數據融合驅動的余熱鍋爐閥門調節方法
2021-01-18 01:43:12秦國帥孟德凱賀伯君季海鵬
燕山大學學報 2021年1期
劉 晶,秦國帥,孟德凱,賀伯君,季海鵬
(1. 河北工業大學 人工智能與數據科學學院,天津 300401;2. 河北省數據驅動工業智能工程研究中心,天津 300401;3. 勞里埃大學 計算機科學學院,加拿大 滑鐵盧 999040;4. 中材節能股份有限公司,天津 300401;5. 河北工業大學 材料科學與工程學院,天津 300401)
0 引言
近年來,隨著社會經濟發展,我國水泥行業產量迅速提升。根據數據表明,2014年我國水泥產量在全球總產量中占比56.7%[1]。同時,水泥行業又是一個典型高能耗產業,水泥行業能耗在全球能源消耗中占比8.5%,并且二氧化碳排放量占比高達34%[2]。
水泥生產過程中,熟料煅燒過程占水泥生產總能耗92.6%以上,其中只有大約60%的熱量被熟料煅燒所利用,剩余的40%熱量隨著窯頭、窯尾的廢氣一起排入了大氣中。不但造成了大氣污染,還造成了大量熱能的損耗。因此如何提升能源利用率成為余熱發電系統的關鍵性問題。
目前,低溫余熱發電技術系統優化方法主要分為兩類,分別是基于專家經驗系統控制優化方法和基于數據驅動系統控制優化方法。
基于專家經驗系統控制優化方法常用模糊控制等手段,以生產現場工作人員的控制經驗為基礎,在系統控制方面進行優化。其中,文獻[3]以有機朗肯循環系統中的蒸發器為研究對象,使用模糊PID控制,使系統具有更好的穩定性。文獻[4]使用PID控制器將渦輪機入口條件保持在過熱狀態,而沒有明顯的過沖現象,提高系統的熱效率。文獻[5]設計了非線性模型預測以及PID聯合控制模型,適用于重型柴油機的平行蒸發器有機朗肯循環(ORC)余熱回收系統的實時增強控制,可確保ORC系統高效、安全地運行。上述方法雖然取得了較好的效果,但隨著系統的復雜程度越來越高,此類方法很難對系統各個參數之間的內部關系進行深度挖掘。
近年來,IOT技術被廣泛應用于工業領域,設備產生了海量的運行數據,基于數據驅動的系統控制優化成為一種主流研究方法。其主要通過深度挖掘歷史數據之間的內在關系調整優化設備參數,常用方法有神經網絡,遺傳算法等。其中,文獻[6]研究渦輪機轉速與工質蒸發壓力對于渦輪機輸出功率的影響問題,將 BP 神經網絡應用于低溫余熱系統建模中,證明了基于BP神經網絡模型在建模中的有效性。文獻[7]采用基于神經網絡的PID控制方法,對中低溫余熱發電系統中膨脹機動態性能進行了調節,證明與傳統PID 控制相比, 該算法具有較好的控制效果。文獻[8]基于遺傳算法提出了一種蒸汽網絡模型,該模型可以減小蒸汽質量平衡的不穩定性和蒸汽能量損失,提高能源利用率。由此可見,基于數據驅動建模是解決工業問題的有效途徑。
由于余熱鍋爐系統中閥門調節影響因素眾多,參數關系復雜,而模糊控制等方法在復雜系統優化中存在局限性問題,因此基于余熱發電系統生產數據的優化成為一種有效手段。針對余熱鍋爐閥門調節問題,本文提出了一種數據融合驅動的余熱鍋爐閥門調節方法。該方法利用大量余熱鍋爐閥門調節數據,深度挖掘余熱鍋爐閥門調節特征的內在聯系,建立余熱鍋爐閥門調節預測模型。由于單個鍋爐存在多個閥門,通過研究閥門調節特性,將該方法分為以下兩個子模型:
1) 針對冷風閥的調節特性,提出了基于過采樣決策樹的冷風閥調節預測模型(Oversampling-based decision tree cooling air valve adjustment prediction model,簡稱ODTVA調節預測模型),該模型首先通過建立特征指標集,預測結果標簽化,過采樣處理,其次在此基礎上建立決策樹預測模型,可有效預測冷風閥調節操作。
2) 針對入口閥和旁通閥的調節特性,提出了基于LSTM-BP共享權值神經網絡的入口閥&旁通閥調節預測模型(Prediction model of inlet valve and bypass valve adjustment based on LSTM-BP shared weight neural network,簡稱LSWBVA調節預測模型),該模型利用LSTM提取閥門調節時序性特征,并通過共享權值的BP神經網絡解決入口閥、旁通閥調節強相關性問題,有效提高了余熱能源利用率。
1 數據融合驅動的余熱鍋爐閥門調節方法
1.1 整體框架設計
數據融合驅動的余熱鍋爐閥門調節方法主要對AQC余熱鍋爐閥門調節進行預測,AQC余熱鍋爐布置在回轉窯窯頭附近,負責回收水泥生產線上廢氣余熱,并加熱水產生過熱蒸汽,以推動汽輪機做功發電。AQC余熱鍋爐包括3個閥門,即入口閥、旁通閥、冷風閥。傳統方法中,當窯頭熱源溫度較高,通過人工調節冷風閥對余熱鍋爐溫度進行控制,防止溫度過高造成安全隱患。為提高余熱回收中能源利用率,入口閥大多數情況處于全開狀態,旁通閥處于微開狀態,狀態比較穩定。
如表1所示,通過分析入口閥和旁通閥開度的歷史數據,入口閥和旁通閥開度存在強負線性相關,冷風閥與其他兩個閥門之間相關性極小。即冷風閥通常單獨調節,入口閥和旁通閥通常一起調節。因此數據融合驅動的余熱鍋爐閥門調節方法針對AQC余熱鍋爐不同閥門的調節分為兩個子模型,分別為冷風閥調節預測模型和入口閥、旁通閥調節預測模型。

表1 閥門狀態相關系數Tab.1 The correlation coefficient of valve state
方法架構圖如圖1所示,首先通過數據預處理,新增閥門調節關鍵特征,并對閥門狀態標簽化,挖掘溫度壓力特征與閥門調節的對應關系。其次,針對冷風閥調節數據多變性以及不平衡問題,通過對訓練集過采樣,構建冷風閥ODTVA調節預測模型。最后,針對入口閥和旁通閥調節依賴時序性特征,以及兩者調節強相關性等特點,構建入口閥&旁通閥LSWBVA調節預測模型, 當入口閥全開時,根據歷史取風溫度變化利用LSTM神經網絡預測當前時間段內取風溫度,當真實取風溫度均值與預測取風溫度均值差值大于偏差閾值,則通過BP共享權值神經網絡同時對入口閥、旁通閥預測,調節兩者開度;當真實取風溫度均值與預測取風溫度均值差值小于閾值則保持入口閥、旁通閥開度不變;當入口閥處于非全開狀態時,則直接預測并調節入口閥、旁通閥開度。基于以上方法,可有效調節AQC余熱鍋爐閥門開度狀態。

圖1 數據融合驅動的余熱鍋爐閥門調節方法架構圖Fig.1 The architecture diagram of data fusion driven waste heat boiler valve adjustment method
1.2 冷風閥ODTVA調節預測模型
傳統人工調節往往是根據當前鍋爐內部的溫度、壓力特征使冷風閥開度增大、不變、減小。 因此,對冷風閥狀態數據進行預處理,將預測類別標簽轉換為增大、不變、減小。通過分析歷史數據,冷風閥調節策略如下所示:
1) 當鍋爐內部溫度、壓力長時間低于臨界閾值,冷風閥處于全關狀態且保持不變;當溫度、壓力長時間高于臨界閾值,冷風閥處于全開狀態且保持不變。
2) 當鍋爐內部的溫度、壓力超過或低于最佳閾值范圍時增大或減小冷風閥開度。
3) 當鍋爐內部溫度、壓力在最佳閾值范圍時保持當前冷風閥開度不變。
針對冷風閥調節數據多變性以及不平衡問題,提出冷風閥ODTVA調節預測模型。該模型通過計算特征參數信息熵,選取特征集合中最大信息增益的分類特征,構造決策樹[9-11]。
構建冷風閥ODTVA調節預測模型流程如圖2所示,首先通過新增特征,以及預測結果標簽化預處理,挖掘溫度壓力特征與閥門調節內在聯系。其次,通過過采樣處理,解決冷風閥調節數據不平衡問題,最后構建基于決策樹算法的冷風閥ODTVA調節預測模型。
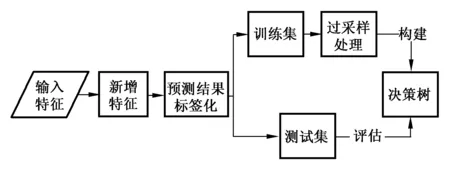
圖2 冷風閥ODTVA調節預測模型Fig.2 The ODTVA adjustment prediction model of cold air valve
1.2.1建立特征指標集
余熱發電系統中AQC余熱鍋爐相關特征眾多,為保證能夠精準預測AQC余熱鍋爐閥門調節,選擇閥門調節影響因素最大的特征作為輸入特征,包括取風溫度、主蒸汽溫度、主蒸汽流量、主蒸汽壓力、過熱器前廢氣溫度等關鍵特征。
閥門調節依賴最近時刻溫度變化,因此通過特征預處理,在以上特征基礎上建立閥門調節關鍵特征,保留調節數據最近時刻時序性特征。
閥門調節會在上一時刻閥門開度的基礎上調節。例如:閥門處于全開或者全關狀態,則無法增大或者減小。因此新增上一時刻閥門狀態特征。
取風溫度作為AQC余熱鍋爐熱源特征,其升降對鍋爐內部溫度變化具有關鍵性的影響。主蒸汽溫度作為余熱鍋爐閥門調節優劣的評價指標,其升降是閥門調節的重要依據。因此添加取風溫差,主蒸汽溫差保留最近時刻溫度變化的時序性特征。
主蒸汽溫度過低會造成能源利用率下降,過高會導致余熱鍋爐存在安全隱患。因此主蒸汽溫度存在最佳閾值區間。通過分析主蒸汽溫度數據,主蒸汽溫度分布服從正態分布。因此利用當前主蒸汽溫度減去樣本均值得到新的關鍵特征,即主蒸汽均值溫差,表示當前主蒸汽溫度與期望溫度的偏差。
綜上所述,輸入特征參數如表2所示。

表2 輸入特征參數Tab.2 Input feature parameters
1.2.2預測結果標簽化
通過預測結果標簽化,挖掘溫度、壓力特征與冷風閥開度調節的映射關系。冷風閥預測標簽化的算法如下:
步驟1:給定閥門全開的最小值OpenStatusValue,大于該值即認為閥門處于全開狀態,給定閥門全關的最大值CloseStatusValue,小于該值即認為閥門處于全關狀態。
步驟2:給定參數RangeNumber,即除全開和全閉的狀態之外的開度區間數量。
步驟3:針對每一個時刻的閥門開度百分比,計算所在的開度區間,生成開度等級。
步驟4:根據下一時刻的閥門開度和當前時刻的閥門開度等級差值進行判斷。如果下一時刻的開度等級大于當前時刻的開度等級,則標記為增大,如果小于,標記為減小,否則,標記為不變。
1.2.3過采樣處理
實際調節中,當余熱鍋爐內部溫度、壓力處于最佳閾值區間時,冷風閥開度保持不變;當余熱鍋爐內部溫度、壓力過高時,冷風閥處于長時間全開,且保持不變;當余熱鍋爐內部溫度、壓力過低時,冷風閥處于長時間全關,且保持不變;以上三種情況導致數據集中不變類別的數據量遠遠多于減小和增大的類別。由于數據集非平衡性會對模型的預測結果造成比較大的影響[12],因此采用SMOTE過采樣的方法增加少數類別數據量,提升模型的預測準確率。
1.2.4基于ID3決策樹的冷風閥調節預測
在實際生產環境中,首先冷風閥存在多種調節情況,其次人工調節存在滯后性,且多人調節單臺鍋爐,導致數據集中存在噪聲問題。針對以上問題,本文提出了基于決策樹算法的冷風閥ODTVA調節預測模型。該模型使用基于ID3決策樹算法進行閥門調節預測,針對特征集合存在連續特征值的問題,通過求解分割點集合,利用分割點將連續值轉換為離散值。決策樹生成算法如下所示:
步驟1:計算信息熵。針對樣本數據集D={x(1),x(2),…,x(n)},其標簽對應Y={y(1),y(2),…,y(n)},首先計算當前樣本集D中的信息熵。
樣本集合D信息熵:
其中,m代表閥門類別集合個數,pi表示集合D中第i類別占比。
步驟2:計算連續值分割點集合T。針對溫度,壓力等特征是連續值,首先對基于該特征的數據集合進行排序,其次對相鄰兩個特征值求均值t,得到劃分點集合T=[t(1),t(2),…,t(n-1)]。
步驟3:計算信息增益。決策樹計算大量數據時,存在連續特征的信息增益計算時間復雜度過高的問題,因此改進了此處的計算方式。針對鍋爐特征取值上下界范圍較小,而樣本較多的情況,給定一個較小的參數step,以max(1,(n·step))為步長,從集合T間隔抽取劃分點,求解基于當前劃分點的信息增益,最終求得劃分點集合中最大信息增益的劃分點。
特征A劃分集合的信息熵:
其中,v表示根據特征A將集合D劃分為v個子集合,|Dj|表示該子集合中的樣本數。
特征A劃分信息增益:
Gain(A)=Info(D)-InfoA(D)
步驟4:最大信息增益。依次遍歷當前特征集合中所有特征,計算信息增益最大的特征。根據當前特征進行劃分[D1,D2,…,Dv]子集合,并將此特征從特征集合中移除。
步驟5:構建子樹。分別對[D1,D2,…,Dv]子集合進行遞歸,重復上述步驟1~4,生成決策子樹。
步驟6:預剪枝。針對決策樹過擬合和數據集中噪聲等問題,采用預剪枝的方法。當存在以下3種情況,即某一子集合所有的樣本屬于同一類時;或樣本集合中樣本數小于最小節點數n·THRESHOLD時;或決策樹深度大于等于最大深度MAX_DEPTH時,將此節點標記為葉節點,此葉節點類別為當前集合中樣本數最多的類別。
1.3 入口閥&旁通閥LSWBVA調節預測模型
由閥門相關系數可知,入口閥、旁通閥兩者之間存在強相關性,調節時會一起調節。
圖3是入口閥和旁通閥調節的示例過程。

圖3 入口閥&旁通閥調節示例Fig.3 The example of inlet valve and bypass valve adjustment
當取風溫度特征處于正常波動,入口閥旁通閥開度穩定不變,保證余熱回收利用率。當取風溫度特征驟升,引起鍋爐內部溫度壓力過高,減小入口閥開度,增大旁通閥開度,減少進入鍋爐內部的熱量。因此入口閥旁通閥的調節依賴取風溫度特征的時序性變化。
如圖4所示,由于傳統機器學習算法無法提取數據時序性特征,因此采用深度學習長短期記憶網絡[13](Long Short-Term Memory, LSTM)提取取風溫度時序性特征。該網絡通過控制遺忘門、輸入輸出門來控制神經節點的遺忘和記憶,有效解決了循環神經網絡中存在的梯度消失或梯度爆炸等問題。因此LSTM神經網絡可有效學習時序性特征并對時序性數據進行預測。

圖4 LSTM神經網絡單元Fig.4 The unit of LSTM neural network
遺忘門計算公式如下:
f(t)=σ(ωf·[h(t-1),x(t)]+bf)
其中,ω是隱藏層t-1時刻輸出h(t-1)與h時刻輸入x(t)的權重,bf是偏置,σ為Sigmoid激活函數,控制細胞單元中保留和遺忘哪些信息。
輸入門計算公式如下:
i(t)=σ(ωi·[h(t-1),x(t)]+bi)
g(t)=φ(ωg·[h(t-1),x(t)]+bg)
其中,φ為非線性激活函數,g(t)是新的記憶信息。σ控制值的更新。
經過遺忘門和輸入門,當前記憶單元更新單元內的記憶狀態,將該時刻以及以前的知識有效傳遞。長期狀態更新公式如下:
S(t)=S(t-1)⊙f(t)+g(t)⊙i(t)
其中,⊙為內積運算。
輸出門計算公式如下:
o(t)=σ(ωo·[h(t-1),x(t)]+bo)
h(t)=φ[S(t)]⊙o(t)
通過遺忘門、輸入門和輸出門的控制,LSTM神經網絡可以有效地提取數據時序性特征[14-15]。
因此針對以上入口閥,旁通閥調節存在的依賴時序性特征,以及強相關特點,提出了入口閥&旁通閥LSWBVA調節預測模型。
1.3.1基于LSTM取風溫度異常檢測
由于取風溫度存在時序性以及較少時刻存在溫度驟升情況,故存在數據失衡問題,針對以上問題,提出基于LSTM取風溫度異常檢測算法。主要思想是利用正常溫度波動較多的情況檢測異常溫度波動較少的情況。由于大多時刻取風溫度處于正常波動狀態,因此在溫度驟升時會出現預測偏差較大的情況,通過對偏差閾值大小的控制可以有效地預測取風溫度的異常狀態。該算法預測流程圖如圖5所示。

圖5 LSTM取風溫度異常檢測流程圖Fig.5 The flowchart of extract wind temperature anomaly detection based LSTM
步驟1:輸入特征。利用LSTM滑動窗口,選擇歷史取風溫度特征[x(1),x(2),…,x(l)]為輸入特征,其中,l為取風溫度歷史步長大小。

步驟3:計算偏差。計算真實溫度均值與預測溫度均值差值θ,如果θ值大于偏差閾值Δ,則認為當前溫度異常,需要調節入口閥和旁通閥。否則為正常,當前入口閥和旁通閥開度不變。

由于該算法通過歷史取風溫度預測當前一段時間內取風溫度變化。因此需要選取合適的歷史步長l以及當前步長r,提高該算法對取風溫度變化預測的精確性。
1.3.2基于BP共享權值神經網絡的入口閥&旁通閥調節預測
針對入口閥、旁通閥存在強相關性特點,提出基于BP共享權值神經網絡的入口閥&旁通閥調節預測算法。通過分析入口閥、旁通閥調節數據,鍋爐內部溫度、壓力特征與入口閥、旁通閥開度狀態存在明顯的映射關系。鍋爐內部溫度壓力越高,入口閥開度越小,旁通閥開度越大。因此可以直接預測入口閥,旁通閥開度。基于BP共享權值神經網絡的入口閥&旁通閥調節預測過程如圖6所示。

圖6 BP共享權值神經網絡入口閥&旁通閥預測流程圖Fig.6 The flowchart of inlet valve and bypass valve predicted by BP shared weight neural network
首先數據預處理,將預測結果標簽化。其次,利用數據集訓練BP共享權值神經網絡。最后,計算真實值與預測值的偏差,通過聯合損失函數,反向更新網絡參數,解決入口閥和旁通閥強相關性問題。該聯合損失函數如下所示:

2 閥門調節實驗以及分析
2.1 數據集描述
數據集來源于某水泥廠余熱發電系統的AQC鍋爐實際生產數據,間隔時間1 min。本次研究的數據集時間為2019-04-09至2019-11-13,共計220 201個樣本。
冷風閥、入口閥、旁通閥閥門調節折線圖和直方如圖7所示,由圖7(a)冷風閥折線圖可以看出冷風閥狀態波動劇烈,開度調節頻繁,從直方圖中可以看出冷風閥具有多種開度等級。由圖7(b)入口閥折線圖,圖7(c)旁通閥折線圖可以看出入口閥,旁通閥調節較少,狀態比較穩定,且調節時會一起調節。從由7(b)入口閥直方圖,以及圖7(c)旁通閥直方圖中可以看出入口閥、旁通閥的開度等級比較固定。綜上所述,該余熱鍋爐主要通過冷風閥控制溫度壓力,在特定時候才會調節入口閥、旁通閥。

圖7 閥門調節數據折線圖和直方圖Fig.7 The line chart and histogram of valve adjustment data
2.2 冷風閥調節實驗
2.2.1冷風閥ODTVA調節預測模型設計實驗
為驗證冷風閥ODTVA調節預測模型有效性,設計實驗對比該模型與其他模型預測結果。針對數據存在不平衡問題,以AUC作為評價指標,比較各調節預測模型的性能表現。

表3 ODTVA調節預測模型參數設置Tab.3 Parameter setting of ODTVA adjustment prediction model
由表4、表5得出,決策樹、ODTVA調節預測模型在單天數據集中AUC高于0.9,證明了決策樹算法在冷風閥操作分類中的有效性。ODTVA調節預測模型相比決策樹調節預測模型,AUC有顯著提升。如圖8混淆矩陣所示,ODTVA調節預測模型可有效提高少數類別的分類準確率。在實際閥門調節中,增大,減小類別的準確率更為重要,因此加入SMOTE過采樣算法可以使調節預測模型效果更好,更加符合實際調節情況。

表4 決策樹調節預測模型單天數據預測Tab.4 Single day data prediction of decision tree adjustment prediction model
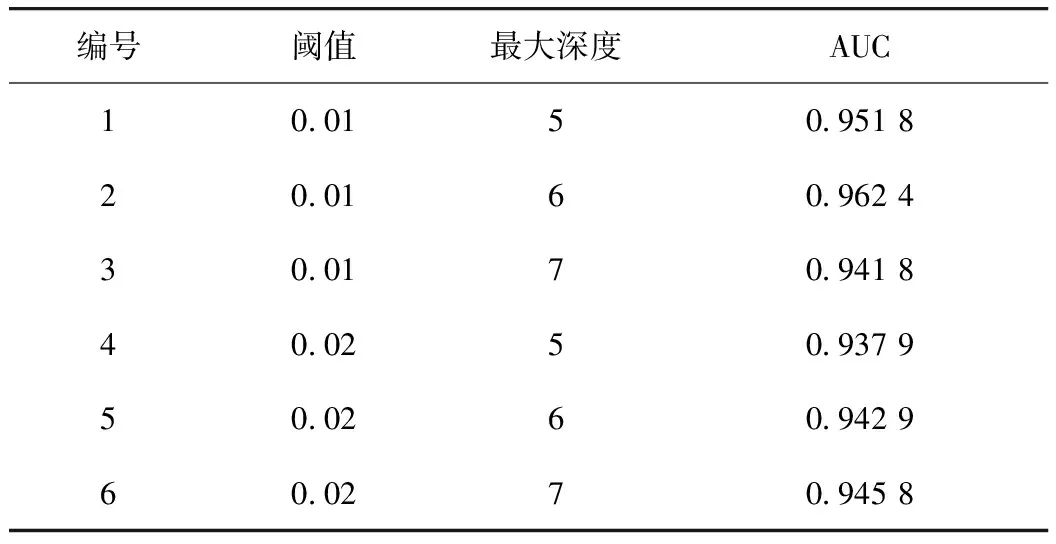
表5 ODTVA調節預測模型單天數據預測Tab.5 Single day data prediction of ODTVA adjustment prediction model

圖8 混淆矩陣Fig.8 Confusion matrix
如表6所示,當數據量增大,決策樹的深度越深,AUC值越低,出現過擬合現象,因此數據量較大時樹深度不該過深。

表6 ODTVA調節預測模型單周數據預測Tab.6 One-week data prediction of ODTVA adjustment prediction model
各調節預測模型實驗結果如表7所示。

表7 各個調節預測模型AUC比較Tab.7 AUC comparison of different adjustment prediction model
使用單天數據量訓練,ODTVA調節預測模型AUC最高為0.962 4,遠高于其他預測模型。由于決策樹算法在生成預測標簽時少數服從多數,因此對噪聲有較強的魯棒性,可以修正調節數據集中的滯后性問題,更適合應用于閥門調節中。
使用單周數據量訓練模型,各調節預測模型AUC基本均出現了下降的情況。這是因為時間增長,數據集中噪聲數據增多。加入SMOTE算法后各調節預測模型AUC均出現了提升,再次證明SMOTE算法在冷風閥門調節的有效性。通過對比各個調節預測模型,冷風閥ODTVA調節預測模型在單天以及單周數據集中AUC均是最高。證明ODTVA調節預測模型在冷風閥操作分類中性能最好。
2.2.2冷風閥調節仿真實驗
針對冷風閥調節預測模型需要應用于實際生產,因此根據實際調節情況設計實驗仿真。使用單周數據訓練模型,預測調節單天冷風閥開度狀態。比較各調節預測模型閥門預測開度與實際真實開度的MAE以及標簽AUC,對比各個調節模型仿真性能。由表7可知,SMOTE算法可以顯著提高各個模型的AUC,因此將對比冷風閥ODTVA調節預測模型與其他過采樣調節模型以及LSTM調節模型。
仿真調節實驗的流程:
步驟1:輸入數據X,預測當前閥門操作Y,即增大,不變,減小操作。
步驟2:如果輸出的Y為增大或者減小,將當前閥門開度增加或者減小1或2個等級輸出。如果輸出開度大于閥門最大開度,將該開度設置為閥門最大開度,如果小于閥門最小開度,將該開度設置為閥門最小開度,并將下一時刻輸入數據中冷風閥門開度替換成該開度。
步驟3:重復以上兩個步驟,預測仿真集中每一時刻閥門開度。
閥門開度MAE表示閥門真實開度與預測開度偏差,MAE越小,預測開度和真實開度越接近。標簽AUC表示閥門預測操作的準確性,AUC越高,余熱鍋爐閥門操作越精準。仿真結果如表8所示,相比其他調節模型,ODTVA調節預測模型具有更低的MAE以及更高的AUC,證明ODTVA調節預測模型仿真效果最好。

表8 冷風閥調節實驗仿真結果Tab.8 The simulation result of cold air valve adjustment experiment
實驗仿真結果如圖9所示,其中,實線為真實值,虛線為預測值。
從圖9(c)中可以看出LSTM調節預測模型效果最差,雖然LSTM調節預測模型雖然在某些波動劇烈的時候可以正常預測,但是由于無法提前對數據過采樣,數據不平衡,因此仿真結果較差。從圖9(d)中可以看出SMOTE-SVM調節預測模在某些時刻預測較好,但是在某些時刻呈一條直線,這是因為雖然對最終類別進行了過采樣,但是在某些閥門開度依舊存在數據不平衡問題,因此SMOTE-SVM調節預測模型在某些閥門開度偏向不變類別。從圖9(a)和圖9(b)中可以看出ODTVA和SMOTE-BP調節預測模型在實際預測中可以較好地調節。如表8所示,與SMOTE-BP調節預測模型相比,ODTVA調節預測模型AUC更高,表示ODTVA調節預測模型調節更加精準。從圖9(b)中也可得出SMOTE-BP調節預測模型實際仿真中波動更加劇烈,而圖9(a)中ODTVA調節預測模型仿真結果則具有更好的穩定性。實際生產中閥門調節穩定性越高越好,因此ODTVA調節預測模型更加符合實際情況。其次,如表8所示,ODTVA調節預測模型的MAE比SMOTE-BP調節預測模型更低,從圖9(a)中也可得出ODTVA調節預測模型相比圖9(b)中SMOTE-BP調節預測模型具有更好的擬合效果。通過對比以上各個模型,證明了ODTVA調節預測模型在冷風閥仿真調節中的效果最好。

圖9 冷風閥調節仿真Fig.9 The simulation result of cold air valve adjustment
2.3 入口閥和旁通閥調節實驗
2.3.1基于LSTM取風溫度異常檢測實驗
輸入層單元個數表示歷史步長,輸出層單元個數表示當前步長。為防止過擬合,在訓練時加入了Dropout。表10是各參數的算法結果。

表9 LSTM神經網絡參數設置Tab.9 Parameter setting of LSTM neural network

表10 不同參數實驗結果比較Tab.10 Comparison of experimental results with different parameters
通過以上實驗對比,LSTM滑動窗口歷史步長l為10,當前步長r為3,Val Loss最低。歷史步長l為20,當前步長r為5,測試集的均值MAE最低,表示根據前20 min預測后5 min,誤差最小。當l為30,r為10,Val Loss以及均值MAE誤差增大。由于該算法通過比較均值誤差判斷當前鍋爐取風溫度是否異常,因此選用歷史步長為20,當前步長為5構建LSWBVA調節預測模型。
2.3.2基于BP共享權值神經網絡的入口閥&旁通閥預測實驗

表11 BP共享權值神經網絡參數設置Tab.11 Parameter setting of BP shared weight neural network
由于入口閥旁通閥調節樣本較少,類別沒有失衡問題,因此直接對比各個參數下算法的準確率評估算法性能。如表12所示,BP共享權值神經網絡入口閥,旁通閥開度預測,平均準確率為83.95%,證明BP共享權值神經網絡可以有效地同時預測入口閥、旁通閥開度。

表12 入口閥&旁通閥預測實驗結果Tab.12 The result of inlet valve and bypass valve prediction experiment
2.3.3LSTM取風溫度預測仿真實驗
為驗證LSTM取風溫預測算法可有效檢測取風溫度的異常上升,利用該模型對調節示例中的取風溫度仿真預測,如圖10所示,其中,實線為真實均值,虛線為預測均值。基于LSTM神經網絡的取風溫度仿真預測結果基本吻合真實狀態下的溫度均值,在溫度驟增時出現真實值與預測值偏差過大的問題,真實值均值遠遠大于預測值均值。由于在此處出現了溫度驟升的情況,相應需要減小入口閥開度,增大旁通閥開度。因此通過設置合適的偏差閾值,計算真實均值與預測均值偏差程度,如果大于給定的偏差閾值,即認為需要調節入口閥、旁通閥。仿真實驗表明,該算法可有效預測入口閥、旁通閥的調節時機,最大限度的利用余熱能源,符合實際的生產需要。

圖10 取風溫度仿真預測結果Fig.10 The result of extract wind temperature simulation prediction
2.3.4入口閥、旁通閥調節仿真實驗
為驗證入口閥、旁通閥LSWBVA調節預測模型在實際應用中的有效性,利用該模型對調節示例入口閥,旁通閥仿真預測。仿真實驗結果如圖11所示,分別是LSWBVA和BP共享權值神經網絡調節預測模型的入口閥、旁通閥調節仿真。
其中實線為真實值,虛線為預測值。從圖11(c)中可以看出由于BP共享權值神經網絡調節預測模型無法提取取風溫度數據的時序性特征,判斷當前溫度曲線變化是否需要調節入口閥和旁通閥,只能根據當前鍋爐內部的溫度特征對閥門進行調節,因此在取風溫度波動穩定時,也會調節入口閥、旁通閥。實際調節中取風溫度波動穩定時主要通過調節冷風閥控制鍋爐內部溫度,只有在溫度驟升時才調節入口閥和旁通閥來控制進入鍋爐內部的熱量。從圖11(a)中可以看出LSWBVA調節預測模型通過LSTM提取取風溫度的時序性特征,對鍋爐取風溫度異常檢測,在鍋爐溫度驟升時通過BP共享權值神經網絡調節入口閥和旁通閥,溫度穩定時保持閥門開度不變。因此LSWBVA調節預測模型相比BP共享權值神經網絡調節預測模型,提高了余熱能源利用率。

圖11 LSWBVA、BP調節預測模型實驗仿真結果Fig.11 The simulation result of LSWBVA and BP adjustment prediction model experiment
3 結論
針對傳統AQC余熱鍋爐閥門調節依賴人工經驗的問題,本文提出了一種數據融合驅動的余熱鍋爐閥門調節方法。首先,通過對原始數據預處理,挖掘閥門調節與鍋爐溫度壓力內部特征的關系;其次,在此基礎上提出了冷風閥ODTVA調節預測模型,仿真實驗表明,該模型具有更好的閥門開度擬合效果;最后,利用LSTM模型對取風溫度特征狀態進行監測,再通過BP共享權值神經網絡對入口閥旁通閥同時調節。仿真實驗結果表明,入口閥&旁通閥LSWBVA調節預測模型可有效地檢測取風溫度驟升異常情況,精準調節入口閥和旁通閥,相比單獨對入口閥旁通閥調節,更加符合實際的實際調節操作,提高了能源利用率。由此證明了數據融合驅動的余熱鍋爐閥門調節方法在AQC余熱鍋爐閥門調節中的有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
流程工業(2022年3期)2022-06-23 09:41:08
中國石油石化(2021年8期)2021-07-20 07:36:12
煤氣與熱力(2021年3期)2021-06-09 06:16:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
智富時代(2018年5期)2018-07-18 17:52:04
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中學科技(2014年11期)2014-12-25 07:38:53
