人工智能和視速度約束的地震波初至拾取方法
2021-06-01 10:29:32DavidCova丁成震魏程霖李韻竹
石油地球物理勘探 2021年3期
關鍵詞:分類
David Cova 劉 洋*③ 丁成震 魏程霖 胡 飛 李韻竹
(①中國石油大學(北京)油氣資源與探測國家重點實驗室,北京 102249;②中國石油大學(北京)CNPC 物探重點實驗室,北京 102249;③中國石油大學(北京)克拉瑪依校區石油學院,新疆克拉瑪依 834000;④東方地球物理公司研究院,河北涿州 072751)
0 引言
靜校正是地震資料處理的重要環節之一,而初至拾取是計算地表靜校正量的一個重要步驟,特別是在地表條件較為復雜的地區,低速風化層速度變化較為劇烈,準確、自動拾取初至成為解決此類地區靜校正問題的關鍵所在。然而,目前大多數的初至拾取方法只能實現部分自動化,需要花費大量時間進行人工質量控制。隨著高密度地震采集技術的應用,地震數據量變得十分巨大,導致初至拾取過程中耗費的人工成本急劇增加。基于深度學習的初至自動拾取方法成本低、效率高,可以滿足當今地震高密度采集的數據量需求。傳統的初至自動拾取方法,如基于能量的方法[1-2]或基于相關性的方法[3-4],普遍要求數據信噪比高、波形一致。在地形變化劇烈或強噪聲干擾的情況下,初至拾取精度會降低。
深度神經網絡適合于解決模式匹配分類問題,它由神經網絡演化而來,結構更加復雜,性能可以隨訓練數據的增加而提高[5]。
深度學習算法可以挖掘數據的特征。深度學習模型由多個層次組成,以學習具有多個抽象層次的數據表示。這是一種層次漸進的特征學習,先從較低層次的特征中學習,從而定義更高層次的特征[6]。在此意義上,初至拾取問題可以定義為模式識別問題,目的是區分背景噪聲與地震有效數據。因此,深層神經網絡可以從地震數據中學習特征而無需人工干預,將地震數據分為噪聲和有效數據兩類。
近幾年來,出現了多種應用機器學習進行初至拾取的方法,如神經網絡[7-8]、支持向量機[9]、模糊聚類[10]、混合卷積神經網絡(Convolutional Neural Network,CNN)[11-12]、全卷積網絡(Fully Convolutional Network,FCN)[13-14]、半監督全卷積網絡(SS-FCN)[15]、U-Net變體[16-17]和伴有遷移學習的卷積神經網絡[18-19]等。在這些方法中,FCN可以逐像素分類、處理不同大小的數據,因此被廣泛使用。
FCN起源于CNN,CNN最早由LeCun等[20]提出,但當時計算能力制約了其更為廣泛的應用。近十年來,由于圖像分類技術的重大突破,卷積神經網絡得到了廣泛的應用,相繼開發了AlexNet[21]、VGG16[22]和GoogleNet[23]等架構。CNN能夠逐步減少輸入數據占用的空間,并有效增加特征映射的數量,但是在預測分辨率方面存在不足。該問題的一種解決方法是使用語義分割進行像素級分類,并從低清晰度表示中恢復高分辨率輸出。目前,語義分割方法一般使用FCN架構。FCN通過下采樣和上采樣兩部分恢復高分辨率輸出,通常可以通過轉置卷積[24-25]或空洞卷積[26-27]實現。U-Net作為FCN的一種變體,具有多功能性、可處理不同大小的數據且分割性能明顯提高[28]等特點。然而,U-Net在實現初至拾取時有一定的局限性,尤其是在數據的信噪比較低時,拾取結果的精度會低于之前的驗證精度。因此,網絡結構需要進一步優化以減少誤差。此外,對圖像后續處理也能有效改善拾取結果[29]。由于近年來U-Net應用效果較好,它的結構得到了更為廣泛的拓展,例如UNet++[30]和Attention U-Net(aU-Net)[31]能較好地解決復雜分割問題。
針對以上問題,本文提出了四個關鍵技術點:
(1)將U-Net網絡模型與簡單變體網絡模型aU-Net、復雜變體網絡模型UNet++的效果進行比較,從不同角度分析分割問題;
(2)通過試驗確定網絡超參數,包括對損失函數、優化器和激活函數等進行試驗;
(3)制定振幅均衡處理流程,可以提高樣本信噪比,均衡訓練樣本,提高訓練穩定性、樣本識別率和預測值魯棒性;
(4)在拾取初至之前,對分割的邊緣添加視速度約束以增加圖像分割細節。
最后,使用該方法對一套陸地地震數據集進行初至自動拾取,獲得了較好的結果。
1 方法原理
1.1 U-Net模型
U-Net模型由兩部分組成,第一部分為編碼器(下采樣),第二部分為解碼器(上采樣)。編碼器是一種傳統的CNN,它通過增加特征映射的數量、減少空間采樣信息提取高層次至低層次的特征。解碼器的作用是恢復數據在編碼過程中的特定位置,逐漸降低分辨率。同時,用殘差連接(Residual Connections)將高分辨率的局部特征與低分辨率的全局特征相結合,增加更具語義意義的輸出。
在用于初至拾取的U-Net結構中,其工作原理是:在輸入的空間位置中檢測信號具體的特征,這些特征與地震有效數據和背景噪聲的特征有關;對檢測到的特征逐像素進行二值分類,得到區分有效信號與噪聲的分割圖像,通過訓練U-Net學習有效信號和噪聲特征并進行分類;將有效信號與噪聲區域之間的分割邊緣定義為初至時間。在初至拾取中,由于初至在單炮記錄上一般是近似對稱出現的,所以邊界檢測問題比傳統的分割問題更簡單。
圖1所示為U-Net結構,每個編碼器層包括兩個無偏差的級聯卷積層以提高分類精度,每個卷積層的值為
(1)

盡管U-Net已經取得了一定的效果,但在分割精度方面仍然存在一些限制。因此,需要使用額外的方法提高分割精度,本文比較了三種不同復雜度的U-Net結構,從不同角度分析該問題。
1.2 UNet++模型
UNet++[30]與U-Net有三個不同之處:一是前者的殘差連接具有卷積層,可以用來解決編碼器特征與解碼器語義之間的語義差別;二是前者的殘差密集連接可以改進梯度流(Gradient Flow);三是與單一損失層相比,前者的深度監督(Deep Supervision)實現了模型剪枝(Model Pruning),可以更有效地提高性能。
U-Net殘差連接直接將高分辨率的特征映射從編碼器傳送到解碼器,通常這個過程會使特征映射產生一定的非相似性。雖然殘差連接有助于恢復網絡輸出的空間分辨率,但是結合來自編碼器與解碼器的語義上不相等的特征映射可能會降低分割性能。當解碼器與編碼器網絡的特征映射在語義上相似時,分隔精度會得到提高。為了實現這一點,U-Net++引入了一個深度監督的編碼器和解碼器,其中編碼器與解碼器通過一系列嵌套和密集的殘差連接結合在一起(圖2)。殘差連接減少了編碼器與解碼器特征映射之間的語義差別,并在高分辨率特征映射上捕捉到細節。疊加特征映射的計算公式為
(2)
式中:Xi,j是節點的輸出,i是沿編碼器的下采樣層,j是沿著殘差連接的密集塊的卷積層序號;H(·)是緊跟激活函數的卷積運算;u(·)是上采樣層;[]是連接層。
1.3 Wide U-Net模型
Wide U-Net(wU-Net)[30]的卷積核由U-Net的32×64×128×256×512變為37×70×140×280×560,通過采用更多的超參數提高網絡性能。wU-Net和UNet++模型具有相似數量的超參數(表1),能夠客觀地度量網絡性能。
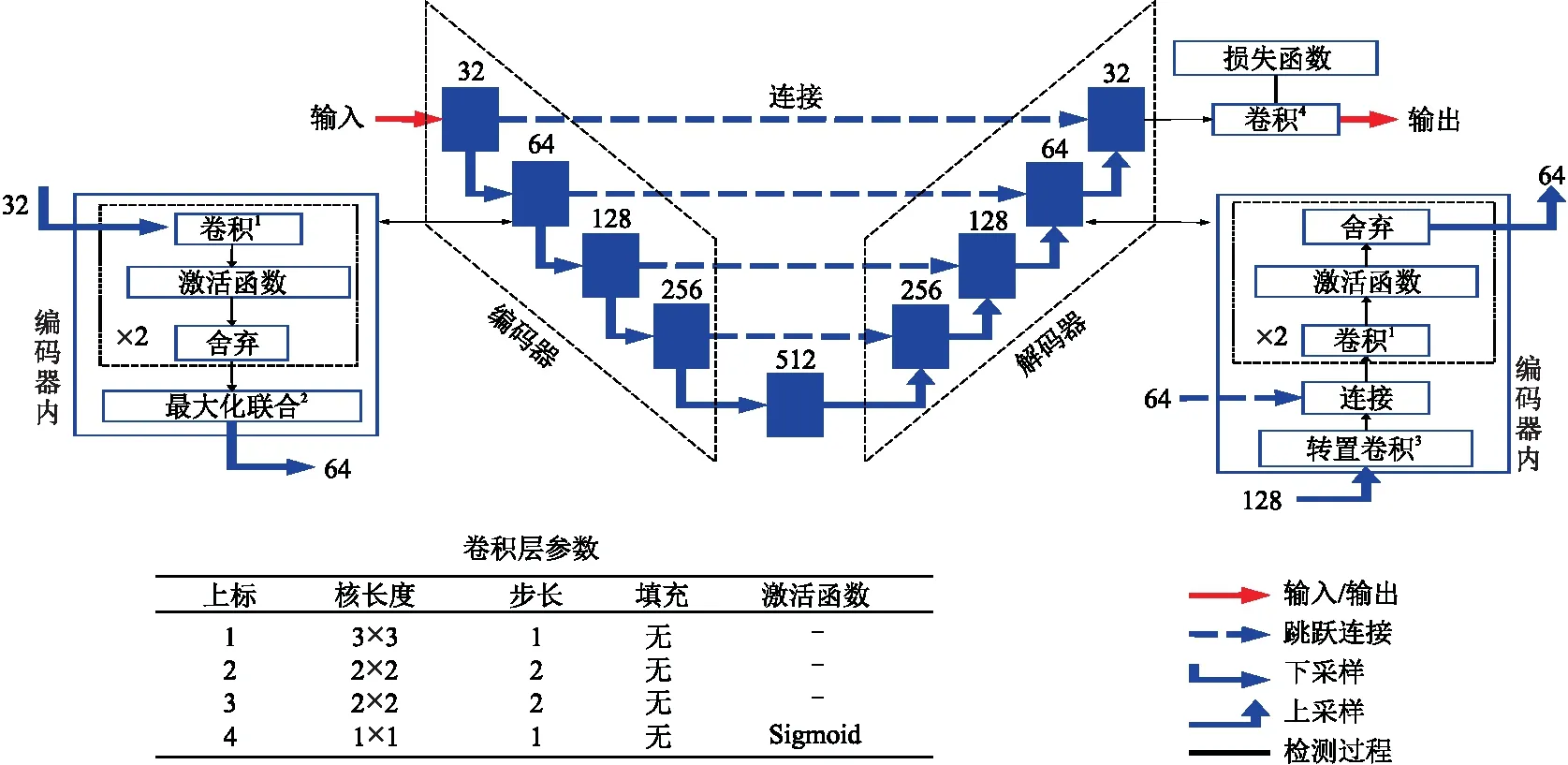
圖1 U-Net結構
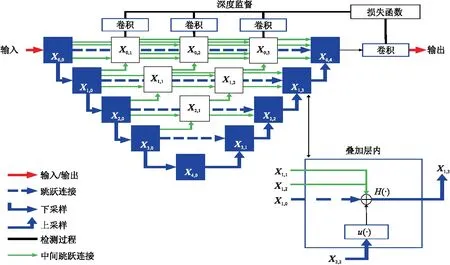
圖2 UNet++結構

表1 U-Net變體的超參數
1.4 Attention U-Net模型
雖然U-Net具有表達能力強、推理速度快、濾波器共享等特點,但是當目標的形狀和大小有很大變化時,它需要依賴多級串聯的CNN。此外,傳統方法會導致計算資源和模型參數的過度冗余使用。為了解決這一問題,發展了Attention U-Net模型,即aU-Net[31]模型(圖3a),引入了注意門(Attention Gates,AGs)(圖3b)。
AGs可以在沒有額外監督的情況下專注于目標結構進行自動學習。在訓練過程中,這些門突出對分類任務有用的顯著特征。此外,它不會顯著增加計算量,也不像多模型框架那樣需要大量的模型參數(表1)。AGs通過抑制不相關區域的特征,提高了模型對稠密標簽預測的敏感性和準確性,同時保持了較高的預測精度。
AGs可以通過以下公式表達,即
(3)
(4)
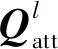
1.5 超參數優化
通過比較U-Net與基于U-Net的三種不同變體模型的性能,發現U-Net優于復雜化的U-Net變體。下面對U-Net的每個超參數進行詳盡測試以得到最優化的結果。測試的參數包括學習率(Learning Rate)、激活功能(Activation Function)、損失函數(Loss Function)、優化器(Optimizer)、舍棄比率(Dropout Rate)和權重初始化(Weight Initialization)等(表2)。
重點分析激活函數和損失函數。首先,傳統的U-Net激活函數是ReLU[32],它存在梯度消失問題。為了避免這種情況,研究人員嘗試了ELU[31],并取得了一些效果。本文中除了以上兩個函數之外,還比較了另外兩個激活函數,一個是帶泄露修正線性單元(Leaky ReLU,LReLU)[33],這是對傳統ReLU的簡單改進,可避免梯度消失問題;另一個是SELU[34],這是一個更復雜的解決方案,可以與ELU相媲美。它們的表達式分別為
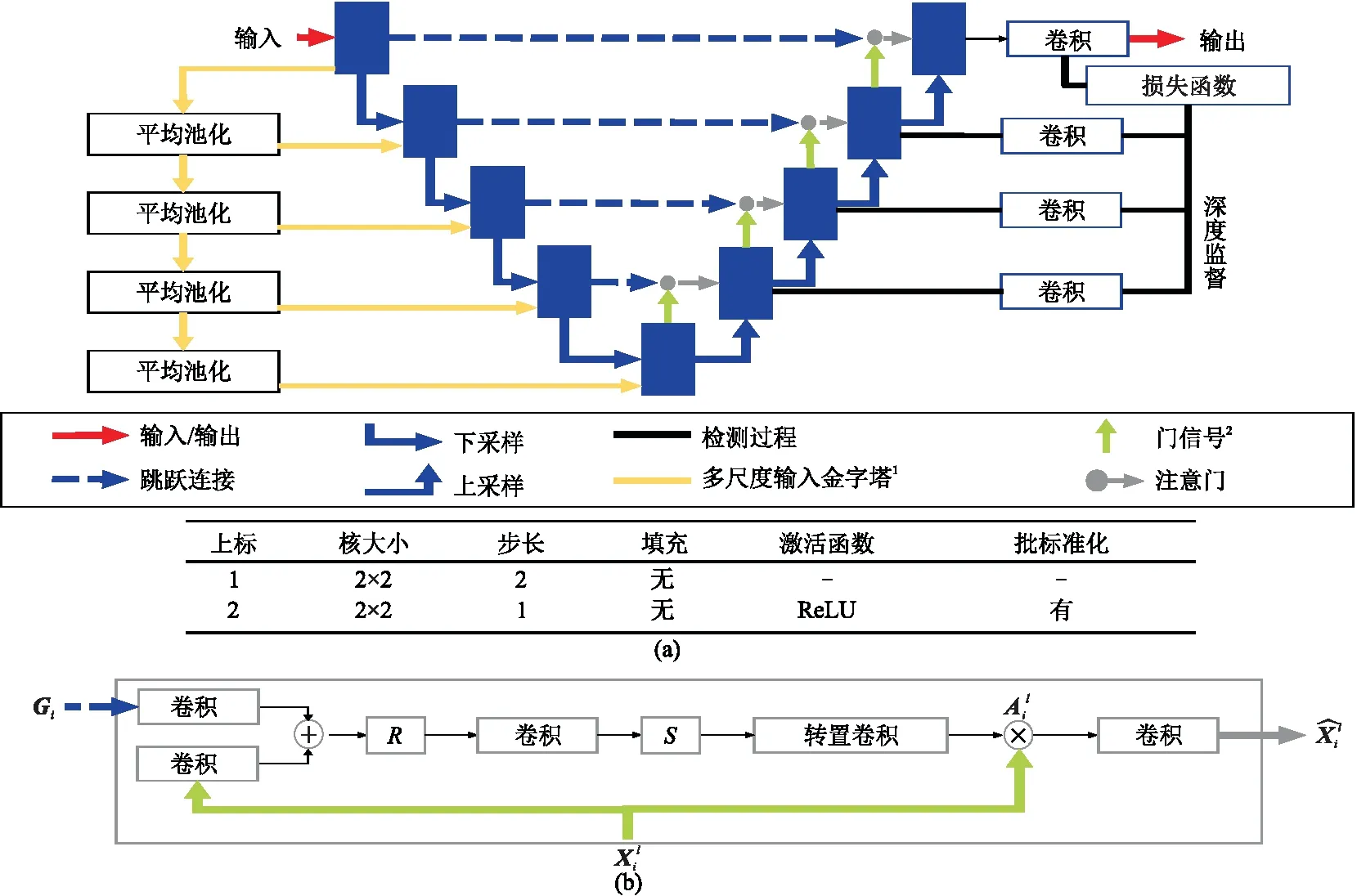
圖3 aU-Net 變體(a)aU-Net結構; (b)注意門R、S分別為ReLU、Sigmiod激活函數

表2 測試的超參數
(5)
和
(6)
式中:Rl,k是第k特征圖處LReLU的輸入;Rs,k是第k特征圖處SELU的輸入;Zk是第k維特征圖處的值;在默認情況下λl為0.001、λs約為1.0507、as約為1.6733,λs和as為固定值,使輸入均值為0、標準差為1。
LReLU是經典的ReLU的變體,它在計算導數時設置一個小的梯度,使梯度值不再停留在零上,因而避免了梯度消失問題;由于沒有指數運算,因而計算速度比ELU快;缺點是不能避免梯度爆炸問題,因為as值是不可學習的,它是預先定義的,取微分時變成線性函數,而ELU是非線性的。
另一方面,SELU允許網絡通過內部規范化特性實現更快收斂,輸出自動歸一化至零平均值和單位方差。此外,該網絡權重初始化需要正態(高斯)分布。它的另外一個優點是不存在梯度消失問題,可通過映射兩個連續層之間的均值(μ)和方差(υ)計算as和λs,并找到同時滿足兩個層的不動點(μ,υ)=(0,1)的解。
在常規的炮點道集中,樣本數量大于初至波樣本和噪聲樣本,因此目前初至拾取面臨的主要問題之一是樣本不平衡(Data Imbalance)。為了克服這一問題,本文測試了四種類型的損失函數:第一種是基于概率分布的二元交叉熵損失函數(Binary Cross Entropy,BCE);第二種是基于區域的損失函數,包括Dice、Tversky和Focal Tversky等;第三種是基于邊界的損失函數,例如Huber;第四種是基于合并的損失函數,例如將交叉熵與Dice合并為一個損失函數(二元交叉熵代價函數+Dice)。二元交叉熵代價函數+Dice[30]為
(7)
式中:Y是真實值;Z是預測結果;N是批大小(Batch Size)。
Dice系數(Dice Coefficient)[35]為預測值與實際值之間相似度的評價指標,局限性在于假陽性(False Positives,FP)與假陰性(False Negatives,FN)的權重相等,即精度高但召回率低。初至拾取是一個高度不平衡的問題,因此要求FN的權重高于FP以提高召回率。
Tversky指數[36]是平衡FP與FN的Dice系數的一個推廣,通過最小化,Tversky指數可變成損失函數,即
(8)
式中:β是假陰性的權重;ε是防止被零除的數值穩定因子。通過調整超參數α和β,可以控制假陽性與假陰性之間的權衡。較大的β值會提高模型的收斂性。當α=β=0.5時,Tversky函數簡化為Dice函數。
Focal Tversky函數[37]向前更進一步,引入了一個與標簽頻率成反比的權重,即
(9)
式中γ是焦點參數因子,可以控制容易分類的“數據”部分與難以分類的“噪聲”部分。該指數對分類良好的樣本的誤差進行加權,防止了大量分類錯誤的樣本對梯度的影響,進而緩解了類別不平衡。另外,當γ=1時,Focal Tversky函數簡化為Tversky函數。
Huber函數[38]是由可調參數δ確定的平均絕對誤差(Mean Absolute Error,MAE)與均方誤差(Mean Squared Error,MSE)之間的平衡,即
Lh(Y,Z)=
(10)
該損失函數用于變化較大的數據或有很少異常值的數據。當δ趨近0時,Huber函數接近MAE;當δ趨近∞時,Huber函數接近MSE。對于較大的異常值,建議使用較小的δ值,因為MSE會影響損失值。但是,當異常值很少時,建議使用較大的δ值,因為MSE會比MAE作用更大。
1.6 數據調節
球面擴散引起信號能量的變化、噪聲等從而導致地震數據中信號能量的不均衡,進而直接影響網絡訓練的性能(圖4a)。本文使用基于四分位距法(Inter Quartile Range,IQR)[39]的最小—最大標準化法和百分位限幅以提高振幅,利用傳統的2σ-3σ限幅以處理異常值。應用全局百分比歸一化方法,數據在該圖中位于標準差2σ范圍內的百分比為95.45%,而位于3σ范圍內的百分比為99.73%。
數據集的差異性可以通過范圍和標準差衡量,但是它們對異常值十分敏感。基于上下四分位數測量離散度,且在測量數據離散度時更能規避異常值的影響。通過IQR可以獲知第一個和第三個四分位數的間距,可顯示數據分布中間50%范圍的值。

圖4 不同方法對地震數據振幅處理效果對比(a)原始地震; (b)AGC; (c)RMS; (d)本文方法
雖然傳統的自動增益控制(Automatic Gain Control,AGC)是一種較有效的方法,但它會加強初至之前的噪聲,這對網絡正確識別和分類樣本而言是一個問題(圖4b),AGC使網絡更加難以區分噪聲與有效數據。同時,低頻噪聲可能會出現在初至波的前面,這可能導致分類錯誤。初至波應當盡可能清晰,以便網絡能從數據像素中識別出噪聲。
均方根(RMS)振幅歸一化方法能夠在一定程度上解決這個問題,但也存在一些不足(圖4c):①在較遠的地震道中,噪聲在整個地震道中都被增強,且在面波周圍區域的特征歸一化后能量較低;②3000ms以下深層的地震數據能量并沒有完全增強。
因此,為了在樣本之間獲得適當的平衡能量,本文將RMS歸一化法與最小—最大標準化法和IQR限幅相結合以截斷極值,并加上T平方補償解決球面發散問題(圖4d)。此方法的優勢在于均衡了整炮數據,從而網絡在訓練過程中可以更容易地正確識別和分類樣本。
在神經網絡中,Basheer等[40]建議在0.1~0.9內進行歸一化以避免飽和,這非常適合網絡內部的激活函數,并且不會導致學習率降低。此外,使用該范圍(0.1~0.9)進行分類任務時會得出錯誤的后驗概率估值,采用最小—最大標準化將其分布范圍限制在0~1內,計算公式為
(11)
式中:x表示總樣本;xi為待標準化的樣本;min(x)為采樣點中的最小值;max(x)為采樣點中的最大值。該方法的主要優點是對原始數據中的信息干擾小,尤其是在非高斯分布或標準差很小的時候。
均值和方差很容易受到異常值的影響。縮尾處理(Winsorization)或限幅(Clipping)可以有效地解決這個問題并能增強統計數據的準確性。振幅范圍越大,顯示的細節越少。因此,振幅直方圖上的四分位數、峰度和偏度有助于分析數據分布,并可適當地剪裁數據,從而避免可能影響歸一化的尖脈沖。
通常,在顯示地震剖面時,振幅限制是通過振幅范圍的2σ(95.45%)、3σ(99.73%)或99%的對稱以避免出現明顯的尖峰,如圖5所示。然而,數據通常是非對稱的,并且適合于計算用于限幅的各個四分位數,這在選擇限幅邊界時可以提供直接控制。
四分位距是一個統計度量,其中“中值50”位于數據之中,如圖5所示,其計算公式為
IQR=Q3-Q1
(12)
式中:Q3是75%以上數據的四分位數;Q1是25%以下數據的四分位數。限幅的原理是:給異常值分配較低的權重或修改權值使其接近集合中的其他值,最小化異常值的影響。在這種情況下,IQR修改Q1與Q3間隔之外的數據點值,不會修改Q1與Q3之間的數據點值。
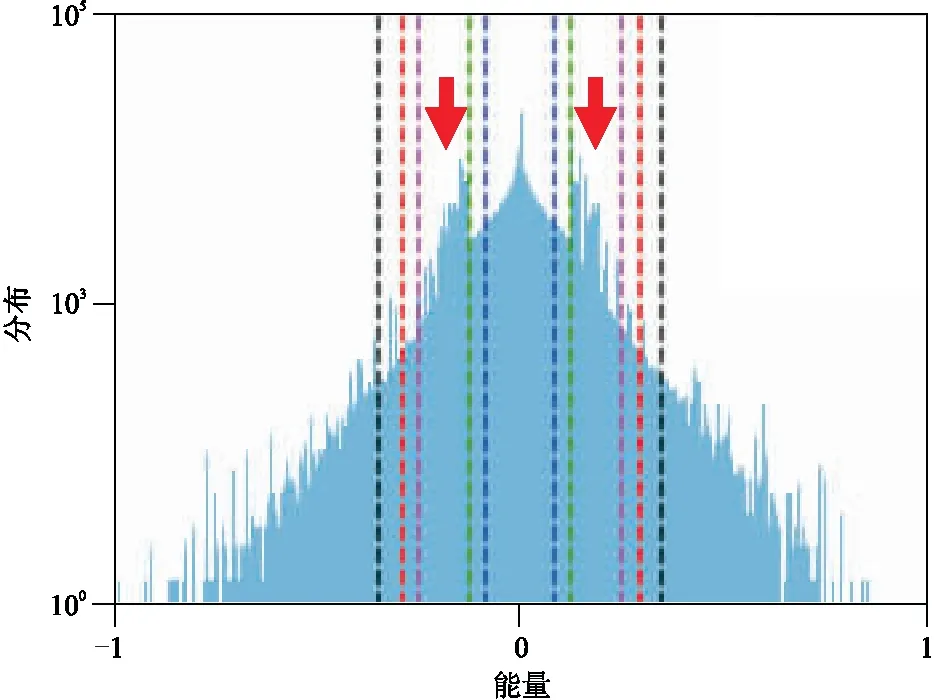
圖5 IQR與σ的對比圖 σ為綠線,2σ為紫線,IQR為藍線,99% 四分位數為紅線,1.5×IQR為黑線
綜上所述,本文設計振幅均衡處理流程如圖6所示。
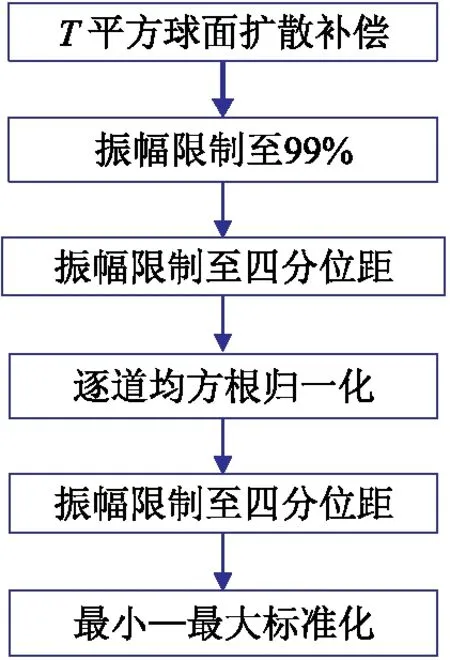
圖6 振幅均衡處理流程
1.7 速度約束
結合地球物理參數的約束,能間接地提高分割圖像的精度,使網絡預測更穩定。首先,為了降低不確定性,將高程靜校正應用于炮檢道集。盡管這些靜校正量并不完全準確,但它們減少了地震道之間的變化;然后,為了減少錯誤分類像素的影響,在初至附近增加視速度約束。錯誤分類像素與初至波上下的低信噪比相關,可以定義兩個視速度約束解決這個問題,一個是初至之上的高速約束解決噪聲誤分類;另一個是初至之下的低速約束解決有效信號誤分類。這些錯誤分類像素通常出現在遠離分割邊緣的地方。網絡可以處理很寬的邊界,且在近地表速度劇烈變化的區域也能獲得很高的精度。
圖7為視速度約束的初至拾取流程圖,它可以提高分割精度和初至的檢測精度。這種地球物理參數約束可通過糾正像素分類錯誤,解決分割異常問題以獲得更高的分辨率。根據區域內不太可能出現的速度值調整上、下限。本文中,速度約束邊界值分別為1650m/s和2100m/s。利用如下公式進行速度約束
(13)

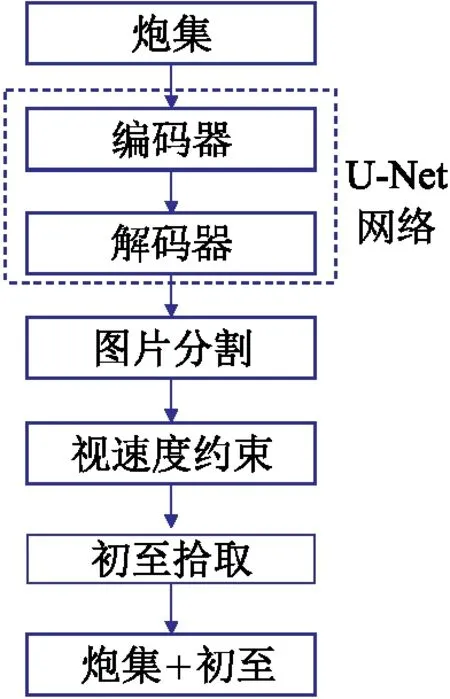
圖7 視速度約束的初至拾取流程圖
1.8 評價標準
本文采用Dice系數和Jaccard指數兩個經典的相似度評價指標評估預測結果。
Dice系數[35]表達式為
(14)
式中Np是樣本中的像素總數。
Jaccard指數[41]表達式為
(15)
2 數據測試
2.1 地震數據
本文所用數據為陸上二維地震資料,包含1000個炮集。道間距為25 m,最大炮檢距為6 km,每個炮集包含480道,采樣間隔為2 ms。振幅隨炮檢距的增加而衰減是初至拾取面臨的主要挑戰,但數據調節后,圖4d中顯示的振幅更均衡。此外,初至拾取僅限于近、中炮檢距(3 km左右)的范圍內,遠炮檢距將用于評估無訓練樣本區域的預測效果。
2.2 振幅調整
振幅調整用于減少數據分類中出現的問題,并平衡相同類別數據間的能量。圖4顯示了原始資料、AGC處理后、RMS處理后和振幅調整后的記錄。由圖可見,與原始資料、AGC處理后、RMS處理后資料相比,經振幅調整后的炮集能量更均衡。圖8顯示了振幅調整中每個步驟之后的能量直方圖,可見能量得到均衡,振幅異常得到明顯衰減(圖8f)。
2.3 標簽構建
將采樣尺寸設置為64×64像素,這相當于128ms的時間窗長和1600m的炮檢距范圍,保留噪聲樣本以增強網絡泛化性,而不是像Lu等[42]那樣刪除它們。
訓練標簽是利用人工拾取的初至通過二進制編碼(例如白色和黑色)填充像素而創建的。標簽是手動選取創建的,第一個分隔符上方的像素等于1,下方的像素等于0。然后,在樣品提取之后,根據如下公式將樣品與標簽配對
(16)

圖8 振幅處理過程中的能量直方圖(a)原始地震; (b)T平方球面發散修正; (c)振幅限制至99%; (d)振幅限制至IQR; (e)逐道均方根歸一化; (f)最小—最大標準化
式中:S是樣本;下標ij表示像素位置。全白(100%)像素填充的樣本被標記為噪聲,被20%到80%白色像素充填的樣本被標記為初至波;無白色像素(0%)的樣本被標記為有效數據。從理論上講,初至波呈高斯分布。在這種情況下,高斯分布的極值容易導致錯誤分類。因此,為了確保初至波能夠被識別,本文將像素數分布限制在20%~80%以保持穩定性。分布在0~20%和80%~100%數據被丟棄。如果像素比例太低(小于10%),則可能會將其錯誤分類為有效數據;如果比例過高(超過90%),則可能會誤判為噪聲。
2.4 網絡訓練
在訓練數據較少的情況下,可以通過數據增廣增加訓練數據量[43]。本文通過水平翻轉炮集以增加所提取樣本的數量,這類似于采集中從兩個方向放炮。這種方式既保留了觀測系統信息,又將樣本數增加了一倍。數據集被隨機地分為兩個部分,其中80%用于5倍交叉驗證(CV),20%用于測試。在訓練階段,5倍交叉驗證數據集(80%)分成五個部分,其中四個部分用于訓練,一個用于驗證。然后,計算平均的訓練和驗證誤差。最后,在對模型進行微調之后,使用測試數據集比較三個U-Net變體的結果。經過100 次迭代后實現了收斂。在一個內存(RAM)為4 GB的NVIDIA Quadro K4200中訓練時間為26h。最終的訓練準確率為99.83%,驗證準確率為99.79%。
2.5 超參數檢驗
本文僅測試、評估不同U-Net超參數(學習率、激活函數、損失函數、優化器、舍棄比率權重初始化等)大小以及不同U-Net超參數組合對初至拾取的影響。
學習率決定了神經網絡在反向傳播過程中每次更新權值的步長,它影響了收斂的速度(圖9)。由圖可見,學習率越大,預測值異常越大(圖9a),這是因為解決方案局限于局部最小值;設法減小左側的預測值異常(圖9b)時,右側的預測值異常仍然明顯;學習率越小,預測精度越高(圖9c),可見左側和右側預測值異常均明顯減小。
激活函數增加了模型的非線性。將函數ReLU與三種函數(LReLU,ELU,SELU)進行比較(圖10)以選擇合適的激活函數。與其他三個函數相比,ReLU具有更廣范圍的異常值(圖10a);LReLU的異常值較高 (圖10b);ELU縮小了異常值范圍(圖10c);SELU效果最佳,不僅減少了異常值,且提高了初至預測精度(圖10d)。
損失函數用于衡量學習過程中預測值與實際值之間的差異或偏差(圖11)。由圖可見,BCE、Dice和Tversky的函數組合對初至預測的結果相對較好,但有一些較大的異常值(圖11a)。損失函數的組合并非總能產生良好的效果,因為參數差異可能會導致意想不到的破壞作用。Dice和BCE函數組合使異常值減小,連續性降低(圖11b)。BCE盡管使初至預測異常值減小,但其連續性也受到影響 (圖11c)。Huber在以少量降低初至波連續性為代價的情況下,提供了減小異常值的最佳方案(圖11d)。
在超參數優化器類型中,隨機梯度下降(SGD)以其脫離局部最小值的速度和能力而聞名[44]。Adadelta根據歷史梯度衡量學習率,學習率隨著訓練過程自動逐漸減小[45]。自適應矩估計(Adam)使用隨機梯度下降估計歷史梯度的一階和二階矩[46]。Adamax是一種基于無窮范數的Adam變體,參數更新的計算要比Adam更簡單[46]。RMSprop通過調整更新參數時的步長以加快梯度下降。
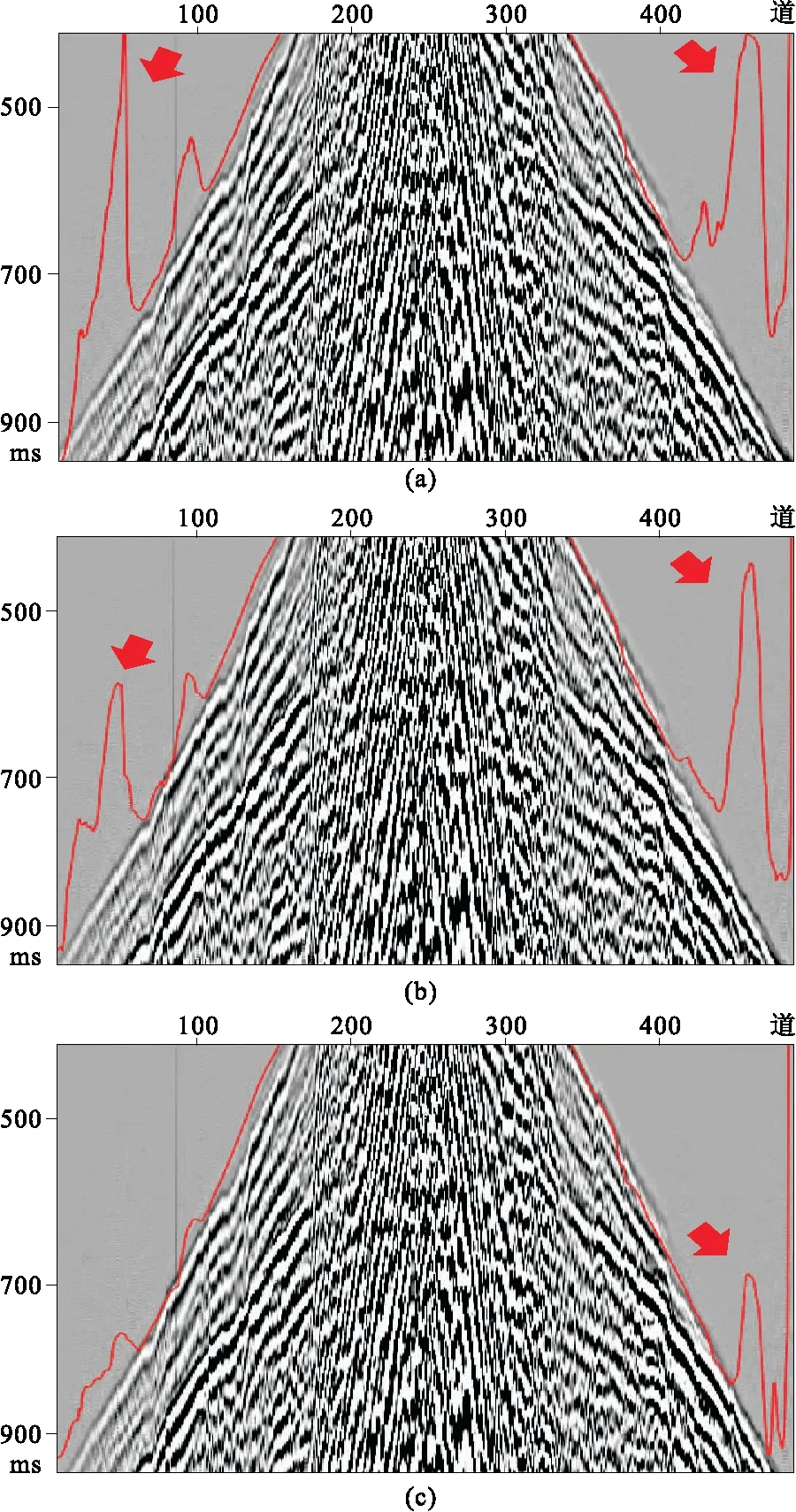
圖9 不同學習率對初至拾取的影響(a)10-4; (b)10-5; (c)10-6紅線為預測結果,箭頭所指尖峰為預測值異常。 圖10~圖15、圖17~圖21同
五種優化器對初至拾起的效果如圖12所示。SGD初至拾起的效果不好(圖12a),這可能與內在跳躍相關。與其他方法迭代次數相同時,SGD初至自動拾取效果均不好。相對于SGD而言,RMS-prop初至拾起的效果改善明顯,只是預測值異常高(圖12b)。Adadelta對預測值異常減小一半(圖12c)。Adam幾乎消除了預測值異常,但初至波出現了輕微的不連續(圖12d)。Adamax不僅消除預測值異常,而且保證了初至拾取的連續性(圖12e)。

圖10 不同激活函數對初至拾取的影響(a)ReLU; (b)LReLU; (c)ELU; (d)SELU
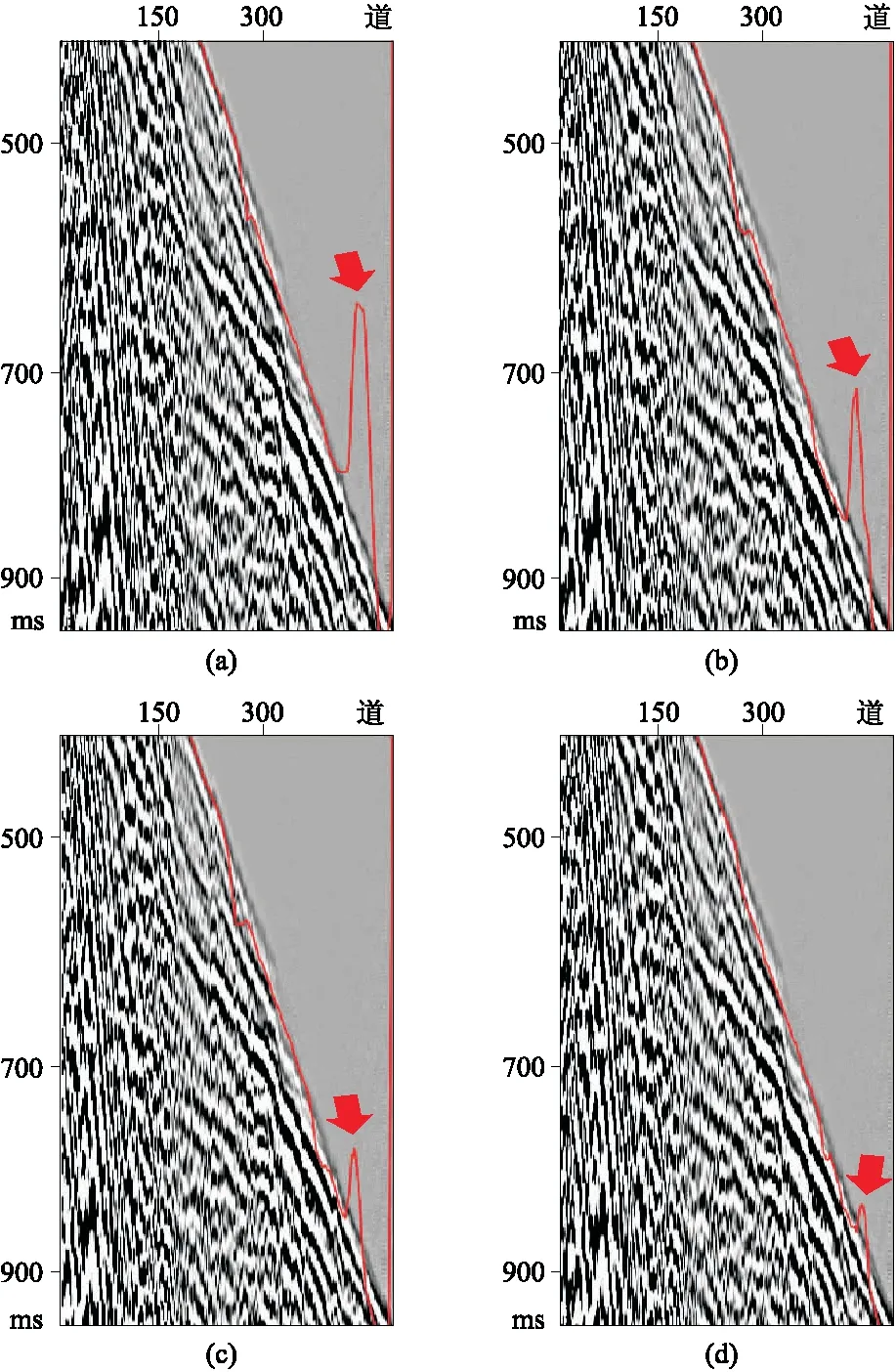
圖11 不同損失函數對初至拾取的影響(a)BCE+Dice+Tversky; (b)BCE+Dice; (c)BCE; (d)Huber

圖12 不同優化器對初至拾取的影響(a)SGD; (b)RMSprop; (c)Adadelta; (d)Adam; (e)Adamax
隨機舍棄一些神經元,可以緩解網絡過擬合,提高網絡的通用性。圖13中展示了舍棄比率對初至拾取的影響。當舍棄比率為0.05時(圖13d),效果最佳;舍棄比率為0.1和0.2時效果較好(圖13b和圖13c);當舍棄比率為0時,預測值異常大(圖13a),如果誤差過大,則需要較長的訓練時間才能收斂到解而得到滿意的拾取效果。
在訓練之前,初始化權重決定了網絡的初始狀態,可以避免梯度消失或爆炸問題的出現。為此,LeCun等[47]利用高斯分布函數得到初始化權重,再乘以輸入數據的平方根。Glorot等[48]和He等[49]改進了LeCun初始化方式。Glorot等[48]初始化更適用于具有Sigmoid的網絡層;He等[49]初始化更適用于具有ReLU的網絡層。由圖14可見,LeCun正態分布權重初始化對初至拾取的預測值異常在左右兩側均很大(圖14a);He正態分布權重初始化對初至拾取的預測值異常在左側幾乎完全消除,而右側的異常也減小(圖14b); Glorot正態分布權重初始化對初至拾取的預測值異常在左側已得到完全校正,而右側也減小(圖14c)。
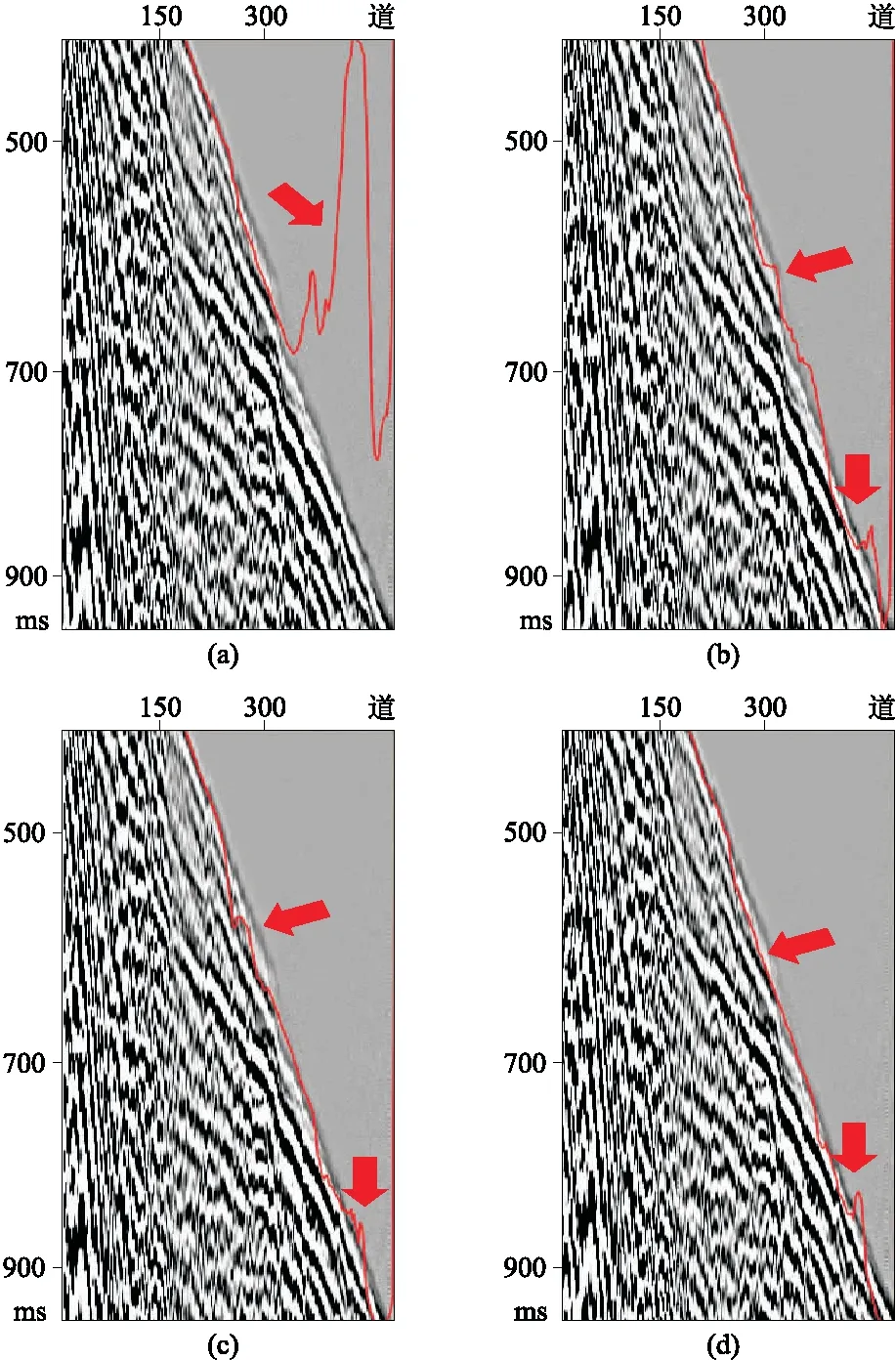
圖13 不同舍棄比率對初至拾取的影響(a)0; (b)0.20; (c)0.10; (d)0.05
對比不同網絡架構初至拾取的結果(圖15)。不建議體系結構之間共享相同的超參數,本文實驗選定損失函數Focal Tversky的參數為γ=2、α=0.3、β=0.7、ε=1;Huber損失函數的參數為δ=0.9,目的是將每個網絡優化到最佳狀態,每個架構的最佳超參數如表3所示。此外,為了提高實驗結果精度,aU-Net模型包含了一種深度監督和金字塔式訓練的變體。

圖14 不同權重初始化對初至拾取的影響(a)LeCun正態; (b)He正態; (c)Glorot正態
UNet++模型通過一系列嵌套和殘差密集連接,形成最復雜的網絡架構,拾取的初至連續性好,但沒能降低預測值異常(圖15a); aU-Net架構初至預測值異常有所減小,但初至不連續(圖15b),這很可能是由于結構簡單及參數的減少導致偏差的增大;伴有深度監督的aU-Net架構,網絡架構復雜性增加,可以降低預測值異常(圖15c); wU-Net架構初至拾起中,盡管預測值異常減小,但拾取的連續性受到了很大的影響(圖15d); U-Net架構拾起初至消除了預測值異常且保存了連續性,效果好(圖15e)。

表3 每個架構的最佳超參數
綜上所述,在某些情況下,在復雜模型與簡單模型之間尋找平衡,不實施新架構而集中更多精力優化超參數時,也有可能獲得令人滿意的結果。
與傳統的BCE相比,U-Net的優勢在于損失函數Huber更關注邊界。與傳統的ReLU和Adamax優化器相比,損失函數SELU可對網絡進行歸一化并提高準確性,這是對傳統的Adam優化器的改進。
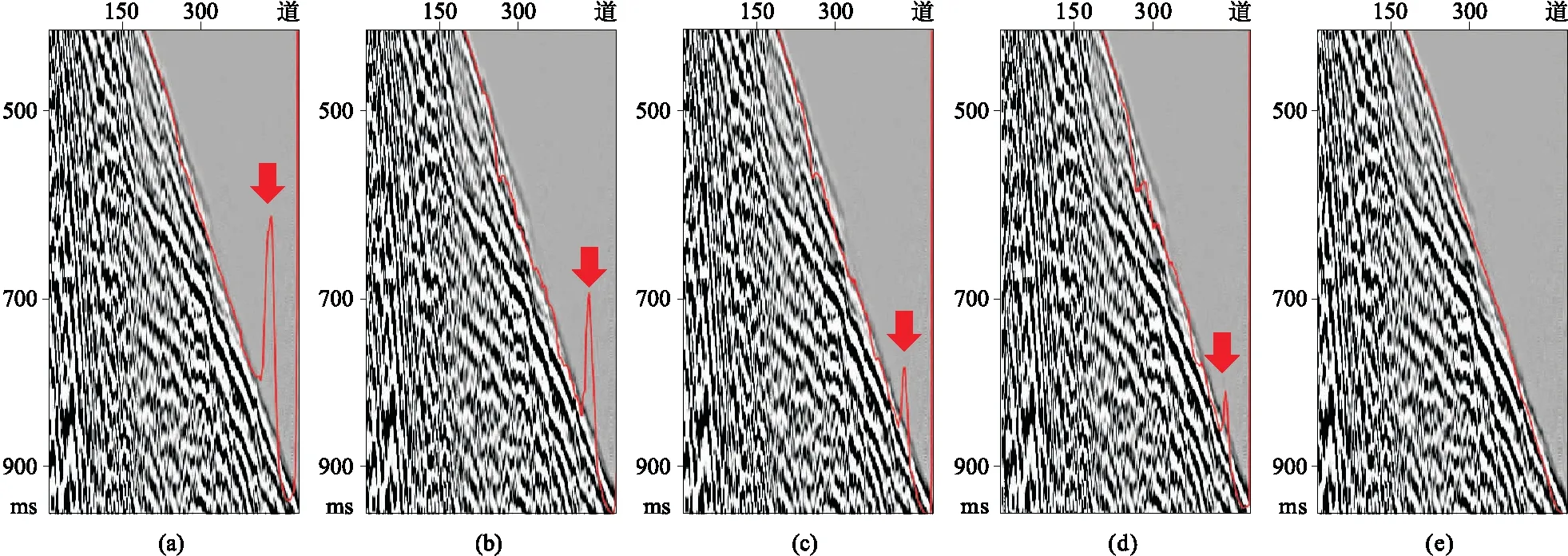
圖15 不同網絡架構初至拾取的結果對比(a)UNet++; (b)aU-Net; (c)aU-Net+DP; (d)wU-Net; (e)U-Net
3 應用效果
3.1 性能評價
計算速度約束前、后分割圖像的準確度、查全率、Dice系數和Jaccard指數(表4,值越大意味著性能越好),結果表明,本文方法提高了初至波預測的精度。
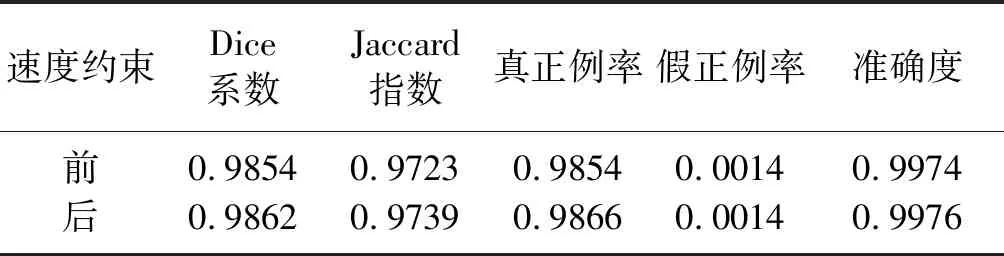
表4 速度約束前、后的得分比較
應用接受者操作特性 (Receiver Operating Characteristic,ROC)[50]曲線評估最終預測結果。圖16顯示了速度約束前、后每道分割結果的ROC曲線。由圖可見,平均真正例率(True Positive Rate,TPR)或查全率從0.9854提高到0.9866;而假正例率(False Positive Rate,FPR)仍保持在0.0014。TPR是噪聲樣本的正確分類,而FPR是數據樣本的正確分類。速度約束后的結果更接近理想情況,即FPR=0、TPR=1。這說明速度約束可以改善分類效果。具體來說,在低信噪比的區域(例如遠炮檢距區域)中,像素無法準確區分有效數據與噪聲數據,噪聲數據降低了所預測初至波時間的精度,而視速度約束可以修改這些像素,從而提高拾取精度。

圖16 速度約束前(紅點)后(藍點)每道分割結果
3.2 初至拾取結果
圖17顯示了本文方法所預測的初至波。結果表明,自動拾取的初至在近炮檢距連續性好,中炮檢距也準確,且在低能區(白色箭頭)的預測值異常點很少。圖17a中藍色箭頭指示了比原始初至拾取結果精度更高的網絡區域;圖17b顯示了拾取的初至與地面起伏存在良好的對應關系(藍色箭頭所示);由圖17c可見,在先前標記信息丟失的中炮距檢區域初至拾取效果較好,這表明在沒有初至波信息的情況下網絡能夠預測初至;圖17d表明,在能量較弱的區域預測精度會降低(白色箭頭所示),并且在末端地震道中拾取結果欠穩定(紅色箭頭所指),并出現在所有采樣點中。這個普遍存在的問題可能是由于計算誤差引起的,而不是網絡預測中所固有的。
對比并定量分析預測結果與人工拾取的結果,如圖18所示。由圖可見,某一單炮負炮檢距情況下絕對平均誤差為2.5088ms (圖18b);另一單炮正負炮檢距情況下絕對平均誤差為4.0812ms(圖18d),大于4個樣點值。同時,也可以看到在信噪比低的區域預測誤差增大。
圖19顯示的是參與訓練的多炮人工拾取初至與本文方法預測結果的對比,平均誤差為8.8993 ms,小于5個樣點值。
之前所有的訓練樣本都來自Xline方向,因此選取了一條與訓練樣本垂直的測線試驗。圖20顯示在正炮檢距和正負炮檢距本文方法自動拾取初至的預測值與人工拾取的結果吻合都很好。正炮檢距下預測結果和人工拾取一致,絕對平均誤差為1.9855ms (圖20b);在正負炮檢距在沒有人工拾取的情況下,本文方法仍然能夠預測出初至結果,絕對平均誤差為6.8889ms (圖20d)。
應用本文方法對另一個工區的數據進行試驗,未重新訓練,而是直接利用以前的訓練結果。由于遠地震道的初至信噪比很低,自動拾取誤差大。單炮記錄1預測結果與人工拾取吻合度很高,絕對平均誤差為2.9785ms (圖21b);單炮記錄2絕對平均誤差為13.1448ms (圖21d)。盡管信噪比不高,但是訓練網絡仍能取得令人滿意的預測結果。
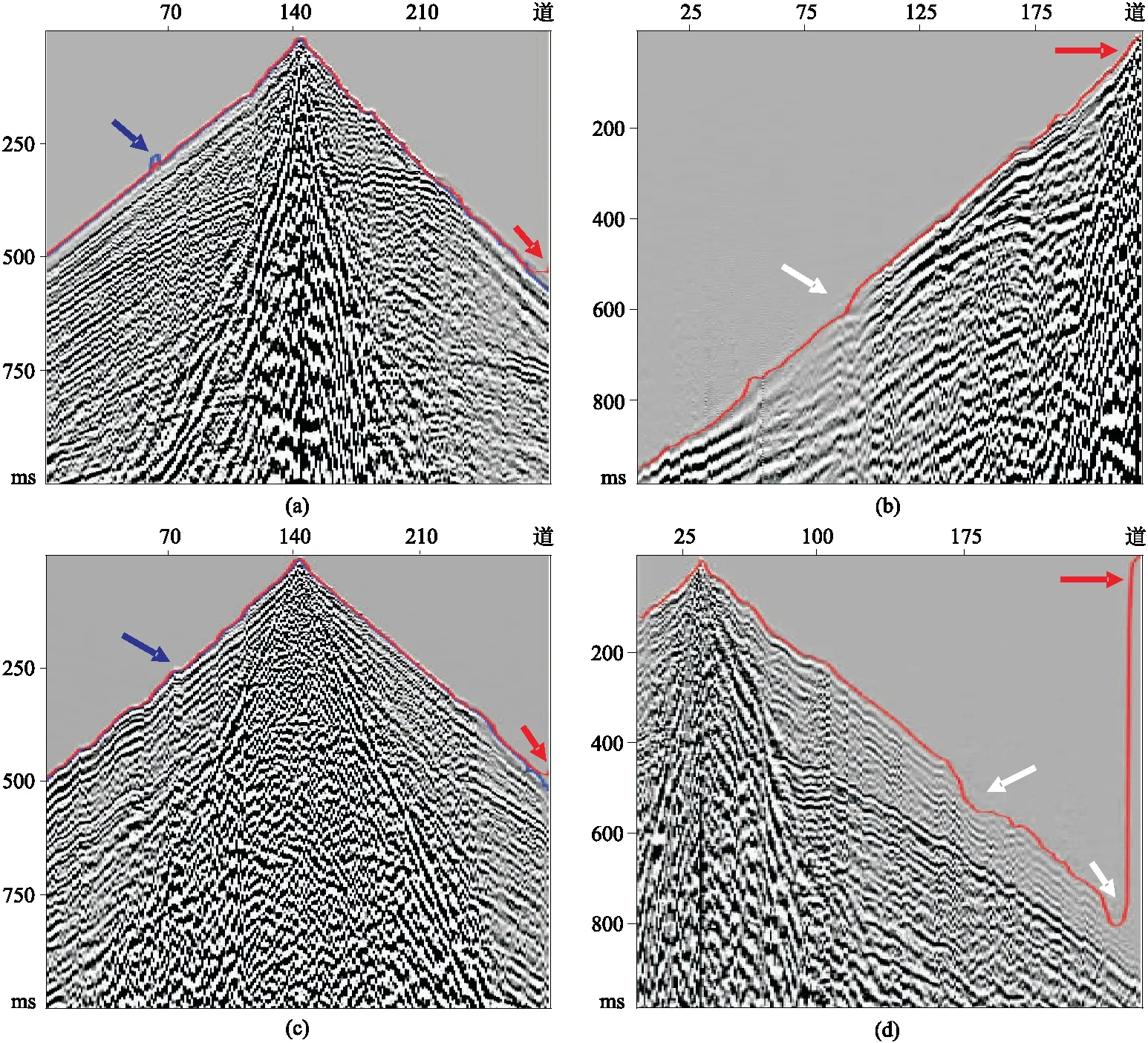
圖17 不同炮檢距初至自動拾取結果(a)和(c)為近炮檢距; (b)和(d)為近中炮檢距 藍線為手動拾取,紅線為本文方法自動拾取,圖18~圖21同

圖18 訓練數據的人工拾取初至和本文方法預測結果差異(a)負炮檢距; (b)負炮檢距的誤差; (c)正負炮檢距; (d)正負炮檢距的誤差
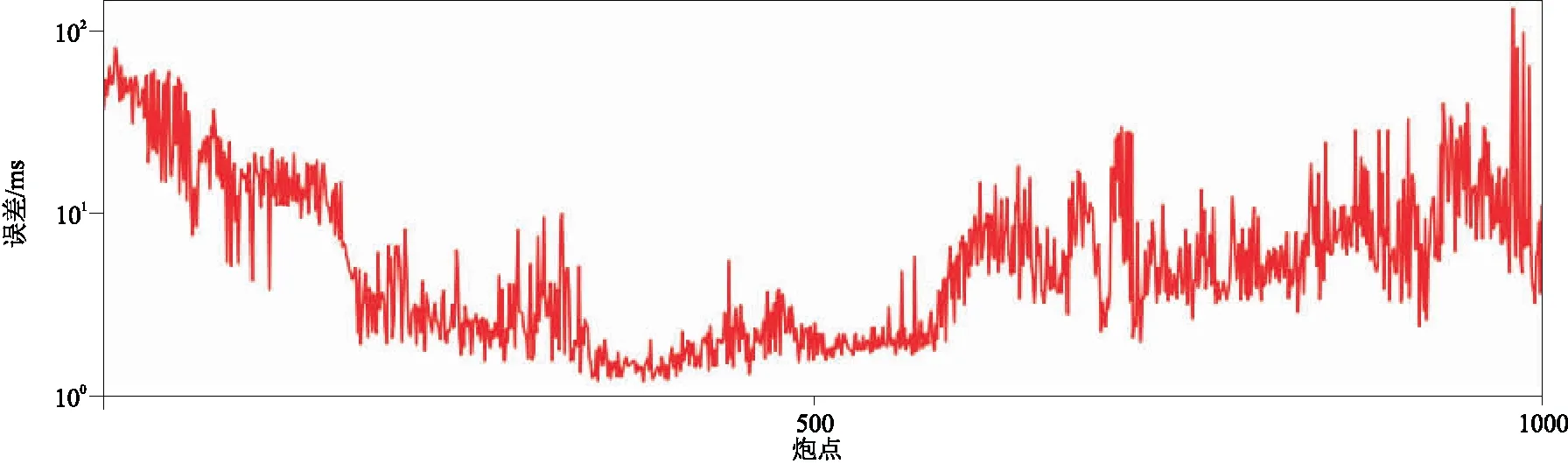
圖19 參與訓練的多炮人工拾取初至和本文方法預測結果差異

圖20 對未參與訓練的數據進行初至預測(a)正炮檢距; (b)正炮檢距的誤差; (c)正負炮檢距; (d)正負炮檢距的誤差
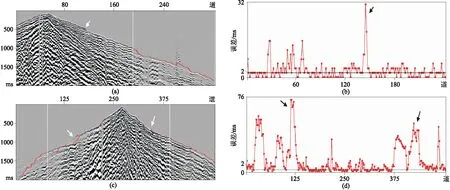
圖21 對未參與訓練的另一工區的數據進行初至預測(a)單炮記錄1; (b)單炮記錄1的拾取誤差; (c)單炮記錄2; (d)單炮記錄2的拾取誤差
4 結論
本文研究了基于U-Net網絡和視速度約束的地震波初至自動拾取方法,并進行了參數試驗和實際資料初至拾取試驗,取得的主要結論為:
(1)基于速度約束的方法提高了分割圖像中邊界識別精度,這些邊界指示了初至波的時間;
(2)最小—最大歸一化和四分位距限幅通過平衡樣本能量對網絡訓練性能有積極影響,提高了分類精度;
(3)該方法在低信噪地震資料中進行應用,預測值異常較小。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
