云數據中心服務器能耗建模及量化計算
2021-04-25 08:11:56周舟袁余俊明李方敏
湖南大學學報(自然科學版) 2021年4期
關鍵詞:模型
周舟,袁余俊明,李方敏?
(1.湖南大學信息科學與工程學院,湖南長沙 410082;2.長沙學院計算機工程與應用數學學院,湖南長沙 410022)
隨著云計算數據中心的大量新建,數據中心的能耗問題越來越嚴重.近期研究顯示[1-2]:全球數據中心的總數已超過300 萬個,耗電量占全球耗電量的1.1%~1.5%.我國數據中心也發展迅速,總數已達到40 萬個,年耗電量已超過500 億千瓦,占全國總耗電量的1.5%.如果以數據中心的PUE(平均電能使用效率)指數來評測,全球先進數據中心的PUE 指數為1.2,而我國的PUE 指數大于2.2.與此同時,大量的報告也顯示[3-5]:許多高性能數據中心服務器的利用率卻遠遠低于50%,其原因在于數據中心資源未得到“有效”利用.因此,節能優化算法的提出有助于提高系統的資源利用率和單位能耗的效用.
能耗模型作為“節能優化算法”的基礎[6-7],其準確性直接關系到優化算法的優劣.一個精確、通用、有效的能耗模型不僅為優化算法提供基礎,而且也有利于該模型的擴充.對于云資源提供者來說,構建精確的能耗模型有助于資源提供者預測和優化數據中心的能耗,提高單位能耗的效用.因此,對其研究具有十分重要的現實意義.
本文的主要工作如下:
1)基于“任務的特征”構建能耗模型.不同于其它的能耗模型僅考慮CPU 密集型任務,在本文中,基于“任務特征”的不同,任務被劃分為三類,分別為計算密集型任務、Web 事務型任務和I/O 密集型任務.
2)不同于已存在的能耗模型僅考慮CPU 和內存部件,而忽略了磁盤和網絡接口卡部件,本文所提出的能耗模型考慮了與能耗有關的所有部件如CPU、內存、磁盤和網絡接口卡.
3)使用“主成分分析法”分析各部件參數對能耗的貢獻并選擇最具代表性的參數.
4)運用大量的實驗證明了本文所提出能耗模型的精確性和有效性.
1 相關研究
目前,對能耗模型的研究可以分為兩類,一類是基于系統利用率的能耗模型[8-12],另一類是基于性能計數器的能耗模型[13-17].
基于系統利用率的能耗模型的主要思想是利用服務器各主要部件的利用率,構建能耗模型.文獻[8]基于服務器中資源使用情況,結合回歸方法建立了線性模型.文獻[9]結合三個參數(%Processor Time,%Memory used,%Page Faults/s)提出了一種CMP(CPU利用率,內存利用率和Pagefaults)模型,相比較以往的能耗模型,該方法具有一定的優勢,但該方法因選擇的參數有限且沒有考慮到負載的特征,其能耗模型的精度仍有待提高.在文獻[12]中,羅亮等人針對數據中心的單臺服務器提出了一種高精度的能耗模型,該模型分析了不同參數對服務器能耗的影響,然后結合多元線性回歸和非線性回歸的方法建立能耗模型.同樣,文獻[11]在線性模型(Linear Model)的基礎上提出了一種改進的能耗模型叫Cubic Model,該模型認為服務器的能耗與處理器(CPU)不應是線性關系,而是立方關系.文獻[12]基于能耗和系統資源利用率的關系,提出了一種服務器能耗經驗模型(Linear Model).此類能耗模型的優點是易于實現且能耗模型的精度較高.
基于性能計數器的能耗模型的基本思想可概括為:根據PMC 與設備能耗之間的關系,針對不同設備(包括處理器、內存、磁盤、I/O 外部設備)篩選出最具代表性的“PMC 集合”;然后通過統計分析的方法,建立PMC 事件與設備功耗之間的函數關系,這種關系既可以是線性關系、也可以是非線性關系.在文獻[13]中,程華等提出了一種基于細粒度的實時能耗模型,該模型由模型設定、性能計數器參數選取、數據采集、模型求解和性能評估這五個部分組成.在此文中,作者選擇PMC 集合(包含二十多個參數)建立系統能耗模型.文獻[14]通過運行負載,在考慮處理器和內存等因素下,基于PMC 方法建立服務器的能耗模型.在文獻[15]中,作者在考慮CPU 和內存兩大因素的條件下,提出了一種Ramon Model.在文獻[16]中,Singh 等使用PMC 方法構建實時的能耗模型.在文獻[17]中,肖鵬等首先形式化資源利用率與能耗之間的關系,然后基于性能計數器提出了一種新型的能耗模型,最后基于該能耗模型提出了一種虛擬機調度算法.此類方法因采集到的事件太多,成本相對較高,模型也較為復雜,故不利于該模型擴充.
2 能耗模型的參數選擇
數據中心服務器的能耗建模如圖1 所示.它包含數據采樣、參數的篩選、建立模型和評估模型四個步驟.
1)數據采樣.數據采樣是數據中心能耗建模的第一步,這一步的主要工作是采集系統的數據,采樣的基本方法有基于性能計數器或者基于系統資源利用率.

圖1 能耗建模的基本步驟Fig.1 Basic steps for energy modeling
2)參數的篩選.在采樣數據之后,就需要對采集到的參數進行篩選.因為采樣的參數有些是與系統能耗相關的,有些是不相關的.如何篩選這些參數呢?此時可以借助于“主成分分析法”或者“相關系數矩陣法”去篩選.
3)建立模型.這一步的主要工作是利用前面篩選出的參數,借助于數學中的線性回歸或者非線性回歸方法(多項式回歸,冪回歸,指數回歸,支持向量機回歸)建立能耗模型.
4)評估模型.這一步的主要工作是對前面建立起來的能耗模型進行評估,比較所得到能耗預測值與真實值的差別,目的是確定該模型的準確性和有效性.
2.1 各部件能耗的代表參數
作為云計算數據中心的任何一臺服務器,哪些參數應該被選擇去構建能耗模型呢?如果參數選擇過少,將導致構建出來的能耗模型精度不夠,如果參數選擇過多,將導致開銷增加且不利于該模型的擴展.因此,選擇合適的參數構建能耗模型極其重要.對于數據中心的任何一臺服務器,其總功率主要由其處理器(CPU)、內存、磁盤和網絡接口卡的功率決定.設Psystem是服務器的功率,參數PCPU、Pmemory、Pdisk和Pnetwork分別代表該服務器的處理器(CPU)、內存、磁盤和網絡接口卡功率,則Psystem可以表示如下:
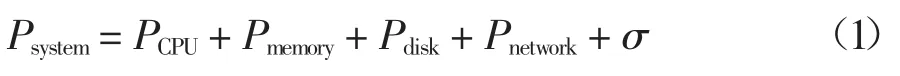
式中:參數σ 是除CPU、內存、磁盤和網絡接口卡之外的其它部件功率,可看作常數.對于處理器的功率PCPU,可用式(2)表達[18]:

式中:參數Pmax代表該部件最大的功率,Pidle代表該部件空閑時的功率,U 代表該部件的CPU 利用率.由于PCPU的值與參數U 相關,所以在監控CPU 的能耗時,參數“Processor Time”被選作處理器的代表性參數.參數“Processor Time”指的是系統中所有處理器都處于繁忙狀態的時間百分比,即CPU 的利用率.對于Pmemory的值,可以用式(3)表達[18]:
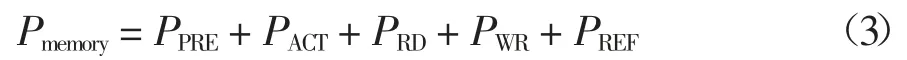
式中:PPRE、PACT、PRD、PWR和PREF分別代表預充電(PPRE)、活動狀態(PACT)、讀狀態(PRD)、寫狀態(PWR)和刷新狀態(PREF)的功率.由于Pmemory的值與讀和寫狀態有關,因此,在監控Pmemory的能耗時,“Memory Used”和“Page Fault/Sec”被選作內存的代表性參數.“Memory Used”指的是內存的利用率,“Page Fault/Sec”指的是處理器處理錯誤頁的綜合速率,單位是錯誤頁數/s.當處理器請求一個不在其工作集(在物理內存中的空間)內的代碼或數據時出現的頁錯誤.這個錯誤包括硬錯誤(那些需要磁盤訪問的)和軟錯誤(在物理內存的其它地方找到的錯誤頁).對于Pdisk的值,可以用式(4)來表示[18]:
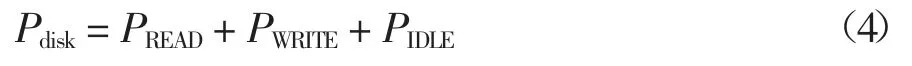
式中:參數PREAD、PWRITE和PIDLE分別代表磁盤讀、寫和空閑時的功率.在監控磁盤的能耗時,“Disk time”和“Disk Bytes/Sec”被選作磁盤的代表性參數.“Disk time”指的是磁盤驅動器忙于讀或寫入請求等服務所用的時間百分比,“Disk Bytes/Sec”指的是在進行寫入或讀取操作時從磁盤上傳送或傳出的字節速率.
對于Pnetwork的值,可以用式(5)計算[18]:

式中:參數C0和C1可認為是一個常數,參數S 指的是文件大小,單位是MB;參數B 指的是帶寬,單位是MB/s.在監視網絡接口卡的能耗時,“Bytes Total/Sec”和“Current Bandwidth”被選作網絡接口卡的代表性參數.“Bytes Total/Sec”指的是在每個網絡適配器上發送和接收字節的速率,包括幀字符在內.“Current Bandwidth”指的是目前帶寬.
2.2 計算密集型任務的參數選擇
計算密集型任務也叫CPU 密集型任務.全球標準性能評估公司SPEC 提供的CPU2006[19-20]數據集就是標準計算密集型任務,該數據集包含“401.bzip2”、“403.gcc”、“429.mcf”、“453.povray”和“450.soplex”等子項.以DELL PowerEdge R720 服務器為例(服務器配置見表1),當它運行“401.bzip2”任務時,其在不同負載下的能耗和相關參數值如表2 所示.

表1 DELL R720 服務器配置Tab.1 Dell R720 server configuration
從表2 得出:當“Processor Time”=4.23%,Memory Used=4.47%,Page Fault/Sec=512.78,Disk Time=0.66,Disk Bytes/Sec=4 102.28,Bytes Total/Sec=562.00 和Current Bandwidth=9.22 ×1018時,此時的能耗為122.49 W.對于這7 個參數(Processor Time,Memory Used,Page Fault/Sec,Disk Time,Disk Bytes/Sec,Bytes Total/Sec 和Current Bandwidth),它們是如何影響能耗的呢?哪些與能耗相關?哪些與能耗不相關呢?為解決這個問題,利用SPSS 中的“主成分分析法”[21]分析每個參數的貢獻(即因子貢獻),表3 列出了每個因子的貢獻.
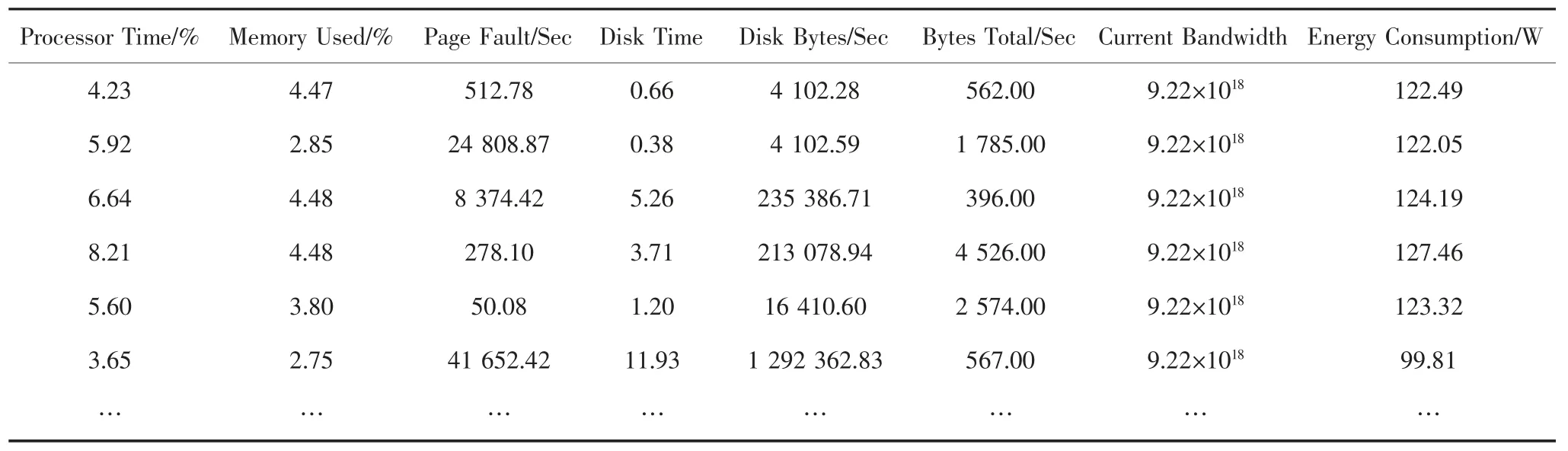
表2 不同負載下的參數值及能耗Tab.2 Parameter values and energy consumption under different loads

表3 計算密集型任務下因子貢獻Tab.3 Factor contribution under computation-intensive tasks
表3 表明:參數“Processor Time”對能耗的貢獻是62%,“Disk Bytes/Sec”是19%,“Disk Time”是14%,“Page Fault/Sec”是4%,“Memory Used”是1%,“Bytes Total/Sec”和“Current Bandwidth”都是0.這些數據說明,“Processor Time”對能耗的貢獻最大,而“Bytes Total/Sec”和“Current Bandwidth”對能耗沒有貢獻.因此,在下一節能耗建模中,值不為零的5 個參數“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”被選中用于實驗建模.
與此相似,在現實生活中,我們干掉高考這個BOSS以后,武功進入了一個瓶頸期,每個人的斗志也因此消磨許多。所以,我們不妨試著將這四年的大學時光,當作是一段特殊的“閉關修煉”,修身養性,格物致知,潛心修煉內功和外功。在不斷提升自我的同時,抵御綁定了潛在風險的外來誘惑。
2.3 Web 事務型任務的參數選擇
HP LoadRunner[22-23]是一種典型的Web 事務型任務,以DELL PowerEdge R720 服務器為例(服務器配置見表1),當它運行“HP LoadRunner”任務,在用戶數是3 000 時,采用同樣的辦法可以得到每個參數對能耗的貢獻即因子貢獻,表4 展示了這7 個參數(Processor Time,Memory Used,Page Fault/Sec,Disk Time,Disk Bytes/Sec,Bytes Total/Sec 和 Current Bandwidth)對能耗的貢獻.
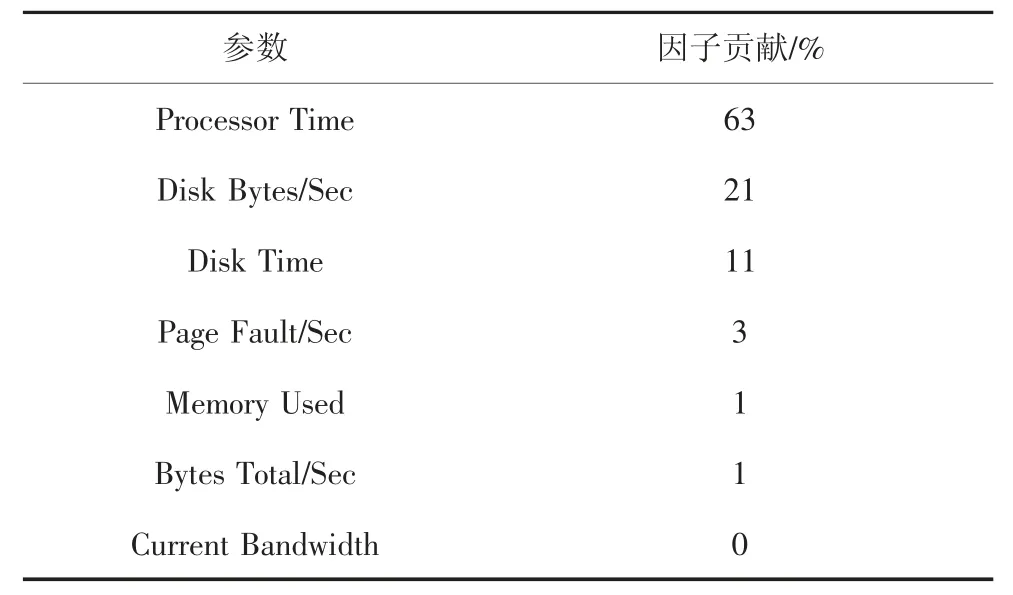
表4 Web 事務型任務下因子貢獻Tab.4 Factor contribution under Web transactional tasks
從表4 可以看出,參數“Processor Time”對能耗的貢獻是63%,“Disk Bytes/Sec”是21%,“Disk Time”是11%,“Page Fault/Sec”是3%,“Memory Used”是1%,“Bytes Total/Sec”是1%,“Current Bandwidth”是0.這些數據說明,“Processor Time”對能耗的貢獻最大,而“Current Bandwidth”為0 即表示對能耗沒有貢獻.因此,在下一節能耗建模中,值不為零的6 個參數“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”,“Memory Used”和“Bytes Total/Sec”被選中用于實驗建模.
2.4 I/O 密集型任務的參數選擇
Iozone[24-25]是一種典型的I/O 密集型任務,以DELL PowerEdge R720 服務器為例(服務器配置見表1),當它運行Iozone 數據集時,采用同樣的辦法可得到每個參數對能耗的貢獻即因子貢獻,表5 展示了這7 個參數(Processor Time,Memory Used,Page Fault/Sec,Disk Time,Disk Bytes/Sec,Bytes Total/Sec和Current Bandwidth)對能耗的貢獻.從表5 可以看出,參數“Processor Time”對能耗的貢獻是53%,“Disk Bytes/Sec”是27%,“Disk Time”是15%,“Page Fault/Sec”是3%,“Memory Used”是1%,“Bytes Total/Sec”和“Current Bandwidth”都是0.這些數據說明,“Processor Time”對能耗的貢獻最大,而“Bytes Total/Sec”和“Current Bandwidth”都為0 即表示對能耗沒有貢獻.因此,在下一節能耗建模中,值不為零的五個參數“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”都被選中用于實驗建模.
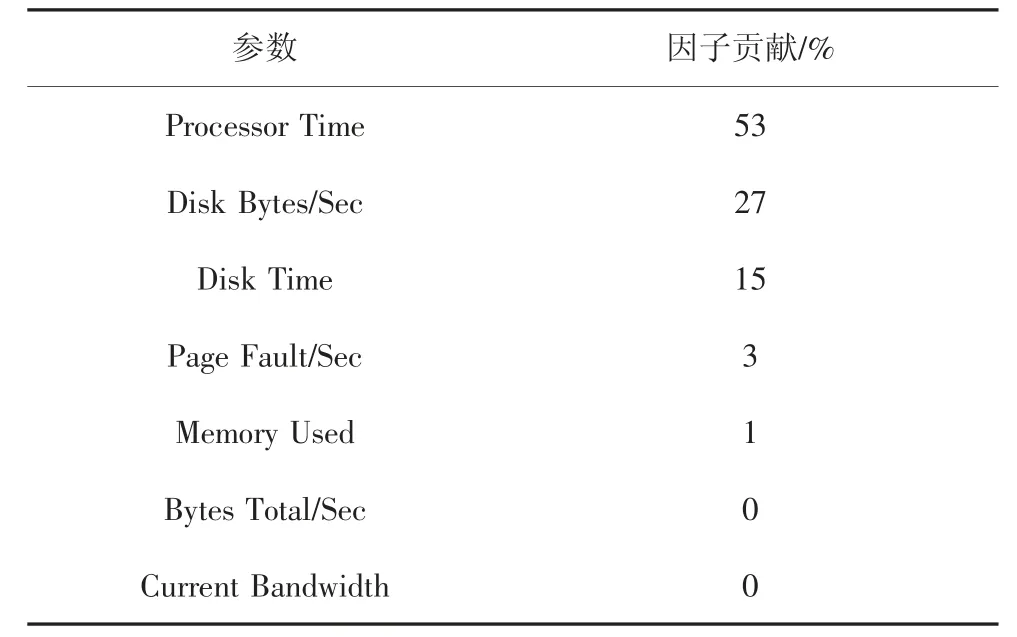
表5 I/O 密集型任務下因子貢獻Tab.5 Factor contribution under I/O intensive tasks
3 能耗建模
對于不同的任務類型,第二節已確定有那些參數被選中用于能耗建模.在這一節中將使用EViews 8.0[26]軟件,分別用多元線性回歸法、冪回歸法、指數回歸法和多項式回歸法建立能耗模型.對于多元線性回歸法,其包含m 個因變量的回歸模型如下:
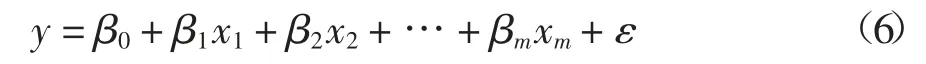
式中:變量y 是觀測到的真實能耗;β0,β1,β2,…,βm是回歸系數;ε 是隨機誤差.對于冪回歸法,其包含m個因變量的回歸模型如下:
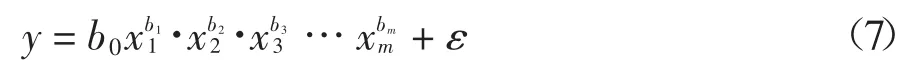
式中:變量y 是觀測到的真實值;b0,b1,b2,…,bm是回歸系數;ε 是隨機誤差.對于指數回歸法,其包含m個變量的回歸模型如下:
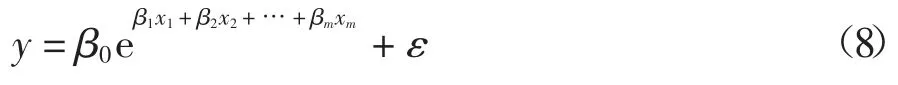
式中:變量y 是觀測到的真實值;β0,β1,β2,…,βm是回歸系數;ε 是隨機誤差.對于多項式回歸,其包含m個變量的回歸模型如下:
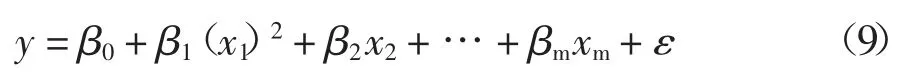
式中:變量y 是觀測到的真實值;β0,β1,β2,…,βm是回歸系數;ε 是隨機誤差.
為方便3.1~3.3 節中所述內容的說明,表6 列出了常用的參數及其代表的含義.

表6 參數及其含義Tab.6 Parameters and their meanings
3.1 計算密集型任務的能耗模型
對于計算密集型任務CPU2006[19-20]數據集,結合2.2 節的代表性參數和EViews 8.0[26]軟件,分別用多元線性回歸法、冪回歸法、指數回歸法和多項式回歸法建立能耗模型,見公式(10)~(13):

式中:參數y,x1,x2,x3,x4,x5分別代表能耗“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”.
3.2 Web 事務型任務的能耗模型
對于Web 事務型任務HP LoadRunner[22-23],在用戶數3 000 情況下,結合2.3 節的代表性參數和EViews 8.0[26]軟件,分別用多元線性回歸法、冪回歸法、指數回歸法和多項式回歸法建立能耗模型,見公式(14)~(17):

式中:參數y,x1,x2,x3,x4,x5,x6分別代表能耗“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”,“Memory Used”和“Bytes Total/Sec”.
3.3 I/O 密集型任務的能耗模型
對于I/O 密集型任務Iozone[24-25],結合2.4 節的代表性參數和EViews 8.0[26]軟件,分別用多元線性回歸法、冪回歸法、指數回歸法和多項式回歸法建立能耗模型,見公式(18)~(21):
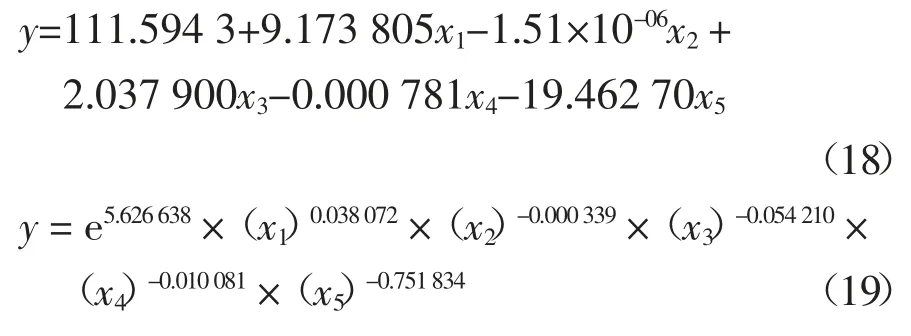

式中:參數y,x1,x2,x3,x4,x5分別代表能耗“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”.
4 實驗結果及分析
本文所用的服務器是DELL PowerEdge R720 服務器(見表1),CPU 頻率是2.0 GHz(2×6 核),內存是DDR2 20 G,磁盤是2×1 TB,網絡接口卡是Intel quad-port Gigabit network adapter.實驗測量能耗的工具是北電儀表公司所生產的Power Bay-SSM.計算密集型任務使用的是“403.gcc”,“429.mcf”,“401.bzip2”,“453.povray”和“450.soplex”數據集[19-20].對于“Web 事務型任務”和“I/O 密集型任務”,則分別使用“Load-Runner”[22-23]和“Iozone”數據集[24-25],這兩個數據集每次產生任務都是“隨機生成”.
為評價本文所建模型的精度,采用式(22)計算每個模型的相對誤差:
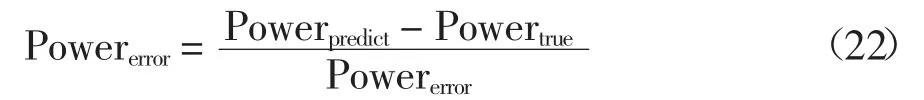
式中:Powerpredict表示能耗的預測值;Powertrue表示能耗的真實值;Powererror表示能耗的相對誤差.
為評價能耗模型的好壞,選擇Linear Model[12],Cubic Model[11]和Ramon Model[15]能耗模型作對比.
4.1 計算密集型任務的實驗結果及分析
利用3.1 節所建立的能耗模型,運行計算密集型任務CPU2006[19-20]數據集,得到預測值和真實值的相對誤差,如圖2 和圖3 所示.
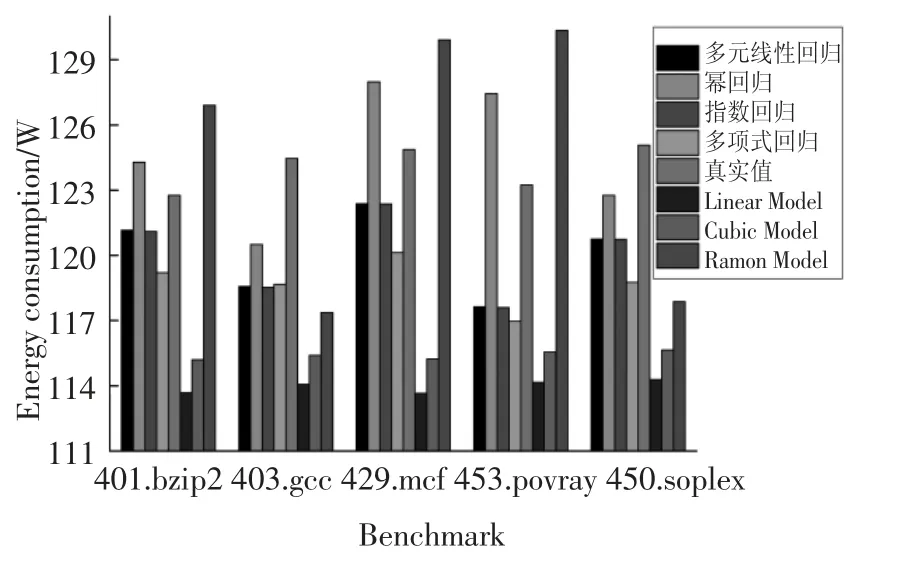
圖2 計算密集型任務下各模型的能耗Fig.2 Energy consumption of each model under computation-intensive tasks
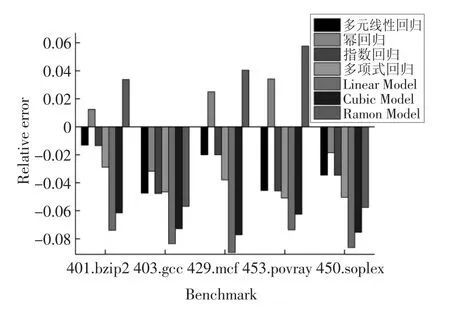
圖3 計算密集型任務下各模型相對誤差Fig.3 Relative error of each model under computation-intensive tasks
圖2 和圖3 分別展示了這7 種能耗模型(多元線性回歸、冪回歸、指數回歸、多項式回歸、Linear Model、Cubic Model 和Ramon Model)的能耗和相對誤差.這4 種模型(多元線性回歸、冪回歸、指數回歸和多項式回歸)優于Ramon Model,原因在于兩方面:第一,這4 種模型在建模時考慮了處理器(CPU)、內存、磁盤和網絡接口卡因素,而Ramon Model 僅考慮處理器(CPU)和內存因素.第二,這4 種模型(多元線性回歸、冪回歸、指數回歸和多項式回歸)考慮了任務的特征并利用“主成分分析法”提高了能耗模型的精度.Ramon Model 優于Linear Model 和Cubic Model,原因在于其考慮了處理器(CPU)和內存兩個因素,而Linear Model 和Cubic Model 僅考慮CPU 因素.
4.2 Web 事務型任務的實驗結果及分析
利用3.2 節所建立的能耗模型,運行Web 事務型任務HP LoadRunner[22-23],在用戶數3 000 情況下,得到預測值和真實值的相對誤差,如圖4 和圖5 所示.
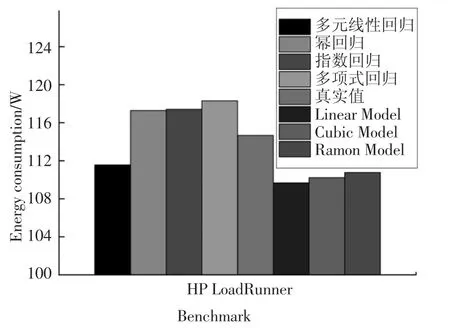
圖4 Web 事務型任務下各模型的能耗Fig.4 Energy consumption of each model under Web transactional
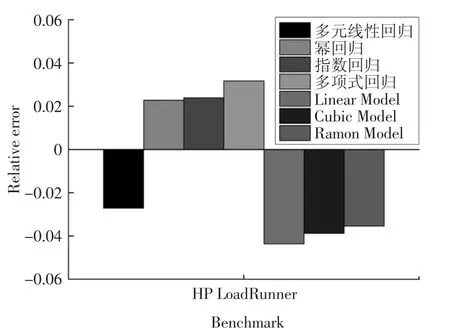
圖5 Web 事務型任務下各模型相對誤差Fig.5 Relative error of each model under Web transactional tasks
圖4 和圖5 分別展示了這7 種能耗模型(多元線性回歸、冪回歸、指數回歸、多項式回歸、Linear Model、Cubic Model 和Ramon Model)的能耗和相對誤差.這4 種模型(多元線性回歸、冪回歸、指數回歸和多項式回歸)相比較Ramon Model,其能耗精度提高1%以上,其原因可歸結為兩方面:第一,Web 事務型任務的特點決定了該類任務對內存和網絡的訪問較為頻繁,Ramon Model 只考慮了CPU 和內存因素,而這4 種能耗模型考慮了處理器、內存、磁盤和網絡接口卡這4 個因素.第二,這4 種模型考慮了任務的特征并利用“主成分分析法”提高了能耗模型的精度.
4.3 I/O 密集型任務的實驗結果及分析
利用3.3 節所建立的能耗模型,運行I/O 密集型任務Iozone[24-25]數據集,得到預測值和真實值的相對誤差,如圖6 和圖7 所示.
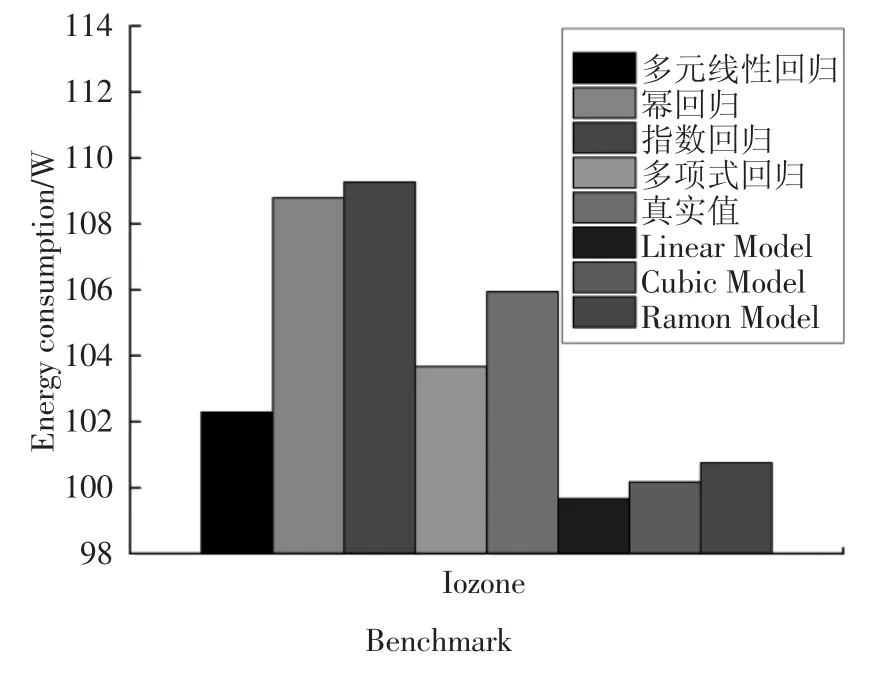
圖6 I/O 密集型任務下各模型的能耗Fig.6 Energy consumption of each model under I/O intensive tasks
圖6 和圖7 分別展示了這7 種能耗模型(多元線性回歸、冪回歸、指數回歸、多項式回歸、Linear Model、Cubic Model 和Ramon Model)的能耗和相對誤差.圖7 表明,這4 種能耗模型(多元線性回歸、冪回歸、指數回歸和多項式回歸)相比較Linear Model,Cubic Model 和Ramon Model,其能耗精度提高3%左右,其原因可歸納為以下兩個方面:第一,I/O 密集型任務的特點是對磁盤的訪問較為頻繁,因此在建模時應該考慮處理器、內存和磁盤多個因素.這4 種能耗模型考慮了處理器、內存、磁盤和網絡接口卡這4個因素.第二,這4 種模型考慮了任務的特征并利用“主成分分析法”提高了能耗模型的精度.
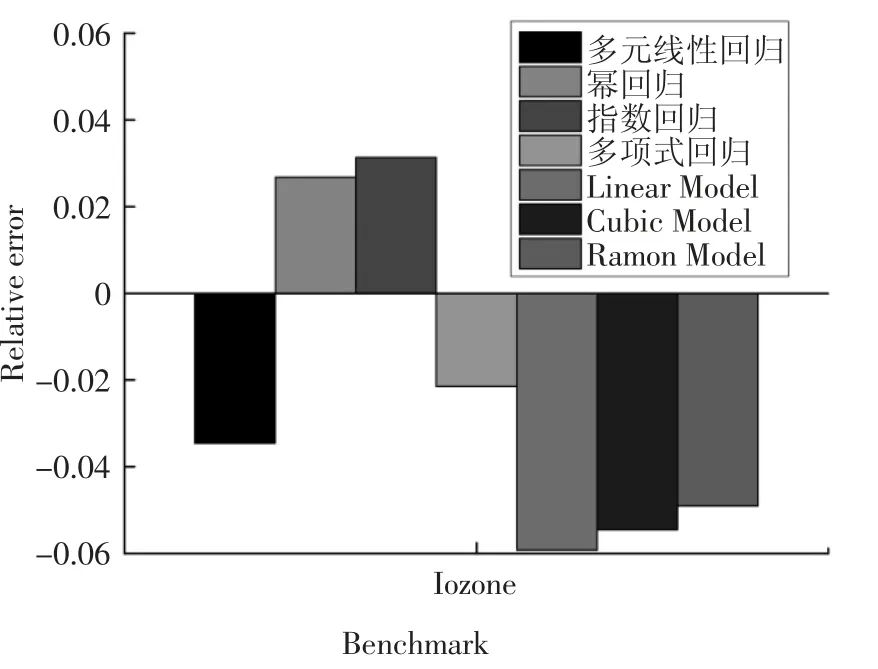
圖7 I/O 密集型任務下各模型相對誤差Fig.7 Relative error of each model under I/O intensive tasks
4.4 4 種模型的對比
根據4.1、4.2 和4.3 節中的實驗結果和分析,不管何種任務類型(計算密集型任務、Web 事務型任務和I/O 密集型任務),冪回歸模型精確度最高,多元線性回歸模型一般,指數回歸模型和多項式回歸模型較差.因此,在以后的能耗建模中,推薦使用冪回歸模型進行能耗建模.
5 總結
針對數據中心服務器能耗模型精度低的問題,本文根據“任務的特征”結合“主成分分析法”構建了新型的能耗模型.與其它的能耗模型對比,本文所構建的能耗模型在精度方面提高了3%,其原因可歸結為:1)本文所構建的能耗模型考慮了“任務的特征”;2)在能耗模型的構建過程中,考慮了CPU、內存、磁盤和網絡接口卡多個因素;3)利用“主成分分析法”篩選出了與能耗有關的部件.
本文所提出的模型有望用于云計算數據中心,為數據中心服務器能耗的“量化”提供理論和實踐依據.同時,本文所提出的模型也可用于評估節能算法的優劣,有助于資源提供者預測和優化數據中心的能耗.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
