基于遷移學習的漢越神經機器翻譯
2021-02-02 08:51:00黃繼豪余正濤于志強文永華
廈門大學學報(自然科學版) 2021年1期
黃繼豪,余正濤,于志強,文永華
(昆明理工大學信息工程與自動化學院,云南省人工智能重點實驗室,云南昆明650500)
隨著我國“一帶一路”戰略的提出,中越兩國交流日益頻繁,漢語-越南語(簡稱漢越)雙語翻譯技術需求不斷增長,但是漢語-越南語神經機器翻譯(neural machine translation,NMT)平行語料規模較小,翻譯性能不夠理想,這成為制約中越兩國交流的瓶頸問題.基于編解碼模型的端到端NMT[1-2]是目前機器翻譯的主流研究方向,其利用編碼器將源語言文本編碼為固定長度的語義表示,解碼器利用該表示逐詞生成相應的目標翻譯.目前基于編解碼的NMT模型包含大量的參數,需要利用大規模平行語料實現參數優化,因此雖然NMT模型在資源豐富型語言翻譯任務上已具備很好的翻譯性能[3-4],但是低資源語言因為語料規模有限,模型無法得到充分的訓練,導致模型性能不佳.Zoph等[5]也證明在低資源的場景下,NMT性能甚至低于傳統的統計機器翻譯(SMT).因此探索如何利用資源豐富型語言來提升漢越NMT性能成為了當下的研究熱點.
目前樞軸語言和遷移學習是解決低資源場景下NMT效果不佳的有效方法.Wu等[6]和Utiyama等[7]提出基于樞軸語言的翻譯方法,使用資源豐富型樞軸語言橋接源語言和目標語言,利用存在的源語言-樞軸語言和樞軸語言-目標語言的平行語料庫,分別訓練源語言到樞軸語言和樞軸語言到目標語言的翻譯模型.該方法的優點在于,即使在缺乏大規模的雙語平行語料庫的低資源場景下,也可以利用樞軸語言實現源語言和目標語言的有效翻譯;但是直接使用樞軸語言作為翻譯的中間橋梁,會因為源語言到樞軸語言、樞軸語言到目標語言的二次解碼而造成誤差累積.相較于樞軸語言方法,遷移學習(transfer learning,TL)可以直接改進源語言-目標語言模型參數.Zoph等[5]提出使用遷移學習提升低資源NMT的方法,利用資源豐富語言上訓練得到的翻譯模型參數對低資源語言翻譯模型參數進行初始化.Cheng等[8]提出一種基于樞軸語言的遷移學習方法,在模型訓練中考慮源語言-樞軸語言和樞軸語言-目標語言之間的關聯性,并通過對源語言-樞軸語言和樞軸語言-目標語言翻譯模型進行聯合訓練,且在訓練期間共享模型參數.但源語言到樞軸語言,樞軸語言到目標語言這樣分步訓練的過程缺少雙語平行語料的指導,導致多語言輸入所產生的噪聲現象;而且上述方法更側重于改進低資源場景下模型的參數,并沒有對單獨的編碼器或者解碼器進行改進.
漢越NMT是一種典型的低資源場景下的NMT,其訓練語料稀缺,但是漢語-英語(簡稱漢英)、英語-越南語(簡稱英越)平行語料卻大量存在,因此適用于使用遷移學習與樞軸語言的方法來解決其翻譯性能不佳的問題.本文提出一種基于遷移學習的漢越NMT(TLNMT-CV)模型,將遷移學習的思想應用到漢越NMT模型的訓練中,在此基礎上引入樞軸語言思想,選擇英語作為樞軸語言來緩解漢越語言差異大的問題.首先利用漢英、英越平行語料訓練編碼器與解碼器的參數,然后利用此參數對漢越NMT模型的編碼器與解碼器參數進行初始化,最后使用漢越小規模平行語料對模型參數進行微調,從而提升漢越翻譯的性能.
1 基于遷移學習的NMT
NMT是一個典型的編解碼結構,其中編碼器讀取整個句子序列并進行編碼,得到句子的向量表示,解碼器利用編碼器獲取到的句子向量作為目標輸入,逐詞生成目標語言的單詞序列.遷移學習可以將模型學習到的參數遷移到相近的任務上,利用高資源翻譯任務得到的參數來改善低資源翻譯任務的性能,從而降低翻譯任務對平行數據的依賴[9].Lakew等[10]提出使用動態詞表的方法,通過將初始語言對的模型參數遷移到新的語言對來提升機器翻譯模型的性能與收斂速度.Hill等[11]證明了在語義相似性任務上,從NMT編碼器中得到的單詞向量表示優于從單語(例如語言建模)編碼器中獲得的單詞向量表示.Mccann等[12]使用NMT模型的注意力機制將詞向量語境化來改善自然語言處理任務的性能.李亞超等[13]在藏語-漢語(簡稱藏漢)NMT研究中采用遷移學習方法緩解藏漢平行語料數量不足的問題:首先使用大規模英漢平行語料訓練得到一個英漢NMT模型;其次,在訓練藏漢NMT模型時,采用英漢翻譯模型整體參數初始化藏漢翻譯模型參數;最后對英漢翻譯模型參數初始化后的漢藏模型使用藏漢平行語料進行參數微調得到最終的模型.與Zoph等[5]提出的方法不同,李亞超等[13]提出的方法對藏漢翻譯模型的所有參數均使用英漢模型來初始化,且在初始化時不要求兩種翻譯模型的漢語詞向量一致,沒有對翻譯模型結構進行修改,更加適用于低資源場景下的NMT.通過以上分析可知,在富資源語言上預訓練NMT模型的參數初始化低資源模型的參數,不僅可以保證富資源語言上學習的語言知識能夠遷移到低資源模型中,還可以加快模型的收斂速度.
2 TLNMT-CV模型
NMT模型將源語言句子表示成一個定長向量,但是固定長度的向量不能充分表達出源語言句子的語義信息.基于注意力機制的NMT先將源語言句子編碼為向量序列,然后在生成目標語言時,通過注意力機制動態尋找與生成該詞相關的源語言詞語信息,大大增強了NMT的表達能力.本文在Klein等[14]提出的基于注意力機制的Transformer基礎上訓練漢英與英越的翻譯模型,訓練流程如圖1所示.首先采用大規模的漢英平行語料與大量的英越平行語料訓練得到兩個預訓練模型(A和B);其次,在訓練漢越NMT模型時,采用漢英模型的編碼器參數初始化漢越翻譯模型的編碼器參數,并且采用英越模型的解碼器參數初始化漢越翻譯模型的解碼器參數;最后,對初始化參數后的模型采用漢越平行語料進行微調訓練,得到最終的TLNMT-CV模型(C).
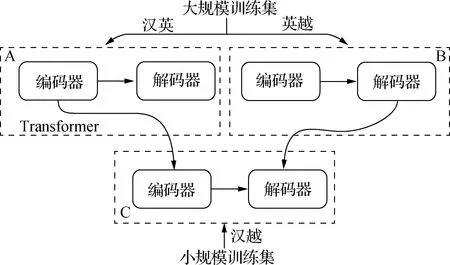
圖1 TLNMT-CV訓練流程圖Fig.1Training flow chart of TLNMT-CV
與Zoph[5]等和李亞超等[13]方法不同的是,本文對漢越翻譯模型的編碼器與解碼器參數,使用漢英模型的漢語端編碼器與英越模型的越南語端解碼器的參數來初始化,在此基礎上再使用小規模漢越雙語平行語料進行微調訓練,得到漢越NMT模型.為了提升預訓練得到的編碼器與解碼器之間的關聯性,保證初始化的參數更有利于微調訓練,本文在進行實驗前對訓練集進行擴充.首先在已有的漢英、英越的訓練集中,對樞軸語言英語進行回譯[15],使用大規模英漢平行語料訓練英漢翻譯模型;然后利用英漢翻譯模型對英越平行語料中的英語進行回譯,從而得到漢-英-越三語平行語料;再使用數據增強[16]的方法增加漢-英-越三語平行語料,提升模型參數之間的關聯性,減少存在的噪聲.
3 實驗與結果分析
3.1 實驗數據
本實驗采用規模為10萬句對的漢越平行語料,其中測試語料0.13萬句對,驗證語料0.1萬句對;70萬句對英越平行語料,其中測試語料0.5萬句對,驗證語料0.4萬句對; 漢英平行語料5 000萬句對,其中測試語料3萬句對,驗證語料1萬句對.在訓練之前對實驗數據進行過濾亂碼與分詞處理,其中漢語分詞工具采用結巴分詞,越南語分詞采用Underthesea-Vietnamese NLP工具.
為了增加實驗數據,使用回譯與數據增強的方法,擴充漢越訓練語料.回譯階段使用漢英大規模語料訓練翻譯模型,對2萬英越平行句對中的英語語句進行回譯得到2萬偽平行的漢英語料,與越南語對應并經人工篩選后得到1.5萬漢越平行語料,將得到的漢越平行語料加入到初始的10萬漢越平行語料中.最后使用數據增強的方法對11.5萬的漢越平行語料詞表(詞表為3.2萬個詞)中出現次數少于3的稀有詞進行替換,再通過人工篩選得到12萬漢越平行語料.
3.2 實驗設置
為了評估TLNMT-CV模型的有效性,實驗選取5個基線系統(基于SMT的Moses[17]、基于OPENNMT[14]框架的Transformer、卷積神經網絡(CNN)、基于注意力機制的Google NMT(GNMT)[18]和李亞超等[13]提出的遷移學習翻譯(Nmt-trans)模型作為對比.
Moses、Transformer、CNN、Nmt-trans、GNMT與本文提出的TLNMT-CV模型,在漢越翻譯方向上均以12萬的漢越平行語料作為訓練集.
Moses訓練中,使用Mgiza[19]訓練詞對齊,利用Lmplz[20]訓練三元語法的語言模型(LM).
Transformer、TLNMT-CV和Nmt-trans模型使用的詞表設置為3.2萬,句子的最大長度設置為50,“transformer_ff”設置為 2 048,“label_smoothing”設置為0.1,“attention head”設置為2,“dropout”設置為0.2,隱藏層數量設置為2,詞嵌入維度設置為256,“batch_size”設置為128,學習率設置為0.2.優化器選擇Adam[21],其參數設置為β1=0.9,β2=0.99,ε=10-8.CNN中編碼器設置為10層,解碼器則采用長短時記憶(LSTM)網絡,批次大小為64,卷積核大小設置為3.GNMT中隱藏層數量設置為2,“num_units”設置為128,“dropout”設置為0.2.
3.3 實驗結果
本文采用雙語互譯評估(BLEU)值作為評測指標.表1給出的是基線系統與TLNMT-CV在漢越和越漢兩個翻譯方向上模型的BLEU值對比結果.其中TLNMTe為參照TLNMT-CV模型只對編碼器參數預訓練,TLNMTd為參照TLNMT-CV模型只對解碼器參數預訓練.
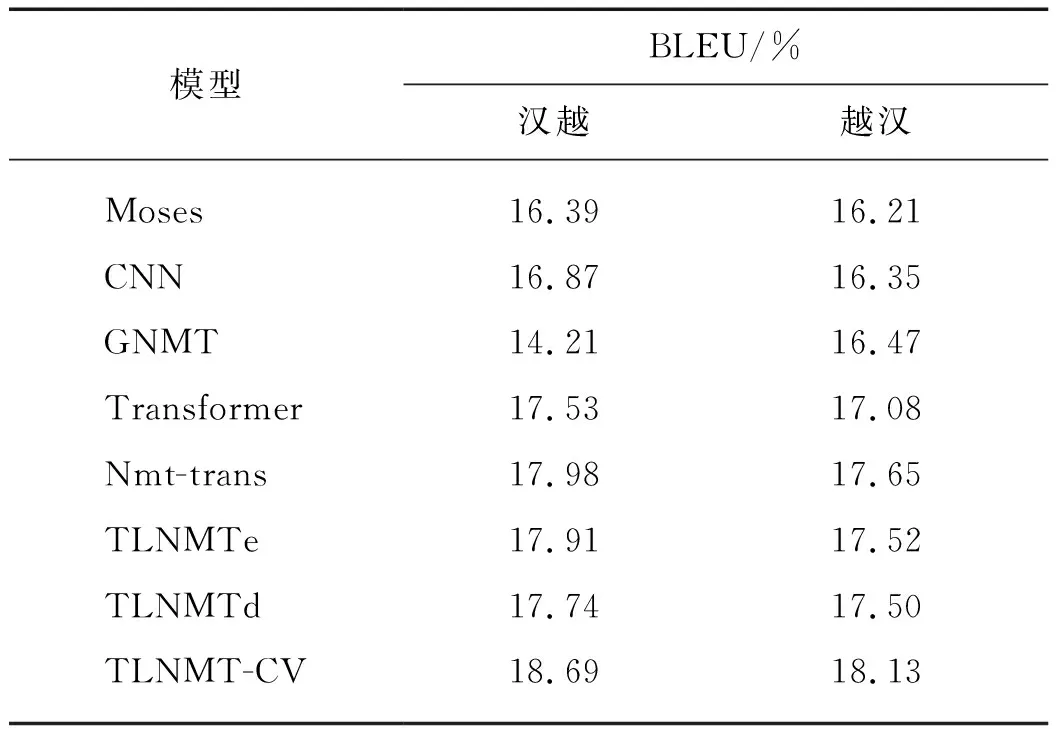
表1 不同模型的BLEU值對比Tab.1 Comparison of BLEU values of different models
從實驗結果可以看出漢越雙語NMT上TLNMT-CV模型效果明顯均優于基線系統,其中TLNMTe模型BLEU值對比Moses模型在漢越翻譯方向上提升1.52個百分點,在越漢翻譯方向上提升1.31個百分點.對比Transformer模型,TLNMTe模型BLEU值在漢越翻譯方向上提升0.38個百分點,越漢翻譯方向上提升0.44個百分點. TLNMT-CV模型在漢越翻譯方向上BLEU值對比Nmt-trans模型提升0.71個百分點,越漢翻譯方向上提升0.48個百分點.TLNMT-CV模型在漢越翻譯方向上BLEU值對比Transformer模型提升1.16個百分點,在越漢翻譯方向上提升1.05個百分點.
表2給出的是基線系統與TLNMT-CV模型在漢越翻譯方向上譯文的對比示例.
以上翻譯示例說明,本文方法雖然仍存在翻譯不充分的問題,但是在漢越NMT任務上,比基線系統能產生更高質量和準確度的譯文.

表2 不同模型的譯文示例Tab.2 Translation examples of different models
4 結 論
本文提出的TLNMT-CV方法,能夠利用漢英和英越大規模語料訓練漢越NMT的編碼器與解碼器的初始化參數,通過小規模漢越語料微調訓練獲得漢越NMT模型,該方法能夠提升低資源場景下漢越NMT性能.對比實驗也證明了本文提出方法的有效性.下一步可以繼續探索利用大規模的漢越單語語料進行預訓練,并將預訓練得到的語言知識融合到漢越雙語NMT模型構建中,提升翻譯的性能.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
