基于深度學習的大米堊白分割算法研究
2021-05-26 08:41:06尚玉婷
中國糧油學報 2021年4期
鄧 楊 王 粵 尚玉婷
(浙江工商大學信息與電子工程學院,杭州 310018)
大米的外觀是關乎大米品質的一項非常重要的指標。正常大米呈白色透明狀,堊白區域因大米含水分過高或水稻收割時未成熟而造成,呈白色不透明狀,邊界不清晰,通常位于大米的腹部。含有堊白區域的大米因為缺少有助于人體代謝的磷酸烯醇式丙酮酸,營養價值低。大米質量安全關系到國人的生命健康,如何更加準確、快速的檢測出大米是否有堊白,堊白度為多少就顯得尤為重要。
基于機器視覺的大米外觀質量檢測是農作物外觀檢測的熱點問題,傳統方法主要為基于閾值分割及支持向量機的算法。Cardarelli等[1]通過SVM算法,以大米圖像的R、G、B平均分量值作為特征數據,對正常米粒和堊白米粒進行識別。侯彩云等[2]開發了一套用于稻谷堊白檢測的圖像處理系統,通過閾值的設定提取稻谷中的堊白區域,并計算堊白度和堊白粒率,但基于經驗設定的閾值給檢測結果帶來了較大的誤差。Sun等[3]根據灰度值的差異提取堊白區域和普通米粒,再采用SVM算法對大米堊白區域進行分類。王粵等[4]用直方圖不同的分布區分普通米和堊白米,采用改進的最大類間方差進一步分析米粒的堊白度、堊白率等信息。基于傳統的機器視覺或機器學習的堊白米識別方法對光照條件,米粒上的劃痕,以及胚芽部分的干擾等因素比較敏感,從而造成識別精度受到較大的影響。
近年來,隨著卷積神經網絡在圖像分類領域獲得的巨大成功,基于卷積神經網絡的語義分割也成為計算機視覺領域中另一個重要的研究熱點。由Long等[5]在2015年提出的全卷積網絡(Fully Convolution Networks,FCN)正式將卷積神經網絡引入語義分割領域。隨后的SegNet[6]、U-net[7]、DeeplabV3+[8]均取得了較好的分割結果。雖然這些網絡有很好的分割效果,但大量的計算也還是限制了其在移動設備上的部署。Howard等[9]提出了輕量級網絡MobilenetV2,使用深度可分離卷積(Depthwise Separable Convolution)代替普通卷積,極大地減少了網絡參數量。PASZKE等[10]使用輕量級語義分割網絡ENet,實現嵌入式端的語義分割,且分割精度優于SegNet。Wang等[11]提出了實時語義分割(Real-time Semantic Segmentation)網絡LEDNet,編碼結構中通過channel split and shuffle降低計算成本,同時保證分割準確度,解碼器加入注意力金字塔網絡(APN,attention pyramid network),減輕網絡的復雜度。
雖然語義分割在很多領域獲得了較大的成功,但將其應用到農作物大米的外觀質量檢測中的研究并不太多。孫志恒[12]采用改進的全卷積神經網絡FCN-8s,并結合超像素分割技術,對大米、大米堊白、大米胚芽進行分類識別,將深度學習應用到了大米堊白區域的智能檢測中,但FCN-8s網絡參數量較大,實時操作有難度。本研究提出了一個輕量級大米堊白米堊白區域識別網絡IMUN,該網絡不僅能實現對大米上的堊白區域進行精確像素級分割,同時網絡模型小,適合于集成到嵌入式可移動設備中。
1 IMUN網絡的構建
語義分割網絡通常由編碼結構和解碼結構組成,解碼部分將編碼結構中學習到的特征從語義映射到像素空間,從而獲得每個像素的類別。為了獲得較好的分類效果,通常采用VGGNet、ResNet、GoogleNet等網絡,這些網絡雖然有較好的分類性能,但參數量大、運算時間長,嚴重限制了語義分割在移動設備和嵌入式設備端的應用。考慮到農作物外觀質量的檢測通常都需要到現場實地檢測,那么面向移動及嵌入式設備的輕量級語義分割網絡就是很好的選擇。因此,本研究編碼結構采用了MobileNetV2網絡結構,并做了以下改進:在倒殘差冗余塊的深度可分離卷積中注入空洞卷積,加大視覺感受野,獲取更多特征信息,同時,線性瓶頸結構(Linear bottlenecks)使信息的輸出不經過Relu6層,從而更好地保留了特征信息。解碼部分基于UNet的解碼結構,上采樣過程中獲取的高層特征信息較為抽象,將上采樣過程中恢復的特征,與同層編碼結構進行特征連接,有助于恢復信息損失,并且能保留更多細節信息。模型整體設計呈非對稱結構,極大地減少了網絡參數,提高了訓練效率。目前,大部分在移動端的深度學習任務都是依賴云服務器完成計算的,本研究模型的提出使得網絡訓練可以不通過云端,直接在移動設備本地完成,避免了系統延時和額外數據開銷等問題。IMUN的整體網絡框架如圖1a所示,編碼結構如表1所示。

表1 編碼結構
1.1 編碼結構
如圖1所示,網絡的編碼結構由11個塊(Block)組成,網絡的輸入圖像為256×256×3的米粒圖像。首先經過1次3×3的普通卷積,并對其做標準化(BatchNormalization,BN),激活函數采用Relu6函數;接著通過5次深度可分離卷積,表1中的Conv dw即為深度卷積(Dwpthwise Convolution,DW);當DW卷積完成后,再利用1×1的PW卷積(Pointwise Convolution,PW)做通道調整,對其做標準化(BatchNormalization,BN),激活函數采用Relu6函數。接著,進入5個倒殘差空洞卷積冗余塊,結構如圖1b所示。
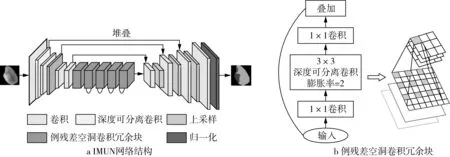
圖1 IMUN網絡結構和倒殘差空洞卷積冗余塊
MobileNetV2延用了MobileNetV1的深度可分離卷積,并加入了倒殘差冗余塊,先對輸入信息做1×1卷積升維,再通過DW卷積和PW卷積。倒殘差冗余塊的引入增強了梯度信息的傳播,同時減少了推理所需內存。此外,加入線性瓶頸結構直接對結果進行線性輸出,防止Relu6層帶來的信息丟失,保留了特征的多樣性,提高了網絡的魯棒性。網絡中在第一個倒殘差結構中不對結果做加法輸出。
實際檢測中,米粒圖像的像素分辨率較低,大量的卷積會導致小物體的特征信息無法重建,也會導致空間級化信息丟失,對分割的準確度有一定的影響。而空洞卷積則可以在不損失空間信息的情況下,很好的保留全局信息,使得每個卷積輸出都包含較大范圍的信息。因此,本研究在f3之后均采用了倒殘差空洞卷積冗余塊,改用膨脹系數為2深度可分離空洞卷積,從而使網絡在擴大感受野的同時,能捕獲到更多的特征信息。
1.2 解碼網絡
本研究的解碼結構如表2所示,與編碼結構呈非對稱,在一定程度上減少了網絡參數量,加速了推理過程。首先將編碼網絡的f3、f4特征層連接,作為解碼網絡的輸入,經過卷積和上采樣操作,與f2特征層的信息進行連接,再通過卷積和上采樣與f1特征層連接,最后做卷積和上采樣操作,輸出與輸入圖像尺度相同的圖像。
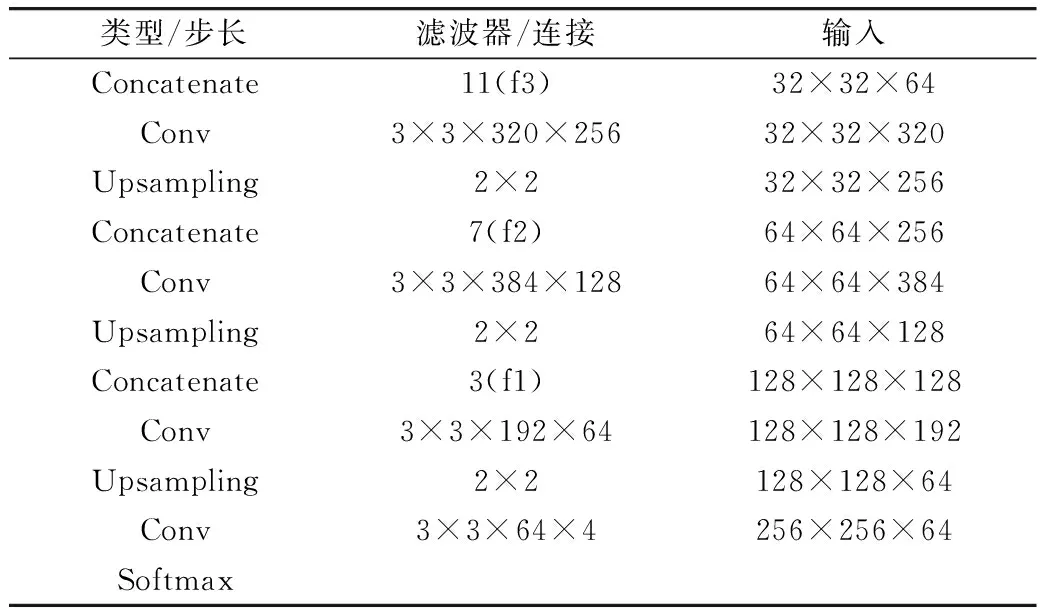
表2 解碼結構
1.3 損失函數的優化
為了得到更準確的分割結果,需要選擇合適的損失函數減少預測值和真實值之間的差距。交叉熵損失函數是語義分割多分類問題中最常用的損失函數,但是這種方法在樣本不均衡的情況下表現得并不好。在一些語義分割場景中,往往一幅圖像中的目標像素比例較小,加劇了網絡訓練的難度。在本研究中,堊白和胚芽部分的像素點相對較少,僅僅選擇交叉熵作為損失函數無法進行準確的分割。Tversky loss可以用來描述真實區域和預測區域的相似程度,在目標不均衡的場景下有較好的表現。針對語義分割多分類任務,本研究提出一種融合了交叉熵損失函數和Tversky系數損失函數的方式,通過交叉熵計算全部類別的損失值,再通過Tversky loss計算米粒和堊白區域的損失值,這兩個損失值的加權作為整個網絡的損失值。具體定義如下:
MLoss=-λ∑p(x)logq(x)+(1-λ)
(1)
式中:p(x)為預測值,q(x)為對應的真值,TP(True Positive)表示實際為正樣本預測正確的樣本,TN(True Negative)表示實際為負樣本預測正確的樣本,FP(False Positive)表示實際為負樣本預測錯誤的樣本,FN(False Negative)表示實際為正樣本預測錯誤的樣本,α是控制FP和FN的權重因子,λ為控制交叉熵損失函數和Tversky系數損失函數權重因子。
2 材料與環境
2.1 數據集采集
本研究選取了市面上比較常見的米粒作為樣本,分別選擇正常粳米、秈米(無堊白區域的透明完整米),堊白粳米、秈米(帶堊白區域完整米)以及碎米(由于加工、運輸等原因造成的米粒破損)。使用大恒HV1341UC相機,25 mm真彩色高清攝像鏡頭,俯視角度拍攝,配合環形光源,盡可能保證采集樣本不失真,背景托盤采用了黑色無紋路面板,方便后續對采集到的樣本進行一系列預處理。采集樣本在圖像分辨率為1 024×768,共采集300幅米粒圖像,每幅圖像約含15粒米,拍攝樣例如圖2所示。
圖2 米粒拍攝樣本
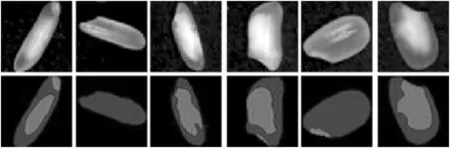
圖3 米粒原圖及標注圖像
2.2 數據集制作
考慮到用于深度學習的米粒數據集中最好是多幅單個米粒的圖像,因此,上節獲得的米粒圖像需要做預處理,對其進行自動切割,由于樣本是隨意放置在拍攝臺上的,米粒之間可能會出現粘連,必須要通過一定的切割算法,讓其自動形成單個米粒的多幅圖像。本研究根據王粵等[13]提出的粘連米粒的分割算法,首先獲取米粒的輪廓線,然后,根據輪廓線上的各像素點的曲率方向判斷米粒是否有粘連,若有,則尋找并計算最佳粘連點對,實現米粒的粘連分割,由此可以獲得每顆米粒的完整輪廓線。之后就可依據每顆米粒的輪廓線信息,獲取對應的米粒的圖像信息,這樣,上節采集到的圖像中的每粒米都可對應生成一副新的背景為黑色的圖像。
通過對粘連米粒的分割,得到2 000幅單個米粒樣本,其中包括936粒正常米,1 049粒堊白米,15粒碎米。為了防止樣本數據太少造成的訓練結果過擬合,對分割后的的2 000個米粒樣本進行數據增強,分別進行鏡像、旋轉等操作,并隨機選取樣本進行顏色抖動,最終得到10 000幅訓練樣本,其中8 000幅為訓練集,1 000幅為驗證集,1 000幅為測試集。使用開源工具Labelme,對采集到的大米圖像中的無堊白區域米粒、堊白區域及胚芽3個部分進行標注,數據集中共有米粒、堊白、胚芽、背景4類。圖3為分割后的米粒樣本與其對應的標簽。
2.3 實驗環境
本研究基于Ubuntu 16.04操作系統,處理器為2顆8核Inter E5-2620V42.0Ghz,128G內存,2 400 MHz,GPU為2塊NVIDIA TITAN XPPASAL。模型的搭建與訓練驗證通過Python語言實現,基于Keras2.1.5深度學習框架,并行計算框架使用CUDA 9.10版本。Batch_size設置為16,初始學習率(Learning Rate)設置為0.0001,訓練40代(Epoch),通過ReduceLROnPlateau調整學習率,當評價指標不再提升時,減少學習率。
3 結果與分析
3.1 不同權重因子對分割結果的影響
為了驗證損失函數的有效性,尋找更合適的權重因子,得到更高準確度的分割結果,本研究做了九組對比實驗,如表3所示。從實驗結果可以看出,當控制Tversky loss的權重因子α=0.9,控制MLoss的權重因子λ=0.7時,堊白區域的Intersection Over Union(IOU,交并比)值最高,達到94.11%,同時Mean Intersection Over Union(MIOU,平均交并比)達到92%,Pixel Accuracy(PA,像素準確精度)和Mean Pixel Accuracy(MPA,平均像素精度)分別為98.61%和96.34%。當α=0.9,λ=0.7時,網絡在迭代30代之后,訓練集的訓練精度呈穩定狀態,接近99.5%,驗證集的訓練精度在98%~99%之間波動;訓練集的損失值最后穩定在5.41~5.92,驗證集的損失值在迭代了35代之后逐漸穩定。

表3 不同權重因子下的評價指標
3.2 與其他語義分割網絡的結果對比
本研究模型旨在盡可能保證準確度的同時,降低模型參數量。本研究的IMUN與其他各種網絡結構的比較結果如表4所示,可視化結果如圖4所示。基于MobilenetV2網絡和基于VGG16網絡的解碼結構與本研究模型均選擇了Unet,由表4可以看出:二者的參數量分別為本研究模型的3倍和14.8倍,即便是參數量較少的MobilenetV2-Unet模型,IOU和MIOU也比本研究模型低了2.65%和2.55%。而LEDnet和Enet作為經典的輕量級語義分割網絡,參數量雖然比本研究模型少,但IOU比本研究模型低了3.55%和6.37%,MIOU低了3.82%和5.16%;Segnet和基于Xception的DeeplabV3+有較好的分割效果,堊白區域的IOU分別達到95.97%和97.45%,但參數量分別為本研究模型的4.9倍和19.7倍,雖然獲得了較高準確率,但參數量較大。
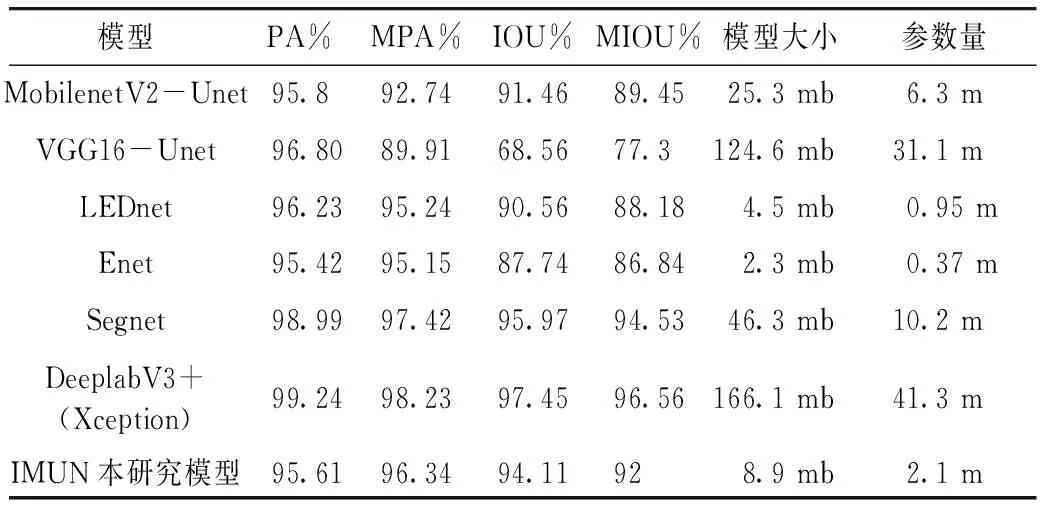
表4 不同模型下的評價指標
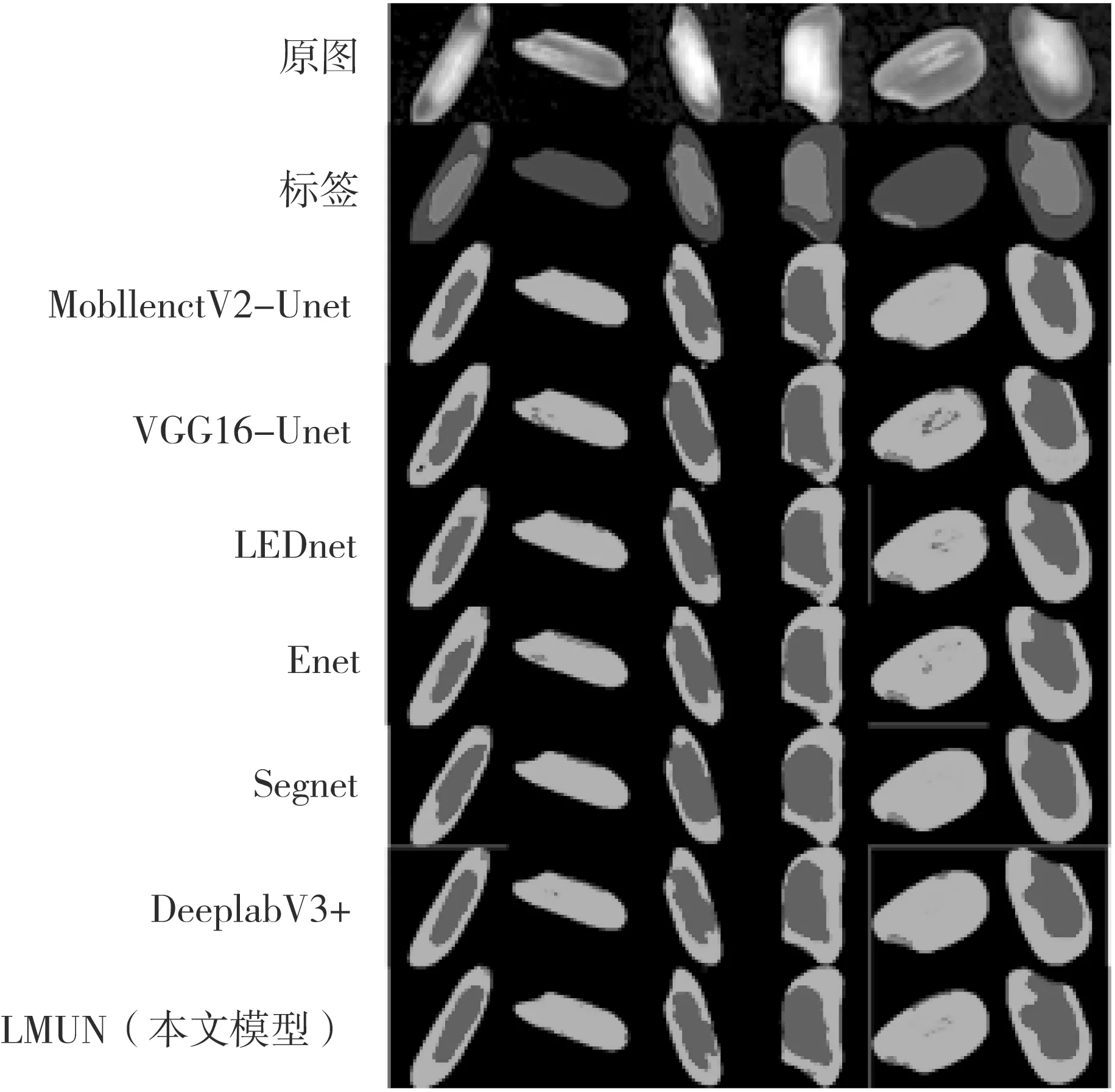
圖4 不同分割方法的可視化結果
4 結論
本研究提出了一個輕量級的語義分割網絡IMUN,與參數量較大的經典語義分割網絡相比,在幾乎不損失準確度的情況下減少了網絡參數量;與輕量級語義分割網絡相比,參數量在同一量級,但對堊白區域的分割能力更為突出。接下來的研究將對網絡進一步優化,提升大米堊白區域的分割準確度;并以本網絡結構為核心,添加圖像采集、圖像預處理、圖像粘連分割等模塊,從而能實時在線檢測包括堊白度和堊白率在內的各種大米外觀信息。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
民生周刊(2012年10期)2012-10-14 09:06:46
外語學刊(2011年1期)2011-01-22 03:38:33
