基于標簽的協同過濾推薦方法研究
2021-05-21 08:33:35齊晶劉瀛劉艷霞胡美振樂海豐
北京聯合大學學報 2021年2期
齊晶 劉瀛 劉艷霞 胡美振 樂海豐


[摘 要] 摘要傳統基于物品的協同過濾算法由于物品相似度矩陣稀疏,推薦準確率不高。針對這一問題,提出一種基于標簽和改進杰卡德系數的協同過濾算法,進行電視節目個性化推薦。首先,爬取相關信息對原始數據進行擴充,并利用統計學方法對時間特征進行歸一化處理,計算用戶偏好系數;然后,統計出現次數較高的類別作為推薦類別標簽,并利用改進的杰卡德系數構造標簽相似度矩陣;最后,根據推薦類別標簽的用戶偏好系數計算節目的推薦系數。實驗結果表明,基于標簽的協同過濾算法可以降低稀疏矩陣對推薦準確率的影響,相比基于物品的協同過濾算法,準確率提高了5%,召回率提高了3.1%。另外,使用改進的杰卡德系數計算相似度,減少了熱門標簽對推薦系統的影響,進一步將準確率提高了5%,召回率提高了2.3%。
[關鍵詞] 關鍵詞協同過濾;標簽類別相似度;個性化推薦;懲罰系數;杰卡德系數
[中圖分類號] 中圖分類號TP 391.3[文獻標志碼] A[文章編號] 1005-0310(2021)02-0047-06
Research on Collaborative Filtering Recommendation Method Based on
Labels
Qi Jing1,Liu Ying2,Liu Yanxia2,Hu Meizhen2,Le Haifeng3
(1. Tourism College, Beijing Union University, Beijing 100101, China; 2. College of Urban Rail Transit and Logistics, Beijing Union University, Beijing 100101, China; 3. College of Robotics, Beijing Union University, Beijing 100101, China)
Abstract: 摘要In the era of big data, traditional itembased collaborative filtering algorithms lead to the sparseness of item similarity matrix, and the recommendation accuracy rate is not high. To solve this problem, a labelbased collaborative filtering algorithm is proposed. First, this algorithm expands the original data by crawling the relevant information, and uses statistical methods to normalize the time characteristics to calculate the user preference coefficient. Next, it selects those with higher occurrences from all crawled categories as recommended category labels. The category constructs a label similarity matrix using the improved Jaccard coefficients that incorporate the penalty coefficients. Finally, the program recommendation coefficients are calculated according to the user preference coefficients of the recommended category labels. The experimental results show that the
labelbased
collaborativefiltering algorithm can reduce the influence of sparse matrix on the recommendation accuracy. Compared with the
itembased collaborative filtering algorithm,
the accuracy rate increases by 5% and the recall rate increases by 3.1%. In addition, using the improved Jaccard coefficient to calculate the similarity can reduce the influence of hot tags on the recommendation system, and further improve the accuracy rate by 5% and the recall rate by 2.3% on the labelbased collaborative filtering algorithm.
Keywords: 關鍵詞Collaborative filtering; Label category similarity; Personalized recommendation; Penalty coefficient; Jaccard coefficient
0 引言
北京聯合大學學報2021年4月第35卷第2期齊 晶等:基于標簽的協同過濾推薦方法研究
隨著電視“互聯網+”和電子商務的興起,個性化推薦有了突飛猛進的發展,相關研究主要集中在推薦算法和推薦應用,不同類型的物品使用不同的推薦算法來達到既定的目的[1]。在推薦算法中,最常用的經典推薦算法包括協同過濾推薦算法、基于內容的推薦算法和基于數據挖掘的推薦算法等[2]。協同過濾推薦算法是通過利用客戶的以往記錄信息建立數學模型,然后對客戶進行推薦;基于內容的推薦算法是根據客戶對內容的喜好建立客戶興趣模型,進一步求解內容-客戶相似度進行產品推薦[3];基于數據挖掘的推薦算法利用從大數據中挖掘到的相關知識對客戶進行推薦。隨著客戶和商品的數目不斷增長,計算的評價矩陣面臨稀疏性問題。為解決這個問題, Sarwar等提出利用奇異值分解評價矩陣,壓縮矩陣維度[4]。Yu等用信息理論的方法衡量客戶和商品相關度,采用特征加權求和方法改進傳統推薦算法,可以提高推薦的準確率和速度[5]。于洪等則利用客戶時間信息作為權重改進傳統方法,可以有效解決對新客戶的推薦問題[6]。黃創光等提出了不確定性近鄰用戶的方法,可在不同應用場景下自適應選擇近鄰用戶[7]。
在傳統的推薦算法中,客戶對商品信息的記錄(例如評分,很多用戶不會主動對商品進行評分)往往很少,這就會導致數據非常稀疏,影響系統推薦的準確率,因此,能否挖掘出有用且充分的信息成為推薦準確率的關鍵。徐德智等將推薦算法和云模型相結合,用云模型計算用戶之間相似度,可以提高推薦系統的準確率[8]。張光衛等融合知識處理機制來計算用戶相似度,利用云模型在知識之間進行定性和定量的轉換,進一步提高用戶之間相似度的準確性[9]。蔣翠清等將PLSA模型應用在用戶相似度計算上,把用戶信息映射到更加明確的語義上,解決了用戶信息語義模糊問題[10]。Kim等則利用聚類方法改進傳統算法,擴展了傳統算法的應用性[11]。然而,這些算法都沒有討論熱門物品或者活躍用戶對推薦結果準確率的影響,并融合相關信息進行推薦。
本文提出一種基于項目標簽的協同過濾算法,并利用懲罰系數減少熱門標簽對相似度矩陣計算的影響,將推薦項目的類別與用戶偏好系數相融合計算項目推薦系數,完成節目推薦。算法分為數據處理、特征提取和算法改進3個階段。
1 數據處理
1.1 數據集
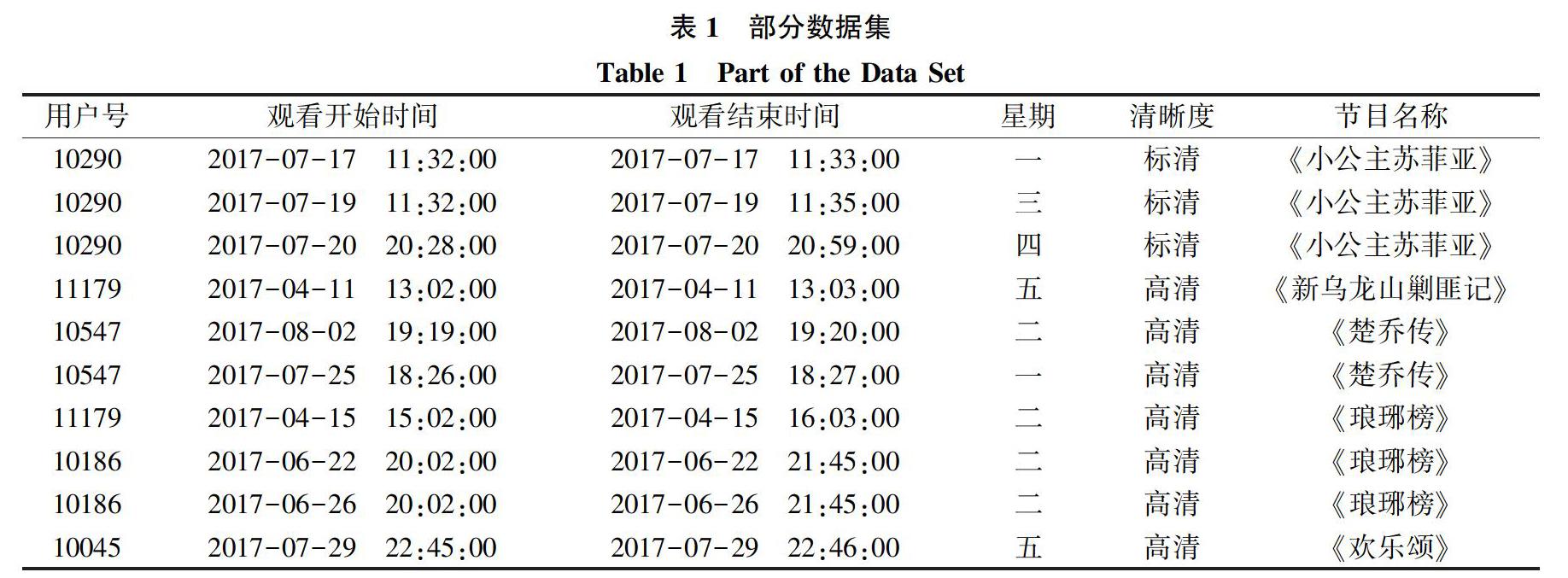
數據來自機頂盒用戶實際觀看記錄,統計時間從2017年4月到10月,數據項包括用戶ID、觀看開始時間,觀看結束時間、星期、清晰度、節目名稱等。部分數據集如表1所示。
1.2 數據預處理
在數據挖掘前須對原始數據進行預處理,以便后期特征提取和建模。預處理步驟如下:
1) 基于物品的協同過濾算法相似度矩陣非常稀疏,影響推薦準確度
。本文嘗試基于標簽的協同過濾算法,根據數據集中的節目名稱爬取節目類型標簽,補充數據集信息。
2) 將同一用戶在不同時間段觀看的同一節目時間進行累加合并。如表1中,用戶10290在不同時間段觀看《小公主蘇菲亞》,將其觀看時間相加得到此用戶觀看該節目的總時間。
3) 將爬取到的類別標簽與數據集中相應的節目進行匹配,建立標簽字典,記錄所有標簽出現的頻率,排除出現次數過低的標簽。
4) 利用融合以后的總時間計算用戶偏好系數(計算過程在2.1節中說明)。
5) 在用戶偏好系數中,設置閾值為0.12,即觀看時間為5分鐘,排除小于閾值的觀看記錄。
6) 在清洗過的數據集中隨機抽取80%作為訓練集,20%作為測試集,分別用來訓練和評估模型。數據預處理結果如表2所示。
2 特征提取
2.1 用戶偏好系數計算
用戶對節目的評分是其偏好程度最直觀的反映,遺憾的是多數用戶的評分項是缺失的,巨大的稀疏性導致評分項并不能反映每個用戶的
偏好系數。本文根據用戶對每個節目的觀看時長計算其偏好系數,如式(1)所示。
Pi=Tei-Tsi。(1)
其中,Tei是用戶觀看第i(i[1,n])個節目的結束時間,Tsi為用戶觀看第i個節目的開始時間。為使用戶觀看時長具有可比性,便于計算推薦系數,須進行標準化和歸一化處理,如式(2)和(3)所示。
Qi=Pi-μσ。(2)
Ni=Qi-QminQmax-Qmin。(3)
其中,μ為全部用戶觀看節目時長的均值,μ=ni=1pin;σ為標準差,σ=1nni=1(pi-μ)2;Ni為歸一化后的偏好系數。
2.2 標簽相似度矩陣
將所有用戶觀看的電視節目預先劃分到不同的類別標簽中,構造一棵類別-節目樹,如圖1所示。屬于同一類別的節目相似度顯然高于屬于不同類別之間的節目。
1) 構建用戶-標簽矩陣。統計每個用戶觀看過的類別標簽,看過的標記為1,沒看過的標記為0。部分用戶-標簽矩陣如表3所示。
2) 構建標簽-標簽矩陣。利用杰卡德系數計算兩個不同類別標簽之間的相似度方法為
J(A,B)=A∩BA∪B。(4)
其中,A、B為不同的標簽類別。A∩B表示在用戶-標簽矩陣中,這兩個標簽類別同時被標注為1的用戶總數;A∪B表示在用戶-標簽矩陣中,這兩個標簽類別的任何一個或兩個被標注為1的用戶總數。例如,對于表3中4個用戶而言,劇情和喜劇之間A∩B=1, A∪B=4,相似度約為0.25。對于相同類別,即將標簽-標簽矩陣中的對角線數值設置為0。針對全部用戶,采用傳統杰卡德系數計算相似度時,沒有考慮熱門物品對計算結果的影響,會影響推薦系統的準確率,計算結果如表4所示。
在計算物品相似度時,加入懲罰因子,如式(5)所示,以減少熱門物品對計算結果的影響,計算結果如表5所示。
J(A,B)=A∩BA∪B×1A∪B。(5)
以用戶2看過的類別標簽(喜劇)為例,在標簽-標簽矩陣中,與喜劇標簽相似度最高的兩個標簽分別為劇情和動作。對比表4和表5發現,喜劇與劇情類別標簽相似度降為原來的6.63%,喜劇與動作類別標簽相似度降為原來的8.16%,喜劇與動畫類別標簽相似度降為原來的8.18%。明顯可以看出,加入懲罰因子后,與熱門標簽相關的類別相似度降幅最大。據此進行電視節目推薦,可以避免熱門標簽對電視節目推薦所占權重過大的問題。實驗表明,改進杰卡德相似系數可以提高推薦系統的準確率和召回率。
3 算法改進
利用傳統算法推薦節目時,先基于用戶觀看過的節目信息,再根據節目-節目相似度矩陣,直接選擇K個相似度較大的節目推薦,并忽略已觀看的節目。基于標簽的協同過濾算法不同于傳統基于物品的協同過濾算法,除了選擇K個相似度較大的新標簽類別進行預推薦外,也不忽略已觀看的標簽類別,因為屬于這類標簽的新節目更值得向用戶推薦。
3.1 新標簽類別的節目推薦
向用戶推薦新標簽類別節目的主要過程分兩步:
1) 計算新標簽和用戶已觀看標簽類別間的相似度。對于測試集D中的某用戶Ui(UiD),根據其已觀看的類別標簽信息,在標簽-標簽矩陣
S中選擇與其觀看過的標簽Xj相似度排名前k個的標簽類別,作為預推薦標簽。這些標簽類別和用戶Ui觀看過的標簽類別Xj之間的相似度系數為Sxj,ki。
2) 計算節目推薦系數。對于預推薦的標簽類別ki,統計訓練集T中所有用戶Tu對屬于ki標簽類別的節目m的偏好系數λkim,并從大到小排序。假設λkim1≥λkim2≥λkim3≥λkim4≥λkim5≥...,選擇前5個節目m1,m2...,m5進行推薦,推薦系數Rmj為
Rmj=Sxj,ki×λkimj。
(6)
3.2 已觀看標簽類別的節目推薦
對于用戶已觀看標簽類別的節目推薦過程也分兩步:
1) 計算已觀看標簽類別的影響因子。從測試集D中選擇某用戶Ui(UiD), 統計其所有已觀看的標簽類別X,并建立字典dict{Xj:nj},其中,XjX,nj為Xj在X中出現的次數。已觀看標簽類別對于推薦節目的影響因子j為
j=nj/n。(7)
其中,n為用戶Ui觀看所有節目標簽類別的總次數。
2) 計算節目推薦系數。對于已觀看標簽類別的節目推薦系數為
Rmj=j×λxjm。(8)
其中,λxjm為用戶Tu對已觀看標簽Xj中節目m的推薦系數。
3.3 選擇節目完成推薦
對上述得到的推薦系數Rmj從大到小排列,將前N個推薦系數所對應的電視節目iN={im1,im2,...,imN} 推薦給用戶Ui。
4 實驗結果及分析
4.1 評價指標
推薦系統的評測指標很多,常用的有平均誤差(MAE)、準確率(Precision)和召回率(Recall)。通常在離線環境下采用預測準確率來評測推薦系統預測用戶行為的能力。本文基于標簽的協同過濾算法采用準確率與召回率來度量,計算方法分別如式(9)和(10)所示。
P=u∈UR(u)∩T(u)u∈UR(u)。(9)
c=u∈UR(u)∩T(u)u∈UT(u)。(10)
其中,R(u)表示在訓練集上為用戶U推薦出的節目集合,T(u)表示用戶U在測試集上觀看過的節目集合。
4.2 實驗參數選擇
相似度較高的標簽類別數量(k)的選擇非常重要,直接影響模型推薦準確率。在基于標簽的協同過濾算法中,分別選擇k=1,2,3,4,5,6進行實驗。實驗表明,當k=2時推薦系統準確率和召回率相對較高,分別如圖2和3所示。
4.3 實驗結果比較
為驗證改進算法的效果,對傳統基于物品的協同過濾算法和本文所提出的基于標簽類別的協同過濾算法進行了實驗對比,準確率和召回率結果如圖4所示。
從圖4中可以看到,基于標簽的協同過濾算法比傳統基于物品的協同過濾算法,在準確率和召回率上都有更好的表現,準確率從10%提高到15%,召回率從13%提高到16.1%。這主要是因為改進算法降低了矩陣稀疏程度,更有利于提升推薦系統的準確率和召回率。
另外,改進杰卡德相似度系數對推薦系統性能和評價指標的影響如圖5所示。
從圖5可知,利用改進杰卡德系數計算標簽-標簽相似度矩陣,可使推薦系統的準確率和召回率進一步提升,其中,準確率提高了5%,召回率提高了2.3%。這主要是因為在改進杰卡德系數中加入了懲罰因子,對熱門標簽進行懲罰,減少了它對推薦結果的影響。
5 結束語
電視節目推薦不同于其他推薦系統,其推薦范圍大、用戶偏好廣、數據更加分散。這些特點使得電視節目推薦存在更大的挑戰,受到了很多學者關注。在協同過濾算法中,相似度矩陣的計算直接影響推薦系統性能[12]。本文提出的基于標簽的協同過濾算法,對標簽進行預推薦,大大減小了物品相似度矩陣的計算維度。另外,為了降低熱門標簽對推薦結果的影響,加入懲罰因子改進杰卡德系數。實驗結果表明,基于標簽的協同過濾算法和加入懲罰因子的杰卡德系數,相比傳統算法在準確率和召回率上都有一定程度的提高。
[參考文獻]
參考文獻內容
[1] 王強.基于協同過濾的個性化推薦算法研究及系統實現[D].成都:西南交通大學, 2017.
[2] 嵇曉聲,劉宴兵,羅來明.協同過濾中基于用戶興趣度的相似性度量方法[J].計算機應用,2010,30(10):2618-2620.
[3] 劉青文.基于協同過濾的推薦算法研究[D]. 合肥:中國科學技術大學,2013.
[4] SARWAR B,KARYPIS G,KONSTAN J, et al. Itembased collaborative filtering recommendation algorithms[C]//International Conference on World Wide Web. Hong Kong:ACM,2001:285-295.
[5] YU K,XU X,ESTER M,et al.Feature weighting and instance selection for collaborative filtering:An informationtheoretic approach [J].Knowledge & Information Systems, 2003, 5(2):201-224.
[6] 于洪,李俊華.一種解決新項目冷啟動問題的推薦算法[J].軟件學報,2015, 26(6):1395-1408.
[7] 黃創光,印鑒,汪靜,等.不確定近鄰的協同過濾推薦算法[J].計算機學報,2010, 33(8):1369-1377.
[8] 徐德智,李小慧.基于云模型的項目評分預測推薦算法[J].計算機工程,2010, 36(17):48-50.
[9] 張光衛,李德毅,李鵬,等. 基于云模型的協同過濾推薦算法[J].軟件學報,2007,18(10):2403-2411.
[10] 蔣翠清,張玉,陸文星,等. 基于標簽的大眾標注系統協同推薦算法[J].情報學報,2011,30(11):1152-1157.
[11] KIM T H, YANG S B. An effective recommendation algorithm for clusteringbased recommender systems[C]// AI 2005: Advances in Artificial Intelligence. Springer Berlin Heidelberg,2005: 1150-1153.
[12] 趙培.面向家庭用戶的電視節目動態推薦方法研究[D].合肥:合肥工業大學, 2017.
(責任編輯 責任編輯白麗媛)
