀
計算機工程與應用 2021年1期
梁 鴻,王慶瑋,張 千,李傳秀
中國石油大學(華東)計算機科學與技術學院,山東 青島266580
計算機視覺起源于20 世紀80 年代的神經網絡技術,并在近幾年得到迅速發展[1]。計算機視覺主要是代替人眼進行圖像的分類[2]、檢測[3]以及分割[4],從工程的角度看它可以使基于人類視覺的任務實現自動化。目標檢測作為計算機視覺的核心任務之一,主要對圖片中所包含的多個不同的物體進行定位并給出其相應的邊界框[5-6]。目標檢測技術已經廣泛應用于人臉檢測[7-9]、自動駕駛[10-11]、工業生產[12-13]、航空航天[14-16]等領域。如圖1所示,目標檢測算法包括傳統的目標檢測算法和基于深度學習的目標檢測算法。
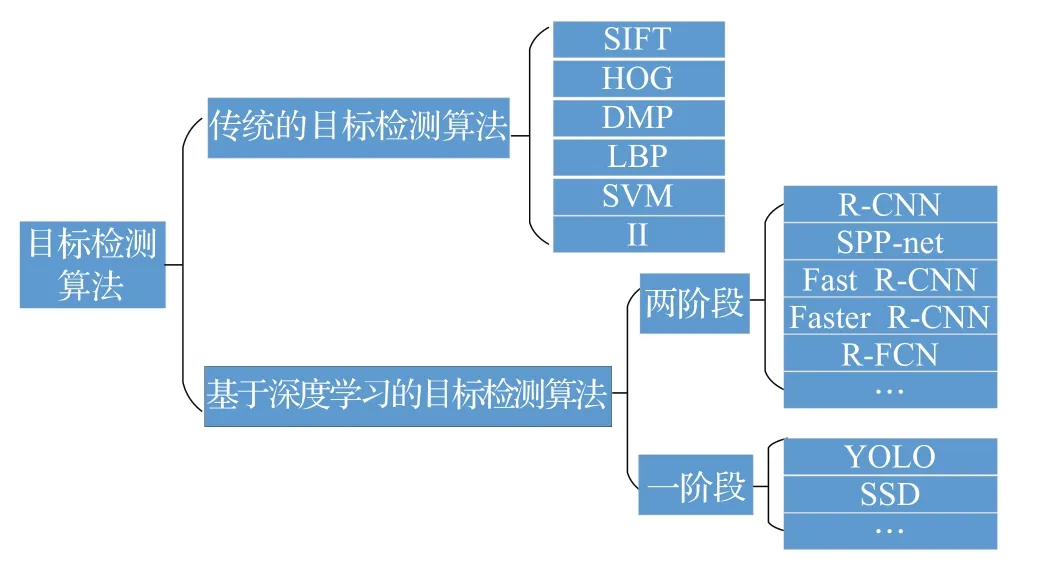
圖1 目標檢測算法分類
傳統的目標檢測算法利用大小不同的滑動窗口選擇出圖像中可能存在目標的候選區域,然后使用手工設計的特征對這些區域進行特征提取,包括尺度不變特征變換(Scale-Invariant Feature Transform,SIFT)[17]、方向梯度直方圖(Histogram of Oriented Gradient,HOG)[18]、可變形的組件模型(Deformable Part Model,DPM)[19]、局部二值模式(Local Binary Pattern,LBP)[20]等特征,最后將圖像特征送到支持向量機(Support Vector Machine,SVM)[21]或迭代算法(Adaptive Boosting,Adaboost)[22]等分類器中進行分類并輸出結果。由于傳統的目標檢測方法受滑動窗口大小和步長的影響,同時手工很難完美的構造出通用特征,場景不同用到的特征就會不同,存在著像窗口冗余、可遷移性差、時間復雜度高等不可避免的問題[23-24]。
1988 年,LeNet[25]作為第一個真正意義上的卷積神經網絡模型被提出,為現代卷積神經網絡奠定了基礎,但由于當時條件限制,計算機硬件水平無法滿足訓練卷積神經網絡的計算量,相比于傳統的目標檢測效果并沒有飛躍的提升。直到2012 年,AlexNet[26]網絡獲得大規模視覺識別挑戰賽(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)的冠軍,人們才開始認識到卷積神經網絡在計算機視覺上的優勢,此后傳統的目標檢測方法停滯不前逐漸退出了圖像檢測領域。
2014 年,Girshick 等人[27]提出的R-CNN 是利用候選區域和卷積神經網絡進行目標檢測的開山之作。此后,基于深度學習的目標檢測方法主要分為兩大類:像R-CNN、SPP-net[28]、Fast R-CNN[29]、Faster R-CNN[30]、RFCN[31]等屬于基于候選區域的兩階段(Two Stage)目標檢測算法。這類算法首先通過邊界框搜索算法[32]或選擇性搜索算法[33]生成一系列相應的候選區域,然后利用卷積神經網絡從原圖像中提取特征進行分類和定位。兩階段算法需要對每一個可能包括物體的候選區域進行檢測,在物體檢測和定位精度方面占有優勢,但隨之帶來的問題是時間復雜度較高;像YOLO[34]、SSD[35]等屬于基于回歸的單階段(One Stage)目標檢測算法。這類算法將目標檢測作為回歸問題,不需要在圖像中生成待檢測候選框,通過回歸模型直接得到目標的類別概率和位置坐標值[36]。單階段算法在速度和時間效率上要優于兩階段算法,但會造成檢測精度的下降。
針對目標檢測中小目標檢測精度低、效果不理想等問題[37],國內外眾多學者開始致力于研究小目標檢測技術。一些建立在現有目標檢測基礎之上的優化改進方法不斷被提出,在一定程度上減少了對小目標進行檢測時出現的漏檢誤檢情況,提高了小目標的檢測效果。本文通過分析基于深度學習的目標檢測技術實際研究情況,介紹了小目標的尺度定義以及存在的技術難點,并對小目標檢測技術的相關改進及技巧進行分類闡述,最后對小目標檢測進行了總結與展望。
1 小目標尺度定義及技術難點
1.1 小目標尺度定義
目前國際上關于小目標的概念還未有明確的定義。微軟公司提出的MS COCO 數據集[38]中對小目標進行了絕對尺度的界定,當目標區域面積小于32×32個像素值時被認為是小目標;另外一種是相對尺度的定義,即目標尺寸的長寬占原圖尺寸的0.1 時為小目標。所以,對于一幅416×416 分辨率的圖像,從絕對尺度講圖像中具有20×30像素值的小鳥算作小目標,從相對尺度講圖像中一輛具有100×100 像素值的汽車也可以算作小目標。
1.2 小目標檢測技術難點
表1為MS COCO實例分割挑戰賽前十結果,表中APS、APM、APL三列的AP(Average Precision,平均精度)值分別代表MS COCO數據集中小尺度目標、中尺度目標、大尺度目標的實例分割平均精度值。可以看出小尺度目標的AP 值永遠是最小的那個且僅為大尺度目標AP 值的一半左右,小目標的檢測性能與中尺度以及大尺度目標相比仍存在著不可忽視的差距。
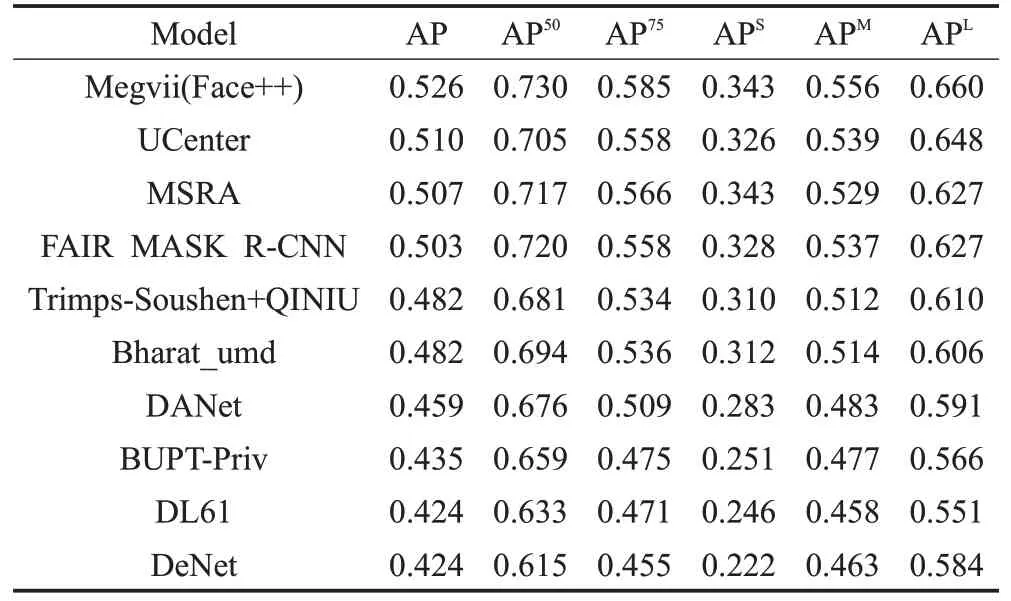
表1 MS COCO實例分割挑戰賽前十結果
下面通過列舉小目標檢測中存在的主要技術難點,來說明造成小目標檢測性能較差的諸多因素。
(1)缺少較大規模的小目標數據集的支持。目前用于圖像分類、檢測、分割等任務所用到的公共數據集,如MS COCO系列、ImageNet[39]、PASCAL VOC[40]系列大多是針對通常尺度大小的目標進行檢測。PASCAL VOC數據集中待識別的20類物體大部分屬于大尺度或者中尺度目標,和PASCAL VOC相比,MS COCO數據集中含有部分小尺度目標,但平均每幅圖片包含實例目標數量多,導致小目標的分布并不均勻。此外,像WIDER FACE[41]、FDDB[42]數據集是專門針對小人臉檢測構建的數據集,DOTA[43]、UCAS-AOD[44]數據集是用于航拍圖像中小物體的數據集,不具有目標檢測的通用性。
(2)復雜環境對小目標檢測造成的干擾。目前小目標檢測大多依托具體場景而存在,像軍事監控[45]、航空海面[46]、油田井場[47]等復雜作業領域。在復雜的背景噪聲下,小目標的信息會被其他較大物體噪聲所掩蓋,或與背景融為一體缺少明顯的圖像對比度[48],這也是造成小目標檢測困難的因素之一。
(3)小目標分辨率低、像素占比少。對于小目標來說,其自身固有的低分辨率、僅占幾個或幾十個像素值等特性使其在目標檢測時能提取到的有效信息十分有限,這是造成小目標檢測效果差的根本原因。因此,在實際應用中,如何準確檢測出煙頭、手機、小尺度人臉等對于小目標檢測技術來說極具挑戰性。
(4)卷積神經網絡對小目標的特征提取存在瓶頸。對于目前通用的目標檢測模型來說,為了增大感受野都會經過幾次下采樣操作,同時對特征進行不斷降維縮小特征圖[49],但是由于小目標邊緣信息模糊、語義信息少,經過CNN后導致小物體信息損失嚴重甚至無法傳入目標檢測器中。
2 小目標檢測方法研究
針對文中上述提到的小目標檢測存在的主要技術難點,國內外學者開始致力于研究基于深度學習的目標檢測技術在涉及小目標檢測方法上的相關改進及技巧。
2.1 數據增強
針對小目標分辨率低、數據集的數量匱乏及分布不均勻等問題,研究表明對小目標做數據增強可以提高對小目標的檢測效果。通過對訓練集進行處理使其滿足小目標檢測所需的規模要求,然后采用不同的方法對數據進行處理使其達到數據增強的效果。
對輸入圖像做水平豎直方向的翻轉旋轉、隨機裁剪、形狀變化、圖像縮放平移、顏色變換等[50-52]方法能在一定程度上提升模型在目標檢測上的泛化性能。當圖像中目標方向的改變不會影響其本身語義時,翻轉和旋轉是幾何變換類中最常見的數據增強方法,但如在交通標志或數字識別中,“左轉”和“右轉”標志及數字“6”和“9”等數據的翻轉旋轉會賦予其錯誤的語義標簽,此類方法便不再適用。對于大多數要求輸入圖像尺寸相同的網絡模型,裁剪能將訓練集中輸入尺寸不同的數據固定為統一大小。圖像的形狀變化、縮放平移會造成圖像失真,改變圖像目標的位置或者占比,如果在圖像背景色調相對單一或者進行目標中心檢測時可以添加此類增強方法,但適用性不高。顏色變換可以均衡圖片光線和色調,突出圖像目標,但不建議應用于數據本身對顏色依賴性強敏感度高的任務中。對于上述的數據增強方法,具體使用哪種方法,使用順序及次數是多少,如何組合才能達到最優的增強效果都值得探索。Google Brain 團隊提出通過生成數據增強搜索空間[53],針對不同數據集自動化組合數據增強的方法,以此替代通過先驗知識進行人為選取的方法。使用增強學習[54]作為搜索算法,將每兩種圖像的增強方法組合在一起作為一個子策略,按順序隨機分配給輸入的每幅圖片,并對該子策略的應用概率和幅度加以輔助。利用這種自動化搜索法豐富了數據集的多樣性,對數據集有良好的遷移性能,為小目標檢測提供了一種可以參考的數據增強方式。
當簡單的基于基本圖像處理的增強方式無法起到顯著的效果,增加圖像中小目標的樣本數量是一種有效的數據增強方法。Kisanta等[55]提出使用過采樣(Oversampling)和增強(Augmentation)的數據增強方法。首先通過調整訓練集中小目標圖像的數量使其達到訓練所需的樣本需求,再對圖像中的小目標進行處理,先調整目標尺度(縮放范圍為±20%)后進行旋轉(旋轉范圍為±15°),復制后進行三次粘貼并保證不會覆蓋已有目標的位置。通過這種方式使得圖像中小目標數量增加,實驗結果顯示小目標的實例分割精度提高了9.7%,目標檢測精度提高了7.1%。網絡不再偏向于大尺度及中尺度目標,小目標對模型訓練時產生的損失貢獻更高,以此實現不同尺度目標之間的預測質量平衡。當小目標分布不均勻,且在訓練時GPU 硬件條件有限時,YOLOv4[56]提出的Mosaic方法可以為小目標檢測提供了一種新的數據增強方式。在每個批次訓練時,隨機將四張圖像進行縮放,然后隨機拼接成一張原圖尺寸大小的圖像。與此同時,Chen 等[57]同樣提出一種將圖像進行拼接的Stitcher 方法,不同的是在對圖像拼接時隨機使用的四張圖像具有相同的尺寸。通過這種將四張不同語義信息拼接在一起的方式,大尺度和中尺度目標縮小為中尺度和小尺度目標,在沒有帶來明顯計算量的同時,不僅增加了小目標的數量,豐富了小目標在訓練集中的分布,也使模型的檢測魯棒性有所提升。
提高圖像分辨率作為一種數據增強方式也可以為小目標檢測提供更多的細節信息。對于一幅低分辨率圖像,如果單純地對圖像進行放大,試圖獲取更大尺度的目標,圖像可能會存在鋸齒、模糊的情況。隨著超分辨率技術的不斷發展[58-59],將低分辨率的圖片重建生成高分辨率圖[60]被應用于小目標檢測領域。2013年,Yang等人[61]提出一種基于局部圖像結構超分辨率法對小目標人臉進行檢測,將人臉分為面部器官、輪廓、平滑區三部分,對于給定的低分辨率(Low Resolution,LR)目標,通過圖像匹配選取與器官最相似的樣本,產生顯著的邊緣結構以及使用塊匹配生成目標細節,以此來對LR 目標進行重建生成高分辨率(High Resolution,HR)目標。2016 年,谷歌提出一種名叫RAISR[62]的超分辨率技術,將大量低分辨率圖片以及對應的高分辨率圖片送給卷積神經網絡去學習兩者之間存在的映射關系。當圖像質量得到增強,高分辨率的小目標數據集能為卷積網絡提供更豐富的細節信息,對后續的小目標檢測也能起一定推動作用。
數據增強能夠在小目標檢測中緩解小目標數據集不足、小目標數量不多、小目標數據集質量不高等因目標數據引起的問題。現有的卷積神經網絡模型在進行圖像分類或識別等任務時,幾乎都利用了數據增強手段,通過大量的數據避免模型出現過擬合的現象。在選擇此類方式時,要保證增強后的數據和原始數據在特性及語義方面保持一致,作為一種簡單直接的提高模型性能的可遷移方式,可以根據上述不同應用條件設計出不同的增強方式應用于小目標檢測。
2.2 多尺度特征融合
現有的絕大多數小目標檢測方法都是基于卷積神經網絡對特征進行直接提取。卷積神經網絡的淺層網絡感受野小,空間分辨率較高目標位置準確,適合檢測小目標,但是特征的語義信息表征能力弱,召回率低[63];深層網絡雖然感受野大提取的語義信息越來越豐富,但由于小目標本身像素占比少,一般經過幾次下采樣處理后特征圖不斷減小,如當步長Sride為16時,32×32大小的區域在特征圖中只有2×2大小,用于檢測小目標的有效區域無法辨別。因此,利用卷積神經網絡對特征進行直接提取可能會導致小目標的信息丟失,不利于對目標的定位[64-65]。如果兩者能夠取長補短進行融合,那么既能利用淺層網絡的細節信息又能結合深層網絡的語義信息,在得到較高召回率的同時對目標進行準確的分類和定位。
為能充分地將不同尺度的特征圖進行融合以此解決卷積神經網絡在特征提取時的瓶頸,文獻[66]中Bell等人以Fast R-CNN為基礎網絡,提出一種Inside-Outside模型。Inside-Net提取Conv3、Conv4、Conv5卷積層對應的特征,通過對不同尺度的特征圖進行連接,結合多個淺層特征圖從而獲得細粒度特征,以此實現多尺度特征的融合;Outside-Net 通過使用兩個循環神經網絡(Recurrent Neural Networks,RNN)[67]網絡組成IRNN結構充分利用視覺識別中的上下文信息。實驗結果顯示,在COCO 數據集中小目標平均準確率從4.1%提高到7.0%,平均召回率從7.3%提高到10.7%。文獻[68]同樣結合RNN 網絡提出RBC 框架,能夠將特征圖中聚合的上下文信息逐漸引入到邊界框回歸器中,在IOU閾值達到0.7 的條件下有效地對大目標和小目標進行檢測,在具有挑戰性的KITTI 車輛數據集檢測中獲得了最優的比賽結果。文獻[69]中Eggert等人和文獻[70]中Chen等人分別通過分析Faster R-CNN在小目標檢測方面的不足,通過對候選區域生成網絡進行改進,利用具有高分辨率的底層特征及上下文信息,相比于Faster RCNN可以更好地檢測小目標。文獻[71]中Kong 等人提出RON框架,在對多尺度目標進行定位時,使用反向連接的方法將具有細粒度信息的淺層特征和具有豐富語義的深層特征結合起來,通過多尺度表征的方式實現對不同尺度大小目標的檢測,豐富淺層特征的語義信息使其更有效的對小目標進行檢測。
圖2 為幾種常見的特征金字塔多尺度融合方式。FPN[72]網絡模型的提出在一定程度上解決了多尺度檢測問題,在沒有帶來明顯計算負擔的情況下增強了特征的表達能力,在小目標檢測中取得了很大的進步。如圖2(a)FPN尺度融合所示,通過FPN網絡得到不同尺度的特征映射后,采用自頂向下和橫向連接的方法,頂層的特征圖在經過上采樣后與下一層尺度大小相同的特征圖進行融合,預測在特征融合后的每一層中獨立進行。文獻[73]通過改進Faster RCNN網絡提出一種HyperNet模型,如圖2(b)HyperNet尺度融合所示,將通過反卷積進行上采樣的深層特征、中間層特征以及進行下采樣的淺層特征整合到一起,作為Hyper特征用于生成候選區域和目標檢測。HyperNet 通過將多層特征進行優勢互補融合為一起,在生成高質量的候選區域的同時相比于Faster RCNN更擅長處理小目標。
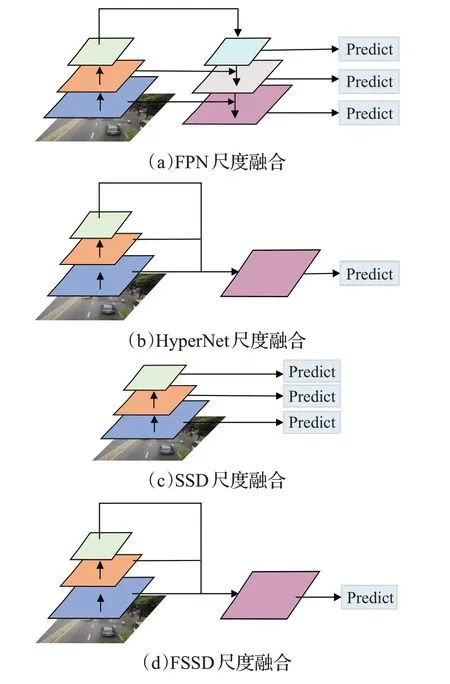
圖2 幾種常見的特征金字塔多尺度融合方式
SSD[35]在對不同尺度大小的目標做預測時使用了不同層的特征信息。如圖2(c)SSD尺度融合所示,SSD使用淺層信息預測小目標,高層信息預測大目標,但淺層語義信息表達能力弱,能學習到的語義信息十分有限。此后,為了更好的基于SSD 檢測小目標,通過尺度融合借助上下文信息改進SSD 的方法不斷被提出。文獻[74]提出的DSSD模型在網絡的后端使用了多個反卷積層[75]進行上采樣,與SSD后面的卷積網絡形成“寬-窄-寬”的非對稱沙漏結構,通過與淺層網絡的輸出進行融合使網絡各層間的語義信息相互結合,在一定程度上減少了SSD 在小目標檢測時出現的誤檢和漏檢情況。文獻[76]提出的FSSD模型可以看作是SSD模型和FPN模型的結合,如圖2(d)FSSD 尺度融合所示,FSSD 模型將不同尺度的特征圖雙線性插值[77]調整為相同尺度后進行融合,然后基于此融合后的特征層下采樣生成特征金字塔結構,進行后續每層特征圖的預測。文獻[78]提出R-SSD 模型,采用結合下采樣、反卷積的方式增加不同特征之間的聯系,將不同層的特征圖調整為同樣尺寸后在淺層的特征圖上融合高層語義信息,從而增強特征的表達能力。文獻[79]提到的RefineDet 將Faster R-CNN和SSD 進行結合,同時引入類似FPN 網絡的特征融合方法,也有效地提高了算法對小目標的檢測精度。
YOLO 系列中的YOLOv2[80]和YOLOv3[81]以及最新的YOLOv4 同樣使用了特征融合的思想。YOLOv2 對于輸入的416×416 尺寸的圖片,借助pass-through layer將淺層26×26×512 維度的特征圖疊加特征連接到深層13×13×2 048 維度的特征圖中,最后在13×13 大小的特征尺度進行預測。為了更好地檢測小目標,YOLOv3繼續沿用YOLOv2 特征融合的思想并加以改進。同時,YOLOv3與類似于FPN的網絡結構相結合,不同于FPN網絡的是YOLOv3 經過上采樣后的特征之間進行的是通道方向的拼接。對于輸入為416×416 尺寸的圖片,YOLOv3 預測時針對大、中、小尺度目標對3 個尺度特征層(分別為13×13,26×26,52×52)進行圖像細粒度特征融合,融合時借助52×52大小的淺層特征圖對檢測小目標非常有用。相比于YOLOv2算法,YOLOv3從單層預測5 種Bounding Box 變成每層預測3 種Bounding Box 且從不同的三層尺度特征圖中獨立進行,YOLOv3通過上采樣高層特征與低層高分辨率特征相融合,在平均精度均值mAP0.5及小目標平均精度APS上取得了不錯的效果。YOLOv4 在對特征進行融合時在FPN 的基礎上提出改進的路徑聚合網絡PAN。考慮到淺層特征需要經過多層網絡才可以傳遞到FPN網絡的頂部,為了更好地獲得淺層網絡的細粒度特征和準確的定位信息,PAN在FPN層的后面添加了自下而上的特征金字塔,縮短了特征傳遞的距離。
此除此之外,2017 年Najibi 等人[82]提出SSH 模型,利用多尺度模塊分別對大、中、小目標進行檢測,不同尺寸的目標對于不同步長的檢測模塊,使用步長為8的檢測模塊通過特征融合及維度縮減的方式對小目標進行檢測,同時通過擴大感受野使用多個3×3的卷積核引入上下文信息。文獻[83]中提出通過構建稀疏離散圖像金字塔結構從而融合多層特征,引入小目標周圍的上下文信息生成具有固定感受野的多尺度模板。相比于不添加上下文信息,通過3倍擴充檢測窗口檢測效果有所提升;通過添加300像素固定感受野使得小目標檢測誤差減少了20%,由此可見充分利用上下文信息有利于輔助卷積神經網絡檢測小目標。
多尺度融合的方法主要是為了在增加小目標語義信息的同時豐富小目標的細節信息,對目標進行更加準確的分類和定位,以此提高小目標檢測效果。但由于不同檢測場景下的小目標的細節信息和語義信息各不相同,導致多尺度融合的方法存在著可遷移性差的問題,即在某種場景下使用的多尺度融合網絡可能并不適用于其他場景下的小目標檢測。因此,在具體場景進行小目標檢測時,還需要根據小目標尺度大小、特征信息多少等情況來具體選取合適的網絡進行多層神經網絡的多尺度融合。
2.3 錨框(Anchor)設計
在引言部分提到傳統的目標檢測算法大多受滑動窗口的影響,需要逐位置的遍歷滑窗產生不同的預設邊框。隨著深度學習的出現,錨框最初應用于Faster RCNN[30]模型,在一定程度上解決了遍歷滑窗時造成的效率低等弊端。Faster RCNN 模型利用RPN(Region Proposal Networks,候選區域網絡)生成候選檢測框時,對于最小尺度為128×128的Anchor,其候選框平均大小要超過100×100,也就是設置的最小Anchor都要比待檢測的小目標大很多,但如果為了檢測小目標考慮將輸入圖像放大來匹配Anchor 時,可能會導致大目標不斷放大從而沒有對應的Anchor 進行檢測。因此,從Faster RCNN 入手考慮對不同尺度的目標檢測時,設計的Anchor要盡可能的覆蓋訓練集中的所有目標,也就是為每個目標都能匹配到一個或多個Anchor。
隨著錨框技術的提出,Anchor 在SSD、YOLO 等主流目標檢測網絡中得到了廣泛的應用。為了更好地檢測小目標,SSD 針對不同的卷積層設計了不同尺寸的Anchor,對于淺層卷積Conv4_3 使用尺度為60 的6 種不同比例的小Anchor,對于深層卷積Conv10_2 及Conv11_2 使用尺度為{228,270}的4 種不同比例的大Anchor。通過這種在訓練中根據目標尺度大小設置Anchor的方法,兼顧到小目標擁有的Anchor小且密集,大目標擁有的Anchor 大且稀疏,使SSD 相比于Faster RCNN 獲得了更好的小目標檢測效果。YOLO 利用全連接層的數據完成邊框預測[34],將物體檢測作為回歸問題,但YOLO 會導致丟失較多的空間信息造成定位不準,不擅長對密集的小物體檢測。YOLOv2[80]摒棄掉全連接層,引入Anchor 機制來預測Bounding Box。為了能有效減少初始損失,YOLOv2沒有直接使用手工設計錨框尺寸,而是通過K-means 算法對訓練集進行聚類[84]。通過聚類找到更符合數據集中目標大小分布特性的錨框尺寸,在一定程度上降低了邊框回歸的難度,收斂速度更快,更有助于網絡訓練。YOLOv3[81]同樣利用聚類得到9個Anchor取代YOLOv2的5個Anchor,在特征圖上小錨框的尺寸可以小至10×13,通過聚類平衡模型的復雜度和IOU 面積,對小物體檢測性能有所提升。此后出現的YOLOv4 也同樣借用了YOLOv3 的錨框機制。
此外,在主流目標檢測框架的改進算法中同樣用到了Anchor 提高小目標檢測精度。文獻[85]中通過分析小尺度目標與預訓練模型尺度之間的關系,提出的SNIP框架對Anchor進行篩選,如果Ground Truth框位于給定的候選區域范圍內,那么就判定為有效框(Valid Box),否則就為無效框(Invalid Box);如果Anchor 和某個Invalid Box 的重疊部分超過0.3,此Anchor 被判定為Invalid Anchor。同時SNIP 引入多尺度訓練,對應3 種不同分辨率的圖像。在訓練時不對Invalid Anchor進行反向傳播,而是有選擇的挑選大小合適的目標進行梯度更新。因此,小目標總有機會落在合適的尺度范圍內參與訓練,以此實現目標尺度和特征的歸一化,提高小尺度物體的檢測效果。文獻[86]為了提高小目標的召回率,同樣提出一種新的稠密錨框策略。具體來說,Adensity=Ascale/Ainterval,其 中Adensity代 表Anchor 的 密 度,Ascale代 表Anchor 尺度,Ainterval代表Anchor 間隔。Ascale分別為32×32,64×64,128×128,256×256,512×512,Ainterval默認為32,32,32,64,128,則Adensity的值為1,2,4,4,4。顯然,在不同尺度上Anchor 的密度是不一樣的,在淺層網絡上的小尺度錨框相比于深層網絡的大尺度錨框要更稀疏。針對錨框密度不均衡的問題對淺層的小錨框進行密集化,例如對32×32的小尺度Anchor進行四倍的稠密化,保證不同尺度的Anchor具有一樣的密度,以此提高小尺度目標召回率。文獻[87]同樣從Anchor角度出發,在網絡模型中通過增大特征映射尺度來降低與特征映射相關的Anchor 的采樣步長,以及在原有預定義的Anchor中心周圍增加Anchor密度,使得與小目標Ground Truth 匹配的Anchor 數量增多,彌補了對小目標檢測性能差的不足。文獻[88]指出基于Anchor 的小目標人臉檢測效果并不理想,如圖3 目標匹配差異圖所示,感受野、設計的Anchor 及小目標人臉之間存在著不匹配問題,小目標的尺寸遠小于設計的Anchor。由于Anchor尺寸并不是連續的,而人臉的尺寸是連續的,這樣會導致在某一設定的范圍內可利用的Anchor 數量減少,過小或過大的目標無法匹配足夠多的Anchor。如果一味的增加Anchor 用于檢測小目標,由此帶來的負樣本數量的增加對于檢測效果并不理想。因此,對不同特征層設置不同尺度的Anchor以此解決Anchor可用數量缺少的問題,對Anchor 的尺寸進行等比例間隔調整設置大小從16到512,使Anchor的尺度值大致可以覆蓋有效感受野的范圍,確保每個特征層都有相對應的Anchor,滿足不同尺寸的目標都能匹配到合適的Anchor進而進行檢測。
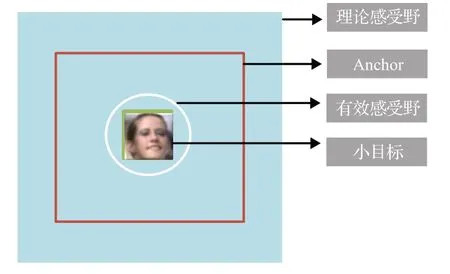
圖3 目標匹配差異
錨框設計被廣泛的應用于小目標檢測,通過設計更符合數據集中目標大小分布特性的錨框,使錨框的尺度值大小盡可能的匹配覆蓋有效感受野的范圍,以此提高小目標的召回率,提升小目標檢測效果。但由于小目標檢測場景通常比較復雜、小目標類型眾多,適用于檢測某種小目標的錨框可能并不適合用于檢測其他小目標;而如果增加錨框的數量來檢測不同類型、大小的小目標,會導致負樣本數量增加,造成誤檢率的提高。
2.4 IOU閾值匹配
交并比IOU(Intersection Over Union)是指目標預測邊界框和真實邊界框的交集和并集的比值,即物體Bounding Box與Ground Truth的重疊度[89],IOU的定義是為了衡量物體定位精度的一種標準。在目標檢測中IOU的閾值默認設置為0.5,即只要IOU大于等于0.5就會被認為是正樣本。如果IOU閾值設置較低,樣本的質量就難以保證;為了獲得高質量的正樣本,可以調高IOU閾值,但樣本數量就會降低導致正負樣本出現比例不平衡[90],且較高的IOU閾值很容易丟失小尺度目標框。
針對上述問題,文獻[91]提出了多階段級聯結構,通過不斷調高IOU 的閾值使其在保證樣本數量的同時不影響樣本的質量,最后訓練出了高質量的Cascade R-CNN 檢測器。在3 個檢測模型階段逐步提高候選框的IOU閾值(閾值分別為0.5、0.6、0.7),當候選框閾值和訓練閾值較為接近的時候,每經過一次回歸樣本就會越接近Ground Truth值以此適應多級分布,從而使前一個階段重新采樣過的候選框更能適應下一階段,在解決訓練出現的過擬合的同時獲得滿足對應閾值的樣本,實驗表明在基準檢測器上使用Cascade R-CNN 結構在MS COCO數據集上取得了不錯的檢測效果,對小目標的檢測精度也有所提升。與此同時,Liu 等[92]同樣提出通過提高IOU 閾值來改進小目標行人檢測的思想。在基于SSD 的行人檢測中均使用單一的IOU 閾值進行訓練來定義正負樣本,為避免單階段檢測器的限制性,提出ALF 模塊,采用級聯網絡的思想多步預測進行漸進定位,以ResNet-50 為基礎網絡,分別對原始圖像進行8、16、32、64倍下采樣提取多尺度特征圖,每階段使用回歸的錨框而不是默認的錨框優化預測器,利用不斷提升的IOU閾值訓練多個定位模型產生更精確的定位,解決了單階段檢測模型SSD對行人檢測的局限性,提高了小尺度行人的檢測性能。
上述兩種方法是根據級聯思想,通過不斷提高IOU閾值來獲得高質量的正樣本,能夠在一定程度上提高小目標的檢測效果,但存在隨著IOU 閾值不斷提高,匹配的Anchor數量減少,導致漏檢的問題。而文獻[88]中則是將IOU 閾值從0.5 降到0.35,使用降低閾值的方法先保證每個目標都能有足夠的錨框檢測。同時為了解決正樣本增加導致樣本質量得不到保證的問題,提出最大化背景標簽的方法,在最底層分類時將背景分為多個類別而不是二分類,對IOU 大于0.1 的Anchor 進行排序,并對每個框預測3次背景值,取背景概率中最大的值作為最終背景,通過提高分類難度以此來解決正樣本質量得不到保證的問題,提高了小目標的檢測準確率。但此種方法可能會出現因IOU閾值過低,造成無效的正樣本數量過多,從而導致誤檢率提高的問題。
對于不同的檢測任務,如果待檢測目標尺度之間相差不大,即數據集中大多為同一尺度目標時,可以適當降低IOU閾值再進行選取,對小目標特征實現最大程度的提取。在實際應用中,同一場景下的檢測不可能只包含單一尺度的目標,存在不同目標尺度跨越相差較大的情況,如果固定IOU 閾值進行統一檢測篩選,會帶來樣本不平衡的問題,小目標特征極有可能被嚴格的IOU閾值舍棄。因此,設置動態IOU閾值作為不同尺度目標檢測更具普適性,根據不同的樣本數量動態調整,當負樣本數量過高時不斷提高IOU閾值平衡樣本數量,避免了直接設置過高的IOU閾值而造成的漏檢,訓練出來的模型泛化性更強。
2.5 縮小目標差異
2014 年,Goodfellow 等[93]提出的GAN(Generative Adversarial Net,生成式對抗網絡)核心思想源于博弈論的納什均衡,GAN 成為近兩年深度學習領域比較熱門的研究方向,廣泛應用于圖像超分重建[94-95]、表示學習[96-97]、風格轉移[98-99]等任務中。GAN 網絡主要有生成器(Generator,簡稱G)和鑒別器(Discriminator,簡稱D)兩大組成部分,兩者相互博弈各有各的作用。
對于檢測小目標,文獻[100]提出利用Perceptual GAN 來增強小目標的特征表達。傳統的GAN 中生成器是學習從噪聲分布到數據的映射,而Perceptual GAN則是負責尋找不同尺度物體間的結構關聯,在生成器中通過引入低層精細粒度特征將原來較差的小目標特征轉換為超分辨率的表達形式,使得生成器將小尺度目標以假亂真生成大尺度目標,通過縮小物體間的表示差異使小物體與大物體有相似的特征表示;辨別器用于判別是真實的物體特征還是通過生成器超分生成的特征。兩個子網絡交替訓練最后達到平衡,在對Tsinghua-Tencent 100K 交通標志數據集[101]以及Caltech 行人數據集[102]的檢測中提高了小目標的檢測精度,具有優良的效果。
此外,文獻[103]提出一種多任務生成式對抗網絡MTGAN對小目標進行檢測,此框架可以適用于現有的任何檢測器。生成器G 借助超分辨率網絡生成高質量的圖像,判別器D判別是否為真實的圖片還是超分生成的圖片,同時判別器D的分類損失和回歸損失經過反向傳播回到生成器中,促使生成器G擁有更多的小物體圖像細節信息。兩者通過交替迭代對抗學習的訓練方式,直到G 生成的數據以假亂真使得D 無法準確區分。MTGAN在小目標檢測中AP值相比于基線檢測器Faster-RCNN[30]及Mask-RCNN[104]增加了1.5%。
借助GAN 網絡能夠獲得分辨率高、小目標特征信息明顯的圖像,并且能夠增加數據集的規模,以此提高小目標檢測的效果。但利用GAN網絡進行小目標檢測可能會出現訓練不穩定的問題。具體來說,如果某一次G生成的結果中一些特征得到了D的認可,這時候G就會認為輸出正確,會繼續輸出類似的結果,實際上G 生成的結果并不好,導致最終生成結果缺失特征不全,導致檢測效果不好。因此,利用GAN 網絡進行小目標檢測適用于小目標類型單一、特征信息明顯的場景。
2.6 超參數調優
基于深度學習的模型參數主要分為參數和超參數[105],參數通常在數據中自動獲取,不需要人為設置,而超參數是模型外部的配置變量,通常需要人為設置。超參數主要包括學習率(learning rate)、批量尺寸大小(batch size)、迭代次數(epoch)、隱藏層數目層數、激活函數的選擇、部分損失函數的可調系數以及正則化系數等。超參數調優是基于深度學習進行目標檢測的關鍵一步,在小目標檢測中更是需要借助參數調優組合選取出最優的超參數,進而發揮最大性能更好的檢測小目標。
如表2,分別從實現機制和優缺點方面對手動調整、網格搜索、隨機搜索及貝葉斯優化算法4種超參數調優方式進行分析。
相對于需要一定的知識和先前經驗的手動調整方法,自動超參數調優方法可以更有效地為模型挑選出相對較優的超參數組合,但現有大多數自動超參數調優都未能擺脫固定的網絡模型結構和數據集,自適應調節存在著在某種小目標檢測中獲得的最優超參數組合可能對另一種小目標檢測模型并不適用,仍需要具體模型具體調優的問題。

表2 常見超參數調優對比
3 討論及未來研究趨勢
在上述幾類能有效提高小目標檢測精度的方法中,數據增強作為普適性最好的提高小目標檢測效果的方法,能夠用于不同的場景、不同類型的小目標檢測,普適性較好;多尺度融合、錨框設計、IOU 閾值匹配、超參數調優也能夠用于不同場景下的小目標檢測,但是都存在著一定程度上的可遷移性問題,即在某一場景下設計的多尺度融合策略、錨框、IOU 閾值和超參數組合并不適合遷移用于其他場景;利用GAN 網絡進行小目標檢測則比較適用于具備一定的特殊條件的場景,其普適性較低。
小目標檢測技術雖得到一定的發展但尚未成熟。文中提到的數據增強、多尺度融合等方法能夠在一定程度上解決小目標分辨率低、卷積神經網絡對小目標的特征提取丟失小目標信息等技術難點。但小目標檢測技術仍面臨復雜場景干擾、缺乏數據集支持等挑戰。在針對小目標做改進時如何權衡檢測速度和準確性也需要進一步考慮,做到具有良好的檢測性能的同時降低算法復雜度,提高檢測效率;另外,現有的小目標檢測技術幾乎都是針對特定的場景所設計,如專門針對小人臉識別或者專門針對小交通標志識別,檢測技術的可遷移性較差,無法更好地適應小目標檢測場景的變化。未來關于小目標檢測技術的研究工作中,研究普適性較好的小目標檢測技術,構建大規模的小目標數據集將成為研究重點。此外,研究可遷移性較好的多尺度融合網絡、錨框、超參數組合等對現有的可以提高小目標檢測效果的方法,進行進一步的改進也是研究重點之一。
4 結束語
基于深度學習的小目標檢測是目標檢測領域的重要分支,小目標檢測廣泛存在于智能醫療、人臉識別、工業生產、自動駕駛等各個領域。本文通過分析現有的深度學習目標檢測算法,結合小目標定義及技術難點,然后對國內外學者提出的小目標檢測改進優化方法進行分類總結,分別從數據增強、多尺度融合、錨框設計、IOU 閾值匹配等幾個方面對現有的小目標檢測方法進行闡述,并分析了各類方法的優缺點、適用場景、可遷移性等,最后探討了未來發展趨勢和可能的研究重點。雖然小目標技術目前仍存在較多挑戰,但是隨著對小目標檢測技術的深入研究,以及卷積神經網絡技術的進步,未來期待能夠出現兼備檢測效果和檢測效率,可遷移性強的小目標檢測技術。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
