兒童運動協調障礙AI診斷系統研究綜述
2021-01-22 05:59:24陳艷杰舒大偉楊吉江
計算機工程與應用 2021年2期
陳艷杰,舒大偉,楊吉江,王 歡,王 青,雷 毅
1.首都醫科大學 附屬北京兒童醫院 兒童保健中心,北京100045
2.清華大學 深圳國際研究生院 信息科學與技術學部,廣東 深圳518055
3.清華大學 信息技術研究院,北京100084
4.國家體育總局體育科學研究所,北京100061
兒童的運動協調能力是兒童發育過程中的核心能力之一,該能力正常的發展對兒童的語言、智力、情感等方面的發展也具有促進作用[1],患有運動協調能力障礙(Developmental Coordination Disorder,DCD)的兒童通常語言、認知等方面的能力也會受到影響,在兒童階段及成人遠期都可能會影響其生活自理能力及社會性相關功能,所以運動協調能力的評估成為兒童早期發育水平的重要指標[2]。
根據美國精神聯合學會(American Psychiatric Association,APA)的調查顯示,5~11 歲兒童的發病率為5%~6%[3],我國2011 年上海地區的一項調查顯示7~12 歲兒童的發病率為8.3%[4]。其較高的發病率不容忽視,但其病因復雜,目前發病機制仍不明確[5],而多項研究表明,早發現早干預是目前行之有效的治療手段。
目前的兒童運動協調障礙的主要診斷手段是通過各種專業量表法[6],如兒童運動協調能力評估量表第二版(Movement Assessment Battery for Children-Second Edition,MABC-2)、發育性協調障礙量表(Developmental Coordination Disorder Questionnaire,DCDQ)等,評分依據有客觀標準,如動作的頻次,也有主觀標準,如動作標準程度判斷,這就要求做診斷的醫生需要有一定經驗及專業性,才能有效評估得出正確診斷結果。我國兒科醫師缺乏情況一直比較突出,且由于地域發展的不平衡,基層的兒科醫師更為缺乏,所以需要一套簡單易行且診斷準確度在一定水平之上的解決方案。
計算機動作識別系統可對人體動作進行識別,目前主要應用于電影演員動作捕捉、運動員動作評估等方面,通過觀察者在身體各部位攜帶一定數目的標記進行動作數據的采集,計算機進行后臺數據處理及動作分析,其對設備和場地都有較高的要求,有著成本高、操作復雜、泛用性差的缺陷,這就意味著難以大范圍地推廣使用。
隨著人工智能的發展,僅基于移動端所拍攝的視頻數據進行動作識別輔助診斷系統有了實現的可能,患者根據提示完成一系列的動作,系統根據所得視頻數據即可對疾病做出診斷,這種形式的診斷方式有著易推廣、易實施的特點,具備良好的應用前景。利用移動端設備進行視頻采集,服務端對視頻數據進行診斷,該方式可有效向基層進行推廣,在此基礎上可獲得大量的數據并進一步提升診療識別能力,對緩解醫療資源不足問題有著重要意義。
1 相關領域研究現狀
當前,兒童運動協調障礙人工智能診斷系統領域的研究較少,動作識別多用于體育視頻分析,Joshi 等[7]基于深度學習方法提出一種視頻分析方法,對體育視頻中的高光時刻進行分析捕捉并截取精華片段,但其只是對視頻內容作是否精華部分的判斷,并不涉及對運動員實例級別的動作評估。Wang 等[8]提出一種分析自由滑雪運動項目的動作評估方法,第一步對視頻數據輸入進行目標跟蹤任務,第二步對抽取出的跟蹤目標進行單人姿態估計,第三步對得到的姿態估計數據進行動作評估,即對動作好壞做二分類任務。Tian等[9]基于花式滑冰動作分析任務,提出利用多個不同視角的攝像頭捕捉動作,然后進行位置矯正補償從二維影像數據獲得三維立體數據的方法,給從二維數據獲取更為準確的三維數據任務提供了新思路。
先做人體姿態估計再去做動作識別任務是一個普遍采用的思路,Chen 等[10]基于Openpose[11]框架,提出使用人體姿態估計的輸出來做摔倒檢測任務,摔倒檢測可以認為是動作識別中的子任務,其使用skeleton-base的人體姿態估計數據根據手工設計的特征標準進行摔倒動作的識別,王新文等[12]使用雙重殘差網絡做摔倒檢測任務。唐心宇等[13]指出直接使用Kinect 作為姿態估計的數據輸入對動作識別的準確度有較大影響,因其對遮擋情況的判斷精度較差,結合深度學習的方法進行姿態估計能大大改善遮擋識別不準確的問題。騰訊醫療AI實驗室提出帕金森疾病診斷系統,該系統提示患者作出相應動作并對其進行診斷,通過深度學習方法識別人體的關鍵點構建人體動作模型,依據成熟的帕金森疾病打分量表進行診斷,其也針對訓練數據不足的情況結合自動融合技術做了數據增強。
2 運動協調障礙的輔助診斷步驟
基于深度學習方法做運動障礙診斷目前有兩種思路,關鍵區別在于是否進行人體姿態估計的中間處理生成skeleton數據,因而產生了兩種不同的處理步驟,需要注意的是由于后續動作識別任務的輸入數據類型不同,所以動作識別任務中采用的模型將有較大差別。
步驟類型1見圖1:
(1)使用移動設備根據提示進行幼兒動作指導并視頻采集,為保證最終檢測效果,對輸入數據的一致性要有一定要求,如光照環境、拍攝角度等方面,對拍攝后的視頻進行必要的預處理操作。
(2)由于得到的視頻數據是已經剪裁好的對應動作視頻,對其分別進行人體姿態估計任務,生成人體姿態估計的skeleton數據,為了保證對兒童識別的準確度,人體姿態估計任務的模型要在對應的兒童數據集上做finetune。
(3)將skeleton數據輸入Skeleton-based類型的動作識別模型,輸出動作準確度的評估結果,對相應動作根據打分量表進行診斷打分,匯總打分結果輸出診斷結果。
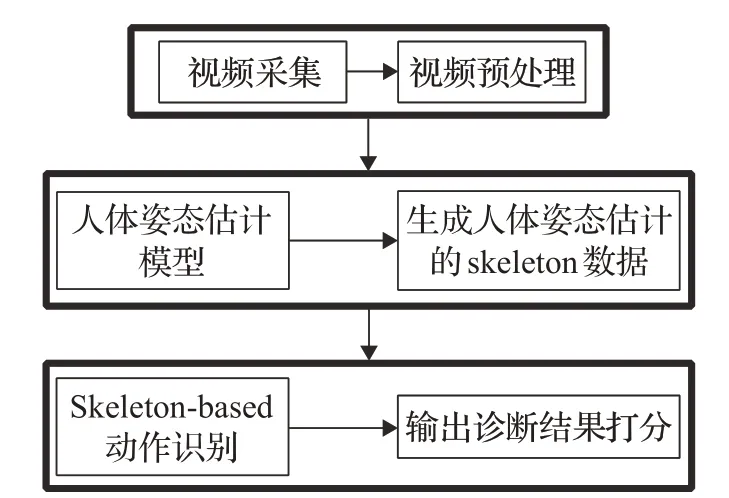
圖1 輔助診斷流程圖類型1
步驟類型2見圖2:
此類型無需進行人體姿態估計的中間任務,直接將視頻數據輸入Video-based類型的動作識別模型進行動作識別,然后進行診斷打分操作,這種類型對動作數據集的要求較高,需要大量的帶標注的動作視頻數據進行訓練。
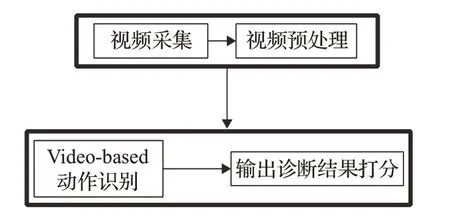
圖2 輔助診斷流程圖類型2
3 人體姿態估計
人體姿態估計是計算機視覺的基礎任務之一,在目前權威的公開比賽COCO keypoint track[14]中,COCO數據集把人體表示為17 個關鍵點,分別是鼻子、左右眼、左右耳、左右肩、左右肘、左右腕、左右臀、左右膝、左右腳踝,該任務需要對人體的關鍵點進行位置估計,這個任務通常還可細分:根據檢測畫面中的人數分為單人姿態估計和多人姿態估計,根據關鍵點信息是否包含三維深度信息分為2D姿態估計和3D姿態估計,此外還有對關鍵點進行跟蹤的人體姿態跟蹤任務。
在應用上,人體姿態估計可用于電影動畫、虛擬現實、人機交互、視頻監控、醫療輔助診斷、運動分析、自動駕駛等方面,同時人體姿態估計面臨著諸多挑戰[15]:
(1)人體是柔性的,這就意味著人體是一個具有高度自由度的物體,對這樣物體的估計難度較高[16]。
(2)對于背景復雜或光照條件弱的待處理圖片,人體與背景的外觀相似性可能較高,且身體的各個部分是被不同的紋理(衣服)所覆蓋的,有時不同部位的紋理是接近的。
(3)環境的復雜性會造成較大的影響,比如出現遮擋,尤其是對于不同人人體相似部位的遮擋。
3.1 傳統方法
相對于目前主流的深度學習方法,早期的傳統方法已經很少被使用了,其主要原因很大程度上是因為深度學習領域的發展,在各類人體姿態估計的數據集上,深度學習的方法已經全面超過了傳統方法的效果,但傳統方法提供的基本思路依然值得學習借鑒。
傳統方法主要針對的是單人的姿態估計任務,粗略可分為兩類,一類方法是直接使用全局的feature,將問題轉化為分類或者回歸問題來進行解決,如文獻[17]中采用的是HOG 直接抽取淺層的全局特征,然后利用Random Forest的方法轉化為分類問題來解決姿態估計問題,第二類方法是基于圖模型,如pictorial structure framework,對圖像的單個part進行特征表示,Andriluka等[18]基于pictorial structure framework 對特征表示優化,來提取更好的特征表示,傳統的方法基本上還是利用的比較淺層的特征,如HOG、SIFT 等,然后對空間位置關系進行建模,而深度學習方法將二者合為一體,這樣的優勢是便于設計和優化。
3.2 深度學習方法
深度學習的方法自2012年AlexNet[19]提出以來就引發了研究熱潮,在人體姿態估計領域也引入了深度學習模型,在2013 年就有文章提出使用CNN 來解決人體姿態估計問題[20],但當時的網絡設計還比較簡單,而且利用CNN只是替代了原有姿態估計方法中的特征表示部分,但在性能上卻已經和傳統方法一致,甚至超過,表1總結了目前主流的人體姿態估計模型。
3.2.1 單人姿態估計
在早期主要發展的是用于2D 單人姿態估計的方法,其中最具有代表性的是2016年發表的Hourglass[21]、CPM[22]兩個工作。CPM 里已經把空間位置關系和特征表示建模在一個模型之中了,不像之前僅把CNN 作為特征表示的方式,輸出的每個channel 實際上就代表一個關鍵點,采用多stage的方式,每個stage可以看作是在前stage 的基礎上做refine,在輸出關鍵點坐標的方式上,不是采用直接回歸坐標的方式,而是采用先預測出heatmap,然后再取argmax等操作獲得最終坐標值,heatmap相對而言能保留更多context 信息,是一種中間態的信息,在此之后的人體姿態估計問題,基本上都是采用heatmap 的方式來獲得關鍵點坐標。Hourglass 網絡的突出特點是結構簡單明了,通過融合feature map 的前后特征來獲取具有更強表示能力的特征,這種U型結構也廣泛用于其他任務,如圖像分割、檢測等。整體的pipeline和CPM是相似的,這本質上是back-bone層面的改進提升。除了以CPM 為代表的思路之外,還有一些思路是基于GAN 的方式[26]進行單人姿態估計任務,在MPII上取得了很好的效果。

表1 人體姿態估計深度學習模型
3.2.2 多人姿態估計
隨著COCO數據集中多人姿態估計任務的提出,用于2D 多人姿態估計的方法逐漸增加,其中較有影響力的代表是Openpose[11],這是多人姿態估計中基于bottomup 的思路,而基于top-down 的思路,后續提出的有CPN[24]、MSPN[25]。
在多人姿態估計中bottom-up思路是先檢測出所有關鍵點,然后對這些關鍵點進行分組,確定關鍵點所屬的對象,openpose基于CPM組件,首先找出圖中的所有關鍵點,然后使用PAF(Part Affinity Fields)方法將這些檢測出來的關鍵點分組確定所屬對象。除了利用PAF來確定關鍵點所屬對象之外,還有一種利用Associative Embedding 的思路[27],就是對每個輸出的關鍵點都輸出對應的embedding,使同一個人的embedding 結果接近,不同人embedding結果差距變大。
多人姿態估計的第二種思路是top-down思路,即先進行檢測任務將圖中的人都找出來,然后進行單個人的姿態估計,此思路下的模型精度更好,由于人體目標比關鍵點更大,檢測到人比檢測關鍵點更容易,這就意味著recall 會更高,其次不需要對類似的關鍵點進行所屬對象分組,而這個問題在bottom-up 思路中會比較困難。CPN[24]設計兩個stage,第一步的GlobalNet 輸出一個coarse的結果,第二步進行進一步的refine,此外和之前研究的不同是采用了更主流的backbone,即ResNet50,更強的backbone對特征具有更好的表征能力。MSPN[25]同樣是基于top-down 的思路,是在CPN 的基礎上做的改進,相比于CPN的兩個stage設計,這篇工作采用了多個stage 的設計,相當于有多步的refine,這樣取得的結果也會更好。
3.3 數據集及評估標準
在深度學習方法中,數據集是尤為重要的,好的數據集不僅可以作為評估不同方法效果的標準,還可以隨著數據集的擴張變化來提升深度學習網絡的性能,下面將對主要數據集及評估標準進行介紹。
3.3.1 2D人體姿態估計主要數據集
在深度學習興起之前就已經存在許多2D人體姿態估計的數據集,這些數據集具有一些缺點,如場景過少、單一視角、圖片數量過少等,這些缺陷導致其無法在深度學習任務中達到更好的效果,尤其是數據量過少,這就會導致深度學習網絡的魯棒性減弱,也會導致容易過擬合等問題,所以本文主要介紹數據量級在千級及以上的數據集,這些數據集出現的時間節點為深度學習興起之后,具有更多樣化的場景及圖片數量,數據集的總結見表2。
Frames Labeled in Cinema(FLIC)Dataset[28],此數據集包含從好萊塢電影中收集到的5 003 張圖片,通過人體檢測器捕捉到了20 000多個人體候選圖片,這些候選圖片送到Amazon Mechanical Turk 進行人體姿態的標注(10個關鍵點),然后手動刪除其中遮擋較為嚴重的數據最后得到總數5 000級別的數據集。

表2 人體姿態估計數據集
Leeds Sports Pose(LSP)Dataset[29],這是一個收集于Flickr 中的運動圖片數據集,包含8 種運動標簽(棒球、體操、跑酷、足球、網球、排球、羽毛球、田徑),其包含2 000張圖片,關鍵點數目為14個。
Max Planck Institute for Informatics(MPII)Human Pose Dataset[30],這個數據集是目前最為主流的數據集,其標注信息相當豐富,數據集數量首次達到了萬級別,數據集的原始來源是youtube 的視頻,從中挑出大約24 920幀的圖片數據,標注了16個關鍵點,相較于之前的數據集增加了眼鼻關鍵點。
3.3.2 2D人體姿態估計的評估標準
數據集的不同也意味著其特點(人體體長標準選用上半身或全身)和適用的任務范圍不同(單人多人),這就需要不同的評估標準來進行算法模型效果的衡量。
Percentage of Correct Parts(PCP)[31],早期使用的標準之一,主要用于表明軀干的定位精準程度,如果兩個端點定位偏差在ground-truth 的一定閾值范圍之內(通常這個閾值設定為50%)則表明定位正確,這個軀干部位包括身體、大腿、小腿、前臂、頭部等,在每個部位的基礎上取其平均值即可得到mPCP值。
Percentage of Correct Keypoints(PCK)[32],與PCP不同,PCK的評判標準適用于判斷關鍵點(如手關節、踝關節、膝蓋等)的預測準確度,定位正確的判斷標準為判斷定位的位置是否落在groud-truth 的一定閾值半徑范圍之內,這個閾值通常設定為軀干長度的一定比例值或者頭部長度的一定比例值,常用的標準為頭部50%的比例值,標記為PCKh@0.5。
The Average Precision(AP),這個指標主要用于多人姿態估計的準確度評估,且適用于那些沒有標注人體的bounding-box圖片,這些圖片通常只標注了對應的人體部位,其評判方式類似于目標檢測的評判方式,主要通過判斷關鍵點是否落在一定區域范圍內來進行評判,在這個范圍內即被判斷為正樣本(true positive),所有預測出的關鍵點會依據PCKh的得分情況次序列出,沒有在ground-truth 范圍內的檢出結果被判定為負樣本(false positive),mAP 表示的是所有關鍵點的AP 指標平均值。COCO[14]中,這個評判方式被進一步細化,提出了Object Keypoint Similarity(OKS)的計算方式,以OKS為評判正負樣本的標準,此指標與目標檢測中Intersection over Union(IoU)的功能是一致的。
3.4 小結
人體姿態估計作為動作識別任務的前置任務,直接影響了動作識別任務的最終效果,由于目前的數據集數量約束,人體姿態估計可作為動作識別的中間任務,進一步進行下游任務時也可以處理得比較靈活,既可以使用手工特征對動作進行判斷識別,也可以進一步使用更高級的算法對動作進行識別,在動作識別實現落地的過程中,人體姿態估計是必不可少的一環。
4 動作識別
動作識別是視覺任務中理解范疇的任務,即對視頻中的人的行為進行識別,其應用范圍廣泛,包括智能安防、虛擬現實、多媒體視頻內容理解等,其中簡單層面的動作識別任務又叫做動作分類,這類任務是給定了一小段視頻片段,然后對其進行分類,處理起來相對容易,還有一類任務是檢測并分類,即給定一段視頻要先進行人的定位和視頻時間區間上的分段,然后再對檢測出來的段進行動作分類,這類任務相對較難。
4.1 傳統方法
在傳統方法中,其主要特點是動作識別所使用的特征是手工設計的特征,如iDT[33-34],其使用的分類器主要是SVM、決策樹或隨機森林,相對深度學習方法,傳統方法的可解釋性更強,在理論分析上更有優勢。
4.2 深度學習方法
隨著計算機視覺[19,35]和自然語言處理[36-37]的深度學習方法的興起,基于深度學習方法的動作識別模型也得到了進一步的研究,且相較于傳統方式取得了更好的效果,其主要優勢在于用深度學習模型抽取特征替代了傳統的手工設計特征,且可以實現端到端的訓練方式,但在可解釋性上目前還存在一些問題。動作識別的最初直接思路是對視頻中的每一幀靜止圖像進行動作識別,這種做法丟失了時間維度的信息,在區分高度相似的動作時會存在很大的問題,如“開門動作”和“關門動作”,所以如何建模時間維度的信息是動作識別準確度的關鍵要素。后續發展的方向可以根據是否進行檢測人體關鍵點的上游任務來區分為不檢測關鍵點的videobased的方法和檢測關鍵點的skeleton-based的方法,表3是對動作識別模型的總結。
4.2.1 Video-based
這類思路是直接方式,即對視頻輸入進行直接檢測分類,不需要skeleton關鍵點生成的中間步驟,相對關鍵點檢測能建模更多豐富的上下文信息,其中有兩類主要采用的方法。
第一類方法是三維卷積,為了解決前述時間維度信息建模的問題,直接思路是引入三維卷積,在原來二維卷積的基礎上擴展空間特征到時間維度上,直接提取包含時間維信息的特征表示,卷積核擴展為3D卷積核,卷積的結果是通過堆疊的方式產生的,Ji等[45]首次將三維卷積的方法引入了人體動作識別領域,7個連續的圖像幀被隨機地從視頻中截取出來,通過一些手工設計的操作輸出有33 個通道的特征圖(如灰度特征圖和光流特征圖),這些特征圖作為卷積網絡的輸入,通過一組設計好的卷積網絡抽取更深層的特征表示,最末端接上全連接層進行分類任務,文中的實驗證明在有噪聲干擾、有遮擋的情況下也能取得很好的識別效果。
Tran 等[39]分析了三維卷積核的尺寸對模型性能的影響,文中用大量實驗證明,對于多數情況下,使用3×3×3尺寸的卷積核能獲得最佳性能,文中設計了一個簡單的三維卷積模型C3D,結構簡單且容易訓練,該模型除了可應用于動作識別之外也可用于目標檢測。
Sun 等[40]提出可將三維卷積進行分解的思路,將三維卷積分解為二維卷積和一維卷積,在模型的低層使用二維卷積來抽取低層的特征,然后在高層使用一維卷積來進行時間維度的特征融合,這樣的設計降低了模型的復雜度,其實驗結果表明此設計有利于緩解過擬合問題。
第二類方法是Two-stream,這是目前研究最為主流的方法,視覺方面的研究表明,視覺信息的處理是由兩個不同信息處理函數的分支組成,分別是做動作的指導調整分支和認知識別分支,由這個思路啟發,Simonyan等[41]將Two-stream的思路用于動作識別領域,思路是做兩個分支,一個分支的輸入是隨機選取的一幀靜止圖像,將靜止圖像輸入RGB 分支提取空間域的特征,另一個分支是光流分支來提取時間域的特征,光流分支采取的輸入是該幀靜止圖像的前后10 幀圖像,這兩個分支是獨立的,提取空間特征的網絡結構和做圖像識別任務的網絡結構類似,所以可以采用ImageNet上的預訓練模型,然后結合起來做動作識別任務,其實驗結果表明可在小數據集上也取得良好的效果。

表3 動作識別模型
Feichtenhofer 等[46]基 于Two-stream 進 一 步 進 行 改良,將三維卷積融合的方式加入到卷積網絡的后段進行時空域信息的融合操作,其文中的實驗結果表明這種操作可明顯提升網絡性能且縮短訓練時間。
之前的研究提出的方法是在一個預固定好的區間范圍內做的動作識別任務,即對一段完整的視頻進行采樣,選取其中需要判斷的部分進行識別,而不是直接對完整視頻進行處理識別,Wang 等[42]提出了Temporal Segment Network(TSN),這是首次實現對完整視頻的端到端處理,TSN基于Two-stream的思路,引入了VGG網絡結構,一段較長的時間序列視頻經過時間域稀疏采樣策略被分割成了不交疊的視頻片段,然后每一段視頻都獨立作為訓練樣本輸入,最后通過融合函數將不同序列段的輸出特征進行融合,最后輸出整個視頻的動作描述。
4.2.2 Skeleton-based
人體的骨架信息實際上是對人體的拓撲結構進行簡化,其在描述人體動作上是信息充分的,相較于直接對視頻片段進行處理,既可以降低噪聲干擾,也可以減少多余的計算消耗,在面對圖像的各種變化時也具有更強的魯棒性,同時也有一些針對人體骨架識別的傳感器被開發出來,如微軟的Kinect[47],還有一些優秀算法也可以輕松生成人體骨架數據,基于骨架信息進行的動作識別可能會是之后動作識別領域的主流方式。
基于骨架序列做動作識別問題實際上是時序問題,傳統的方式是通過手工設計的特征來進行動作識別和判斷,這些特征包括不同關鍵點之間的位置偏移旋轉等,Wang 等[48]指出這種方式做動作識別會導致模型的泛化性能很差,基本只能針對特定的任務才能表現出效果,深度學習方式具有很強的抽取特征能力,在模型泛化性上會比手工設計特征的方式要好得多。
由于動作識別存在時域的信息,最早的思路是引入具有抽取時域特征能力的RNN 網絡,Du 等[43]采用了RNN 結構進行序列特征的表示,文中將人體的骨架序列分為五個序列部分分別輸入五個RNN子網絡之中進行序列特征的表示,采用了多層堆疊的方式處理前后輸入的特征,對最后輸出的特征向量進行分類判別動作。
人體骨架是一個自然的拓撲結構,而RNN 只能抽取其序列信息,在表征其特征時仍有不足,而圖結構可以有效表征圖拓撲結構數據特征,所以基于GCN 的方法被越來越多地應用于基于人體骨架的動作識別任務之中,使用GCN 的核心問題是如何將原始數據組織為特定的圖結構。Yan 等[44]首次提出了基于GCN 的動作識別模型ST-GCN(Spatial Temporal Graph Convolutional Networks),其將人的關鍵點作為時空圖的頂點,而時空圖的邊是用人體連通性和時間來表示,最后使用標準的SoftMax分類器對輸出的特征進行分類。
4.3 數據集
動作識別的數據集有兩種類型,一種是RGB 類型的,另一種是適用于基于骨架的行為識別數據集,這種類型的數據集通常還包含深度數據,這兩類數據集分別適用于不同的任務,進而又使得這些任務采用不同的方法,基于RGB的數據集主要用于Video-based的方法,而基于骨架行為識別類型的數據集主要用于Skeletonbased的方法。
UCF-101[49],這個數據集包含13 320個視頻片段,包含了101 種戶外的動作類別,是RGB 類型的數據集,其中視頻的幀率為25幀,視頻的分辨率為320×240,每段視頻剪輯的平均時長為7.21 s,視頻的總時長約為1 600 min,最短時長為1.06 s,最長時長為71.04 s。
HMDB-51[50],這個數據集的數據來源是youtube 上的電影以及視頻,具有7 000左右數量的視頻片段,分成了51組動作類別,這個數據集被分成了3個訓練集和3個測試集,集合之間是沒有重疊部分的,這個數據集也是RGB類型的數據集。
NTU-RGB+D[51],與其他數據集最大的不同是增加了深度數據,目前已有基于深度數據的算法[52],這個數據集的主要采集設備是Kinect v2,包含了56 880 個視頻片段,是目前最大的基于骨架行為識別類型的數據集,其包含了25個關鍵點的3D空間坐標位置。為適應不同任務目標的需求,其有兩個部分,分別適用于不同的評判標準,一個是Cross-Subject類型,總共包含40 320個視頻片段用于訓練集,另外的16 560個用于驗證集,根據不同的subject劃分為40個組,另外一類是Cross-View類型,包含37 920 個視頻片段用于訓練集,18 960 段用于驗證集,劃分的標準是根據相機視角不同劃分,相機2和3作為訓練集,相機1作為驗證集。
NTU-RGB+D 120[53],這個數據集屬于骨架動作識別類型,是近期出現的數據集,其包含120個動作類別,包含114 480 個骨架序列數據,在NTU-RGB+D 中表現良好的模型,在這個數據集中仍表現較差,是目前較為有挑戰性的數據集。
4.4 動作識別與智能診斷難點分析
常規人體動作識別本質上是屬于視頻分類任務,根據視頻數據判斷動作類別,而智能診斷系統需要對動作做更加細粒度的判斷分析,如動作的細節姿態、動作的頻度等方面,相比于常規動作識別,智能診斷系統對動作精度的要求更高,除此之外目前主流動作識別算法還存在一些難點:
(1)目前的動作識別算法對場景和物體的依賴性較大,由于視頻信息提取后建模的主要部分包括外觀信息,其中場景以及物體信息和動作信息耦合在一起,動作識別的結果不得不依賴于外觀信息的建模,這對模型的泛化性能是一個挑戰。
(2)主流動作識別算法中提取的光流特征是用來建模時域信息的,由于光流是計算視頻幀間差異,其表征長時動作能力有限,在建模時域信息上仍存在不足,智能診斷系統的輸入是長視頻段,具有豐富的時域信息,如何對時域信息的建模是核心問題之一。
(3)目前的動作識別數據集對于動作細粒度并沒有定義,如人體的變化姿態角度等更細節的問題,而這對于智能診斷系統的診斷效果很關鍵,因為診斷判斷的依據有時就是動作的細微差別,這要求診斷系統對于動作的細粒度如何定義需要更加明確,這也對數據集提出了更高的要求。
4.5 小結
動作識別相對人體姿態估計是更高語義層次的任務,依據目前的主流數據集和方法可以分為Video-based類型和Skeleton-based類型,相較于Video-based的方法,Skeleton-based 的方法使用的數據是骨架序列數據,其魯棒性要更強而計算消耗會更少,其數據的獲取方式可來源于Kinect 的采集數據也可來源于優秀的人體姿態估計算法,對于基于骨架模型的方式如何更好建模動作信息是核心問題之一,尤其針對骨架動作識別類型的數據集而言,目前比較有效建模的方法是基于GCN 的方法,因為圖結構是更好表征自然拓撲結構的方式。
依據動作識別的Video-based和Skeleton-based方法可將兒童運動障礙AI診斷系統的分為兩種方式:
Video-based診斷,這類方式的優勢是可實現端到端的訓練,網絡結構簡單,但是缺點是對數據集要求更高,且由于是直接處理的視頻數據,對于算力的要求也更高,適用于有良好數據集標注的情況。
Skeleton-based 診斷,這類方式的優勢是對算力需求較低,因為動作識別步驟需要處理的是skeleton數據,數據量比視頻更少,也減少了更多的干擾成分,但其目前的性能相對較差,且性能依賴于人體姿態估計算法的skeleton 生成結果,但其可作為一個模態的特征作為其他模型的補充,適用于多模態學習的情況。
5 結束語
人體姿態估計和動作識別是做兒童運動協調障礙兩個核心子任務,由優秀的人體姿態估計算法來生成準確的人體骨架模型,然后結合動作識別中基于骨架動作識別的算法進行動作判斷和打分,最終得到醫療層面的診斷結果,這是目前而言最能實現落地的技術路線方向,而不采用人體骨架模型中間層的技術路線實現起來的難度以目前的研究進展來看是相當大的,但其優勢是可實現端到端的訓練,對人體的特征建模能包含更豐富的信息。
兒童運動協調障礙AI 診斷系統想要實現落地目標,其未來重點研究方向包含兩個層面,第一是提升識別準確度方向,目前通用的數據集還沒有針對兒童的數據集,在做遷移學習過程中可能會產生準確度下降的問題,第二是降低計算成本方向,目前移動端設備的算力水準不夠滿足要求,直接在移動端給出診斷結果不僅診斷準確性會有所下降,計算速度也不達標,目前的常規解決思路是通過移動端進行數據采集,在服務端進行運算,這樣可以緩解移動端算力不足問題,該問題的另一個解決思路是做輕量化的模型,可將整體算力上的要求降低。
對于兒童運動障礙診斷系統目前數據集缺失問題,可行的解決手段主要有兩種方式,第一類是通過與醫院加強合作,這樣可以直接獲得所需的數據集,但這樣得到的數據集數量可能存在限制,第二類是在已有的小數據集基礎上,通過數據增強等技術手段擴展目前數據,可通過在主流數據集上進行預訓練,在小數據集上進行fine-tune的方式解決數據集不足問題。
AI 診斷系統的開發仍面臨著諸多難點,自動化診斷是其主流發展方向之一,通過建立數據采樣、數據分析、數據產出等自動化流程,可進一步實現技術落地和推廣,該技術的進一步發展有助于提升醫療普惠程度和醫療效率,對緩解醫療資源不足有著重要意義。
猜你喜歡
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
中國衛生(2014年2期)2014-11-12 13:00:16
