基于高光譜成像技術的小麥籽粒品種鑒別方法研究
2021-05-26 08:28:10吳永清賀媛媛郭波莉巨明月張影全孫倩倩
中國糧油學報 2021年4期
吳永清 李 明 賀媛媛 郭波莉 張 波 巨明月 張影全 孫倩倩
(中國農業科學院農產品加工研究所;農業農村部農產品加工重點實驗室,北京 100193)
小麥是重要的糧食作物之一,產量僅次于水稻位居第二位,是中國主要糧食作物之一[1]。小麥品種鑒別在作物育種、市場流通、糧食加工等領域均具有十分重要的意義。高光譜成像結合圖像(形態、紋理等特征)和光譜信息,可同時快速、無損檢測樣品的物理(顏色、大小、形狀和質地等)和內部組成成分的化學和分子信息(水分、脂肪、蛋白及其他氫鍵物質)[2],已廣泛用于水稻[3,4]、玉米[5,6]、大豆[7,8]的鑒別研究,在實現小麥籽粒品種快速無損鑒別方面具有可行的理論基礎。
近年來,國內外已有基于高光譜成像技術對小麥品種鑒別方面的研究報道,但仍處于初步探索階段。Mahesh等[9]采集了加拿大西部種植的8個小麥品種籽粒的960~1 700 nm波長范圍的高光譜信息,比較不同比例的訓練集、測試集和驗證集的建模效果,研究發現,模型性能隨著訓練集比例增大而提高。董高等[10]利用最小二乘-支持向量機(LS-SVM)和最小二乘判別(PLS-DA)算法對單粒小麥850~1 700 nm波長范圍的高光譜信息建立分類模型,實現了強筋、中筋、弱筋3個單籽粒小麥類型之間的分類。丁秋[11]等采集了10個品種共500個小麥籽粒388~1 009 nm波長范圍的高光譜圖像,運用主成分分析法提取3個特征波長,提取特征波長下小麥籽粒圖像的形態特征和紋理特征,應用貝葉斯(Bayes)判別分析法進行建模,訓練集和預測集的整體正確判別率分別為98%和100%。張航等[2]基于400~1 000 nm和900~1 700 nm波長范圍的高光譜信息建立了小麥品種的主成分分析-支持向量機(PCA-SVM)分類模型,結果發現900~1 700 nm波長范圍建模效果優于400~1 000 nm,其中3個品種間種子分類正確率平均達到95%以上,4個品種間種子分類準確率在80%左右,6個品種間種子分類準確率在66%左右。Bao等[12]采集了5個小麥品種874~1 734 nm波長范圍的高光譜信息,采用變量標準化算法(SNV)、多元散射校正(MSC)和小波變換(WT)等進行光譜預處理,應用主成分分析(PCA)、連續投影法(SPA)和隨機森林(RF)提取特征波長,基于全波長和特征波長建立線性判別(LDA)、支持向量機(SVM)和極限學習機(ELM)分類模型。發現基于全波長的ELM模型性能最佳,訓練集和預測集分別為91.3%和86.26%。目前高光譜成像技術應用于小麥籽粒品種鑒別的模型正確判別率、穩定性以及重現性等問題尚需要進一步的研究和探討。
為明確高光譜成像技術對小麥籽粒品種鑒別的可行性和有效性,本研究利用高光譜成像技術采集小麥籽粒光譜和圖像信息,優選不同部位光譜、預處理方法和特征波長提取方法;在此基礎上,建立基于光譜信息、形態特征信息、光譜和形態特征信息結合的分類模型,構建小麥品種快速、無損、有效、穩定的鑒別技術。
1 材料與方法
1.1 實驗材料
選取黃淮冬麥區的6個主栽品種:師欒02-1、濟麥22、周麥27、藁優2018、鄭麥366、矮抗58 的籽粒作為實驗材料,同一品種各選100粒勻稱、完好無損的籽粒作為實驗樣本,完成后將每種樣本單獨密封于標記好的自封袋保存。
1.2 實驗方法
1.2.1 高光譜信息采集
實驗所用儀器為高光譜圖像采集系統(Hyperspec?VNIR-E),其有效光譜的范圍為400~1 000 nm,共184個波段。采集高光譜圖像信息時,小麥腹溝朝下,統一采集小麥籽粒背面的信息。
1.2.2 光譜信息和形態特征提取
運用ENVI軟件中的ROI工具提取感興趣區域和形態特征。在胚、胚乳部位各選擇一個邊長為20像素的正方形區域作為感興趣區域(如圖1所示),選擇的胚、胚乳、胚和胚乳部位混合感興趣區域的平均反射值作為樣品的原始光譜信息。形態特征包含小麥籽粒長、寬和長寬比,其中長是小麥籽粒上距離最長的兩端點之間長度的像素數,寬是小麥籽粒上垂直于長度兩端點之間連線中最長線長度的像素數,長寬比是小麥籽粒長度和寬度像素數的比值。
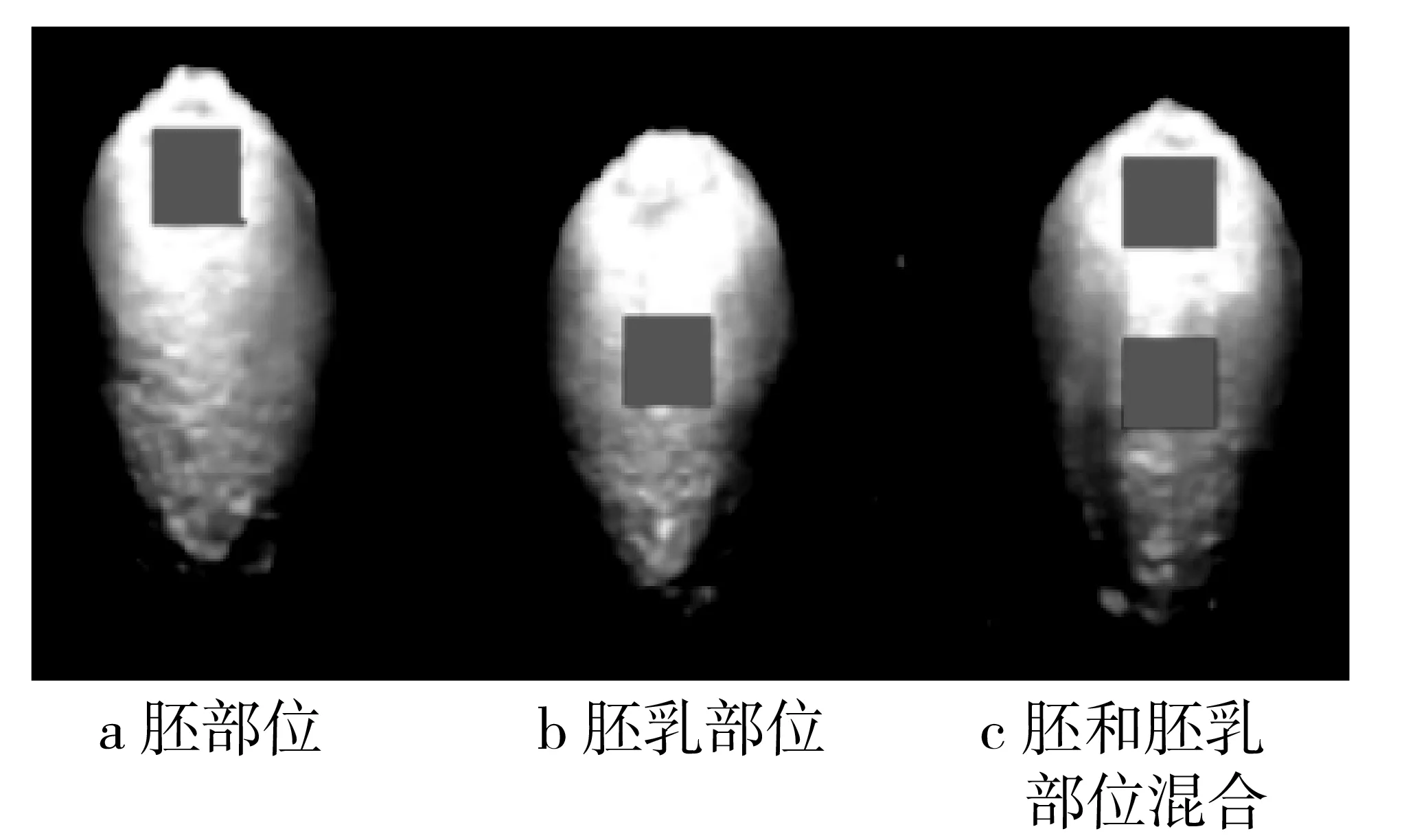
圖1 小麥籽粒不同部位ROI提取示意圖
1.2.3 光譜數據分析方法1.2.3.1 光譜預處理和特征波長提取
本實驗選取移動窗口平滑法(MA)、歸一化(NL)、一階求導(1stDer)、基線校正(BL)、變量標準化算法(SNV)5種方法對胚乳區域的原始光譜進行預處理,采用競爭性自適應重加權算法(CARS)和連續投影算法(SPA)進行特征波長提取,分別建立LDA、SVM和K最鄰近(KNN)模型并進行預測,篩選最優的光譜預處理和特征波長提取方法。
1.2.3.2 樣本集劃分
6個小麥品種樣本共600粒,根據Kennard-Stone算法按照3∶1劃分訓練集和預測集,訓練集450粒小麥籽粒用于判別模型的建立,預測集150粒小麥籽粒用于判別模型的驗證。
1.3 光譜數據分析軟件
本研究采用ENVI 5.1、The Unscramber X 10.3、Matlab R2019b等軟件進行光譜數據分析。
2 結果與分析
2.1 不同小麥籽粒部位光譜對建模效果的影響
由表1可知,基于胚乳和胚、胚乳部位混合光譜建立的LDA模型的預測集正確判別率均為79.3%,但基于胚乳部位光譜建立的SVM和KNN模型的預測集正確判別率均高于胚、胚乳部位混合光譜所建模型。因此,確定基于小麥胚乳部位光譜建立的模型性能最佳。故后續的研究均基于胚乳部位的光譜進行。
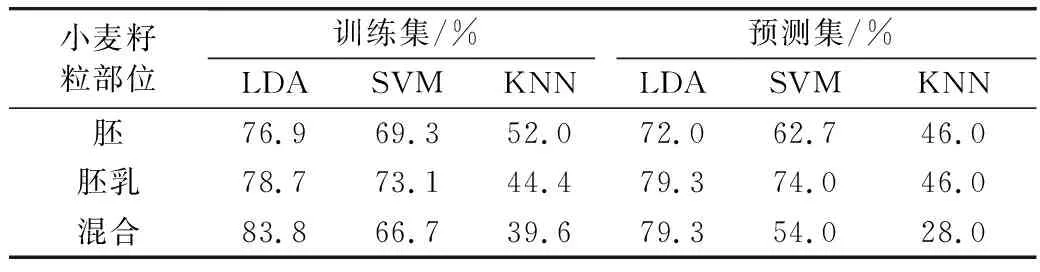
表1 基于不同小麥籽粒部位光譜建立的模型判別結果
2.2 不同光譜預處理對建模效果的影響
由表2可知,與基于原始光譜(RAW)建模效果相比,研究采用的大部分光譜預處理方法能提高LDA和SVM的建模效果,但只有4種方法或組合對KNN建模效果有提高作用。單一預處理方法整體上優于組合預處理方法,其中單一處理的1STDer最優,基于其處理的光譜建立的SVM模型訓練集和預測集的正確判別率分別為83.6%和84.0%。因此,基于原始光譜和1STDer處理后的光譜進行后續特征波長提取方法篩選的研究。
2.3 不同波長提取方法以及全波長對小麥品種鑒別的影響
2.3.1 競爭性自適應重加權算法
CARS算法(設置蒙特卡羅采樣次數N=100,五折交叉檢驗)在MatlabR2019b軟件中運行的結果如圖2所示,圖2中表示為波長變量優選過程中各波長變量回歸系數的變化趨勢,“*”所對應的位置即為RMSECV值最小處對應波長變量子集最優,子集中分別包含了34和41個波長變量,即基于原始光譜和1STDer處理后的光譜進行CARS特征波長提取的特征波長分別為34和41個。

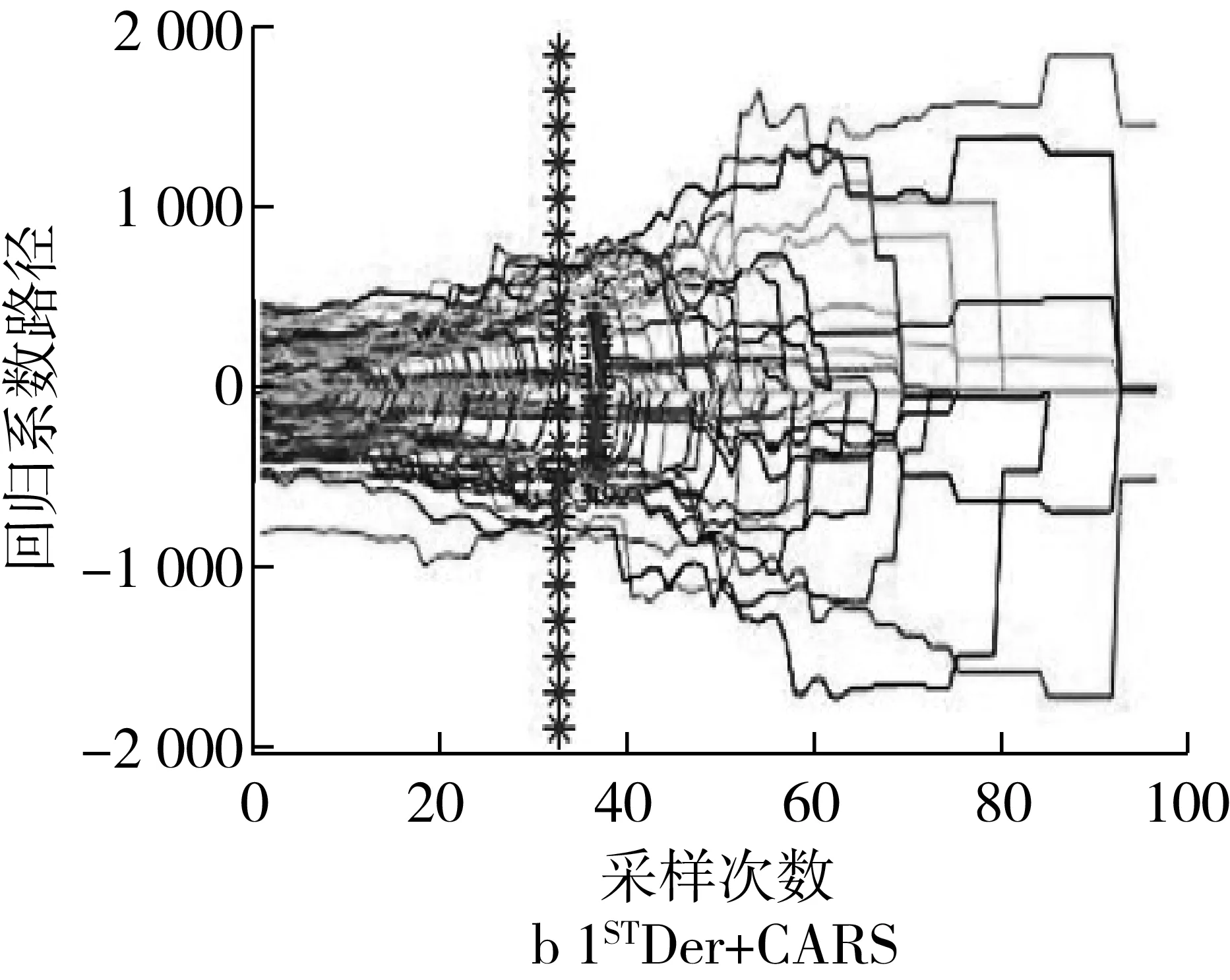
圖2 CARS算法提取特征波長
2.3.2 連續投影算法
本研究采用SPA算法基于原始光譜和1STDer處理后的光譜進行特征波長提取,結果發現當特征波長數為33和39個時,RMSE值達到最小值分別為1.083 7和1.176 6,即基于原始光譜和1STDer處理后的光譜進行CARS特征波長提取的特征波長分別為33和39個。
2.3.3 判別模型的建立與預測分析
由表3可知,基于特征波長建立的模型的效果整體上優于全波長。SPA的降維程度高于CARS,但建模效果CARS優于SPA。由2.3.2可知,光譜1STDer預處理能提高建模的效果。但由表3可知,基于原始光譜進行特征波長提取的建模效果優于經過1STDer預處理的光譜,其中建模效果最佳的為RAW-CARS-LDA模型,其訓練集和預測集的正確判別率均為84.7%。故采用RAW-CARS提取的特征波長的光譜進行后續的基于光譜信息、形態特征、二者結合建立的模型對小麥籽粒品種鑒別的影響研究。
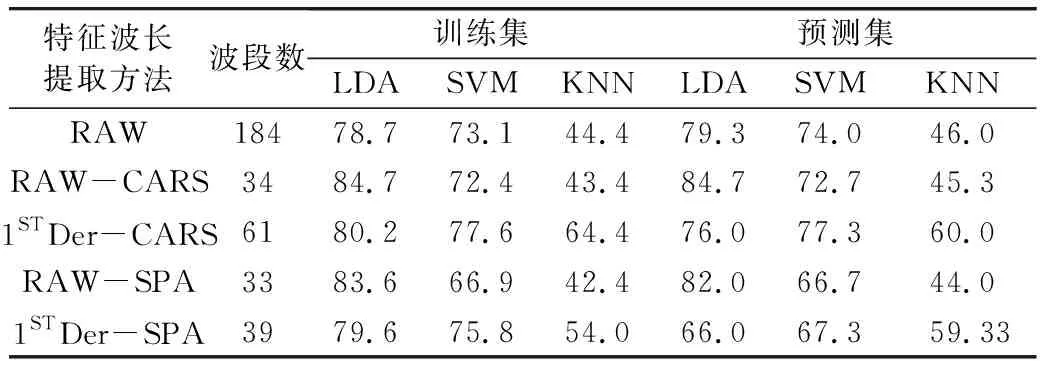
表3 基于不同特征波長提取方法建立的模型判別結果
2.4 基于光譜信息、形態特征、二者結合建立的模型對小麥籽粒品種鑒別的影響
由表4可知,基于特征波長的光譜信息建立的模型中,LDA模型效果最佳,其訓練集和預測集的整體正確判別率均為84.7%。基于形態特征建立的模型整體效果比基于特征波長的光譜信息建立的模型差,其中KNN模型最佳,其訓練集和預測集的整體正確判別率分別為55.8%和50.7%。基于特征波長的光譜信息和形態特征結合建立的模型,其訓練集和預測集的整體判別率分別為91.8%和86.0%,分類效果優于單一使用光譜信息或形態特征建模效果。因此,結合光譜信息和形態特征結合建立的LDA模型能夠有效的實現小麥籽粒品種鑒別。
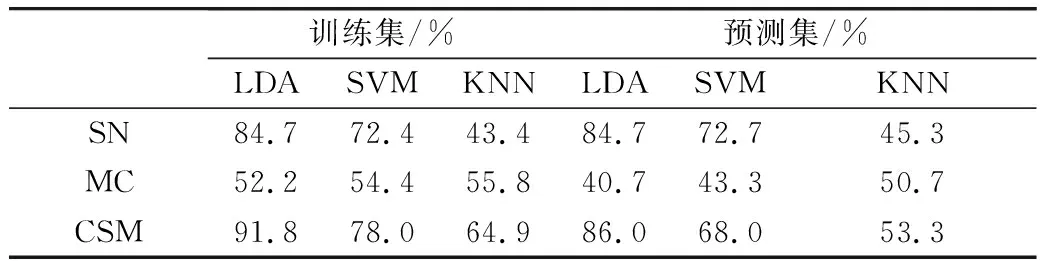
表4 基于光譜信息、形態特征、二者結合建立的模型判別結果
3 討論
本研究比較了基于胚、胚乳、胚和胚乳混合部位光譜所建模型效果,發現胚乳部位光譜所建模型性能略優于胚部位以及胚和胚乳混合部位光譜,與董高等[10]的研究一致。這可能由于小麥籽粒胚和胚乳表面紋理不同所致,胚部位表面凹凸不平,反射光的不規律性使得胚區域的光譜數據存在一定隨機誤差,其光譜不能很好的反映胚區域的物質特性。此外,不同部位光譜所建模型性能的差異也可能由于小麥籽粒胚和胚乳部分化學成分不同。小麥籽粒胚部纖維含量高,而胚乳主要由蛋白和淀粉粒組成[13,14]。
不同預處理方法對模型的判別精度有較大影響,本研究比較了MA、NL、BL、1STDer、SNV對小麥籽粒光譜預處理的效果,其中經過1STDer預處理之后的模型判別效果最好。這可能由于本研究中的6個小麥品種的原始光譜波段差異小且中存在大量與樣本自身性質無關的冗余信息,這會干擾到所建模型的判別精度和預測模型的效果,而1STDer能消除基線平移、背景的干擾、分辨重疊峰、提高分辨率和靈敏度[15]。Bao等[12]的研究發現,與原始光譜建立的小麥品種鑒別模型相比,WT、SNV、MSC 3種預處理方法對模型性能均沒有提高作用。因此,應根據光譜特征選擇適當的預處理方法,也突出了進行預處理方法篩選的重要性。
特征波長提取不僅可以簡化小麥品種鑒別研究中模型結構,而且可以剔除不相關、低貢獻的波長,提高運算速度,降低設備開發成本。CARS算法將每一個波長作為單獨的個體,利用自適應重加權采樣技術篩選出PLS模型中的回歸系數絕對值大的波長,淘汰回歸系數絕對值小的波長,并采用交叉驗證選出PLS模型中均方根誤差值最小的變量子集,即為最優波長變量子集[16]。SPA是一種采用前向選擇特征波長的算法,通過SPA提取到的特征波長具有共線性小和冗余度低的性能,但卻可以代表大多數樣本的光譜信息[17]。本研究中SPA的降維程度高于CARS,但建模效果CARS優于SPA,因為經SPA法剔除了過多信息,其中包含了大量有用信息。CARS算法基于胚乳部位原始光譜提取了34個特征波長,僅用了全波長的18.5%波段,但訓練集和預測集的正確判別率分別提高了6%和5.4%,說明CARS是基于高光譜技術的小麥品種鑒別研究有效的特征波長提取方法。而Bao等[12]研究采用SPA、主成分分析載荷(PCA loading)和隨機蛙跳(RF)3種方法提取了全波長5%、18%、25%的波長,相比基于全波長的光譜建立的ELM模型的預測集正確判別率86.26%,基于SPA、PCA loading、RF 3種方法提取的波長建立的模型的正確判別率分別降低了15.72%、14.26%、3.02%。因此,應根據特定光譜選擇適當的特征波長提取方法。
本研究基于特征波長的光譜信息和形態特征結合建立的模型,預測集正確判別率為86.0%,比單一使用光譜信息、形態特征所建LDA模型分別提高1.3%和45.3%,董高等[10]分別基于6個品種小麥籽粒的胚和胚乳光譜信息和形態特征結合建立的LS-SVM模型的正確判別率分別為98.89%和100%,比僅使用光譜信息建立的LS-SVM模型分別提高3.33%和1.11%。同是進行6個小麥品種的品種鑒別,本研究的判別正確率低于董高等[10]研究,而影響進一步提高正確率的原因可能在于:其一,采用的形態特征參數數量較少,本研究僅采用長、寬和長寬比3個參數,而董高等[10]的研究采用了小麥籽粒長、寬、長寬比、離心率、矩形度、圓形度、周長、面積、胚乳面積、胚面積以及二者面積比等12個參數;其二,光譜采集的波長范圍不同,張航等[2]的研究表明900~1 700 nm波長范圍所建模型的小麥品種鑒別效果優于400~1 000 nm波長范圍所建模型。本研究采用的波長范圍為400~1 000 nm,而董高等[10]采用的波長范圍為850~1 700 nm。故后續研究可增加形態特征參數的數量以及將波長范圍擴大至2 500 nm,以獲得更多的化學成分的光譜信息,從而進一步提高本研究的6個小麥品種鑒別模型的正確判別率。
4 結論
本研究基于高光譜成像技術進行6個小麥品種的品種鑒別研究,得到以下結論。
基于胚、胚乳和胚、胚乳部位混合光譜所建模型中,胚乳部位的建模效果最佳,其訓練集和預測集的正確判別率分別為78.7%和79.3%。
采用MA、NL、BL、1STDer、SNV 5種預處理方法以單一和組合的方法對光譜進行預處理,所建模型中,單一處理建模效果優于組合,其中1STDer效果最佳,其訓練集和預測集的正確判別率分別為83.6%和84.0%。
利用CARS和SPA算法進行特征波長提取,CARS建模效果優于SPA,基于原始光譜進行特征波長提取的建模效果優于經過1STDer預處理的光譜,其中RAW-CARS-LDA建模效果最佳,其訓練集和預測集的正確判別率均為84.7%。
基于特征波長的光譜信息和形態特征結合建立的LDA模型,分類效果優于單一使用光譜信息或形態特征信息建模效果,訓練集和預測集的正確判別率分別為91.8%和86.0%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
