深度強化學習在智能制造中的應用展望綜述
2021-01-22 05:59:28孔松濤劉池池
計算機工程與應用 2021年2期
孔松濤,劉池池,史 勇,謝 義,王 堃
重慶科技學院 機械與動力工程學院,重慶401331
以人工智能為代表的第四次科技革命取得了眾多成果,眾多行業正進行著智能化的轉變。機器學習領域的深度學習(Deep Learning,DL)[1],已經能實現圖像識別[2]、音頻識別[3]、自然語言處理[4]等功能,出色體現深度學習在信息感知方面的能力[5]。強化學習(Reinforcement Learning,RL)[6]是人工智能的另一發展成果,含義是讓智能體在訓練中根據得到的獎勵和懲罰不斷學習,最終根據學習經驗做出高水平決策。目前在機器控制、機器人等領域應用廣泛[7]。人工智能的發展目標是實現具有觀察環境信息、獨立思考決策的智能體(Agent)[8],智能體不僅需要智能提取信息,還需要做出智能決策,并且可以積累經驗,保持學習的能力。深度強化學習(Deep Reinforcement Learning,DRL)[8]是實現這一目標的理論基礎,DRL作為人工智能的最新成果之一,功能強大且發展迅速。人工智能的眾多工作領域,如無人駕駛和智能流程控制,要實現智能體獨立完成觀察到動作的完整工作流程,單一的DL 或者RL 都對此無能為力,兩者結合才能完成任務。
DRL 的控制水平在很多領域的表現不輸人類甚至超越人類。阿爾法狗(AlphaGo)戰勝職業棋手李世石,顯示了智能體強大的學習能力。DRL 可以無監督的情況下獨立學習,可以學習人類專家的經驗,最終達到專家水平,甚至在某些方面超越人類。與人腦相比,計算機在連續控制中穩定性更高。以無人駕駛為例,智能體可以杜絕人類駕駛員的主觀錯誤,如疲勞、酒駕、分神等潛在事故因素。成熟的無人駕駛技術可降低事故率、保障交通安全,對于維護人民生命財產安全具有重要意義[9]。除了控制水平,在經驗遷移方面,智能體也更有優勢。智能體能通過直接的復制模型、數據分享等,完成批量的經驗傳遞。對于不同的設備和控制流程,只要有一定的相似性,都可以進行經驗遷移。遷移學習[10]為這種經驗復制提供了理論支撐,并產生了新的研究方向。
除了無人駕駛方面的應用,DRL 在計算機博弈、人機交互、機器人控制、文本生成等領域,都表現出較強的學習能力。
智能制造是由智能機器和人類專家組成的人機集成智能系統,它可以在制造過程中進行分析、推理、判斷、概念和決策等智能活動[11]。在智能制造中,DRL 可用于建立自學習、自適應、高效的智能機器。隨著DRL算法的發展和應用,越來越多的生產過程通過智能機器實現,真正實現無人化和規模化生產。深度強化學習的算法研究和在智能制造中應用研究,對人類跨入智能制造時代具有重要意義。
1 深度強化學習的基本原理
1.1 深度學習
深度學習(Deep Learning,DL)是神經網絡、人工智能、圖形建模、優化、模式識別和信號處理等研究領域的交叉領域。深度學習的提出受到視覺機理啟發,2006年,Hinton提出的一種稱為深度置信網絡的深度學習模型,揭開了深度學習發展的序幕。2012 年Hilton 團隊提出的AlexNet 模型在Imagenet 競賽中取得冠軍[12],帶來了深度學習的發展熱潮。深度學習提高了計算機對高緯度信息的提取能力,在此基礎上完成分類、識別等工作。
深度學習在信息提取方面的強大能力,主要是通過多層神經網絡內部的非線性變換實現的[1]。在深度強化學習算法中,目前主要有基于卷積神經網絡的深度強化學習和基于遞歸神經網絡的深度強化學習,分別代表卷積神經網絡和遞歸神經網絡與強化學習的結合。
卷積神經網絡(Convolutional Neural Network,CNN)在計算機視覺應用有突出表現,是近年來深度學習發展的熱門。在圖像處理時,網絡通過層層計算,提取圖像信息并對圖像信息降維,實現對圖像信息的計算機語言映射。常用的卷積神經網絡有LeNet[13]、AlexNet[14]、VggNet[15]、ResNet[16]等。
遞歸神經網絡(Recursive Neural Network,RNN)在自然語言處理中有突出應用,是一種擁有“記憶能力的神經網絡”。遞歸神經網絡雖然擁有這種“短期記憶”的優勢,但也存在不足,比如梯度消失和梯度爆炸帶來的影響[17];網絡訓練每一步都保留前面每一步的價值信息,而不是最近的和關系最大的。為了改善這些問題,Hochreiter 等[18]提出了長短期記憶網絡,通過增加線性干擾,讓網絡對信息選擇性地增加或減少,比如降低對較遠信息的權重,增加關系強的信息權重。對于遞歸神經網絡只向前反饋,目前狀態只依賴前面的輸出,而忽視了后面的影響,為了解決這個問題,Schuster等[19]提出了雙向遞歸網絡,可以對兩個方向進行學習。
1.2 強化學習
1.2.1 強化學習與馬爾科夫決策過程
強化學習(Reinforcement Learning,RL)的決策過程是智能體(Agent)與環境交互做出的馬爾科夫決策過程。其過程為智能體根據環境即時狀態St,為了獲得環境反饋給智能體的最大獎勵,做出智能體認為的最優動作a,其獎勵依據是,采取動作a 之后的狀態St+1的價值Rt(St,at,St+1),再加上后續所有可能采取的動作和導致的狀態的價值乘以一個折扣因子γ,求得的累積獎勵Gt為:
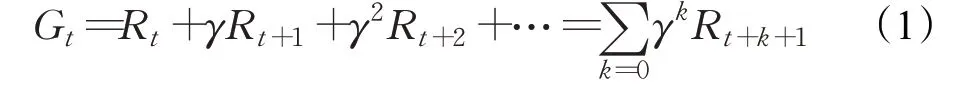
其中折扣因子γ 用于削減遠期決策對應的獎勵權重,原因是離當前狀態越遠,不確定性就越高,決策最終目標是為了達到目標狀態并實現累積獎勵最大化。強化學習的基本構架如圖1所示。
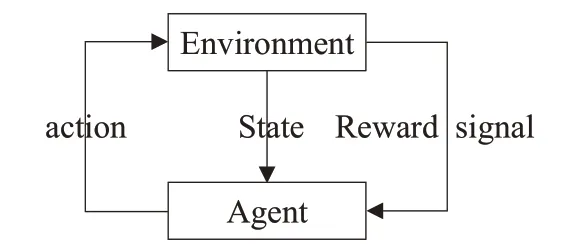
圖1 強化學習基本框架
強化學習根據模型是否已知,可以分為基于模型的強化學習(Model-Based Reinforcement Learning,Model-Based RL)和無模型強化學習(Model-Free Reinforcement Learning,Model-Free RL)。兩種強化學習方法各有優勢,基于模型的強化學習擁有較高的學習效率,最典型的就是AlphaGo和AlphaZero。但大多數實際控制領域都是未知復雜環境,在模型未知的情況下完成控制任務,因此應用較多的是無模型強化學習。
1.2.2 價值函數
對于連續控制環境,狀態信息非常巨大,無法對每一個狀態和行為都采用查表式的方法存儲每個狀態和行為的價值。強化學習解決此類問題需要引入適當的參數,恰當地選取描述狀態的特征,通過構建一定的函數,來近似計算得到狀態或行為價值。連續控制中這些由特征描述的狀態,通過近似價值函數計算價值,而不必存儲每一個狀態的價值,大大提高了算法效率。帶參數的價值函數,確定參數才能確定價值函數,參數求解多采用梯度下降法訓練求解,例如經典的強化學習算法:深度Q學習。
基于價值的強化學習存在一些不足:在空間規模龐大和連續行為的狀況下不適用;對隨機策略的求取能力差,無法單獨應付連續動作問題,導致強化學習的學習能力差。
1.2.3 策略函數
解決連續控制問題可以進行策略的直接學習,即將策略看成是狀態和行為的帶參數的策略函數。通過建立恰當的目標函數,利用智能體與環境的交互產生的獎勵,學習策略函數的參數。基于策略函數的強化學習可以省略對狀態的價值的學習過程,針對連續行為空間可以直接產生具體的行為值。
基于策略的強化學習存在的最明顯的缺點是:在一些復雜問題的求解中,計算難度大,迭代時間過長。
1.2.4 演員評論家方法
Actor-Critic算法是基于價值函數和策略函數,分別創建網絡。基于策略函數的網絡,代替策略函數充當演員(Actor),產生行為與環境進行交互;基于價值函數的網絡,代替行為價值函數充當評論家(Critic),評價演員的表現,并指導演員的后續動作。這種算法一方面基于價值函數進行策略評估和優化,另一方面優化的策略函數又會使價值函數更加準確地反應狀態的價值,兩者互相促進最終得到最優策略。
2 深度強化學習主要算法
深度強化學習的主要算法有兩種類型:基于值函數的DRL和基于策略梯度的DRL。主要算法如表1所列。
2.1 深度Q學習算法及其改進
深度Q網絡[25](Deep Q-Network,DQN)是基于使用卷積神經網絡來代替強化學習的近似價值函數,原理是:利用神經網絡的非線性表示能力,表示出某一確定環境下所有可能行為及其對應的價值。參數Q(s,a)是針對特定狀態產生的狀態行為價值對,其中s 表示狀態,a 表示行為。DQN算法通過訓練神經網絡,替換對非線性函數的參數的求解。DQN算法的核心是目標函數、目標網絡和經驗回放,使DQN算法較好地學習得到強化學習任務的價值函數。
DQN算法使用一個權重參數為θ 的深度卷積神經網作為動作值函數的網絡模型,通過該模型Q(s,a,θ)模擬動作值函數Qπ(s,a),即:

DQN 使用均方誤差(Mean-square Error)定義目標函數,作為深度神經網絡的損失函數,公式為:
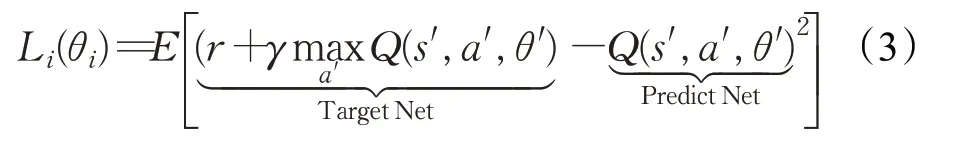
式中,參數s′和a′為下一時間步的狀態和動作,γ 為折扣因子。該目標Q值使用目標網絡(Target Net)進行預測,而當前Q 值使用預測網絡(Predict Net)進行預測,使用均方誤差計算Q-learning的時間差分誤差。計算網絡模型參數θ 的梯度公式為:
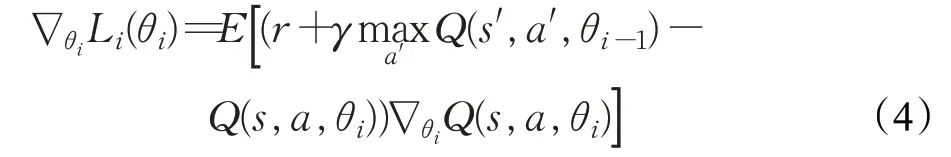
式中,i 代表迭代次數。DQN使用小批量隨機梯度下降法實現網絡模型對目標函數的優化。每產生一個行為a 和環境實際交互后,神經網絡都會進行一次學習并更新一次參數。
DQN 算法可以通過Q 值實現對環境的端對端控制,在Atari2600游戲中取得超越人類的成績[26]。其主要不足為:不能保證一直收斂,因為這種估計目標值的算法過于樂觀,高估了一些情況下的最優值,導致算法將次優行為價值認定為最優行為價值。后續對DQN的改進方法中,根據側重點的不同,改進方向可以分為:改進訓練算法、改進神經網絡結構、改進學習機制、新提出RL算法這四大類,不少改進方法在解決舊問題的同時,也帶來了新問題。比如:Van Hasselt等提出雙價值網絡的DDQN[27]被認為較好地解決了價值高估問題,但帶來了新的價值低估問題,還需要進一步的研究。Anschel等[28]提出平均DQN,基于過去一定步數學習的Q值的平均,再取最大值作為新的目標值,這種方法提高了穩定性,在眾多游戲測試中優于DQN 和DDQN,但也帶來了訓練時間大、成本高的問題。DQN 算法和主要擴展及其所屬方法分類如表2所示。
除了在游戲控制方面,DQN 及其擴展算法在其他連續控制領域中有很多應用嘗試。Liu等[37]提出一種基于DQN 的無人機空戰智能決策方法,采用Q 網絡實現動作值函數的精確擬合,仿真結果證明了DNQ 算法在行為與獎勵兩方面都有突出表現;Huang 等[38]設計了一種DQN 算法來優化無人機的導航與路線,數值結果表明,設計的DQN導航可以給出較好的測量;Sharma等[39]提出一種基于視覺的DQN算法來控制四旋翼無人機的自主著陸,模擬結果表明,僅需低分辨率的相機就能實現著陸,在某些狀況下優于人類駕駛員。Ao[40]提出了一種基于DQN(Deep Q-learning Network)的熱過程控制方法,通過設計的DQN 控制器的水箱水位控制系統仿真實驗證明,DQN 算法可以很好地應用于熱過程控制。可預見,DQN及其改進型號,將會在更多控制領域得到實際應用,但這些控制任務,過于依賴狀態控制,尤其是最終狀態,所以這些應用還停留在實驗階段。

表1 主要深度強化學習算法分類
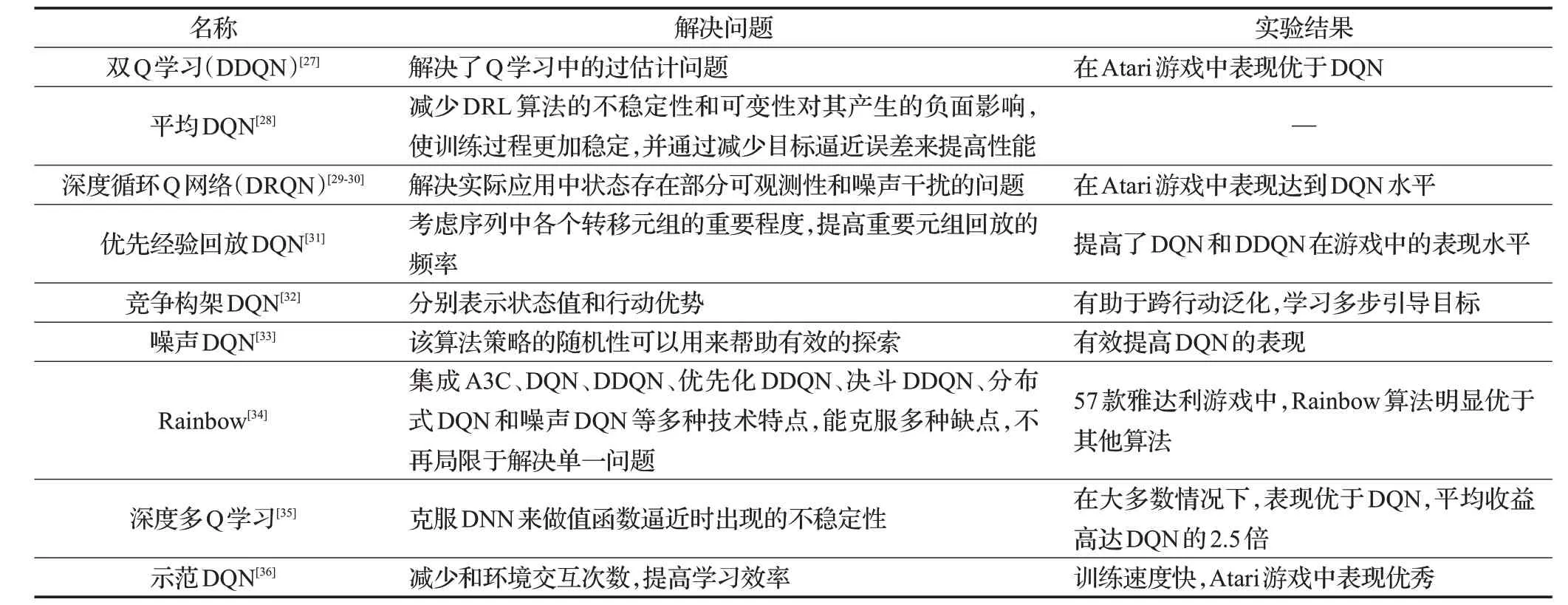
表2 DQN算法的改進算法、解決問題和實驗驗證結果
DQN 算法實現了深度學習和強化學習的結合,對深度強化學習的發展有重要意義。但DQN算法及其改進類型在實際應用中存在不足:無法處理連續動作控制任務。
2.2 基于策略梯度的深度強化學習算法
2.2.1 深度確定性策略梯度算法及其改進
深度確定性策略梯度(DDPG)算法是基于深度學習、DQN 算法、Actor-Critic 網絡的確定性策略算法,2016 年DeepMind 團隊首次提出。相對于DPG,DDPG的核心改變是采用深度神經網絡建立Actor 和Critic 的近似價值函數,并使用深度學習訓練網絡,Actor網絡直接生成確定的行為,Critic網絡評估策略的優劣。DDPG具有更高的學習效率,將復雜的控制問題直接與策略行為掛鉤,是目前應用于復雜、連續控制的重要算法。
DDPG 結合了之前算法的優點,特別是DQN 的改進方案,具有更高的學習效率,將復雜的控制問題直接與策略行為掛鉤,應用領域有:機器人控制、自動駕駛、無人機等。Casas[41]使用DDPG優化控制交通信號燈,將區域而非單獨路口車輛檢測器的信息當作輸入,智能處理交通信號燈問題,改善了各個路口信號燈固定不變引起的交通不協調問題;Phaniteja 等[42]使用DDPG 進行具有27 個自由度的機器人保持平衡的關節空間軌跡訓練;Do等[43]開發的機器人澆筑實驗,在避免碰撞和傾灑的情況下將液體倒入指定高度。應用較多還有無人駕駛領域,眾多的無人汽車與無人飛行器基于DDPG進行使用,也在實際應用中推動DDPG的發展。
DDPG 最重要的突破就是在解決連續控制問題上具有較高效率,缺點有訓練時間過長、訓練數據需求大、訓練初期的學習策略不穩定等。
Houn等[44]提出一種基于知識的DDPG算法(Knowledgedriven Deep Deterministic Policy Gradient,KDDPG),能夠在沒有大量數據的情況下,較穩定地讓機器人完成裝配學習。Zheng等[45]提出一種自適應雙引導DDPG算法(Self-Adaptive Double Bootstrapped DDPG,SOUP),將一根DDPG算法擴展到多個演員評論即架構,通過多對搭配使用的演員和評論家,學習多個策略并評估,從而得到更高的學習效率。Zhang等[46]針對DDPG算法訓練數據需求大、訓練效率低的問題,提出了異步章節式DDPG(Asynchronous Episodic DDPG,AE-DDPG),AE-DDPG 中的智能體可以同時與多個隨機環境交互,從而實現很高的數據吞吐量,并采用情景控制思維[47]重新設計DDPG的經驗回放,使智能體能夠快速鎖定高回報政策。
2.2.2 優勢函數
優勢函數是衡量一個動作帶來的回報的重要手段,是計算A3C算法、TRPO算法的重要組成。已知Q值函數Qπ(St,at)和狀態值函數Aπ(St),優勢函數Aπ(s,a)的計算公式為:

值函數V(s)可以理解為在該狀態下所有可能動作所對應的動作值函數乘以采取該動作的概率之和。動作值函數Q(s,a)是單個動作所對應的值函數,Qπ(s,a)-Vπ(s)能評價當前動作值函數相對于平均值的大小。這里的優勢值指的是動作值函數相對于當前狀態的值函數的優勢。如果優勢函數大于零,則說明該動作比平均動作好,如果優勢函數小于零,這說明當前動作還不如平均動作好。
2.2.3 信賴域策略優化算法及其改進
策略梯度的方法存在問題:不能保證得到合適的步長使學習最有效,方法迭代的效果受步長影響較大,如步長太小,訓練效率太低,如步長過大,噪聲影響反饋信號,學到的可能是更壞的策略。找到合適的步長,保證學習效果最起碼不會變差,即保證策略更新后的回報函數單調遞增,John Schulman 提出了信任域策略優化方法(Trust Region Policy Optimization,TRPO)。
TRPO 算法最大的優勢在于確保策略模型在優化模型時單調提升,穩定地改進策略。TRPO算法的核心思想是建立在優勢函數上,主要支撐是找到一種衡量策略之間優劣的計算方法,并以此為目標最大化新策略和舊策略相比的優勢。單調提升算法的整體思路簡單,但具體的設計和計算非常復雜。
TRPO 算法最大的優點是能保證策略始終朝著好的方向持續更新,缺點主要有:計算過程復雜、對策略與環境的交互依賴大、缺乏步長選擇準則。
Jha等[48]針對TRPO算法步長選取準則不足、收斂速度慢等缺點,提出準牛頓信賴域策略優化算法(Quasi-Newton Trust Region Policy Optimization,QNTRPO),QNTRPO 與TRPO 的主要不同在于每次策略迭代的計算步驟,QNTRPO在相同的計算成本下比TRPO有更大的計算速度;Gupta等[49]提出一種合作強化學習算法,將信賴域策略優化算法擴展到大型智能體控制任務,可以讓幾十個、數百個智能體合作來完成任務,并可以在連續動作空間縮放,稱為PS-TRPO。實驗證明,PS-TRPO算法在多智能體協同領域,比DQN 和DDPG 擁有更多優勢。根據PS-TRPO 算法開發的三個智能體學習系統,在連續動作空間也有很好的表現;為提高TRPO 在稀疏獎勵的強化學習中的表現,Zhang 等[50]提出了后見信任區域策略優化算法(Hindsight Trust Region Policy Optimization,HTRPO),HTRPO使用二次KL估計逼近,減少方差,提高學習穩定性,設計了后知目標過濾機制,縮小后知目標空間與原始目標空間的差異,獲得更好的學習效果。HTRPO 在一些離散和連續的控制任務,比TRPO有更強的學習能力。
Schulman 等[51]在TRPO 算法基礎上提出了最近策略優化算法(Proximal Policy Optimization,PPO),與TRPO 算法最大的不同是PPO 算法可以實現多個時期的小批量更新,實現比TRPO 更簡單的計算,也具有更好的樣本復雜度。Heess 等[52]提出了分步式PPO 算法(Distribute PPO,DPPO),提高智能體在獎勵信號有限的條件下的學習水平。在控制實驗中,DPPO在更高的效率下實現了類似于TRPO的性能。除此之外,Shani[53]、Liu H[54]、Liu B[55]等都對TRPO 信任域策略算法做了改進,在算法或者應用上取得了一定進展。
2.2.4 異步優勢演員評論家網絡算法及其改進
Mnih 等人基于異步強化學習(Asynchronous Reinforcement Learning,ARL)的思想,提出一種輕量級的深度強化學習框架:異步優勢的演員評論家算法(Asynchronous Advantage Actor-Critic,A3C),A3C 算法使用異步梯度下降算法優化深度網絡模型,并結合多種強化學習算法,能夠使深度強化學習算法基于CPU 快速地進行學習。
A3C算法核心是:優勢函數演員評論家算法和異步算法的結合。演員評論家算法在A3C算法中,包括基于策略學習的演員和基于價值學習的評論家。優勢演員評論家算法,是在演員評論家算法基礎上,對評論家模型進行更新時,引入優勢函數的概念,以確定其網絡模型輸出動作的好壞程度,使得對策略梯度的評估偏差更少。A3C的異步操作是指:利用多個智能體與多個環境進行交互,提高學習效率。異步構架主要由環境、工人和全局網絡組成,其中每個工人作為一個智能體與一個獨立的環境進行交互,并有屬于自身的網絡模型。不同的工人同時與環境進行交互,其執行的策略和學習到的經驗都獨立于其他工人。因此該多智能體異步探索的方式能夠比使用單個工人進行探索的方式更好、更快、更多樣性地工作。
A3C算法可以得到更好的收斂性,在高維控制和連續空間的表現更好。Lin 等[56]在A3C 算法基礎上,提出一種協同異步優勢演員-評論家算法(collaborative Asynchronous Advantage Actor-Critic,cA3C),智能體在線學習深度知識提取,實現自適應的知識轉移。實驗表明,cA3C算法的收斂水平比A3C更高,也獲得了更高的獎勵;針對A3C算法的優勢函數存在方差,影響性能的問題,Chen 等[57]提出了一種平均異步優勢演員-評論家算法(Averaged Asynchronous Advantage Actor-Critic,Averaged-A3C),降低優勢函數的方差。Averaged-A3C主要改進是對已經學習過的狀態值取平均來計算優勢函數,提高訓練過程的穩定性。實驗表明,Averaged-A3C比A3C算法擁有更好的性能和穩定性。Kartal等[58]將A3C算法與末端預測(Terminal Prediction,TP)結合,提出了一種末端預測的異步優勢演員評論即算法(A3C-TP),主要改進是智能體在學習控制策略時,預測目前狀態到最終狀態的距離從而促進學習。在Atari游戲和雙足步行者領域的實驗結果表明:在大多數測試領域中,A3C-TP 的表現優于標準A3C;Labao 等[59]提出一種融合梯度(Gradient Sharing)共享的異步優勢演員-評論家算法(A3C-GS),A3C-GS算法具有在短期內自動分散員工政策進行探索的特性,在政策多樣化的情況下,理論上算法長期收斂于最優政策。實驗表明,A3C-GS算法在高維環境中比其他基于策略梯度的算法表現更好,取得了更高的分數。Hernandez-Leal[60]、Wang[61]、Holliday[62]等都對A3C 算法進行了改進實驗,取得了一定進展。
總的來說,A3C算法,降低了DRL對計算機計算性能的要求,并且在效果、時間和資源消耗上都優于傳統方法。但對于實際問題,計算機計算能力仍然限制了A3C算法的潛力。
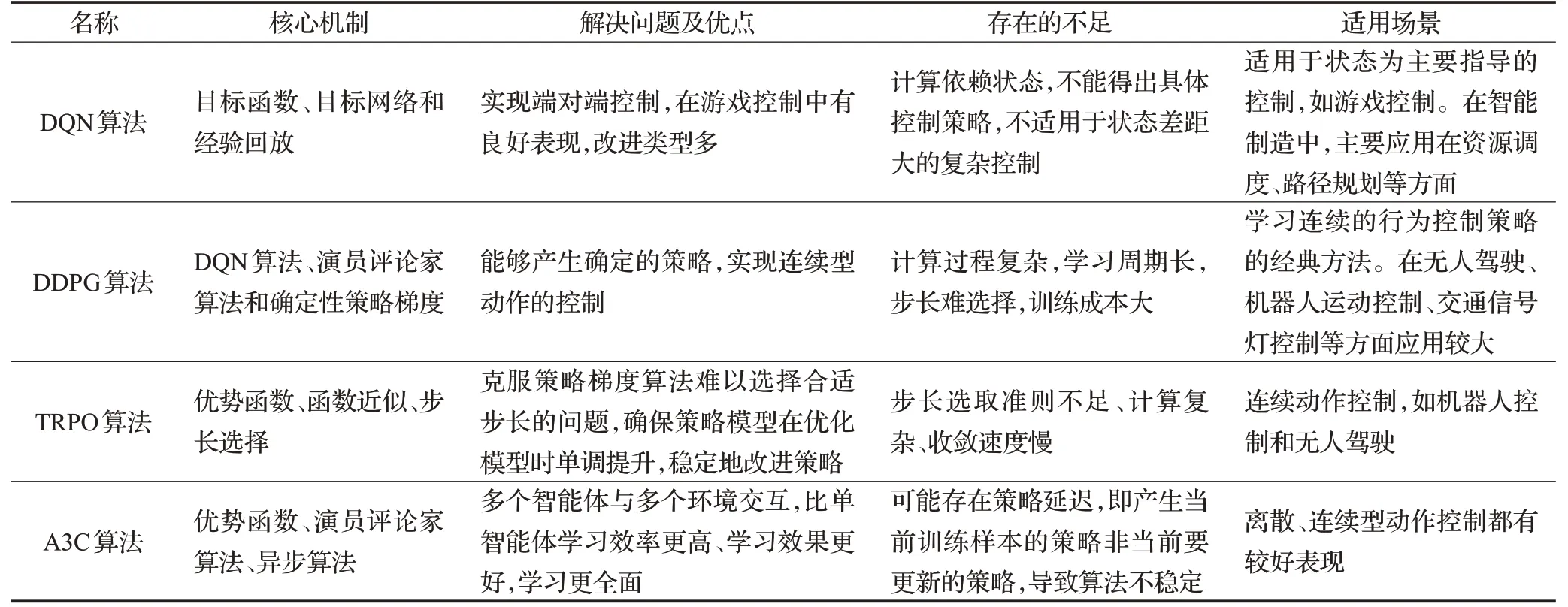
表3 主要研究結果提煉表
2.3 其他相關研究
除了基于值函數和基于策略梯度的算法進展的研究,通過其他角度對深度強化學習的研究也取得了一些進展。基于模型的強化學習(Model-Based RL)算法能夠更高效地學習,但很難擴展到深度神經網絡這種表達能力強的模型,無法應用到復雜、高維的控制任務。將深度神經網絡應用到Model-Based RL上的研究很有價值。Luo等[63]提出了一種基于模型的隨機下界優化算法(Stochastic Lower Bounds Optimization,SLBO),通過實驗表明,在一系列連續控制基準測試任務中,SLBO只需要較少樣本就達到了比原算法更高的學習率。Nagabandi[64]、Ebert[65]、Huang[66]等都對Model-Based RL應用在高維控制任務上做了一些研究。
強化學習是基于獎勵調整策略,但在一些復雜任務中,環境在到達最終結果前回報稀疏,強化學習任務面臨反饋稀疏的問題,影響學習效率。Kulkarni 等[67]提出一種分層DQN算法(hierarchical-DQN,h-DQN),開創了層次強化學習算法(Hierarchical Reinforcement Learning,HRL),層次強化學習將控制任務分成若干層次,從多層策略中學習,每一層都負責在不同的時間和行為抽象層面進行控制。最低級別的策略負責輸出行動,使更高級別的策略可以在更抽象的目標和更長的時間尺度上自由運作。Vezhnevets[68]、Nachum[69]、Rafati[70]等都對HRL做了研究。
對于復雜任務,獎勵稀疏問題會導致設定獎勵函數非常困難,給出的獎勵函數也并非完全可以衡量決策的好壞。基于Ng 等[71]提出的假設專家最優思想,利用專家數據采用函數近似的方法建立獎勵函數,這種稱為深度逆向學習[72]的方法,可以作為研究復雜環境下的獎勵函數的新方法。You 等[73]在無人駕駛中,通過收集專家駕駛員的大量演示,使用深度逆向強化學習方法學習基于數據的最優駕駛策略,利用神經網絡逼近專家駕駛員數據的獎勵函數,實現期望的駕駛行為。Fahad 等[74]研究了機器人學習人類導航的深度逆向強化學習方法。此外,在過程控制領域,某些復雜控制任務,通過逆向強化學習方法,讓機器學習專家知識,獲得較高的控制水平,也是很有價值的研究方向。
2.4 主要研究成果對比分析
上述深度強化學習的研究,都取得了一定成果,但這些研究的原理和研究角度的不同,決定了每種方法的特性和應用場景。主要提煉內容如表3所示。
除了從應用性能角度,DRL 算法的改進,對設備的要求程度和學習時間也是重要評判依據。這也是DQN發展到A3C算法的推動力之一,即提高學習速度和減少對硬件系統的依賴。其中一些算法的學習時間、計算機設備,以及在雅達利游戲中與原始實驗的得分對比率[24],如表4所示。
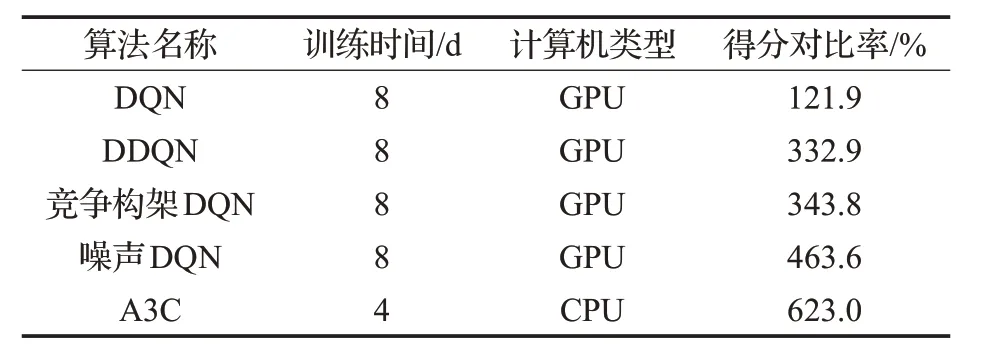
表4 一些改進算法的學習時間和設備表
綜上,DRL 算法發展的趨勢是更高的表現、更高的學習效率以及對硬件的更低依賴。
3 在智能制造中的應用展望
3.1 智能裝配
智能機器人控制是人工智能的標志性成果之一,可以分擔人類工作。工業機器人可以取代人類在一些高溫、高壓或者其他不適環境下工作,也可以完成一些體力工作。除此之外,還發展到一些高精度裝配工作。傳統的機器人編程通過定義裝備位置和動作進行工作,這種編程比較復雜,且不能適應環境變化,只能執行程序固定的工作內容,如果環境發生改變或者調整生產線,就需要重新編程。深度強化學習提供了解決這些問題的途徑,已經得到了多次驗證。Inoue 等[75]針對傳統機器人編程復雜、調參困難的問題,提出一種基于遞歸神經網絡的DRL算法模型,通過使用一個7軸鉸接機器人手臂,完成精度較高的插孔實驗,驗證模型的有效性,并計劃利用模型學習不同的生產環境參數,縮短適應新生產時間。Schoettler 等[76]針對傳統工業機器人缺乏自適應的特點,提出了利用DRL算法的解決方案,并通過一些復雜規格和形狀的實驗,證明DRL 可以解決復雜的工業裝配任務。Zhao 等[77]提出一種基于DRL 的工件裝配序列規劃系統(Assembly Sequence Planning for Workpieces,ASPW)的設計方法,對復雜裝配產品進行自動排序,提高裝配效率。在建立的實驗平臺上,設計出了一種新的ASPW-DQN算法,克服DRL算法缺乏獎勵和缺乏培訓環境的困難,在實驗中取得了較高的準確度。Wu[78]、Vecerik[79]、Xu[80]、Luo[81]等都對DRL算法應用在裝配機器人上做了實驗研究,取得了一定成果。相信在未來,工作精度高、適應能力強、崗位轉換容易的裝配機器人會出現。
3.2 智能運輸與路徑規劃
運輸機器人極大減輕了人類繁重的搬運工作,檢測機器人可到人類不能到達的地方對工業設備進行檢測,這都離不開機器人路徑規劃。傳統機器人主要依靠編程或者利用傳感器進行固定路徑行駛,可以滿足簡單的貨物運輸。傳統機器人在較復雜的工廠中,易受干擾;在出發點、目的地或者路徑狀況導致的運輸線路改變時,需要重新編程、調試,靈活性、經濟性較差;由于對一些惡劣環境掌握有限,傳統算法對未知環境的適用性較差。此外,研究人員還提出了蟻群優化[82]、粒子群優化[83]、模擬退火[84]和遺傳算法[85]等智能方法來解決全局路徑規劃問題[86],但這些方法在高維環境下表現不佳。DRL算法可以賦予機器人根據環境狀態和任務變化,自主規劃路徑的能力。比如在某一通道占用的情況下,仍能找到另一條道路到達目的地。Zhou 等[87]提出并驗證了一種基于DQN 的全局路徑規劃方法,能夠使機器人在密集的環境中獲得最優路徑。機器人的輸入方式是直接攝入圖像,能夠有效避開障礙物。Sui 等[88]設計了一種并行深度DQN 算法,求解多智能體約束的編隊路徑規劃問題。Wang 等[89]提出了一種基于雙DQN 和經驗優先重放的移動機器人路徑規劃方法,能夠通過感知周圍環境的局部信息,在未知環境下規劃路徑,通過實驗驗證了可靠性。這些研究表明,智能路徑規劃能夠讓工業機器人擁有更強的工作能力,應用廣泛,是人工智能研究的熱點領域之一。
3.3 智能過程控制
過程控制任務的主流控制器,包括單回路和多回路PID 控制器、模型預測控制器和各種非線性控制器,大多數現代工業控制器都是基于模型的,因此良好的性能需要高質量的過程模型。PID 控制器和基于模型的控制器需要定期維護以保持性能。通常的做法是持續監控控制器的性能,并在性能下降時啟動補救模型重新識別程序,維修過程通常是復雜的和資源密集型的,并且會導致工作中斷,代價較高。此外,在高級的控制任務中,很難建立高質量的模型,導致這些控制器很難適用于非線性或者高維控制任務。DRL 應用在過程控制領域,可以同時接受數據信息和高維信息,對環境的理解更具體,能夠根據獎勵不斷學習,提高控制水平,在一定程度上時間越久,學習水平越高,保持較高的控制性能,節省維護成本。Andersen 等[90]對DRL 應用在過程控制做了相關理論研究。Spielberg 等[91]提出一個基于數據的DRL控制器,通過與過程交互學習控制策略,并且通過大量仿真驗證了DRL控制器的有效性和優越性。在未來,除了現有的自動控制環節,更多目前需要人工控制的崗位,也可以通過DRL算法取代。
3.4 新智能調度
傳統的智能調度方法有:基于知識的系統、專家系統、遺傳算法、模擬退火、神經網絡和混合系統等,這些調度方式過于依賴人工調度的淺顯知識[92],不能解決復雜的調度問題,并且實時控制性較差,將DRL應用于智能調度的新智能調度可以解決上述問題。新智能調度在智能制造中可以完成資源分配工作和任務分配工作,并且擁有一定實時反應能力。Singh等[93]針對運輸資源的分配問題,提出一種基于DRL的車輛調度框架,通過與外部環境的相互,分別為每輛車輛學習最優策略。實驗結果表明,該框架可以提高20%的車輛利用率,乘客等待時間與車輛巡航時間降低34%。這種方法沒有考慮每個車輛間的相互影響,雖然降低了計算難度,但調度策略對于全局來說不能保證是最優策略,不適用智能制造全局調度的要求。Hua 等[94]采用DRL 算法進行資源調度,對分配任務中的限制條件進行考慮,采用無模型方法解決一些限制條件沒有明確公式關系的問題。研究對既需要全局調度,又存在子區域調度的問題,采用A3C 算法進行最優控制,在仿真實驗中驗證了有效性。但這種方法沒有考慮子區域之間的相互影響,仍然存在全局最優考慮不足的情況。對于調度任務,調度環境越大,全局性越強,對計算的要求越高。在計算能力有限的情況下,適當將大區域調度分割為子區域調度,可以平衡計算與策略最優程度的關系。Mao 等[95]的研究在智能調度中加入了有限考慮考慮級別。在智能制造中,某些生產或者資源需要優先考慮。具體方法是使用前饋神經網絡結合演員評論家算法,實驗結果表明,該算法都收斂于最優性間隙小于4%的理論上界。在考慮了優先性和公平性的情況下,該算法具有較大實用價值。在未來可以繼續考慮劃分更多優先等級,并根據實際生產狀況,自動調節優先等級。Guan等[96]研究了利用DRL算法解決在資源分配中的近實時性問題,即在單位時間里根據環境調整一下分配策略。該研究基于DRL算法設計了一種經濟電力調度模型,利用DRL 的連續控能力在單位時間間隔調整一次分配狀態。這種方法既節省了計算資源,又具有一定實時控制性能,在大型資源分配中有較大應用前景。但這種方法不能保證收斂性,未來需要繼續改善計算性能。Li[97]、Waschneck[98]、Liu[99]等從不同角度對DRL 在智能調度中的應用進行研究。
3.5 其他應用展望
DRL擁有獨特優勢,在智能制造中擁有較大應用空間,除了上述應用展望之外,DRL還可以結合傳統專家系統,產生新一代反饋學習專家系統,能夠在給出專家知識之后,根據反饋繼續學習,提升診斷水平和決策水平,這可以更好發揮專家系統的潛力。專家系統的建議一般假設為最優,限制性在于對問題的診斷水平,結合DRL的專家系統可以根據獎勵提高診斷水平,提高故障與對策的匹配水平;DRL可以設計出一種對工業設備壽命或者狀態的置信預測器,例如對一些高溫高壓的儲存設備,將已經發生過的實際數據當作輸入進行學習,一次性預測未來一定時間的各項參數,并在預測日期到達之后,與產生的真實數據對比,產生的反饋來修正預測網絡,這樣隨著時間的增加,預測水平可以保證一定時間段的準確性。這種方法可以比傳統檢測更加可靠和經濟,擁有較大的研究價值。
4 存在的問題和未來發展方向
深度強化學習(DRL)是比較新的技術,功能強大,但也存在必須解決的問題,并可能催生新的發展方向。
(1)DRL 是機器模仿人類的方法,由于對人腦的了解還不夠,還缺乏與之對應的人腦機理知識。比如深度學習(DL)的機器視覺對應人腦神經元的視覺機理,但強化學習(RL)的策略目前與人腦生物學知識的對應不足,限制了強化學習新的發展突破。未來需要對人腦有進一步的研究,并與深度強化學習理論對應,從而突破人造智能體的技術障礙。
(2)計算能力的提升是將深度強化學習應用在實際中的必備條件。目前主流改進方案是算法的提升和硬件設施的進步。隨著云計算技術等網絡大輸出處理技術的進步,通過這些技術結合DRL,將DRL的計算任務在線分配處理,批次處理某一區域或者任務的計算,可以帶來DRL計算速度的大提升。
(3)基于模型強化學習雖然目前應用受限,但未來發展潛力巨大。隨著DRL 學習能力的提高,智能體能夠學習復雜環境的模型,并且可通過模型預測未來。對于一些復雜但封閉性較強的制造環境,基于模型的強化學習有較大的研究價值。
(4)DRL 訓練的支撐是反饋獎勵,應用在工業過程控制中,如何充分利用專家數據提高學習能力,節省學習成本,是很有價值的研究方向。對于稀疏獎勵任務,可以根據與專家做法的重合程度,設置短期獎勵,提高學習效率。
(5)DRL 是將DL 和RL 結合的技術,但DRL 的控制,如機器人、無人車等,嚴重依賴DL 的視覺輸入,但DL 目前只能發揮感知作用,無法取代力學分析等深層知識,造成DRL 的一些仿真研究與現實應用有較大差距。未來將DL 和RL分開研究,獲得更高的穩定性,然后再拼裝,也是很有價值的研究方向。
(6)DRL 算法可以解決智能控制的程序問題,但與之匹配的工業硬件設施還沒有相關標準,例如能處理海量工業數據的計算機、能夠測量數據傳輸且接收指令的智能閥門等,都是與理論算法相匹配的研究重點。
5 結束語
本文對深度強化學習的原理進行了講述,包括深度強化學習的原理,以及深度強化學習主要的算法發展。可以看到深度強化學習的算法已經發展出了很多成果,應用水平也不斷提高。可以得到深度強化學習算法的發展方向有:更高效的學習、更快的計算結論、更準確的評估獎勵。隨著一些關鍵問題的解決,在未來的智能制造業中,深度強化學習可以擔任更多角色。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
