高鐵車廂內RTM語言清晰度預測及優化
2021-04-17 02:02:54張學飛王瑞乾儲麗霞
噪聲與振動控制 2021年2期
季 杰,張學飛,王瑞乾,儲麗霞
(1.常州大學 城市軌道交通學院,江蘇 常州213100;2.常州西南交通大學 軌道交通研究院,江蘇 常州213164)
隨著目前高速列車運行速度的持續提升,列車車內的聲環境惡化[1-2],車內噪聲環境首先對乘客的乘車體驗感造成極大的影響,其次還會降低車內乘客間交流的言語清晰程度[3],并且還會對乘客接收車內語音廣播系統播報信息的準確程度造成干擾,因此有必要對車內語言清晰度進行研究并優化。在如今計算機技術高速發展的年代,基于幾何聲學開發的一些室內聲場預測方法已經達到應用水平,其中聲線跟蹤法由于其高精度及高效率已經在聲場預測領域得到了較為廣泛的應用,能夠較高效地對聲粒子在聲場環境中的傳播情況進行較好預測,故本文使用聲線跟蹤法對高鐵車廂內的語言清晰度進行預測。
1 理論背景
1.1 聲線跟蹤法
聲線跟蹤法(Ray Tracing Method,以下簡稱RTM)是室內聲場計算的常用方法之一,假設聲音以聲粒子形式沿直線傳播,且不考慮其在空間內傳播的波動性,另外在可以反射或者衍射的聲場空間內,將聲源發出的聲粒子與聲場空間內壁面的碰撞點相連便是聲線。目前為止已經有很多在混響聲場和長封閉空間聲場中使用聲線跟蹤法進行聲場預測的例子:Jang 等在長空間的SEA模型中采用GESEA與RTM 相結合的方法成功預測聲音傳輸情況[4];蔣忠進等使用RTM 根據聲音傳播的機理計算接收球半徑及聲線密度,對封閉聲場空間進行預測[5];蔡銘等通過對室內聲場進行剖分并且結合RTM 顯著提高計算效率[6]。
在整節列車車廂的模型中,先在各個揚聲器位置上放置合適的聲源,然后從聲源發出一根聲線,求出與車廂內反射面的碰撞點,基于Snell 或Lambert定律形成反射折射之后判斷聲線是否經過車廂內接收能量的傳感器,若未經過則接著求反射聲線,若經過傳感器便記錄聲線能量及傳播時間等數據,并判斷聲線能量是否低于事先設定的閾值,若高于則返回繼續計算該聲線,反之則停止運算并同時發出下一條聲線,隨之開始計算該點的平均脈沖響應,整個流程圖如圖1所示。
本文通過RTM確定合適的聲線密度、接收點半徑及體積,并疊加聲線傳播能量,得出傳感器最終接收到的聲壓級。初始聲線密度的影響因素包括聲源發出的初始聲線數目、聲場空間體積、反射面吸聲系數;另外傳感器的接收點半徑及體積大小會對聲線傳播能量誤差及聲線丟失數量有影響,導致預測精度降低[7]。聲線跟蹤法優點為計算效率高、計算速度快、且較容易被計算機實現,但是計算精度略差并且對低頻段的預測有一定誤差。
1.2 聲線跟蹤法計算車內聲壓級
在RTM 中通過前處理設置聲源發出的總聲線數目得出聲源的初始聲功率,通過聲源發出的初始聲功率L和初始聲線數量n來計算初始聲線Ln,公式如下:
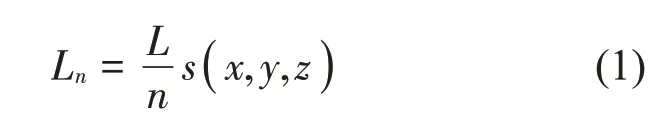
式中:聲源發出的聲線初始傳播路徑為s(x,y,z),傳感器的接收半徑關系式如下:
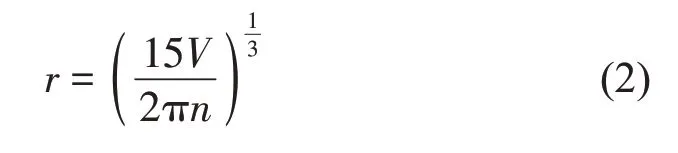
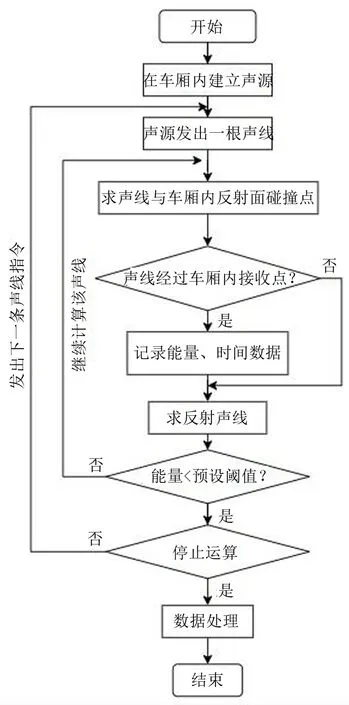
圖1 車廂內部聲線跟蹤法預測流程圖
式中:V為室內聲場環境的總體積,通過傳感器測得各個測點的脈沖響應。
在車內聲場空間使用RTM預測時,根據傳播時間及聲能量計算出車內的聲壓級,公式如下[8]:

式中:根據各個聲線的傳播時間對聲強進行排序、疊加,得出傳感器的脈沖響應In(x,y,z),根據脈沖響應計算出車內聲場的聲壓級,其中ρ0c0表示高鐵車廂內空氣阻抗,一般取為400 kg/(m2s),將ρ0c0值代入式(3)得出:
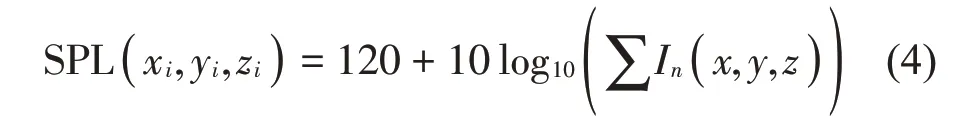
1.3 語言清晰度計算
本文基于RTM 對列車車內聲場空間進行仿真預測分析,研究高鐵車廂內廣播系統揚聲器位置和數目對車內語言清晰度的影響。依據國際標準“IEC60268-16(4.0 版,2011-06)”[9]預測車內語言清晰度,該標準在經歷4次修訂后更完整成熟。Houtgast 等將聲音傳輸系統中的調制轉移函數(Modulation Transfer Function,MTF)概念引入到計算語言傳輸指數(STI)中[10],其計算示意圖如圖2[11]所示。目前推薦的STI 測量方法有兩種,分別是基于采集調制信號的直接法和基于收集脈沖響應信號的間接法,本文使用間接法測量。

圖2 調制轉移函數示意圖
在STI 計算過程中信噪比也較為重要,根據接收到的脈沖響應信號計算出調制轉移函數m(F)=m0/mi,其中m取值為0~1,隨后將MTF 轉化為信噪比,公式如下:

根據信噪比再將數據轉化成中間傳遞指數TI:

傳遞指數TIy,z由一個頻率調制某個頻帶得出,將這個頻帶在0.63 kHz~12.5 kHz 內用14個以1/3倍頻程為間隔的頻率調制成TIy,欲得到語言傳遞指數,需要對125 Hz~8 000 Hz 之間7個頻帶的TIy求平均,最后根據不同頻帶下的清晰度指數計權,計算出車內語言傳遞指數,公式如下:
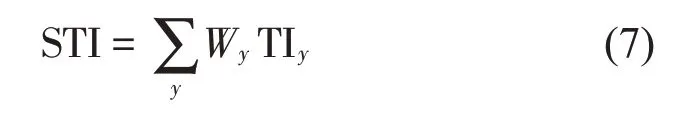
STI間接測量法流程圖如圖3所示。
2 模型驗證與預測結果優化
2.1 RTM仿真模型驗證
統計能量法(SEA)與聲線跟蹤法(RTM)均適用于中高頻噪聲,為驗證本文RTM的正確性,將SEA與RTM及實驗室試驗結合進行方法驗證。
先在VA One中建立預測模型聲腔,其中發聲室尺寸為5.4 m×4.1 m×3.3 m,接收室尺寸為4.5 m×4.2 m×3.3 m,將尺寸為985 mm×970 mm×8 mm的鋼板放置于兩聲腔之間,聲源位于左側聲腔,計算頻率為100 Hz~8 000 Hz,聲波速為343 m/s,阻尼損耗因子為0.1%,聲腔內流體為空氣,聲源布置及測點布置與實際試驗一致,進行RTM 仿真驗證及SEA 驗證,模型及試驗布置如圖4所示。由于模型是爆炸視圖,所以部分傳感器及聲源顯示在聲腔外部。
VA One中可以設置自動聲線數目,故在驗證模型中采用自動聲線數來進行模型驗證,分析完成后自動生成34 677條聲線。
驗證結果如圖5所示。基于3種方法的聲壓級變化趨于一致,隨著頻率升高聲壓級緩慢降低,并在2 000 Hz左右出現吸收峰值,由于統計能量法不適用于低頻,并且在較小模型中聲波長度接近或大于聲腔尺寸,故聲線跟蹤法低頻誤差略大,因此這兩種仿真方法不能精確計算低頻聲壓級,1 250 Hz~6 000 Hz 之間的聲壓級誤差均小于8 dB,在中高頻段驗證誤差較小,結果可信,故本文中基于RTM模型的計算方法是有效的。

圖3 STI間接測量法流程示意圖
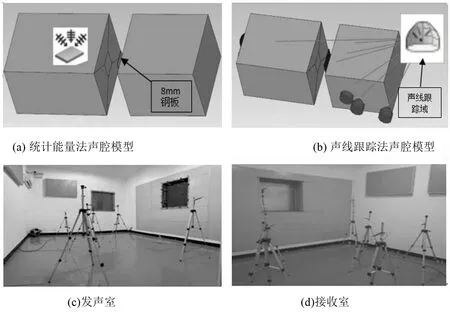
圖4 模型圖及試驗圖
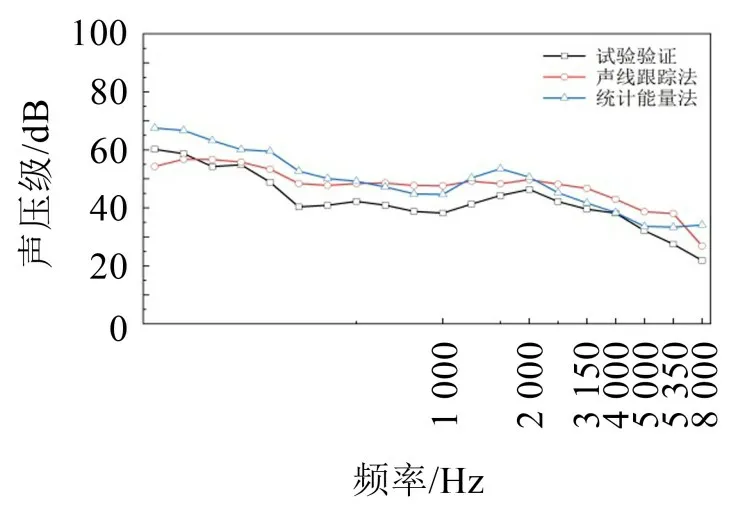
圖5 驗證結果圖
2.2 高速列車模型
驗證完成后在VA One中建立高鐵車廂模型,模型分為車頂、側墻、地板、端墻、座椅、車窗等區域,模型由15 849個節點、644個板單元及231個聲腔構成,使用幾何聲學中的RTM并結合列車車內語言清晰度進行研究。為能夠正確地模擬真實環境,在列車模型內揚聲器位置通過布置球狀聲源來模擬列車廣播系統播報的情況,并將傳感器設置到乘客所處位置,用來模擬乘客接收到的聲信號,以此來對高鐵車廂內語言清晰度進行預測研究并優化。用每個聲線跟蹤計算聲源傳播到RTD傳感器(Ray tracing domain 聲線跟蹤域傳感器,以下簡稱RTD 傳感器)的聲場,計算得出的STI 數值能夠較為準確地預測及評價車內語言清晰度,并且在提高語言清晰度的同時STI 呈現出單調遞增的趨勢[12-13]。在整個模型空間內建立合適的聲線跟蹤域,借助RTM建模形成聲場內部或外部的聲學流體子系統,并將聲線跟蹤域連接到模型內所有的聲源、反射面及各個指定坐標點的RTD傳感器,所建立的模型連接聲線跟蹤域后如圖6所示。將車廂內部聲腔的流體設置為空氣,由于車內空氣流體的內部損耗因子較低,故將聲衰減系數設置為0.1,車廂內地板鋪設地毯,座椅及車廂內部側墻頂板的擴散系數設置為1 %。由于VA One 軟件支持聲線識別模型空間,故分析前聲線數目設置為自動設置,模型內子系統能夠進行的反射數與衍射數分別設為5,分析語言清晰度過程中聲線通過模型內部連接面進行反射、折射并且反射面各元素之間的最大角度設為15°,連接面類型設置為Reflecting,根據模型內部空間大小及傳感器的位置、數目等多方面因素,設置傳感器的接收半徑為0.03 m,以便傳感器更精確地接收聲信號,模型的爆炸視圖如圖7所示。

圖6 車廂聲線跟蹤域連接模型

圖7 車廂模型爆炸視圖
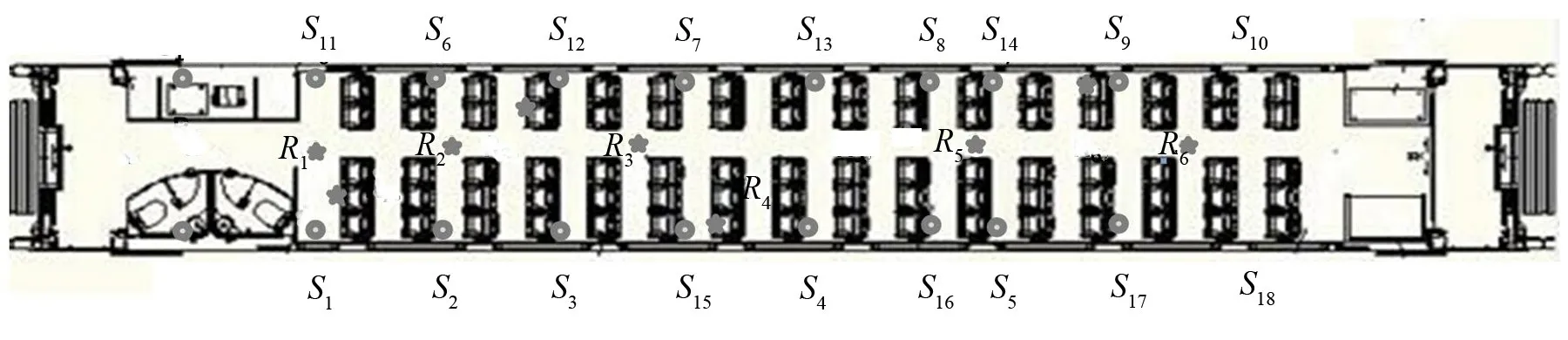
圖8 基于車廂內部聲線跟蹤法預測的聲源、傳感器測點分布圖
2.3 聲源及傳感器的布置
本文使用聲線跟蹤法預測的對象是某型高速列車的單節車廂,使用VA One軟件進行建模該型高速列車內部尺寸為:長17.6 m,寬2.9 m,高2.2 m。車內聲源S1~S18位于車廂內部18個廣播系統揚聲器處,使用聲線跟蹤法來模擬車內語言廣播系統的聲傳遞,模型內設置的球狀聲源是用于公共廣播的揚聲器聲源(Compact acoustic sources 緊湊球型聲源,以下簡稱CAS聲源),距離車內地板高度均為1.6 m,用來模擬車廂內部公共廣播揚聲器的發聲效果;傳感器設置在距離地板高度為1.2 m的所有座椅處及1.5 m高的過道中,模擬乘客在坐姿及站姿情況下人耳所處位置。聲源、6個特殊位置傳感器布置圖(左側為車頭部位)如圖8所示。
2.4 預測結果
在使用RTM進行仿真預測的過程中,調用10個聲源S1~S10對模型先進行穩態分析,仿真完成后自動生成114 137條聲線,并得到RTD 傳感器處125 Hz~12 500 Hz頻率范圍內的聲壓級,各個頻率下車內聲壓級云圖,如圖9所示。
由圖可見,中低頻情況下車廂內聲壓級較高,且隨著頻率升高聲壓級減小,另外從總值來看車廂中部及左側3 排座位處聲壓級較高,可以初步說明位于左側的乘客接收聲信號效果比右側好,且車廂后部區域存在盲區,聲壓級接收不全面,有待改進。
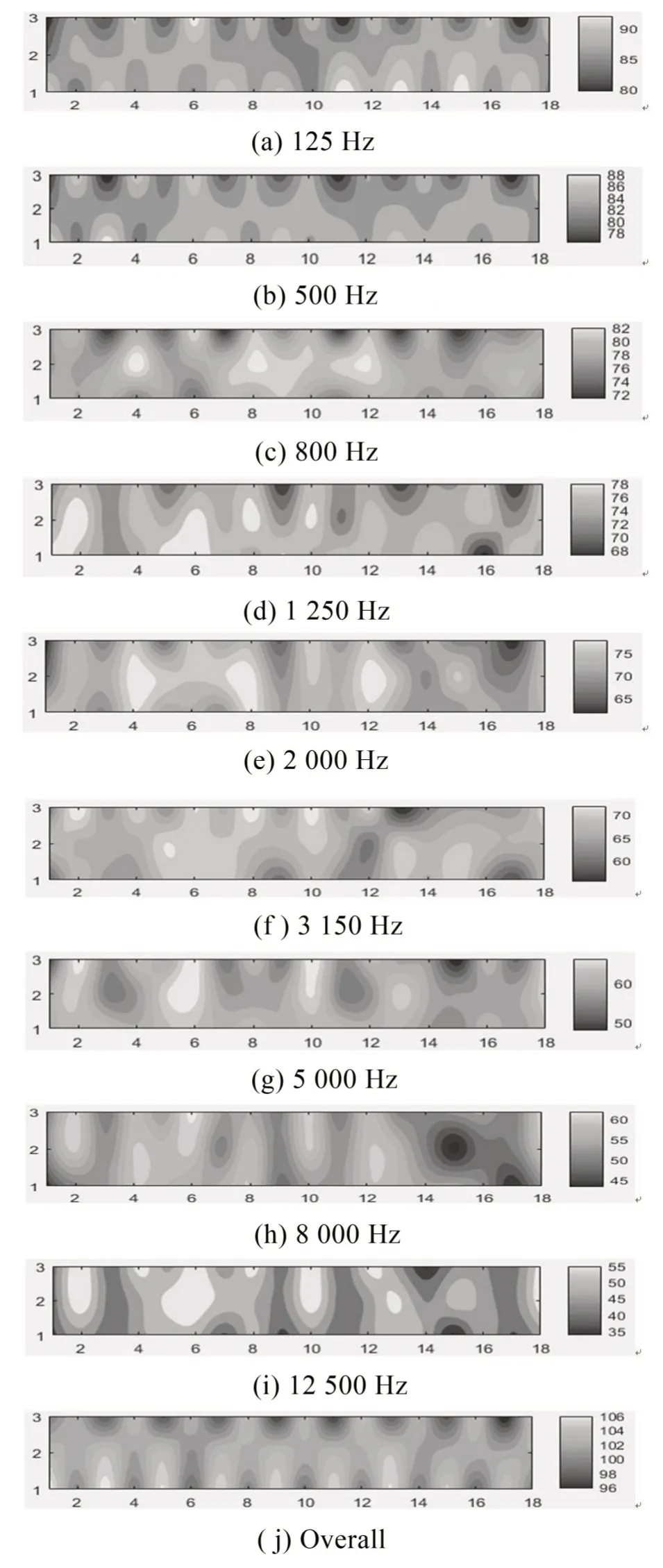
圖9 車內聲壓級分布云圖
隨后,通過測出的聲壓級值得出脈沖響應信號,進行語言清晰度分析計算,分別模擬從聲源發出男女聲的聲線,自動生成的聲線數為645 896,對傳感器測得的數據加權求出平均值,根據距離依次畫出STI值的折線圖,如圖10所示。
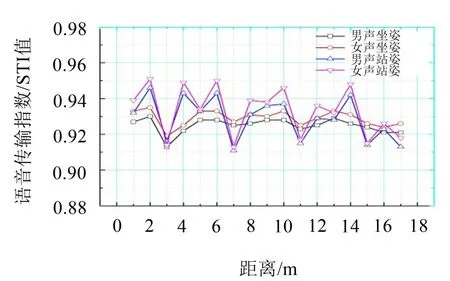
圖10 男女聲站、坐姿STI值對比圖
從圖中得出距離車頭3米處STI值略差,車廂頭部及中部的STI值趨于穩定并較為良好,列車尾部STI值具有隨距離增加而下降的趨勢,總體來看女聲在同樣的情況下比男聲預測效果更好,并且在同樣情況下站姿較坐姿語言清晰度更好,且女聲依舊比男聲效果好,建議使用女聲進行語音播報。
在預測車內語言清晰度過程中,還采用T30 指標作為參考系數,其數值越低語言清晰程度越好。仿真過程中車內測點數目較多,故采用6個特殊位置的測點R1~R6進行125 Hz~8 000 Hz的信號采集,如圖8所示。從表1可得,車廂中后部語言清晰度效果略差,并且各個測點處低頻率的T30值較高,語言清晰度有待提高。
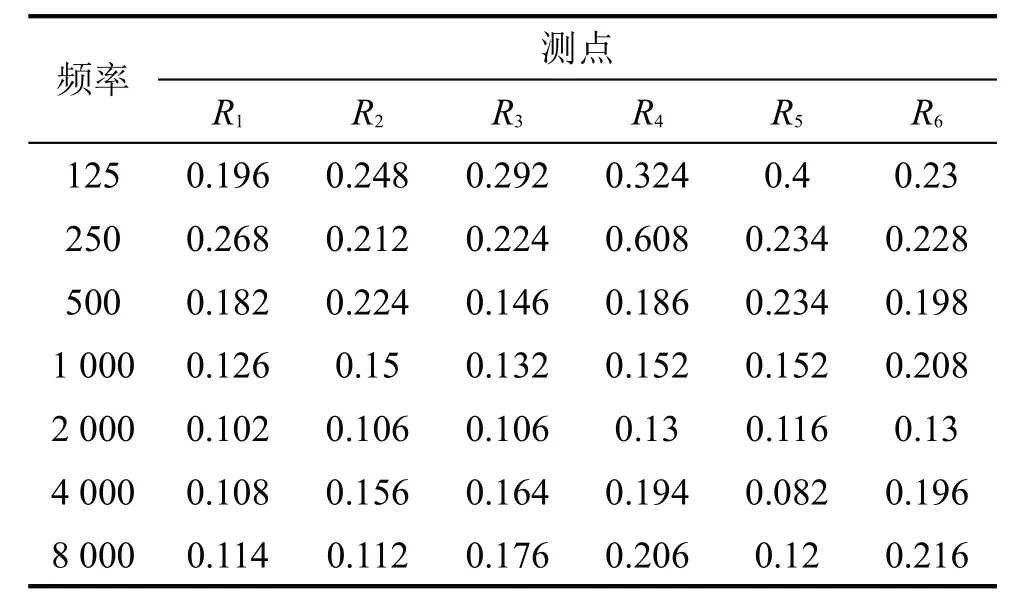
表1 T30仿真結果/S
2.5 優化結果
在進行仿真預測后,文中還進行了一定的優化改進,將車廂內CAS 聲源數目提升至12、14、16、18個(S1~S18),分別進行男女聲仿真預測,如圖8所示。發現并不是聲源數目越多STI值越高,語言清晰度的好壞程度與聲源數目沒有線性關系。其中在使用女聲進行預測時,在將聲源數目提升至14個的情況下,車內各個位置的STI值都較為穩定,并且不存在清晰度較差的盲區,效果較好,如圖11所示。而對男聲進行預測時,聲源數目增長后清晰度反而不會提高,如圖12所示。綜合最初預測結果得出使用女聲進行語言播報的效果較好。
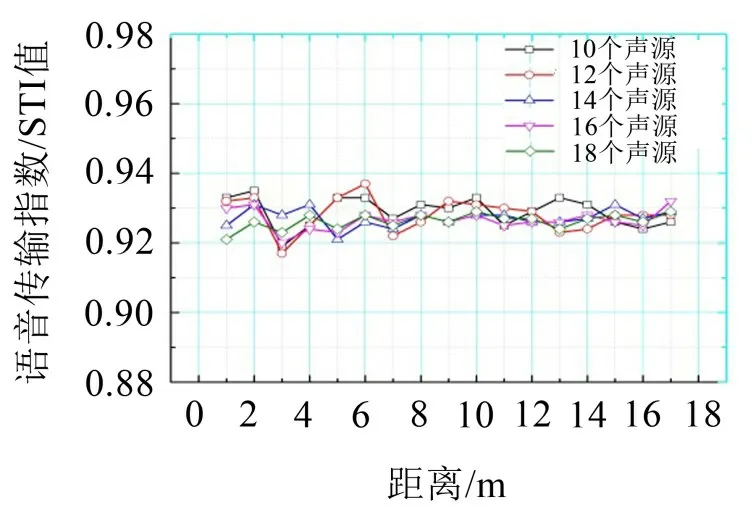
圖11 女聲聲源STI值優化對比圖
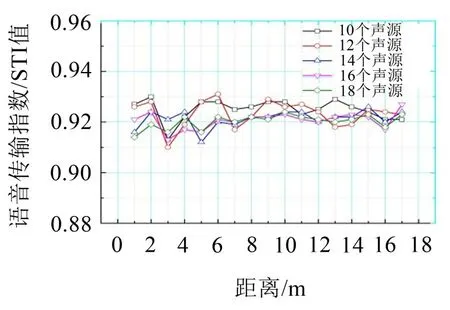
圖12 男聲聲源STI值優化對比圖
3 結語
本文先采用聲線跟蹤法(RTM)與統計能量法(SEA)及試驗進行對比驗證,證明聲線跟蹤法的正確性與準確性,并基于RTM 利用最新的STI 國際測量標準對車內語言清晰度進行預測及簡單優化,能夠得出以下結論:
(1)建立一種通過使用聲線跟蹤法預測高鐵車廂內語言清晰度的模型,對車內聲壓級、語言傳輸指數STI、混響時間T30 指標進行預測研究,發現車廂內部靠近轉向架區域語言清晰度效果略差,車廂頭部及中部的語言清晰度良好;
(2)對于車內廣播系統,使用女聲效果好于男聲,且較男聲而言,女聲更不容易被干擾,建議使用女聲進行廣播系統播報;
(3)基于預測得出的結果,改變聲源數目及部分聲源位置對高鐵車廂內語言清晰度有改進效果,但聲源數目與語言清晰度并不呈線性關系,而需采用合適的聲源數目及位置。在聲源數目為14個并采用女聲進行播報時車內各處的STI值都較為穩定并且不存在清晰度較差的盲區。本文對改善乘客乘車體驗及舒適度有一定的參考價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
