電網行業元數據集成數據存儲策略研究
2021-01-28 03:35:42萬嬋魏理豪楊秋勇楊朝誼蘇華權
微型電腦應用 2021年1期
萬嬋, 魏理豪, 楊秋勇, 楊朝誼, 蘇華權
(廣東電網有限責任公司 信息中心, 廣東 廣州 510000)
0 引言
隨著電力行業以及智能電網技術的持續發展,電網行業中形成了大量的智能配用電數據,此類數據包括不同的類型,并且涉及到了不同的用電主體,例如有企業、政府等,而各個主體的業務以及工作重心存在明顯的差異性,使得智能配用電數據表現出不同的特征。一是具有較高的數據維度,首先是電力企業的業務類型不一,并且眾多的業務之間具有較高的獨立性,但是無法保證各個系統數據采集時間的一致性,這是增大數據維度的重要因素;其次是不同主體在智能配用電數據的存儲與管理方面難以保持一致,顯著提高了數據維度[1-3];二是不同形式的智能配用電數據并存,從數據類型的角度來看,一般可以將智能配用電數據劃分為結構化、非結構化以及半結構化類型,通常三者是共存的。其中結構化數據主要指的是定義比較明確的數據類型,包括常見的數據庫表中的結構化數據等,而這正是傳統的智能配電網業務相關的數據類型。在智能電網等新技術發展的過程中,智能配用電的基礎分析數據變得更加豐富,不再只是傳統的結構化數據,而是集成了音頻、圖片以及視頻等類型的非結構化數據,在這種情況下逐步形成了三種數據類型共存的局面[4-9]。由此看出,智能配用電數據總體體現出數據規模大、更新頻率高等特點。如采用傳統的數據管理方式,已經無法滿足智能配用電數據的管理要求。與此同時,存儲設備、處理器等硬件也處于高速發展的狀態,此類技術的發展都為智能配用電數據的管理提供了支持。因此,應結合大數據處理技術等新技術來實現對智能配用電數據的妥善管理,從而為用戶提供更高質量的數據服務。
1 配用電大數據多源集成
隨著數據處理技術的不斷發展,逐步出現了更先進的數據集成技術,能夠對各種異構數據源內的數據進行統一管理,降低由于數據格式不同而產生的影響,從而提升數據的使用效率。由于配用電數據的類型較多,在這個過程中不可避免的存在異構化問題,目前主要利用數據規范化以及生成標準化元數據的方式進行處理,其中前者主要是根據構建的數據字典來規范數據的存儲格式;后者則是將各種類型的數據轉化為規范化的XML格式數據[10-11],在這個過程中首先要通過預處理技術解析非結構化、半結構化以及結構化數據的內容,由此形成標準的XML格式數據,然后利用中間件技術來實現對標準格式數據的管理。
1.1 數據預處理
對于智能配用電數據的處理過程來說,首先應該進行預處理的過程,具體包括數據的篩選、歸一化等過程,由此可以將各種類型的元數據存儲為統一的XML 格式,并保存在集群節點中,從而為數據的查詢與應用奠定良好的基礎。其中數據的預處理過程,如圖1所示。
(1) 數據篩選
首先是進行數據篩選的過程,其實就是先采用一定的方式對現有的數據進行過濾,將無用或者干擾數據剔除,一般包括數據分類、屬性識別等過程。
(2) 數據變換
在數據篩選完成后,即需要進行數據變換的過程,數據變換有不同的方法,例如有平滑聚集、簡單函數變換等,在實際應用中應該根據具體要求選擇合適的方法,通過數據變換即可得到 XML 格式的元數據。
(3) 數據歸一化
在數據變換之后需要進行歸一化的過程,即采用規范化的XML格式表示數據,目前數據歸一化的方法較多,常用的有離散化方法、維度歸一化方法等。對于本文研究的智能配用電數據來說,首先將原始數據轉化為標準的XML 格式數據,然后按照合理的方式對電網數據進行命名,如果元數據屬于電網外部,則主要劃分為電力用戶、第三方機構以及政府元數據;而電網內部的元數據主要是根據電壓等級進行劃分,具體包括0.4 kV、10 kV、35 kV、110 kV電壓等級元數據。在完成數據的預處理工作后會得到較為規范的XML 元數據集,便于對數據進行后續的處理。
1.2 中間件技術
中間件技術已經廣泛應用于不同類型的系統設計中,能夠對不同的技術提供統一的數據訪問接口,從而實現數據的共享與交換。隨著對中間件技術研究的增多,逐步出現了多種類型的中間件技術,并獲得了較多的應用。在本次研究中主要使用了數據訪問中間件技術,通過這種方式能夠有效地管理XML 元數據倉庫。其具體的流程,如圖2所示。
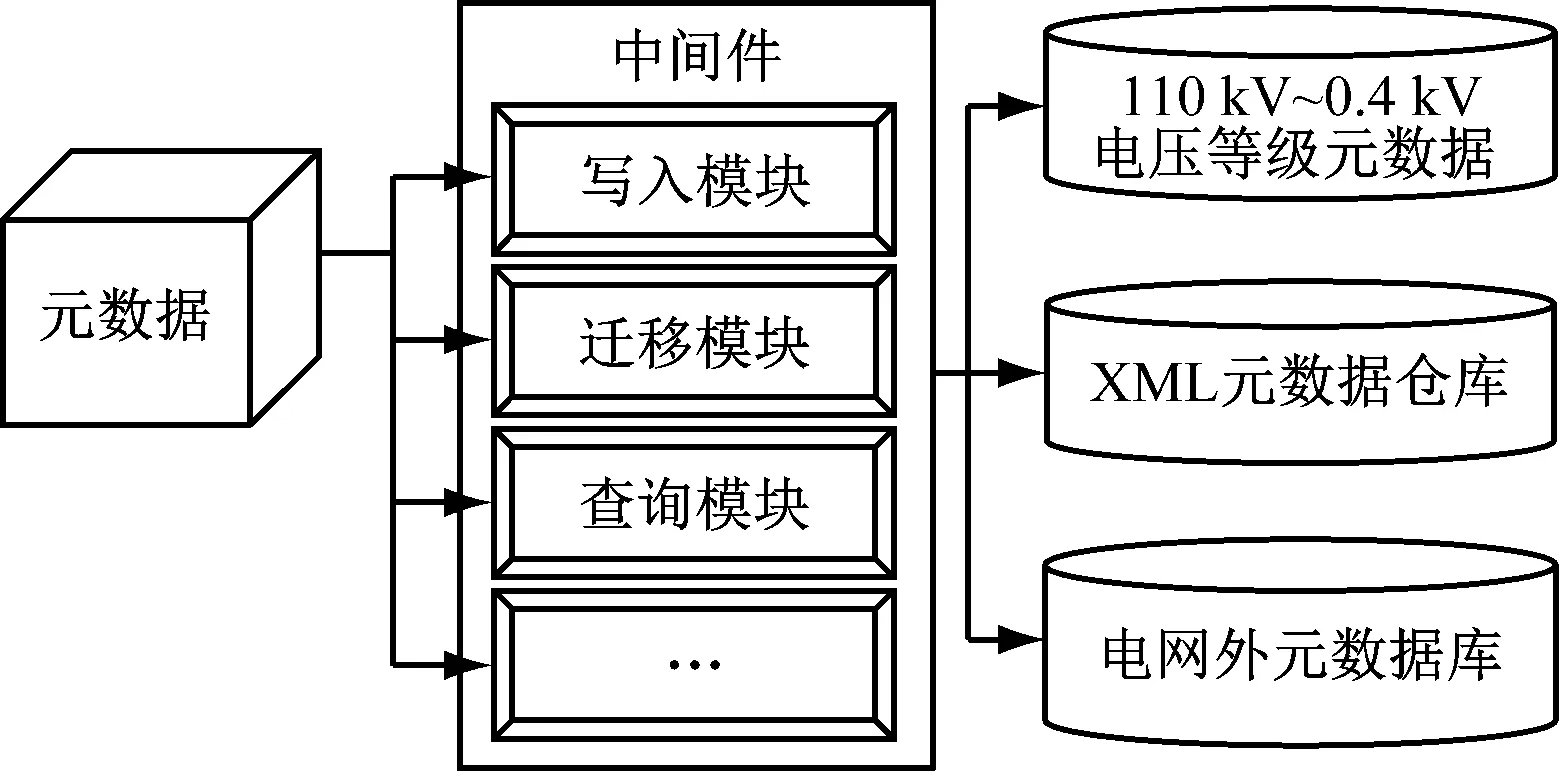
圖2 基于中間件的元數據管理
2 基于Hadoop的多源配用電大數據存儲優化
2.1 數據分布問題
當前在電力數據管理方面大多采用了關系型數據庫實現數據的管理與存儲,這種方式能夠滿足大多數情況下的數據管理需求。但是隨著電力行業的持續發展,特別是智能電網以及微電網技術的出現,電力數據呈現出更大規模、更高量級的特征,只是采用傳統的集中式關系型數據庫已經無法滿足數據管理需求,并且還存在查詢速率慢、安全性低等問題。為了有效地解決這些不足問題,很多學者進行了研究,逐步形成了更先進的數據管理技術。其中基于Hadoop的分布式文件系統HDFS即為一種有效的解決方案,已經廣泛應用到了海量數據的存儲中,在實際案例中的應用效果證明了其在大規模數據存儲與管理中的優勢,未來具有廣闊的應用前景。
2.2 基于哈希分桶算法的數據存儲優化方法
很多學者在分布式數據儲存領域進行了研究,并提出了不同的數據優化算法,其中哈希存儲算法在數據存儲優化方面得到了較多的應用。部分學者提出多副本一致,哈希算法在分布式數據存儲方面能夠達到一定的優化效果,但是這種方式存在一定的不足,即忽略了數據自身的關系,無法直接應用到本文研究的配用電數據中。實際中的配用電數據具有較多的類型[12-15],例如有用電負荷數據、氣象數據以及地理數據等,此類數據一般不是獨立的,而是彼此關聯、互相影響。因此在數據存儲優化中應該考慮到這種關聯性,即設計一種基于數據關聯性的哈希分桶存儲算法,如圖3所示。
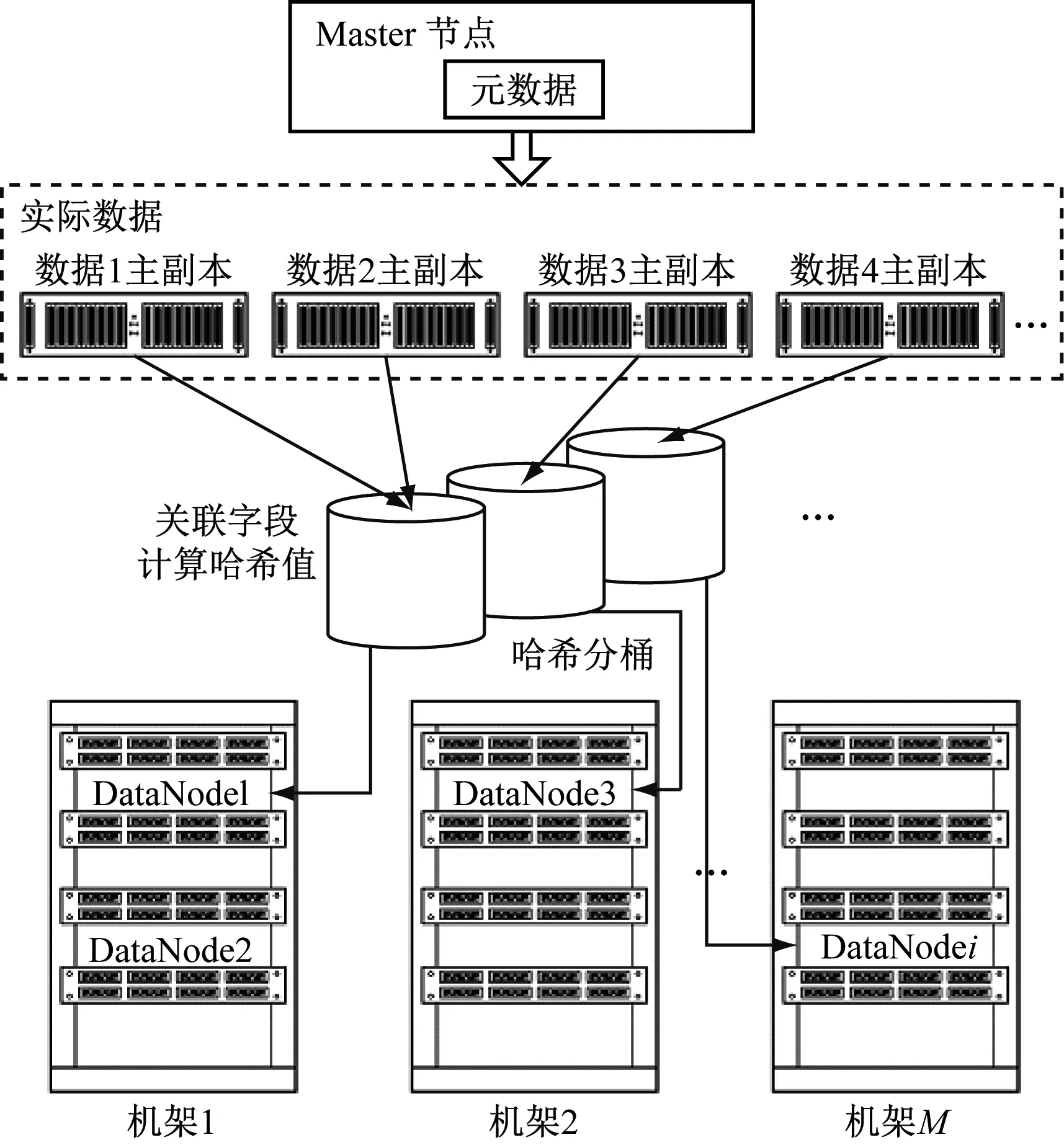
圖3 基于哈希分桶算法的數據存儲
由圖3可知,在該存儲優化方式中,體現出如下四個特點。
首先,采用分離存儲的方式對實際數據與元數據進行管理,其中實際的數據都統一存儲在Slave節點中,而元數據的管理則是利用Master節點實現的。分離存儲的方式能夠提升數據管理的邏輯性和規范性。同時對全部數據配置了三個副本,以保證數據管理的安全性與可靠性。在本次設計中考慮到不同類型業務的數據管理需求,分別采用了地理屬性、設備ID當作電網外部、內部數據的關聯字段,保證了數據查詢的規范性。
其次是關聯數據的集中存儲過程,需要先將各個數據主副本統一存儲在不同的桶內,然后在同一個節點中存儲相同的數據,最后建立與HDFS系統的映射,由此實現了數據的集中存儲。
第三,第2、3副本具有一定的特殊性,需要根據數據的傳輸效率等信息將其與對應的節點進行匹配。通常情況下,主副本與第3副本可以存在于相同的機架中,而第2副本存儲的機架需要區別于主副本。
第四,對于各個數據節點來說,則需要采用合理的方式進行劃分,例如劃分數據塊大小為256MB、64MB等,在這個過程中應該考慮到負載均衡以及存儲的有序性,從而保證數據存儲的規范性。
3 多源數據并行關聯查詢方法
當前在計算機計算領域中越來越多的使用了并行計算方法,其主要是把復雜的執行任務劃分為多個不同的子任務,并將各個子任務分配到獨立的處理器中,使得整個計算過程可以同時執行,采用這種方式能夠提高系統的處理性能,并滿足不斷增長的計算需求。在本文中基于之前提出的哈希分桶存儲優化算法已經實現了對多源配用電數據的存儲,然后需要采用一定的方法解決多源數據的查詢問題[16]。在本次研究中基于并行思想設計了一種基于MapReduce的查詢方法,這種方法將主要的查詢過程集中在Map(映射)階段實現,避免在Reduce(約減)階段產生過多的操作;同時在本地節點根據之前定義的關聯字段完成查詢過程,能夠有效地提升查詢效率,減少對資源的占用。詳細的查詢流程如下。
(1) 首先對查詢的條件以及關聯字段(地理標識或者是設備ID)進行確定,在此基礎上可以得到MapReduce任務。
(2) 其次是形成節點中的數據文件,并通過預處理等過程得到符合標準的數據,整個過程需要考慮到集群中數據的存儲特征。
(3) 然后獲取Map任務中符合查詢條件以及關聯字段的數據,并將其劃分到相同的組中,按照相同的方式可以得到各個Map任務的結果,最后匯總所有Map任務的處理結果,并得到統一的關聯查詢結果。
4 實驗驗證
針對上述提出的方案,采用試驗的方式進行驗證,以驗證算法是否能夠達到預期的性能。首先需要確定查詢的條件以及關聯字段,這里二者分別是時間與區域編號,將用電負荷、設備ID 建立關聯后,根據確定的查詢條件和關聯字段對各個數據文件進行處理,由此可以得到含有氣象、用電負荷等信息的數據集。在實驗過程中設置不同大小的數據子集來測試對應的查詢時間,如表1所示。

表1 數據基本情況
為了驗證本算法的應用效果,在實驗中采用了其他的方法進行對比,如圖4所示。
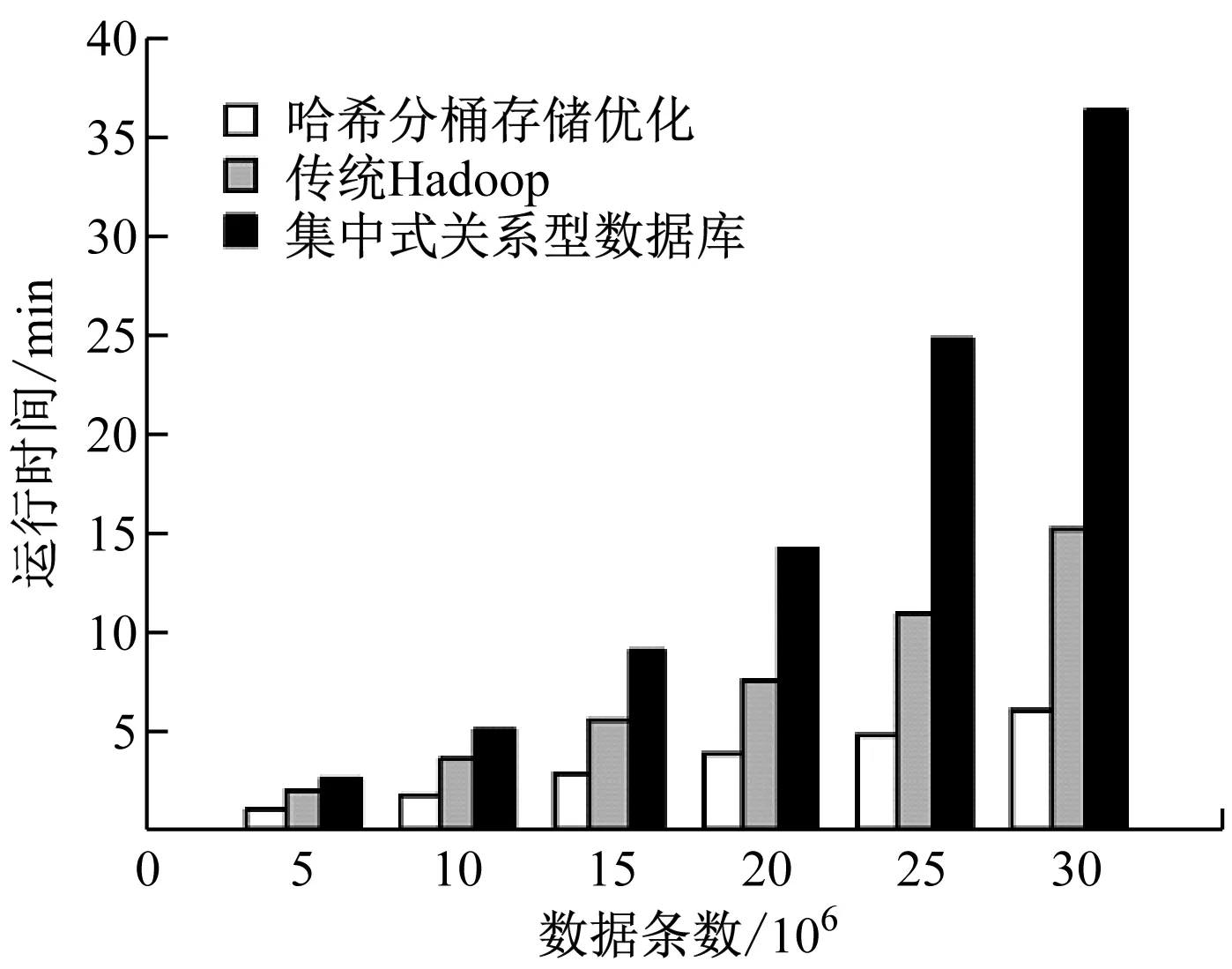
圖4 不同存儲方式的查詢時間對比
由圖4可知,相對于傳統的Hadoop查詢方法以及集中式關系型數據庫查詢方法,本文提出的基于哈希分桶存儲分布優化的多源數據關聯查詢方法具有一定的優勢,具體表現在較高的查詢效率方面,能夠顯著降低查詢過程花費的時間,在實驗中根據測定的查詢時間發現其分別占據其他兩種方法查詢時間的39.6%、16.4%。經過分析發現,本算法主要采用了集中存儲關聯數據的方式,無需過多的在節點之間傳輸數據,在本地節點即能夠完成大多數的處理過程,由此不僅提升了處理效率,同時降低了對資源的占用。另外在數據集規模持續增大的過程中,本文提出算法的查詢時間沒有出現較大的增長,始終保持較為穩定的查詢效果,因此可以將其有效地應用到多源配用電數據的關聯查詢中。
5 總結
通過上述的研究看出,本文針對電力行業元數據的存儲問題,主要做了以下幾方面的工作:一是將數據全部轉換為XML格式數據,以方便進行管理;其次引入希哈分桶算法對數據進行存儲,大大提高了存儲效率;三是引入MapReduce的查詢方案,提高了查詢效率。結果表明,本文構建的方法可行,具有一定的借鑒。
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
當代陜西(2019年15期)2019-09-02 01:52:00
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
學苑創造·A版(2018年11期)2018-02-01 06:29:20
