電子政務領域中文術語層次關系識別研究
2021-02-25 10:37:36鄧三鴻張寶隆
情報學報 2021年1期
張 衛,王 昊,鄧三鴻,張寶隆
(1.南京大學信息管理學院,南京210023;2.江蘇省數據工程與知識服務重點實驗室(南京大學),南京210023)
1 引言
數據驅動時代,電子政務信息作為我國政府機構的戰略性資源,正伴隨著自動化辦公與社會管理的革新與日俱增。2019年,中央部委成功打通了42個國務院部門垂直管理信息系統[1],而地方平臺“云上貴州”更是以1387TB的數據量實現了省市縣政府9728個部門政務系統的對接[2]。不難發現,海量電子政務信息資源在開放共享中日益表現出多源異構的特征,這使得傳統的以電子政務主題詞表為核心的政務術語知識體系的不足也越發凸顯,其特點主要表現為3個方面:①基于內容主題的術語層次較淺。就國內具有代表性的《綜合電子政務主題詞表》而言,其范疇表依據主題內容劃分為21個知識范疇,雖然涉及政務領域廣,但是術語層次較淺(僅至3級)。②基于結構關系的術語層次缺失。詞表內諸多層次術語具有結構包含關系(如“保衛”與“安全保衛”),但尚不全面。③術語層次關聯缺少語料支持。過去在缺少政務語料的條件下,只能采取人工構建詞表的方式。隨著電子政務的發展,公眾對政府工作的參與性顯著提高,一方面通過網絡百科以標準化的形式了解政務知識;另一方面借助社交媒體關注實時的政務信息資源。這些都在當下催生出大量政務語料,也為在缺少語料庫條件下形成的詞表開拓了較大的術語層次優化空間。
由此可見,傳統詞表中的電子政務術語由于缺少在大規模語料支持下對層次范疇和語義邏輯的深層優化[3],難以在大數據時代適應電子政務信息資源的標引、檢索以及組織工作,這就使得從語義角度自動化識別電子政務術語的深層關聯顯得尤為重要。
本體作為語義網體系內一種有效的知識組織方式,可以在信息系統的整合過程中將資源解析為機器所能理解的知識,通過語義驅動實現信息資源在網絡環境內的交換與共享[4]。因此,本研究以本體學習6層次理論[5]中的概念層次為指導,采用電子政務主題詞作為術語集,首先通過對網絡百科語料中提取的內容特征采取聚類的方式生成具備高召回率的概念層次,稱為基于內容的層次關系;其次,借助術語共現理論[6]對社交媒體語料建立概念格結構生成具有高準確率的概念層次,稱為基于結構的層次關系;最后,將二者相融合,以前者為整體框架、后者為修正指導,從而形成了一整套電子政務術語本體構成方案,所形成的電子政務本體將在信息檢索與推薦、跨部門協同共享、政務知識發現等實際應用中提供支持。
2 相關研究工作
采取內容與結構相融合的方法,對電子政務術語層次關系進行識別工作的研究基礎主要包括兩個方面:電子政務術語層次的組織工作和術語層次關系的識別方法。
就我國電子政務術語層次的組織工作而言,具有代表性的是中國科學技術信息研究所于2005年編制完成的《綜合電子政務主題詞表》,該詞表由字順表與范疇表所組成,是迄今為止國內收詞量最多、專業覆蓋面最廣的政務主題詞表[7]。然而,由于詞表由來已久,而且電子政務信息資源開放共享的訴求日趨強烈[8],學者們也逐步展開了對詞表的改進工作。賈君枝等[9]運用FAST主題詞分面對詞表進行分面式改造以契合公眾檢索需求。王汀等[10]則基于詞表與百科提出了面向大規模本體的自動化擴充方案。目前,尚未有學者對詞表的層次體系進行補充擴展抑或延伸細化。考慮到在缺少語料庫下人工構建詞表的主觀性以及現有層次關系的不完備性[11],例如,在字順表內,結構層面的術語“保衛工作”并未像“安全保衛”那樣歸置為“保衛”的下位類,也沒有從內容層面細化“安全保衛”與“保衛工作”二者術語間的語義聯系。因此,本文將基于范疇表的知識體系,通過大規模語料識別內容與結構層面的術語層次關系,形成具備深層樹狀結構的電子政務術語本體。
就本體中術語層次關系的識別方法來說,主要包括基于規則模板的方法與基于統計的方法[12]。基于規則模板的方法往往與句法依存分析[13]相結合,需要人工制定語言模板,在面向大規模非結構化文本所能獲取的層次關系較為有限[14]。此外,不同領域所制定的模板方案在相互間的可移植性不高[15],這也不利于規則模板的推廣。因此,本研究對電子政務術語層次關系的識別工作將基于統計的方法展開。由于采取不同的統計方法能夠分別識別內容與結構兩者層面上的術語層次關系,故將其劃分為與之對應的兩個角度:內容角度和結構角度。
內容角度,是指通過對文檔內容所解析出的向量空間進行聚類以達至對術語聚類的目的。該方法由于對識別術語關聯性具有較高的召回率而得到廣泛應用,具體包括:層次聚類[16]、K-means聚類[17]、DBSCAN聚類[18]等。然而,這些方法在大規模術語層次關系的識別中均具有一定局限。如層次聚類是一種小規模高精度的聚類算法;K-means運行結果具有較大的隨機性;DBSCAN聚類易將大量獨立點判斷成噪聲,不適合高維稀疏數據。相較之下,源于圖論思想的譜聚類[19]逐漸受到學界的推崇,其核心思想是通過降維將高維空間的數據映射到低維,從而實現對樣本數據特征向量的聚類,面對高維稀疏矩陣能夠實現精準且穩定的劃分效果,適用于從內容角度識別術語層次關系。
結構角度,是指在術語共現理論的指導下通過形式概念分析(formal concept analysis,FCA)建立能夠抽取出層次關系的概念格結構。該方法由于具備較高的準確率,在術語層次識別中也有不俗的表現。如de Farias等[20]通過FCA對巴西莫索羅市犯罪記錄數據進行分析并建立具有犯罪模式的概念格,以期規劃預防和打擊犯罪的戰略。王昊等[21]以“白血病”為例借助FCA實現了中文醫學領域本體層次結構自動構建的有效方法,并對面向學科資源的醫學專業術語層次關聯的抽取進行了詳細論證。
對兩者進行比較。從內容角度采取聚類的方式識別層次關系,有利于提高術語關聯的召回率,但準確率無法得到較好的保障;從結構角度采取FCA方法,能夠有效地提高術語層次間的準確性,但由于概念格結構相對復雜使得層次關系的識別過于嚴格,導致在層次關系的抽取中會遺漏掉很多上下位關系。可以發現,采取基于內容或結構的統計方法各有利弊,然而尚未有研究將兩者方法整合以優化術語層次關系的識別效果。
綜上所述,在電子政務術語的組織工作中,鮮有學者基于大規模語料對內容與結構層面的術語層次體系進行擴展延伸,更鮮有研究將基于內容和結構的統計方法相融合對術語層次關系的識別效果進行優化改進。因此,本文擬將基于大規模語料從內容與結構雙重視角識別電子政務術語層次關聯,以前者生成的基于內容的層次關系為整體框架,以后者生成的基于結構的層次關系為修正指導,形成一個兼顧層次關聯召回率與準確率的電子政務領域術語本體。
3 采用方法
本研究所采用的方法是針對電子政務術語所檢索到的自然語言文本,從內容和結構雙重視角識別電子政務領域中文術語層次關系的邏輯流程,如圖1所示。
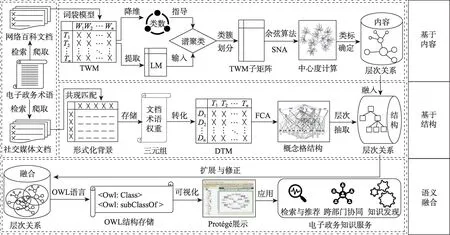
圖1 電子政務中文術語層次關系識別的邏輯流程
由圖1可知,電子政務中文術語層次關系的識別主要包括3個模塊:①基于內容的層次關系識別。從內容特征的角度識別層次關系需要保證文檔內容對電子政務術語內涵的支撐度,故采用網絡百科作為語料,按照術語列表依次獲取百科文檔;隨后,構建詞袋模型從文檔內容中提取關鍵詞特征,獲得文檔-詞語矩陣(document word matrix,DWM),并根據術語與百科文檔間的獨立匹配關系將其轉化為術語-詞語矩陣(term word matrix,TWM);接著,使用降維所確定的聚類數目與TWM所提取的拉普拉斯矩陣(Laplacian matrix,LM)進行譜聚類劃分矩陣類簇,并形成TWM子矩陣;進一步,對子矩陣進行余弦相似度計算以獲取術語之間的相似度,采用社會網絡分析(social network analysis,SNA)計算術語中心度,并將中心度較高的術語作為子矩陣的類目標簽;最后,使用多層譜聚類的方式,形成一個初步具備理論內涵的層次框架。②基于結構的層次關系識別。考慮到識別基于結構的層次關系有賴于在每篇文檔中不同術語之間的共現屬性,可用于揭示實踐場景中電子政務術語間的應用情況,故采用社交媒體文檔作為語料,并按照術語列表依次檢索、爬取;隨后,通過在社交媒體文檔內術語的共現匹配建立形式化背景,并以<文檔-術語-權重>三元組的格式存儲;接著,將三元組轉化為文檔-術語矩陣(document term matrix,DTM),使用FCA建立電子政務術語的概念格結構,并從中抽取出更為精細且具備實踐特性的層次關系。③語義融合。將基于內容與基于結構的層次關系相融合使其互為擴展、修正,便構成了更為完整、準確的電子政務術語本體,通過OWL結構存儲即可開展多元的電子政務知識服務。下文將對整套流程中所采用的具體方法展開闡述。
3.1 基于內容的TWM與基于結構的DTM構建
從內容的角度通過聚類識別電子政務術語的層次關系,需要深入網絡百科文檔對單個術語的釋義提取內涵特征,同時,要避免單個特征的力度過大,故采用TF-IDF構建電子政務術語內容文本的詞袋模型[22],提取并統計出每個電子政務術語所對應的釋義文檔中相對于整體語料文檔區分度較高的關鍵詞及其權重,以此作為特征量化其在每個文檔中的重要度。其中,單個文檔的關鍵詞及關鍵詞權重能夠形成一個權重向量,即文檔特征向量,所有文檔特征向量的集合便構建了電子政務領域的DWM,而由于每個電子政務術語能夠與其釋義文檔獨立匹配,故DWM亦可轉換為TWM,后續聚類工作將基于TWM展開。
從結構的角度通過FCA識別層次關系,需要統計出所有術語在每條社交媒體文檔內的共現情況,故而采取函數匹配判斷單個社交媒體文檔內所有術語是否出現,若出現統計為1,否則為0。若在一篇文檔內不止一個術語出現,則稱為術語共現[23]。其中,單個文檔內術語集合的共現情況能夠形成一個向量,所有文檔向量的集合便構建了存儲<文檔-術語-權重>三元組的電子政務領域DTM,后續FCA工作將基于DTM展開。
3.2 基于PCA與T-SNE的聚類數目確定
對電子政務術語TWM聚類之前需要確定聚類數目,目前受到學界認可的自動化處理方式是將矩陣降維至二維或三維空間,通過可視化輔助聚類數目的判斷[24]。
(1)主成分分析(principal component analysis,PCA)是一種對高維數據進行線性降維的方法[25],將高維特征映射到低維正交特征上,計算數據在正交特征上投影的方差,方差越大,正交特征包含的信息量越多,刪去小特征值方向上的數據即可達到降維效果。
(2)T分布隨機鄰域嵌入(T-distributed stochas‐tic neighbor embedding,T-SNE)是一種非線性降維算法[26],通過高維數據點之間的概率分布使得相似對象有更高的概率被選中,同時,將對象點映射至低維空間構建概率分布,使兩者盡可能相似以達到降維的效果。
首先,用數據點間的條件概率表示相似度,以xi為中心構建高斯分布(方差為σi),則有高維空間中任意兩點xi、xj間的相似性pj|i均可使得鄰域內的點(k)相似性較大,如公式(1)所示:
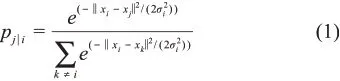
其次,為克服數據點間的“擁擠問題”,對高維數據點分布實行對稱化使其與采用t分布的低維概率分布矩陣對稱,用高維空間數據點對xi、xj和映射的低維空間重組的數據點對yi、yj之間的聯合概率pij、qij分別表示數據點之間的相似度,如公式(2)所示:
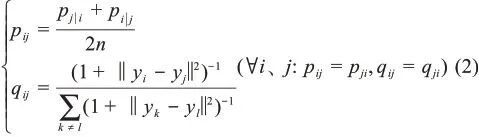
再次,采用KL散度(Kullback-Leibler diver‐gence)作為目標函數測度兩種分布之間的差異,利用隨機梯度計算的方法優化迭代目標函數,目標函數與梯度計算的判別式分別為
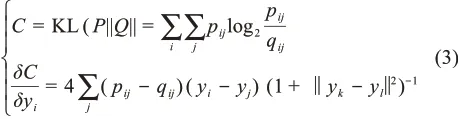
最后,T-SNE使用困惑度(prep)描述樣本點的有效近鄰點個數,其通過二分搜索的方式尋找最佳方差,計算公式為
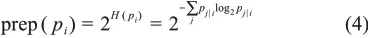
其中,H(pi)是pi的香農熵,用來度量樣本數據的不確定性。熵值越大,困惑度越大,領域數據點的數量越多,相互之間的概率也越接近。
綜上所述,PCA算法運行高效但特征值分解具有一定局限,降維主元并不一定最優;T-SNE精確性更優,而高復雜度計算會導致訓練時間過長。因此,可先行使用PCA對TWM進行線性降維,若降維效果不佳,則進一步采取T-SNE開展非線性降維。
3.3 基于譜聚類的術語類簇劃分
在聚類數目的指導下,可對電子政務術語百科文本的TWM進行譜聚類劃分術語類簇。譜聚類是一種源于圖論思想的聚類算法,將集中的數據點視為無向加權圖的頂點,從而讓數據點之間的相似關系轉化為無向圖的加權邊,使得數據集的聚類轉化為無向加權圖的切分問題[27]。譜聚類的核心在于對數據集LM的特征向量進行聚類,以達到更為精準的劃分效果,具體步驟如下:
Step1.輸 入 數 據 集TWM={v1,v2,…,vm},聚 類 數目為l。
Step2.將數據集圖譜化,定義任意兩點vi、vj之間的權重wij來表示兩點之間的相似度,當數據點間有連接邊時,wij>0;否則,wij=0,且無向圖的性質使得wij=wji。此外,圖形的邊權重通過高斯距離獲得,計算公式為
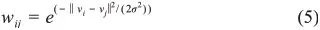
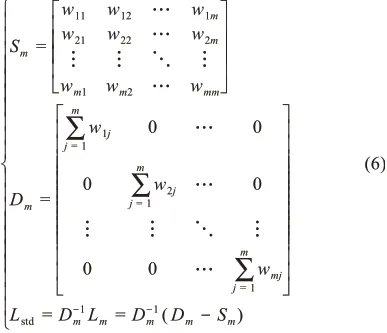
Step3.通過數據集的邊權重計算相似度矩陣Sm與對角矩陣Dm,以此構建拉普拉斯矩陣(Lm),并將其進行標準化處理(Lstd):
Step4.計算并獲取Lstd前e個最大的特征值與特征向量,將特征向量作為列向量進行集合得到矩陣um×e={u1,u2,…,ue},并對其規范化得到新矩陣Tm×e,規范公式為
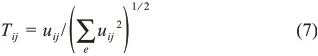
Step5.對Tm×e的 行 向 量 使 用K-means聚類,輸出類簇C1,C2,…,Cl,各類簇內的術語為通過聚類所劃分的電子政務術語集合。
因此,通過譜聚類可構建電子政務術語TWM的無向加權圖,并計算LM開展后續聚類工作,以達到從內容層面劃分電子政務術語類簇的目的。
3.4 基于中心度的術語類標確定
在劃分了電子政務術語類簇后,緊接著就是提取每個類簇的類目標簽。首先,針對譜聚類所切分TWM的 類 簇C1,C2,…,Cl提 取 出 子 矩 陣TWM1,TWM2,…,TWMl。其次,在每個子矩陣內以詞語為屬性構建術語特征向量,通過余弦算法計算術語特征向量的相似度,獲得表示術語間相似度的術語-術語矩 陣(term-term matrix,TTM)TTM1,TTM2,…,TTMl。最后,將TTM輸入社會網絡工具借助SNA計算各子矩陣內的術語中心度,提取中心度較高的術語作為子矩陣的類目標簽,即類簇C1,C2,…,Cl的標簽。
3.5 基于FCA的概念層次結構生成
FCA是一種數學語言驅動的本體概念構建方法,概念所有對象的集合被認定為概念的外延,而其中公共屬性的集合被稱為概念的內涵。從中抽取包括內涵和外延在內的概念層次結構,稱為概念格結構模型[28]。因此,采取FCA便能夠利用對象(政務文本)與屬性(政務術語)之間的二元關系抽取出基于結構的層次關系。
若電子政務術語集合A(屬性)、社交媒體文檔集合O(對象)以及二者間的關系R共同構建了一個三元組B=(A,O,R),其中,aRo表示在對象o∈O中有屬性a∈A,將三元組B進行轉化獲得電子政務DTM。
那么,在三元組B中,對O、A的冪集定義兩個映射f和h如下:
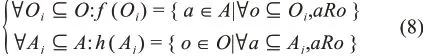
公式(8)反映了對象集合(Oi)中的共同屬性以及相同屬性(Aj)中的所有對象。此時,若f(Oi)=Aj且h(Aj)=Oi,則認為C=(Oi,Aj)是以Oi為外延、Aj為內涵的概念。
若對 于概念C1=(O1,A1)、C2=(O2,A2)有A1?A2,則稱C2是C1的子概念,而這種父子關系便形成了層次序以揭示概念間的層次關系。
實質上,概念間的父子關系的判斷是推理DTM內以文檔為特征的術語向量間的包含關系。因此,采取求與運算實現FCA判斷DTM內術語向量間的父子關系,可識別基于結構的電子政務術語層次關系。
3.6 基于語義融合的層次關系優化與評價
在將基于內容與基于結構的層次關系進行融合之后,便可以從擴展與修正兩個角度優化電子政務術語語義融合的上下位關系,并提煉出4種典型的融合類別,如表1所示。
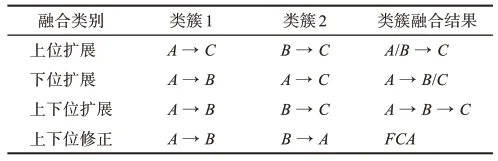
表1 語義融合類別
在表1中,語義融合的類別主要包括:①上位擴展,即不同的上位術語(A、B)指向同一個下位術語(C),以擴展下位詞的上位概念;②下位擴展,即代表一個上位術語(A)同時指向不同的下位術語(B、C),以擴展上位詞的下位概念;③上下位擴展,即通過同一個術語(B)將其上位術語(A)與下位術語(C)融合,以擴展上下位概念;④上下位修正,即以FCA結果為準,對沖突的上下位關系(A→B、B→A)開展進一步修正。

對電子政務術語層次關系優化之后,緊接著就是對所識別術語層次關系的召回率與準確率進行評價。如前文所述,現有的標準化主題詞表中,術語間層次關系尚存不足,不利于對基于語料庫所識別的術語層次關系進行評判。因此,本文將訴諸電子政務領域專家對術語層次關系的召回率與準確率進行評價,計算公式為其中,R表示基于術語實體進行抽樣評價所獲取的召回率;P表示基于術語關系進行抽樣評價所獲得的準確率。其中,基于術語實體進行抽樣評價,是指隨機抽取特定數量的電子政務術語。根據術語集內所識別出的上下位關系,領域專家一方面評價得到正確識別的術語層次(TP_entity);另一方面給出術語集內尚未識別出的層次關系(FN_entity),以此計算得出R。同時,由于當抽取的術語集中層次關聯的數量較少時會影響準確率的計算精度,故基于術語關系隨機抽取特定數量的層次關聯(TP_relation+FP_relation),并由領域專家評價得出正確識別的數量(TP_relation),以此計算得到P。
3.7 基于OWL語言的知識存儲與展示描述
將基于內容、結構和融合所得的層次關系通過OWL語言進行存儲形成電子政務知識結構。OWL存儲語法 主要有<owl:Class>和<rdfs:SubClassOf>兩種形式[29]。其中,前者用于定義類,后者用于描述類之間的父子關系,包含兩種知識存儲方法,如圖2所示。
由圖2可知,第一種方法(圖2a)利用語法(10)先行定義父類術語“保衛”,隨后通過式(11)在定義子類術語“安全保衛”的同時規定二者間的父子關系;第二種方法(圖2b)運用語法(12)在定義子類的同時定義父類,并描述二者間的父子關系。第一種編碼語法與第二種編碼語法均可表示“保衛”為“安全保衛”的上位類,即采用任意一種均可對識別出的電子政務術語層次關系編碼。將所有上下位知識結構存儲為OWL文件,并使用Protégé打開,即可對電子政務領域術語的層次關系進行展示。

圖2 電子政務術語層次關系編碼
4 實驗結果
本文以《綜合電子政務主題詞表》內“政法、監察”類主題詞為術語集,采用第3節的邏輯方法,運用Python 3.7、Matlab 2017、Gephi 0.9.2、Protégé5.0等工具,分別從內容和結構的識別術語間的層次關系,將兩者結果融合為電子政務本體以開展深入分析。
4.1 基于內容的層次關系識別結果及分析
基于內容層面識別電子政務術語層次關系需要訴諸網絡百科語料,其中百度百科憑借其詞條收錄數量、開放編輯機制、搜索引擎用戶基礎等方面的優勢已經成為全球最大的中文網絡百科[30],更利于揭示中文領域的術語知識內涵。因此,按照術語集列表依次檢索并爬取了所有術語的百度百科,爬取時間為2019年10月3日,在進行數據清洗后得到與術語匹配的1378個釋義文本。接下來,對內容層面層次關系的識別將基于該文檔展開。
(1)電子政務TWM構建。由于詞表已根據主題內容將“政法、監察”類術語劃分為5個二級范疇,故基于此分類標準通過TF-IDF模型分別構建這5類術語集的TWM,一共得到包括“綜合用語”(232×1605)、“公安”(384×1949)、“司法”(522×2320)、“監察”(144×629)、“國家安全”(96×426)在內的16114個術語-詞語關聯權重。
(2)PCA與T-SNE聯合輔助聚類數目確定。首先,對TF-IDF算法所生成的電子政務TWM進行PCA降維,將高維矩陣降至2維以展現術語在平面上的分布,從而輔助聚類數目的確定。若PCA線性降維的效果不佳,則進一步采取T-SNE非線性降維。以“司法”類術語為例,結果如圖3所示。
由圖3可知,“司法”類術語特征的PCA降維結果表明,電子政務術語在二維空間內分布較不均衡,不利于對術語聚類數目的可視化劃分;而TSNE降維能夠使得術語在文本空間內達到較好的分布效果。通過可視化不難發現,“司法”類術語的聚類數目可設定為5,其余類簇在確定向下細分的類目時均參照此種方法。
(3)基于內容的層次關系生成。在降維所得聚類數目的指導下,對電子政務術語的TWM進行多重譜聚類,獲得電子政務術語的層次關系,如表2所示。
由表2可知,在內容視角下,電子政務術語經過多重譜聚類已劃分為穩定層次,并在原有詞表的基礎上向下細分了3~4層。本研究通過余弦算法計算每個類目內術語間的相似度,再借助SNA計算術語中心度,將中心度較高的術語作為類目標簽。以“司法”類第2層中的類簇為例,結果如圖4所示。
在圖4中,SNA結果表明該類簇內中心度前3的術語分別為“行政復議”(196)、“行政司法”(195)及“訴訟代理”(186)。其中,前兩者的中心度最為接近,而從術語內涵的角度來看,“行政司法”是指行政機關依照司法程序解決糾紛的所有行政行為,其內涵廣度超過了作為行政行為一種的“行政復議”,故擇其為該類簇的標簽。
本研究分別對表2中的第2、3、4層類目采用SNA的方法確定類目標簽,從內容視角識別電子政務術語的層次關系,一共得到了1371對上下位關系。通過圖2中的OWL語法對層次關系自動編碼,可存儲基于內容的電子政務術語層次知識結構,如圖5所示。
讀取“政法、監察”領域內由基于內容的電子政務術語知識結構所存儲的OWL文件,通過Onto‐Graf插件對基于內容的層次關系進行展示,如圖6所示。

圖4 類簇標簽確定
圖5 基于內容的電子政務術語層次知識結構
images/BZ_73_224_795_1013_1018.png
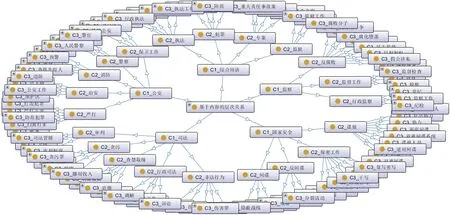
圖6 基于內容的電子政務術語層次關系展示(1~3層)
在圖6中,從外在特征的角度來看,基于內容的電子政務術語層次具備清晰的知識框架。在“綜合用語”“公安”“司法”術語集內,類簇的最大深度可至5層;在“國家安全”“監察”術語集內,最小層次為2層。在知識框架的118個類目內,最大簇為“監察”類的第3層類目“監察工作”,共有44個術語;最小簇為“監察”類第2層類目“行政監察”,共有3個術語。此外,超過一半的知識類目分布于框架的第3層,占整體類目的56.8%,說明采取聚類方法所形成的基于內容的層次關系較為合理。
從內在特征的角度而言,本研究將通過例證的方式從電子政務知識本體橫向擴散的差異性與縱向延伸的繼承性兩個方面分別探索其優劣,如表3所示。

表3 基于內容的術語層次內在特征分析
一方面,表3展現了“公安”類術語內的一簇知識結構。從橫向擴散的角度來說,“安全保衛”知識簇在第4層所拆分的類目標簽可以代表保衛工作的針對對象(反動組織)、執行主體(隊伍)和具體活動(反恐),能夠體現出較為明顯的差異;從縱向延伸的角度來說,C1_公安→C2_保衛工作→C3_安全保衛→C4_反動組織/反恐/隊伍,也能在類簇不斷細化的過程中反映出術語內涵的繼承。因此,基于內容的層次關系具備一定的有效性。
另一方面,表3中的知識結構也尚存不足。如底層術語“防暴警察”歸屬于第4層的“反恐”類在內容層面雖無問題但并不全面,這是因為術語“警察”也可以作為其上位類,因此可進一步對電子政務本體進行擴展。又如該類簇將“保衛工作”設定為“安全保衛”的上位類,然而“保衛工作”的定義是指國家安全和公安保衛的組成部分,故將其作為“安全保衛”的下位類更為合適。此外,術語“反革命組織”歸屬于“反動組織”的范疇會比作為“隊伍”的下位類顯得更為貼切,所以已有層次關系亦可進一步修正。
4.2 基于結構的層次關系識別結果及分析
基于結構層面識別電子政務術語層次關系需要訴諸社交媒體語料。其中,以政務微博為代表的政務社交媒體歷經十年發展,從2009年的幾十個賬號增長到如今的179930余個,已經成為我國最大的移動政務平臺[31]。因此,按照術語集列表順序自動檢索并爬取了所有“政法、監察”類電子政務術語的政務微博文本,爬取時間為2019年10月3日,獲取從當日起向前回溯10個頁面的微博文檔。本研究通過去除缺失值、重復值和整理文檔集與術語集對應關系等數據清洗操作,得到與電子政務術語相匹配的政務微博共計21638條,基于結構的層次關系識別將圍繞這類文檔展開。
(1)術語共現關系生成。相較于基于內容角度使用單個術語的百科文檔,基于結構識別層次關系更強調不同術語在文檔內的共現情況。若繼續按照詞表對“政法、監察”類術語二級范疇的劃分方式,會致使5個類簇內的術語相互隔離,同時也會遺漏很多上下位關系。較為典型的為“綜合用語”類的術語集合包含有與其他4類術語集密切相關的術語,如“案件”“犯罪”“反貪”等術語,在實踐場景中均有可能與“公安”“司法”“監察”類術語在政務文本中共同出現。因此,基于結構視角識別層次關系將不再采用詞表所提供的二級范疇劃分方式,而是將所有術語作為一個整體,通過函數匹配術語集在21638條政務微博文本內的共現結果,共得到32592個關聯。
(2)形式化背景與FCA。將電子政務術語在文檔中統計,得到共現關聯以<文檔,術語,權重>三元組的形式進行存儲,并將其轉化為DTM,形成電子政務領域的形式化背景EFM={D,T,R}。其中,D中 共 有21638個對象;T中 共 有1378種 屬 性;R中存在32592個關聯。通過編寫求與運算程序對EFM實現FCA,如圖7所示。
在圖7中,由工作區的元胞數組可知,本實驗使 用DTM(21638×1378)存 儲EFM,通 過 對 象(電子政務文檔)所形成的向量空間判斷屬性(電子政務術語)之間的包含關系,從而實現FCA獲取電子政務術語間的上下位關系,并形成了Result對稱數組(1378×1378),包括行術語(LT)、列術語(CT)和上下位關系(H),記作:LT為CT的H,例如,“案件”為“案件處理”的上位,如此累計得到1505對上下位關系。通過數據庫連接運算刪去其中冗余關系,最終獲得1232對上下位關系。
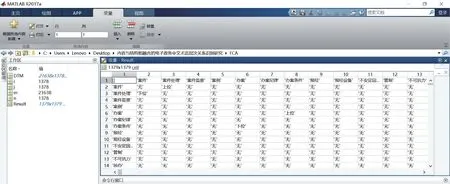
圖7 基于結構的上下位關系生成
(3)知識存儲與可視化。通過行列轉換,將所獲得的上下位關系轉換到二維,并使用OWL語法進行存儲,展示基于結構的電子政務術語層次關系,如圖8所示。
在圖8中,從外在特征的角度來看,電子政務術語基于結構的層次關系的整體框架尚不完備。在結構層次的392個類目中,僅首層就分裂出247個類目,占總體知識類目的絕大多數(63%),僅存有2簇最大深度雖也可至第5層,這使得縱向延伸的類目較為有限。此外,類目的最大簇為“案件”,共有49個術語;最小簇中含有1個術語,且在首層類目中占據的比例最大(39.3%)。不難發現,整體框架的層次性與完整性均略顯不足。
從內在特征的角度而言,基于結構的層次關系的精準性較高。延續對表2中層次關系的說明,結構層次結果顯示,“防暴警察”為“警察”的下位類,“安全保衛”為“保衛工作”的上位類,“反革命組織”歸置為“恐怖組織”的下位類,根據內容層次所識別“恐怖組織”為“反動組織”的下位類,推理可得“反革命組織”也從屬于“反動組織”的范疇,這些均能夠對內容層次框架進行有效的擴展與修正。此外,結構層次最大深度的2個類簇分別為C1_審判→C2_一審終審→C3_終審制度→C4_兩審終審制度→C5_四級兩審終審制度、C1_案件→C2_特別程序→C3_終審制度→C4_兩審終審制度→C5_四級兩審終審制度,根據“審判”“案件”的知識內涵,類簇在深層次細分過程中同樣也能夠保持較強的準確性。
4.3 語義融合結果及分析
基于內容的層次關系為電子政務術語本體搭建了初步框架,該框架具備有效的完整性與層次性,但準確性尚可優化。相較之下,基于結構的層次關系則更為精準,但對本體框架的支撐性略顯不足。因此,進一步將兩者進行語義融合,前者用于框架搭建,后者旨在修正與擴展,以構成一個框架完整、層次深入、精度準確的電子政務術語本體。
語義融合一共得到2603對上下位關系,通過連接運算對合并的上下位關系進行去重,得到2182對上下位關系,形成了“政法、監察”類電子政務術語本體,如圖9所示。
在圖9中,“政法、監察”類電子政務術語本體具備更為完整、清晰的外在特征,類簇最大深度延伸至11層,語義細分維度大幅加深。在整體框架的638個類目內,最大簇為“監察”類第3層類目的“檢察”以及處于“司法”類第5層或處于“監察”類第6層的“監察工作”,均聚合有40個術語,而最小簇含包含1個術語,占總體類目的39.5%。此外,超過一半的知識類目(52.8%)分布于本體的第4、5層,最多的第4層類目占到整體的29.8%,說明了類目在不同層次間的分布更為均衡。
基于表1中所列舉的語義融合類別,在電子政務本體中截取囊括所有類別的一個局部進行說明,其內容與結構層面的層次關系如表4所示。
在表4中,內容與結構兩者層次關系的語義融合主要有4種代表形式:①上位擴展,即“出入境”“安全員”“保衛工作”多個上位術語指向同一下位術語“民航安全保衛”;②下位擴展,即同一上位術語“治安”指向“出入境”“治安處罰”多個下位術語;③上下位擴展,即通過同一術語“保衛”將其上位術語“打擊犯罪”與下位術語“安全保衛”連接為同一個類簇;④上下位修正,以FCA為準對“安全保衛”與“保衛工作”的上下位關系進行修正。根據表4中內容與結構視角下層次關系的語義融合,從電子政務術語本體中抽取出經過擴展與修正后的上下位關系,如圖10所示。

表4 電子政務術語層次關系融合(局部)
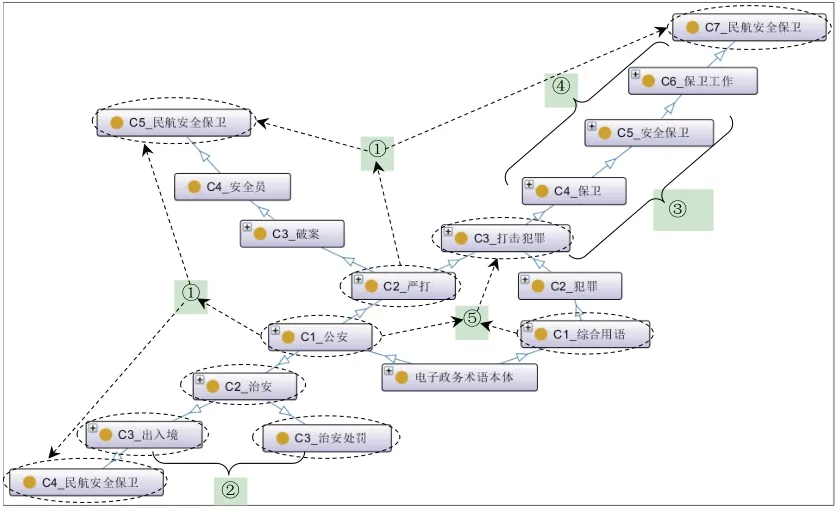
圖10 電子政務術語本體擴展與修正(局部)
在圖10中,語義融合主要展現了電子政務本體中“公安”類與“綜合用語”類術語的擴展與修正情況。由①可知,在“公安”類術語集內,通過擴展上位概念“C3_出入境”“C4_安全員”及“C6_保衛工作”,使得類簇“C2_治安”以及由“C2_嚴打”所細分的“C3_破案”“C3_打擊犯罪”分別指向了同一下位術語“民航安全保衛”,該術語處于“C2_治安”的第4層,“C3_破案”的第5層,“C3_打擊犯罪”的第7層;由②可知,在“公安”類術語集內,“C3_出入境”“C3_治安處罰”擴展了其上位術語“C2_治安”的下位概念;由③可知,在“公安”“綜合用語”類術語集內,上位術語“C4_保衛”及下位術語“C6_保衛工作”分別擴展了“C5_安全保衛”的上下位概念;由④可知,通過FCA所抽取層次關系的指導,將“C5_安全保衛”修正為“C6_保衛工作”的上位類。此外,在整體局部中可以進一步發現與①同屬于上位擴展的編號⑤,其通過擴展上位概念“C2_嚴打”及“C2_犯罪”致使“C1_公安”與“C1_綜合用語”分別指向了同一下位術語“C3_打擊犯罪”,使得原本詞表中不同二級范疇內的術語得以關聯,也驗證了以整體術語集進行FCA的必要性與有效性。
綜上所述,①~⑤表明語義融合能夠切實有效地擴展并修正術語的層次內涵,繼而提升電子政務術語本體層次關系的召回率與準確率。
4.4 電子政務術語本體評價分析
在形成了電子政務術語本體之后,接下來就是測度本體中層次關系的召回率與準確率,繼而對本體所識別的層次關系進行評價分析。本體中1~3層術語、3~7層術語和7~11層術語的數量分布大致滿足1∶3∶1,故可大致分為1~3層的大類術語、3~7層的中層術語和7~11層的深層術語。其中,大類術語代表著電子政務本體的整體知識架構,中層術語在整體框架的基礎上廣泛擴散知識關聯,深層術語則將擴散的知識進一步細化延伸。因此,從這3個層面測度術語層次的召回率和準確率能夠有效評價電子政務本體的整體質量。
基于術語的分布規律,本研究采取隨機抽樣的方式,分別從1~3層、3~7層、7~11層中分別抽取出20、60、20個術語實體以及術語集中所識別的上下位關系,總共抽取5次,取樣過程中秉持每層術語的抽取數量相對均衡,如此便得到了用于評價召回率的5組術語實體樣本;采取相同的方式從1~3層、3~7層、7~11層 中分別抽 取出20、60、20對層次關系,總共抽取5次,得到用于評價準確率的5組術語關系樣本。結合論文發表數量、被引次數、代表性著作以及所在機構遴選出5位電子政務領域專家,并將5組樣本分別發予領域專家對術語層次關系進行評價,收回反饋統計評價結果如圖11所示。
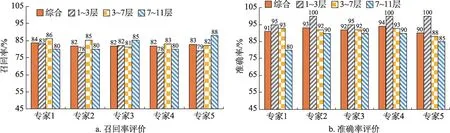
圖11 電子政務術語本體抽樣評價結果
由圖11可知,從整體來看,電子政務本體層次關系的評價結果良好,5位專家評價的綜合召回率均在80%以上,綜合準確率在90%以上,這表明將內容與結構的層次關系相融合取得了較好的應用效果。從召回率而言,處于1~3層、3~7層、7~11層的術語關聯的召回率較為均衡,并未體現出明顯差異;從準確率來看,處于1~3層術語層次的準確率最高,3~7層次之,7~11層最低但也均在80%以上,這一方面說明了電子政務本體具備良好的知識擴展性與延伸性,同時,也反映了術語層次關系的準確率會隨著層次加深逐級遞減。基于此,在電子政務術語本體內各大類中進一步遴選出深層類簇進行準確性分析,如表5所示。
由表5可知,從整體上來說,電子政務術語層次關系的準確性較高。就“綜合用語類”與“公安類”而言,兩者分別通過“C2_犯罪”與“C2_嚴打”所細分的下位術語“C3_打擊犯罪”在第3層合并為一簇,并自上而下深化至第10層,包含保衛、執法隊伍、犯罪案件等子類術語;就“司法類”而言,術語細化主要包含依法行政、訴訟過程、實例案件等方面的內容,能至第11層;就“監察類”而言,術語依據監察工作與監察部門的內涵演化至第8層;就“國家安全類”而言,術語延伸的軌跡圍繞間諜工作展開并達至第8層。
基于內容角度的層次關系大幅加深,同時也促使諸如“放火”“放火案”“放火案件”抑或“監察”“監察部”“監察部門”“紀檢監察部門”等基于結構角度的層次關系得以關聯,這說明采用電子政務語料識別術語層次關系有效彌補了人工詞表的不足。
5 結語
本文基于內容與結構視角,首先,通過對網絡百科內容所提取出的特征詞語采取譜聚類的方式,生成基于內容的層次關系;其次,根據術語集在社交媒體文檔中的共現匹配情況,采用FCA建立概念格結構,從而提取基于結構的層次關系,以前者具有高召回率的層次關系為整體框架、后者高準確率的層次關系為修正指導進行語義融合,形成了一整套電子政務領域中文術語本體識別方案。對“政法、監察”類電子政務主題詞的實驗表明,內容與結構層面的語義融合,則達到了很好的擴展與修正效果,專家評價結果顯示電子政務本體中層次關系的整體召回率(≥80%)與準確率(≥90%)均較高,術語在語義內涵的延伸過程中較好地彌補了原有詞表在內容與結構層面上的不足,這說明采用大規模語料所形成的電子政務本體具備良好的知識擴展性與延伸性。
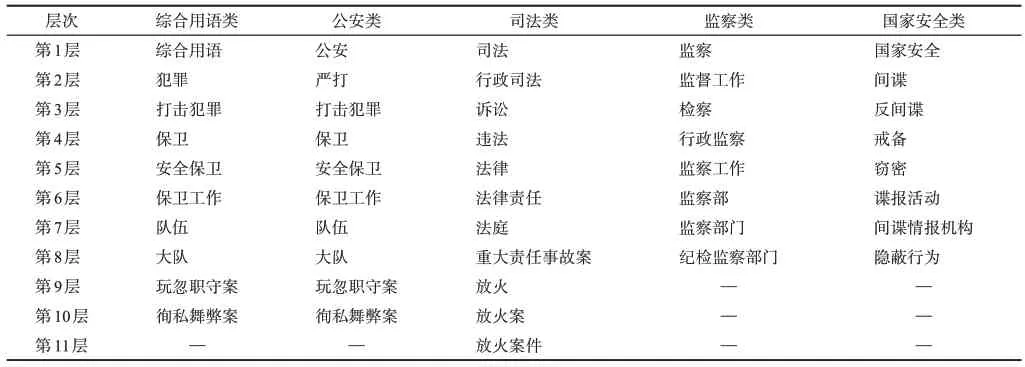
表5 電子政務術語本體深部層次準確性分析
本文針對“政法、監察”領域所形成的電子政務術語層次關系識別方法,是一種可以在短時間內面向更多政務領域(“科技教育”“對外事務”“軍事國防”)、更大規模術語開展知識組織工作的自動化體系,所構成的電子政務術語本體也將在后續知識管理工作中開啟更為智能的應用,本文暫列出3點:①信息檢索與推薦。利用電子政務本體的推理功能,一方面,通過關鍵詞擴展助力于用戶信息需求表達;另一方面,根據本體內術語的上下位關聯實現政務信息的個性化推薦。②跨部門信息共享。基于“公安”“司法”“監察”“國家安全”等領域的關聯術語,指導公安部、司法部、監察部、國家安全部等跨部門信息系統之間的政務信息資源共享,以開展不同部門間的政務合作。③政務知識發現。通過電子政務術語關聯,探索未被發掘的政務知識資源,繼而洞悉并提取出電子政務領域的新興知識,以期為優化未來國家行政管理的工作效率提供參考。
另外,本研究也存在可完善之處。第一,通過機器識別層次關系通常對語料要求較為嚴苛,而百度百科與政務微博均源于網絡文本,在無人工干涉的條件下會致使語料內容較為粗糙,后續將著重提高語料質量以展開對比實驗;第二,文章對術語層次關系的識別來自現有詞表,而長期以來,在政務工作中所產生的新主題詞并未被詞表收錄,接下來的研究將試圖識別未登錄詞間的關聯以擴充電子政務本體的層次體系。
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
科學大眾(2021年21期)2022-01-18 05:53:48
科學大眾(2021年17期)2021-10-14 08:34:02
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
臺聲(2016年2期)2016-09-16 01:06:53
現代企業(2015年9期)2015-02-28 18:56:50
土木建筑工程信息技術(2013年2期)2013-10-17 03:14:12
