高校網絡輿情監測機制研究
2021-04-05 08:56:11陳蒙李學志
現代信息科技 2021年17期
關鍵詞:數據挖掘
陳蒙 李學志


摘? 要:隨著當今時代網絡的高速發展與廣泛應用,大量的互聯網信息也隨之而來,如何對互聯網進行監測與分析便成了一項重大的命題,識別網絡輿情在公眾情緒中的變化趨勢具有重要意義。基于此,對高校的網絡輿情監測機制進行分析研究,提出一個基于互聯網話題定時的新詞結構發掘方法。通過監測校園中的公共事件,實現對校園中網絡信息的有效監控。
關鍵詞:高校輿情;輿情監測;數據挖掘;情感分析
中圖分類號:TP391.1 ? 文獻標識碼:A 文章編號:2096-4706(2021)17-0145-04
Abstract: With the rapid development and wide application of the network in today's era, a large amount of internet information also appears. How to monitor and analyze the internet has become a major proposition, it is of great significance to identify the change trend of network public opinion in public sentiment. Based on this, this paper analyzes and studies the network public opinion monitoring mechanism of universities, and puts forward a new word structure mining method based on internet topic timing. By monitoring the public events in the campus, we can effectively monitor the network information in the campus.
Keywords: university public opinion; public opinion monitoring; data mining; sentiment analysis
0? 引? 言
現在是大數據的時代同時也處于人人都是自媒體的時代,社交網絡成為現下大家進行溝通、交流和獲取信息的主要且重要媒介和平臺。由于網絡信息傳播的特點一級網絡自身的自由性與包容性,使得我們傳輸的信息不管好與不好,積極與消極,都能在網絡中快速傳播。再加上網民自身對于訊息具有較強的好奇心和獵奇心理,導致其對于消極和負面的信息表現出更大的興趣,這也無形中刺激了信息的二次迭代傳播,甚至會形成一股不可控的影響力。高校也是一個重要的信息傳播場所,學校的主要成員是學生,學生是年輕和活力的代表,這個人群對于新生事物會表現出更強大的關注度,而且作為年輕的一代往往不具備甄別是非好壞的能力,缺少較強的信息識別和判斷意識。而且,現在的趨勢是,社會大眾和媒體對高校校園越來越關注,其所處的輿論環境也是越發復雜,故其對于高校網絡輿情的研究具有現實意義。
針對高校校園網絡輿情的監測和群體網絡的演化研究的需求,對高校網絡輿情監測機制進行研究和分析[1]。校園網絡輿情監測平臺,其目的在于能夠及時、準確、高效地對以大學生為群體的網絡輿情進行監控,提供科學合理的技術方法對網絡輿情態勢進行分析和研判,并將評判結果反饋給高校學生管理部門,以便制定相應的對策,維護高校校園的穩定。學生作為校園網絡輿情的重要載體,交互的對象往往也是學生,而其相互之間的互動以及交互也是導致校園網絡輿情的主因。針對這一基本特點,本文網絡輿情信息獲取的來源主要包括針對大學生的各類論壇、貼吧、微博等。根據以上需求,該機制的研究主要從以下幾個方面開展:輿情信息采集(文本挖掘)、輿情信息預處理(文本挖掘)、輿情分析(情感分析)。在文本挖掘方面,我們采用“Scrapy-Redis-Bloomfilter”分布式爬蟲框架對語料庫進行抓取,并以微博評論為實驗對象。在文本處理方面,系統將自動裝配數據庫中的語料庫,完成相應的處理工作。在情感分析方面,我們嘗試用一種新的思路構建漢語分詞詞典。為了彌補情感詞典在識別“形容詞不定式句”時的有效性不足,我們準備一套情感映射的預備方案,并且考慮到句子中狀語副詞對于情感表達可能會產生的影響[2]。
1? 高校網絡輿情監測
1.1? 數據挖掘
如何從互聯網上去獲取有效的數據使我們進行數據分析的一個非常重要的組成部分。
Pais等人[Pais,Cordeiro,Martins等人(2019)]開發了一種基于API的特定社交網絡爬蟲技術。該技術可以通過社交網絡提供的API輕松方便地去獲取結構化數據。但是對于類似于微博的社交網絡,有限的訪問令牌日期、API數據內容和訪問時間會嚴重阻礙到數據收集。若是使用網絡爬蟲技術的話,則是沒有如上的要求和限制的。在此,我們選擇使用selenium工具去啟動瀏覽器,進而去模擬出登錄的動作,在此基礎之上去分析網頁,最后得到我們想要的數據。在此,介紹一下selenium,它是一個用于進行Web應用程序測試的工具插件,可以拿來處理涉及復雜環節的登錄。但是有一個我們無法忽視的細節問題,它對于抓取數據量大的海量數據效果不是很理想,基于此,提出了一個新的改進方案:可以去利用爬蟲框架Scrapy,把Scrapy-Redis的分布式組件中的Redis數據庫導入到該框架中,進去達到一種更加高效的分布式爬蟲系統,該系統的提出也能用來解決數據率低的問題。基于這樣的研究前提,我們的輿情監測平臺系統的數據采集部分采用Scrapy-Redis分布式框架,使用基于二進制向量和哈希函數的重復數據刪除算法Bloom Filter對抓取前后的url進行過濾和處理。
1.2? 情感分析
對于前面采集到的數據,我們準備采用文本情感分析的方法對獲取的數據進行處理。現在來講,對文本情感進行分析主要是采用兩種方法進行分析研究,分別是基于機器學習的方法和基于詞典的方法[3]。前者主要是從文本中提取一些積極和消極的情感文本作為訓練集,并根據情感分類器對所有的文本進行積極和消極方向的分類。該方法已應用到許多領域,但是仍然有其不足之處:需要人為的標注訓練模型;當遇到的文本數據規模比較大的時候,無法保證一個較高的準確度;由于語言本身句子結構和用法的靈活性,在特征選擇方面存在著許多干擾因素。于是針對上述的研究分析結果,我們選擇用基于詞典的方法對數據進行分析和處理。我們往往會選擇一個比較龐大的,質量稍微比較高一些的情感詞典,結合相應的語義規則,去評判相關的輿情熱度和情感傾向性,為我們提供一個感知輿情,掌控輿情和引導輿情的方法。
2? 相關技術
2.1? 文本挖掘及數據分析
大家都很清楚,基于Scrapy-Redis的分布式爬蟲框架主要是用于協助我們捕獲評論信息的。但是有一個情況需要考慮,當用于爬行的數據超過一定量的時候,Redis會占用大量內存空間。同時爬蟲框架自身也是需要占用內存,故在此使用Scrapy同時進行爬蟲變得有些困難。在這里,我們可以使用一個可以刪除重復數據的算法Bloom Filter,該算法通過使用數組表示要進行檢測的集合,通過概率算法快速去判斷出該集合中是否存在重復元素,通過研判,若是集合中存在有重復的數據,可以進行刪除操作。這個算法在空間和時間上都占用優勢。我們準備了一些解決方案用于對抗微博上的反爬蟲行為的檢測,用來確保獲取數據的任務。具體做法為:
(1)重新編寫代理IP池的維護腳本。國內的幾家主要代理IP供應商的網站,采用的都是“雙進程+多線程+多協程”的維護模式,可以異步操作“代理IP池驗證”和“代理IP池旋轉”,確保可用的IP存活率為90%。以上保證了主爬蟲框架能夠實時使用100多個http類型的代理ip。代理IP的使用頻率控制在1/5分鐘。
(2)基于STAFF對國內24家網絡服務商主頁進行監控框架,采集中繼服務器IP;分布式爬蟲攜帶Socks5來偽裝HTTPS流量以實現全局訪問。
(3)準備200個微博免驗證賬號,定期模擬登錄破解驗證,確保cookie池可用。
我們可使用以下描述的兩種方法進行數據分析,用來確保大多數沒有用處的數據被過濾掉。第一種優先可調用爬蟲智能分析報紙庫,它可以為我們提供更為強大的功能,以及它可讀性也不錯。具體做法是,Article類首先被導入到報紙庫中,然后直接傳入URL,并調用它的下載方法。其次,去調用解析方法來對網頁進行智能解析。最后,根據需要過濾掉沒有用處的數據。而在Scrapy中,有兩種提取數據的方法供我們選擇,一種是使用Xpath選擇器,另一種是使用CSS選擇器。在Scrapy爬蟲框架中,text()函數經常與Xpath表達式一起使用,以提取節點的數據內容,而我們常常會選擇Scrapy自帶的解析器Scrapy Selector的XPath工具來解析HTML信息。
2.2? 數據清理
接下來我們要對已經采集獲取到的文本數據進行分析處理,由于獲取的原始數據會存在錯誤、格式不一致的情況或是帶有一些與情感分析不太相關的內容,我們統稱其為臟數據。為了提高數據的質量,須對數據進行規范化處理。
2.3? 情感分析
我們對文本進行的情感分析,主要是通過分析文本信息數據來挖掘出來情感傾向。對于文本情感分類,首先從文檔中提取情感特征,然后使用分類器對其進行分類。這里使用的分類器主要是采用樸素貝葉斯方法構建文本情感分析分類器[4],繼而將情感粒子細分。
2.3.1? 建立詞典
詞典的覆蓋面和完整性往往決定最終的分析效果,詞典也是文本情感分析中非常核心的環節。我們選取的一般情感詞典有清華大學褒貶義詞典、知網情感分析用詞語集、臺灣大學NTUSD。考慮到網絡新詞更新速度非常快,我們選擇基于這些通用情感詞典,基于時間維度對每天的采樣信息進行分析,發現新詞,擴展情感詞典。
2.3.2? 文本預處理
文本預處理包括中文分詞和停止詞的去除。刪除停止詞就是遍歷語料庫中的所有單詞,并刪除停止詞[5]。
2.3.3? 建立模型
根據分詞的結果進行正負極性的分類。如何實施,我們采用樸素的貝葉斯算法。其是一種基于概率的算法,根據一定的先驗概率,計算出Y變量屬于某一類的后驗概率[6]。具體步驟如下所示:根據構造的向量矩陣,計算公式為:
接下來的工作重點是細分情緒粒子,詞匯本體中的情緒分為7種類型:希望、快樂、沮喪、憤怒、恐懼、失望、震驚,情緒強度為:1、3、5、7、9、5級,9級強度最大,1級強度最小[7]。每個詞對應的信息,如在每種情緒下的極性。將上述分割結果轉換為字典,繼而對對文本分詞結果進行分類操作處理,甄別出其中代表情感的詞匯、否定意義的詞匯以及程度副詞。第一步是先將初始權重W的值設置成為1,從詞匯本體中的第一個情感詞開始,用其情感詞的權重值與情感值進行乘法運算作為分數值,隨之去判斷確認詞匯本體中的情感詞是否有程度副詞和否定詞匯,若是其中有一個是消極的詞匯,則用權重值W乘(-1)作為程度副詞程度值。第二步用新的W的權重值去進行遍歷第二個情感詞,循環操作直到詞匯本體中所有的情感詞都被遍歷一遍。每次遍歷結束之后的權重值之和就是這個文本最終的情感值,當然這個最終結果值是以累加和的形式存在的[8]。
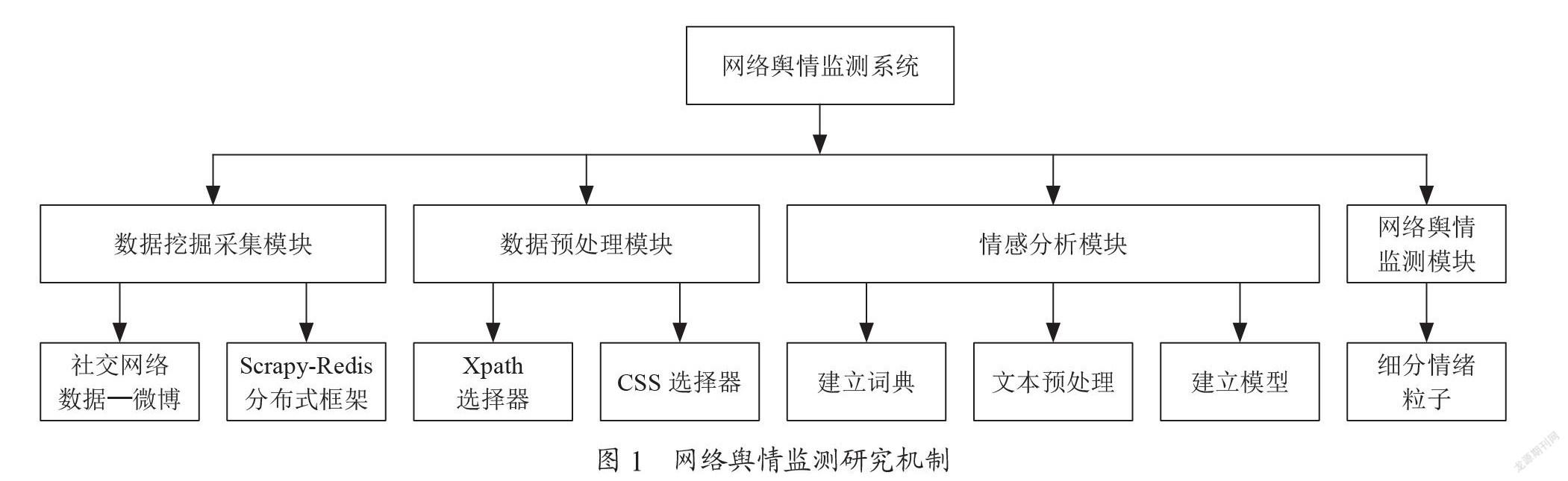
2.4? 系統總體設計
網絡輿情監測系統總體架構,如圖1所示。該設計主要是由以下幾個模塊組成的:數據挖掘采集模塊、數據預處理模塊、情感分析模塊、網絡輿情預測模塊。
2.5? 實驗對象描述
現在的學生使用社交網絡比如微博,貼吧記錄自己的日常以及表達各自的情感,微博和貼吧也是近年來發展比較快的社交網絡,它可以做到信息實時更新與傳播。故選擇它們為主要的研究對象,通過“Scrapy-Redis-Bloomfilter”的分布式爬蟲架構來獲取數據信息,為了保證文本數據的合理性和有效性,我們對其進行了預處理操作,然后采用上述的方法對信息進行情感分析。
2.6? 實驗配置
我們選擇了一臺存儲類型為DDR4 2 400 MHz,硬盤容量為128 GB SSD+2 TB的PC機作為實驗PC。表1詳細說明了PC的配置。
2.7? 監測結果展示
通過對來自新聞、微博、貼吧等相關社交網絡中的有關新疆理工學院的文本類輿情信息進行實時全面監測,并且通過圖片文字識別技術幫助我們進行圖片輿情監測,獲取到的信息更加全面,更加準確。監測到的實時信息如圖2所示。
我們將社交網絡上獲取到的有關新疆理工學院的相關信息數據進行處理分析,數據可視化展示,清楚并且有效地傳達處理輿情信息,如圖3所示。
3? 結? 論
在本文中,我們對高校網絡輿情監測機制進行探索分析和研究。首先,考慮到網絡輿情環境,在可轉移模型有限、種子語料庫不足的情況下,嘗試采用改進的方法區構建情感分析相關的詞典。建立中文分詞詞典。當情感詞典不能直接有效地對文本的深層情感進行分類時,我們可以根據基準的積極情緒和消極情緒進行分類和區分,將情感映射到深層情感,實現間接分類。同時,我們整合了一些優秀的網絡詞匯和情感詞匯,進一步擴展了詞匯語料庫,提高了系統識別的準確性。我們接下來的工作重點將會放在以下幾個方面:在網絡世界中我們經常使用表情符號來表達我們的觀點,但是在數據采集的過程中我們卻人為的沒有考慮這些因素。這是因為不同年齡階段的網友對同一個表情符號的理解是不一樣的,我們無法獲取到準確地信息。我們還會動態持續地改進構建一套“網絡輿情詞典”,畢竟網絡語言更新比較快,不同年齡群體的網絡都有自己的一套網絡習慣用語,而傳統的詞典是不能夠好好去甄別這些詞匯,一套好的詞典是能夠幫助我們提高分詞效率。最后我們需要改進的工作是需要優化網絡爬蟲框架,需適度且適量地增加請求的頻率,進而去提高整體的爬行效率,在前期的工作中我們為了確保爬蟲可以獲取到一些敏感的詞匯信息,我們設計了匿名代理訪問網站的方案,這個在解決問題的同時卻讓我們的數據爬蟲速度降低了,這已成為我們下一個階段關注和解決的重點。
參考文獻:
[1] 李瑋潔.校園網輿情監測平臺與網絡群體演化的研究 [D].北京:北京交通大學,2012.
[2] 賈珊珊.基于規則與模型相結合的中文微博情感分類研究 [D].石家莊:石家莊鐵道大學,2015.
[3] 王世泓.基于情緒詞典擴展技術的中文微博情緒分析 [D].南京:南京航空航天大學,2015.
[4] 馬曉玲,金碧漪,范并思.中文文本情感傾向分析研究 [J].情報資料工作,2013(1):52-56.
[5] 葉翔斌.網絡文本情感分析的研究與實現 [D].長沙:湖南大學,2015.
[6] 宋靜靜.中文短文本情感傾向性分析研究 [D].重慶:重慶理工大學,2013.
[7] 朱儉.基于集成情感成員模型的文本情感分析方法 [J].計算機工程與應用,2014,50(8):211-214.
[8] 孫本旺.漢藏雙語情感詞典構建及情感計算研究 [D].西寧:青海大學,2019.
作者簡介:陳蒙(1991.01—),女,漢族,河南南陽人,講師,碩士研究生,主要研究方向:網絡輿情,數據挖掘。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
