抵抗泄露攻擊的Clos網絡分布式調度方法*
2021-04-25 06:44:20李琴,張帥
寶雞文理學院學報(自然科學版) 2021年1期
關鍵詞:方法
李 琴,張 帥
(濰坊工程職業學院 信息工程系,山東 青州 262500)
近年來,計算機網絡技術逐漸增強,網絡中所有數據包和服務器的連接方式呈現出多樣化特征,網絡惡意攻擊導致數據泄露問題已經成為網絡安全中存在的重要隱患[1]。當前,經常出現的網絡惡意攻擊方法有很多種,例如:網絡數據受木馬、病毒干擾,防火墻遭受黑客攻擊等現象,這些方法在通常情況下都會針對網絡安全漏洞來進行攻擊。近幾年來,Clos網絡呈爆炸式增長,導致數據在傳輸的過程中很容易發生擁堵的情況,如何針對Clos網絡分布式數據進行調度[2-3]已成為當前研究的熱點話題。但目前的網絡調度過程中,普遍存在調度完成總時間較長、能量消耗較大、平均帶寬利用率較低等問題。如何合理調度Clos網絡已成為當今社會亟待解決的問題[4-5]。
文獻[6]提出了一種基于MVB網絡數據分布式調度優化方法,該方法將網絡中最小負載作為目標組建分布式調度模型,同時采用免疫遺傳算法對模型進行求解,具有較快的收斂速度,但是耗時較長。文獻[7]提出了一種基于Storm網絡拓撲結構分布式調度方法,該方法結合網絡數據通信過程中存在的優勢以及熱邊概念,有效降低網絡數據傳輸的數量,提升Storm集群的性能,快速實現網絡分布式調度。該方法調度完成總時間較短,但是在數據調度過程中消耗了大量的能量。文獻[8]提出了一種基于加權最小連接數的分布式調度方法,通過網絡服務端中最小的連接數負載因子獲取網絡中不同服務器之間的最好的方案,并且選取最小的服務器進行連接,以實現網絡分布式調度。該方法穩定性較好,但是也存在耗時較長的問題。
針對上述方法存在的問題,提出一種基于貓群優化算法的Clos網絡分布式調度方法。實驗結果表明,本文方法調度完成總時間較短、能量消耗較小、平均帶寬利用率較高。
1 基于貓群算法的Clos網絡分布式調度方法
1.1 調度模型的組建
引用分布式網絡攻擊檢測算法來求出Clos網絡中數據包的信任值,并通過對閾值的設定,構建Clos網絡抵抗泄露模型,當Clos網絡數據包信任值低于所設定的閾值時,則受到惡意攻擊,具體過程如下。
假設在Clos網絡系統中植入n個惡意病毒,并且使每個病毒都帶有自己獨特的特征,當病毒集合為N={p1,p2,…,pn}時,所有病毒自己特征所對應的特征集合為p={x1,x2,…,xn},Clos網絡系統中數據包集合為Ω={σ1,σ2,…,σn},這時每個Clos網絡中數據包都有自己所對應的信任值,如公式(1)所示。
(1)
式中,C(σi)表示Clos網絡中數據包的初始容量大小,C(σi)′表示該網絡中數據包在產生一定改變之后的容量大小。
在Clos網絡系統中,所有數據包和它所對應的IP地址都是一個隨機變量,在遭受到惡意因素(病毒、木馬)進行攻擊時,這些惡意因素也將會隨機選擇網絡數據包和它所對應的IP地址來進行選擇性攻擊,在這個過程中,這個惡意因素也是一個隨機變量,并且每個變量之間都是相互獨立存在的,針對這個問題,引入概率密度函數(公式(2))來體現病毒的分布情況。
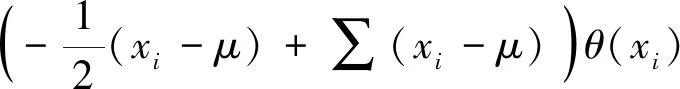
(2)
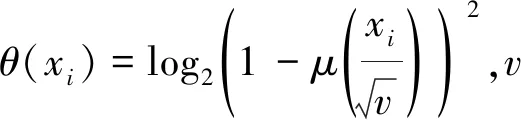
假設Clos網絡中含有xi個特征的惡意攻擊病毒pi從IP地址為ipj的服務器進入,被入侵的Clos網絡數據包為σj,這時就會對ipt服務器進行攻擊。利用公式(3)給出惡意攻擊病毒pi攻擊Clos網絡數據包σj之后,Clos網絡數據包信任值的變化情況。
(3)
式中,(ipt-ipj)表示Clos網絡IP地址的二進制差值,對Clos網絡系統中數據包的信任值進行閾值T(ω)設定,當Clos網絡數據包的信任值小于T(ω)時,Clos網絡數據包受到病毒的惡意攻擊,將會導致Clos網絡數據泄露,利用公式(3)可以對Clos網絡攻擊的病毒進行追擊,以此來查找出IP地址。
為了使后期的Clos網絡數據包信任值能夠通過Clos網絡系統確定出危險等級,這時就需要對惡意攻擊的危險等級進行評估,當病毒惡意攻擊危險等級越大時,病毒攻擊的危險性就越大,Clos網絡數據泄露的可能性就越大,結合Clos網絡系統中病毒惡意攻擊的危險等級,組建基于抵抗泄露攻擊的Clos網絡分布式調度模型。
Li=F(ipj)F(xi)F(ωj)
(4)
式中,F(ipj)表示Clos網絡中服務器IP地址為ipj的危險度函數,F(xi)表示Clos網絡系統中含有xi個特征病毒的危險度函數,F(ωj)表示Clos網絡數據包信任值ωj的危險度函數。
1.2 基于貓群優化算法的Clos網絡分布式調度方法
以1.1節構建的Clos網絡抵抗泄露模型為依據,結合最短實踐以及最優數據流負載因素,組建貓群算法[9]適應度函數,獲取Clos網絡分布式最優調度方案。
貓群算法是一種模擬貓的日常全部生活狀態的一種優化算法,主要利用搜索以及跟蹤獲取最優解。其基本操作流程如下。
(1)將貓群進行初始化處理;
(2)通過分組率將貓群隨機劃分為跟蹤以及搜尋2種不同的形式;
(3)根據貓的規定值對它所追蹤的對應算子重新進行位置更新;
(4)分別計算每只貓的適應度,同時保留適應度最優的貓;
(5)假設滿足約束條件,則終止算法;否則返回步驟(1)。
跟蹤模式是模擬貓處于跟蹤狀態下組建的模型,在該模型下,通過改變各個貓的維度進行位置更新,其中更新模式主要通過以下2個步驟實現。
(1)速度更新
每只貓都有自己當前的速度,將其記為:
Vi={Vi1,Vi2,…,Vit}
(5)
每只貓主要通過公式(6)進行速度更新,將Xbest(t)作為當前貓群里經歷的最優位置,即適應度最好的貓。
(6)
其中,d代表“貓在d維處的位置”,c代表“調節參數”,rand代表“(0,1)的隨機數”。
(2)位置更新
每只貓通過公式(7)進行位置更新:
(7)
搜尋模式主要是模擬貓在搜索以及尋找下一個地點所組建的模型。在該種狀態下,每只貓通過適應度取值的大小在記憶池中選取最佳位置,具體的操作步驟如下。
(1)將自身位置進行復制;
(2)執行變異算子;
(3)計算記憶池中各個貓的適應度,同時采用適應度取值最高的貓代替當前的貓[10],實現位置更新。
采用貓群算法進行模型求解的具體過程如下。
(1)將參數進行初始化;
(2)將貓群進行初始化處理,隨機得到不同的初始解;
(3)計算每只貓的適應度,其中適應度函數表示為:
F=∑xijdij
(8)
其中,xij代表“城市i到城市j的訪問次數”,dij代表“城市i到城市j的距離”;
(4)將所有貓隨機分布到搜尋模式組以及跟蹤模式組;
(5)確定出所有貓的模式組,判斷每只貓所處的模式,同時對各組內貓的個體執行對應的模式算子,分別計算每只貓的適應度,且更新全局最優貓;
(6)當更新完所有貓之后,如果沒有達到最大迭代次數,則返回至步驟(4)重新計算,直到滿足最大迭代次數后結束進化;
(7)獲取最優Clos網絡分布式調度方案。
2 實驗與仿真證明
為了驗證基于貓群算法的Clos網絡分布式調度方法的綜合有效性,需要進行實驗測試,實驗操作系統為Windows8,內存為64 G,將本文方法與基于MVB網絡數據分布式調度優化方法(方法1)和基于Storm網絡拓撲結構分布式調度方法(方法2)進行對比實驗。
(1)調度完成總時間/s
調度完成總時間越長,說明任務調度越慢;反之,則說明任務調度速度越快。表1詳細給出了3種不同方法的調度完成總時間對比結果。
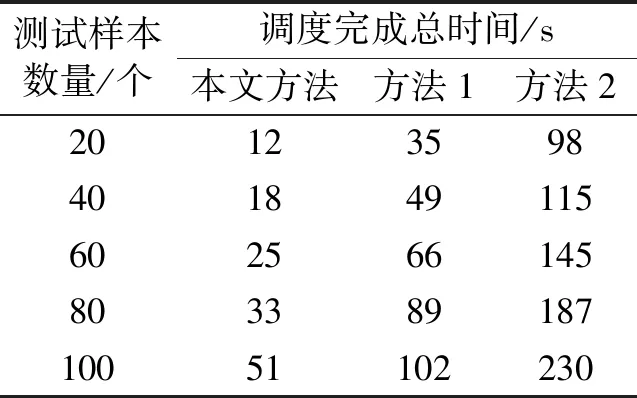
表1 3種方法調度完成總時間變化情況Tab. 1 Changes in scheduling completion total time of 3 different methods
分析表1數據可知,隨著測試樣本數量的增加,3種方法的調度完成總時間均隨之增加。與方法1及方法2相比,本文方法的調度完成總時間增加速度明顯慢一些,說明本文方法能夠在較短的時間內實現任務調度。
(2)平均帶寬利用率/%
平均帶寬利用率α為Clos網絡系統中每條網絡數據實際獲得的帶寬和指定帶寬之比值的平均值,主要表示Clos網絡數據的均衡程度,α的取值越高,說明網絡負載越均衡,具體計算式為:
(9)
其中,rrf代表“網絡節點數量”,arf代表“節點移動利率”。
圖1為3種方法的平均帶寬利用率對比結果。
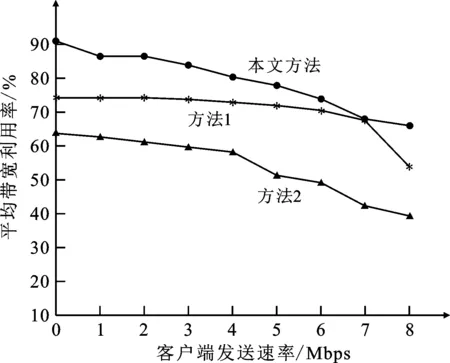
圖1 不同方法平均帶寬利用率對比Fig. 1 Comparison of average bandwidth utilization of different methods
由圖1可知,當數據流量負荷持續增加時,3種方法的平均帶寬利用率均呈現下降趨勢。其中本文方法充分考慮到Clos網絡中全部路徑數據負載情況之后進行選擇,有效降低了網絡出現擁堵的概率,帶寬利用率明顯得到有效改善;方法1針對網絡中占有率最高的網絡數據進行調度,在實際操作過程中忽視了對網絡服務質量的需求,所以導致帶寬利用率下降。方法2采用網絡數據調度策略導致其發生數據的概率較大,促使帶寬利用率明顯偏低。3種方法中,本文方法的帶寬利用率明顯更高一些,說明本文方法具有更好的調度性能。
(3)調度能量消耗/J
對比3種方法的調度能量消耗,實驗結果如表2所示。
由表2可知,不同調度方法的能量消耗均會隨著測試樣本數量的增加而增加。本文方法的調度能量消耗明顯更低一些,這說明本文方法的綜合性能相比另外2種方法有了很大程度的提升,同時也充分驗證了本文方法的優越性。
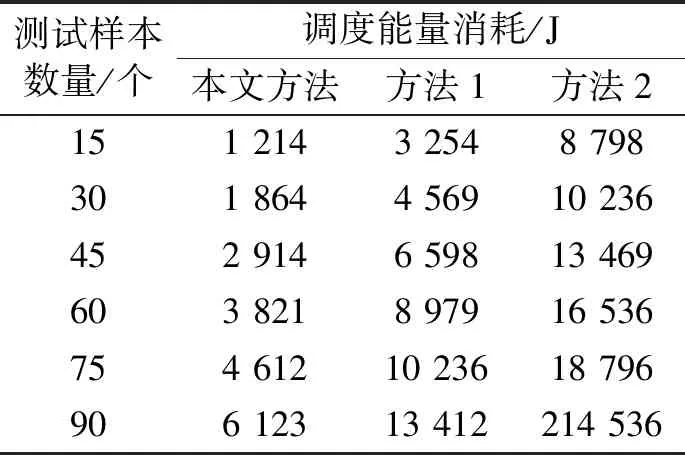
表2 3種方法調度能量消耗變化情況Tab. 2 Changes in scheduling energy consumption of 3 different methods
3 結束語
針對傳統的Clos網絡分布式調度方法中存在的各種不足,提出基于貓群優化算法的Clos網絡分布式調度方法。利用該方法進行網絡分布式調度可以節省調度時間,降低能量消耗,優于其他傳統方法,具有一定的適用性。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
