基于華為云的數據挖掘和展示系統研究
2021-01-12 03:55:04楊杰
無線互聯科技 2020年24期
楊 杰
(山西職業技術學院,山西 太原 030006)
0 引言
大數據時代的來臨,促使各行各業的數據量爆發式增長,數據類型也呈現出多類型、動態化等特點。通過分析海量數據、提取有效數據并展示對于企業發展具有重要指導作用。華為云由于具有良好的數據處理能力和可操作性,成為服務終端的主要應用媒介之一。本文依托華為云的優勢,通過分析海量數據、挖掘提取有效數據并系統展示出來,旨在提高數據處理能力,實現數據的可視化,為用戶提供數據處理、展示的一體化平臺[1]。
1 數據挖掘以及華為云服務器概述
1.1 數據挖掘概念
數據挖掘是基于量化、不全面、離散的數據中,通過采集其中的內在聯系點,挖掘內在的關系網、從而形成潛在的評估思路,進而指導現場作業。所挖掘的數據不僅包括結構數據也包括非結構數據。如圖像、文本以及網絡中的異性數據。所挖掘的方法和思路不僅涉及數理也包括統計分析,主要應用于信息數據維護、管理和優化甚至過程控制[2]。
數據挖掘是基于量化的數據來對行業和領域做出預測分析。其基本的目的是在所在的數據庫中找到數據之間的內在聯系點和關系網。主要有以下幾類功能。
概念分析:主要包括對某類事物和對象內在聯系的描述,并對其特征點進行概況分析。
關聯分析:數據關聯是通過發現數據之間發展的內在規律,從而描述數據之間某些屬性同時出現的模式。如數據之間存在多個對應的數據關系或者具有一定的規律性,則稱此過程為關聯。關聯分析就是基于既定的數據結構中不斷地發展其內在的項集模式知識(又稱關聯規則)[3]。
分類與預測:基于關聯分析的基礎上,對重要的數據集合進行整合和預測評估,此類方法的主要對象是離散的數據點。
聚類分析:通過對內在聯系的數據點進行分類、重組,促使各個單一的數據個體聯系在一起,從而達到數據單元“物以類聚”的目的。
偏差檢測分析:偏差檢測就是從數據已有或期望值中找出關鍵測度顯著變化的那些數據對象。進行偏差檢測時,主要采用的方法是,比較不同觀測結果和不同參照值之間存在的差別。
1.2 華為云服務器
華為云服務器作為知名的數據處理端,使用者根據自身的情況可向華為云的供應商采購相應類型的服務器,因為云服務器通常會虛擬化服務器中的資源數據、計算和儲存,所以使用起來,與通常的物理服務器基本沒有差別。
華為云服務器一般突出自主選擇性,購買者可根據自身情況向供應商購買不同大小、內存、寬帶等配置的服務器。購買者對自己的服務配置不滿意,可以隨時隨地的對服務器進行升級。此外服務器還提供全面的服務,在購買完對應的服務器后,用戶可以自主下載所需要的軟件,并提供病毒檢測以及漏洞修復等功能。由于其CVM部署在云端極大地降低了物理媒介、基礎設施的經濟成本,為企業省下大量資金;最后云服務器克服了傳統的物流服務器在系統配置中由于人為干預而造成的失誤,云服務器提供“重裝系統”,僅僅需要數秒鐘就可以實現系統的重新配置,極大提高了用戶的時效性,云服務器具有便攜的網絡連接服務,在云端可將任何數據信息發布至對應的網絡端,使用者可隨時隨地查看發布信息[4]。
2 基于華為云的數據挖掘
2.1 開發環境
本文借助華為云服務器,配置為1核,內存匹配為1G,寬帶為11Mbps,磁盤容量為20G,此外在云服務器上安裝安全組件端口和ICMP協議。
云服務器上本文適用python3.6.0安裝包,安裝結束后配置對應的環境變量,最后再進行python模塊安裝。
2.2 數據庫
爬蟲和API接口技術所獲取的源數據存放至MySQL數據庫中,該數據庫涵蓋了全國各個省市的數據信息,主要包括了城市名稱、所屬省份、時間和溫度等數據信息,每隔一小時要更新一次數據。
2.3 系統測試
在Windows系統下構建網站并進行檢驗,通過Apache部署后校核云服務器的效果。首先需建立一個Django項目,其次讓 httpd.conf文件監聽 8091端口并設置對應的儲存目標,輸入對應的賬號、密碼后保存信息登陸。
在Django模塊下匹配 request.py文件并在云服務器發布,然后利用網頁工具打開獲得同樣的界面,具體如圖1所示,為了區別服務器和云服務器的差別,Windows使用不同的瀏覽器來進行訪問[5]。
首先在互聯網上借助爬蟲技術和接口技術獲得源數據,數據獲取后保存至云服務器端,方便系統的存取,在數據處理和展示模塊中利用python來進行數據的預測,最后通過 Tableau 和 R 語言集成對全國每個省會城市進行可視化展示。
在項目中該業務運行成功后,就會上傳該項目到云服務器,這樣,用戶就能夠在終端通過輸入IP地址以及端口信息來查看系統的相關內容。
3 系統展示
將Django 項目按照前文的項目的規劃應用至云服務器中,在客戶端數據登錄鏈接,具體如圖2所示。進入MySQL數據庫有Django生成對應的數據表并保存至數據庫中,方便隨時調用[6]。
本文選用成都市的氣候數據分布情況為例,得到氣候數據分布圖,可記錄溫度、濕度以及空氣質量指數等,數據每隔15分鐘更新一次,不僅可以篩選時間,還可以篩選城市以及濕度和空氣質量指數等。當在篩選器中選擇成都、2017年12月23日時,就會顯示成都市當時的氣候分布情況。
4 結語
大數據時代有效的數據對于任何企業、機構的發展都至關重要,目前市場上大部分的系統功能都是獨立的,無法實現數據分析、挖掘以及展示一體化。本文為適應時代發展,平臺發展需求,將數據分析、挖掘以及展示進行集成化。首先基于API 和網絡爬蟲技術獲得原始數據,根據數據挖掘算法對數據進行處理分析,最后將有價值的數據以可視化界面展示處理,實現數據的可視化并選用成都市的氣候數據分布情況為例,得到氣候數據分布圖,可記錄溫度、濕度以及空氣質量指數等并進行了數據化展示,驗證了系統的可行性,為后續的平臺的進一步數據指導提供良好的交互性。
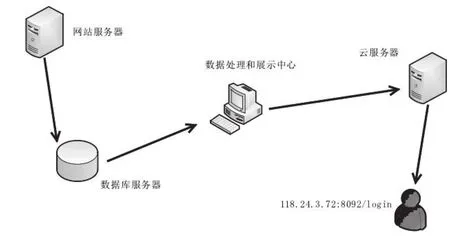
圖1 項目流程

圖2 客戶端數據登錄鏈接
猜你喜歡
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
信息通信技術(2015年6期)2015-12-26 01:16:46
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
