融合了K近鄰與密度峰值算法的K-means算法
2021-04-22 17:09:01王煒唯周云才
電腦知識與技術 2021年8期
王煒唯 周云才
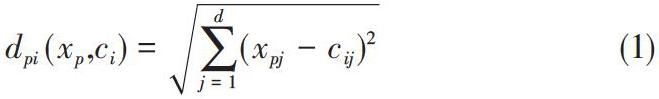
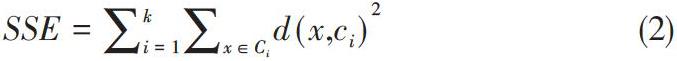

摘要:初始聚類中心的隨機選擇,根據主觀經驗確定類簇數等問題時常伴隨著原始K - means算法。為了攻克以上問題,改進算法采用峰值法以及融合了K近鄰算法的密度峰值算法逐一調整。通過在UCI數據集上測試及與原始K - means算法、最大最小距離距離算法在準確率、穩定性和處理數據速率方面的比較,其中最為突出的是,改進算法的準確率達到了96%以上。
關鍵詞:K-means算法;PCA降維;峰值法;KDPC算法
中圖分類號:TP301.6? ? ? 文獻標識碼:A
文章編號:1009-3044(2021)08-0182-03
Abstract:The random selection of the initial clustering centers, and the determination of the number of clustering based on subjective experience often accompany the original K-means algorithm. In order to overcome the problems, the algorithm used Peak method and the fusion of the density peak algorithm and K-nearest neighbor algorithm to adjusted K-means algorithm. The most prominent of these is that the accuracy of the improved algorithm has reached more than 96% through testing on the UCI dataset and comparing with the original K-meaning algorithm, the maximum and minimum distance algorithm in terms of accuracy, stability and processing data rate.
Key words: K-means algorithm; shannon entropy; improved DPC algorithm
1 引言
近年來,數據大爆炸引發了人們對數據分析的需求,數據挖掘技術應運而生。而K-means算法在數據挖掘中處于重要地位。因其具有簡單易懂、容易實現、時間復雜度低,處理龐大數據集效率更高等優點,所以在工作中常常成為首要的選擇。然而在該算法也會產生不容忽略的問題[1-4]:①類簇數需要根據經驗人工確定;②初始類中心的選擇是隨機的。
針對上述的不足,本文對算法做了以下改進:首先利用香農熵改進歐式距離計算公式,提高樣本點相似度計算的精度;其次同時使用峰值法、融合了K近鄰算法的密度峰值算法(簡稱KDPC算法)自動確定類簇數及精準的初始類心。論文的實驗數據顯示,改進后的算法(簡稱KDPCK-means算法)聚類結果十分貼近真實數據分布,算法性能較高。
2 原始K-means算法
2.1 原始K-means算法原理
K-means算法是經典的無監督聚類算法[5-7],在對數據處理前無須知道數據真實類別,直接以數據相似度判斷函數來估量數據間的相似度,將整體未知類別的數據集劃分成不同的數據簇。K-means 算法的執行過程是:
1) 根據對數據集X的先驗知識,確定數據集X的類簇數k;
2) 在X中隨機選取k個數據點作首次聚類的k個類簇的類心ci(i = 1,2,...,k),同樣地,每個聚類中心也有d維屬性即cij(j = 1,2,..., d);
3) 計算除類心點以外的剩余數據對象與這k個類心的相似度,根據計算結果,將這些剩余數據對象分配給最相似的那個類心所屬類別,最終形成k個類簇Ci。相似度計算一般使用歐式距離計算公式:
4) 重新計算各個新得到的類簇Ci中所有數據對象d個維度的均值,將計算結果賦值給聚類中心。然后重復步驟c、d直至聚類目標函數收斂。目標函數的定義如下:
式中的x代表屬于簇Ci的所有數據對象。
2.2 原始K-means算法缺陷分析及改進
根據2.1節中的算法思想可知,原始K-means算法存在諸多如下缺陷。
1) 數據集的最佳聚類數k根據對數據的先驗知識確定,缺乏客觀科學性。針對該問題,本文提出峰值法來決此問題。
2) 本文利用原始K-means算法對10維以上數據集聚類時發現,該算法對10維以上的數據集聚類效果很差,因此本文在面對高維數據集時,先對其降維處理,以便得到較好的聚類效果。
3) 當初始聚類中心選到含有相同類簇的數據對象時,聚類結果將會偏離真實數據分布情況,生成局部最優解。針對該問題,本文利用融合了K近鄰算法的密度峰值算法加以解決。
3 原始K-means算法的改進
3.1 峰值法確定數據集的最佳類別
實驗證實,最佳聚類數范圍為[2,Int([n])][8]。本文經過大量實驗發現以Calinski-Harabasz系數(CH)為指標,得到各數據集的最佳聚類數最準確。同時,由于K-means算法對高維數據集聚類效果差,本文在對高維數據集聚類前采用能最大保留數據信息的PCA降維。峰值法選取最佳聚類數的過程如下:
1) 判斷數據集維數,若數據集超過10維,先對數據集采用PCA降維,然后計算數據集的最佳聚類數范圍;
2) 在該范圍內取不同的整數k值,對每個確定的k值用原始K-means算法對該數據集聚類10次,得到不同k值對應的最佳CH值。CH系數定義如下:
Ci表示簇Ci的類心,ni表示簇Ci擁有的數據總數,cM表示整個數據集的中心即均值,n表示整體數據集的數據數,即CH值越大,聚類效果越好。
3) 根據b步驟,以k為橫坐標,CH系數為縱坐標,畫出對應的折線圖,選擇圖中的峰值點對應的k值即為該數據集的最佳類別數。
3.2 KDPC算法
根據大多數據集中樣本點的分布可知,類心常被其他樣本點環繞,且各個類心之間相隔較遠。而這一特點正好符合DPC算法應用的前提條件。因此該算法可以很好地解決原始K-means算法中首次聚類類心隨意選擇的問題。然而該算法在計算樣本點局部密度值時未考慮鄰近樣本點的分布且在選取初始聚類中心時,仍依賴人工選擇,因此本文提出KDPC算法,具體過程如下:
1) 樣本點局部密度的計算:
(1)? 引入參數K結合賦權歐式距離來計算截斷距離dc:
上式中的N代表樣本點總數,(4)式表示距離樣本點i最鄰近的第K個樣本點間的賦權歐氏距離,(6)式等號右邊的第二項是每個樣本點的第K最鄰近賦權歐氏距離與所有樣本點的第K最鄰近賦權歐氏距離的均值的標準差。
2) 樣本點i的距離計算:
根據上式結果,將其降序排列,然后以γ為縱軸,點的標號為橫軸,建立平面直角坐標系。靠近近橫軸、更平滑密集是非類簇中心,而類簇中心遠離橫軸,且相對分散,類簇中心點與非類簇中心間界限較明顯。在自動選取初始類心前需要結合3.1節的峰值法選擇排在前k位的點作為初始類心。
4 實驗
4.1 實驗概述
本文在下圖所示的數據集上,通過與原始K-means算法、最大最小距離聚類算法的準確度、穩定性和收斂速度的比較來檢驗KDPCK-means算法的改進是否有效。
4.2 實驗展示與分析
由于文本篇幅限制,下文主要展示本文算法在Iris數據集上的運行效果。
由圖1可知:Iris數據集有3個γ值凸出的間斷點,最佳聚類數為3,將前3個最大的γ值點作為Iris數據集的初始類心。
由表2可知,KDPCK-means算法得到的初始類心、最終類心與Iris數據集真實類心十分接近。
在這兩種數據集中,KDPCK-means算法的精確度顯優于前兩種算法,其迭代次數也明顯少于前兩種算法。通過以上實驗數據可知,KDPCK-means算法在一舉解決了原始K-means算法中問題的同時,在準確率、穩定性及運行效率上都得到了有效的提升。
參考文獻:
[1] Al Hasib A,Cebrian J M,Natvig L.A vectorized k-means algorithm for compressed datasets:design and experimental analysis[J].The Journal of Supercomputing,2018,74(6):2705-2728.
[2] Douzas G,Bacao F,Last F.Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE[J].Information Sciences,2018,465:1-20.
[3] García J,Crawford B,Soto R,et al.A k-means binarization framework applied to multidimensional knapsack problem[J].Applied Intelligence,2018,48(2):357-380.
[4] Manju V N,Lenin Fred A.AC coefficient and K-means cuckoo optimisation algorithm-based segmentation and compression of compound images[J].IET Image Processing,2018,12(2):218 -225.
[5] 陳思敏.基于位置指紋識別的WiFi室內定位算法研究與實現[D].南京:南京郵電大學,2016.
[6] 韓雅雯.kmeans聚類算法的改進及其在信息檢索系統中的應用[D].昆明:云南大學,2016.
[7] 孔超.基于分布式平臺的高校網絡輿情分析系統研究與實現[D].成都:電子科技大學,2017.
[8] 郭靖.K-means聚類算法改進研究[D].北京:中國人民公安大學,2018.
【通聯編輯:李雅琪】
