結合雙編碼器與對抗訓練的圖像修復
2021-04-12 05:19:36孫大松張備偉
計算機工程與應用 2021年7期
李 健,孫大松,張備偉
南京財經大學 信息工程學院 教務處,南京 210023
近年來,圖像修復技術逐漸成為計算機圖形學和計算機視覺領域的研究熱點。它是解決如何使用計算機實現圖像的自動修復,以及如何判斷修復結果是否有效的問題,已在文物保護、影視特技制作、虛擬現實等領域得到廣泛應用。傳統圖像修復算法主要有兩種[1]:一是基于紋理的圖像修復[2-6]。這種方法主要是從圖像內部提取小塊(patch)并利用這些小塊補全圖像的破損部分。這種算法善于傳播高頻細節,但無法捕獲圖像的語義或全局結構。故其僅適用于圖像破損區域附近有重復的內容,或者是小而均勻的區域,而面對復雜的圖像或者大面積缺失時無法生成合理的輸出。另一種方法是基于外部搜索的圖像修復。這種方法試圖從大量的同類圖像中提取小塊補全破損部位,但是若沒有很好的相似圖像,修復會出現錯誤,并且由于需要訪問外部數據庫,故該算法的局限性較大因而無法得到廣泛的應用。
以上兩種傳統的圖像修復方法的局限性在于不能很好地理解圖像的語義內容,而隨著深度學習研究的發展,卷積神經網絡(Convolutional Neural Network,CNN)[7-8]的出現使提取圖像的高維特征成為了可能,這些特征有助于生成語義上合理的圖像,從而解決了傳統算法的難題。
文獻[9]提出的上下文編碼器(Context Encoder)算法,是首個利用深度學習在圖像修復領域取得成就的算法,其在大面積缺失的圖像修復問題中有著不錯的效果。它在自動編碼器(Auto Encoder)的基礎上,通過加入生成對抗網絡(GAN)[10]來使生成的圖像更加真實。但是這種方法的輸出不穩定,在修復過程中存在丟失掩模信息的問題,在直接利用掩模覆蓋破損區域圖像時,會產生扭曲或者偽影,也會生成不合理圖像。且修復的區域邊緣比較明顯,全局一致性較低,導致修復結果比較模糊粗糙。Pix2Pix[11]方法通過在生成器中參考U-Net[12]全卷積結構,引入跳躍連接(skip connections),提升圖像的細節效果,將上下文編碼器擴展為具有精細紋理修補的端到端修復方法。但其由于使用反卷積,與上下文編碼器一樣會產生棋盤偽影,且對復雜圖像的修復效果不佳。另外由于受到神經網絡結構的限制,早期的基于神經網絡的圖像修復算法以修復圖像中央的矩形區域為主,且在輸入破損圖像和掩模時采用逐像素相乘的方法,在原圖黑色區域較多的情況下掩模信息容易丟失,難以生成合理的輸出。
針對上述問題,本文在卷積神經網絡和生成對抗網絡基礎上,結合上下文編碼器和Pix2Pix 兩種方法的特點,為了改善破損區域信息丟失問題和實現對任意破損區域的重建,設計了一種結合雙編碼器與對抗訓練的圖像修復算法:首先,給出雙編碼器模型,設計了掩模圖像生成管線和圖像生成管線,通過編碼掩模特征解決上下文編碼器丟失掩模信息的問題,并將掩模信息和圖像信息在通道層面合并后傳播到深層的網絡中,使得神經網絡更容易對破損區域進行優化。其次,在圖像生成管線中引入跳躍連接(skip connections),保留不同分辨率下像素級的細節信息,并通過恒等映射傳播梯度,從而促進生成器對圖像上下文語義內容的學習并加速網絡的收斂。接著根據生成式對抗網絡的思想,結合遷移學習[13],引入對抗訓練設計鑒別器,使圖像的修復結果更加清晰銳利。最后,利用本文算法在數據集和不同掩模形式下進行實驗和測試,從定性和定量的角度與其他算法進行比較,從而驗證該算法的有效性和實用性。
1 雙編碼器模型
本章介紹雙編碼器模型及其原理。雙編碼器模型包括五個部分:圖像編碼器、圖像解碼器、掩模編碼器、掩模解碼器和鑒別器。其中掩模編碼器和掩模解碼器組成了類似于傳統的自動編碼器結構[14]。圖像編碼器、圖像解碼器和鑒別器構成了和上下文編碼器[10]相仿的結構;與后者不同的是,圖像解碼器需要同時讀入圖像特征和掩模特征。除此之外,引入了跳躍連接,將編碼器中的特征圖與解碼后對應的同樣大小的特征圖在通道上進行拼接,且圖像解碼器輸出的是完整圖像而不是僅僅預測缺失的部分。為了提高解碼器的輸出質量,在圖像解碼后添加了鑒別器。綜上所述,雙編碼器模型結構如圖1所示。
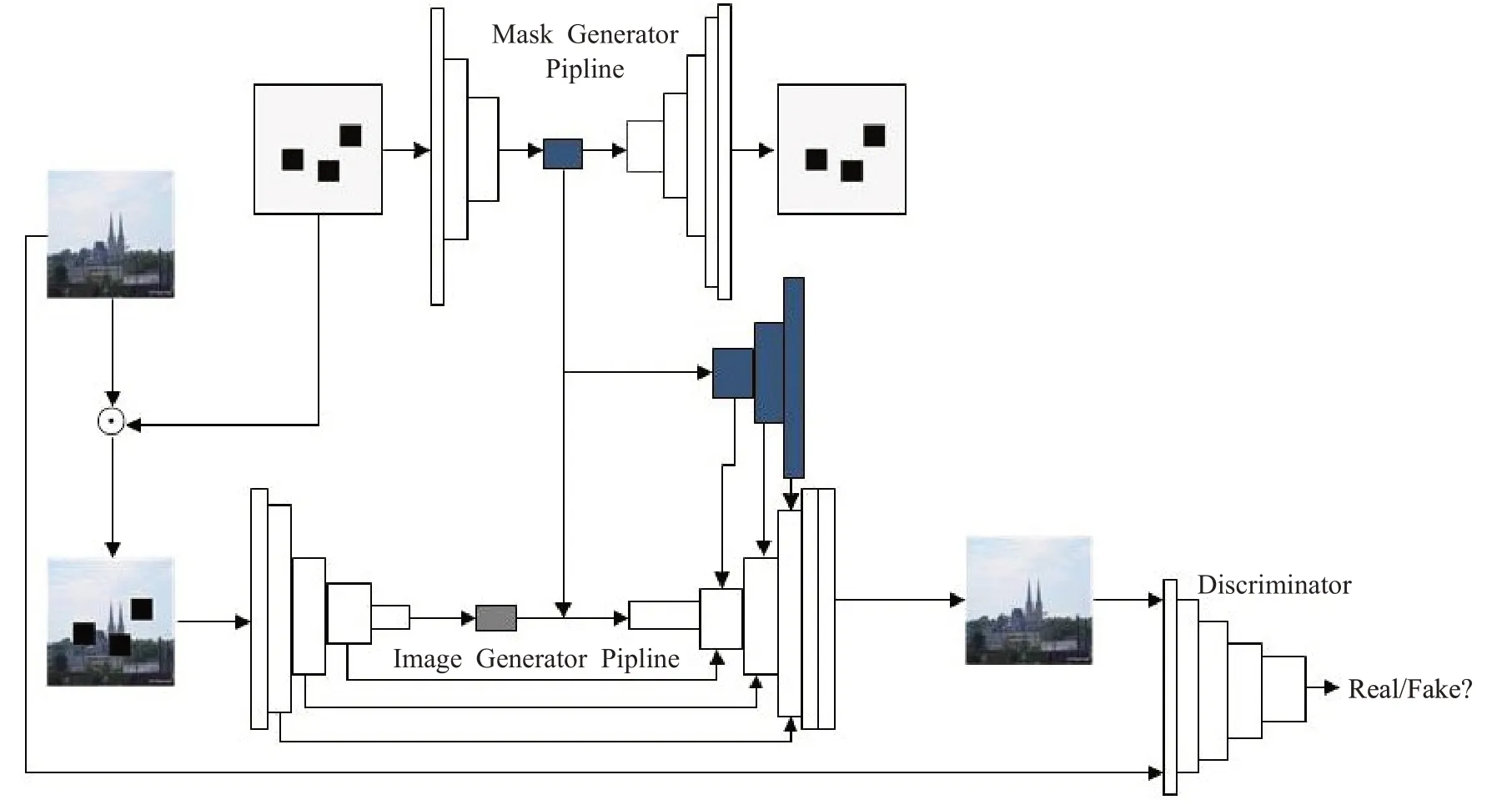
圖1 模型網絡架構
1.1 掩模生成管線
掩模生成管線為一個標準的編碼器-解碼器(encoderdecoder)結構。相對于輸入圖像,掩模僅為單通道的1比特陣列,其數據量較小且特征提取和重建相對容易,不需要額外的鑒別器輔助。掩模編碼器的輸入為單通道的掩模圖像,像素值為0 代表該點圖像缺失,否則為1。因掩模數據量低且沒有高精度需求,故采用3 個步長為2的卷積層和2個池化層對特征圖尺寸進行快速縮減。在特征提取完成后,添加一個全連接層以產生一定程度的空間層面的數據交換。
在實驗中,發現基于反卷積的生成網絡容易形成棋盤偽影。這主要是因為反卷積容易產生不均等重疊,特別是在卷積核不能被步長整除的情況下[15]。為了解決棋盤偽影的問題,掩模解碼器通過堆疊上采樣-卷積[16]結構重建掩模圖像。“上采樣-卷積”方法先對輸出圖像使用插值算法上采樣,再對上采樣后的圖像進行卷積,實現了和反卷積類似的效果。通過比較反卷積在解碼器上的實現,上采樣-卷積可以有效地解決棋盤偽影的問題,故在圖像生成管線的解碼器中也使用上采樣-卷積代替反卷積。上采樣后的卷積將特征傳播到周圍像素,實現了特征的重構。每個上采樣-卷積結構使圖像尺寸變為原來的兩倍,同時通道數量有一定程度的降低。通過5 層這樣的網絡將編碼器輸出的特征圖還原為單通道的掩模圖像。通過掩模生成管線可以生成單獨的掩模特征信息,在接下來的操作中與圖像特征信息一起輸入到圖像生成管線,從而改善了圖像修復過程中掩模特征丟失的問題。掩模生成器的體系結構如表1所示,從左至右依次為網絡層類型(Conv為卷積層,Pooling為最大池化層,UP-Conv 為上采樣-卷積,Interpolate 為上采樣)、輸入(寬×高×通道數)、卷積核、步長和輸出。
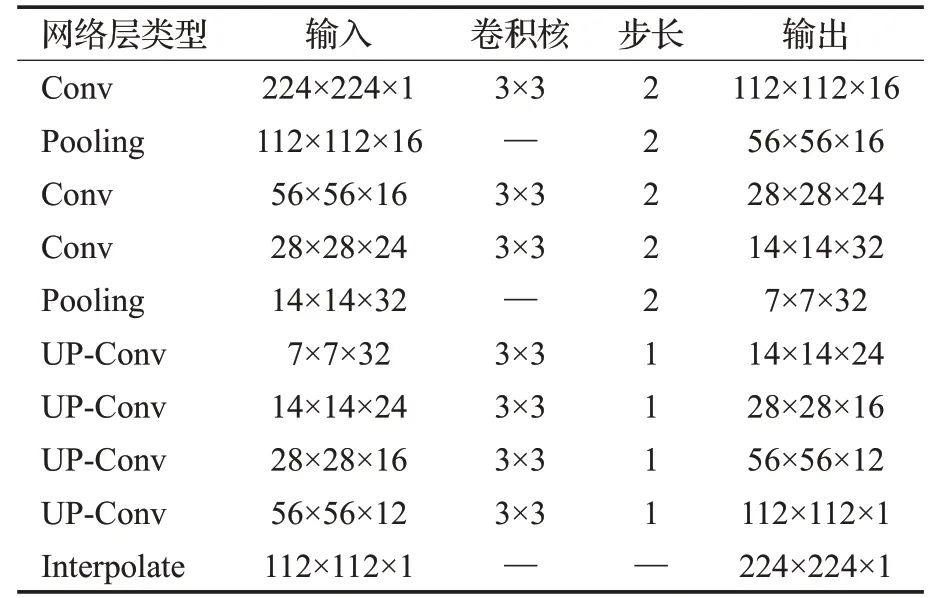
表1 掩模生成管線體系結構
1.2 圖像生成管線
原始圖像為3通道的RGB圖像,通過將其逐通道與掩模進行乘法操作得到破損圖像,然后輸入圖像編碼器。為了讓神經網絡掌握原始圖像的全貌,從而提取更高層次的特征,需要擴大神經網絡的感受野。故本文使用了深層的卷積網絡,且引入了跳躍連接,同時使用膨脹卷積來有效地避免擴大卷積核導致的參數增多。在生成管線中采用了全卷積結構,未使用池化層從而簡化模型并減少數據的損失。
圖像編碼器通過多層次的卷積網絡來提取圖像詳細的語義特征信息。在每個卷積模塊后添加了一個批量標準化層以提高網絡的穩定性并加速收斂。為了實現層間信息的傳播,在通常的網絡結構中會添加全連接層。與通常的全連接和上下文編碼器中使用的逐通道全連接層不同,本文設置了一個基于組的全連接層。這種全連接層可以在連接多個特征圖時減少參數的數量且避免不必要的空間浪費,實現參數數量和靈活性的平衡。
圖像解碼器具有相對較為復雜的結構。解碼器需要同時輸入圖像的特征圖和掩模的特征圖,并根據這些特征圖重建完整的圖像。相較于前文提到的圖像修復算法將掩模和圖像信息同時傳播的方法,本文使用2個上采樣管道同時重建圖像和掩模,其中,掩模的上采樣管道包含3個上采樣模塊,每個上采樣模塊包含一個上采樣-卷積結構和一個批量標準化層。圖像的上采樣管道則包含6 個上采樣模塊。重建的掩模和圖像在通道層面疊加以輔助后續的修復工作。
在圖像生成管線中設計skip connections,將圖像編碼器中的特征圖與經過解碼之后相同大小的對應特征圖按照通道進行拼接,重用通過恒等映射傳遞的特征,從而對因編碼器下采樣而損失的圖像信息特征進行補充,強化生成器的結構預測能力[17],從而進一步提升生成圖像的細節。由于繞開了模型中間的非線性激活層,skip connections避免了梯度的消失,提高了圖像生成管線的學習能力并加速網絡的收斂。此外,也顯著擴大了網絡的深度[18],增強網絡的表達能力。
圖像生成管線的體系結構如表2所示,從左至右依次為網絡層類型(其中Conv為卷積層,D-conv為膨脹卷積層,UP-conv為上采樣-卷積)、輸入(寬×高×通道數)、卷積核、步長、膨脹系數和輸出。
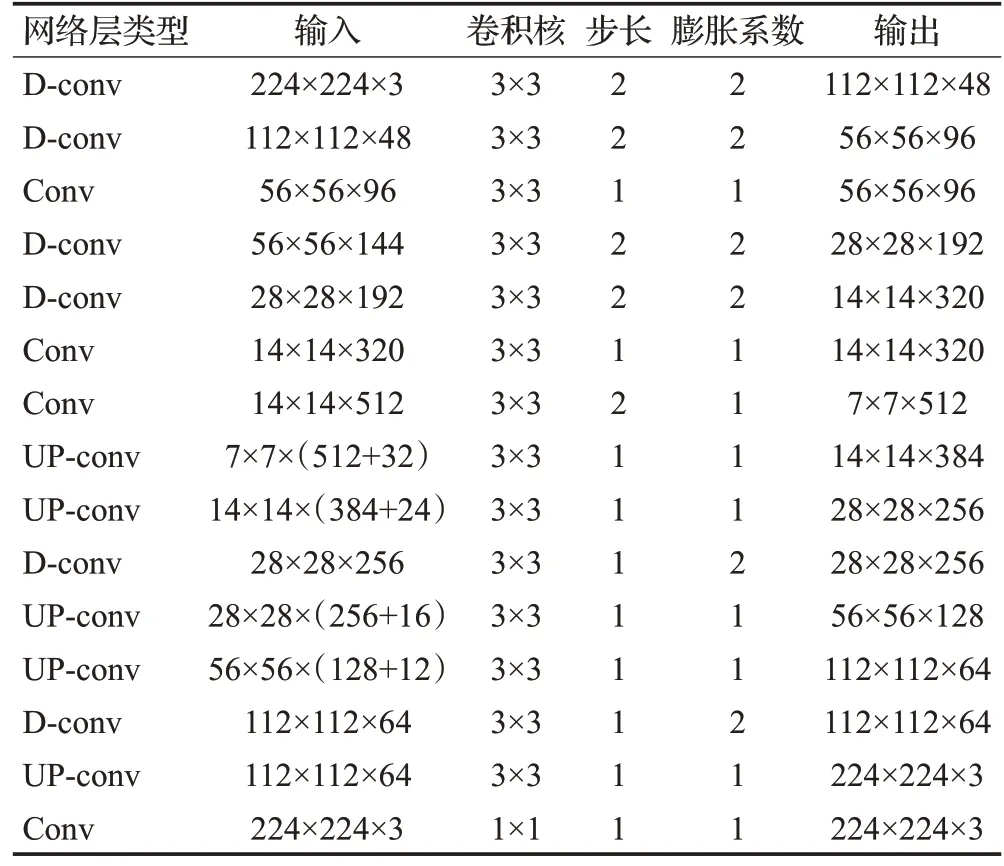
表2 圖像生成管線體系結構
1.3 鑒別器
為提高重建圖像質量,本文根據生成式對抗網絡思想,設計對抗訓練鑒別器。由于該鑒別器僅需要完成特征提取和分類任務,為了降低訓練成本,這里使用了遷移學習。對ResNet18[18]進行微調(Fine-Tuning),實現鑒別器的特征提取。ResNet18的輸出為1 000維的特征向量,使用全連接層將它映射到一個神經節點上并使用sigmoid激活函數限制輸出值域。鑒別器網絡體系結構如表3所示,從左到右依次為網絡層結構、卷積核、步長和輸出。

表3 鑒別器體系結構
1.4 損失函數
在圖像生成管線中,使用重構建損失來規范重建過程中的行為,使重建結果更具結構性且與周圍的信息一致。這里定義重建損失為真實圖片和生成圖片的L2 損失。記原始圖片為y,經過掩模處理后的破損圖片為x,圖像生成管線用G表示,則修復結果可以表示為G(x)。那么重構建損失Lrec可以表示為:

L2 損失用于修復缺失低頻信息的圖像,由于其缺乏高頻細節,會導致修復結果不可避免的模糊。因此,為了提高圖像的高頻細節的質量并使圖像更加清晰,在使用重構建損失外,根據生成式對抗網絡GAN[10]的思想,在模型中加入了鑒別器,從而引入了對抗損失。對抗損失可以促進網絡生成更加清晰的圖像。公式(2)定義了生成式對抗網絡的損失函數。若將圖像生成管線的編碼器-解碼器模型看作GAN 的生成器,則G與D可以組成GAN。GAN 的原理類似于一個博弈(gametheoretic)的過程,在這個過程中,生成器和鑒別器交替的進行梯度下降和梯度上升。
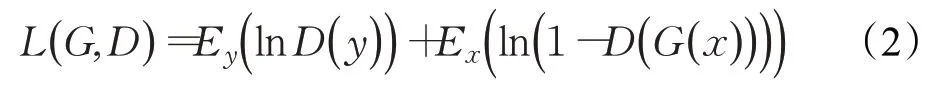
其中D(?)代表鑒別器,G(?)代表生成器。
在實際操作中,為了易于實現,生成器的損失函數參考了GAN 的作者提供的第二種方式[10],并用其作為生成器的對抗損失函數:

公式(3)可以理解為要生成輸入鑒別器后輸出一個較大概率的數據,對于生成器來說ln(D(G(x)))越大越好。
對抗損失可以提高圖片的真實性,重構建損失用于判斷生成圖片與真實圖片的語義差異,故生成器采用由重建損失和對抗損失組成的聯合損失進行訓練:
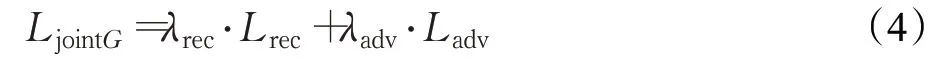
鑒別器損失函數則根據公式(2),分別采用0和1標簽對修復后的圖片和真實圖片進行損失計算:
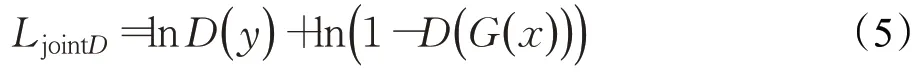
在本實驗中通過計算LjointG和LjointD,更新編碼器解碼器及鑒別器參數不斷優化直至達到收斂。
2 模型訓練
雙編碼器模型由5個模塊組成,各個模塊復雜度不同收斂速度也不一致。因此,這里分為兩部分進行訓練。由于圖像重建不依賴掩模重建但需要穩定和高效的掩模編碼設施,故首先訓練掩模編碼器和解碼器;訓練完成后固定掩模編碼器的參數,利用掩模編碼器為圖像重建管線提供掩模特征。
圖像重建管線由圖像編碼器、圖像解碼器和鑒別器構成,前兩者構成自動編碼器,自動編碼器又可作為生成器和鑒別器組成GAN。其訓練流程如下:
1.讀取圖像y,生成掩模M,破損圖像x=M?y(?為點乘);
2.掩模編碼器對M編碼,得到特征向量Fm;
3.圖像編碼器對x編碼,得到特征向量Fx;
4.圖像解碼器基于Fm和Fx生成重建圖像xr;
5.計算xr和y的重構建損失Lrec,優化編碼器和解碼器;
6.使用xr和假標簽、y和真實標簽分別計算鑒別器對生成的修復圖片和原圖的損失LjointD并更新鑒別器參數;
7.重復步驟1~4,得到重建圖像x"r;
9.重復上述步驟至訓練結束
在訓練中設計兩種掩模形式,一是將圖像中心的112×112區域作為掩模;二是采用動態生成的掩模,在圖像的192×192區域內隨機生成并填充3個32×32的矩形作為掩模。為了提高破損部分對整體的影響,在計算損失前對原始圖像和重建圖像處于掩模外的區域進行降低亮度的處理(如圖2 所示)。該處理通過將圖像和反轉掩模逐像素相乘實現,這里反轉掩模的定義如下:

其中m為原始掩模,k為系數。實驗表明,在k=1.5的情況下,破損區域對整體的影響比例從6%提高到了17.1%。

圖2 反轉掩模處理
為了提高訓練效率,這里使用Adam 優化器[19]對網絡參數進行調整。Adam根據對梯度的一階矩和二階矩估計,動態地調整學習率,相較于隨機梯度下降(SGD)等優化算法,使用Adam優化的網絡收斂更快。由于模型較為復雜且各模塊有不同的復雜度,本文采用的訓練參數如表4所示。
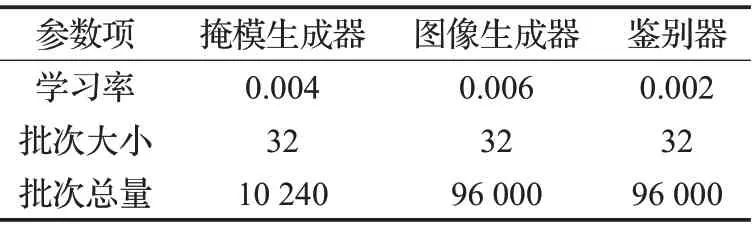
表4 訓練參數
本文使用pytorch1.0 深度學習模型框架進行實驗,運算設備為GTX 965M,對應CUDA版本為9.0,cuDNN版本為7.5。使用places2 數據集進行訓練和測試。places2 是一個場景圖像數據集,從中隨機抽取80 000張圖像用于訓練,10 000張用于測試。為滿足遷移學習中使用的ResNet18輸入要求且在一定程度上降低運算量,測試圖片統一縮放至224×224,圖片中心的112×112的區域為掩模。整個模型的訓練完成時間約4天左右。
3 實驗結果與分析
如圖3為定性評估,將本文方法分別與自動編碼器(Auto Encoders,AE)方法、深度卷積生成對抗網絡(Deep Convolutional Generative Adversarial Network,DCGAN)[20]、上下文編碼器(Context Encoder,CE)以及Pix2Pix圖像修復算法進行比較。在相同迭代次數下訓練模型后,不同方法在places2 數據集上的修復結果如圖3所示。

圖3 不同方法的修復結果
第一列圖(a)分別對應著未添加掩模的原始圖像。第二列圖(b)為添加了掩模的缺損圖像。第三列圖(c)為自動編碼器的修復結果,可以看出這種方法的修復結果很粗糙,效果很不好。這是因為自動編碼器并不是在真正地學習如何重建圖像,而是僅通過逐像素地比較原圖和重建圖像的重構建損失來優化修復結果,且重構建損失并不能保證降到最低。第四列圖(d)為DCGAN的修復結果,這種方法相比于自動編碼器添加了對抗訓練,因而其圖像修復質量相對有了提高,但是修復內容的細節依然比較粗糙。第五列圖(e)為上下文編碼器的修復結果,這種方法結合了前兩者的優點,但全局一致性不高,且修復語義內容不夠準確,同樣缺乏細節信息。第六列圖(f)為Pix2Pix圖像修復算法的修復結果,由于借鑒U-Net網絡引入了skip connections,修復部分的細節相比于上下文編碼器有了明顯提高。該方法與上下文編碼器相似,在實驗中會產生一定的扭曲或者偽影,這是由于使用反卷積而造成的。最后一列圖(g)為本文的方法,由于結合前面幾種方法的優點,并對掩模進行單獨的編碼,很好地改善了掩模信息和圖像信息的損失問題,同時將反卷積替換為上采樣-卷積,圖像修復的結果更加細膩平滑,減輕了偽影現象,且圖像的整體更加一致。
理論上,本文算法可以對任意尺寸和任意形狀的掩模進行修復。受局部卷積[21]的啟發,本文采用了動態掩模并進行了實驗,為了降低模型的復雜度,本文簡化了掩模的形式。在224×224 的圖像中央192×192 的區域內,隨機生成并填充3 個32×32 大小的矩形作為掩模。矩形的部分完全重疊被視為合理的情況,因為這種情況下掩模尺寸降低同時復雜度提高。圖像的修復結果如圖4所示,可以看出本文模型在不同動態掩模的修復上也有不錯的效果。

圖4 動態掩模的修復結果
以上為視覺方面的定性評估,在定量評估方面,采用了峰值信噪比(PSNR)和結構相似性指數(SSIM)[22]評估重建后的圖像。二者公式如下:
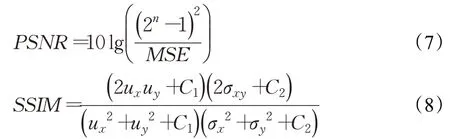
其中MSE為修復圖像與原始圖像的均方差,ux和uy為均值,σx和σy為方差,σxy為協方差;C1=(k1L)2,C2=(k2L)2,L為像素動態范圍,當圖像深度為8 bit 時,L=255,k1和k2通常具有默認值0.01和0.03。
PSNR 和圖像間的均方差直接相關,用于評價圖片的高頻細節,其值越大,表明圖像的失真越小。SSIM的取值在0 到1 之間,其值越大說明修復后的圖片與真實圖片的差值越小,即修復的效果越好。
對于掩模生成器,隨機生成了500 張掩模,使用掩模編碼器和解碼器進行重建,其平均PNSR為32.15 dB,SSIM為0.913。
不同算法在places2數據集上的表現,如表5所示。

表5 算法定量比較
從表5中可以看出,本文算法引入對抗訓練從而顯著提升圖像細節,通過雙編碼器結構有效減少了掩模信息的損失,PSNR值相對于前面幾種算法有了明顯提高,同時通過跳躍連接改善圖像信息特征的損失問題,促進了模型對圖像的整體結構的預測,改善了圖像的結構性,故SSIM值也比較大。
4 結論
本文討論了一種結合雙編碼器與對抗訓練的圖像修復算法。通過設計掩模編碼器和圖像編碼器分別對掩模和圖像進行編碼,將掩模特征向量和圖像特征向量同時輸入圖像解碼器中,解決了掩模信息丟失問題,實現對任意破損區域的修復。在圖像生成管線中使用跳躍連接促進圖像語義特征的深層傳播,減少因下采樣造成的圖像信息損失,強化圖像的整體結構性并提升模型的訓練速度加快收斂。同時結合生成式對抗網絡設計一個鑒別器,通過對抗訓練優化模型,進一步提高圖像的細節和修復效果。最后在不同的數據集上對該算法的網絡模型進行了訓練和測試,并與其他算法進行了比較。實驗結果表明,本文算法修復結果更為準確,整體效果更好。下一步的工作是解決圖像修復過程中由于特征在樣本中出現頻率較低而導致的特征丟失問題,進一步完善圖像修復模型,提高模型的運行效率。
