基于集成學習的疾病預測模型研究
2021-04-29 06:56:26劉金花王洋趙婧
微型電腦應用 2021年4期
劉金花, 王洋, 趙婧
(1. 山西醫科大學汾陽學院 衛生信息管理系, 山西 汾陽 032200;2. 北方自動控制技術研究所, 山西 太原 030006)
0 引言
目前大多數人遭受各種慢性疾病的困擾,如心血管疾病、糖尿病、腎衰竭等,病人除了需要花費大量時間和金錢進行治療外,還會遭受各種并發癥的困擾[1]。因此,慢性疾病的早期識別和檢測已成為全球的熱點問題,并在臨床實踐中發揮著至關重要的作用。近年來,各種數據挖掘技術和機器學習算法被用來預測和診斷疾病。但是,現有模型都假設用于訓練模型的數據是完美的。
本研究的主要目的是以糖尿病為例建立一種具有更高可靠性能的疾病預測模型,綜合考慮并解決了目前模型中存在的數據的缺失值、數據類別不平衡和分類評價指標選取三個問題。首先,采用補償算法對缺失數據進行填補。然后,選擇一種合適的過采樣技術來解決類別不平衡問題。最后,通過一組對比實驗來選擇合適的、優秀的分類器。本研究所提模型的框架,如圖1所示。
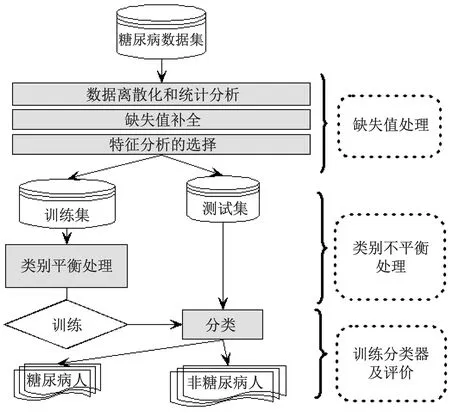
圖1 本研究所提模型的框架圖
在整個實驗過程中,采用了臨床試驗中比較關注的指標來評價分類性能。實驗表明,本研究所提模型在皮馬印第安人糖尿病數據集上取得了較高的性能,比同一數據集上的其他預測模型性能更好、更可信。
1 相關工作
目前已經提出了許多糖尿病的預測模型。V. Anuja Kumari[2]采用以徑向基函數為核的支持向量機,準確率達到78%。Vijayan[3]采用AdaBoost算法,以決策樹(Decision Tree,DT)、貝葉斯(Na?ve-Bayes,NB)、支持向量機(Sup-port Vector Machine,SVM)和決策殘差作為基分類器,使用決策殘差獲得了80.72%的最佳準確率。Maniruzzaman[4]發現醫學數據的結構具有非正態性、非線性和內在相關性。因此,他們采用了基于高斯過程的分類,采用了線性、多項式和徑向三種核的分類方法,使用徑向核的分類準確率達到了81.97%。前面所述這些文獻都是在原始數據集上直接進行實驗,而沒有考慮數據的質量。Maniruzzaman[5]首先用中位數替換缺失數據和離群值,提取糖尿病數據集的特征。對比10種不同的分類器,實驗表明,隨機森林(Random Forest,RF)特征選擇和RF分類技術的準確率為92.26%,靈敏度為95.96%,特異度為79.72%。Birjais[6]采用K-近鄰(K-Nearest Neighbors,KNN)對缺失數據進行填補,梯度提升分類器的準確率達到86%。但這些方法的數據中均存在大量缺失和類別不平衡問題。
2 研究材料和方法
2.1 數據分析和缺失值填補法
本研究使用的數據來自UCI機器學習知識庫的皮馬印第安人糖尿病數據集[7-8]。對該數據集屬性的描述,如表1所示。
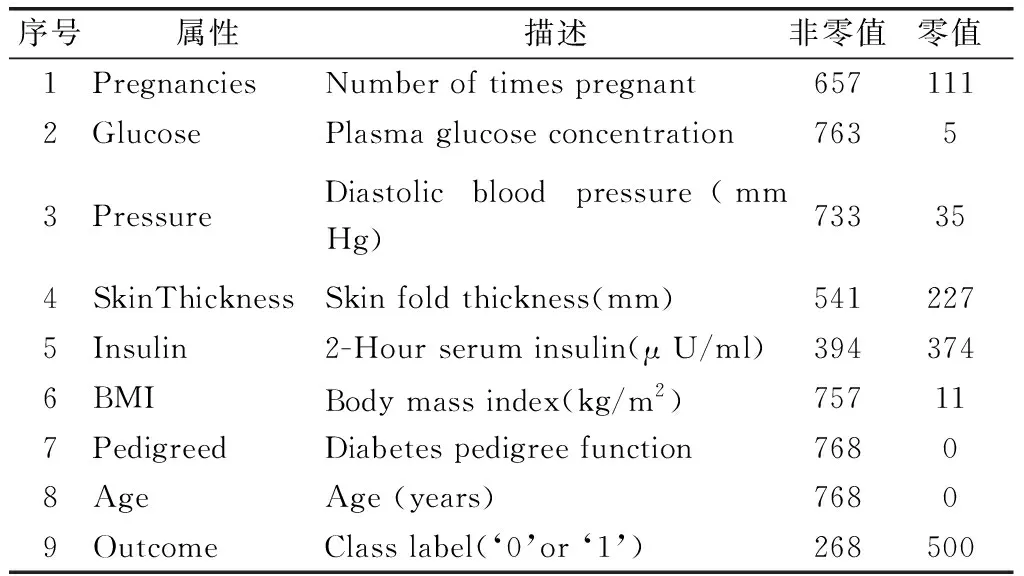
表1 皮馬印第安人糖尿病數據集描述及缺失值統計
包括268名患者和500名非患者。很明顯,患者人數遠遠超過非患者。舉一個極端的例子,如果所有的樣本都預測為非糖尿病患者,就可以達到65.1%的準確率。不平衡數據集會削弱學習算法預測少數類別的能力,這個結論已經得到了驗證[9]。因此,在數據類別不平衡的學習任務中,僅用準確率來評價分類性能是不可信的。此外對數據集進行了統計分析,因為有大量缺失值。
各類大數據集中特別是醫療數據中存在大量的缺失值是很正常的,然而,數據的純度和完整性是機器學習算法的基礎。補償法是處理缺失值最常見的手段。在這里,本研究采用了條件均值填補方法,即根據類標簽將數據集分為糖尿病和非糖尿病兩組,缺失的值由每個組的平均值替換。
2.2 特征選擇和分析
在基于機器學習的研究中,良好的數據是基礎,而特征是數據表示的基石。糖尿病數據集有8個屬性(特征),本研究還對數據進行了基于皮爾森相關系數的特征相關分析,如圖2所示。
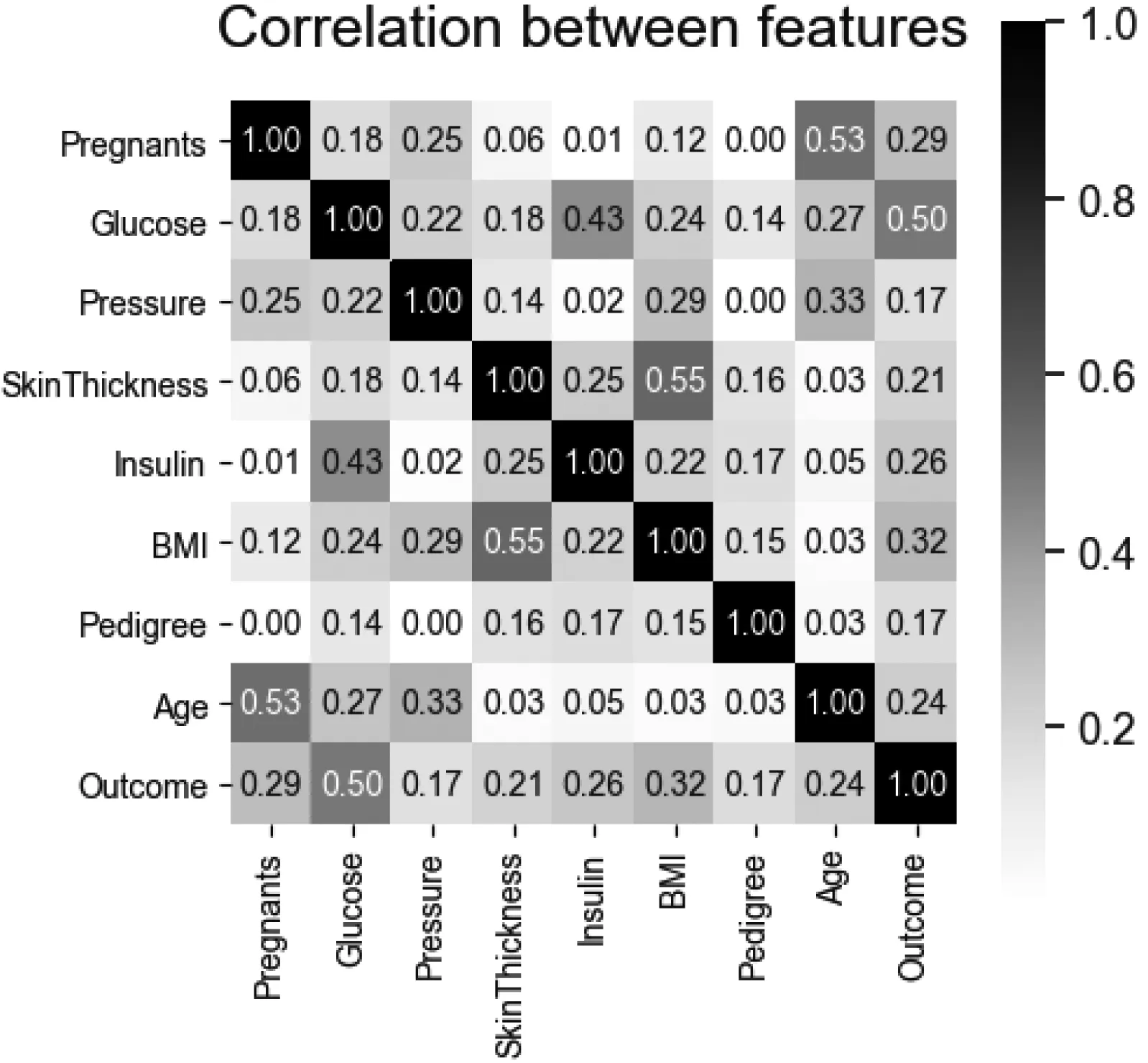
圖2 糖尿病數據集間特征的相關性分析
所有8個特征與結果呈正相關。而血糖、BMI、胰島素、懷孕次數是糖尿病的重要特征。此外,年齡與懷孕、血壓這兩屬性的相關性較大,BMI與皮瓣厚度的相關性較大。所以選擇了除了Pedigreed 屬性之外的其他7個屬性作為最后的特征。
2.3 數據類別平衡處理
針對類別不平衡問題,已經提出了許多解決方案,如欠采樣、過采樣、代價敏感學習法、基于集成的方法等[10]。由于人工合成少數類樣本的過采樣技術(Synthetic Minority Over-sampling Technique,SMOTE)是通過隨機生成新實例來擴充數據,而不是簡單地從原始數據中復制現有樣本[11]。因此,這里使用了SMOTE來解決類不平衡的問題。
對于給定的少數類樣本x,求得它與其他少數類樣本之間的最近鄰,并計算它們的差值(距離)。然后,隨機選取0和1之間的數乘以該差值,并將其添加到原始樣本x中。生成新樣本,如式(1)。
(1)

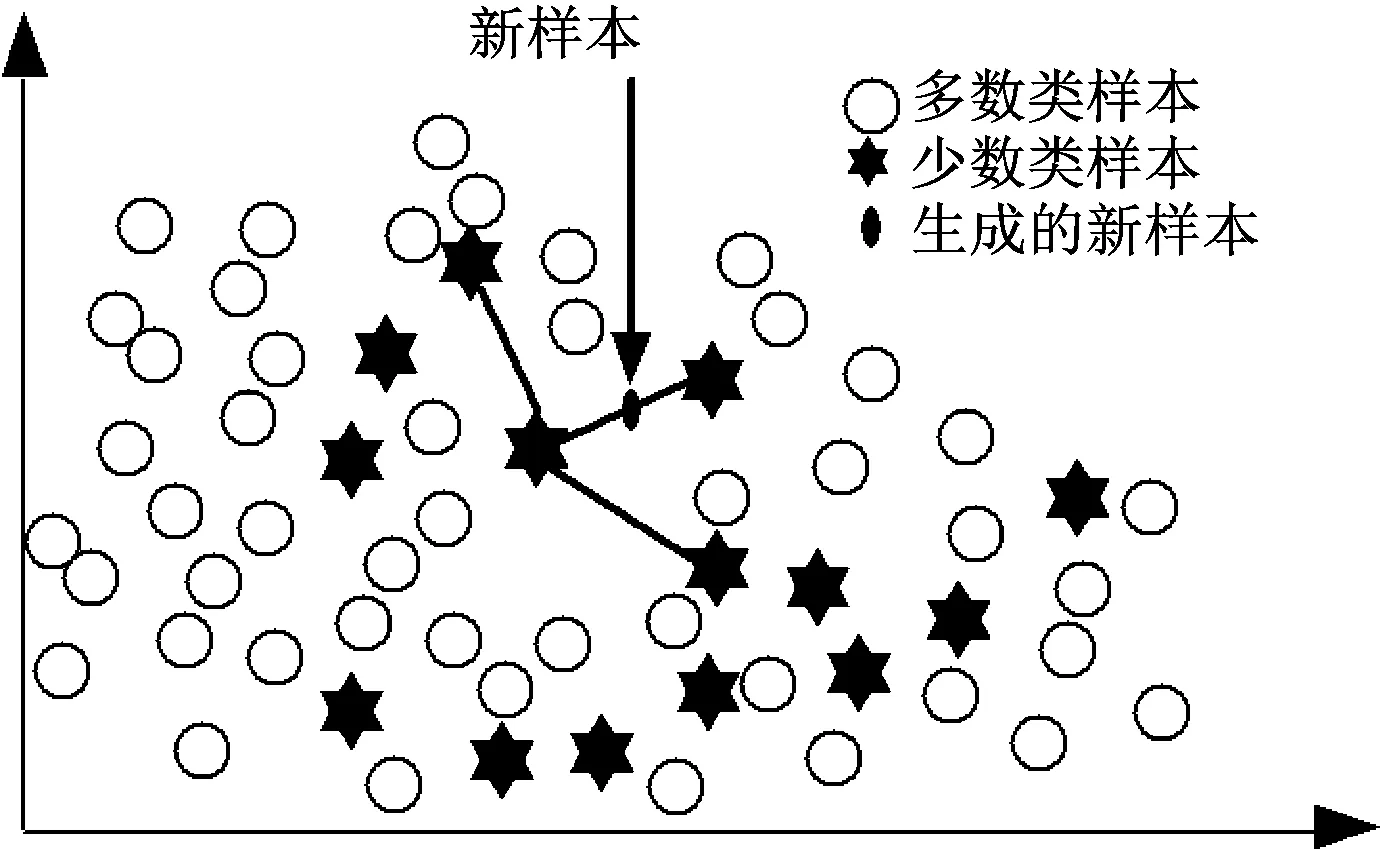
圖3 SMOTE生成新樣本的過程
3 梯度提升樹
梯度提升決策樹(Gradient boost decision tree,GBDT)是另一種強大的集成算法。其核心思想與隨機森林一樣,GBDT采用迭代的方法建立決策樹,并通過減少損失函數對模型進行評估。沿著損失函數梯度下降的方向,GBDT不斷更新當前模型的參數,不斷地對模型進行調優使損失函數收斂到全局最小。

(1) 初始化預測模型F0(x)為一常數,如式(2)。
(2)
其中決策樹分類器γ也初始化為常數。
(2) 循環迭代m=1:K(K為最大迭代次數). 每迭代一次構建一個基于回歸樹的弱分類器,并且生成相應的預測值Fm(x). 負的梯度計算,如式(3)。
-gk(x)=-[?L(yi,F(xi))/?F(xi)]F(x)=Fm-1(x)
i={1,2,…,N}
(3)
(3)h(x;αm)為弱分類器建立的回歸樹,第m個回歸樹應該沿著m-1次損失函數梯度下降的方向建立。因此,參數αm利用式(4)進行更新。
(4)
(4) 沿梯度下降的方向優化步長,將使損失函數逐步變小,如式(5)。
(5)
(5) 在每次迭代后,模型的預測函數將隨之進行更新,如式(6)。
Fm(x)=Fm-1(x)+βmh(xi;α)
(6)
4 實驗與分析
4.1 實驗設置
為了消除屬性之間的差異,在實驗之前,首先得對數據進行歸一化處理。為了獲得穩定可信的結果,本實驗采用了十折交叉驗證策略。
4.2 評價指標
由于糖尿病數據存在缺失和類別不平衡的問題,本研究引入更多的指標來充分評價分類性能。除了ACC、靈敏度、特異度,還有接受者操作特性曲線(Receiver Operating Characteristics, ROC)和ROC曲線下的面積(Area under the ROC,AROC)。AROC指標是一種較好的醫學診斷指標,在理論和實踐上都得到了驗證。上面提到的這些指標都是基于混淆矩陣定義的。混淆矩陣,如表2所示。

表2 混淆矩陣
準確率(Accuracy,ACC)是指分類器正確預測陽性樣本或陰性樣本的能力。如式(7)。
(7)
靈敏度(Sensitivity,SEN)表示分類器在實際陽性樣本中識別陽性項的能力。SEN與醫學上的漏診率密切相關,如式(8)、式(9)。
(8)
MissedDiagnosisRate=1-Sensitivity
(9)
一般來說,一個好的疾病預測模型應該提高SEN,降低漏診率,因為陽性樣本指的是糖尿病患者。反之,特異性(Specificity,SPE)則表示分類器識別實際陰性樣本中陰性項的能力SPE在醫學上與誤診率有關,如式(10)、式(11)。
(10)
MisdiagnosisRate=1-Specificity
(11)
特異性是醫學上的另一個主要指標,SPE越低,誤診率越高。因此,一個良好的診斷模型應盡量減少誤診率和漏診率,也就是提高診斷的SEN和SPE。
ROC是一個綜合指標,權衡SEN和SPE。ROC曲線是以SEN為縱坐標,1-SPE(也稱為誤診率)為橫坐標繪制的曲線。AUC是ROC的數量指標,指ROC曲線下方的面積。理論上,AUC的取值為[0,1],在理想的分類器中,AUC的值應該是1。
5 結果與討論
為了驗證本研究所提方法在每個階段的性能,設計了多組對比實驗。此外,除了本研究提到的GBDT算法外,還選取了RF、NB、DT和邏輯回歸(Logistic Regression,LR)三種傳統的分類算法進行實驗。本研究采用5個分類器對原始的糖尿病數據集進行分類,并將其結果作為基準,如表3所示。
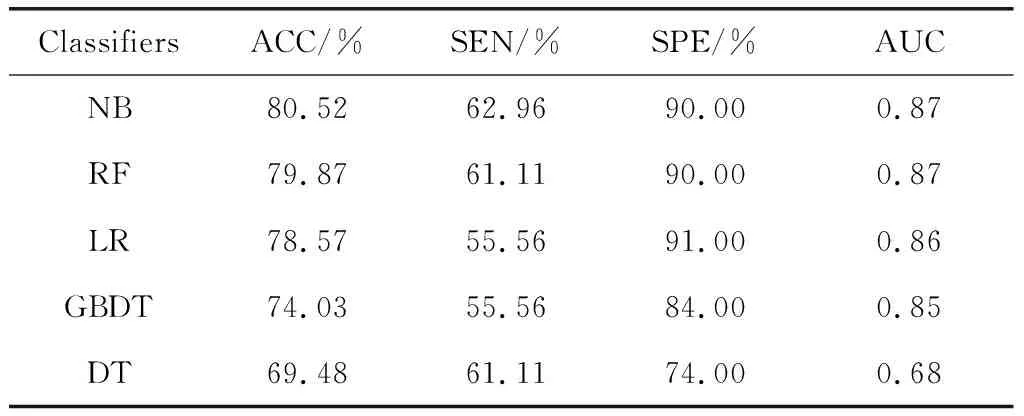
表3 在原始數據集上分類性能比較
先忽略準確率,從表3可以看出每個分類器的靈敏度較低,即醫學上的漏診率較高,顯然不符合臨床診斷試驗的要求。
數據經過條件均值補全法填補,又經過SMOTE處理后,得到了完整的類別平衡的訓練數據,如表4所示。

表4 在平衡數據集上訓練分類器的性能比較
表4給出了在平衡數據中訓練模型得到的測試分類性能。從表4可看出,各分類器的SEN均有提高,特別是GBDT和RF算法,但各分類器的SPE有所下降。這是合理的,因為SEN和SPE本質上是矛盾的。五種分類算法的ROC曲線,如圖4所示。
顯然GBDT相比其他具有更強的鑒別能力,而RF的分類性能略低,但在運行時間上如前面所述,RF要比GBDT更好。因此,可以根據自己的情況選擇分類器。
所提模型與現有模型的對比,如表5所示。本研究所提模型的準確率落后于Maniruzzaman et[5],然而,他們是在類別不平衡的數據中進行的實驗,ACC會傾向多數類,不可信。因此,在不同分布的訓練數據中進行實驗,ACC不具可比性。除去ACC,可以看到本研究所提模型的SEN和SPE都高于其他模型。從臨床實踐的角度來看,本研究模型優于其他模型。
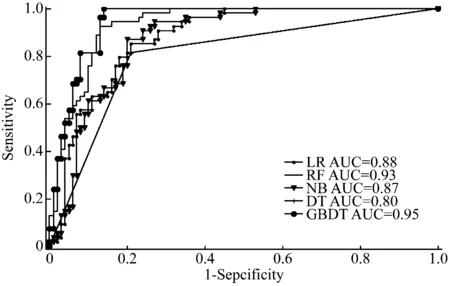
圖4 不同分類器的ROC曲線比

表5 與現有模型進行比較
6 總結
針對慢性疾病的預測與早期識別,本研究綜合解決了在已有預測模型中存在的問題,利用條件均值法對缺失數據進行填補。類別不平衡導致分類結果不可信、不可靠,本研究利用SMOTE算法對數據進行平衡處理。此外,與以往的評價指標不同,本研究采用臨床診斷試驗中更常用的SEN、SPE和ROC來評價預測結果。GBDT與其他常規分類器相比,其預測ACC為90.26%,SEN為100%,SPE為85%,AUC為0.95,表現出良好的性能。此外,同樣的方法可以推廣到預測其他類型的疾病。預測結果可以提醒醫生和病人及早控制和治療。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2022年5期)2022-08-24 02:35:42
中老年保健(2022年1期)2022-08-17 06:14:56
中老年保健(2021年5期)2021-08-24 07:07:20
中老年保健(2021年11期)2021-08-22 03:15:16
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
