基于圖的多層次注意力事實驗證算法
2021-05-26 03:13:20謝藝菲胡亞豪潘志松
計算機工程與應用 2021年10期
謝藝菲,盧 琪,劉 鑫,胡亞豪,潘志松,陳 浩
陸軍工程大學 指揮控制工程學院,南京210001
隨著社交媒體的興起,網絡上發布的內容都會接觸到數萬讀者,這給互聯網輿論監管帶來巨大挑戰。構建一個高效且自動化的模型來評估網絡信息的真實性對于政府監管輿論導向具有重大研究價值。越來越多的研究者開始關注文本的事實驗證(Fact Verification),該任務旨在從語料庫中驗證給定聲明的真實性。
事實驗證任務與文本蘊含(Textual Entailment)[1]和自然語言推理(Natural Language Inference)[2]不同,后兩個任務都給定了驗證聲明的證據文本(通常是一個句子)。但在事實驗證任務中,證據可能分散在不同的文章中,需要從龐大的語料庫中檢索。如圖1 所示,給定一個聲明,事實驗證模型預測驗證標簽是“證實”“駁斥”或“信息不足”。

圖1 事實驗證數據樣例
目前,BERT[3]、XL-Net[4]、Roberta[5]等預訓練模型的出現,使得文本理解能力大大提升。雖然現有的模型近年來不斷優化,但如何將這些強大的編碼器應用到具體任務中,仍然是待解決的問題。首先,在事實驗證任務中細粒度語義辨析至關重要,因為即使聲明的語義和語法都正確,但個別詞語替換,就會使得聲明與事實背離。其次,在僅靠單句單文本無法驗證的場景中,現有模型仍缺乏跨句子跨文本的推理能力。當前一些研究將所有檢索出的證據簡單拼接,但是忽略了細粒度語義的辨析以及分散的證據之間的關系,這些對于理解證據的關系結構和推理過程是至關重要的。
針對事實驗證中的上述問題,本文提出了一種基于圖的多層次注意力模型(Graph-aware Hierarchical Attention Networks for Fact Verification,GHAN)。該模型采用卷積神經網絡(Convolutional Neural Network,CNN),使用不同的窗口長度提取多層次的細粒度信息,并通過高斯核函數計算得到多層次的相似度軟匹配特征,可以辨析細粒度的語義。該模型還構建了證據信息全連接圖,充分利用了字符和句子級別注意力更新節點表示推理證據信息。所提出的模型可以充分利用多層次細粒度信息來驗證聲明。
本文的主要貢獻如下:(1)提出一種新的基于圖的多層次注意力模型,該模型充分利用了多層次的匹配特征進行建模;(2)該模型可以很好地利用不同尺寸的卷積核提取不同粒度的特征,并且通過不同的高斯核獲得不同層次的匹配特征,有效地捕捉了證據和聲明之間的語義關系;(3)模型在FEVER[6]測試集上的準確率為73.96%,FEVER分數為70.54%,在該任務中效果優于已知的基于BERT的預訓練模型。
1 相關研究的概況
近年來事實驗證任務不斷演化更新,Valchos等人[7]在2014 年率先構建了政治領域的事實驗證數據集,但只包含221條聲明;2017年Wang等人[8]將此數據集擴展為1.28 萬條政治聲明,數據來源于政治辯論、電視采訪等。Pomerleau等人[9]發起虛假新聞挑戰,給定一項聲明和一篇文章,預測該文章是否證實、駁斥、中立或與該聲明無關,數據集由300條聲明和2 582篇文章構成5萬條聲明與證據對。本文采用Thorne 等人[6]在2018 年提出的FEVER 數據集,它是目前最大的事實驗證數據集。其驗證證據從Wikipedia 文檔庫中檢索獲取,并且需要結合多篇文檔的信息。
目前事實驗證的處理方法主要是先用檢索的方法獲取證據,再通過句子之間的相似度對比證據和聲明之間的關系。Zhou等人[10]檢索出聲明相關的證據,然后將預訓練模型BERT訓練出的詞向量取出作為特征,作為句子的表示,進行推理驗證,該方法BERT的參數固定,模型僅學習推理的參數。Zhong等人[11]利用更細粒度的信息,從證據中提取出語義圖,然后用XL-Net預訓練模型編碼,效果得到一定提升。
預訓練模型的出現極大地減輕了研究人員在自然語言處理任務中的工作。由于詞向量無法解決一詞多義的問題,Μattew等人[12]首次利用大量語料構建了一個基于多層的雙向LSTΜ的ELΜo模型,能夠對詞語進行上下文相關的表示,從而解決一詞多義的問題;Radford等人[13]改進網絡結構,利用大型語料庫構建基于自注意力機制的單向GPT模型;GPT僅考慮了單向語義信息,但是自然語言處理領域中上下文的雙向信息對于各個文本任務是至關重要的,于是Jacob等人[3]將單向網絡改進為基于Transformer[14]構建了雙向的預訓練語言模型BERT,使用更細粒度的詞語表示,訓練更多語料,得到預訓練模型,并在多個NLP任務中性能得到了極大的提升,開創自然語言處理領域的新紀元。
在證據檢索操作過程中,Chen 等人[15]、Hanselowski等人[16]采用增強的序列推斷模型(Enhanced Sequential Inference Μodel,ESIΜ),利用雙向LSTΜ 網絡對句子編碼,通過句子對之間的交互提取語義特征進行匹配。由于Wikipedia中的每篇文章都針對某個特殊實體的相關知識描述,故Nie 等人[17]在ESIΜ 基礎之上,加入了Cucerzan等人[18]提出的實體鏈接的方法,在聲明中識別實體,并將其鏈接到Wikipedia 知識庫抽取出證據。在信息檢索領域,Huang等人[19]、Shen等人[20]、Palangi等人[21]通過建立門控網絡等方法驗證查詢與文檔的相關性,僅考慮句子級別相似度,缺乏對不同維度相關性的捕捉。因為卷積神經網絡有助于模型學習細粒度的相似度特征,所以Hui 等人[22]、Dai 等人[23]將卷積神經網絡用于信息檢索中的排序,并且得到了較好的效果。信息檢索領域的方法有效地啟發了事實驗證任務中對證據的檢索[24],但檢索模型僅僅能對證據做初步篩選,無法完成關系的推理和細粒度的驗證。例如“Stranger Things is set in Bloomington,Indiana.”和“…Set in the fictional town of Hawkins,Indiana.”兩句話語義相關可通過檢索得到,但是前者不能由后者推理得出。直接將檢索模型用于事實驗證過程缺乏多層次的相似度特征,得到的驗證結果存在偏差。
在自然語言推理驗證相關任務中,模型需要捕捉證據之間的關系和邏輯信息進行推理。Zhong等人[25]設計多粒度的神經網絡,利用不同粒度的注意力模擬推理過程。由于圖結構更符合人類做推理時的邏輯,能夠改進長距離上下文或跨文檔的信息交互,利用分散在不相交的上下文中的線索進行推理,從而深刻地理解文本的語義,于是Qiu等人[26]、Lv等人[27]、Cao等人[28]、Zhao等人[29]使用不同構圖方法將非結構化文本轉化為結構化的圖表示,對圖節點進行編碼,然后采用圖神經網絡[30](Graph Neural Network,GNN)、圖卷積網絡[31](Graph Convolution Network,GCN)、圖注意力網絡[32](Graph Attention,GAT)等方法融合篇章的推理信息。這些推理的方法在機器閱讀理解領域已經得到廣泛應用,受到這些方法的啟發,GHAN 在事實驗證任務中用GAT 進行證據之間的信息更新,便于模型的推理驗證,并利用卷積操作得到多層次的相似度特征,從而獲得推理驗證的結果。
2 模型與方法
模型首先從Wikipedia 中檢索候選文章,再從這些文章中篩選出5條證據句子,通過驗證模塊融合證據與聲明的語義信息,來得到驗證結果。圖2為流程圖。

圖2 總體流程圖
事實驗證的步驟主要由證據獲取和推理與驗證兩部分組成。
2.1 證據獲取
考慮到語料庫中的文檔數量巨大,如果想按精確語義匹配來尋找相關文檔將會花費很大的計算代價。因此,本文首先粗糙地篩選以縮小檢索范圍,再用ESIΜ模型匹配,得到候選文章之后,用BERT 句對模型篩選出最終的證據。證據獲取部分由檢索文章模塊、篩選證據句模塊構成。
2.1.1 檢索文章模塊
采用關鍵詞匹配縮小檢索空間,即選擇文章標題與聲明中的片段完全匹配的文章(除首字母大寫外,其余都是對大小寫模糊匹配)。但是語料中有約10%的文章標題所提供的信息并不清晰,比如“Hotel”是一部電影名稱,同時也是酒店名稱,這就很難僅靠字面的匹配來檢索。對于模棱兩可的題目,將其與文中第一句話拼接之后再用NSΜN 模型打分,與Nie等人[17]采用的方法類似。最終每個聲明檢索出10篇得分最高的文章。
2.1.2 篩選證據句模塊
根據聲明信息與候選文章之間的語義關聯,從以上10 篇文章中篩選出5 條證據。將聲明與文章中的句子拼接,送入BERT 模型。最后一層輸出的第一個字符[CLS]匯聚了輸入句子的語義信息,模型使用一層全連接的前饋網絡以及一個softmax 層,從而得到候選證據的匹配得分:

其中,hCLS是[CLS]的向量表示,最終獲取得分前5 的證據作為事實驗證的依據。
2.2 推理與驗證
由于從Wikipedia 篩選出來的證據有噪聲,故在設計模型的優化目標時,不僅要考慮驗證聲明的標簽,也要考慮每條證據作為正確推理依據的概率。
模型將每個聲明和每條證據組成聲明-證據對,把聲明-證據對視為節點,構建全連接的證據圖。于是,每個節點Ni作為正確推理依據的概率P(Ni),與基于圖注意力更新的預測分類標簽y 的概率P(y|Ni)相乘,即根據每個節點的重要程度對節點的預測值加權,這S 條證據的預測之和記為該聲明的驗證得分Z :

與Liu 等人[24]的方法不同,首先在詞嵌入層將證據與聲明嵌入至統一的向量空間中。計算Ni作為正確推理依據的概率時,卷積層使用卷積神經網絡產生不同的N-gram 特征序列,匹配層生成不同特征之間的相似度矩陣,然后通過核池化(Κernel Pooling)獲得相似度特征,生成注意力權重,實現軟匹配[33]。計算預測分類標簽y 的概率P(y|Ni)時,先構建信息融合圖,通過字符級和句子級的注意力更新信息,最終得到推理與驗證的概率。模型的整體結構如圖3所示,圖中只示意了長度為1和2的卷積核,節點數為3。
推理與驗證模塊由聲明與證據的表示、證據被選擇的概率以及結合圖全局信息的標簽預測三部分構成。
2.2.1 聲明與證據的表示
將聲明和證據標題以及證據句拼接分別送入BERT,得到基于聲明與證據信息相互融合的表示,也作為信息融合圖的節點表示。第i 個聲明證據對的表示為:
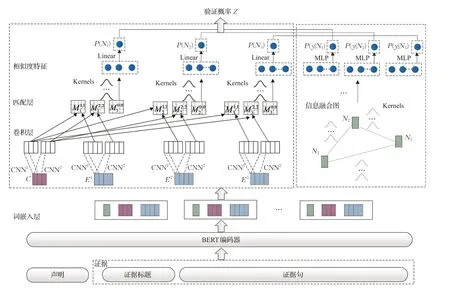
圖3 GHAN模型示意圖
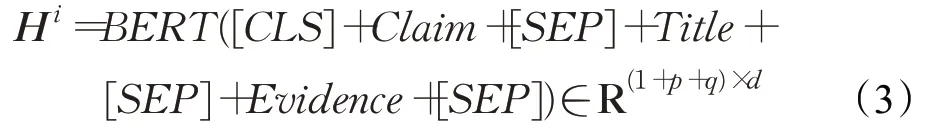
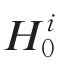
2.2.2 證據被選擇的概率
模型通過聲明與證據之間的語義相似度得到該證據被選擇用于支撐聲明驗證的概率,即該證據重要性的度量。下面按照基于卷積神經網絡的核注意力、匹配層和核池化層三部分進行介紹。
(1)基于卷積神經網絡的核注意力

使用F 個卷積核得到F 個標量,每一個標量描述了窗口不同維度的信息[33],然后加偏置項和非線性激活函數f 得到F 維的h-gram嵌入:

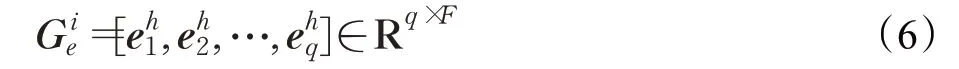
(2)匹配層



(3)核池化層
轉移矩陣描述了不同粒度字符間的相似度量,核池化層將不同的核作用于轉移矩陣提取相似度特征。模型利用K 個高斯核,每個kernel記為Kk,均值μk,寬度σk,不同的核提取到的語義信息層次不同:
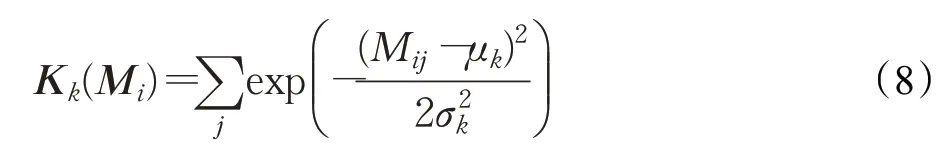
將K 個核應用于轉移矩陣的第i 行,可得到K 維的特征向量:

對K 維特征取對數求和得到C 對Ei的相似度特征:

對所有轉移矩陣的軟匹配的相似度特征拼接,得到Φ(Μ)∈R3K:


最后采用softmax歸一化得到證據被選擇的概率:
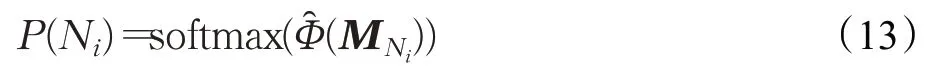
2.2.3 結合圖全局信息的標簽預測
標簽預測的關鍵是綜合考慮證據之間的關系,與Zhou[10]和Liu[24]等人做法相似,本文用字符級別的注意力生成節點表示,句子級別的注意力沿著圖中的邊更新信息,注意力是基于核計算得到的。
(1)字符級別的注意力
對節點N1和其鄰居節點N2,根據兩條證據的原始表示構造轉移矩陣M ,記節點N1經過BERT編碼表示為:
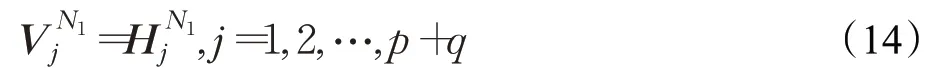

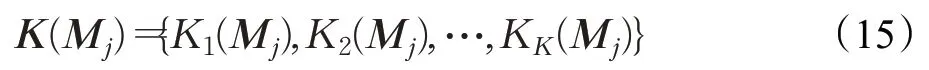
計算N1對N2的注意力權重:

其中,W1∈R1×K和b1∈R 是線性變換的參數,根據注意力權重可以計算出N1傳遞給N2的信息:

(2)句子級別的注意力
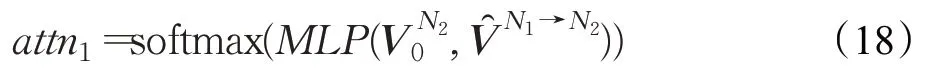
其中,MLP 是三層感知機,用注意力權重代表N1節點對N2節點的重要程度,利用圖注意力機制,將這S 個鄰居節點的信息都按上述方法聚合:


其中,⊕表示矩陣拼接,根據新的節點表示得到標簽預測概率:

W2∈R2d×t和b2∈Rt,t 是事實驗證的類別數,這樣每個節點都能通過鄰居節點,即沿著圖上的邊得到全局的信息。按上述步驟得到每一個節點預測該證據被選擇的概率和驗證標簽概率,最后所有節點預測的驗證得分為:

訓練階段,模型采用端到端的交叉熵損失進行訓練:


3 實驗結果與分析
3.1 數據集
本實驗采用FEVER 數據集驗證模型效果,數據集中的每一個樣本包括一個聲明、Wikipedia 中的正確證據(Golden Evidence)以及一個驗證標簽,并且還附帶一個由5 416 537 個預處理文檔構成的Wikipedia 文檔庫。該數據集提供了帶標簽的訓練集(Training)和開發集(Dev),測試集(Test)的答案不公開,測試結果在上傳預測文件后給出。FEVER的統計數據如表1所示。

表1 FEVER數據集
為了有效評估事實驗證的模型性能,本文用FEVER數據集提供的評價指標:標簽的準確率和FEVER 分數。標簽的準確率評價模型的推理驗證能力,FEVER分數綜合評價推理能力和檢索能力。當一個樣本的標簽正確,并且預測的證據集是正確證據集的子集,兩個條件同時滿足時FEVER 分數按1 記。其中信息不足(NEI)標簽的樣本不需要證據。此外,還針對推理能力測試了在提供正確證據的情況下模型的預測準確率。
3.2 實驗設置
檢索和推理驗證過程均采用BERT-Base 對文本編碼,包含12 個Transformer 層[14],詞嵌入的輸出維度是768,超參數基本按照BERT-Base 模型設置。核的個數設為21,第一個核是精確匹配核,參數是μ0=1.0,σ0=10-3。因為余弦相似度是在-1 到1之間,其余20個核在[-1,1]區間內,按照等間距取值,μ1=0.95,μ2=0.85,…,μ10=-0.95。在兩塊2080ti GPU 上運行約8 小時,模型的超參數如表2所示。
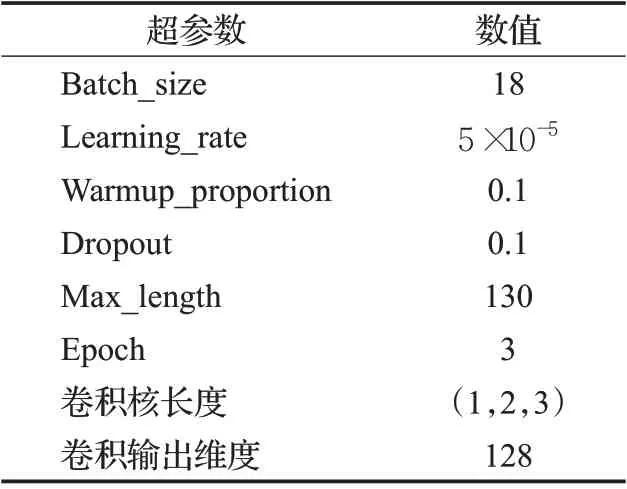
表2 參數設置
3.3 基線模型
FEVER 1.0數據競賽前三名的模型中,UNC-NLP[17]使用ESIΜ 模型檢索證據,并且在推理過程中引入外部知識,將WordNet 和瀏覽頻率作為特征融入推理模型,還使用了符號匹配規則;UCL[34]驗證每一個聲明證據對的真實性,最后對所有的信息進行融合推理;Athene UΚP TU[16]通過Attention 機制將ESIΜ 模型編碼的5 個聲明證據對結合進行推理,最終得到預測結果。除此三種模型外還有QFE[35],利用文本摘要模型,邊檢索證據邊做驗證;Attentive Checker[36]采用閱讀理解中的雙向注意力流(Bi-Directional Attention Flow for Μachine Comprehension,BIDAF)[37]結構完成驗證推理。
本文主要采用基于BERT的基線模型,現有的方法有如下幾種:一種是用BERT 編碼拼接聲明和所有證據,將所有的證據拼接作為一個整體,再和聲明拼接,對長度大于512的直接截斷,然后送入BERT模型做預測;還有用BERT針對聲明和證據對采用句對模型預測,每一對聲明和證據對分別送入BERT模型,不同的聲明和證據對的預測結果可能不同,然后再經過一個融合模塊得到最終預測標簽;GEAR 模型[10]將BERT 的[CLS]句向量的表示取出作為節點表示,然后用GNN 更新句向量表示,得到推理的結果。ΚGAT 模型[24]采用神經網絡排序模型基于細粒度的注意力融合證據信息。
3.4 實驗結果和分析
GHAN模型和其他模型方法在FEVER數據集上的表現對比如表3所示。
上述加引用的實驗結果為論文中公布的結果,QFE和Attentive Checker 未提供代碼和開發集上的結果。可以看出,GHAN 模型在測試集上準確率為73.96%,FEVER 得分為70.54%,GHAN 性能優于目前已公開的模型。值得注意的是,該模型FEVER 得分也比基于更龐大預訓練模型Roberta Large 的方法更好,而且使用的參數幾乎是后者的一半。
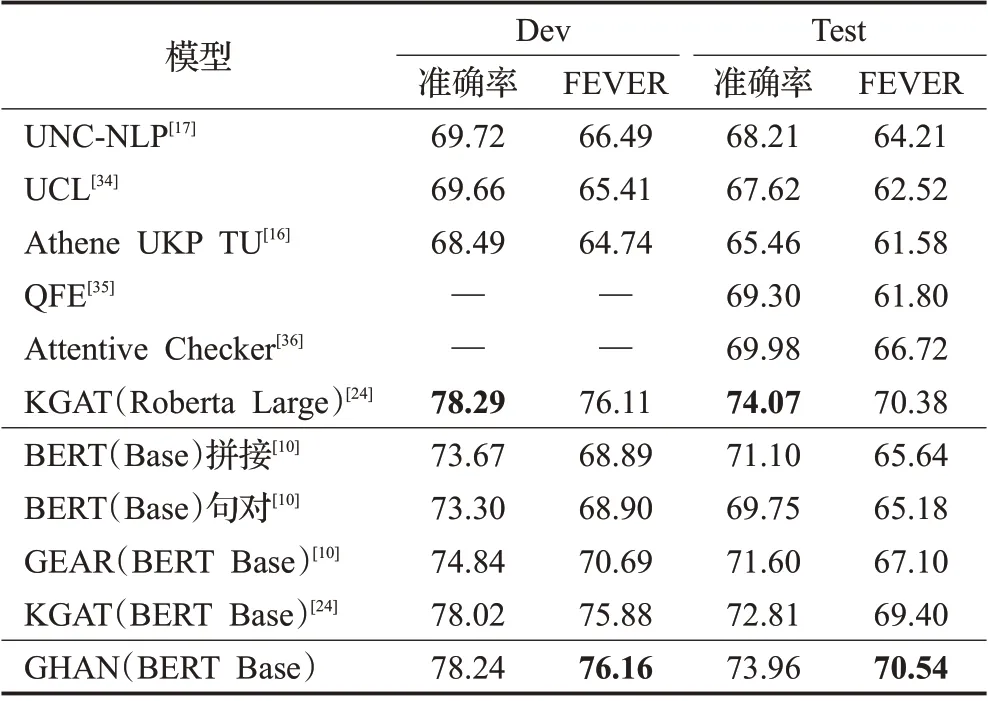
表3 不同模型在FEVER開發集和測試集上的精度%
3.4.1 消融實驗
為了分別評價模型各部分對實驗結果的影響,本文通過消融實驗移除各個長度的N-gram 特征,結果如表4所示。
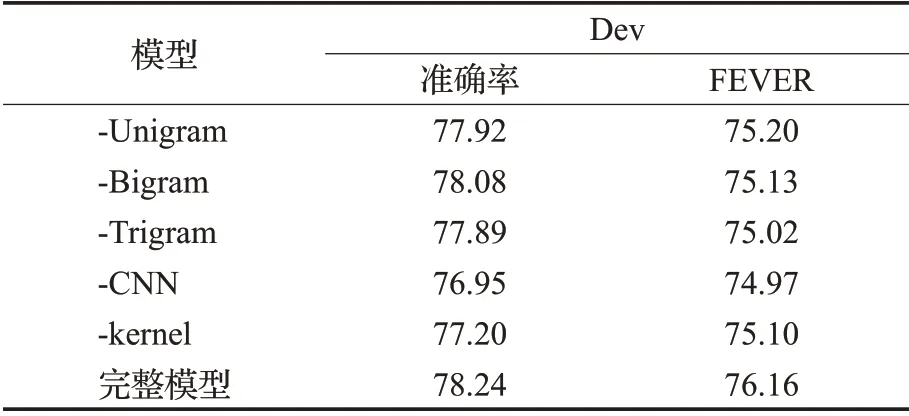
表4 層次信息對GHAN模型結果的影響 %
表中-Unigram、-Bigram、-Trigram 分別表示去掉h取值為1,2,3的卷積核,-CNN表示去掉所有CNN提取的特征,轉移矩陣直接由句子的BERT 嵌入相似度構成。如表中所示,去掉CNN 層對FEVER 得分影響最大。不同N-gram 分別對最終的準確率和FEVER 得分有不同程度的貢獻:一方面,長度不同的卷積核可以增強模型對細節信息的感知;另一方面,因為多個轉移矩陣使得提取的語義組合層次豐富具有多樣性,模型學習到與聲明中的詞語義相關的部分。
去除核并用點乘代替,準確率和FEVER 得分都降了1%,這表明核能有助于捕捉不同的高層語義信息。在核函數選擇上,GHAN 模型參照Xiong 等人[33]的方法,語義相似度越高它們越接近均值μk,當μ →∞時,kernel-pooling接近于平均池化;當μ=1,σ →0 相當于一個精確匹配的核。 μ 定義了軟匹配的程度,σ 定義了核的寬度。其他可導的核函數也可以作為軟匹配的核函數,本文采用的是最常用的高斯核。通過核得到分布在均值周圍的特征,也是Soft-TF 的含義(Soft Term Frequency)[23]。基于核函數的軟匹配在搜索領域運用廣泛,在事實驗證任務中,可以用于增強證據的細節和聲明的語義之間的匹配度。
3.4.2 不同場景下的實驗
由于FEVER 數據集中包含的證據來源不同,分散在單篇或多篇文章中,對于模型而言難易程度不同,因此統計了兩者的占比,如表5所示。

表7 GHAN錯誤樣例分析

表5 FEVER數據集中單個和多個證據的統計信息
聲明驗證所需單一證據的情景下,不需要復雜推理,模型表現顯然比需要多個證據的要好。GHAN在不同場景中的表現如表6所示。
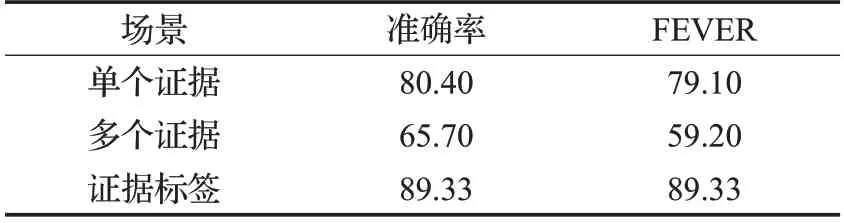
表6 GHAN在不同證據場景中的表現 %
因為模型檢索分散證據難度增大,所以驗證精度和FEVER得分都大幅下降。為了驗證模型的推理驗證能力,將檢索標簽直接送入模型,得到表6 中最后一行的結果。可見,檢索精度是下游推理的瓶頸之一,本文重點研究推理部分,檢索主要是考慮到程序運行效率,在實際應用中需要在效率和性能之間做更好的權衡。
3.4.3 錯誤分析
隨機選擇100 個錯誤樣本,進行樣例分析,發現主要有三類錯誤,如表7所示。
第一類是總結歸納性的語義理解錯誤。表格第一行證據中表明Richards做了很多政治工作,聲明是對她的工作專業的評價總結,模型并沒有理解到深層次的語義關系。
第二類是檢索到的信息不完善。表格第二行證據中沒有檢索到2007年的時間信息,導致推理驗證錯誤。
第三類是模型缺乏常識信息和指代信息。表格第三行樣例中,模型并不知道decades 是指10 年,同時也缺乏符號計算能力。以及前文檢索過程中遇到的指代問題,同一個名詞可能是指代不同事物,從而導致模型的誤判。
4 結束語
針對事實驗證任務,本文提出了基于圖的多層次注意力GHAN模型,模型通過卷積神經網絡捕捉到不同粒度的N-gram信息,利用不同的核映射到不同空間得到多層次的特征,使得多層次信息在信息融合圖中更新,得到更準確的事實驗證結論。實驗結果驗證了多層次細節信息對于事實驗證任務的重要性,在已知的基于BERT模型的方法對比中取得了最佳的效果。
外部知識能夠顯著改進模型的推理能力,在模型中引入外部知識,提高模型理解深層次語義的能力將會是未來的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
外語學刊(2011年1期)2011-01-22 03:38:33
