海洋環流模式NEMO的代碼現代化
2021-02-01 03:01:38周生昌劉衛國宋振亞楊曉丹
海洋科學進展 2021年1期
周生昌劉衛國宋振亞楊曉丹
(1.山東大學 軟件學院,山東 濟南250101;2.自然資源部 第一海洋研究所,山東 青島266061;3.青島海洋科學與技術試點國家實驗室 區域海洋動力學與數值模擬功能實驗室,山東 青島266237;4.海洋環境科學和數值模擬自然資源部重點實驗室,山東 青島266061)
研究海洋的手段主要有理論研究、觀測試驗和數值模擬,其中觀測試驗是數值模擬和理論研究的基礎,理論研究為數值模擬和觀測試驗設計提供指導,而數值模式則集成了人們從觀測數據和理論研究中所獲得的知識和理解,不僅可以用來驗證理論假說和彌補觀測資料的不足,而且是能夠最終用于預測未來變化的唯一工具[1]。隨著海洋和氣候變化研究的不斷深入,高性能計算機的發展,海洋數值模式正逐步朝著更高分辨率、更多物理過程和更快計算速度的方向發展[2]。一般來說,水平分辨率每提高1倍,計算量會增大到原來的8~10倍[3]。同時,隨著分辨率的提高,會有越來越多的原次網格不能描述的物理過程被包含進來,而新的次網格過程的參數化也需要通過將多組數值試驗結果與實測數據進行比較來進行評估和調整,這顯然也提高了對計算量和計算能力的要求[4]。因此,充分利用和發揮高性能計算機的性能來提高海洋數值模式計算速度已成為模式發展的一個必要條件。
目前高性能海洋數值模擬的研究主要采用以下幾種方案提高模式計算能力:1)基于分布式內存并行化程序。主要采用MPI(Message Passing Interface)消息傳遞接口使計算任務合理分布在多個獨立進程的計算單元內,并通過高速網絡進行數據通信。該方法實現復雜,需考慮邊界交換、負載均衡等問題,雖然可擴展性好,但節點之間交換會帶來通訊開銷。2)基于共享式內存并行化程序。主要采用Open MP等接口將計算任務分配給多個線程,并通過共享內存地址的方式實現數據交換。該方法實現相對容易,無通訊開銷,但一般來說無法跨節點,這限制了其并行規模。3)基于進程/線程并行化程序。該方法是以上2種并行方式的結合,實現較為復雜,在異構計算機(如CPU+GPU、國產申威處理器等)上效果特別顯著。
上述3種方案主要從并行擴展方面提高模式計算性能,這需要大量的計算資源,且程序在設計和實現中并未考慮代碼現代化。特別是隨著高性能計算機的發展,這些方案已經無法充分利用和發揮現代計算機的優勢。楊曉丹等[3]在海浪模式MASNUM上開展了代碼現代化優化方面的嘗試,通過檢查代碼的規范性、合理性,并針對語言特性對代碼進行改進,使之更好地適應計算機基礎架構,充分發揮了現代計算機的計算特點。但是在此海浪模式中,計算量最大的源函數與相鄰點無關,無分區間數據交換通訊,并且由于分支判斷少,cache命中率高[5],這與海洋環流模式NEMO(Nucleus for European Modeling of the Ocean)[6]計算特點有較大的差異。NEMO不但存在大量的數據交換,而且分支判斷較多。因此如何使用代碼現代化方法優化和提高海洋環流模式的計算性能,非常具有代表性和必要性。
為了充分利用和發揮現代高性能計算機的性能,進一步促進海洋環流數值模式的應用和發展,本文基于代碼現代化的概念,提出了海洋環流模式代碼現代化優化的方案,并在此基礎上對海洋環流模式NEMO進行了優化,分析和探討了代碼現代化優化方案在海洋環流模式應用中的前景和局限性,為今后海洋環流數值模擬的研究和發展提供參考和建議。
1 優化方案設計
1.1 優化策略
現代高性能計算機是由多核和眾核處理器、高速緩存和內存、高帶寬處理器以及它們之間的通信結構和高速I/O組合而成的[7]。為了充分適應平臺的現代化結構,充分發揮平臺的性能,需要發展高性能和現代化的軟件,包括對原始代碼進行改進,以及為現代計算機重新設計應用程序以獲得最大性能,但這些均需要充分利用高性能計算機硬件資源,這是代碼現代化的基礎。
本文基于代碼現代化優化策略,并結合NEMO海洋環流模式的特點以及現有平臺架構,制定了6個階段的優化策略,如圖1所示。為了保證結果的準確性,排除平臺因素引起的誤差,每次均取2次試驗結果的平均值作為最終結果。
1.2 試驗算例
試驗算例為全球海洋環流真實算例ORCA1_LIM,該試驗算例只包含海洋動力學、熱力學(OPA模塊)以及海冰動力學(LIM模塊)。模式共積分120個時間步長,水平網格數目為362×292,垂向網格數目為75。為了減小I/O對擴展性的影響,本研究中的測試是針對模式計算性能的無I/O測試。
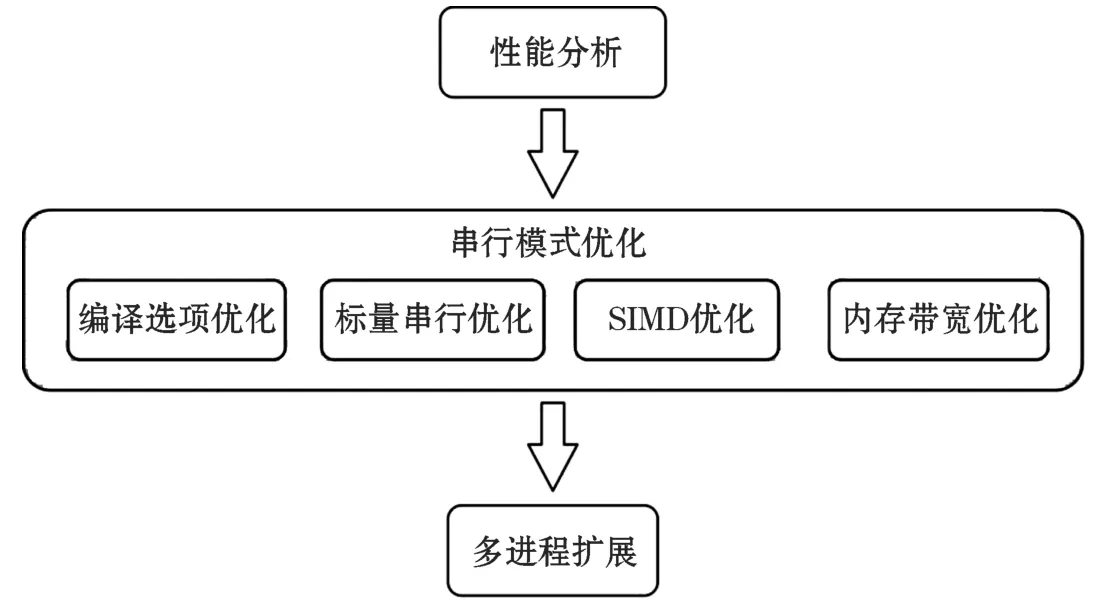
圖1 代碼現代化優化策略Fig.1 Code modernization optimization strategy
1.3 測試環境
試驗測試環境如表1所示,單節點內共有兩顆Intel Xeon Gold 6252處理器,每顆處理器有24核心,因此單節點共有48物理核心,96邏輯核心,內存為384 GB DDR4。

表1 測試環境Table 1 The testing environment
2 NEMO優化
2.1 定位熱點函數
為了更準確地獲取影響NEMO模式計算效率的瓶頸,從而更有針對性地對NEMO模式進行優化,首先使用Intel Vtune Amplifier工具定位出模式的熱點函數,即耗時較多的函數,如圖2所示。結果顯示NEMO的熱點函數極為分散,即熱點函數較多,耗時分布較為均衡,本研究選取前五個熱點函數(tra_ldf_iso,lim_rhg,tra_adv_tvd,ldf_slp、nonosc)進行重點優化。

圖2 串行模式各函數計算時間Fig.2 Serial mode function calculates time
2.2 編譯選項優化
在性能分析的基礎上,本研究首先使用編譯選項對模式進行優化。使用x HOST選項使編譯器生成處理器支持的最高指令集,該選項在本文測試環境下等效于x MIC-AVX512;使用ipo啟用文件之間的過程間優化,使編譯器對單獨文件中定義的函數執行內聯函數擴展;使用no-prec-div選項對模式的浮點數除法進行優化,將除法改為乘倒數的形式進行計算,從而提高運算效率;此外,還使用了fp-model fast=2,qopt-dynamic-align,qopt-prefetch等優化選項,具體如表2所示。在經過編譯選項優化后,NEMO的整體加速比可以達到1.21倍。通過對輸出結果進行分析,以海表面溫度為例,得出O1和O3兩種編譯選項所引起的誤差絕對值不超過9.3×10-6℃,占僅占平均海表面溫度的0.00005%,且誤差絕對值在1.0×10-8℃以下的網格點占比超過99.8%,滿足精度要求。同樣,對其它變量的檢查也滿足精度要求。因此編譯選項優化是有一種有效的優化手段。

表2 編譯選項優化列表Table 2 The list of compilation option optimization
2.3 標量串行優化
標量串行優化的目的是通過對熱點函數代碼進行調整修改,如去除重復計算、減少條件分支、降低循環嵌套等,確保代碼使用最少的計算量和合適的精度獲得正確的結果。下面以traldf_iso熱點函數為例介紹此優化過程。
在如下例子中(圖3a),zdk1t和zdkt計算公式是相同的,即zdk1t(ji,jj,jk-1)=zdkt(ji,jj,jk),因此通過將zdk1t從循環中移除,在計算完zdkt后再將結果賦值給zdk1t,可以減少重復性計算,如圖3b所示:

圖3 重復計算優化前和優化后Fig.3 Repeat calculation before optimization after optimization
當從內存中訪問數組元素時,兩次訪問的尋址間隔會影響Cache命中率,降低計算效率。由于Fortran中的數組是按照列優先的方式存儲,因此調整數組元素訪問順序,使得相鄰兩次訪問的尋址間隔變小,可以有效提高Cache命中率。調整數組元素訪問順序前后分別如圖4a和4b所示。
另外,減少循環嵌套也能有效提高模式計算效率。在圖5a的循環中,z2d是臨時數組,目的是存儲zftu在三維空間沿K軸方向的積分。由于三重循環計算效率較低,因此利用Fortran提供的forall命令將該循環減少為一重循環,如圖5b所示。經過上述串行與標量優化后,NEMO模式整體計算效率提升1.22倍。

圖4 調整數組元素訪問順序優化前和優化后Fig.4 Adjust access order of array element before optimization after optimization

圖5 循環嵌套優化前和優化后Fig.5 Loop nesting before optimization after optimization
2.4 SIMD優化
SIMD(Single Instruction Multiple Data)即單指令多數據流,以同步方式,在同一時間內對多個數據執行同一條指令。矢量化是現代計算機的一個標志,利用自動矢量化,可以顯著提高軟件的計算性能。在本測試環境下,利用x HOST選項編譯時,已包含了自動矢量化功能。然而自動矢量化需要遵循矢量化規則,如循環中不能存在數據前后依賴以及跳轉語句等。以下是自動矢量化失敗的例子及采用的優化策略。
在圖6a所示的代碼中,由于zdit和zdjt都是由指針方式實現的動態數組,Fortran指針可以作為別名指向一塊內存地址,因此編譯器不能判斷zdit和zdjt指針之間是否存在數據依賴,從而無法實現自動矢量化。通過將假定依賴的語句拆分成2個循環,使每個循環滿足自動矢量化的條件,可以實現自動矢量化(圖6b)。

圖6 SIMD數據依賴優化前和優化后Fig.6 SIMD data dependency before optimization after optimization
另外,由于代碼中存在大量的指針作為臨時數組,因此在不影響物理過程的前提下,通過將指針修改為動態數組,可以使代碼安全地進行自動矢量化,如圖7所示。經過SIMD優化后,NEMO模式整體計算效率提升至1.23倍。

圖7 SIMD指針優化前優化后Fig.7 SIMD pointer before optimization after optimization
2.5 內存帶寬優化
當CPU需要讀取內存中的數據時,CPU將首先發出一個由內存控制器執行的請求,然后再將數據由內存返回中央處理器,此過程的時間稱為延時周期。為了縮短延時周期,中央處理器和內存之間設置了L1和L2緩存。由于L1和L2均采用靜態隨機訪問的原理,可以將其理解為內存帶寬[8]。對內存帶寬進行優化,提高緩存命中率,也是提升軟件計算效率的有效方式。
由于海洋環流模式復雜的物理過程,模式中使用大量的臨時數組保存計算過程的中間結果,這就造成了運算時參與計算的數組過多的問題。當CPU計算時,如果一條語句需要同時讀取大量數組,由于內存帶寬限制,則會減少緩存命中率,降低計算效率。因此減少或避免使用臨時數組,是緩解內存帶寬占用過高的一種優化手段。
如圖8a所示,數組A,B為臨時數組,運算時首先通過計算為A,B數組賦值,并在之后的循環中訪問該數組。優化策略為將臨時數組A、B去掉,而把計算賦值的功能重構為子程序cal_a,cal_b,并在循環中需要此中間結果時調用。

圖8 內存帶寬優化優化前和優化后Fig.8 Memory bandwidth before optimization after optimization
對熱點函數進行分析后,發現traldf_iso、nonosc和lim_rhg中均存在大量臨時數組,可以使用上述策略進行優化。圖9顯示了優化前后各個函數的計算時間以及其加速比,可以看出優化后單個熱點函數的計算效率有效提升10%~40%,效果顯著。另外,由于NEMO的熱點函數呈現分散的特點,此優化使得模式整體計算效率加速至1.31倍。

圖9 內存帶寬優化前后函數時間對比Fig.9 Comparison of function time before and after memory bandwidth optimization
2.6 MPI多進程擴展
NEMO模式總體是一個循環過程,其中時間是循環的主序列。循環從數據讀取開始,以結果輸出為結束。循環部分包含模式中的所有核心計算,總計算量占總循環過程的95%及以上[9]。本文使用的NEMO 3.6版本基于MPI消息傳遞接口編寫,使用MPI分布式內存并行計算可以有效的進行任務劃分,從而提高計算效率。在經過以上串行優化之后,接下來利用Intel Trace Analyzer Collector工具對NEMO進行多進程擴展測試,以觀察模式的負載均衡性。
圖10顯示了模式在48進程時的負載均衡性,從結果可以看出,計算(藍色)和通信(紅色)時間占比比較合理,且分配給每個進程的計算任務基本一致,其中進程間的計算時間占比最大相差不超過8%,有40個進程相差在1%以內,基本實現了負載均衡,不需要進行進一步優化。

圖10 48進程下負載均衡分析Fig.10 Load balancing analysis of 48 processes
為了更全面地對模式的并行能力進行檢驗,我們進一步測試了模式的擴展性。圖11為海洋環流模式在不同進程數下的加速比。在單節點48進程內,隨著進程數的增加,加速效率逐漸降低,這是由于增加進程引起的代價不可消除,如進程間通信量增加,帶寬限制等。另外,程序中必定有不能并行的串行部分,即使進程無限增多,通過并行所產生的加速比都是受限的,即阿姆達爾定律[10]。因此模式無法隨著進程的增加獲得線性加速比。此外,當進程數超過48時,由于測試環境沒有開啟超線程,進程可能會被掛起等待,同時進程間通信增加,加速效率會繼續降低。
在經過編譯選項優化、標量串行優化、SIMD優化、內存帶寬優化幾個步驟后,模式整體性能得到了有效提升,如圖12所示。選取合適的編譯選項可以充分發揮計算機的性能,使得計算效率提升了21%;通過規范代碼書寫,去除重復計算,減少循環嵌套等方法,實現串行代碼優化,以及通過修改代碼,使之符合編譯器對矢量化的要求,實現編譯器自動矢量化,這兩步優化共實現了2%的性能提升;另外,針對模式占用內存帶寬過高的問題,提出了去掉臨時數組的解決方案,使得優化后的單個熱點函數加速比最高可以達到1.4倍,模式整體加速了8%。經過上述優化,最終模式的整體計算效率共提升了31%,節省了接近1/3的計算資源。同時,48進程下的MPI并行模式計算效率相較于串行模式提升了15.8倍,雖然單節點內擴展性較弱,但負載均衡性較好。
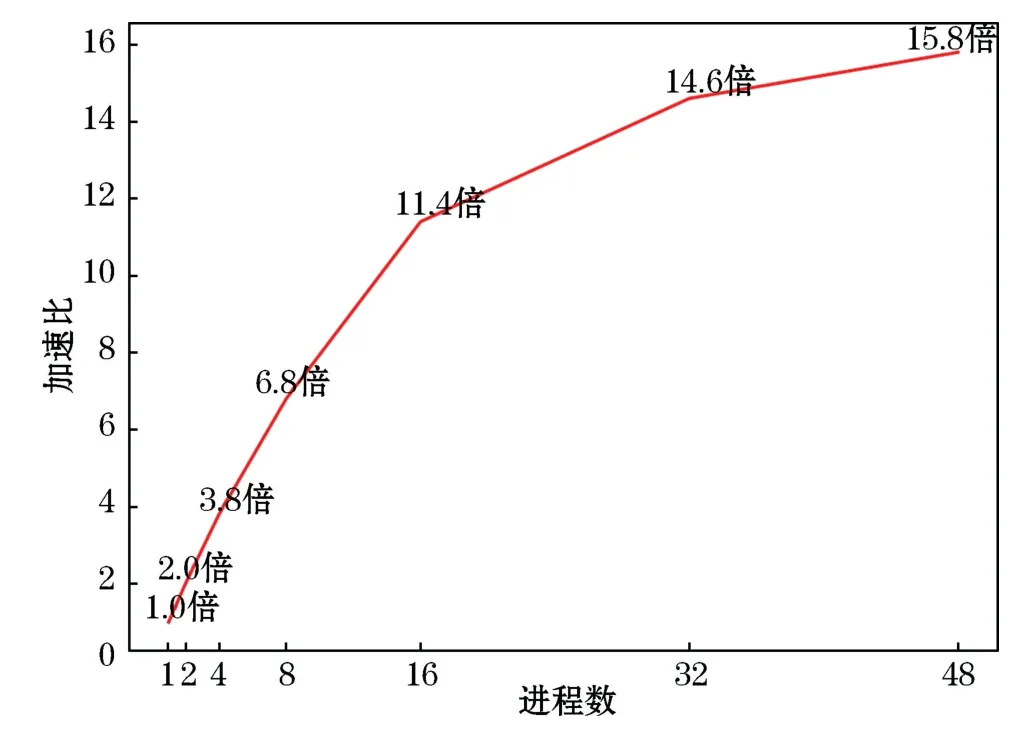
圖11 不同進程下的加速比Fig.11 Acceleration ratio of different processes

圖12 各優化步驟加速比Fig.12 Acceleration ratio of each optimization step
3 試驗結果分析
3.1 大量指針被假定數據依賴
矢量化有許多限制,例如存在數據依賴、函數調用(數學庫調用除外)、在同一循環中混合可矢量化類型以及存在與數據相關的循環退出條件等,則不能進行矢量化。其中數據依賴分為寫后讀依賴和讀后寫依賴。寫后讀依賴即計算一個數組元素時需要依賴該數組已經計算的元素,如果強制將其矢量化,可能后面需要讀取的依賴元素并沒有被計算完成,因此造成讀取數據錯誤。除了存在不可避免的計算中的前后依賴之外,NEMO的矢量化報告顯示模式源代碼中存在大量的指針,而由于Fortran中的指針可以作為別名指向內存地址,因此編譯器通常無法判斷包含指針的代碼是否存在數據依賴,從而無法自動矢量化。本文采取了兩種方法來避免因指針造成的無法矢量化問題,包括拆分循環和將指針修改為動態數組。但需指出的是,這只是針對熱點函數的局部優化,因此效果有限。若要全局優化此問題,則需要將代碼重構。
3.2 循環嵌套過多
NEMO的核心計算都包含在循環嵌套中,源代碼中的函數多是四重循環,包括一維時間循環以及三維空間循環。當算例規模達到一定程度時,會不可避免地出現效率低下。另外,由于編譯器僅會對最內層循環進行自動矢量化,因此循環嵌套過多也會造成SIMD優化效率低下。針對此問題,一種優化思路是遵循內大外小的原則,即將迭代次數多的循環放在最內層,提高SIMD優化效率。但更有效的解決方案則是減少循環嵌套層數,但是需要從根本上改變算法問題,這將是非常復雜的工程。
3.3 內存帶寬過高
本研究中的串行與標量優化以及SIMD優化效果有限,而在經過內存帶寬分析及優化后,熱點函數的性能提升十分明顯,這說明NEMO海洋環流模式內存帶寬占用過高是個比較顯著的問題。這是由于NEMO計算時涉及大量數組運算,因此會出現大量緩存未命中的情況,需要頻繁從內存中讀取數據。而當內存帶寬占用過高時,處理器從內存獲取數據的速度會出現瓶頸。去除臨時數組是一種解決方案,但卻會增加大量的重復計算,增大計算壓力,這與串行代碼優化中的去除重復計算優化策略恰恰相反。但針對具體的NEMO內存帶寬瓶頸問題,去除臨時數組后減少的時間遠遠大于增加重復計算帶來的計算時間,因此去除臨時數組是非常有效的。
4 結 語
在本文中,首先介紹了NEMO模式特征,并根據代碼現代化指導步驟制定了NEMO的優化策略。隨后給出了試驗算例以及測試環境,并詳細介紹了NEMO代碼現代化的優化過程。結果表明,通過對選取的熱點函數進行編譯選項優化、標量串行優化、SIMD優化以及內存帶寬優化,串行的海洋環流模式的整體加速比可以達到1.31倍,其中熱點函數加速效果非常明顯,例如traldf_iso相較于原始性能提升了2.3倍。但因模式熱點函數分散,選取的熱點函數并不是模式的全部計算瓶頸,因此整體加速比有限。最后對NEMO在MPI多進程下進行了擴展性測試,測試結果表明在48進程(測試環境最大核心數)的加速比為15.8倍,計算和通信時間占比合理,負載均衡。但可能是由于內存帶寬占用過高,導致單節點內擴展性較差,這需要進行進一步分析驗證。另外,我們還對優化后的模式結果進行了驗證,以確保優化后結果的準確性。需要注意的是,雖然對于海洋模式NEMO來說,我們的優化對模擬結果影響不大,在誤差允許范圍內,但是在海氣耦合模式中,由于存在強的非線性海氣相互作用,誤差可能會被放大,因此在優化時需要注意并檢驗。總的來說,代碼現代化在不增加任何硬件成本的前提下是一種行之有效的優化方案。
此外,在對NEMO進行代碼現代化優化的過程中,分析出其主要存在以下幾點影響計算效率的問題,如模式大量使用指針、循環嵌套過多、內存帶寬占用過高等。針對這些問題,本文給出了相應的解決方案,如將指針修改為動態數組,減少循環嵌套次數以及去除臨時數組等,可以為今后海洋模式的設計和改進提供參考。
另外,MPI并行化僅在二維方向上進行分解(沿著jpi和jpj)[11]。當MPI進程數增多時,每個進程間的通信量會成倍增加,通信開銷會越來越大,導致模式性能下降。為了減少通信時間,通過引入MPI/Open MP混合并行將會是一個切實可行的方法。Open MP可以實現共享內存層面的任務并行,它是一種簡單有效的并行方式[11-12]。這種混合并行方法通過減少MPI進程數,可以減小進程間通信開銷,同時利用Open MP打開超線程又能充分利用計算資源,使得并行結構更加合理[13]。由于部分NEMO算例的特征是在三維數組上沿著jpi、jpj和jpk執行的操作,因此可以將Open MP共享式內存并行化應用在jpk(此試驗中為75)方向上,提高進程內的計算能力。在熱點函數中引入MPI/Open MP并行化后,由于進程間通信數量減少,將有利于提高模式的擴展性。這是接下來研究的方向之一。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
中國外匯(2019年20期)2019-11-25 09:54:58
現代企業(2015年2期)2015-02-28 18:45:09
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
中華女子學院學報(2012年6期)2012-03-25 13:52:27
