一種融合表觀與屬性信息的車輛重識別方法
2021-02-02 08:50:40謝秀珍羅志明李紹滋
廈門大學學報(自然科學版) 2021年1期
謝秀珍,羅志明,連 盛,李紹滋
(1.廈門大學信息學院,福建廈門361005;2.龍巖學院數學與信息工程學院,福建龍巖364002)
隨著城市車輛迅猛增加,對目標車輛的快速查找、跟蹤和定位已成為公共交通安全管理的重要內容之一.目前大部分道路交通監控系統中,對車輛的識別主要是通過識別特定角度高清攝像頭拍攝的前后車牌號來完成的;但在實際環境中還存在大量攝像頭分辨率低、拍攝角度非特定、車牌被遮擋等情況,導致無法直接從視頻中提取車牌號來對車輛進行識別,因此也需要采用其他方法實現對車輛的識別工作.車輛重識別也叫作車輛再識別,其主要目的是構建一個跨攝像頭的車輛圖像檢索模型,能夠對某一監控攝像頭下拍攝到的指定目標車輛,實現快速準確地檢索與識別該車輛在其他不同監控攝像頭下對應出現的圖像[1].在真實的道路交通監控場景中,車輛圖片不可避免受到各種因素的影響:光照明暗、拍攝角度、障礙物對目標車輛的不同部位的遮蓋、攝像設備的分辨率不同等,都會導致很大的車輛外觀差異性.因此與其他目標檢測識別[2-3]問題相類似,要實現準確的車輛重識別,其中的一個重要環節是提取車輛特征來作為重識別的主要依據,特征的判別力強弱將直接影響重識別的結果.
在深度學習[4]方法被廣泛運用之前,主要是通過手動設計提取各種具有較強判斷性的視覺特征(整體或部分的顏色特征、紋理特征或關鍵敏感區域的特征).如:王盼盼等[5]手動提取車輛圖片的HSV(hue,saturation,value)和局部二值模式(LBP)特征并進行融合,再進行奇異值分解,提取特征值;李熙瑩等[6]運用部件檢測算法有針對性地檢測和提取區別性較強的車窗和車臉等部位的特征并將其進行融合,生成新的融合特征,然后利用圖像特征之間的距離進行分類識別.
隨著大規模車輛數據集的構建,例如:VeRi-776數據集[7]、VehicleID數據集[8]、Toy Car RE-ID[9]數據集和VRIC[10]數據集,各種基于深度學習的車輛重識別模型也陸續被提出.Liu等[1]提出了“PROVID”模型來進行漸進式車輛重識別,實現在特征方面由粗到細以及監控中由近及遠相結合的搜索;Yan等[11]提出了一個基于多任務框架的模型,將車輛圖像建模成多粒度的關系,并提出了廣義的二元“相似/不相似”關系的成對排序和基于多粒度的列表排序方法,漸進地利用多粒度排序約束來緩解精確車輛搜索問題;Liu等[12]提出由4個分支構成的“RAM”模型,把整體特征和區域特征聯合起來,提取更詳細、更具辨別力的特征;Bai等[13]使用敏群三元組嵌入的方法,顯著減輕了類間相似和類內方差對細粒度識別的影響;Zhou等[9]利用車輛角度信息,提出了兩種端到端深層架構,學習車輛不同視點角度的轉換;Shen等[14]結合時空信息,提出了一個兩階段框架,排除具有高相似度的不同車輛間的相互干擾,有效地規范了重識別結果;He等[15]通過訓練一個額外的車輛部位檢測器,可以定位具有顯著判別能力的局部區域并提取相應的特征,該方法可以有效地利用車輛的局部特征;Chen等[16]將車輛沿著水平、垂直以及特征通道方向劃分成多個不同的子部分,然后再將這些子部分的特征進行融合,得到相對包含更多局部信息的車輛特征.
上述方法均有一定的代表性,說明充分利用手動提取或深度提取的特征,對車輛重識別工作中所依賴的車輛表觀信息或角度信息等特征進行恰當處理,均能夠取得不錯的性能.目前大多數方法多從整體層面提取車輛特征,缺乏對局部細節的描述;或者使用額外的檢測分支來定位車輛局部區域,增加了人工標注的工作量.此外,不同顏色或者不同車型的車輛肯定具有不同ID,且顏色與車型在變化的環境因素中亦能較容易被判斷和分類;但現有方法更多是將顏色、車型作為屬性信息加入到額外的監督損失函數中,并沒有很好地將這些屬性信息融入到車輛的特征中用于提升車輛重識別的準確率.
基于此,本文提出一種融合“多尺度表觀特征”與“車輛屬性信息”的車輛重識別算法模型.該模型以預訓練的ResNet-50[17]作為骨干網絡提取車輛的基礎特征向量;通過兩個分支從中分別計算提取車輛顏色與車型相關的屬性特征、局部與整體融合的多尺度表觀特征;采用動態自適應加權的方式對這兩個分支的特征進行融合,用于獲得更具有判別力和魯棒性的深度特征作為車輛的最終特征表示;并使用一個多任務目標優化函數對整個模型進行參數優化訓練.
1 模型框架
本文構建了一個如圖1所示的車輛重識別網絡模型.該模型首先通過一個在ImageNet數據庫上構建的骨干殘差網絡-50(ResNet-50)計算提取車輛基礎特征向量z;接下來分別從基礎特征向量中計算提取車輛顏色和車型屬性特征fattribute以及多尺度車輛表觀特征fappearance;然后將車輛屬性特征融合到車輛表觀特征以輔助提取強化提升的車輛特征向量f.本文通過一個多任務的損失函數,在綜合考慮車輛分類、車輛顏色分類和車型分類的基礎上具體優化網絡模型參數.本節后續將分別介紹整個模型的具體計算流程.
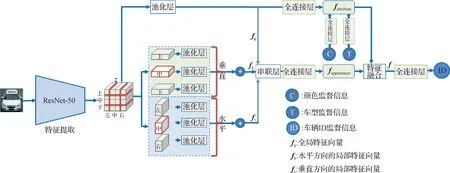
圖1 融合表觀和屬性信息的車輛重識別網絡Fig.1The vehicle re-identification network fused appearance with attribute information
1.1 基礎特征提取
目前ImageNet數據庫上預訓練的深度網絡模型被廣泛作為各種計算機視覺任務的特征提取骨干網絡.預訓練模型指的是已經訓練好的能執行大量數據任務的深度學習框架卷積神經網絡(CNN).預訓練結束時,會得到結果較好的一組權重值供他人研究共享.隨著深度學習網絡層數的增加,CNN表達力增強,有利于提高分類準確率;但層數并不是可以無限增加的,到達瓶頸值后網絡收斂緩慢,分類準確率不升反降.這種情況下,采用ResNet能解決這個問題:通過增加殘差結構單元,讓網絡在層數增加的同時不會出現退化現象.本文綜合考慮準確率和計算復雜度,采用了目前其中之一的ResNet-50[17]作為骨干特征提取器,用于提取車輛圖片的基礎特征向量z.實際計算過程中,為了提取局部特征,本文中刪除了ResNet-50網絡中的全局池化層及后續的全連接(FC)層,并把最后一個殘差模塊的步長設置為1,因此對于一個256×256大小的輸入圖片,初始特征向量的維度為z∈R16×16×2 048.
1.2 屬性特征提取
車輛的顏色與車型是從整體上描述車輛的相關屬性信息,因此,在本文中從共享的全局特征向量z中計算提取出車輛的顏色車型屬性.首先通過一個全局的池化層將骨干網絡計算提取的初始基礎特征向量z轉換成一維的特征向量,然后再通過一個FC層映射成最終的屬性特征向量fattribute:
fattribute=δ(W1P(z)),
(1)
其中,W1∈R512×2 048為屬性特征對應FC層的參數矩陣,P是全局平均池化操作,δ是ReLU激活函數.
1.3 表觀特征提取
在車輛重識別過程中,車輛的全局表觀特征是從整體上識別車輛,在特定環境下具有較強的判斷力,是必不可少的重識別特征;但在環境影響下,同一個車輛的整體表觀特征差異較大,由于全局特征缺乏對局部細節的細節描述,在一定程度上降低了表達力.而局部特征是對車輛某個部分的具體描述,例如車輛前部的車標、車尾的形狀、兩側的外觀等,對車輛的特征表達比較細膩具體,區分度明顯,能補充增加整體特征的表達力;尤其是在處理相同顏色、相同車型整體屬性的車輛時,局部特征更是發揮了關鍵的輔助“點睛”作用.基于此,本文在提取車輛表觀特征時,除了提取車輛的全局表觀特征外,同時分別沿著水平方向和垂直方向將車輛劃分成左、中、右和上、中、下等不同的區域提取對應的局部特征,這里各區域的劃分不是平均分配,而是有所重疊.每個區域的劃分量占整體的1/2,其中水平方向的中部和垂直方向的中部各被使用2次(如圖1所示的虛線框部分).最后將各局部特征與整體特征進行融合,得到最終的多尺度車輛表觀特征.
1) 全局特征提取.全局特征從整體上表示車輛的表觀信息,與屬性特征提取相類似,本文同樣通過一個全局的池化層將初始特征向量z轉換成一維的全局特征向量fg:
fg=P(z).
(2)
2) 水平方向的局部特征提取.車輛前部的車標、車窗等局部區域能夠提供較為具體的車輛信息,這些局部信息對車輛的重識別非常有幫助,但精確地提取這些信息需要大量的人工標注,工作量大.通過觀察,本文中發現一些比較固定的事實可利用,如車輛的車窗通常位于整個圖片的上半部分,車標和車燈位于圖片的下半部分等.
因此,本文在提取水平方向局部特征時,首先沿著水平方向把z重疊的部分分成左、中、右3個局部特征,即h1=z[0:7;:;:]、h2=z[4:11;:;:]、h3=z[8:15;:;:];然后通過池化操作分別把h1、h2和h3轉換成一維特征向量;最后使用求和操作把這3個局部特征融合成表示整個車輛水平方向的局部特征fh:
fh=P(h1)+P(h2)+P(h3).
(3)
3) 垂直方向的局部特征提取.在提取垂直方向的局部特征時,本文采用與提取水平方向的局部特征相類似的方法.首先沿著垂直方向把z有重疊的分成上、中、下3個局部的特征,即v1=z[:;0:7;:]、v2=z[:;4:11;:]、v3=z[:;8:15;:];接下來也采用池化與求和操作得到融合后的垂直方向的局部特征fv:
fv=P(v1)+P(v2)+P(v3).
(4)
在計算得到fg、fh和fv之后,將這3種特征進行融合,得到總的表觀特征fappearance.本文中主要通過一個串聯層和一個FC層計算得到車輛最終的fappearance.首先使用串聯層得到一個高維的特征向量,再通過FC層將高維的特征向量進行降維,同時保持與屬性特征的維度一致.具體的計算式為:
fappearance=δ(W2[fg,fh,fv]),
(5)
其中W2∈R512×6 144為表觀特征對應FC層的參數矩陣.
1.4 特征融合
在完成屬性特征與多尺度表觀特征的提取工作之后,通過注意力的加權求和將屬性特征與表觀特征進行融合.首先,通過一個注意力機制,利用多尺度表觀特征計算屬性特征的加權權重,使用該權重對屬性特征進行加權;再與多尺度表觀特征進行融合得到車輛最終的特征向量f:
f=fappearance+φ1(W3fappearance)fattribute.
(6)
其中:W3∈R1×512為計算屬性特征注意力權重的FC層參數;φ1是Sigmoid激活函數,將權重值轉換到[0,1]之間.
1.5 優化目標函數
針對車輛的顏色與車型屬性識別,本文在屬性特征fattribute的后面增加兩個并行FC層,用于計算將提取的屬性特征分類到不同的顏色和車型的概率:
pcolor=φ2(Wcolorfattribute),
(7)
ptype=φ2(Wtypefattribute),
(8)
其中,Wcolor∈RC×512是顏色分類FC層的參數矩陣,Wtype∈RT×512是車型分類FC的參數矩陣,φ2是Softmax激活函數,C和T分別是整個數據庫中車輛顏色與車型的種類.
針對車輛ID標簽分類部分,本文在特征向量f后面增加一個FC層,用于計算將不同的車輛圖片分類到對應的車輛ID類別的概率.在訓練過程中,將同一輛車的所有不同攝像頭拍攝得到的車輛圖片的ID分類標簽設為一致,作為一個相同的類別,該類別的概率為:
pID=φ2(WIDf),
(9)
其中,WID∈RN×512,是車輛分類FC的參數矩陣,N是訓練集中所有不同車輛的ID數.
得到pcolor、ptype和pID后,使用交叉熵損失函數計算得出各自的分類損失Lcolor、Ltype和LID,計算如下:
L=-qTlog(p),
(10)
其中,q是訓練數據的真實的獨熱(one-hot)標簽,p是模型的輸出概率.
最后再使用了一個多任務的優化目標函數用于優化整個網絡模型的參數.該優化目標函數L由3個部分組成,分別是車輛的ID分類損失LID、顏色分類損失Lcolor和車型的分類損失Ltype:
L=λ1LID+λ2Lcolor+λ3Ltype,
(11)
其中,λ1、λ2和λ3為LID、Lcolor和Ltype相應的權重.
另外,在車輛重識別模型的訓練過程中,三元組Triplet損失函數[18]也經常被用于減小相同ID車輛圖片的歐式距離,同時增加不同ID車輛圖片之間的歐式距離.錨點車輛圖片a、相同ID的其他車輛圖片p、其他ID的車輛圖片n構成三元組(a,p,n),相應的Triplet損失函數為:
(12)
其中:D為兩個樣本間的歐式距離;m是正負樣本之間的歐式距離間隔,在本文中取值為0.3;ya、yp、yn分別是車輛圖片a,p,n對應的ID.
為進一步增加特征的判別力,在優化目標函數(11)的基礎上,本文將Triplet損失函數引入模型的訓練,得到最終的優化目標函數:
L=λ1LID+λ2Lcolor+λ3Ltype+λ4Ltriplet,
(13)
其中λ4是Ltriplet對應的權重.
2 實驗與結果分析
為驗證本文所提算法模型的有效性,在VeRi-776數據集上進行了訓練與測試,并與其他幾個目前性能較優的算法進行對比.
2.1 VeRi-776數據集
VeRi-776數據集是由北京郵電大學構建的用于車輛重識別的數據集,該數據集有城市監控場景下20個攝像頭拍攝的776輛汽車的50 000多張圖片,將其中576輛汽車的37 778張圖片用于構建訓練集,剩下的200輛汽車的11 579張和1 678張圖片分別用于構建測試集和查詢集.數據庫中每一輛車的多張圖片均由2~18個攝像頭在不同角度、光照、分辨率和遮擋情況下拍攝得到,同時也標注了每一輛車的顏色與車型信息.車輛的顏色有黑、灰、白、紅、綠、橙、黃、金、棕和藍10種顏色;車型有轎車、運動型多用途車(SUV)、兩廂車、多用途車(MPV)、廂式車、皮卡車、公共汽車、卡車和房車9種車型.
2.2 評價指標
為評價模型的準確率,本文采用平均精度均值(mean average precision,mAP)和Rank-k作為車輛重識別效果的評價指標.
1) mAP.車輛重識別是一種圖像檢索任務,mAP是圖像檢索任務中常用的評測指標,通過綜合考慮召回率和準確率來評價算法全局性能.對查詢集中的某一張圖片,假設在測試集中與之相關的正確圖片數為k,該圖片檢索的平均精度(average precision,AP)pav定義如下:
(14)
其中,Ri指按照相似度從高到低排序后包含前i個正確檢索結果所需的最少檢索圖片數.在計算得到查詢集中每一張圖片的AP之后,對所有查詢圖片的AP求平均得到mAP.
2) Rank-k.車輛重識別任務就是要在車輛圖片數據集中尋找與被查詢車輛最相似的車輛.對于每一張被查詢圖像,計算它與數據庫中所有圖像的相似度.Rank-k即表示根據相似度進行排序后的結果中,與被查詢車輛可能屬于同一ID的前k張圖像.
2.3 實驗參數設置
輸入到模型的圖片尺寸均縮放像素為256×256,批大小為64,使用隨機梯度下降法Nesterov訓練參數,新添加層的初始學習率為0.1,其他預訓練層的初始學習率為0.01.網絡模型共訓練40輪,在第20輪時把學習率乘以0.1.訓練的過程中,本文也采用將圖片隨機翻轉和隨機擦除的數據增強方法.式(11)和(13)中的λ1、λ2、λ3和λ4的取值分別為1,0.5,0.5和0.5.在Triplet損失訓練時,采用困難樣本挖掘策略.
在進行車輛重識別檢索測試時,本文采用f的相似度作為判別標準,相似度計算采用的度量距離為歐式距離.
2.4 實驗結果分析
本文提出的算法模型在提取特征時融合了屬性特征與表觀特征,其中多尺度表觀特征融合了根據水平方向和垂直方向劃分的多個局部特征和全局特征的多尺度特征,因此在第一部分實驗中,主要分析網絡模型中不同特征模塊組合對車輛重識別準確率的影響.只包含單一全局表觀特征,不包含屬性特征、水平方向和垂直方向局部特征的基準模型記為Baseline;在Baseline模型的基礎上增加局部特征的模型記為Baseline+Part,增加屬性特征的模型記為Baseline+Attribute;增加局部特征與屬性特征的模型記為Baseline+Part & Attribute.
各模型的準確率如表1所示.單獨增加局部特征和屬性特征時,相比于Baseline模型,mAP分別提高了0.8和1.1個百分點,Rank-1提高了1和1.2個百分點;在同時增加這兩個特征時,mAP可達到72.9%,Rank-1達到95.1%.該結果表明本文構建的局部特征和屬性特征對車輛重識別的準確率的提升有顯著作用,且這兩種特征互補.
除了對比增加不同特征模塊對車輛重識別準確率的影響外,本文也計算了Baseline+Part & Attribute模型對于車輛顏色和車型分類的準確率.在VeRi-776數據集的測試集與查詢集上的顏色識別準確率分別為94.7%和95.1%,車型識別準確率分別為93.3%和93.9%.另外,通過對測試集上混淆矩陣分析發現:在顏色識別過程中,易出現將白色分類為灰色,棕色分類為黑色的錯誤;在車型識別過程中主要存在將SUV分類為轎車,兩廂車分類為轎車的錯誤.

表1 不同特征組合得到的mAP和Rank-k準確率Tab.1 The mAP and Rank-k accuracies of different feature combinations %
接下來,本文比較了所構建的車輛重識別算法模型與近年來性能較優的算法模型的準確率,按照取得的mAP排序,結果如表2所示.可以看出,本文提出的模型取得比其他大部分模型更高的mAP.其中,DenseNet121[19]、VAMI[20]、PROVID[1]、VGG+CTS[21]和VSTP[14]取得的mAP分別為:45.1%,50.1%,53.4%,58.3%和58.8%,遠低于本文采用的ResNet-50骨干模型的準確率78.2%.其中DenseNet121[19]和VGG+CTS[21]采用的DenseNet121和VGG模型,其提取的基礎特征判別力低,從而導致最終的準確率偏低;VAMI[20]首先為每張輸入圖像提取單視圖特征,再使用單個角度的特征生成多角度的特征,最終得到全局多視圖特征,但生成多角度的特征與真實的多角度特征還是存在一定的差異,因此效果一般;PROVID[1]和VSTP[14]結合時間或空間信息,雖然能從時序上對檢索結果進行一定的重排序,但是所使用的基礎網絡判別力以及時序信息的計算會增加相應的計算復雜度.SSL[22]通過(GAN)生成大量的虛擬樣本用于數據擴充,并使用半監督的方法進行訓練,可以在一定程度提高識別的準確率,但使用GAN會增加模型的訓練時間和計算復雜度.RAM[12]提出了4個分支構成的深度模型,也是通過把整體特征和區域特征進行聯合起來,用于提取更詳細、更具辨別力的特征,但該模型提取的特征維度更高,易造成對訓練數據的過擬合.QD-DLF[23]設計四向深度學習網絡將基本特征映射壓縮為水平、垂直、對角線和反對角方向特征圖,最后將這些特征歸一化用于獲取多維度的表觀特征,但該方法并沒有考慮車輛的屬性等相關信息.MTCRO[24]使用多任務卷積神經網絡和新型排序優化的方法,可以在一定程度上提高特征提取后的檢索精度.BS[25]中使用了聯合Triplet損失函數與交叉熵分類損失函數訓練網絡模型,可以取得比單獨使用交叉熵分類損失函數更優的性能,但整體性能并未見優勢.JDRN[26]提出了一種多域聯合學習框架,通過利用多個數據集的車輛圖片訓練一個更加魯棒的模型,該方法雖然可以提高準確率,但對數據集要求更高,需要利用多個不同的數據集來訓練模型.最后,我們注意到:由于MRL+Softmax[27]在增加不同車輛之間基礎上通過度量學習,使相同車輛在不同視角下的距離相對增大,使用Softmax函數訓練后在Veri-776數據庫上的mAP和Rank-5可以達到78.5% 和99.0%,超過了本文的78.2%和97.0%,但MRL+Softmax通過聚類估計車輛視角時會引入新的數據噪聲,導致Rank-1指標上要低于本文的95.8%,其次MRL+Softmax引入了視角約束也會增加模型的訓練復雜度.
另外,Re-ranking[28]被作為一種后處理的方法,被用于提高重識別排序的準確率,在本文中也將Re-ranking用于提高車輛重識別的準確率.從表2中可以看到,SSL[22]與JDRN[26]以及本文所提方法在使用Re-ranking進行后處理之后,mAP均有提高,其中,本文方法從75.0%提高到78.2%,優于SSL[22]與JDRN[26]分別使用Re-ranking后的準確率69.9%和73.1%.
最后,隨機選取7個不同車輛,使用本文方法結合Triplet損失進行訓練,重識別結果按照相似度從高到低進行可視化排序,如圖2所示.可以看出,本文構建的方法可以準確地重識別不同角度、不同光照條件拍攝的同一車輛,同時也發現通過紅色框標注出來的識別錯誤主要集中在相同車型或相同顏色的車輛之間的區分錯誤.
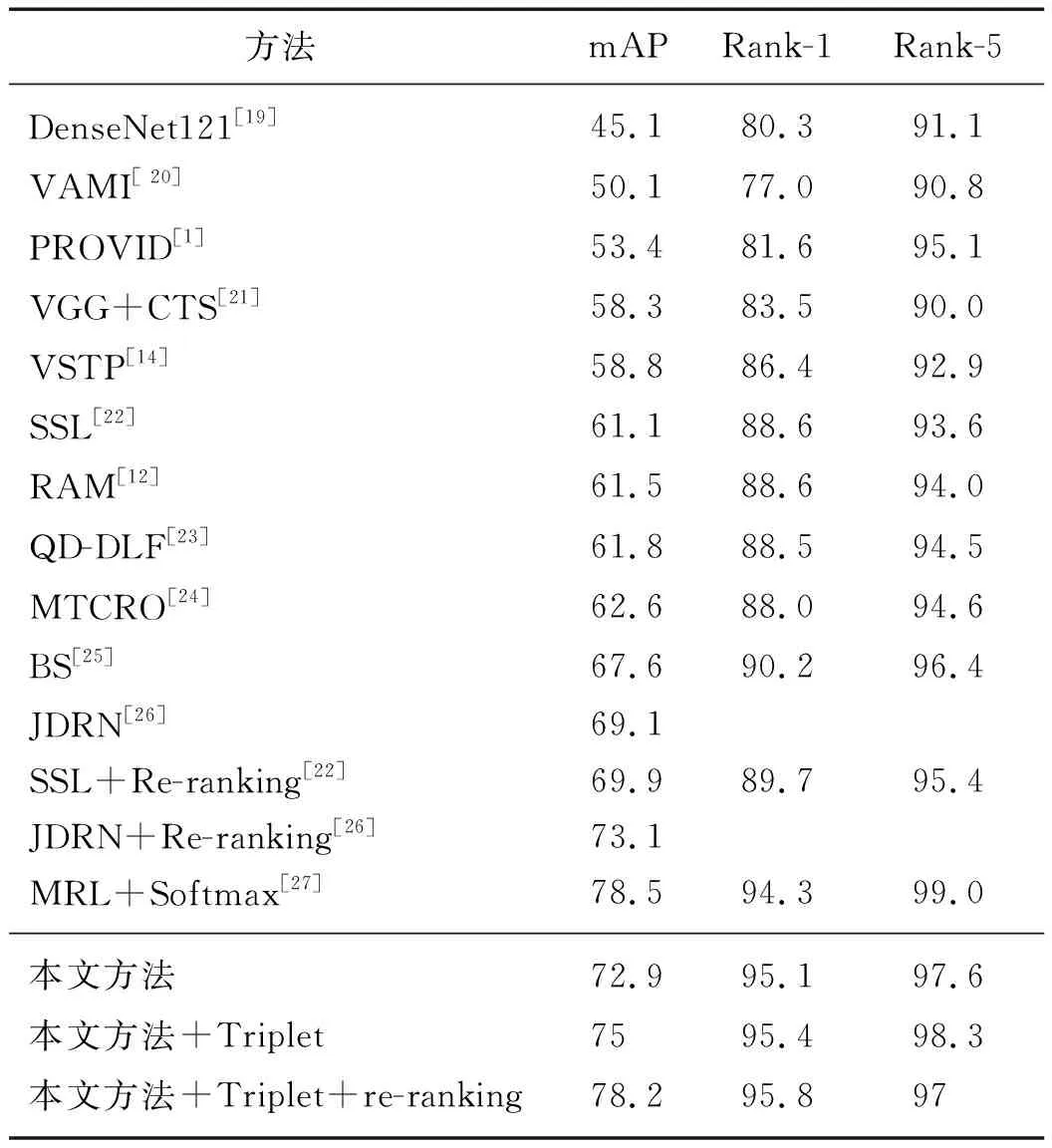
表2 不同車輛重識別方法的對比Tab.2 The comparison of differentRe-identification methods %

圖2 本文所構建模型相似度排名前10的檢索結果Fig.2The top-10 retrieval result of our method
3 結 論
本文嘗試將車輛的顏色、車型屬性信息融合到多尺度車輛表觀信息來獲得既具判別力又具魯棒性的車輛特征.在改良的ResNet-50網絡計算基礎特征向量的基礎上,用兩個分支分別計算車輛屬性特征和多尺度表觀特征,再進行融合得到最終特征向量,通過多任務優化目標函數對網絡參數進行優化.在VeRi-776測試數據集上的實驗結果證明了本文方法的識別效果遠遠優于目前的大多數性能較優的方法.然而,本文方法也不可避免地存在不足之處:在顏色識別過程中易將白色分類為灰色,棕色分類為黑色;在車型識別過程中的錯誤主要有將SUV分類為轎車,將兩廂車分類為轎車等.后續的研究工作中將嘗試解決這些問題.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
