檔案信息進行大數據應用的初步實踐
2021-05-07 02:24:26朱夢玲
現代信息科技 2021年23期
關鍵詞:人臉識別



摘? 要:隨著大數據在各行業應用的廣泛深入,取得良好的成果,許多檔案行業學者對檔案信息在大數據應用方面進行了研究和實踐,通過采用人工智能技術對檔案信息進行預處理,如利用OpenCV算法對文本檔案進行OCR識別,采用ASR技術對音視頻檔案進行語音識別,采用人工智能技術進行人臉識別等。對獲得的數字化檔案信息采用隱馬爾科夫模型進行結構化,最后形成“一人一檔,一事一檔”等大數據應用實踐。
關鍵詞:OCR;語音識別;人臉識別;數據結構化;一人一檔;一事一檔
中圖分類號:TP39? ? ? ? ?文獻標識碼:A文章編號:2096-4706(2021)23-0142-03
Preliminary Practice of Application of Big Data in Archival Information
ZHU Mengling
(Guangdong Yunxun Information Technology Co., Ltd., Huizhou? 516000, China)
Abstract: With the extensive and in-depth application of big data in various industries, good results have been achieved, many scholars in the archives industry have studied and practiced the application of big data in archives information. They preprocess archives information by using artificial intelligence technology, such as OCR recognition of text archives by using OpenCV algorithm, ASR (automatic speech recognition) technology is used for speech recognition of audio and video archives, and artificial intelligence technology is used for face recognition. The obtained digital archives information is structured by hidden Markov model (HMM), and finally forms big data application practices such as “one file for one person, one file for one thing”.
Keywords: OCR; speech recognition; face recognition; data structure; one file for one person; one file for one thing
0? 引? 言
我們國家在電子政務方面自動化、標準化、網絡化漸趨完善,每天都產生大量的反映政務活動的各種格式的電子檔案,結合國家對政府檔案行業“存量數字化、增量電子化”的要求,各地綜合檔案館積累了海量的電子檔案文件,為下一步利用這些海量的檔案信息資源進行政務大數據的應用實踐打下基礎。
隨著新一代信息技術的發展,尤其是人工智能和大數據技術的日漸成熟和廣泛應用,大數據技術已體現出有其廣闊的應用前景,在交通出行、安防、個性化信息推送、消費等各方面都有成功的應用,大數據也展示出了其巨大的商業應用價值,而檔案因其數據量龐大,格式多樣,存在跨時空、跨領域、跨行業的特點,涵蓋了政務活動、社會活動、經濟活動的方方面面,使檔案天然的具有大數據屬性,在此背景下,檔案的利用模式將發生重大變革,從被動用檔轉變成主動用檔。檔案信息資源的大數據應用場景將集中在歷史場景還原、人物和事件軌跡聚合、政務輔助決策等方面。
本文將從檔案信息資源在大數據應用中的“一人一檔”“一事一檔”等方面進行政務大數據應用實踐的探討,從技術準備和實踐路徑等方面進行概括,提出我們的檔案大數據應用思路和技術方案。
1? 技術準備
在檔案信息化的基礎上,將大數據技術和人工智能技術應用到檔案數據中,融合OCR文本識別、音視頻文件語音文本識別、聲像檔案人臉識別,對非結構化的電子檔案數據完成結構化處理,通過多維度的關聯匯聚,將相關檔案以時間軸和GIS空間結合,生動形象的展現出人物和事物的發展軌跡。
1.1? 傳統的數字化檔案文件經過OCR識別后形成文本數據
基于人工智能的OCR技術通常使用OpenCV算法庫,通過圖像處理和統計機器學習方法從圖像中提取文本信息,包括二值化、噪聲濾波、相關域分析、AdaBoost等。將檔案庫中的紙質檔案,通過掃描、系統掛接、圖像準備、文本識別、提取檔案信息、保存識別到的文本信息。由于OCR識別存在一定的誤差,系統要能夠允許對識別后的OCR文本做修改,以保證深度學習的準確率,同時為大數據分析打好基礎。OCR識別還可用于全文檢索等檔案模塊,在海量的檔案數據中,快速定位想要查找的檔案文件甚至文件段落,對檔案工作有很好的推動作用。
將上傳的PDF、OFD、Word等檔案文件進行OCR識別,形成文本,可查看以及粘貼復制,同時也能進行大數據檢索。OCR識別界面如圖1所示。
1.2? 音視頻檔案進行語言識別后形成文本數據
語音識別涉及的領域包括:數字信號處理、聲學、語音學、計算機科學、心理學、人工智能等,是一門涵蓋多個學科領域的交叉科學技術。基于人工智能的音視頻檔案語音識別就是讓系統對音視頻檔案進行音頻提取,提取后對原始音頻進行部分消除噪聲來增強語音信號,且按一定時間進行切割并生成音頻文件進行語音信號的特征提取,這一過程能更好地尋找語音的內在特征,然后再通過語言模型訓練,計算語言特征提取后的特征矢量與每個聲學模型的距離來進行模式匹配,最后通過語音模型語法規則進行語音匹配,輸出識別結果。
音視頻檔案語音識別的應用可以很好地解決地方口音、方言和少數民族語言帶來的音視頻檔案識別問題,且該應用識別音頻輸出的文本信息可用于檔案音視頻檢索,而不再僅限于傳統的著錄信息檢索,相比較傳統的檢索方式,應用音視頻文本檢索后,檢索效率可以有很大的提高,提高了檔案人員的工作效率也提高了公眾對檔案的利用率;通過音視頻關鍵字和OCR識別的文本檔案、通過互聯網收集的檔案信息一起進行大數據分析,這將會大大提高聲像檔案的利用率,提升檔案工作人員的工作效率。音頻檔案語音識別界面圖如圖2所示。
1.3? 聲像檔案提取人臉信息
局部二值模式(local binary pattern,LBP)的人臉識別方法源于紋理分析領域。它首先計算圖像中每個像素與其局部鄰域點在亮度上的序關系,然后對二值序關系進行編碼形成局部二值式,最后采用多區域直方圖作為圖像的特征描述。該方法在FERET人臉圖像數據庫上取得了很好地識別性能。人臉識別后將識別到的人臉保存在數據庫中,作為查詢匹配庫。采取提取人臉外部矩形框、人臉面部輪廓特征提取、計算人臉特征、比較人臉特征、判斷是否小于閾值等流程實現人臉識別和特征提取以及結果匹配,最終實現人臉檢索,其中計算人臉特征使用Resnet將人臉特征用128維向量標識,比較人臉特征采用計算歐式距離的方法。
根據以上人工智能算法提取人臉的特征數據、屬性數據,將聲像檔案中的人臉數據提取后結構化并匯聚整合,建立檔案人臉庫。檔案管理者也可通過對比檔案人臉庫,編輯標識人物姓名、身份、身體特征信息,完成聲像人物標注,形成描述統一、內容完備的人臉庫。建立人臉庫后再歸檔該人物聲像檔案可實現自動識別歸類,比如還原某位優秀共產黨員歷史時只需搜索該人臉或者姓名、身份等信息,該人物在庫中的所有相關聲像檔案立刻展現。與文本檔案OCR識別相結合,可形成人物鏈,可將該人物的文本檔案和聲像檔案相結合匯聚成個人檔案概覽。聲像人臉提取與檢索界面圖如圖3所示。
1.4? 數據要素提取和結構化
OCR識別完成了對檔案文本文件和音視頻文件轉換成可深入利用的數據,但這些數據均為原始的非關系型數據,要進行大數據分析和利用,需首先基于人工智能技術對這些非關系型數據進行結構化,使非關系型數據轉換成關系型數據庫。在結構化的過程中結合時空關系和人臉特征模型,構成更廣泛的人、事、時空的關聯性。
借助世界上最大的多語種語料庫,進行分詞粗分、細分、強制、合并、校正、詞性標注、命名實體識別、依存句法分析、成分句法分析、語義依存分析、語義角色標注、詞干提取、詞法語法特征提取、抽象意義表示等過程,提取人名、地名、事件等信息。使用隱馬爾科夫模型(Hidden Markov Model,HMM)作為語音信號的統計模型,采用前向-后向算法、Baum_Welch算法以及Viterbi解碼算法對檔案文件識別后的OCR文本進行中文分詞,對數據要素進行提取,提取后進行抽象意義表示,即完成數據要素的提取和結構化。數據要素提取和機構化相關圖示如圖4所示。
2? 實踐路徑
(1)經OCR和視頻文本識別后產生海量的文本數據,雖經過了檔案邏輯的多維編目、元數據的提取和標注等操作,但對事物內所包含的有機信息依然有限,要進行大數據應用,需先按照“人物、事件、時間、原因、結果”等主要要素,職務、單位、行為、場所、等細分要素進行結構化,對文本中所包含的主要要素、細分要素進行基于人工智能的自動識別和提取、聚合,完成數據清洗和預處理,建立龐大的關系型主動利用檔案大數據庫,提供了檔案大數據應用的堅實基礎和無限可能性。
(2)對檔案信息大數據最直觀的利用進行多維度組合分析,因檔案大數據完成了結構化,產生主要要素和細分要素相結合的多維度要素,有時空、事件、人物、單位機構等,可對各類要素多維度進行組合分析,使用諸如回歸、聚類、關聯值、異常值等數據挖掘方式,也可按照時空維度的方式,結合GIS地圖,可直觀立體地表現出事件所產生的時間和空間信息,涉及到人物時,可將關系型檔案大數據和人臉特征信息結合,建立起檔案大數據和圖片、音視頻的關聯關系。其中在聲像檔案進行拍攝時,可打開拍攝設備中記錄時間和GPS經緯度的參數,則可自動獲得產生聲像檔案時的時空要素。
(3)在數字檔案信息要素中,人物和事件是最為核心的要素,也是檔案最為直觀的分析對象,在結構化后,可使用聚類的方式對人物要素進行聚合,包括人名、職務、單位、行為等,結合聲像檔案中的人臉等要素,按時間軸線為主,GIS空間為表現形式,聚合成時空環境中的一人一檔,若要查看某位同志的職業升遷,則可通過一人一檔形成的時間軸,直觀地看出職位變動以及該人物參加的活動等;
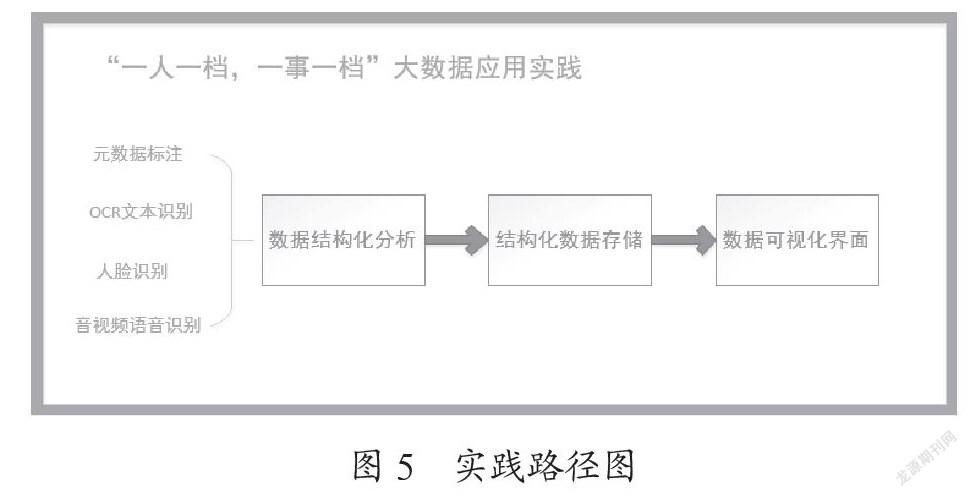
也可按照事件進行檔案大數據利用,如“城市更新”“軌道建設”“鄉村振興”“疫情防治”等具體事件進行多維聚合,以時空為表現形式,形成一事一檔的利用模式。實踐路徑如圖5所示。實踐結果界面圖如圖6實踐結果圖。
3? 結? 論
信息技術的大范圍應用使得各類生產活動中所產生的數據量逐漸增多,這必定會為檔案管理工作帶來較大的難度,對于檔案事業來說,信息技術的普及及應用既是機遇又是挑戰,信息量和數據量的大幅度增長不僅會增加檔案管理負擔,還突出表現了原有檔案管理模式中的不足,在信息化的背景下,要求檔案管理工作根據當前的發展形勢進行創新與整改,全面提升檔案管理的信息化水平和管理效率,為人們提升更加高效的檔案服務。而在信息化的基礎上,應加大對檔案海量數據的分析力度,做到檔案大數據的主動用檔。檔案大數據的主動用檔的利用場景,不僅限于一人一檔及一事一檔,在歷史場景還原、政務輔助決策、事件和人物的規律性分析等方面均可發揮作用,在新一代信息技術,尤其是隨著人工智能技術和大數據技術的日漸成熟,對檔案的價值挖掘提供了無限的想象空間和可能性,“大數據+檔案”是形成主動用檔、智能用檔,讓檔案發揮更大利用價值的重要途徑。
參考文獻:
[1] 趙甲信.關于加快推進縣域檔案信息化建設工作步伐的幾點體會 [J].陜西檔案,2008(6):30.
[2] 趙鵬,李光.檔案工作落實科學發展觀的關鍵——實現檔案實物化管理向信息化管理的轉變 [J].山東檔案,2005(5):7-9.
[3] 陶水龍.大數據特征的分析研究 [J].中國檔案,2017(12):58-59.
[4] 陳菲.大數據視角下的檔案利用問題研究——由提高數據加工能力談起 [J].機電兵船檔案,2017(3):74-76.
[5] 王玲,張妍妍.大數據時代檔案工作面臨的大機遇與大挑戰 [J].蘭臺世界,2014(17):15-16.
作者簡介:朱夢玲(1997—),女,漢族,湖北黃岡人,工科學士學位,本科,研究方向:檔案大數據。
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
學生天地(2020年31期)2020-06-01 02:32:06
電子制作(2019年14期)2019-08-20 05:43:34
中國交通信息化(2018年1期)2018-06-06 07:29:55
電子制作(2017年17期)2017-12-18 06:40:55
中國公共安全(2017年7期)2017-10-13 08:18:26
電子制作(2017年1期)2017-05-17 03:54:46
中國公共安全(2017年9期)2017-02-06 03:05:32
現代工業經濟和信息化(2016年6期)2016-05-17 05:36:23
華東理工大學學報(自然科學版)(2015年2期)2015-11-07 09:16:51
