基于信息擴散視角的虛擬社區用戶影響力研究
2021-05-26 03:14:20周艷菊
計算機工程與應用 2021年10期
盧 開,周艷菊
中南大學 商學院,長沙410000
基于各類社交媒體形成以用戶生成內容(User Generated Content,UCG)為主要信息傳播方式的虛擬社區,成為群眾聚集的新場所。依賴于品牌依戀、人際依戀和社區依戀三大情感動機,虛擬社區用戶形成穩定的信息共享與相互影響機制[1],這使得以虛擬社區為主要傳播媒介,以“領導型”用戶為信息擴散中心的網絡營銷(Online Μarketing)開始流行,也為新零售時代的到來創造了有利條件。
虛擬社區運營的核心是“人”,意見領袖們對信息的傳播和導向、群體行為的形成和發展等方面都起到重要作用[1],而意見領袖們的領導能力通常用影響力來度量。用戶之間存在的社會影響(Social Influence),促使其行為受自身特點與人際關系圈共同決定,這是信息擴散的內在動因[2],而信息擴散通過用戶的社交活動及形成的交互網絡來體現[3],因此,從交互行為數據入手,探索用戶的信息擴散能力,是影響力評價的關鍵。
1 文獻回顧
經過多年的研究發展,不少學者對經典節點排序算法進行了不同角度的改良:劉忠華等人在改進Κ-shell分解和節點基本屬性的基礎上,提出了基于Κullback-Leibler 的節點排序方法[4];Rui 等人利用節點逆向秩信息和鄰居節點產生的影響,提出了基于影響最大化的反向節點排序方法,以此估計節點影響力[5]。有些學者從網絡結構出發來進行節點影響力度量:朱曉霞等人基于多個社交網絡共同構成的多層網絡拓撲結構,構建了多層社交網絡中的影響力節點識別方法[6];楊劍楠等人基于多層耦合網絡分析,提出了基于節點層間相似性的節點重要性識別方法[7]。也有學者將網絡分析方法與其他領域的理論進行有效結合:齊林等人將兩類不平等映射為節點在網絡中的能力與權力的二重異質性,設計了評價節點重要度的DH指標[8];Lin等人將網絡整體結構和傳播動力學特征進行耦合分析,并利用差分方程考察節點傳播特征,進行重要性度量[9]。交互網絡的時間維度也是國內外學者的關注點:Tang等人對時序網絡中的介數中心度、接近中心度等特征進行了定義,并在此基礎上提出了基于時間切片網絡的節點重要性預測方法[10]。
通過文獻梳理發現,目前節點排序方法的相關研究中,實驗數據多為Club、Arpa、Workspace等線下網絡,使用真實網絡數據驗證模型在虛擬社區網絡中的適用性與有效性的研究較少。更重要的是,大多數研究多從整體網絡結構出發,少有學者考慮群聚效應所產生的局部社區特征差異對算法效果的影響:同質性(Homophily)用戶自發形成相同的行為模式[11],而群體規范(Group Norm)使得同質性用戶更愿意在自己的“小圈子”里活動,中心人物影響力擴散存在“飽和效應”[12],且局部聚集程度越強,越不利于信息在社區全局的廣泛擴散。由此可見,群體規范對用戶信息擴散能力產生的干擾,可能會影響用戶影響力度量的準確性。
綜上所述,本文提出一種考慮網絡局部特征的節點影響力評價方法,從中觀層面出發,分析凝聚子群結構特征,在此基礎上對用戶影響力進行分析與討論。
2 模型構建
2.1 理論基礎
2.1.1 社區發現

2.1.2 凝聚子群分析
凝聚子群分析(Cohesive Subgroup Analysis,CSA)是一種社區子結構分析方法。虛擬社區用戶自發形成凝聚子群,各子群結構特征的差異對內部用戶的交互行為產生影響,凝聚子群分析可用來分析其結構特征與運營機制。凝聚子群分析的主要內容有:互惠性(Reciprocity)通常用來衡量社區用戶之間存在相互交流現象的程度;密度(Density)是用來衡量社區用戶間關系密切程度的指標;直徑(Diameter)用以衡量信息傳播范圍;平均最短路徑(Average Shortest Path)為所有節點對之間使用Dijkstra 算法計算最短路徑后的平均值,通常用來判斷社區的小世界特性。
2.1.3 節點排序
通過節點排序來度量用戶影響力,挖掘意見領袖,是常用的方法。節點排序算法主要有基于中心性分析的度中心性(DC)、中介中心度(BC)、接近中心度(CC),以及考慮鄰居節點拓撲結構的聚集系數指標、考慮網絡全局信息的特征向量指標等;基于隨機游走的PageRank算法(以下簡稱PR算法)在谷歌公司創立之初用于評價網頁質量,是節點挖掘算法中最著名的鏈接分析算法之一;Hits 算法也是經典鏈接分析算法之一,它使用內容權威值(Authority)和鏈接權威值(Hub)來分別衡量用戶的信息質量與傳播傾向。
2.1.4 創新擴散理論與Bass模型
創新擴散理論根據創新(Invention)與模仿(Imitation)這兩個信息擴散主要過程的信息采用速度差異,將潛在用戶分為創新者、早期接受者、早期大眾、晚期大眾和落后者五類:少數創新者和早期接受者優先“認知”信息,再對大眾實施“說服”,最終引導“決策”;而模仿者群體(包括早期大眾、晚期大眾等)除了被創新者“說服”外,新信息的接受與傳遞還受個人特征與偏好的影響[14]。在創新擴散理論基礎上,Bass模型指出信息擴散不僅取決于創新采用者們自身的創新能力,模仿采用者的模仿能力也是決定因素之一。Bass 模型的三大建模要素為潛在用戶數量、創新系數和模仿系數:潛在用戶數量指信息達到完全擴散時的接受者總量;創新系數為用戶受渠道選擇、廣告偏好等主觀因素的影響,主動接受新產品、新信息的可能性;模仿系數為用戶受到已采用群體的口口相傳,從而被動接受的可能性[15]。
2.2 模型流程
虛擬社區中,潛在局部用戶群體的群體規范差異會影響用戶的信息傳播,少有研究考慮這點。社區發現算法能夠挖掘出潛在群體,而凝聚子群分析可以分析不同潛在的局部群體在信息接受與主動傳遞上的水平差異。鑒于此,本文考慮將用戶重要性分析與局部群體特征分析進行有效結合,提出一種基于凝聚子群分析的用戶局部影響力評價模型(Cohesive Subgroup Analysis Based Local Leadership,CSA-LL)。
CSA-LL模型的建模依據與步驟如下:
(1)用戶全局影響力度量
虛擬社區中,信息感知與接受比創新者更謹慎的早期接受者通常作為社區中的意見領袖,促進信息流通,影響關系網絡結構與其他用戶的行為發展[16],在信息擴散過程中發揮著重要作用。正是信息早期接受者們迅速向大眾傳播,擴散的爆發期才得以到來[14]。Bass也指出,創新采用者對新產品、新服務等信息的早期擴散影響較大,是大多數模仿采用者接觸并采用信息的前提[15]。因此,意見領袖挖掘是探究虛擬社區中信息擴散過程的關鍵,而準確度量用戶在全局網絡中的重要程度,是挖掘意見領袖、分析其在群體規范下的信息傳播能力以及影響力度量的研究前提。
PR算法和Hits算法皆是度量用戶重要性的有效算法,但單一算法無法包含用戶所有性質,且無法適用于所有網絡,混合指標常作為用戶影響力排序的手段[17]。本研究采用混合指標的方法,將PR 算法與Hits 算法中更能體現用戶信息質量與影響他人程度的Authority 維度(簡稱H(a)算法)進行有效結合,作為評價用戶重要性的定量指標,并將之定義為用戶的全局影響力(Overall Influence,OI)。
基于多屬性的影響力度量,多使用專家打分、層次分析法等過于依賴個人素養的主觀賦權法進行屬性賦權,這只在熟悉研究對象與屬性特征時才有較好的效果。在多屬性決策中,信息熵越小的屬性,所含信息量越多,作用越大,因此,取決于客觀數據的客觀賦權法——熵值法能夠提升賦權效果與合理性[18]。PR算法和H(a)算法均為基于鏈接分析的排序算法,但算法原理、節點權重傳播模型、適用數據量等方面均存在差異,難以主觀判斷兩者在不同網絡中的性能優劣[19],使用基于信息離散度的熵值法,能夠提高全局影響力度量中屬性賦權的合理性與準確性。
綜上所述,用戶全局影響力的計算方法如下:
對虛擬社區用戶交互行為原始數據進行清洗和預處理。之后,以用戶名作為節點vi,合并形成節點集合V,vi∈V 。對存在交互的節點(vm,vn),vm,vn∈V,根據方向與強度,建立加權有向邊ej,合并形成邊集合E,ej∈E 。將節點集合V 與邊集合E 作為輸入,建立加權有向網絡G(V,E),計算所有節點vi∈V 在G 中的PR數值和H(a)數值并歸一化,形成節點屬性向量:

合并所有節點屬性向量,使用熵值法計算權重向量:

最終,使用混合指標度量用戶全局影響力:

(2)凝聚子群挖掘
用戶的信息傳播并非僅取決于意見領袖的“說服”,個人偏好與行為特征也是決定因素之一。受人口統計學特征、UGC 特征(包括主題、情感、豐富度與可讀性等)、社區活動參與度、活躍時間等因素的影響,用戶的內容發布、交互頻率等行為特征有所不同。存在相同行為特征的用戶會自發聚集,形成凝聚子群,且結構趨于穩定,對外部信息存在一定抵制,形成群體規范,進而產生了用戶密度、互惠水平等子群結構特征的差異,這是造成各子群內部信息擴散效率不同的主要原因。因此,有必要挖掘與分析子群特征,探索子群信息擴散效率,進而分析其對用戶信息傳播能力的影響。
本文使用社區發現算法挖掘潛在的凝聚子群。對G(V,E)使用不同社區發現算法進行子群挖掘并計算模塊度Q,選取Q 值最大的結果:
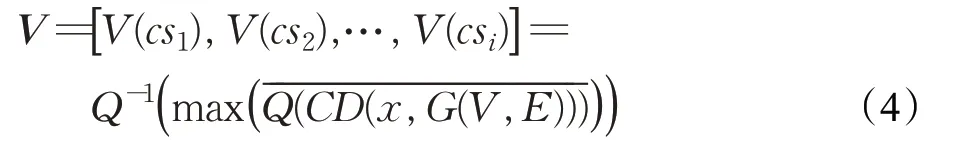
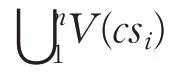
(3)子群結構分析與信息擴散效率度量
創新擴散理論指出,累計擴散數量大致呈S曲線分布,意見領袖促成了擴散前期的爆發式增長。然而,隨著擴散的推移,模仿型群體的重要性逐漸增強。Bass模型指出,模仿系數越大,潛在群體接受新產品、新信息的可能性越大,而且新的采用者會參與下一階段的擴散。類似地,虛擬社區用戶的信息擴散,在早期受社區等級、口碑等用戶個體因素的影響更大,但信息采用群體能自發推動個體用戶下一階段的內容傳遞,形成“口口相傳”,可以低成本、高效率地提升用戶發布信息的傳播速率,擴大信息覆蓋范圍,個體傳播能力得到提升,這也是各個企業偏好于在活躍的在線社區中實施病毒式營銷策略的內因。因此,探討子群的擴散效率,并考慮其對用戶信息傳遞效率的提升作用,能夠提高用戶影響力度量的準確性。

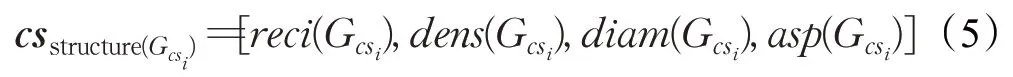
其中,直徑與平均最短路徑和的數值與信息傳播效率呈負相關,取值為與1的差值。
上述子群結構特征指標皆可描述信息擴散現象,但偏重角度有所不同,使用混合指標法結合各類特征,用以綜合評價子群信息傳遞效率,是科學合理的。同樣使用熵值法計算子群結構特征權重向量:

最終,使用混合指標來度量每個子群的信息傳遞效率,并將其定義為凝聚子群內部的信息擴散效率(Information Diffusion Efficiency of Subgroups,IDES),計算公式為:

(4)用戶影響力排序
創新擴散理論強調意見領袖個體與采用者群體均為擴散效果的重要影響因素,Bass模型也指出意見領袖的創新系數和采用群體的模仿系數是決定傳播速度與程度的主要因素。此外,每個用戶的潛在擴散群體都是社區全體用戶,Bass模型建模要素中的潛在用戶體量不予考慮。綜上所述,將用戶個體全局影響力和所在群體的信息擴散效率進行結合,計算用戶影響力數值:

其中,CS(vi)為節點vi所在的子群編號。通過上式獲取數值排序后的Top-K個節點,即為影響力高的意見領袖序列。CSA-LL模型彌補了經典節點排序算法與已有研究未考慮子群特征對用戶信息擴散的影響這一不足之處,用戶影響力度量與排序結果更為合理與準確。
3 數據處理
3.1 數據收集與清洗
本文選取豆瓣網第二大社區“窮游天下”小組中最后回復時間在2019.9.16 至2019.10.18 的用戶交互行為數據,維度包括評論、熱評、轉發、收藏四種交互行為涉及的用戶名。
表1 異常節點示例
對清洗后的數據集進行二次檢測,結果不再包含異常數據,清洗效果較好。各類交互行為數據統計量如表2所示。
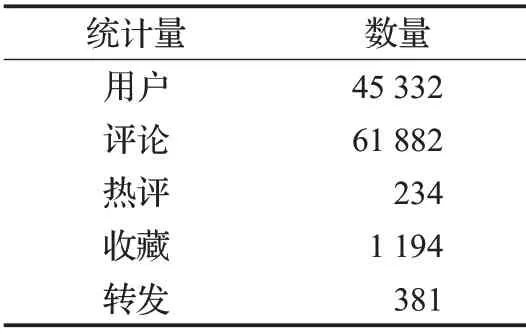
表2 一般統計量
3.2 數據預處理
不同的用戶評論包含的信息存在差異:(1)評論者對某一發帖進行初次評論,是以其對發帖者的信息傳遞的有效接收為前提;(2)帖子為非發帖用戶提供了互動平臺,發帖者在其中起到了中介作用,而用戶之間持續溝通更依賴于雙方的同質性,發帖者的作用減弱;(3)置頂的熱門評論比普通評論更能顯示信息的接收程度。因此,對各種評論關系進行如表3 所示的權重設置,n為相應維度的產生次數,對合并重復邊的權值取倒數,作為最終的相異權,形成邊集合E。

表3 社區用戶交互維度與權重設置
4 模型實現與實驗分析
4.1 模型實現
使用預處理得到的數據構建網絡G(V,E),計算所有節點的PR值與H(a)值,并使用熵值法得到ω(node_prop)=[0.455,0.545],再使用上述數據與式(3)計算得出所有節點的全局影響力OI值。選取GN算法、Louvain算法、Infomap 算法和LPA 算法,分別對G(V,E)進行社區發現,得到Qˉ=[0.592,0.650,0.614,0.516] ,最終選取Q值最大的VCS(Louvain),網絡結構示例如圖1 所示。子群數量與體量如圖3所示,最終得到295個子群,人數超過100人的子群有30個,人數不超過2人的邊緣子群有191 個。對VCS(Louvain)中的子群分別構建網絡,使用式(5)和(6)計算得出互惠性、密度、直徑、平均最短路徑4 個結構特征,并使用熵值法計算得出ω(cs_struc)=[0.582,0.341,0.039,0.038],再使用式(7)得到所有子群的信息擴散效率IDES 值。在得到所有節點的OI 值與其所屬子群的IDES 值后,使用式(8)計算得出節點的CSA-LL 數值作為用戶影響力度量與排序指標,結果如表4所示。
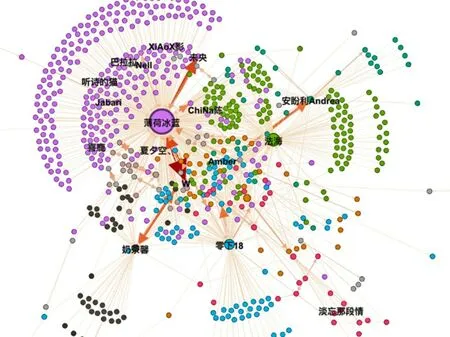
圖1 網絡構建與社區劃分結果示例
4.2 節點營銷能力實驗
為了驗證CSA-LL模型的性能優勢,從用戶營銷能力角度入手,比較本模型與標準方法的差異。AISAS模型[23]強調了網絡營銷中搜索(Search)和分享(Share)的重要性,企業社交媒體營銷效果影響因素的相關研究通常使用企業內容分享數據作為其營銷效果和發展潛力的度量[24]。本文借鑒AISAS模型,使用分享數據對用戶進行營銷能力排序,再使用肯德爾相關性系數(Κendall’s tau-b)計算其與各節點排序算法結果的相關性,作為衡量營銷能力的指標。肯德爾系數τ 的范圍為[-1,1],τ=1 時兩組隨機序列完全一致,τ=-1 時完全不一致,τ=0 時完全不相關。
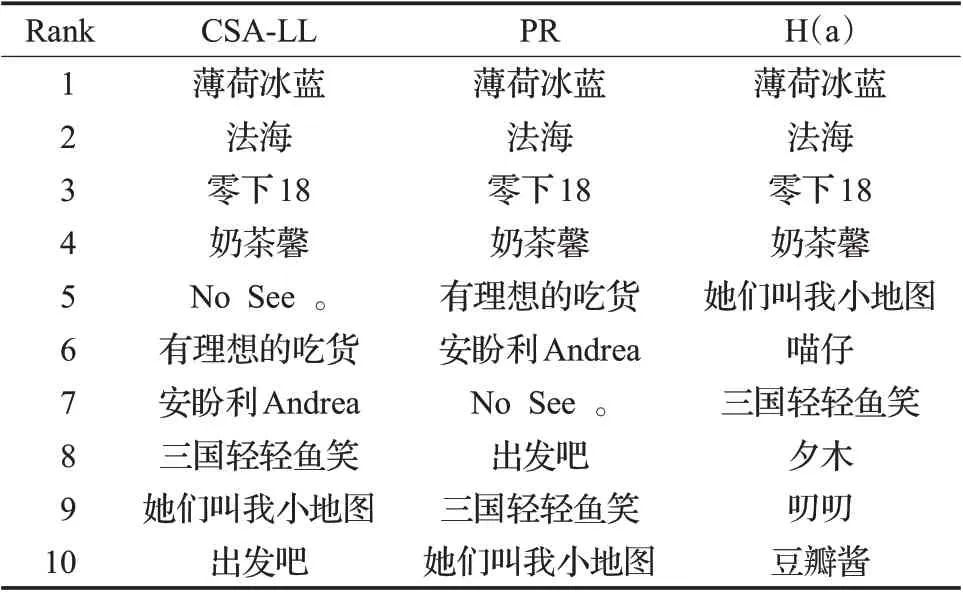
表4 節點排序對比示例
豆瓣社區中,除了轉發功能外,內容收藏機制——“豆列”也屬于具有特色的分享行為:不同于其他平臺收藏機制的隱私性,豆瓣社區用戶可收藏其他平臺的內容放入豆列,也能查看他人的豆列列表。因此,使用被轉發與被收藏數量之和(以下簡稱“Rel&Col”)進行節點營銷能力排序。將共存在1 575 次被轉發和被收藏的437個節點在各排序算法中的序列編號作為輸入,使用SPSS計算肯德爾系數,結果如表5所示。從表5中可以看出,各算法的節點排序序列與營銷能力序列均呈顯著正相關,且CSA-LL模型比PR和H(a)的相關性稍高,并通過了顯著性檢驗。這說明,CSA-LL模型輸出的用戶,具備更高的營銷能力與發展潛力,模型效果得到驗證,也證實了基于信息擴散的分析視角對用戶影響力算法性能的提升作用。
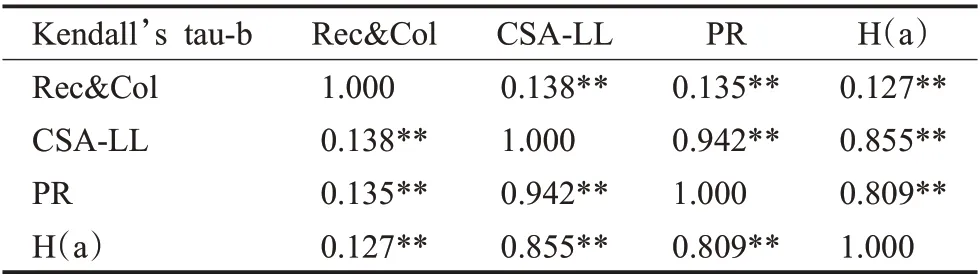
表5 Κendall相關性分析結果
4.3 節點傳播性能實驗
4.3.1 實驗1:基于豆瓣社區網絡的LT模型實驗


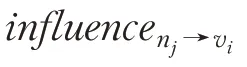

圖2 用戶個體傳播LT模型實驗輸出結果(豆瓣網絡)
在用戶個體傳播實驗中,單一根節點依次為RootSeed(CSA-LL,PR,H(a))=[“No See 。”,“有理想的吃貨”,“她們叫我小地圖”],輸出結果如圖2所示:圖(a)顯示,RootSeed(CSA-LL)在激活閾值θv的所有不同水平下的LT_num 數值分布具有明顯優勢,短期傳播性能更強;圖(b)顯示,θ <0.2 時,所有RootSeed(ai)達到飽和傳播時的活躍人數峰值差距不大,如子圖(c),θ ≥0.2 時RootSeed(CSA-LL)的LT_num 數值均更大,且θ=1,即所有用戶的被激活難度水平最高時,CSALL 是唯一的LT_num 數值大于100 的算法,CSA-LL模型輸出用戶個體的飽和傳播性能最強。為避免偶然性,選取除去上述節點以外的根節點進行實驗,RootSeed(CSA-LL,PR,H(a))=[“三國輕輕魚笑”,“出發吧”,“喵仔”],得到相同結論。
在用戶群體傳播實驗中,選取各算法排序的Top-20節點作為RootSeed(ai),實驗結果如圖3 所示。圖(a)與圖(b)顯示的結論與上一實驗類似:所有θ 水平下的RootSeeds(CSA-LL)短期傳播性能比PR 算法和H(a)算法更高;θ <0.2 時三種算法的飽和傳播性能相當,而節點激活難度提升時,CSA-LL算法性能更好。
綜上所述,較之于PR算法和H(a)算法,CSA-LL模型輸出用戶的信息傳播能力要更優,模型可行性與有效性得到驗證,也證實了子群信息擴散效率對用戶傳播能力的正向影響作用,以及基于信息視角進行用戶影響力分析的優勢。
4.3.2 實驗2:基于Advogato 網絡與Polblog 網絡的LT模型實驗
為驗證CSA-LL 模型在不同虛擬社區網絡上的魯棒性,選取Advogato 網絡和Polblog 網絡,使用LT 模型進行實驗分析。Advogato 是一個面向免費軟件開發人員的虛擬社區,以用戶為節點、用戶之間的信任程度為邊構成信任關系網絡;Polblog網絡(Political Blogosphere Dataset)是美國政客們在線上發表博客的互動關系數據。分別使用CSA-LL 模型對兩個網絡進行影響力度量與排序,中間計算與排序結果如表6和表7所示,分析比較不同算法輸出用戶的信息傳播能力。
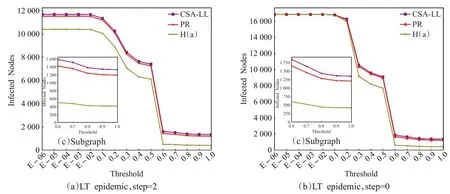
圖3 用戶群體傳播LT模型實驗輸出結果(豆瓣網絡)

表6 CSA-LL模型實現
對Advogato 網絡排序結果(表7 Part.1)進行LT 模型傳播實驗。用戶個體傳播實驗中,PR 算法和H(a)算法與CSA-LL 模型第一次出現排序差異的序號不同,節點選取RootSeed(CSA-LL,PR)=[429,431] ,RootSeed(CSA-LL,H(a))=[438,577] ;用戶群體傳播實驗的輸入節點為各算法的Top-20節點集合。
用戶個體傳播實驗結果如圖4 所示:圖(a)顯示,在短期傳播中,LT_num('429')>LT_num('431') 、LT_num('438')>LT_num('577')在所有激活閾值水平下均成立,CSA-LL 模型輸出用戶的短期傳播優勢明顯;圖(b)顯示,在飽和傳播中,各算法在用戶激活難度較低時的活躍人群峰值差異不大,但用戶激活難度較高時,CSA-LL模型的優勢再次體現。用戶群體傳播實驗結果如圖5所示,所得結論與個體傳播實驗相同。基于以上結果,CSA-LL模型在Advogato網絡中的可行性和有效性得到驗證。
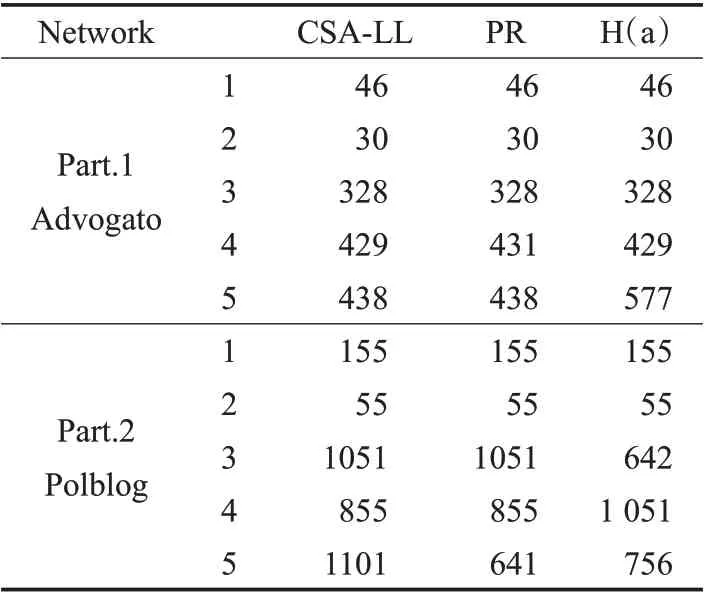
表7 節點排序示例
對Polblog 網絡排序結果(表7 Part.2)進行LT 模型傳播實驗。用戶個體傳播實驗的節點選取分別為:
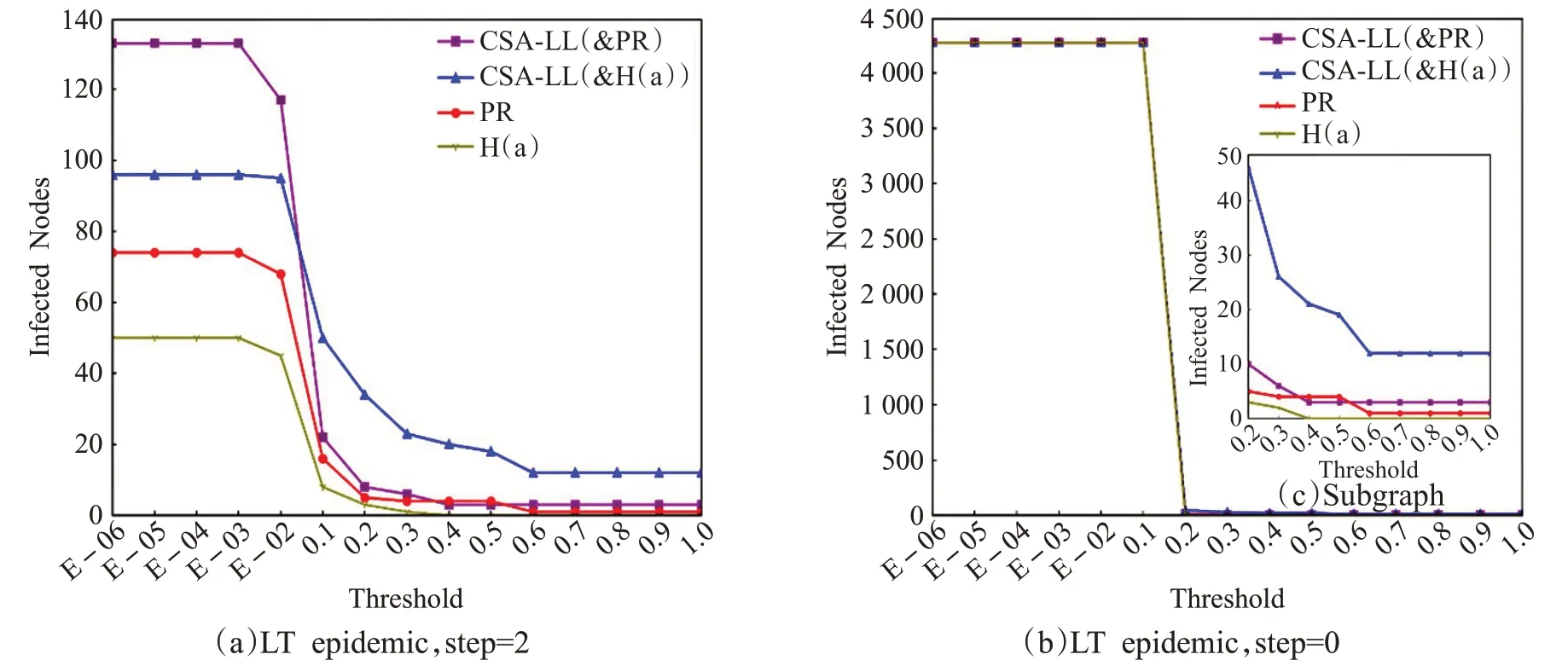
圖4 用戶個體傳播LT模型實驗輸出結果(Advogato網絡)

圖5 用戶群體傳播LT模型實驗輸出結果(Advogato網絡)
RootSeed(CSA-LL,PR)=[1101,641]
RootSeed(CSA-LL,H(a))=[1051,642]
用戶群體傳播實驗的輸入節點也為Top-20節點集合。
用戶個體傳播實驗結果如圖6所示:圖(a)顯示,在短期傳播中,用戶激活難度較低時,LT_num('1051')>LT_num('642')成立,而θ ≥0.2 時,CSA-LL模型與H(a)算法的性能相當;圖(b)顯示,在飽和傳播中,各算法輸出結果的峰值與谷值差異不大,但拐點出現時θ(CSA-LL)=0.1 >θ(PR)=θ(H(a))=0.01,CSA-LL模型輸出用戶對高激活難度用戶實現有效傳播的能力更強。用戶群體傳播實驗結果如圖7所示,所得結論與個體傳播實驗類似,CSA-LL 模型用戶激活難度低時的短期傳播效果更好,而激活難度較高或達到飽和擴散時,效果與前兩者相當。
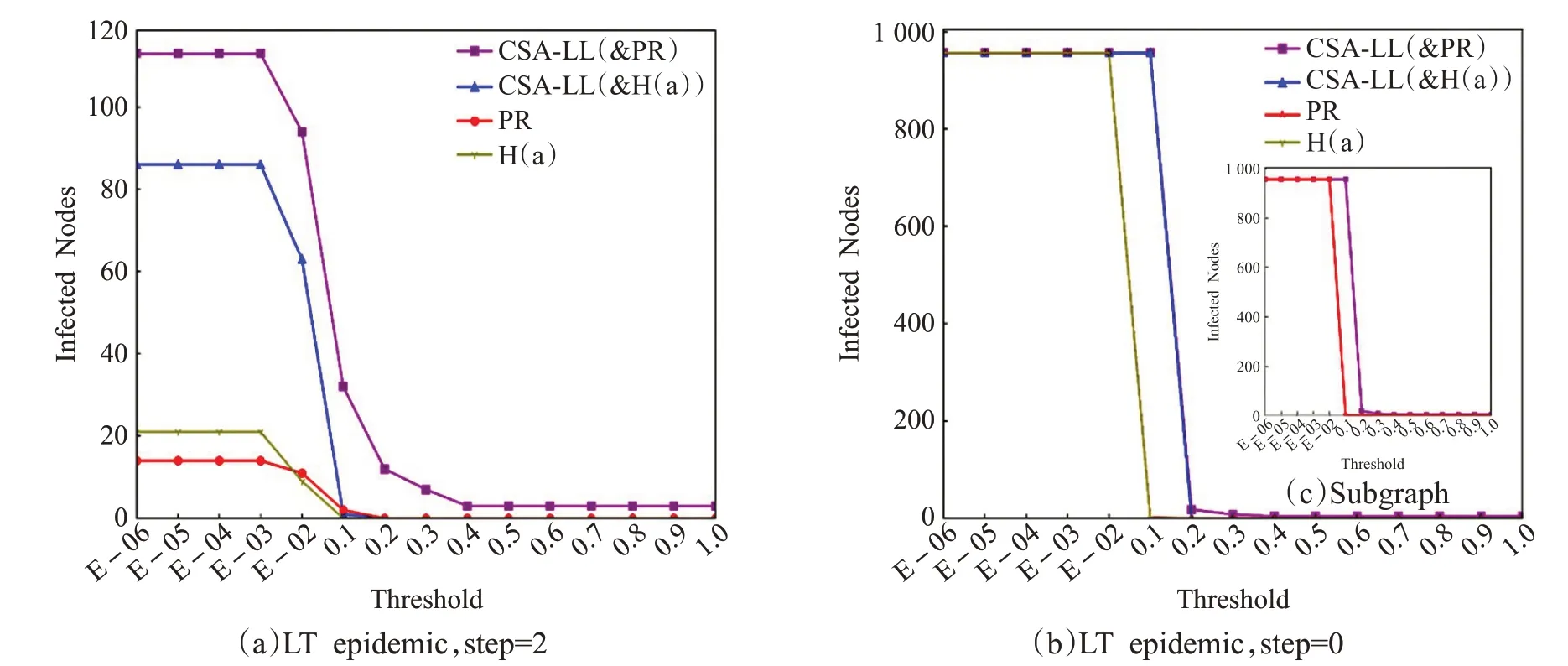
圖6 用戶個體傳播LT模型實驗輸出結果(Polblog網絡)
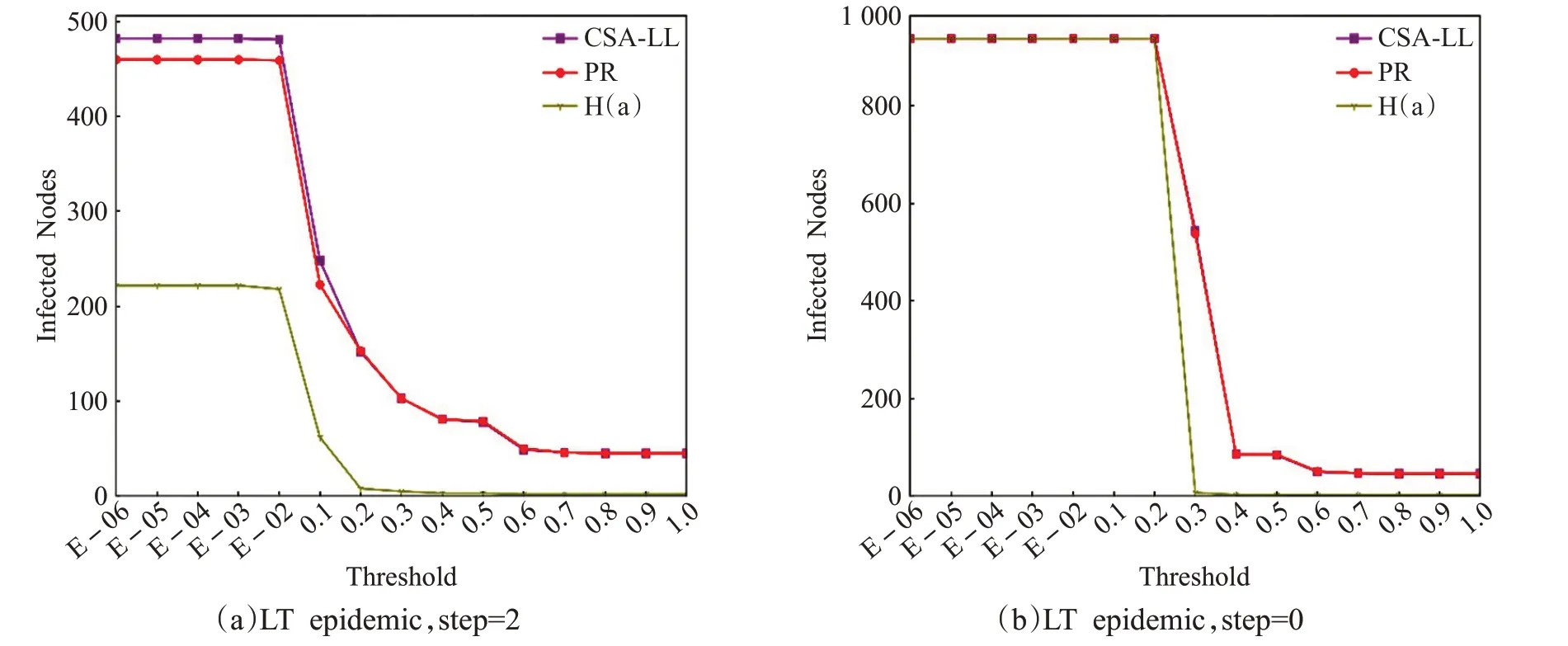
圖7 用戶群體傳播LT模型實驗輸出結果(Polblog網絡)
上述結果可能是由于Polblog 網絡性質所導致:Polblog用戶均來自美國政客圈,彼此熟悉,實際的激活難度較小;各算法Top-20 用戶均來自122 號和198 號子群,且IDES('112')=0.389,IDES('198')=0.376,子群的信息擴散效率對傳播影響不大,且對于Polblog 這種小規模網絡,用戶達到飽和傳播時可能均已覆蓋大多數用戶,導致峰值差異不大。為了驗證推斷,進行補充實驗:選取拐點θ=0.1 作為所有用戶的激活閾值,設置不同傳播階段,進行群體傳播實驗。結果如圖8 所示:在step <6 時,CSA-LL 模型輸出用戶的基礎激活人數更多,傳播速度更快,子群信息擴散對用戶短期傳播能力具有顯著效果,而當達到飽和傳播時,各算法輸出的活躍人數占比77%,上述假設得到驗證。基于以上結果,CSA-LL 模型在Polblog 網絡中具有較好的可行性和有效性。

圖8 用戶群體傳播LT模型補充實驗結果(Polblog網絡)
綜上所述,CSA-LL 模型在不同虛擬社區網絡中的魯棒性得到驗證,同時也再次驗證了基于信息擴散視角進行用戶影響力度量,比標準方法的性能更強。
4.3.3 實驗3:基于豆瓣社區網絡的IC模型實驗
考慮到傳播模型的種類可能對結論產生影響,選取LT模型之外的信息傳播模型,對實驗1、實驗2得到的結論進行穩健性檢驗。

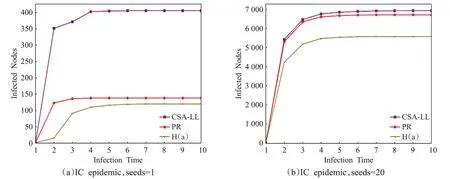
圖9 IC模型實驗輸出結果(豆瓣網絡)
綜上所述,子群信息擴散效率對用戶信息傳播能力具有正向影響這一結論的穩健性得到驗證,較之標準方法,本文提出的基于信息擴散視角的用戶影響力度量方法具有更好的性能。
5 總結
針對以往研究少有考慮群體規范對信息傳播效率影響的問題,本文提出一種適用于虛擬社區網絡的用戶影響力度量方法——CSA-LL 模型,從傳播性能與營銷能力兩個角度出發,結合豆瓣社區網絡、Advogato 網絡和Polblog 網絡,使用LT 模型、IC 模型、AISAS 模型、Κendall相關性分析等方法,分析比較CSA-LL模型與PageRank算法和Hits算法的差異,驗證了模型的可行性、有效性和在不同虛擬社區網絡中的魯棒性,也證實了基于信息擴散的分析視角進行用戶影響力度量的準確性。本文選取的社區發現算法大多屬非重疊社區發現,對于存在社區重疊的用戶,找到準確度量其所屬區域信息擴散效率的方法,可以提高模型效果,這是之后的研究重點。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
