面向低資源場景的論辯挖掘方法
2021-04-23 04:41:22葉鍇魏晶晶魏冬春王強廖祥文
福州大學學報(自然科學版) 2021年2期
葉鍇, 魏晶晶, 魏冬春, 王強, 廖祥文
(1. 福州大學數學與計算機科學學院, 福建 福州 350108; 2. 福建江夏學院電子信息科學學院, 福建 福州 350108)
0 引言
主觀性文本能反映人們對現實事物的看法, 具有巨大的研究價值. 論辯挖掘[1]的目標是自動學習文本的論辯結構, 進而識別論點和提取相關論點間的邏輯關系, 從而幫助人們在如政府決策等事務中做出決策, 提供便利.
傳統的論辯挖掘方法主要采用機器學習模型, 如樸素貝葉斯[2]等, 并取得不錯的性能. 但傳統方法依賴于特征工程的設計, 難以應用于低資源場景. 現有工作大多采用神經網絡進行端到端的特征表示學習[3],但論辯挖掘單一領域的現有標注數據難以滿足神經網絡的訓練. 因此, 有研究者對多個領域數據集進行聯合訓練[4-5], 利用任務間的關聯信息改進模型性能. 但這些方法沒有利用文本的層級結構信息, 難以檢測跨段落的論點部件邊界.
針對上述問題, 本研究提出一種面向低資源場景的多任務學習論辯挖掘方法, 該方法采用多任務學習策略, 學習文本的字符級共享表示, 同時在序列編碼中融入文本的結構信息進行求解. 該模型共享任務的字符級特征, 有效利用領域間的信息以解決低資源場景訓練數據不足的問題; 此外, 學習到的結構信息能有效捕獲長依賴關系, 幫助模型更好識別長論點部件. 采用了文獻[4]中所使用的六個數據集進行實驗, 實驗結果表明, 與當前最好的方法相比, 本研究提出的方法在宏觀F1值上有1%~2%的提升, 較好地驗證了該方法的有效性.
1 相關工作
1.1 論辯挖掘
論辯挖掘是自然語言處理中的新興領域. 文獻[2]首先在法律文本上通過樸素貝葉斯模型完成論點分類任務. 這些方法嚴重依賴手工特征, 成本高昂. 文獻[3]首次提出基于神經網絡端到端的論辯挖掘模型, 并證明論辯挖掘任務更適合視作序列標注進行求解. 文獻[6]發現論辯挖掘領域標簽的概念化差異一定程度上阻礙了論辯挖掘任務的跨域訓練. 文獻[7-8]的研究工作表明由于論辯挖掘領域概念化不同, 大多數據集缺乏規范的論辯架構且存在噪音, 因而難以在網絡文本中開展. 文獻[9]首次采用監督學習檢索文本中與給定主題相同立場的論證內容. 文獻[4]首次將多任務學習應用在論辯挖掘并提升了性能, 證明了多任務學習也能處理論辯挖掘這一復雜任務. 文獻[5]通過對多個數據集進行聯合訓練, 利用多任務之間的關聯信息一定程度上改進了論點部件檢測和識別的性能.
1.2 多任務學習
多任務學習目的是在學習主任務時, 同時學習其它任務以獲取額外信息改進主任務. 文獻[10]首次提出多任務學習, 認為將復雜問題分解為更小且合理的獨立子問題分別求解再組合, 能夠解決初始的復雜問題. 文獻[11]在此基礎上增加了“竊聽”機制, 所有任務共享模型的編碼層. 文獻[12]的工作表明多任務學習對于數據稀少的任務更加有效. 文獻[13]通過同時借鑒同任務高資源語言數據和相關的任務數據學到的知識, 解決低資源語言訓練數據缺乏, 即低資源問題. 文獻[14]提出一種新的參數共享機制——稀疏共享, 為每個任務從基網絡中抽取出一個對應的子網絡來處理該任務, 在任務相關性弱的場景下, 稀疏共享提升較大.
2 問題描述
論辯挖掘任務的目標是學習文本的論辯結構以識別論點, 本質是序列標注任務. 因此, 對于論辯挖掘問題, 其形式化定義描述如下, 在給定的某個含n個單詞的主觀性文本x={x1,x2, …,xn}和對應的標簽y={y1,y2, …,yn}, 其中yi定義如下:yi={(b,c)|b∈(B, I, O),c∈(P, C, MC)},b代表論點邊界檢測的標簽, B代表起始單元, I代表中間單元, O則表示非論辯單元,c表示論點部件的類型. 這里以學生論文數據集作為示例, P表示前提, C代表主張, M則表示文本中唯一的主要主張. 具體的標注示例如表1.

表1 學生論文數據集標注樣例
3 模型建立
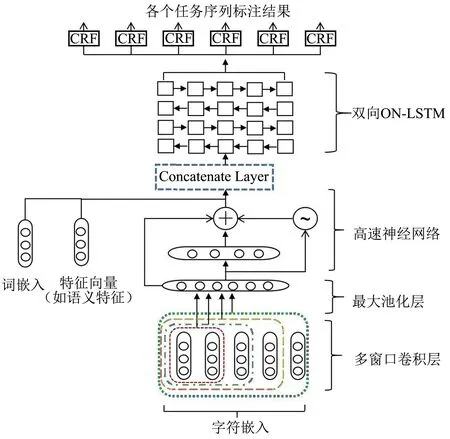
圖1 論辯挖掘多任務學習模型
本研究引入多任務學習解決多個不同領域數據集的論辯挖掘任務, 所提出的框架CNN-Highway-On-LSTM-CRF如圖1所示. 該模型主要包括以下模塊: 1)基于CNN的字符表示; 2)基于高速神經網絡的特征過濾層; 3)基于ON-LSTM模型的詞級標注方法; 4)輸出層. 本研究將以自下而上方式詳細介紹所提出的模型框架.
3.1 基于CNN的字符級表示
本研究拓展了文獻[15]提出的CNN模型. 具體如下:
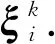
3.2 基于高速神經網絡的特征過濾
為進一步提高實驗效果, 引入高速神經網絡進行特征過濾. 其主要通過轉換門和進位門控制不同層信息衰減的比例, 具體實現如下:at=z?σ(Wat-1+b)+(1-z)?at-1. 這里,σ為非線性函數,z=σ(Wat-1+b)為轉換門, (1-z)成為進位門, 這里W表示轉關門的權重矩陣.
3.3 基于ON-LSTM模型的詞級標注方法
文本的每個句子可以被表示為層級結構, 在低資源場景下, 這些結構特征能改善模型性能. 因此, 引入有序神經元長短時記憶網絡(ON-LSTM)[16]作為詞級序列標注模型.
在ON-LSTM通過對內部的神經元進行排序將層級結構信息集成到LSTM中, 通過控制神經元的更新頻率來表示不同尺度的依賴關系, 與標準的LSTM架構相比, 其引入了新的更新規則, 定義如下:
這里,xt是當前輸入,ht-1為前一時間步的隱藏狀態.
3.4 模型求解
標簽依賴是解決序列標注任務的關鍵. 例如BIO標注方法中, 標記I不能出現在B之前. 因此, 聯合解碼標簽鏈可以確保得到的標簽是有意義的. 條件隨機場(CRF)已被證明能夠捕捉標簽依賴信息. 因此, 采用CRF作為模型的最終預測層.
本研究整個模型的輸入為一段論辯挖掘文本序列, 最終輸出為該文本序列預測的標簽序列Y.
4 數據集描述
采用文獻[4]所使用的數據集, 數據集具體情況如表2所示. 其中Domain表示數據集所屬的領域, Len為數據集的最大句子長度, Token為每個數據集每篇文章的平均單詞數量, Class 為每個數據集論點部件的類型, 每個數據集的類型都不相同.

表2 數據集詳情
5 實驗結果與分析
本節將從實驗的對比模型、 參數設置以及評價指標進行介紹, 同時對不同場景的實驗結果進行簡要的分析.
5.1 實驗對比模型
為了驗證本研究模型的有效性, 選取以下模型作為基準實驗.
1) STL[4]. 單任務學習模型, 該模型僅針對單一數據集進行訓練和預測.
2) MTL-Bi-LSTM-CRF[4]. 多任務學習模型, 采用Bi-LSTM進行特征提取, 用CRF進行序列標注, 記為MTL.
3) CharLSTM+Bi-LSTM-CRF[17]. 該模型在2)的基礎上引入字符級的LSTM進行字符特征提取, 記為LBLC.
4) CharCNN+Bi-LSTM-CRF[17]. 與3)不同的是字符級的LSTM換成了字符級的CNN, 記為CBLC.
5) CNNs-Highway+Bi-LSTM-CRF[5]. 與4)不同的是字符級的CNN換為TextCNN-Highway, 記為CHBLC.
5.2 評價指標
5.3 實驗結果及分析
在現實場景中, 由于標注代價高昂, 論辯挖掘仍十分缺乏標注數據, 因此, 本研究模擬了低資源場景, 比較模型在各種場景中的性能. 為模擬低資源場景, 按照21 k, 12 k, 6 k, 1 k的單詞規模對數據集進行隨機抽取, 其規模指的是訓練樣本數目.
5.3.1多任務學習的任務數量和任務差異對實驗的影響
為探究任務數量對實驗的影響, 以Hotel為主任務, 逐次增加輔助任務的數量. 如圖2~3所示, 在迭代次數相同的情況下, 隨著任務的增加, 模型的訓練時間隨之增長, 模型性能也逐步提高. 與模型復雜度增加改善的性能提高相比, 其帶來的訓練時間增加仍在可接受的范圍.
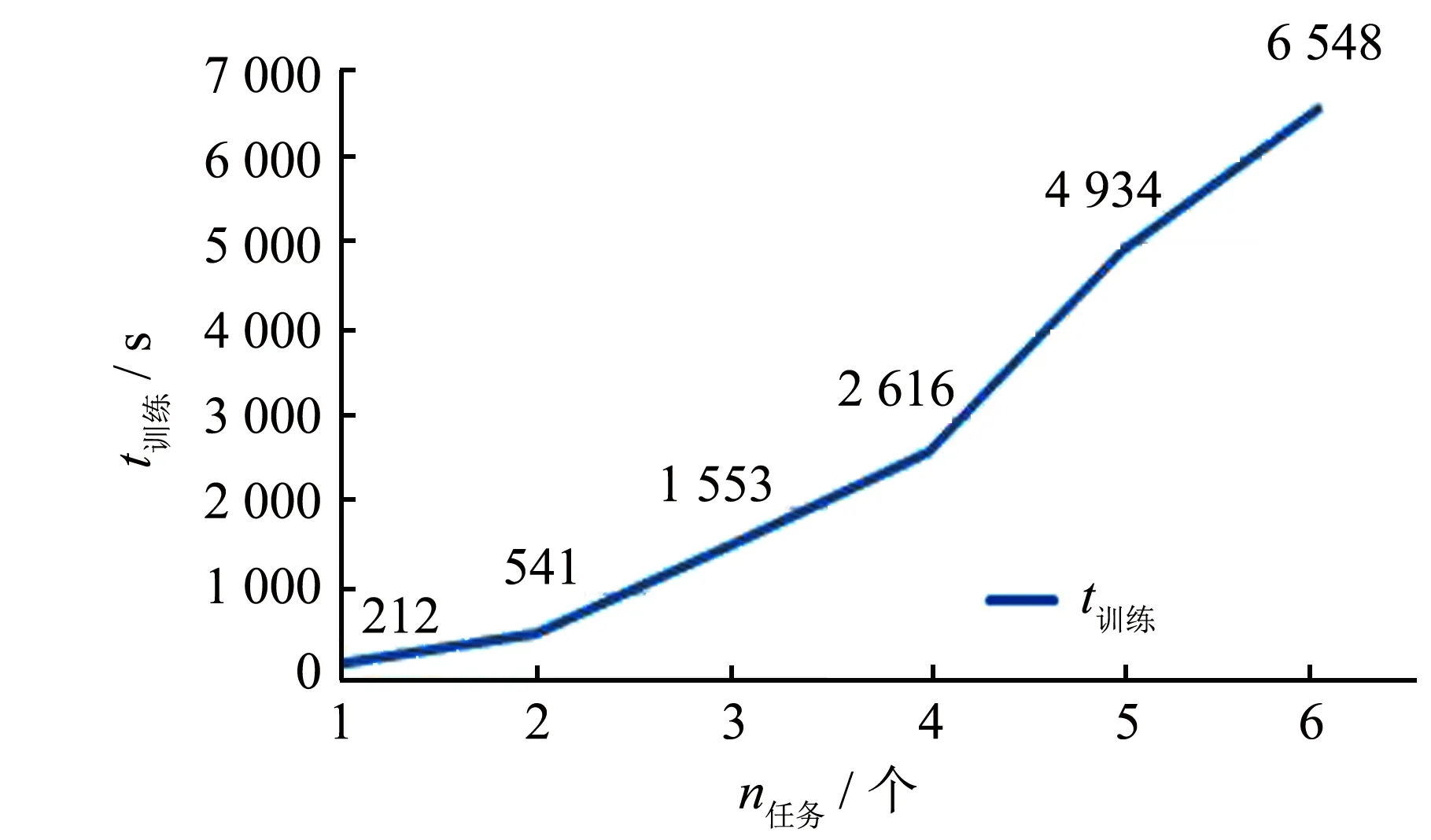
圖2 任務數量對模型訓練時間的影響
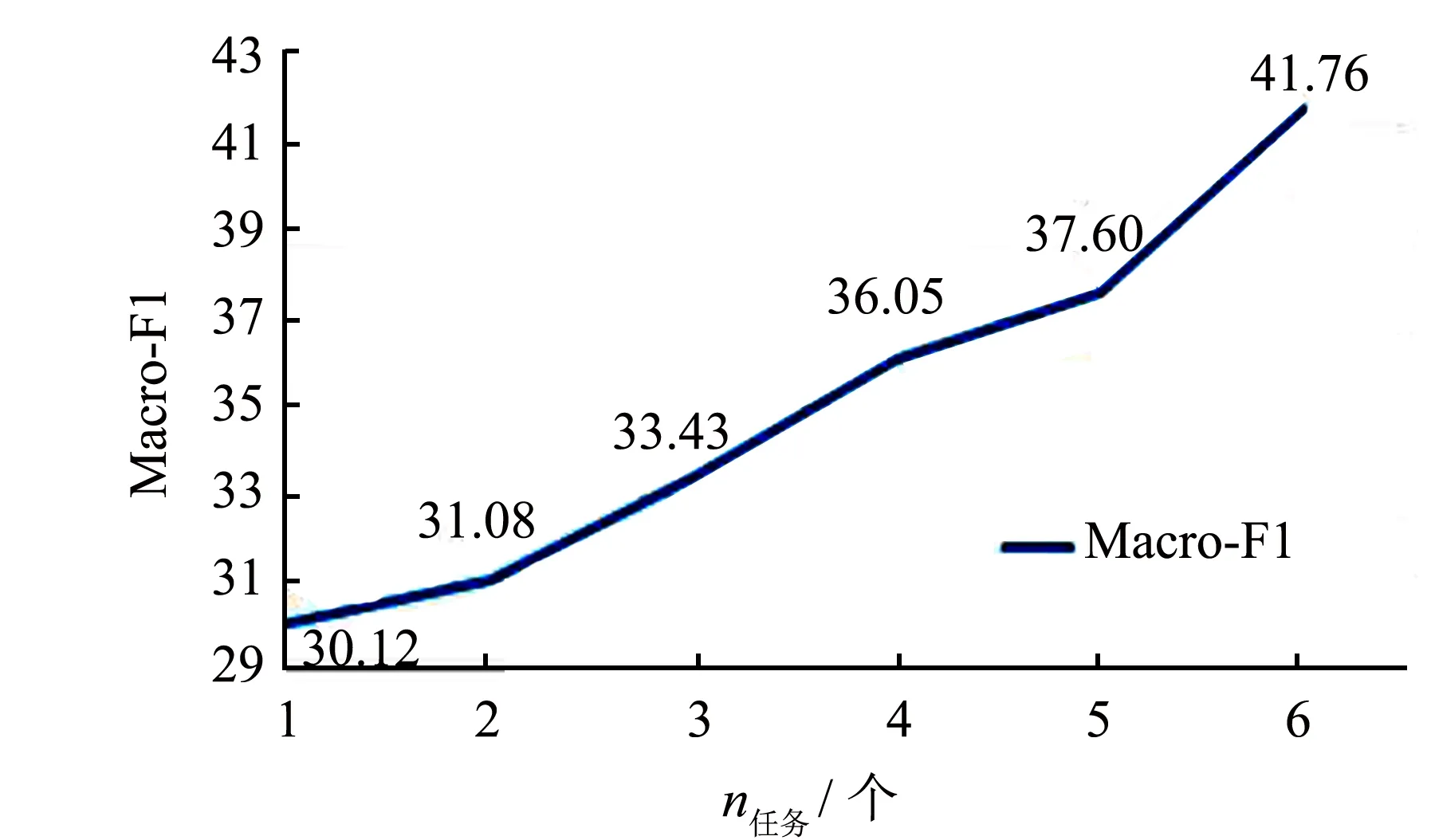
圖3 任務數量對模型性能的影響
為了探究多任務學習方法中任務間差異對實驗的影響, 分別以Essays等五個數據集作為Hotel輔助任務進行對比實驗, 實驗結果如圖4~5所示.從圖4可以看出, 每個任務的引入都對模型性能有一定的提升, 而任務間差異的大小影響性能的提升幅度. 由圖5可以發現, 差異較大的News作為輔助任務時模型收斂時間較長, 而幾個差異相近的輔助任務: Var, Wiki, Web等, 其收斂時間相近. 從實驗結果綜合來看, 模型的差異性對模型收斂時間有一定的影響, 但影響有限.
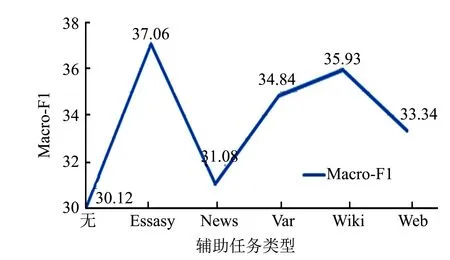
圖4 任務差異對模型性能的影響
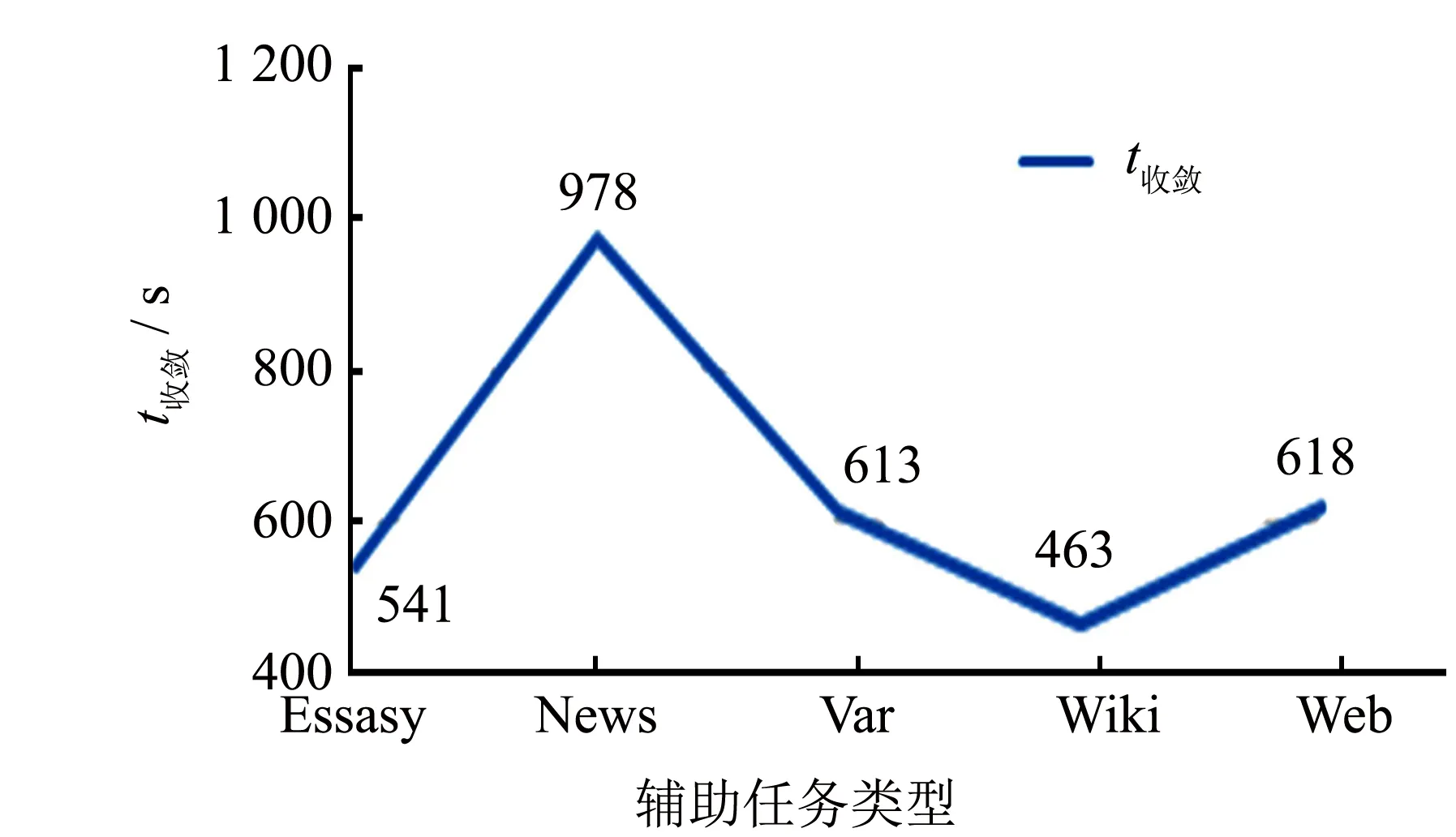
圖5 任務差異對模型收斂時間的影響
5.3.2數據稀疏情況下對比各個模型性能
在不同低資源場景下的模型Macro-F1值如表3所示, 其中, 提升最高且穩定的是Hotel數據集, 在四種低資源場景下均獲得了1%~4%的提升. 在1 k, 6 k, 12 k的單詞場景中, 大部分數據集都取得了1%~5%的提升, 在21 k的單詞場景中, 雖然沒有取得顯著的提升, 但也達到了與當前最優方法模型相近的性能. 從表4中可以看到, 在絕大部分場景中, 本研究模型性能高于所有基準模型, 在數據規模越小的場景中, 性能提升越大.
觀察實驗結果發現, MTL等多任務模型較單任務模型在各個任務上都獲得了一定的提高, 特別是Wiki數據集, 在21 k的單詞場景提升了8.9%. 這可能是因為Wiki數據集是社交媒體上隨機采集的文本, 存在大量非論辯成分, 影響其他論點部件類型的判斷, 而多任務機制的引入降低了過擬合的風險, 提升了對論辯類型的預測準確率. 例如在News數據集中Premise因為存在大量的O而被單任務模型預測為O, 而多任務減少了這種情況.
結合實驗預測標簽情況對結果進一步分析, 發現本研究所提出的模型捕獲了層級結構信息, 利用這些信息能夠較好地判斷論點邊界, 進而提升模型的性能. 如Hotel數據集中, 在1 k的單詞規模下提升了8.8%, 其他規模也提升了2%左右. 這是因為論點部件長度過長, 存在跨段部件時, 基準模型難以捕捉這一長依賴信息, 使得預測的論點邊界過小而發生錯誤, 而本研究模型利用層級結構信息, 能夠捕獲長依賴信息, 提升邊界的預測準確度, 進而提升了模型性能.
綜上所述, 與單任務學習模型和其他的基準模型相比, 本研究的模型方法在大部分低資源的場景下都能取得一定的提升, 由此證明本研究方法在面向低資源場景下是有效的.
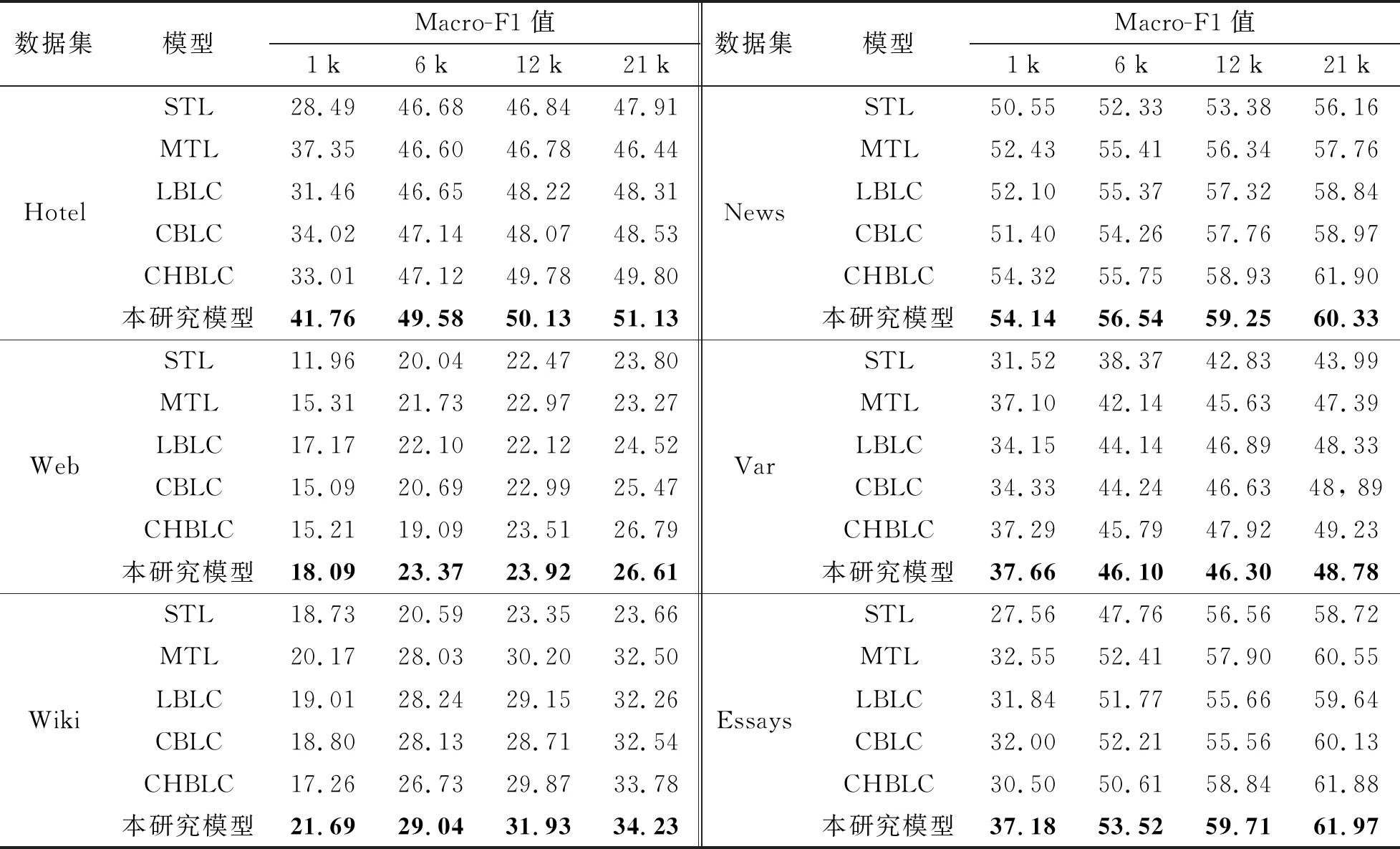
表3 不同低資源場景下各個模型的Macro-F1值
5.3.3在完整數據集場景下比較各個模型性能
雖然論辯挖掘任務目前仍缺少標注數據, 但隨著研究的進行, 數據資源將不斷豐富. 因而, 所提方法還需考慮有足夠訓練數據的場景. 因此, 將在完整數據集場景中比較各個模型性能, 以驗證所提方法的有效性(表4). 從表4的實驗結果可以看出, 本研究所提出的模型在完整數據的場景中較前面的基準模型獲得了一定的提升. 其中Hotel較其他模型提升較為明顯, 這可能是因為Hotel論點部件長度普遍較長且標簽多達7種, 其他模型難以解決這種長依賴多標簽問題, 而本研究模型通過學習隱藏的層次信息, 可以較好地解決這類長依賴問題.
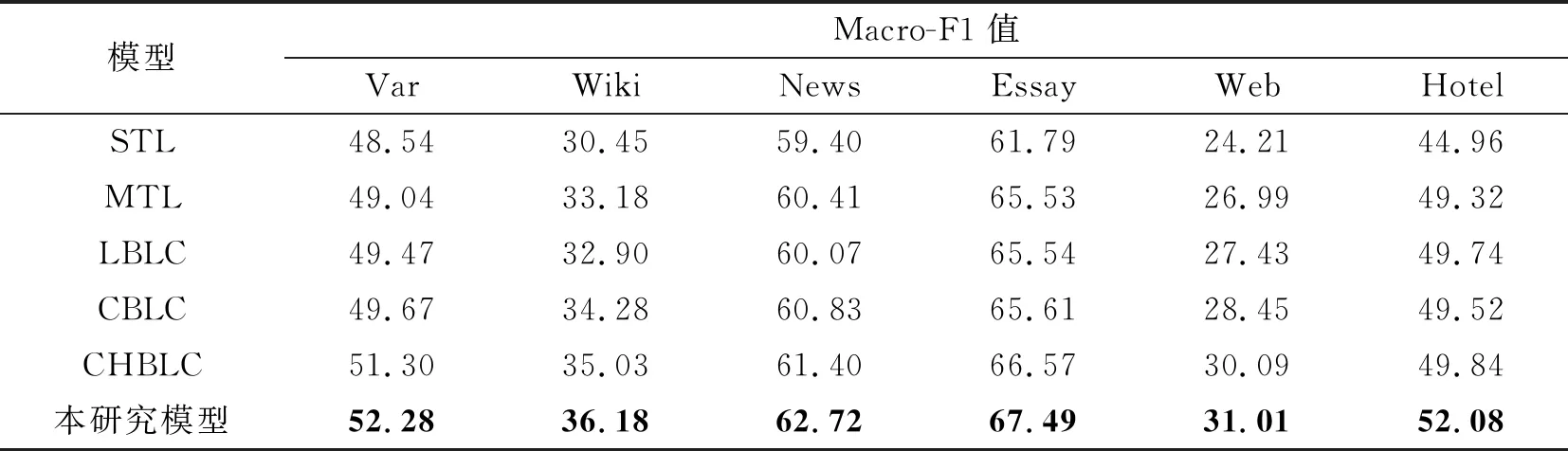
表4 完整數據集下各個模型的Macro-F1值
從對比實驗中, 可以發現MTL模型所代表的多任務架構較單任務性能有較大改善. 其在Essays數據集上提升最為顯著, 提升了3.74%, 而提升最少的Var和News也提升0.5%~1.0%, 說明多任務方法是解決多個數據集論辯挖掘任務的有效方法.
綜上所述, 與單任務學習模型相比, 多任務學習模型能獲得較好的效果, 利用字符級信息模型也能進一步提升性能. 而本研究方法較其他模型更加優秀, 說明本方法在完整數據集上也有不錯的效果.
6 結語
本研究提出一種面向低資源場景的多任務學習論辯挖掘方法. 該方法應用多任務學習策略獲取多任務間的共享信息表示, 并引入ON-LSTM, 最后通過條件隨機場進行標注. 通過與現有方法的實驗結果對比, 證明所提方法利用多任務可有效解決論辯挖掘任務缺乏數據的問題, 同時解決跨段論點部件難以檢測的問題. 接下來的研究中, 將繼續探索如何更加有效地利用資源以提升模型性能, 促進論辯挖掘在新興領域中的應用.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
