二類不均衡數據分類問題常用策略研究
2021-05-04 11:06:54楊小軍王力猛
智能計算機與應用 2021年11期
楊小軍,劉 志,王力猛,劉 文
(國防大學 聯合勤務學院,北京 100858)
0 引 言
分類是數據挖掘領域的一類重要問題,現有的分類方法都很成熟,如決策樹、支持向量機、樸素貝葉斯方法等,并利用這些方法成功地解決了許多實際問題。但隨著應用范圍的擴大和研究的深入,分類方法在使用過程中遇到了數據樣本分布不均衡問題。通常稱數據分布不均衡的數據集為不均衡數據集,數據分布不均衡表現為兩種形式:一是類間數據分布不均衡;二是在某一類樣本的內部存在著類內不均衡。在不均衡數據集中,將樣本數量少的類稱為少數類或正類,樣本數量多的類稱為多數類或負類。
對不均衡數據進行正確分類,是數據分類的一個難題。問題來源于不均衡數據集的樣本分布特點,以及傳統分類算法固有的局限性。傳統分類算法的重要前提是:數據集中各樣本比例是均衡的;以總體最大精度為目標,很容易忽略少數類;所有的分類錯誤代價都相同。因此,如果用傳統的分類器來直接處理不均衡數據集,會造成少數類樣本的分類精度較差,尤其是數據不均衡嚴重時更是如此。鑒于目前研究不均衡分類問題都是基于不均衡的兩類問題,則本文主要研究比較二類不均衡數據分類問題的常用策略。
1 不均衡數據分類策略
常用的不均衡數據分類策略主要有如下幾類:在數據層面,通過重采樣來解決數據分布不均衡狀況;在算法層面,通過代價敏感算法或是集成算法提升不均衡數據分類時的性能;通過數據層面與算法層面相結合的策略進行改進。
1.1 數據層面的處理方法
由于不均衡數據集是數據樣本之間比例不均衡,可通過對各類別數據的增刪,重新實現不同類別數據樣本之間的平衡。數據重采樣是最具代表性的數據層面處理辦法,可將其分為欠采樣、過采樣,以及二者結合的混合采樣方法。最簡單的重采樣為隨機過采樣(ROS)方法和隨機欠采樣(RUS)方法。通過簡單復制/刪除部分樣本的方式,達到平衡二類樣本比例的目的。而隨機方法的缺點是增加了過學習的概率。因此目前考慮更多的是啟發式方法。
Chawla提出的SMOTE[1]方法,是一種經典的啟發式過采樣方法。SMOTE方法首先為每一個少數類樣本隨機地挑選出幾個相鄰的樣本,然后在這個少數類樣本和挑出的鄰近樣本的連接線上,以隨機方式取點,生成沒有重復的少數類樣本。因此,在很大程度上解決了隨機過采樣方法產生的過擬合問題。此后,在SMOTE方法的基礎上形成了大量的改進算法:如D-SMOTE過抽樣算法,是采用求最近鄰樣本均值點的方法來生成少數類樣本;N-SMOTE算法[2],則采用了周圍空間結構信息的鄰居計算公式來生成少數類樣本等等。
啟發式欠采樣方法為達到更好的分類效果,采用方法去除掉那些遠離分類邊界的、有數據重疊的、且對分類作用不大的多數類樣本。典型的欠采樣方法有Tomek links方法[3]和ENN方法等。Tomek links方法是先判斷兩個不同類樣本之間是否構成了Tomek links,是則進行樣本剪輯;ENN算法的基本思想是,刪除離每個多數類樣本最近的3個近鄰樣本中的2個。在實際應用中,為了達到最佳效果,一般將各種欠采樣和過采樣方法混合使用。在增加少數類數據樣本同時,減少了多數類數據樣本,最終達到兩類數據樣本平衡的目的。SMOTE+Tomek links、SMOTE+ENN[4]是典型的混合采樣方法。
1.2 算法層面處理方法
在算法層面,不均衡數據學習常用的方法有:代價敏感算法、集成學習方法、單類學習方法和特征選擇方法。
1.2.1 代價敏感算法
傳統分類器以實現樣本整體誤差最小為最終目標。在訓練過程中,由于數量偏少的緣故,少數類樣本的預測準確率很低,甚至出現被忽略的情況。為了提升少數類的重要程度,代價敏感算法給少數類樣本造成的誤差施加更大的懲罰。算法的中心思想是:運用該方法訓練分類器的目標是最小化樣本的整體誤分代價,不再追求實現樣本整體誤差最小化。代價敏感算法的核心是代價矩陣的設計,其設計是否合理,最終決定了分類模型的性能。在二分類問題中,代價矩陣見表1。

表1 二分類問題的代價矩陣Tab.1 The cost matrix of binary classification
其中,Cij表示第i類樣本被誤分成j類的代價,應賦大于0的值。左對角線上的元素Cii表示被正確分類的代價,其取值應為0。重要的類別應賦更大的代價,如Cij>Cji表示第i類樣本比第j類更重要。在類不均衡學習中,一般更為關心少數類樣本。如癌癥檢測中的指標異常、機器故障檢測中出現的異常等。因此可將少數類視為重要類,在代價敏感學習中賦予更大的錯分代價[5]。但誤分代價具體取值難以確定。
1.2.2 集成學習算法
集成算法是將多個弱分類器組合構造成一個強分類器。由于單個算法能力有限,找到的多數是局部最優解,而非全局最優解。集成學習算法對多個局部最優解進行綜合,可以提升分類器的性能,已被證明是一種能有效解決不均衡問題的技術。典型的集成算法有裝袋方法(Bagging)和提升方法(Boosting),其主要思想是先對訓練集進行不同方式的訓練,得到不同的基分類器;再對基分類器進行組合,最終達到提升集成分類器學習效果的目的。在Bagging算法中,為了提高集成分類器泛化能力,以有放回的方式從原始訓練集中隨機選取出若干樣例形成訓練集,多次選取不同訓練集以增加基分類器差異度。AdaBoost算法是Boosting方法中的代表,通過在迭代中加大被錯誤分類樣本的權重,減少被正確分類樣本的權重,由有差異的訓練樣本集得到不同的基分類器,最終經過加權集成為最終的分類器。在迭代過程中,Bagging算法每個樣本的權重都一樣,而Boosting算法卻能夠根據樣本的錯誤率不斷調整樣本的權重。因此,在處理不均衡分類問題時,基于Boosting的算法在一定程度上優于基于Bagging的算法[6]。
在實際處理不均衡數據分類時,通常將數據層面的方法與算法層面的方法相結合,解決不均衡分類問題。如,將采樣技術和集成算法結合。其中最典型的是Nitesh V.Chawla提出的SMOTEBoost[7]方法。該方法通過結合SMOTE過采樣技術和AdaBoost提升方法,來解決不均衡數據分類問題。SMOTEBoost算法在訓練開始前,先使用SMOTE方法生成少數類樣本,再使用Adaboost方法對樣本分類,提升了少數類樣本的分類準確率,避免了過擬合。此外,將采樣和代價敏感算法相結合,也是不均衡數據學習的一類重要方法。
對常用的集成算法進一步集成就形成了混合集成算法。為防止采用降采樣技術后,造成多數類樣本信息丟失的情況,Liu等提出EasyEnsemble和BalanceCascade算法[3]。EasyEnsemble算法首先利用Bagging技術對多數類樣本進行多次有放回隨機采樣,形成多個與少數類樣本數量相同的多數類樣本子集;接著將每個多數類樣本子集與少數類樣本組合,用AdaBoost方法訓練分類器;最后將所有的多數類子集所形成的分類器再組合。BalanceCascade算法與EasyEnsemble算法的原理類似,區別之處在于每一次形成多數類樣本子集時,已正確分類的多數類樣本將被從多數類樣本集中去掉。
此外,單類學習方法是在分類時,只識別樣本中的少數類,主要應用于異常檢測領域。特征選擇從已知的特征集合中選擇出代表性特征子集,從而保留原數據的主要信息,其目的是去除冗余特征。在不均衡數據集中選出關鍵的區分特征,將會增強少數類和多數類的區分度,提升分類器中少數類和整體的正確率。
2 不均衡數據分類器評估指標
評價分類器性能的指標有查準率、召回率(查全率)、F-meas ur e、A U C等。對于傳統分類器來說,數據集中多數類和少數類的分布大致保持均衡,分類準確率是最常用的性能評價指標。對不均衡數據集,則不能用準確率去評價一個分類器的好壞了,而常用G-mean和F-measure、A U C作為分類器性能的評估指標。
表2表達的是二類分類結果的混淆矩陣。表中T P和T N分別表示被正確預測的正類、負類樣本數,F P和F N則分別表示被錯誤預測為正類的負類樣本數和被錯誤預測為負類的正類樣本數。因TP+T N是分類器正確預測的樣本數,F P+F N則是分類錯誤的樣本數量,T P+T N+F P+F N是所有數據樣本數量。則分類準確率Acc可以由式(1)得出:

表2 分類結果的混淆矩陣Tab.2 Confusion matrix of classification results
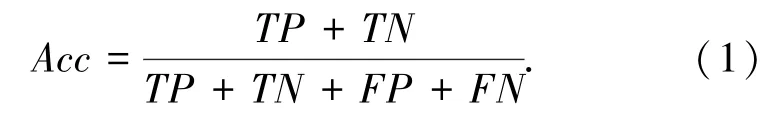
查準率P r eci s i on、召回率(查全率)R ecal l、真正率TP R、真負率T N R等指標,也可由這4個變量,通過以下各式得到:

其中,查準率和召回率是一對矛盾的度量指標,一個指標高時,另一指標往往偏低。為實現兩者之間的平衡,將其合并為一個F-mea s u r e度量。只有當查準率和召回率都高時,F-mea s u r e的值才會大,其計算公式如下:

此外,采用G-mean來衡量真正率T P R和真負率T N R之間的關系。只有當正類和負類的準確率同時都高時,G-mea n值才會高,G-mean值可用來衡量不均衡分類器的整體準確率,其計算公式如下:
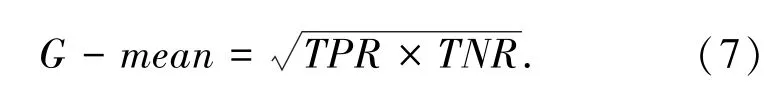
在不均衡數據學習中,還有一種常用的性能評價標準:受控者操縱特征曲線下面積(A U C)。受控者操縱特征曲線(R O C)顯示了分類模型真正率和假正率之間的關系,是對各樣本的決策輸出值排序而形成的。R O C曲線下的面積就是AU C測度,A U C能很好地評價不均衡分類器的泛化性能。
F-measure、G-mean與A U C的取值范圍均為[0,1],分類器性能與其值成正比,即指標值越大,分類器性能越好。
3 各種策略分析實驗
各種處理不均衡數據集的方法各有優劣。在不同的應用場景下,對各種不同的數據類型,需要采用不同的處理方法。下面對常用的3種類不均衡分類策略:重采樣方法、代價敏感學習、集成學習及其組合方法進行實驗分析比較。本文試驗數據來自于KEEL數據集(http://www.keel.es/),本文從中選取了10個樣本數據集,見表3。使用基于Java語言的開源軟件KEEL實現了不均衡數據集的分類學習。KEEL軟件有專門的不均衡數據學習模塊,集成了大部分主流的不均衡數據處理方法。實驗采用G-mean和A U C值作為評價不均衡分類學習能力的指標,用G-mean值衡量分類器的準確率,A U C值衡量分類器的泛化性能,取值越大,性能越優。實驗采用5折交叉驗證法。實驗環境具體配置為:處理器為Intel i7-4720 2.60GHz;8G內存;64位windows操作系統。
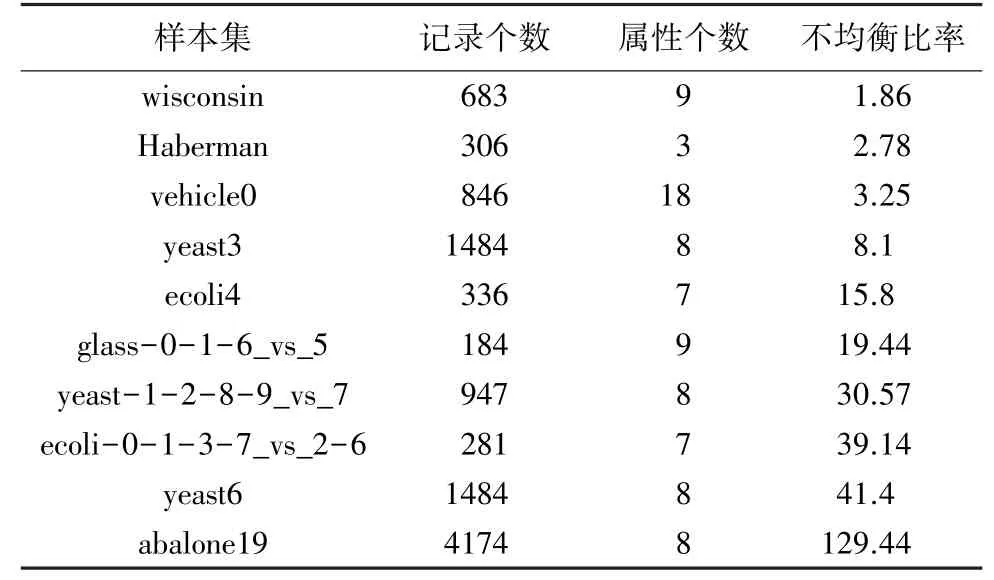
表3 不均衡數據集基本信息Tab.3 Basic information about imbalanced data sets
3.1 實驗方法與結果
(1)重采樣方法在不均衡數據集上的分類性能比較。實驗選用了過采樣方法SMOTE、欠采樣方法Tomek links方法、混合采樣方法SMOTE_Tomek links和SMOTE_ENN方法。通過重采樣方法實現了數據集的再平衡之后,選用常用的決策樹算法C4.5進行分類。各種重采樣方法與C4.5算法的結合在不同數據集上的性能見表4。表中的TL表示Tomek links欠采樣方法,SMOTE_TL表示SMOTE_Tomek links混合采樣方法。
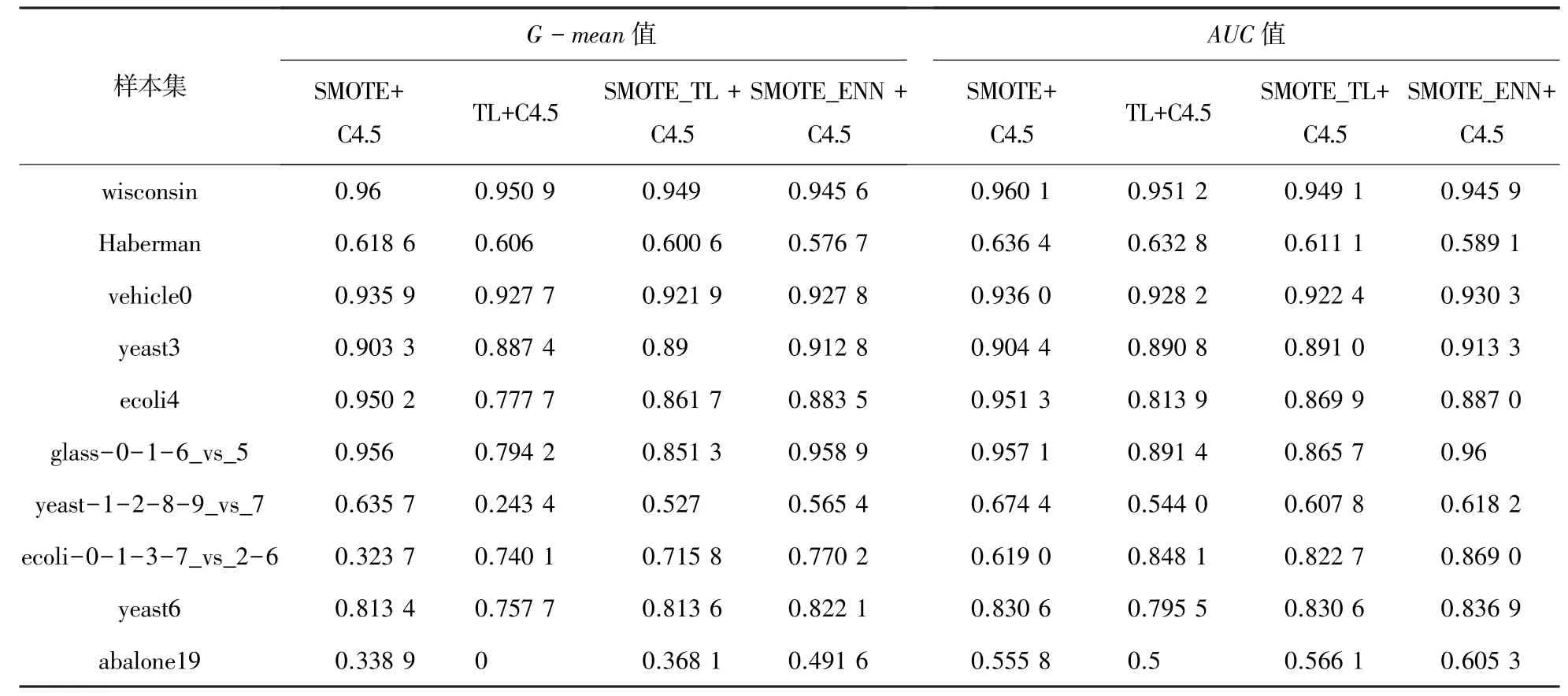
表4 重采樣方法性能比較Tab.4 Performance comparison of resample method
(2)3種代價敏感算法在不同數據集上的性能比較。實驗結果見表5。C4.5CS表示代價敏感決策樹算法,SVMCS表示代價敏感支持向量機算法,NNCS表示代價敏感神經網絡算法。
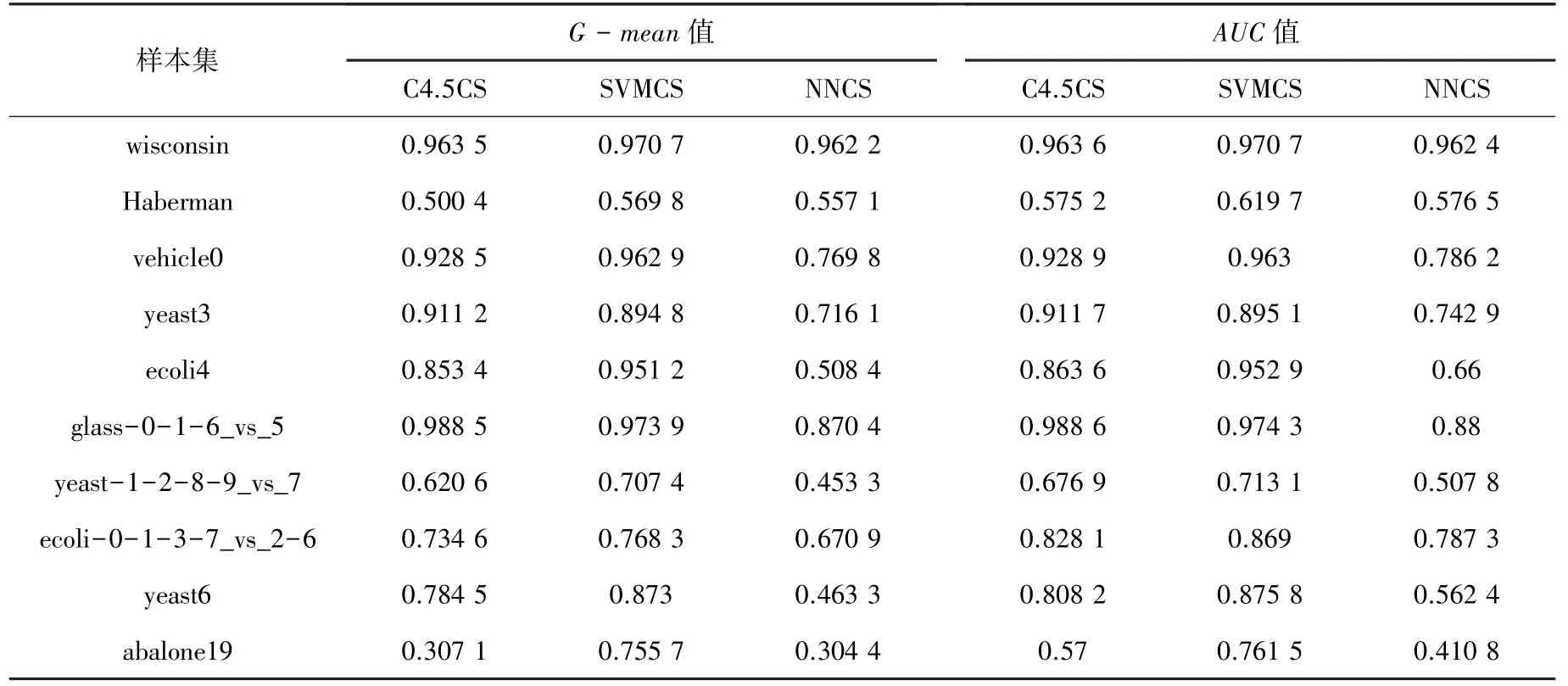
表5 代價敏感方法性能比較Tab.5 Performance comparison of cost-sensitive learning method
(3)重采樣方法SMOTE和SMOTE_ENN方法性能比較。選用經典的重采樣方法SMOTE和SMOTE_ENN方法,將其與代價敏感決策樹算法C4.5CS進行組合,觀察其是否比與普通決策樹算法C4.5結合性能提升更大,結果見表6。
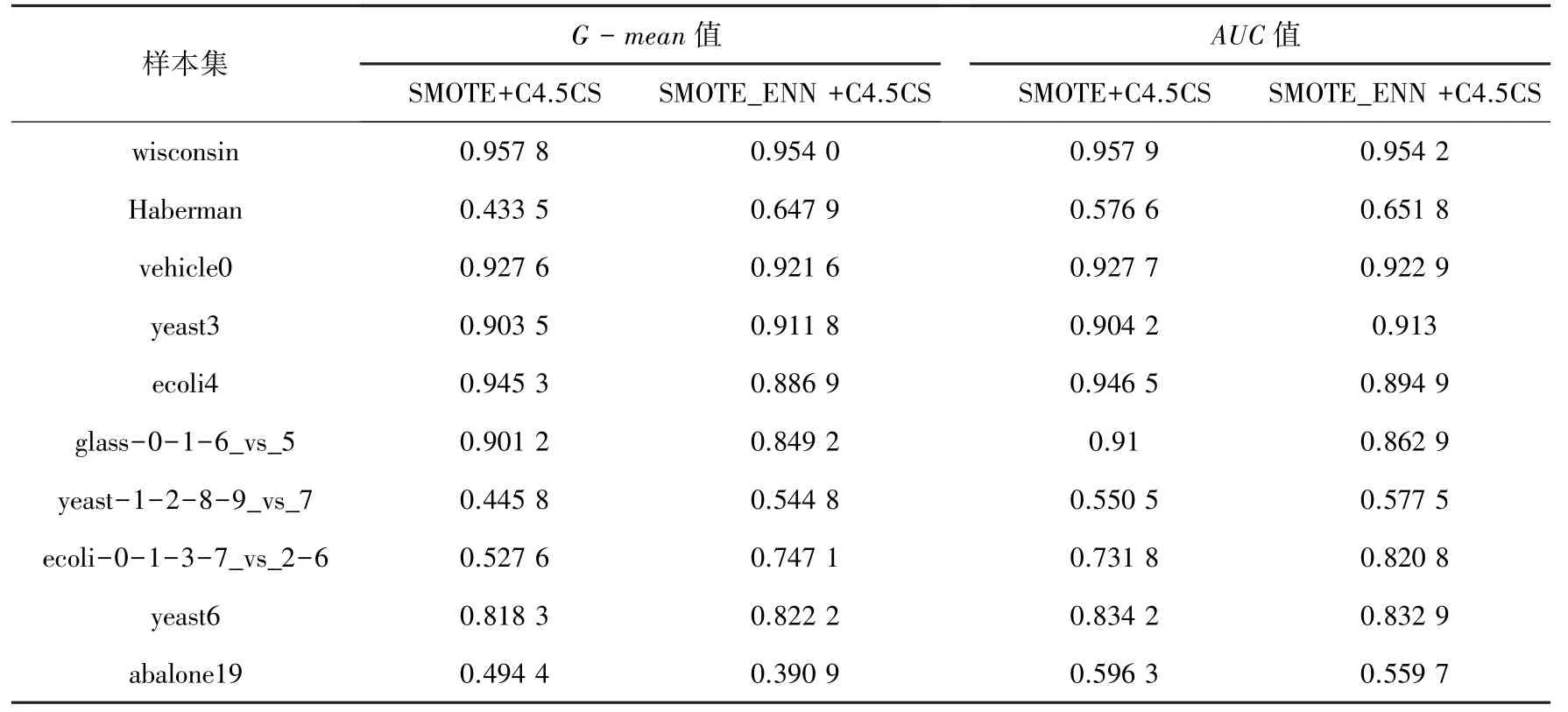
表6 重采樣與代價敏感集成方法性能比較Tab.6 Performance comparison of ensemble learning method about resample and cost-sensitive learning
(4)經典集成方法性能比較。比較3種經典集成方法SMOTEBoost、EasyEnsemble、BalanceCascade在不同數據集上的性能,這3種集成方法均以C4.5決策樹算法作為弱分類器,結果見表7。
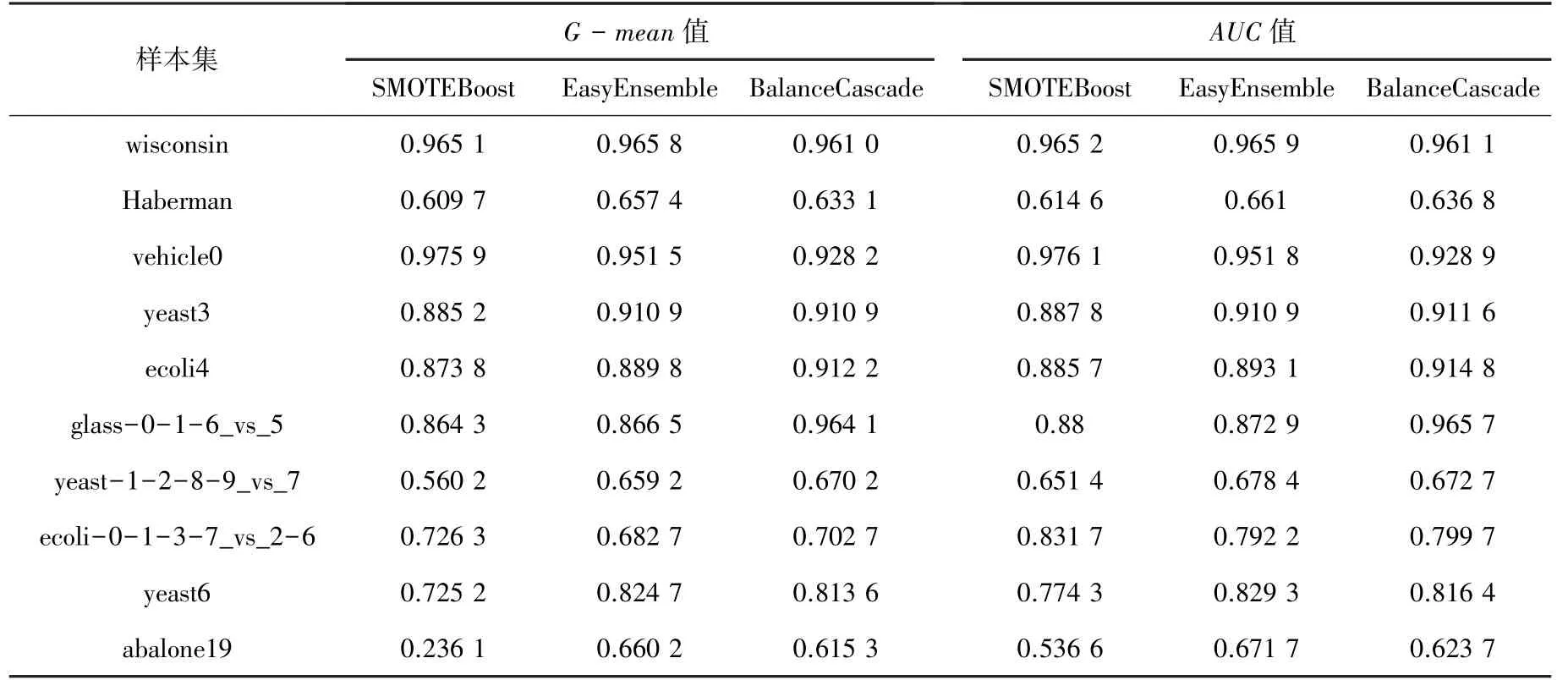
表7 經典集成方法性能比較Tab.7 Performance comparison of classical ensemble learning method
3.2 實驗結果分析
(1)重采樣方法分析。根據表4的實驗結果,過采樣方法SMOTE在大部分數據集上的G-mean值和AUC值都高于欠采樣方法Tomek links,只有在一個數據集“ecoli-0-1-3-7_vs_2-6”上出現例外,而且隨著不平衡率的增加,二者之間的差值有逐漸增大的趨勢,這說明SMOTE方法的性能全面優于Tomek links方法。混合采樣方面,當不均衡率小于3時,SMOTE_TL采樣方法的G-mean值和AUC值都高于SMOTE_ENN方法。不均衡率大于3后,SMOTE_ENN方法的G-mean值和AUC值普遍高于SMOTE_TL方法,說明SMOTE_ENN的準確率和泛化性能優于SMOTE_TL方法。比較SMOTE和SMOTE_ENN這兩種相對更好的方法,當不平衡率在30以內時,SMOTE方法的G-mean值和AUC值高于SMOTE_ENN方法或是與其接近。當不平衡率超過30時,SMOTE_ENN方法的G-mean值和AUC值才會高于SMOTE方法。
(2)代價敏感學習方法分析。根據表5的實驗結果,代價敏感支持向量機算法SVMCS的G-mean值和AUC值,大多數情況下都高于另外兩種代價敏感算法。在不均衡比例較高時,代價敏感決策樹方法C4.5CS的性能與代價敏感支持向量機算法SVMCS的性能相差不大,在兩個數據集中C4.5CS的準確率與泛化性能甚至超過了SVMCS方法。當不均衡比例超過100時,如在“abalone19”數據集中,SVMCS的性能比另外兩種代價敏感方法要高出很多。相比較而言,代價敏感神經網絡算法的性能比另外兩種算法差。
(3)重采樣方法與代價敏感方法集成分析。根據表6的實驗結果,當不平衡率小于10時,二種集成方法在不同數據集上所表現出的性能沒有明顯的規律可循。不平衡率在10~20時,SMOTE+C4.5CS集成方法的性能要強于SMOTE_ENN+C4.5CS集成方法。當不平衡率在20~100時則相反,SMOTE_ENN+C4.5CS方法的性能要強于SMOTE+C4.5CS方法。當數據分布嚴重不均衡時,SMOTE+C4.5CS方法的性能又超過了SMOTE_ENN+C4.5CS方法。總體而言,重采樣方法與代價敏感方法的集成方法其性能表現出的規律性不強。
(4)C4.5為基分類器的3種經典集成方法比較分析。根據表7的實驗結果,當不均衡率小于3時,EasyEnsemble方法的性能優于其它二種方法。不平衡率在8~30之間時,BalanceCascade的性能要強于SMOTEBoost方法和EasyEnsemble方法。當不均衡率超過40后,EasyEnsemble較另外兩種集成方法重新取得了性能優勢。當不均衡率超過100時,SMOTEBoost方法的G-mean值明顯下降,AUC值也不如另外兩種算法。
4 結束語
迄今為止,對于不均衡數據分類的理論成果非常少,本文所作的研究也只是在實驗數據的基礎上,總結出一些經驗性的結果,迫切需要進行更深入的理論分析和研究。另外,目前研究不均衡分類問題都是基于不均衡的二分類問題,即使是不均衡的多類問題,也是通過將原問題分解成二類問題的方法去解決,并沒有針對多類不均衡問題公認的評價指標。因此,需要進一步的深入研究,提出針對多類不均衡分類問題的評價指標和相應的學習算法。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
