深度學習語音合成技術綜述
2021-05-14 06:28:10張小峰羅健欣
計算機工程與應用 2021年9期
張小峰,謝 鈞,羅健欣,楊 濤
1.中國人民解放軍陸軍工程大學 指揮控制工程學院,南京210007
2.中國人民解放軍31121部隊
語音合成是將文本轉化成語音的技術,在日常生活中有著廣泛的應用,比如智能客服、虛擬助手、智能閱讀等[1-2]。目前,常見的語音合成方法有拼接法(concatenative speech synthesis)、參數法(parametric speech synthesis)、統計參數法(Statistical Parametric Speech Synthesis,SPSS)以及深度學習法(deep learning)等。其中,拼接法和參數法也叫傳統語音合成方法。
文獻[3]從前端文本處理、語音生成角度對語音合成技術進行綜述,首先綜述語音合成中前端文本處理技術,然后綜述語音合成技術,文獻[3]綜述的語音合成技術有拼接法、參數法以及前饋神經網絡等。文獻[4]則首先簡述了傳統的語音合成方法,然后從深度神經網絡在語音合成技術中的應用角度綜述語音合成技術,比如受限玻爾茲曼機、深度置信網、循環神經網絡等在語音合成中的應用,最后介紹了基于Wavenet[5]和Tacotron的語音合成技術。
不同于上述的語音合成技術綜述,文章從聲學模型和聲碼器角度,系統綜述基于深度學習的語音合成技術進行,包括各種基于深度學習聲學模型、聲碼器和端到端語音合成系統等,并分析了各自的特點、優勢、劣勢,以及適應的場景。文章涉及了上述綜述中基于深度學習的語音合成技術,但沒有涉及到傳統的語音合成技術。
自2016年谷歌公司提出Wavenet聲碼器至今,涌現出多種基于深度學習的語音合成技術,這些技術從合成語音質量、合成速度以及模型復雜度等方面提高語音合成技術性能。基于深度學習的語音合成系統主要有兩種,一種是將深度學習應用到傳統語音合成系統各個模塊中建模,這種方法可以有效地合成語音,但系統有較多的模塊且各個模塊獨立建模,系統調優比較困難,容易出現累積誤差。這種系統的代表是百度公司提出的Deep Voice-1[6]和Deep Voice-2[7]。
另一種是端到端語音合成系統,這種系統旨在利用深度學習強大的特征提取能力和序列數據處理能力,摒棄各種復雜的中間環節,利用聲學模型將文本轉化中間表征,然后聲碼器將中間表征還原成語音。聲學模型和聲碼器是端到端語音合成系統的重要組成部分,一些語音合成系統會在聲學模型之前加上文本分析模塊,文本分析模塊對輸入的文本進行預處理,比如詞性標注、分詞以及韻律生成等。由于文本分析是自然語言處理的內容,所以文章不進行綜述。
圖1是語音合成系統分類示意圖,端到端語音合成系統由聲學模型和聲碼器兩個部分組成,聲學模型實現文本和語音在時間上的對齊,聲碼器將聲學模型輸出還原成語音波形。由于聲碼器不僅可以在端到端語音合成系統中,也可以單獨作為語音合成的模型,所以文章首先對基于深度學習的聲碼器進行綜述,詳細介紹經典的聲碼器這些工作原理,分析聲碼器的優缺點。然后對聲學模型進行綜述,在聲碼器和聲學模型的基礎上對語音合成系統進行綜述。最后對基于深度學習的語音合成技術發展做出展望。

圖1 語音合成系統分類
圖2 是近幾年基于深度學習的語音合成技術發展歷程,包括聲碼器、聲學模型和端到端語音合成系統,還有一些衍生的聲碼器、聲學模型和端到端語音合成系統沒有列出。

圖2 基于深度學習的語音合成技術發展歷程
1 聲碼器
聲碼器單獨作為語音合成模型時需要和預處理模型結合使用,預處理模型為聲碼器提供語言學特征或聲學特征等控制條件。基于深度學習的聲碼器按照其生成語音原理可以分為自回歸式和并行式。自回歸式聲碼器按照時間順序生成語音,生成每一時刻的語音都依賴之前所有時刻的語音。并行式聲碼器并行生成語音,不再按照時間順序。并行式聲碼器主要有基于概率密度蒸餾[8]聲碼器和基于流[9]聲碼器兩種。基于概率密度蒸餾聲碼器是在自回歸模型基礎上結合逆自回歸流[10]和概率密度蒸餾方法,采用教師學生模式訓練模型,教師模型是預訓練好的自回歸模型,學生模型用逆自回歸流方法訓練,損失函數一般是教師模型和學生模型輸出之間的相對熵(Kullback-Leibler 散度,KL 散度)。基于流的生成式模型最初用于生成圖像,但基于流的聲碼器也可以較好地生成語音。基于流的聲碼器只需要一個模型、一個損失函數就可以高速生成語音,而基于概率密度蒸餾的聲碼器需要兩個階段訓練和多個輔助損失函數。圖3是聲碼器按照工作原理的分類,圖中所列的是經典聲碼器,沒有包含衍生的聲碼器。
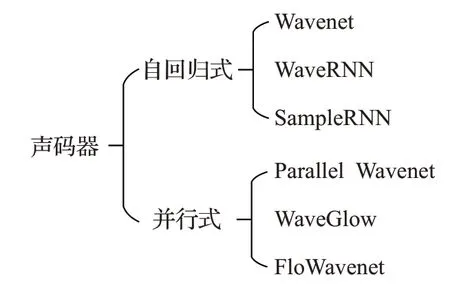
圖3 基于深度學習的聲碼器分類
1.1 自回歸式聲碼器
自回歸聲碼器是較早研究的聲碼器,按其網絡模型主要有基于卷積神經網絡聲碼器和基于循環神經網絡聲碼器兩種。基于卷積神經網絡聲碼器利用卷積神經網絡建模,通過因果卷積、帶洞卷積等達到按時序生成語音的目的。基于卷積神經網絡聲碼器能夠充分利用GPU等并行計算資源,訓練速度比基于循環神經網絡的聲碼器快。基于循環神經網絡的聲碼器利用循環神經網絡建模,比如長短時記憶網絡(LSTM)[11]、門循環單元(GRU)[12]等。
Wavenet[5]是谷歌DeepMind提出的由卷積神經網絡構成的生成式模型,該模型不僅可以生成語音也可以生成圖像、音樂等。Wavenet 作為聲碼器時有Wavenet 聲碼器[13]和條件Wavenet 聲碼器兩種模式。Wavenet 聲碼器需要語言學模型或聲學模型等提供控制條件,比如聲譜圖、F0 基頻等。圖4 是Wavenet 結構示意圖,訓練前將語音序列聯合概率x={x1,x2,…,xT} 分解為各時刻條件概率的乘積,如公式(1)所示:

x是語音波形值序列,xt是一個時刻波形值。訓練過程中利用因果卷積和帶洞卷積逐點生成語音的波形。因果卷積和帶洞卷積保證模型按照時間順序生成語音。生成階段,模型采用逐采樣點自回歸方式,按公式(1)計算每個時刻的波形值。

圖4 Wavenet
條件Wavenet聲碼器在Wavenet聲碼器基礎上接收額外的輸入條件進行建模,如公式(2)所示:

h是額外的輸入條件。比如在合成多說話人語音時,說話人編碼就可以作為額外的輸入,在文本轉語音任務中,文本也可以作為額外的輸入。條件Wavenet聲碼器有兩種建模方法:全局方法和局部方法。全局方法是指模型接收單額外輸入條件h,該條件在所有的時間點上影響模型的輸出。局部條件建模方法是指模型有第二種時間序列ht,ht是通過對原始數據的低采樣率獲得。局部條件建模效果比全局建模的效果要差一些。
Wavenet 全卷積神經網絡的設計可以充分利用GPU 并行計算資源,訓練速度比較快且合成語音質量高。但是由于采用逐點自回歸方式生成語音,所以生成語音速度慢。對于16 kHz采樣率,16 bit采樣位的語音,每秒需要計算16 000個采樣點,每個采樣點有65 536種可能,這需要較大的計算量和計算耗時。雖然Wavenet采用了μ律壓擴[14]將16 bit的采樣位降低成8 bit的采樣位,但是生成語音速度仍然達不到實時的要求。
雖然Wavenet存在模型較為復雜、計算量大及合成速度慢等問題,但Wavenet是基于深度學習聲碼器的重要組成部分,對語音合成技術的發展有著重要影響,基于Wavenet衍生出多種聲碼器。
對于Wavenet 聲碼器需要額外的模型提供控制條件,文獻[15]提出直接使用現有的聲學特征作為Wavenet的輸入特征,這樣不需要對原始語音建模,從而避免了語音分析和生成過程各種先驗的假設。文獻[16]在文獻[15]基礎上研究多說話人的語音合成。
對于Wavenet 合成語音有噪音的問題,文獻[17]通過在Wavenet 模型之前引入基于感知權重的噪音整形技術,減少Wavenet因為卷積神經網絡難以捕捉語音信號動態信息而產生的噪音,但是這種做法會造成合成語音的質量下降。Excitnet[18]結合LPC(Linear Predictive Coding,LPC)聲碼器和Wavenet 聲碼器優點,使用自適應預測器將與共振峰相關的頻譜結構從輸入語音信號解耦,然后通過Wavenet對激勵信號的概率分布進行建模,實現了高效訓練和生成語音。
針對Wavenet 訓練復雜,計算量大的問題,Fast-Wavenet[19]在Wavenet基礎上通過引入緩存,將因果卷積和帶洞卷積計算過程中不變的結果保存在緩存中,需要時直接使用,這樣可以節約計算的時間,提高訓練和生成語音的速度。FFTNet[20]則對Wavenet 結構進行調整,通過多通道卷積的結構,提高合成語音的速度同時減小模型規模且合成語音的質量較高。
不同于上述基于卷積神經網絡的聲碼器,SampleRNN[21]采用處理序列數據常用的循環神經網絡建模,SampleRNN有多層循環神經網絡組成,最低層叫采樣層,其余層叫幀層。各層以不同時鐘速率運行,學習不同抽樣級別。采樣層一個時間步只學習一幀樣本,而最高的幀層一個時間步可以學習較多幀樣本。幀層對語音非重復幀做處理,每個幀層都是一個循環神經網絡,循環神經網絡可以由LSTM、GRU等組成,也可以是其他循環神經網絡變體組成。采樣層對單個樣本數據進行處理,直接計算出語音波形。
SampleRNN和Wavenet都是直接對原始語音建模,Wavenet 利用卷積神經網絡學習語音前后特征的關系,而SampleRNN 從循環神經網絡的角度,利用多層循環神經網絡學習語音不同時間維特征。SampleRNN生成語音速度比Wavenet快,模型也比Wavenet簡單,合成語音質量和Wavenet 相當。但是由于SampleRNN 采用循環神經網絡,所以訓練過程中并不能充分利用計算資源,需要采用較多的技巧加速模型訓練。
不論是Wavenet 還是SampleRNN 都很難達到實時語音合成,WaveRNN[22]針對生成式語音合成中耗時較大的模塊進行了專門分析和改進,達到超實時語音合成速度且合成語音質量也沒有大的下降。WaveRNN認為生成式語音合成模型生成語音速度可以用公式(3)表示:

T(u)是生成語音的總時間,語音有 |u |個采樣點,N 表示模型神經網絡層數,c(opi)代表每層神經網絡計算耗時,d(opi) 表示硬件執行程序時間。對于以上幾點,WaveRNN 分別使用單層循環神經網絡和兩層softmax層簡單模型減少神經網絡層數,采用裁剪法[23-24]減少每一層神經網絡計算耗時,使用折疊法減少因為語音較長而需要的時間。
WaveRNN 通過上述方法達到了提高語音生成速度、降低模型規模的效果。WaveRNN 合成語音速度比Wavenet 和SampleRNN 快很多且可以部署在移動端等計算資源較少的設備上。LPCNet[25-26]在WaveRNN基礎上結合線性預測模塊,進一步提高了語音合成的效率,在同等大小模型的情況下,LPCNet合成語音的質量更高。
1.2 并行式聲碼器
自回歸式聲碼器按照時間順序構建語音,每一點語音值都需要依賴歷史語音值,合成語音質量高,但實時性不足。不同于自回歸式逐點生成語音,并行式聲碼器同時生成整段語音,每個語音點之間沒有依賴關系。并行式聲碼器按其原理主要有兩種:一種是基于概率密度蒸餾,利用逆自回歸流和概率密度蒸餾訓練和生成語音,比如Parallel Wavenet[27]和Clarinet[28]。逆自回歸流是一種每個可逆函數都基于自回歸神經網絡的特殊的標準化流[29-30]。逆自回歸流最大似然估計是自回歸式,因此逆自回歸流模型會和概率密度蒸餾模型結合使用。概率密度蒸餾原本是模型壓縮的方法,通過優化學生模型和教師模型輸出之間的誤差,得到規模較小的學生模型。另一種是基于流,通過一系列可逆函數,利用簡單的分布在中間表征的控制下生成語音波形,基于流的模型是目前研究的熱點。
自回歸模型并行輸入訓練數據逐點輸出預測結果,特點是訓練速度快但生成速度慢。逆自回歸流模型相反,逐點輸入訓練數據并行輸出預測結果,所以基于逆自回歸流模型的訓練速度慢,但是生成速度快。Parallel Wavenet結合逆自回歸流和概率密度蒸餾方法,首先訓練好自回歸的教師模型,然后從教師模型中蒸餾學習出學生模型,學生模型用逆自回歸流的方法訓練。Parallel Wavenet 損失函數是學生模型和教師模型輸出之間的KL散度,通過優化KL散度使學生模型輸出不斷逼近教師模型輸出。公式(4)是模型損失函數,H(PS,PT)是學生模型和教師模型輸出的交叉熵,H(PS)是學生模型輸出的熵。

僅優化KL散度,學生模型還不能很好地生成語音,Parallel Wavenet 增加了感知損失、對比損失、能量損失等輔助損失函數提高學生模型生成語音質量。感知損失可以防止產生不好的發音,對比損失可以消除噪音,而能量損失協助匹配人類語音的能量。
Parallel Wavenet極大提高了語音合成速度,但實踐中發現很難有效實現該模型,因為Parallel Wavenet 首先假設教師和學生模型的輸出均服從混合邏輯斯特分布,然后對混合邏輯斯特分布進行蒙特卡洛采樣后計算兩者的KL 散度。蒙特卡洛采樣會導致訓練過程不穩定。對此,Clarinet 采用高斯分布取代教師學生模型輸出的混合邏輯斯特分布,兩個高斯分布可以直接計算KL散度,公式(5)所示:

q 是學生模型輸出的高斯分布,p 是教師模型輸出的高斯分布,uq和σq為q 均值和標準差,up和σp是p 均值和標準差。為了保證訓練過程中數值計算的穩定性,Clarinet還對σq和σp增加了正則項,如公式(6)所示:

Parallel Wavenet和Clarinet通過逆自回歸流和概率密度蒸餾的方法實現了高速訓練和生成語音目的,但在實際中這兩種方法使用并不多,因為這兩種模型訓練過程比較復雜且合成效果也不穩定。
不同于Parallel Wavenet 和Clarinet 需要兩個階段訓練和多個輔助損失函數。基于流的聲碼器只需要一個模型和一個損失函數就可以高速生成語音。標準化流是通過一系列可逆函數用簡單分布模擬復雜分布的一種生成式模型。在語音合成中,對于原始音頻x,假設存在可逆函數f(x):x →z,則可以直接將x 映射到先驗Pz,則x 的對數概率分布函數可用公式(7)表示,這樣就可以用一個已知的簡單分布計算一個復雜的分布的似然估計。

基于流的模型的優勢是訓練過程簡單,不需要多次訓練和多個損失函數且結果穩定。WaveGlow[31]結合Glow 和Wavenet 以均值為0 的高斯球形分布作為先驗分布,以梅爾頻譜作為控制條件,通過擠壓層、1×1可逆卷積和仿射耦合層[32]等擬合語音波形。FloWavenet[33]的原理和WaveGlow 相似,FloWavenet 認為基于流的生成式模型要實現高效訓練和生成需要滿足兩點:(1)計算公式(7)的雅克比矩陣的公式f應該簡單易于計算;(2)將噪音點z轉化成語音信號點x的逆函數x=f -1(z)應該容易計算。如要并行生成和易于計算,第二點必須滿足。為了滿足上述兩點,FloWavenet 使用類似文獻[32]的仿射耦合層中,并在每一個模塊中使用了多層流。
WaveGlow 和FloWavenet 實現了高速生成語音,降低了訓練的難度和復雜度。但是基于可逆流的模型通常有較多的神經網絡層和大量的參數,這使得基于流的模型很大,比如Wavenet 和Clarinet 只有1.7×106個的參數,而WaveGlow有200×106個的參數。
MCNN[34]通過多頭卷積網絡重建語音波形,該模型雖然不需要如Parallel Wavenet 那樣多次訓練,但模型仍需要四個輔助損失函數,訓練過程比較復雜,且由于MCNN是在完整的聲譜圖上還原波形,所以并不清楚能否在梅爾頻譜這樣的聲譜圖上還原波形。
文獻[35]從人類發音角度建模,模型由三個部分組成,一個是源模塊,用于生成基于正弦的信號,作為激勵源。另一個是基于非自回歸帶動卷積的過濾器,過濾器將激勵轉化成語音波形。最后一個是條件模塊,這個模塊將輸入的聲學特征進行預處理,然后輸入到前兩個模塊。通過這三個模型,文獻[35]避免了基于概率密度蒸餾復雜的訓練環節。
表1是幾種聲碼器性能參數表,Wavenet合成語音質量高,但模型較為復雜,生成語音速度慢。SampleRNN和WaveRNN是基于循環神經網絡的聲碼器,這兩個模型比Wavenet 小,合成語音質量和Wavenet 相當。WaveRNN速度最快,模型最小。WaveGlow 和FloWavenet 是結合Wavenet和流的并行式聲碼器,兩者的工作原理相近,結構不同。表中合成速度以實時為基準,實時是指合成一秒的語音需要一秒的時間,不足是指合成一秒語音需要超過一秒的時間。在實際應用中一般會要求語音合成系統具有超實時性,因為部署在服務器端的語音合成需要考慮網絡時延問題,5G 的發展會在一定程度上緩解這個問題,但不能從根本上解決問題,所以實用的語音合成系統需要可以實時合成語音。
2 聲學模型
經典的語音合成系統中語言學模型和聲學模型通常分開建模,這會導致模型比較復雜且需要研究人員具有專業的語言知識。隨著深度學習的發展,特別是基于注意力機制[36-38]的序列到序列(seq2seq)模型[39]的提出,使得將語言學模型嵌入到聲學模型中成為可能。文獻[40]首次提出基于序列到序列加注意力機制[41]的聲學模型,其原理是通過輸入文本序列生成梅爾頻譜。文獻[40]聲學模型可以很好地生成梅爾頻譜,但需要預訓練的隱馬爾科夫模型輔助學習,因此文獻[40]只能合成較短的語音。
和聲碼器相似,基于深度學習的聲學模型的發展也經歷了自回歸式和并行式兩個階段。自回歸式聲學模型出現較早,生成的中間表征質量高、速度慢。并行式聲學模型生成中間表征速度快,但質量會有所下降,且訓練過程比較復雜。本章節從自回歸和并行式兩種聲學模型綜述。
2.1 自回歸式聲學模型
自回歸式聲學模型在語音合成中用的比較多,其基礎是seq2seq加注意力機制的編碼解碼模型。編碼器將文本轉化成上下文矢量,解碼器根據上下文矢量直接解碼出結果。注意力機制建立起上下文矢量與輸入文本之間的聯系,這樣可以更好地利用輸入的信息。在語音合成聲學模型中,注意力機制可以將解碼器的注意力集中在輸入的相關文本上。由于注意力機制在聲學模型有著重要的作用,所以這里介紹一下注意力機制。
圖5 是seq2seq 加注意力機制的示意圖,對于輸入序列x=(x1,x2,…,xL)和與之對應的輸出序列y=(y1,y2,…,yT),首先將輸入序列編碼成(h1,h2,…,hTx) 嵌入特征,st為循環神經網絡的隱層狀態,如公式(8)所示,ct為第t時間步的上下文矢量,如公式(9)所示。公式(10)是解碼器解碼的結果。


表1 基于深度學習的聲碼器總結
公式(9)中,上下文矢量ct每次計算都和輸入h有關,這種方式稱為基于內容的注意力機制[41],這種方式沒有考慮輸入文本之間的位置關系,相同的輸入具有相似的權重值。另一種基于位置的注意力機制將輸入文本之間的位置關系代入計算,上下文矢量計算公式如式(11)所示,這種稱注意力機制為基于位置的注意力機制[37]。


圖5 循環神經網絡加注意力機制示意圖
2.1.1 編碼器
編碼器提取輸入文本的特征,將輸入文本轉化成上下文矢量,編碼器的結構一般比較簡單。Tacotron-1[42-43]的編碼器采用了預處理網絡和CBHG[44]模塊。預處理網絡是一系列非線性轉換層,將文本轉化成嵌入矢量,CBHG 模塊結合注意力機制將嵌入矢量轉化成上下文矢量,CBHG 模塊可以減少過擬合以及誤發音等情況。Tacotron-2[45]編碼器在Tacotron-1 編碼器基礎上進行了簡化,僅使用普通的LSTM 和卷積網絡,沒有使用復雜的CBHG 模塊。Deep Voice-3[46-47]的編碼器則采用全卷積進行建模,全卷積的編碼器可以并行訓練。
2.1.2 解碼器
解碼器是聲學模型的關鍵,后期對于聲學模型的改進也是集中在解碼器。解碼器根據上下文矢量直接解碼出結果,解碼的結果需要根據聲碼器選擇。解碼器可以解碼出原始的聲譜圖,也可以解碼出梅爾頻譜。原始的聲譜圖可以保留更多的語音信息但是會有大量的冗余信息增加訓練過程的不穩定性,梅爾頻譜雖然會丟失大量的信息,但是通過良好設計的聲碼器可以還原出丟失的信息,因此解碼器通常會以梅爾頻譜為解碼結果。
Tacotron-1 采用基于內容注意力機制解碼器[36],每一個時間步每一循環層都會生成一個注意力詢問。Tacotron-2的解碼器和Tacotron-1結構相似,但是采用基于位置的注意力機制[37],以更好地適應輸入文本有重復字的情況。Deep Voice-3 解碼器則是由帶洞卷積和基于Transformer[38]注意力機制構成,基于卷積的解碼器比基于循環神經網絡的聲碼器解碼的速度要快一些。由于在合成語音過程中,對于注意力機制的錯誤較為敏感,所以Deep Voice-3進一步采用了[48]注意力機制。
上述的解碼器可以高質量地生成中間表征,但是都存在曝光偏差[49]問題。曝光偏差是由于在訓練過程中,解碼器使用真實值作為每一個解碼步的輸入,而在預測時使用上一個解碼步的輸出作為本次解碼步的輸入,這種訓練和預測的輸入會造成不一致性。曝光偏差會導致合成語音出現漏詞、重復詞以及不完全合成等現象。
2.2 并行式聲學模型
并行式聲學模型并行解碼出結果,并行解碼的兩個難點是根據輸入的文本需要解碼出多少幀中間表征以及并行解碼出的各幀之間的依賴關系如何界定。目前常用的辦法仍是概率密度蒸餾,通過預訓練的教師模型指導學生模型。Fastspeech[50]通過從預訓練好的自回歸模型中提取文本語音對齊信息,結合Transformer、一維卷積網絡[51]以及概率密度蒸餾等方法并行生成中間表征。Fastspeech解決了自回歸聲學模型合成速度慢、合成結果不穩定以及合成過程難以控制等問題。Paranet[52]則采用軟注意力機制從自回歸的教師模型中學習,并行生成中間表征。
不同于Fastspeech 需要對齊模型或者Paranet 依賴自回歸的教師模型。GlowTTS[53]通過流和單調對齊搜索方法可以高速生成中間表征。基于流的聲學模型是研究的熱點,比起基于概率密度蒸餾的聲學模型,基于流的聲學模型結構更加簡單,模型也更加穩定。
3 語音合成系統
3.1 傳統和深度學習結合語音合成
將深度學習引入到經典語音合成各個模塊中建模是一種有效的語音合成方法,Deep Voice-1是這種方法的代表。Deep Voice-1合成速度快,合成語音質量也較高。但系統由多個模塊組成,容易產生累積誤差且誤差難以定位。
Deep Voice-2 在Deep Voice-1 基礎上改進了多說話人語音合成系統,方法是將說話人矢量引入到模型中訓練。目前直接將深度學習引入到經典語音合成系統各個模塊中建模的研究已經不多了,Deep Voice 系列的第三代Deep Voice-3 已經轉為采用端到端語音合成方法。
3.2 端到端語音合成系統
文獻[40]是首個端到端語音合成系統,開啟了端到端語音合成系統的研究。該系統需要一個預訓練的隱馬爾科夫對齊模塊輔助聲學模型學習文本與語音在時間上的對齊,其次該系統采用一些輔助的訓練技巧會影響合成語音質量。
Char2Wav[54]有閱讀器和聲碼器兩部分。閱讀器有編碼器和解碼器組成,編碼器是一個雙向的循環神經網絡,解碼器是基于注意力機制的循環神經網絡,聲碼器是SampleRNN。
Tacotron-1語音合成系統聲學模型是基于內容注意力機制的聲學模型,聲碼器是Griffin-Lim 算法,Griffin-Lim算法不是深度學習模型,文獻[42]提出可以將Griffin-Lim算法替換為基于深度學習的聲碼器。Tacotron-2在Tacotron-1的基礎上采用了Wavenet作為聲碼器。
Tacotron 系列語音合成系統架構簡單,合成語音質量高。WaveTTS[55]在Tacotron系列原有頻域損失函數基礎上引入時域的損失函數,這樣可以提高合成語音的質量。針對Tacotron 解碼器采用的強制教學模式會造成曝光偏差問題,文獻[56]提出用概率密度蒸餾的方法,訓練教師解碼器時采用強制教學方法,而訓練學生解碼器采用常規的自回歸方式,通過優化學生解碼器和教師解碼器的輸出誤差提高學生解碼器的準確性,從而減少曝光誤差。文獻[57]則采用對抗生成網絡的方式避免曝光誤差。
文獻[58]使用Tacotron 聲學模型和Excitnet 聲碼器組成端到端語音合成系統,該系統可以合成具有特定風格的語音。
Deep Voice-3是全卷積語音合成系統,聲學模型可以生成多種中間表征,對應也有多種聲碼器。Deep Voice-3 可以學習多說話人語音且訓練時間短、合成語音速度快。
VoiceLoop[59]在文本到中間表征過程中在編碼解碼的基礎上添加了固定大小的緩存機制,這樣可以減少模型的復雜度,VoiceLoop聲碼器是WORLD[60]。
Clarinet是在Parallel Wavenet和Deep Voice-3基礎上改進的可以高速訓練和并行生成的完全意義上端到端的語音合成系統。Clarinet通過單個神經網絡直接將文本轉換為語音波形。Tacotron、Deep Voice-3 等語音合成系統是先將文本轉換為頻譜,然后將頻譜轉換成語音。Clarinet 完全從文本到原始語音波形的端到端訓練,實現了對整個語音合成系統的聯合優化。比起分別訓練的模型,Clarinet 在語音合成的自然度上有大幅提升。
文獻[61]提出使用Transformer替代Tacotron-2中的注意力機制,這樣編碼器和解碼器可以同時工作,提高了合成語音速度,基于Transform 的自注意力機制更好地適應長序列依賴問題。
4 研究展望
聲碼器是語音合成技術的基礎,聲碼器的發展歷經了自回歸式到并行式兩個階段。目前聲碼器已經可以滿足不同場景的需求,但是高質量的聲碼器模型規模比較大,這意味著訓練和部署模型需要較多的資源,而這些資源往往不是很充沛。所以如何在較少的資源上提高聲碼器的性能是研究的一個方向,目前很多研究是在聲碼器性能和模型復雜度之間做權衡。
端到端語音合成系統有漏發音和誤發音的問題。這其中的一個原因是聲學模型生成中間表征不穩定,特別是采用序列到序列加注意力機制的聲學模型有曝光偏差等問題。如何解決聲學模型結果不穩定是一個研究熱點。一些解決的方法有將注意力機制由位置敏感改為相關位置敏感[62],采用蒸餾學習[56],增加時長控制和自適應優化策略[63]或者將改變注意力策略[64]以及應用額外的注意力機制輔助學習[65-66]等。
現階段語音合成系統雖然可以實現高質量的語音合成,但是難以控制合成語音的風格:不同人會有不同風格,同一個人在不同狀態下也會有不同的語音特點。目前常用的辦法有預先從語音中提出可以表征韻律變化的隱變量,將隱變量代入語音合成模型中[67-69]訓練、引入新的文本特征[70]或者引入句法、語義結構等信息[71]。
現有的語音合成系統都需要大量的語音文本數據,但現實中這些數據往往很難獲得,所以如何能在較小的數據集上訓練出高質量語音合成模型是一個研究方向。現有的方法有基于遷移學習[72]和半監督學習方法[73]等。
合成的語音仔細識別仍可以區分出自然語言和合成語音,這是因為合成語音過程中存在聲學模型不準確、過度平滑以及聲碼器不準確等問題。所以如何能降低這些問題對合成語音的影響是研究的一個方向,文獻[74-75]提出在合成語音過程中增加語音增強的模塊,比如聲學特征增強、語音增強等。
一句話中可能會包含多種語言,比如漢語和英語。這種跨語種的語音合成也是一個研究方向,一些做法是找到一種可以表示相關語種特征的矢量,然后將特征矢量嵌入語音合成模型[76]中訓練。
5 結束語
基于深度學習的語音合成技術無論是在合成語音質量上還是速度上都取得了重大的進展。聲碼器是語音合成技術的基礎,基于深度學習的聲碼器歷經了自回歸式和并行式兩個階段。自回歸式可以生成高質量的語音,但速度慢,并行式可以快速生成語音,但存在著模型較大,訓練過程比較復雜等問題。聲學模型將文本轉化成中間表征,和聲碼器相似,聲學模型也經歷了自回歸式和并行式兩個階段。端到端語音合成系統將聲學模型和聲碼器結合建模,直接建立起從文本到語音的合成,降低了語音合成研究對專業知識的要求,是目前研究較多的語音合成方法。
語音合成應用場景豐富,不同場景對語音合成的要求也不盡相同。滿足在不同場景下的要求將是語音合成發展的一大考驗。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
