基于LSTM網絡的光伏發電功率短期預測方法的研究
2021-05-27 08:10:48宋紹劍李博涵
可再生能源 2021年5期
宋紹劍,李博涵
(廣西大學 電氣工程學院,廣西 南寧530004)
0 引言
由于光伏發電功率具有隨機性和波動性等特性,因此,大規模光伏發電并網會造成電網功率劇烈波動,嚴重影響了電網系統的安全穩定運行以及調度規劃[1]。精準預測光伏發電功率有利于電網調度人員合理調整發電計劃、維護電力系統的穩定運行。
目前,光伏發電功率預測方法有兩種,分別為基于物理模型的直接預測方法和基于歷史數據的間接預測方法[2],[3]。直接預測方法主要依托天氣數值或氣象云圖等信息預測發電功率,所用的模型有天氣數值模型[4]、地基云圖模型[5]以及天氣數值與云量圖像相結合的預測模型[6]等。直接預測方法需要準確的天氣預報信息、電站地理信息和大量的天空圖像信息,且對采集設備和采集方式有較高的要求,導致該預測方法的魯棒性較差。同時,直接預測方法所用模型具有無法獲取時間相關性信息、缺少對歷史數據的記憶能力等缺點。間接預測方法包括時間序列法[7]、回歸分析法[8]等統計方法和人工神經網絡[9]、支持向量機[10]等人工智能方法。間接預測方法能夠克服直接預測方法對物理機理掌握不足等困難,適用于光伏短期、超短期功率預測。長短期記憶(Long Short-term Memory,LSTM)網絡是一種具有時序記憶功能的遞歸神經網絡(Recurrent Neural Networks,RNN),將其應用到光伏發電功率預測領域成為當前的研究熱點。文獻[11]首次將LSTM網絡應用到光伏發電功率預測中,分析結果表明,加入具有記憶能力的神經網絡能夠有效提高預測精度。但由于此類研究尚處于起步階段,相關的研究較少,因此,基于LSTM網絡的預測方法仍然須要進一步優化研究。
本文建立了一種基于LSTM網絡的光伏發電功率短期預測模型(以下簡稱為LSTM網絡預測模型),利用LSTM網絡的歷史記憶能力和人工智能算法的自學能力,進一步提高該模型的預測精度和適應性能。在原始數據預處理過程中,本文依據日照晴朗指數將天氣類型量化為[0,1]內的數值;然后,依據光伏電站當地氣候特點將樣本數據進行季節標識;接著,為了降低輸入數據序列維度和模型復雜度,本文采用主成分分析法(Principal Component Analysis,PCA)對多元影響因素數據進行處理、分析,并篩選出累計貢獻率排名前8位的主成分作為本文模型的輸入,并結合歷史發電數據對LSTM網絡預測模型進行訓練和測試;最后,將本文模型的預測結果與基于誤差反向傳播(Back Propagation,BP)的短期預測模型(以下簡稱為BP網絡預測模型)和不帶記憶能力的RNN網絡短期預測模型(以下簡稱為RNN網絡預測模型)進行對比分析。分析結果表明,本文方法對時序數據預測具有較強的魯棒性、預測結果更加準確,為電力調度部門調整發電計劃提供更有力的保障。
1 光伏發電功率的主成分分析
1.1 影響光伏功率輸出的關鍵因素
光伏發電功率的隨機性、波動性等特征大大增加了預測難度。影響光伏發電功率的因素較多且復雜,主要分為兩類:一類是由電氣零件老化、參數設置、內部損耗和安裝角度等光伏電站內部因素導致的;另一類是由太陽輻射強度、溫度、風速、季節特性等外部氣象因素導致的。由于光伏電池在出廠時已進行了各項檢測,安裝角度和使用年限也是依據國家規定標準執行的,因此,轉換效率等參數差別不大,于是本文將光伏電站內部因素作為可控常量,僅把環境溫度、太陽輻射強度、天氣類型等外部氣象因素作為光伏發電功率預測的主要影響因素。為保證模型預測結果的準確性,在建立光伏發電功率預測模型的過程中,應全面考慮有關氣象因素的影響,但因這些氣象因素影響強度不同,過多輸入影響強度較低的氣象因素反而會增加數據冗余,對預測結果不利。另外,有些氣象因素之間存在一定的耦合性,而另一些氣象因素之間相互獨立,單純將某一氣象因素與光伏發電功率做相關性分析和篩選,會在一定程度上造成該氣象因素的隱含價值信息疏漏。綜上可知,采用PCA對主要影響因素進行處理,既能提取有價值的信息、保證預測精度,又能降低輸入變量維度、節省運算時間。
1.2 主成分分析
PCA將m維空間內的因素群投影到p維空間上(p<m),在包含原始數據信息的同時,將各因素整合重組構成新的、維度較少的主成分數據,計算步驟如下[12]。
①定義元素矩陣X=(x1,x2,…,xm)由m個因素,n組樣本數組成,則X的原始矩陣可表示為

②原始矩陣中變量xi與xj的相關系數rij(i,j=1,2,…,m)和相關系數矩陣R的計算式分別為

式中:I為單位向量。
累計貢獻率閾值的表達式為

式中:λj為特征根。
④將初始樣本數據序列投影到p個特征向量構成的新序列,該新序列的主成分表達式為

式中:Yij為降維后的p維主成分;ej為特征向量。
累計貢獻率閾值a的取值根據原始數據維數和降維后試驗精度的要求確定,由于降維后的數據矩陣既要包含原始數據的大部分有效信息,又要具有降維作用,因此,本文選取累計貢獻率在85%~95%的維度作為PCA的降維參考維度。主成分表征數據轉換到新維度中的維度信息,并不對應初始各維度中原始變量的物理含義[13]。
2 長短期記憶神經網絡
2.1 LSTM網絡結構
LSTM是一種以循環神經網絡RNN為基礎并加以改進的深度學習算法,其核心思想是將數值為小數的梯度由連乘形式變為累加形式,該方法可使LSTM在處理長期時序信息時解決梯度消失的問題。LSTM神經網絡結構與RNN相似,均由輸入層、隱藏層和輸出層組成。LSTM神經網絡結構示意圖如圖1所示。圖中:xt-1,xt,xt+1分別為t-1,t,t+1時刻的網絡輸入變量;ht-1,ht,ht+1分別為t-1,t,t+1時刻輸出的短期狀態;ct-1,ct分別為t-1,t時刻的網絡記憶狀態;ft,it,ot分別為遺忘門、輸入門和輸出門;σ為sigmoid激活函數;gt為更新t時刻輸入狀態的控制門。

圖1 LSTM神經網絡結構示意圖Fig.1 Schematic of LSTM neural network structure
由圖1可知,LSTM中模塊A讀取輸入xt,并輸出ht,信息從上一個步驟傳遞到當前步驟進行計算。與RNN不同的是,LSTM的模塊A中添加了由3個“控制門”單元和時間記憶“傳送帶”組成的記憶模塊。3個“控制門”分別為遺忘門ft、輸入門it和輸出門ot。遺忘門負責篩掉須要丟棄的信息;輸入門負責決定輸入新信息的數量;輸出門負責輸出狀態信息的位置。3個“控制門”是由sigmoid激活函數σ和一個逐點相乘的連接,實現對信息的控制。在信息傳輸過程中,ct-1通過遺忘門和輸入門的信息處理更新自身狀態變為ct;然后,由tanh函數對ct進行處理,處理結果與ot輸出項相乘,確定LSTM中模塊A須要輸出的結果,該結果與ct一同輸送到下一模塊中。網絡運算過程中,ct與輸入信息共同決定輸出信息的同時,ct自身狀態也在不斷更新。攜帶記憶信號的ct,解決了RNN網絡梯度消失的問題,使得LSTM神經網絡能夠真正有效地利用時序信息,各隱藏層之間的相互聯系使ct在時序數據分析中有很強的適應能力,LSTM記憶模塊如圖2所示。

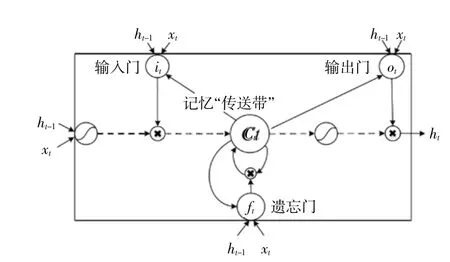
圖2 LSTM記憶模塊Fig.2 Memorymodule of LSTM

2.2 LSTM網絡的訓練算法
LSTM神經網絡的訓練算法是一種隨時間展開的反向傳播算法 (Back Propagation Trough Time,BPTT)。LSTM神經網絡的訓練算法的具體步驟如下:首先,前向計算每個LSTM單元的輸出值;然后,反向計算每個單元的誤差項,利用相應的誤差項計算每個權重的梯度;最后,權重通過梯度下降算法更新。LSTM訓練流程圖如圖3所示。
3 光伏發電預測模型設計
3.1 數據處理
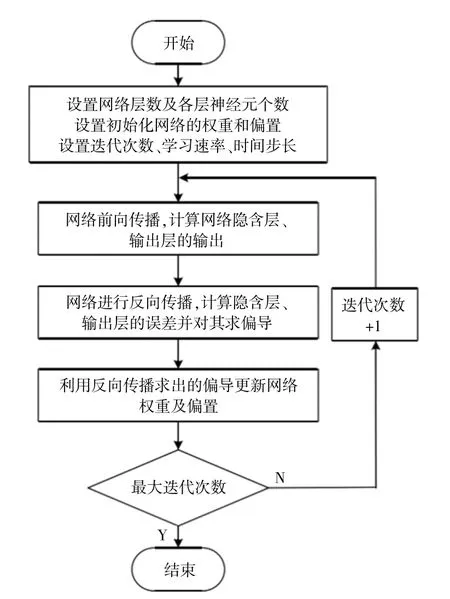
圖3 LSTM訓練流程圖Fig.3 Process of LSTM network training
在實際預測過程中,存在由于設備故障、人為失誤、極端天氣等因素導致數據樣本出現信息異常或缺失,以及由于物理意義和單位量綱不同導致變量之間存在較大數量級差距的問題。為了解決上述問題,本文對原始數據樣本進行缺失信息補充、歸一化等預處理,該做法在提高模型預測精度的同時減少了運算步驟、提高了模型的訓練效率。本文以2017年3月1日-2018年2月28日廣西某額定裝機容量為20MW的光伏電站的歷史發電數據作為實驗依據。發電功率采樣時間間隔為30min。氣象因素采用中國氣象網和美國國家航空航天局(National Aeronautics and Space Administration,NASA)獲取的太陽輻射強度、地表溫度、天氣晴朗指數等。
缺失信息分為數值型數據和非數值型數據。當缺失信息為數值型數據時,以該數據對應的氣象因素的其他所有樣本數據的平均值來補充缺失信息;若缺失信息為非數值型數據時,可根據統計學中的眾數概念,以該缺失信息對應的氣象因素中出現次數最多的信息補充缺失信息。將電站實測發電數據和對應日氣象數據匹配后,通過歸一化處理,可使各維特征限定在一定的范圍內,以降低運算陷入局部最優化的概率,歸一化公式為

式中:Xnorm為歸一化后的數據;X為原始數據;Xmax,Xmin分別為原始數據集中的最大值和最小值。
由于天氣類型屬于描述性詞匯,無法直接帶入模型,而日照晴朗指數是受天氣影響的一種無量綱量,不能完全替代天氣類型帶入模型,因此,本文以日照晴朗指數作為量化天氣類型的依據。隨機選取晴朗、多云、陰天、雨(雪)4種天氣類型各50 d的光伏電站的日發電量數據組成樣本集,利用該樣本集和對應日的日照晴朗指數輸出散點圖如圖4所示。
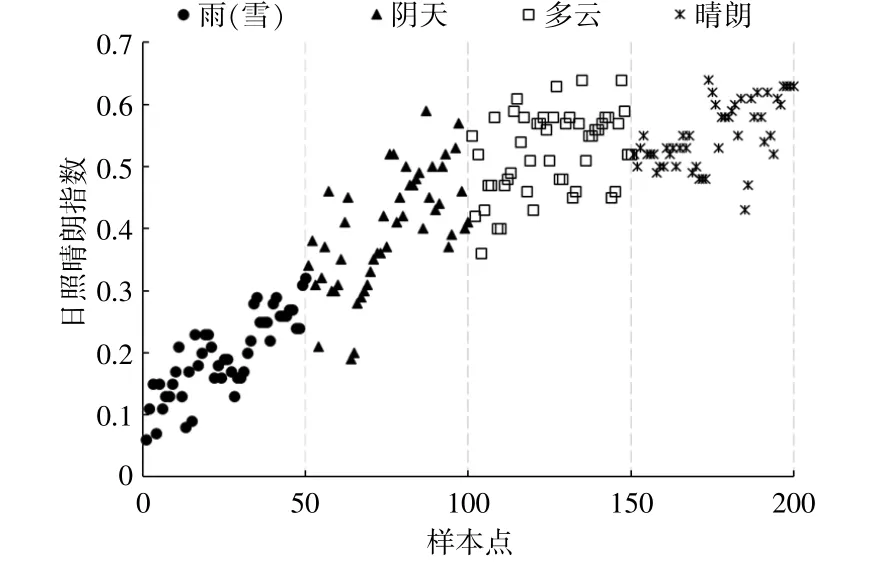
圖4 各天氣類型樣本點與對應日的日照晴朗指數的關系散點圖Fig.4 Relationship between weather types and insolation clearness index
以雨(雪)天氣為例,由圖4可知,散點分布對應的日照晴朗指數集中在[0.1,0.3],日照晴朗指數為0.15處的散點分布最為密集。4種天氣類型對應的日照晴朗指數由小到大依次為雨(雪)<陰天<多云<晴朗。本文將天氣類型按日照晴朗指數的平均值量化為[0,1]的離散數值。天氣類型量化結果如表1所示。

表1 天氣類型量化結果Table 1 Quantitative chartofweather type
除受氣象因素影響外,光伏電站發電功率也會隨季節更替發生變化。同種天氣類型出現在不同季節,光伏電站發電功率也會不同。以多云天氣為例,從數據樣本中抽取不同季節多云天氣時的光伏電站發電功率組成4組樣本,每組樣本取樣時間均為15 d。不同季節多云天氣類型光伏電站發電功率如圖5所示。
由圖5可知:夏季,光伏電站的發電功率高于其它季節;冬季,光伏電站的發電功率低于其它季節。為了進一步提高本文模型的預測能力,將光伏電站的歷史發電功率與氣象因素對應后,按季節對光伏電站的歷史發電功率進行劃分,基于日照時間夏長冬短,雨、旱季節分明等氣候特點,以及光伏電站歷史發電功率的分析結果,將本文預測模型對四季時長的定義進行了重新劃分。
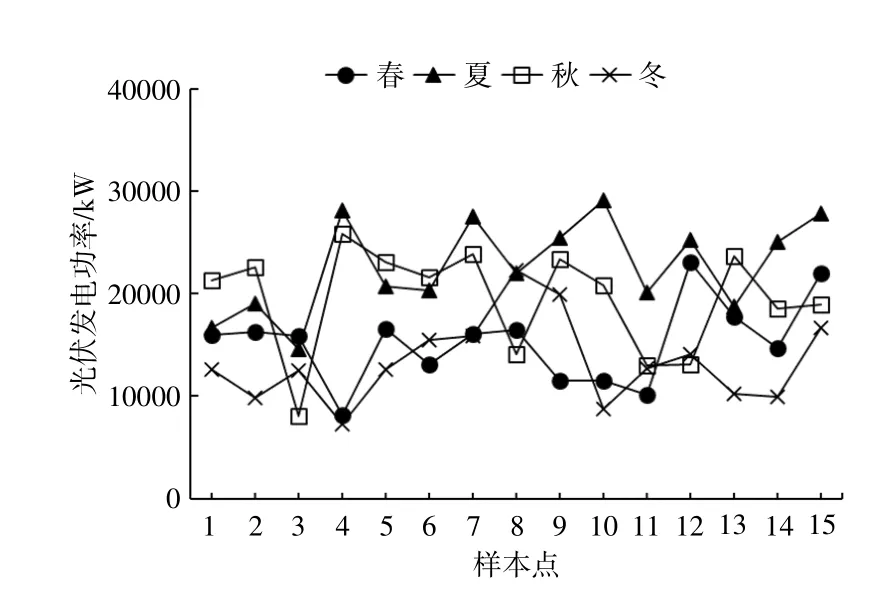
圖5 不同季節多云天氣類型光伏電站發電功率Fig.5 Power generation of cloudyweather types in different seasons
圖6為廣西1981-2010年各月平均環境溫度曲線圖。
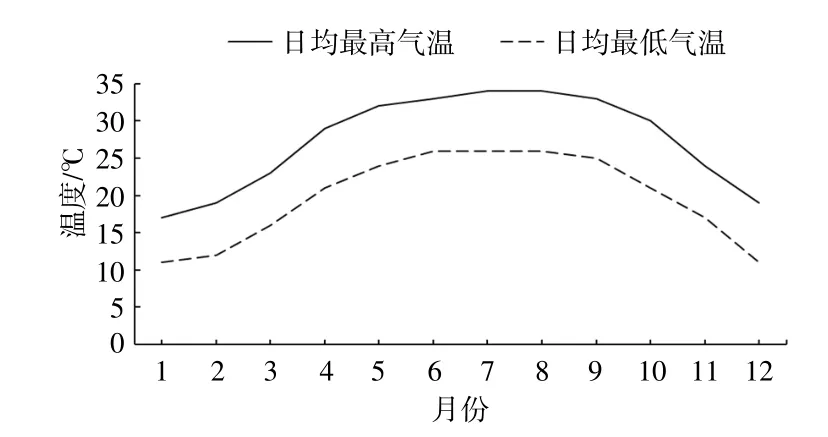
圖6 廣西1981-2010年各月平均環境溫度曲線圖Fig.6 Historical temperature curve of eachmonth in sampling area
由圖6可知,廣西全年歷史最低溫度出現在1月和12月,4-10月溫度偏高,2,3,11月為氣溫過渡月。根據中國氣象局統計的廣西氣候特征顯示,廣西氣候干濕分明,其中,4-9月為雨季,10月-次年3月為干季。結合氣候特征和候溫季節劃分法,將預測模型定義的春季設置為2-3月、夏季設置為4-9月、秋季設置為10-11月、冬季設置為12月-次年1月,其中,夏季標識時長為6個月,其余3個季節標識時長均縮短為2個月。
3.2 模型參數設置
LSTM網絡預測模型的輸入層為多元數據序列,根據實際采集到的信息相關性分析,輸入變量初始序列包含06:30-18:00時段,時間間隔為30 min的24個采樣點發電功率(春季選取時段為06:30-18:00,其它季節時段選取稍有不同,但每天采樣點數不變),結合采樣日對應的地表溫度、距地面2m處的溫度、當日最高溫度、當日最低溫度、紅外線輻射量、霜點、濕度、風速、天氣類型以及季節標識信息,共計34維數據構成一天的輸入變量初始序列。采用PCA對預處理后的輸入變量初始序列進行分析,計算出序列中各主成分協方差矩陣特征值、方差貢獻率和累計貢獻率見表2。

表2 各主成分協方差矩陣特征值、方差貢獻率和累計貢獻率Table 2 Covariancematrix eigenvalues and variance contribution rate and accumulated contribution rate
由表2可知,前8個主成分累計貢獻率為94.983%,前8個主成分可以涵蓋原始樣本數據序列的絕大部分信息,主成分個數繼續增加后對應的累計貢獻率增幅不大,因此,主成分數量設置為8個。將34維初始輸入序列矩陣降維至新的8維矩陣中,輸入層節點數設置為8。模型的隱藏層層數越多,其非線性擬合能力越強,但訓練時間也隨模型復雜度的提高而增長。經過多次訓練可知,LSTM隱含層節點數為14的結構可以取得較好的預測效果,因此模型隱含層節點數設置為14。預測結果為待預測日06:30-18:00時間間隔為30min的發電功率,因此,預測模型輸出層的神經節點數設置為24。
3.3 模型評價指標
由于決定預測模型精確性的評價指標較多,采取單一的評價指標容易受到計算誤差的影響,因此,本文采用平均絕對誤差MAE、均方根誤差RMSE和相關系數R這3種誤差標準分別對預測結果進行分析。MAE和RMSE值越小,R值越大表明預測效果越好。MAE,RMSE和R的計算式分別為

4 算例分析
為了檢驗LSTM網絡預測模型的預測性能,從樣本中根據不同季度隨機抽取連續3 d的發電數據作為測試樣本,其余作為訓練樣本。將LSTM網絡預測模型反歸一化的預測結果與基于BP和RNN網絡搭建的預測模型預測結果進行比較,3種預測模型均采用同一數據集進行訓練和測試。BP網絡預測模型輸入層節點數為PCA降維后的8個輸入變量,輸出層節點數與LSTM網絡預測模型輸出層均為24個,隱含層節點數依據經驗公式計算得出合理范圍,經過多次試驗驗證,最終設置為16個。RNN網絡預測模型結構同理,輸入層節點數為8個,輸出層節點數為24個,經過反復試驗將其隱含層節點數設置為11個。3組預測模型學習速率均設為0.01,訓練的目標誤差為1×10-4,最大訓練次數為1×103次。圖7為4個季節連續3 d測試樣本的發電功率預測結果對比。

圖7 不同季節下,3種模型連續3 d預測結果對比Fig.7 Comparison of threemodels for three consecutive days in different seasons
通過對比MAE,RMSE和R三者的結果分析預測模型的精度,3種預測模型預測四個季節的預測結果如表3所示。
以春季為例,BP,RNN網絡預測模型預測結果的MAE分別為4.771和3.216,而LSTM網絡預測模型的MAE降低到了1.657;BP,RNN網絡預測模型預測結果的RMSE分別為7.34,5.29,LSTM網絡預測模型的RMSE降低到了4.1。
為進一步驗證LSTM網絡預測模型在不同天氣類型下預測光伏發電功率的準確性,在相同季節(春季)的樣本中,再次隨機選取4種天氣類型各一天的發電功率作為測試樣本,剩余樣本數據作為訓練樣本。不同天氣類型下3種網絡預測模型的預測結果與實測發電功率數據如圖8所示。

表3 3種預測模型四季的預測結果Table 3 Error results of three predictionmodels in four seasons
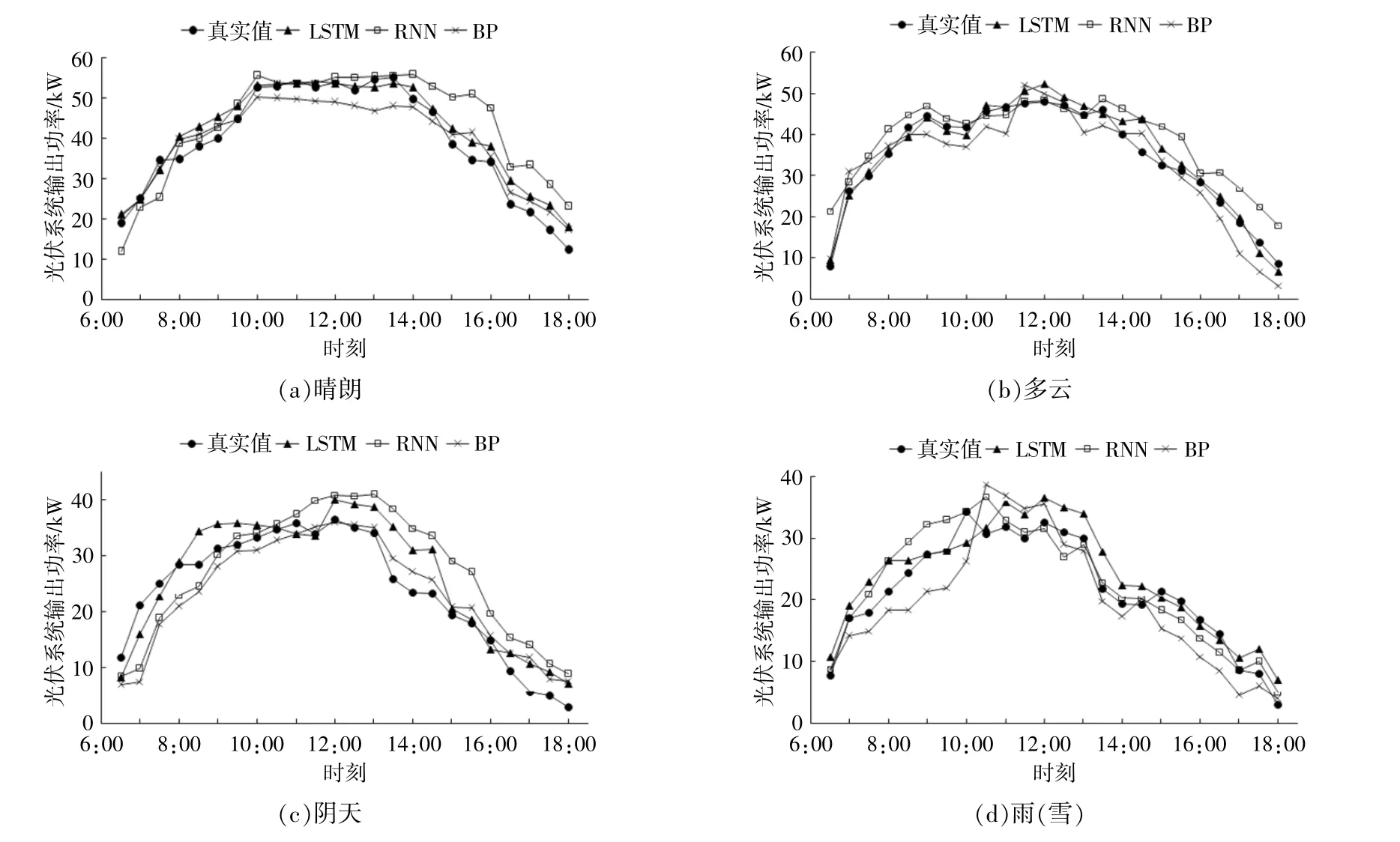
圖8 3種模型在不同天氣類型下的預測結果對比Fig.8 Comparison of threemodels in differentweather types
由圖8可知,晴朗與多云天氣條件下LSTM網絡預測模型的預測結果明顯優于BP與RNN網絡預測模型,而陰天和雨天的預測結果相對稍差,故再次計算了4種天氣類型中3組預測模型的MAE,RMSE,R進行比較,計算結果見表4。

表4 3種預測模型不同天氣類型的預測結果Table 4 Error results of three predictionmodels in differentweather types
由表4可知,在晴朗和多云天氣下,LSTM網絡預測模型的預測誤差明顯低于其他兩種預測模型;陰天和雨天的MAE小于4,RMSE小于5.5,R值為0.966,均優于BP和RNN網絡預測模型的預測結果。
在光伏發電功率預測方面,本文基于LSTM網絡搭建的預測模型的預測誤差明顯低于BP、RNN網絡預測模型的預測誤差,在不同季節的預測結果都具有良好的預測精度,由此證明了本文方法在時序預測方面的準確性,以及預測模型在惡劣天氣條件下運算的魯棒性,在光伏發電預測方面具有較為明顯的優勢。
5 結論
由于光伏發電功率數據具有時序性和非線性的特點,而傳統的機器學習模型和物理模型無法同時兼顧這兩個問題,使得預測精度較低。本文基于LSTM網絡搭建的預測模型在訓練和預測時,可以有效地保留或剔除歷史訓練產生的影響因素,使預測結果能夠更好地體現數據信息的時序性。在預處理階段按季節劃分樣本數據,經過對冗余信息處理后輸入到預測模型中,提高預測模型的數據處理效率。將LSTM,RNN和BP網絡預測模型均在劃分好的數據集中比較試驗,試驗結果證明LSTM在預測光伏發電功率時具有更好的魯棒性和泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
