低電阻率三元金合金材料的逆向設計
2021-05-15 02:38:54王向東徐鵬程劉秀娟陸文聰
中國材料進展 2021年4期
王向東,徐鵬程,盧 天,劉秀娟,陸文聰,
(1.上海大學 材料基因組工程研究院,上海 200444)(2.上海大學理學院,上海 200444)
1 前 言
近年來,機器學習(machine learning, ML)或數據挖掘已經成功地應用于材料科學研究中[1-4]。例如,Xue等[5]報道了如何通過自適應設計加速尋找具有目標性能的新材料,并進行了推理和全局優化,以尋找具有極低熱滯后的鎳鈦基形狀記憶合金。何鵬程等[6]報道了模式識別在核殼結構鈷鋁復合氫氧化物形貌可控合成中的應用。由于三元金合金組分和配比的復雜性,到目前為止,找到一種簡單、有效的方法來設計具有理想性能的新材料仍然是一項挑戰。我們期望通過ML模型設計出性能更好的新材料,從而加速對新材料的研究。
金合金具有接觸電阻低、導電性和導熱性良好、噪音電平低以及抗有機氣氛污染能力良好等優良的電學和化學性能[7, 8],故金合金在電接觸材料方面具有很好的應用前景,尤其是在輕負荷、小接觸壓力使用條件下更能顯示其優良的特性[9-11]。電接觸材料一般在電器開關中使用,電阻率是其重要特性之一,因此研究低電阻率三元金合金具有非常重要的意義。
本工作采用的材料設計策略流程如圖1所示。原始數據由51個三元金合金樣本組成,利用最大相關最小冗余(mRMR)結合XGBoost算法篩選出建模的特征變量,然后應用作者實驗室開發的模式識別逆投影方法設計了3個低電阻率三元金合金候選樣本,最后通過XGBoost模型估算出候選樣本的電阻率。
2 實驗方法
2.1 數據集與描述符
本文原始數據來自于材料數據科學平臺(MPDS)數據庫[12, 13],它由51個在常溫常壓下的三元金合金樣本組成。在數據集中,用化學符號表示三元金合金(ABC)時,先將Au元素排在A位,然后將其他兩個元素按電負性上升的順序排列,若兩個元素的電負性相同,則再按價電子數上升的順序排列。對目標值電阻率取負對數,得到其數值在4~6.8之間。將數據集中-lgρ大于5.71(數據集的中位數)的劃分為優類樣本(good samples),將-lgρ小于5.71的劃分為劣類樣本(bad samples),因此可得到優類樣本26個,劣類樣本25個。本工作中共收集了64個特征描述符[14],其中包括62個原子參數描述符和2個組分描述符。
2.2 最大相關最小冗余算法
mRMR算法是一種濾波式的特征篩選算法,它以不同的方式在相關性和冗余度之間進行權衡,并且以互信息作為計算準則來比較特征與類變量之間的相關性以及特征之間的冗余度,通過最大化特征與類變量的相關性以及最小化特征之間的冗余度來進行特征選擇[15]。
最大相關性原理是指選擇那些與模型具有最大相關性的特征,相關性越大,則說明訓練出的模型解決問題的能力越強。特征之間的相關性越大,則冗余度越高。為了減少特征之間的冗余度并使每個特征具有代表性,需要將冗余度降低到最小,這就是最小冗余原理。
2.3 統計模式識別
統計模式識別是ML的主要方法之一, 為了實現統計模式識別方法的自動建模,有必要從通過不同方法獲得的眾多投影圖中自動選擇最佳模式識別分類投影圖(二維投影面)[16]。
2.3.1 最佳投影識別法
由于不同的計算原理,不同的統計模式識別方法可以獲得不同分類結果的投影圖。但即使相同的統計模式識別方法也可能具有不同的投影方向,如主成分分析(PCA)方法能得出N(N-1)/2個不同的投影圖, 其中N為特征變量數。為此, 我們利用最佳投影識別法[17]探索尋找分類最佳的二維投影面, 其原理是在計算了若干個統計模式識別投影后(本工作應用了主成分、偏最小二乘、Fisher判別矢量、球形映照等投影),使用迭代方法在每個隱含的投影平面上搜索出最佳分類的投影圖,即在該投影圖上將優類樣本在一定范圍內聚集, 且使優化區(優類樣本分布范圍)混合的劣類樣本的數量盡可能少。
2.3.2 逆投影法
模式識別投影圖上顯示的樣本點的坐標是各原始特征變量的線性組合或是某種沒有實際意義的映像,實際工作中實施的“優化樣本”必須由原始特征變量來表示,因此需要通過特定的算法將二維模式識別圖上優化區域中設計的“優化樣本”返回到原始樣本,該過程被稱為“逆投影”[6]。
逆投影是為二維空間的設計點找到多維空間的源像。如果沒有約束條件,那么逆投影將有無數多個解,故逆投影的結果只有在某些約束條件下才是唯一的。例如,為線性逆投影引入的約束條件是將設計點在各個投影矢量上的坐標取定值,而為非線性逆投影引入的約束是使逆投影的誤差函數最小。
本工作采用線性的模式識別逆投影方法,只需要用戶在投影圖上設定一個點,就能得到一組由橫縱坐標的投影矢量所決定的聯立方程組(含2個方程組),如式(1)所示:
(1)
其中,xij為第i個投影上的第j個特征變量(有n個),aij和bi是決定模式識別投影的系數,ci是設計樣本的投影坐標。由式(1)確定的定量關系只有2個,因此,若想得到唯一解,必須給定n-2個約束條件。本工作進一步采用n-2個變量的平均值代入上面的方程,則可將上面的方程轉化為二元一次線性方程組,從而求得該方程組的唯一解。
3 結果與討論
3.1 變量篩選
變量篩選的目的是去除冗余的自變量,用盡可能少的自變量建立預報結果盡可能好的ML模型。為了去除共線性的自變量,本工作計算了所有64個特征描述符(自變量)之間的皮爾遜相關系數,若2個變量間的皮爾遜相關系數大于0.9,則刪除其中一個變量[18]。任意2個描述符x和y之間的皮爾遜相關系數(R)的計算如式(2)所示:
(2)

利用mRMR算法對44個特征變量進行排序[15]。圖2給出了排序在前15的變量間的皮爾遜相關系數熱圖。隨后通過XGBoost算法篩選出與ML的最優變量子集[19]。為了評估變量子集,采用實驗值與留一法預測值之間的相關系數(R)來評價變量篩選的效果,最優變量子集相應的R值最大。從圖3可以看到相關系數R與所選變量數之間的關系,即R值隨著變量數先增加,在達到最大值之后逐漸減小。因為最合適的變量數可能在峰值附近,因此選擇了前11個變量進行了更詳細的計算。從圖3中可以發現,R的趨勢與均方根誤差(RMSE)正好相反,利用前5個變量所建的XGBoost模型擁有最好的表現,即最大的R值與最小的RMSE值,故選擇前5個變量進行后續的ML建模和材料設計。這5個變量分別為B位組分數(RB)、C位組分數(RC)、C位電負性(χC)、B位第二電離能(I2B)、C位第一電離能(I1C)。
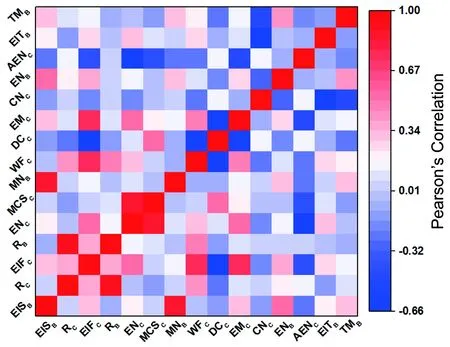
圖2 排序在前15的變量間的皮爾遜相關系數熱圖Fig.2 Heat map of Pearson correlation coefficient among the top 15 variables
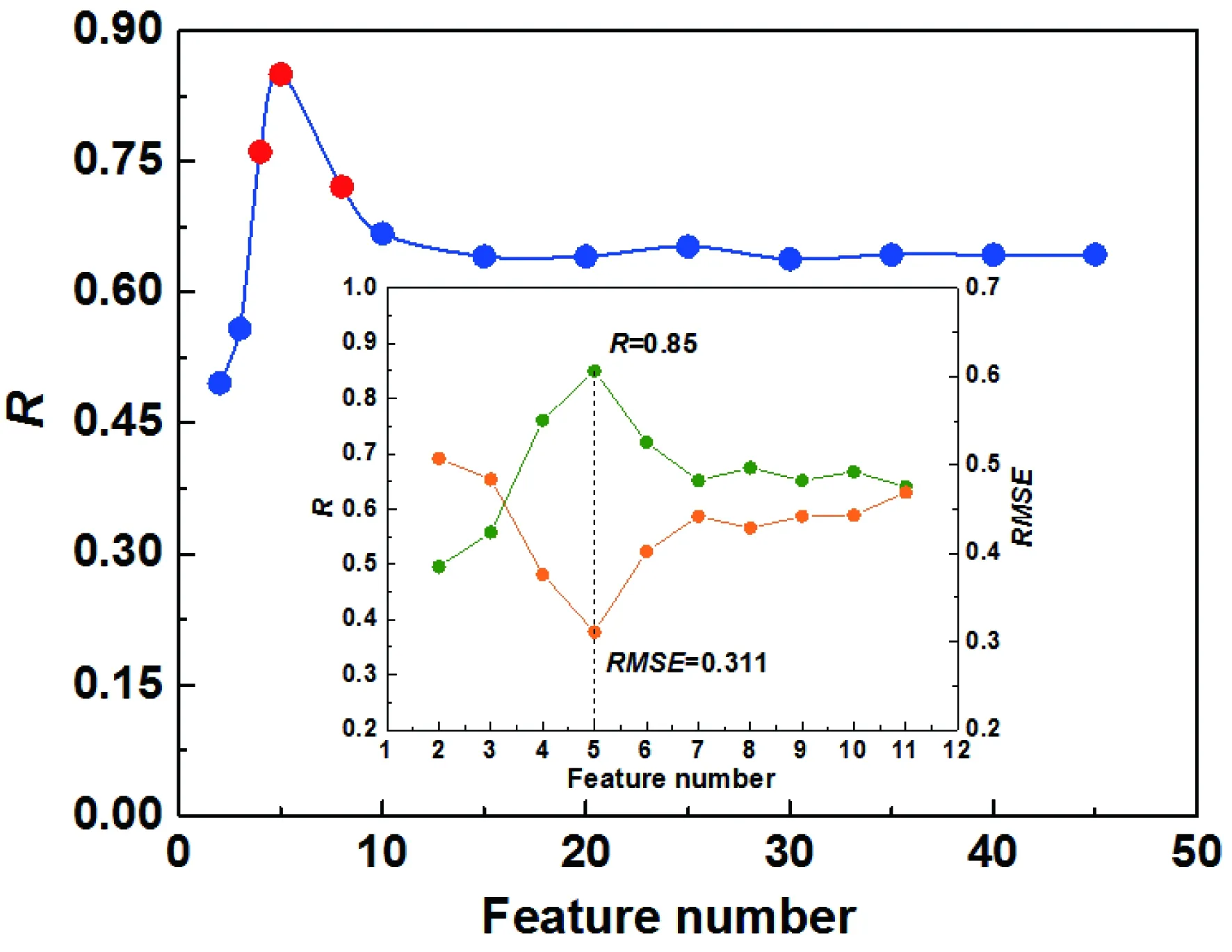
圖3 mRMR-XGBoost進行變量篩選Fig.3 Variable screening by mRMR-XGBoost
3.2 逆向設計
利用本實驗室的HyperMiner數據挖掘軟件[20],以RB、RC、I2B、χC和I1C為特征變量,電阻率為目標值,經過最佳投影計算,得到如圖4所示的最佳模式識別投影圖及逆投影點,對應于PCA方法的第一主成分PCA(1)和第三主成分PCA(3)構成的投影圖,發現有明顯的統計分布規律[6, 21, 22]。圖4中的矩形區域為優化區,其中優類樣本約占70.3%,高于總樣本中優類樣本所占比例(51%)。由此得出,若要得到低電阻率的三元金合金,則設計的三元金合金樣本應盡可能控制在優化區內。圖4中優化區分布范圍可由如下聯立方程組式(3)和式(4)表示:
4.530≤0.648[RB]+0.207[RC]+8.531×10-4[EISB]+
1.005[ENC]+4.358×10-3[EIFC]≤8.322
(3)
0.915≤-6.979×10-3[RB]+7.821×10-2[RC]+4.678×10-3
[EISB]-1.775[ENC]-1.211×10-3[EIFC]≤4.485
(4)
在最佳模式識別投影圖中選取3個點作為虛擬樣本(virtual samples),如圖4所示。然后使用模式識別逆投影的方法計算出3個虛擬樣本的特征變量(表1)。最后通過計算歐式距離,得到與虛擬樣本點最接近的候選樣本,如表2所示。
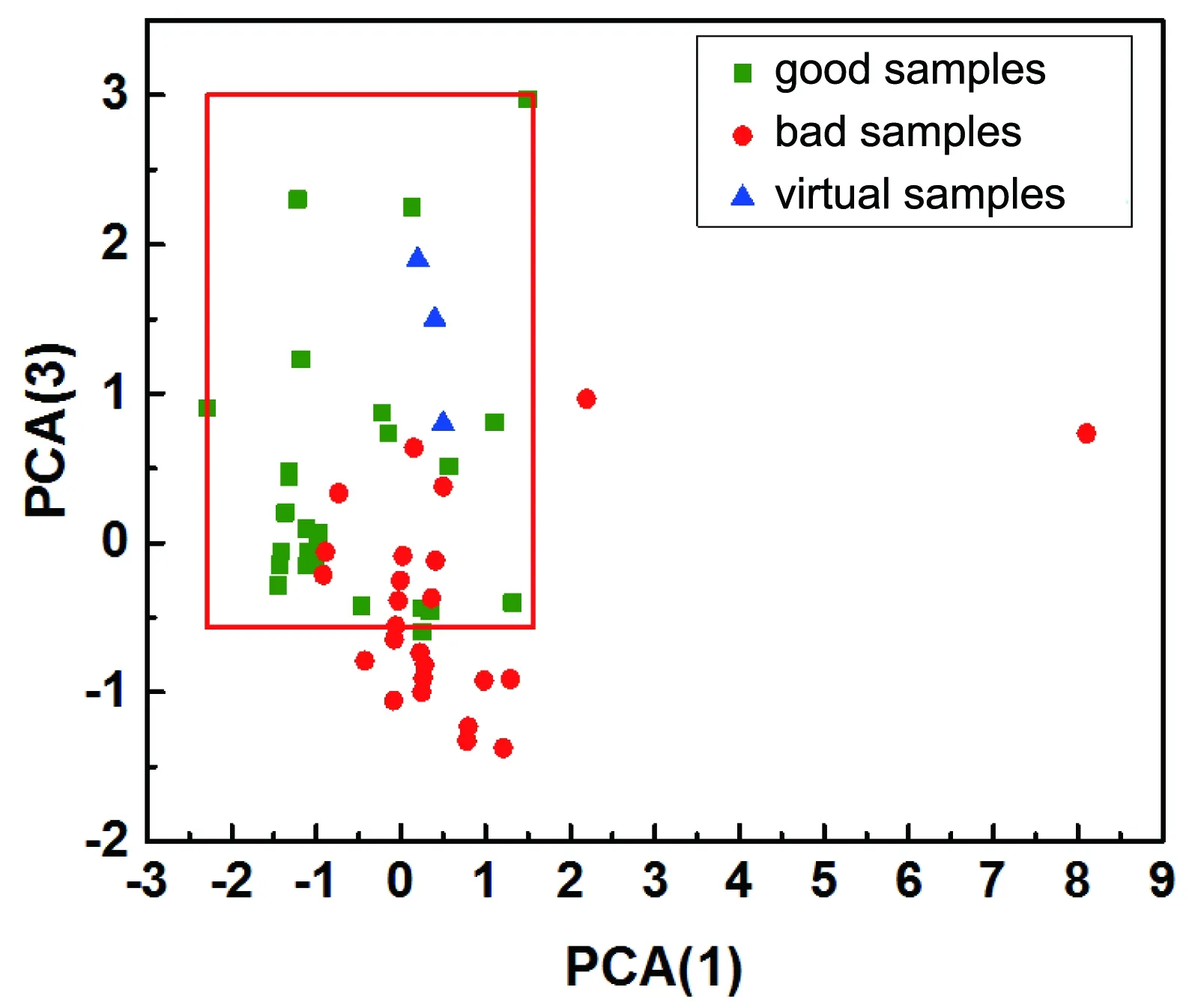
圖4 最佳模式識別投影圖及逆投影點(虛擬樣本)Fig.4 Optimal pattern recognition projection diagram and inverse projection point(virtual samples)
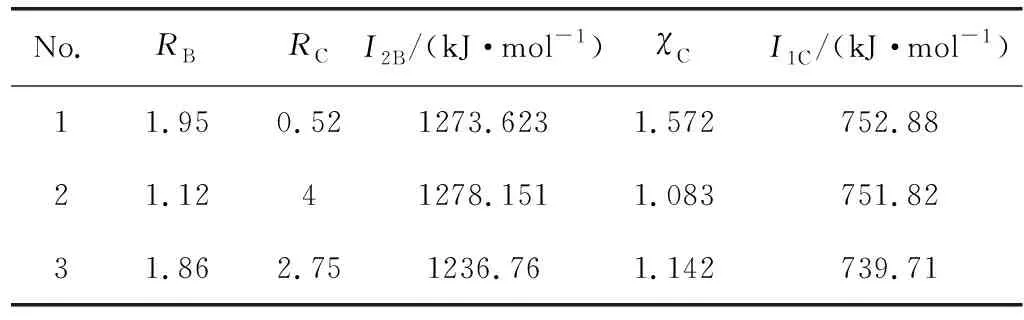
表1 逆向設計的虛擬樣本Table 1 Virtual samples of inverse design
由表2可知,候選樣本分別由1個前過渡元素和2個后過渡元素組成。依據Chen等[23]研究中3個過渡元素金屬間化合物的形成規律,可得出結論,Rsp(B)/Rsp(C)>1.3的三元合金系能形成三元金屬間化合物(Rsp表示原子偽勢半徑)。因為Rsp(Zr)/Rsp(Cu)為1.38,Rsp(Sc)/Rsp(Cu)為1.35,均大于1.3,所以候選樣本可形成三元合金。
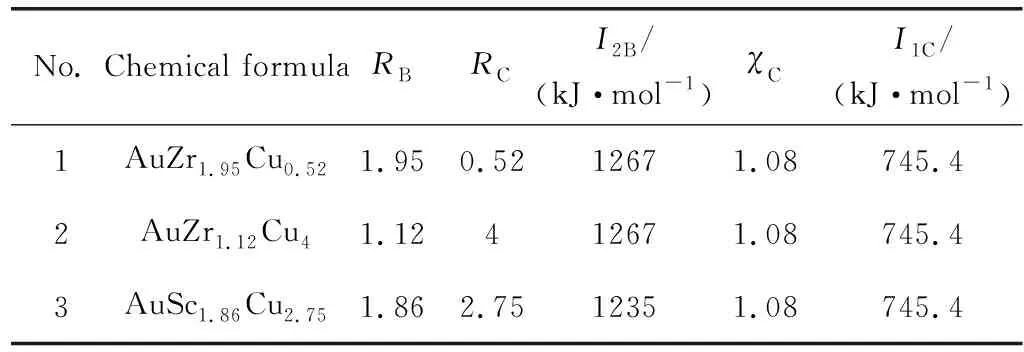
表2 對應虛擬樣本的候選樣本Table 2 Candidate samples corresponding to virtual samples
3.3 性能估算
采用4種不同的ML算法,即XGBoost、支持向量回歸(SVR,采用徑向基核函數)[24]、多元線性回歸(MLR)[25]和嶺回歸(KRR)[26],來構建-lgρ與特征變量的ML模型。根據每種算法的留一法交叉驗證的表現篩選-lgρ性能估算模型。從圖5可以看出XGBoost模型擁有最高的R值和最低的RMSE值,分別為0.850和0.331,超過了其他模型的結果[27]。因此,后續選擇XGBoost模型進行三元金合金-lgρ的估算。
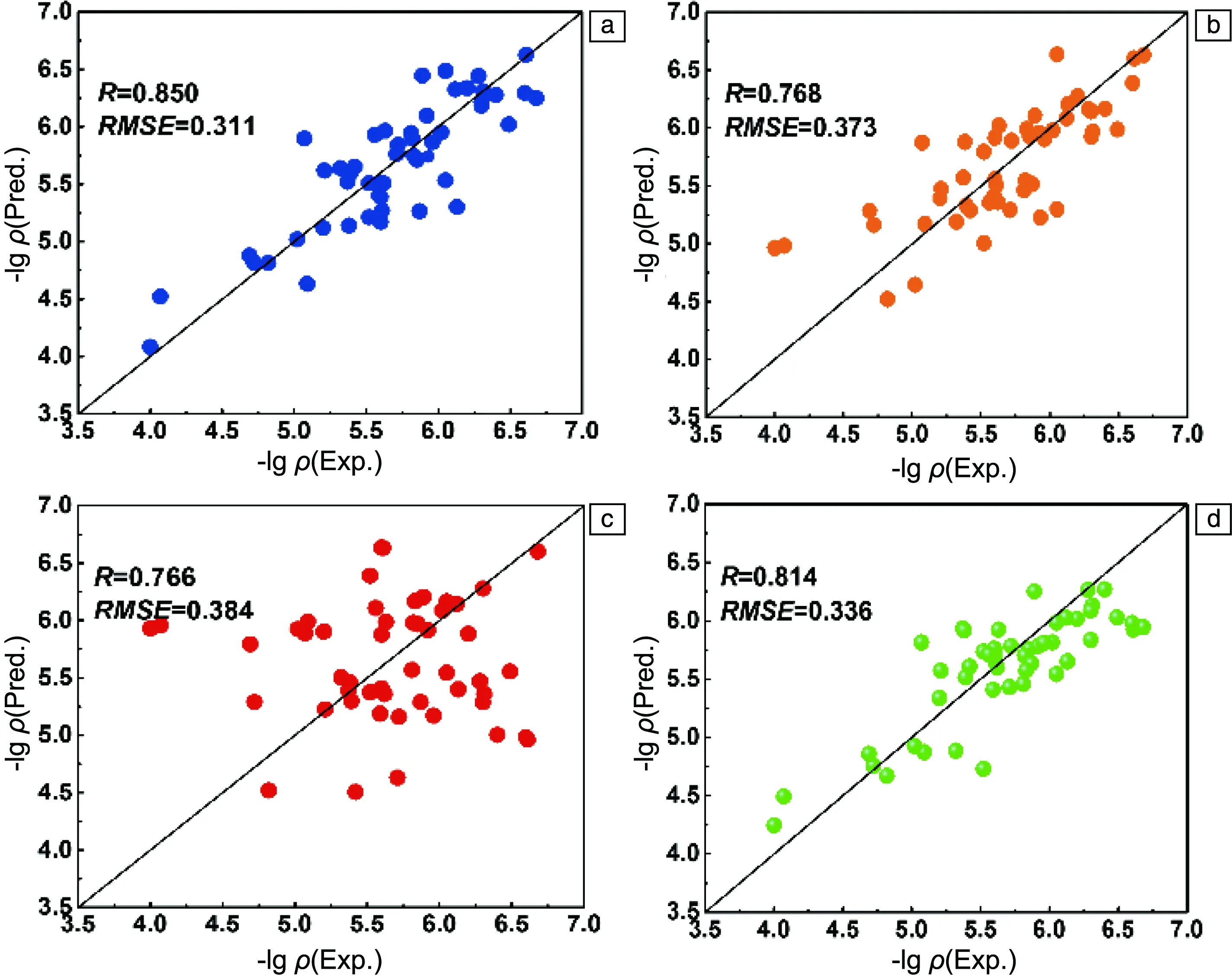
圖5 采用不同ML算法測得的三元金合金-lg ρ預測值(Pred.)與實驗值(Exp.):(a)XGBoost,(b)KRR,(c)MLR,(d)SVRFig.5 Predicted value (Pred.) and experimental value (Exp.) of -lg ρ of ternary gold alloys by using different ML algorithms:(a) XGBoost, (b) KRR, (c) MLR, (d)SVR
使用XGBoost模型對候選樣本的-lgρ進行估算,可得到3個候選樣本的-lgρ值,如表3所示。從表3中可以看出,候選樣本的-lgρ值均大于原始數據集中-lgρ的最大值6.68,故模式識別及其逆投影算法可用于低電阻率三元金合金材料的逆向設計。
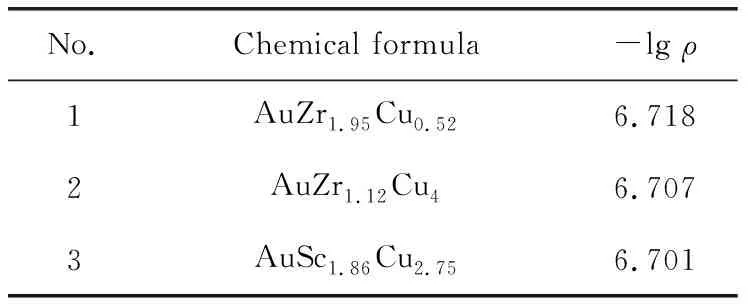
表3 候選樣本估算值Table 3 Estimated values of candidate samples
4 結 論
本文以設計低電阻率三元金合金為目標,利用本實驗室的HyperMiner數據挖掘軟件,通過模式識別最佳投影找出了形成低電阻率三元金合金的邊界條件,然后應用模式識別逆投影方法設計了3個低電阻率三元金合金候選樣本,最后通過XGBoost模型估算出候選樣本的電阻率。結果表明,根據逆投影方法設計的AuZr1.95Cu0.52、AuZr1.12Cu4和AuSc1.86Cu2.75樣本具有較低的電阻率,其-lgρ預報值分別為6.718,6.707和6.701,均超過了原始數據集-lgρ的最大值6.68。因此,本工作的研究方法可用于指導新材料的理論設計,有助于實驗數據的統計規律挖掘,用以加快新材料設計發展。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術啟蒙(2018年7期)2018-08-23 09:14:18
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
電子測試(2017年23期)2017-04-04 05:06:50
智能系統學報(2017年5期)2017-01-22 11:21:30
智能系統學報(2015年3期)2015-01-29 15:20:12
河南科技(2014年23期)2014-02-27 14:19:15
