基于深度神經(jīng)網(wǎng)絡(luò)的配資網(wǎng)站識(shí)別研究
2021-06-03 02:23:02王叢雙
何 穎, 楊 頻, 王叢雙, 湯 娟
(四川大學(xué)網(wǎng)絡(luò)空間安全學(xué)院, 成都 610207)
1 引 言
近年來(lái),隨著科技的迅速發(fā)展,互聯(lián)網(wǎng)已經(jīng)成為人們生活中不可或缺的一部分. 中國(guó)互聯(lián)網(wǎng)絡(luò)信息中心在2020年的數(shù)據(jù)統(tǒng)計(jì)顯示,我國(guó)網(wǎng)民規(guī)模突破9億,網(wǎng)站數(shù)量達(dá)497萬(wàn)個(gè)[1]. 然而,在互聯(lián)網(wǎng)為人們的生活帶來(lái)巨大便利的同時(shí),網(wǎng)絡(luò)的負(fù)面影響也逐漸顯現(xiàn). 網(wǎng)絡(luò)違法信息開(kāi)始出現(xiàn)在互聯(lián)網(wǎng)的各個(gè)角落,其中通過(guò)提供非法配資來(lái)賺取盈利的網(wǎng)站對(duì)網(wǎng)民群體造成了嚴(yán)重的影響,威脅到了網(wǎng)絡(luò)用戶的財(cái)產(chǎn)安全.
配資是指根據(jù)資金需求方與配資公司簽訂的協(xié)議,在資金需求方原有資金的基礎(chǔ)上,配資公司以原始資金作為配資基數(shù)按照一定比例另行提供新的資金供資金需求方使用. 配資公司要求資金需求方必須使用其公司的賬戶進(jìn)行操作,若選擇使用自己的賬戶,則需要抵押物,如車、房等. 配資公司會(huì)隨時(shí)監(jiān)督賬戶的虧損情況,當(dāng)虧損達(dá)到原有資金的一定金額并且持續(xù)虧損時(shí),配資公司會(huì)強(qiáng)行平倉(cāng). 大量民間配資公司利用互聯(lián)網(wǎng)信息技術(shù)搭建互聯(lián)網(wǎng)配資平臺(tái),而這些配資網(wǎng)站并不具備經(jīng)營(yíng)證券業(yè)務(wù)資質(zhì),其在本質(zhì)上就不被法律允許,這種不受監(jiān)管的配資帶來(lái)的爆倉(cāng)風(fēng)險(xiǎn)和資金安全風(fēng)險(xiǎn)不容忽視. 而大量配資網(wǎng)站往往裹上投資咨詢、網(wǎng)絡(luò)信息和商貿(mào)服務(wù)的外衣,有著極強(qiáng)的迷惑性. 因此,為了能夠?qū)ε滟Y網(wǎng)站進(jìn)行監(jiān)管,迫切需要能夠準(zhǔn)確檢測(cè)出配資網(wǎng)站的方法.關(guān)于以網(wǎng)絡(luò)釣魚(yú)、網(wǎng)絡(luò)色情為代表的以提供非法內(nèi)容為主的網(wǎng)站識(shí)別工作已經(jīng)取得了一定的進(jìn)展,但是對(duì)于配資網(wǎng)站識(shí)別的相關(guān)研究較少. 針對(duì)惡意網(wǎng)站識(shí)別問(wèn)題,研究者提出了很多解決方案和識(shí)別技術(shù),主要有基于黑名單的識(shí)別方法,基于網(wǎng)站URL異常特征的識(shí)別方法和基于網(wǎng)站頁(yè)面內(nèi)容的識(shí)別方法.
基于黑名單的識(shí)別方法是用蜜罐技術(shù)、人工檢查等手段預(yù)先構(gòu)建一份包含網(wǎng)站URL或關(guān)鍵詞信息的列表,通過(guò)黑名單技術(shù)可準(zhǔn)確識(shí)別已被確認(rèn)的釣魚(yú)網(wǎng)站或其他類型網(wǎng)站. 以PhishTank[2]為例,人們可自愿提交和共享釣魚(yú)網(wǎng)站網(wǎng)址,依據(jù)其提供的列表可以主動(dòng)過(guò)濾釣魚(yú)網(wǎng)址. 這種方法誤報(bào)率低,但是無(wú)法準(zhǔn)確識(shí)別新出現(xiàn)的釣魚(yú)網(wǎng)站,維護(hù)和更新完整的黑名單列表是十分困難的.
基于網(wǎng)站URL異常特征的識(shí)別方法是用分析URL特征來(lái)構(gòu)建網(wǎng)站識(shí)別模型. Abdelhamid[3]根據(jù)URL特征,提出一種基于多標(biāo)簽規(guī)則的分類算法來(lái)識(shí)別釣魚(yú)網(wǎng)站,能夠從單個(gè)數(shù)據(jù)集生成具有多個(gè)類標(biāo)簽的規(guī)則. Moghimi等[4]提出基于規(guī)則的使用兩種新的特征集的釣魚(yú)識(shí)別方法,使用字符串近似匹配算法來(lái)確定特征集中的頁(yè)面內(nèi)容和URL之間的關(guān)系. 方勇等[5]使用LSTM算法來(lái)挖掘釣魚(yú)網(wǎng)址字符序列的潛在特征,提出基于LSTM與隨機(jī)森林的混合框架模型提高了釣魚(yú)網(wǎng)站的識(shí)別效率和檢測(cè)準(zhǔn)確率,能夠快速識(shí)別海量釣魚(yú)網(wǎng)站攻擊. 但是網(wǎng)站URL特征有限且容易模仿,這在很大程度上限制特定網(wǎng)站識(shí)別的實(shí)際效果.
基于網(wǎng)站頁(yè)面內(nèi)容的識(shí)別方法是用挖掘標(biāo)題、圖片、關(guān)鍵字等網(wǎng)頁(yè)內(nèi)容中的特征進(jìn)行識(shí)別. Mao等[6]指出網(wǎng)頁(yè)之間的相似性是檢測(cè)釣魚(yú)網(wǎng)站的一個(gè)重要指標(biāo),提出一種基于網(wǎng)頁(yè)之間視覺(jué)外觀相似度來(lái)量化網(wǎng)頁(yè)可疑度評(píng)級(jí)的算法,使用層疊樣式表作為基礎(chǔ)來(lái)量化每個(gè)頁(yè)面元素的視覺(jué)相似性,并用真實(shí)的釣魚(yú)網(wǎng)站樣本證明了它的有效性. Zhang等[7]從文本內(nèi)容和視覺(jué)內(nèi)容的角度檢測(cè)釣魚(yú)網(wǎng)站,利用貝葉斯理論推導(dǎo)出的概率模型,有效地估計(jì)文本分類器和圖像分類器的匹配閾值,可直接合并不同分類器產(chǎn)生的多個(gè)結(jié)果. Jain等[8]綜合分析了基于視覺(jué)相似性的釣魚(yú)檢測(cè)技術(shù),其利用文本內(nèi)容、文本格式、HTML標(biāo)簽、層疊樣式表和圖像等特征集來(lái)做出判斷,能夠有效應(yīng)對(duì)釣魚(yú)攻擊. 這些工作的關(guān)鍵在于特征的選取,不同特征的識(shí)別效果存在一定的差異. 另外,沙泓州等[9]在研究中指出,移動(dòng)互聯(lián)網(wǎng)的繁榮和社交網(wǎng)站的興起使得網(wǎng)頁(yè)的傳播途徑逐漸多元化,可以通過(guò)掃描“二維碼”和社交網(wǎng)站的形式傳播. 新的應(yīng)用場(chǎng)景的出現(xiàn),豐富了特征選擇的范圍,也對(duì)特定網(wǎng)站識(shí)別時(shí)選擇的特征提出了更高的要求. 同時(shí),網(wǎng)站規(guī)模的迅速擴(kuò)大帶來(lái)了海量新特征,為了保證識(shí)別效率,需要選擇有助于識(shí)別特定網(wǎng)站的重要特征變量.
近年來(lái)深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)[10]、圖像處理[11]、自然語(yǔ)言處理[12]和大數(shù)據(jù)分析[13-14]等許多領(lǐng)域的應(yīng)用中取得了不錯(cuò)的表現(xiàn). 深度神經(jīng)網(wǎng)絡(luò)(Deep Neural Networks, DNN)作為一種深度學(xué)習(xí)架構(gòu)在分類問(wèn)題方面[15-16]非常成功. 在上述研究成果的基礎(chǔ)上,本文從5個(gè)不同的維度選取能夠有效識(shí)別配資網(wǎng)站的重要特征,包括域名特征、搜索引擎收錄特征、HTML標(biāo)簽特征、圖片特征和文本特征,較全面地體現(xiàn)了配資網(wǎng)站和其他類別網(wǎng)站的本質(zhì)區(qū)別,提出一種基于深度神經(jīng)網(wǎng)絡(luò)的配資網(wǎng)站識(shí)別模型.
2 基于深度神經(jīng)網(wǎng)絡(luò)的配資網(wǎng)站識(shí)別模型
2.1 模型框架
本文提出的配資網(wǎng)站識(shí)別模型如圖1. 該模型主要包含三個(gè)部分:數(shù)據(jù)采集模塊、特征處理模塊和識(shí)別模型模塊. 首先,我們通過(guò)動(dòng)態(tài)爬蟲(chóng)技術(shù)和文本處理手段采集原始數(shù)據(jù),進(jìn)行格式化處理后,經(jīng)特征提取器提取多維度特征數(shù)據(jù);然后,經(jīng)過(guò)特征向量化,將字符串等文本特征轉(zhuǎn)化為特征向量;最后,我們將實(shí)驗(yàn)數(shù)據(jù)隨機(jī)抽樣分成兩組,使用深度神經(jīng)網(wǎng)絡(luò)算法,利用訓(xùn)練集建立配資網(wǎng)站識(shí)別模型,再利用測(cè)試集對(duì)該模型的識(shí)別性能進(jìn)行驗(yàn)證.
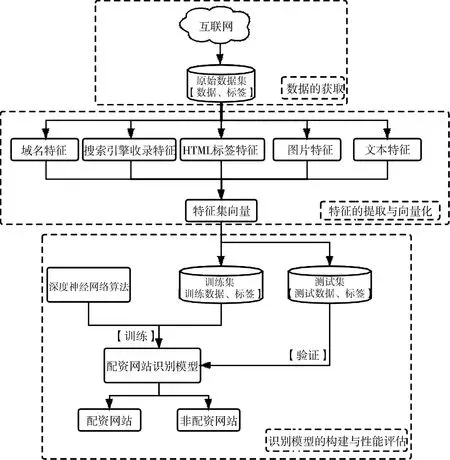
圖1 識(shí)別模型構(gòu)建及評(píng)估流程Fig.1 Process of recognition model construction and evaluation
2.2 特征選取
為了提高配資網(wǎng)站識(shí)別的準(zhǔn)確性和可靠性,選取的特征需要能夠充分體現(xiàn)配資網(wǎng)站的特征,并能夠有效區(qū)分配資網(wǎng)站和其他類型網(wǎng)站. 本文參考傳統(tǒng)惡意網(wǎng)站識(shí)別特征,在對(duì)大量配資類網(wǎng)站樣本分析的基礎(chǔ)上,從多個(gè)維度選取了共60個(gè)特征,這些特征可歸納為域名特征、搜索引擎收錄特征、HTML標(biāo)簽特征、圖片特征和文本特征等5大類,具體內(nèi)容如圖2所示.
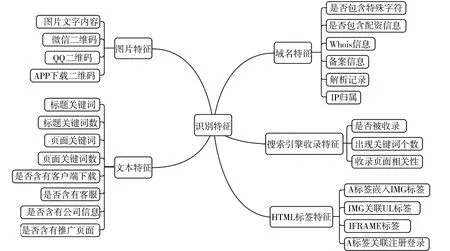
圖2 識(shí)別特征Fig.2 Identification features
(1) 域名特征.基于域名的特征可以分類為詞匯特性和域名屬性特性.
詞匯特性是域名本身的文本屬性. 域名由于其便于記憶的特點(diǎn),成為使用者使用網(wǎng)站的代名詞,運(yùn)營(yíng)者為了促進(jìn)網(wǎng)站傳播,加深使用者記憶,會(huì)使用與網(wǎng)站內(nèi)容相關(guān)的短詞匯,如PZ、Peizi等字符. 域名中的短文本詞匯是反映網(wǎng)站類型的一個(gè)重要體現(xiàn).
域名屬性信息包括域名的Whois信息、備案信息、解析記錄、IP歸屬等,這些信息可以反映目標(biāo)域名的背景情況,Whois信息有域名的注冊(cè)時(shí)間、注冊(cè)人等,備案信息有備案網(wǎng)址名稱、備案主體信息等,解析記錄有目標(biāo)域名變更情況,IP地址的歸屬等. 單獨(dú)來(lái)看這些信息并不能作為有效區(qū)分配資網(wǎng)站和非配資網(wǎng)站的特征,但將這些特征與其他特征融入在一起后,能有效地反映域名的背景狀況. 除此之外還有域名解析記錄在一定時(shí)間范圍的變化頻率,實(shí)驗(yàn)中選取一年(域名的一般購(gòu)買周期),獲取該一年內(nèi)域名解析IP的變更次數(shù),以及這些IP地址是否屬于CDN類型IP或IDC類型IP等.
(2) 搜索引擎收錄特征.搜索引擎是一種收錄互聯(lián)網(wǎng)各種類型網(wǎng)站網(wǎng)頁(yè)內(nèi)容,給用戶提供海量?jī)?nèi)容準(zhǔn)確檢索服務(wù)的工具. 借助搜索引擎,可以使用關(guān)鍵詞檢索出大量與關(guān)鍵詞相關(guān)的內(nèi)容. 為了利于網(wǎng)站的傳播,增加被搜索引擎收錄的內(nèi)容,存在一種搜索引擎優(yōu)化技術(shù)(Search Engine Optimization, SEO),來(lái)提高某一個(gè)網(wǎng)站被網(wǎng)絡(luò)收錄的速度和關(guān)鍵詞數(shù)量. 配資網(wǎng)站需要通過(guò)推廣來(lái)增加用戶量,一般會(huì)使用這種技術(shù)手段增加收錄關(guān)鍵詞量. 因此,指定域名網(wǎng)站的搜索引擎收錄情況,是否被搜索引擎收錄配資等關(guān)鍵詞,是配資網(wǎng)站的重要特性之一.
(3) HTML標(biāo)簽特征.每一個(gè)網(wǎng)站都是由HTML、Javascript和CSS共同組建而成,用戶瀏覽網(wǎng)頁(yè),是瀏覽器對(duì)這些代碼渲染后的效果. 通過(guò)對(duì)配資網(wǎng)站的大量分析,本文發(fā)現(xiàn)配資類網(wǎng)站在網(wǎng)頁(yè)結(jié)構(gòu)上具有眾多特有特征:(a) A標(biāo)簽嵌入IMG標(biāo)簽. 配資網(wǎng)站常使用在A標(biāo)簽中嵌入IMG標(biāo)簽來(lái)使用戶點(diǎn)擊圖片以達(dá)到跳轉(zhuǎn)的目的. 配資網(wǎng)站會(huì)在網(wǎng)站首頁(yè)添加大量虛假的友情鏈接,包括銀行等,使用這種技術(shù)手段來(lái)欺騙用戶,并且A標(biāo)簽的鏈接多為站外鏈接;(b) 導(dǎo)航欄IMG標(biāo)簽. 眾多配資網(wǎng)站會(huì)在導(dǎo)航欄左側(cè)使用圖片標(biāo)簽的形式展示配資站點(diǎn)的名稱,右側(cè)則以u(píng)l/li標(biāo)簽結(jié)合A標(biāo)簽的形式給出導(dǎo)航菜單選項(xiàng),A標(biāo)簽內(nèi)容為站內(nèi)鏈接;(c) Iframe標(biāo)簽. 配資網(wǎng)站為了簡(jiǎn)化部署復(fù)雜度,達(dá)到快速建站,快速遷移的目的,會(huì)使用iframe標(biāo)簽嵌入主站內(nèi)容,從而實(shí)現(xiàn)只需要修改主站內(nèi)容,其他網(wǎng)站就會(huì)同步更改;(d) 基于A標(biāo)簽的注冊(cè)、登錄跳轉(zhuǎn). 配資網(wǎng)站為用戶提供了復(fù)雜的交易功能,需要涉及用戶注冊(cè)、開(kāi)戶等,因此基于A標(biāo)簽的注冊(cè)跳轉(zhuǎn)也被應(yīng)用于模型中.
(4) 圖片特征.非法配資網(wǎng)頁(yè)的傳播方式隨著新的應(yīng)用場(chǎng)景的出現(xiàn)逐漸多元化. 二維碼作為一種全新的信息傳遞、識(shí)別和存儲(chǔ)技術(shù),能夠快速傳播網(wǎng)頁(yè). 配資網(wǎng)站在設(shè)計(jì)網(wǎng)頁(yè)頁(yè)面時(shí),往往將二維碼放置在醒目的位置,吸引用戶去掃描,以達(dá)到推廣網(wǎng)頁(yè)的目的. 同時(shí),隨著即使通訊工具的廣泛使用,配資公司還會(huì)利用微信或QQ二維碼、APP下載二維碼來(lái)宣傳配資資訊,錯(cuò)誤地引導(dǎo)投資者. 因此,檢查網(wǎng)頁(yè)中是否包含二維碼圖片是識(shí)別配資網(wǎng)站的有效方法. 配資網(wǎng)站中的虛假宣傳圖片、配資內(nèi)容宣傳圖片也是本模型關(guān)注的重點(diǎn),通過(guò)提取配資網(wǎng)站中的圖片數(shù)據(jù),并使用文字識(shí)別工具識(shí)別圖片中的文字信息,基于文本關(guān)鍵詞來(lái)判斷文本內(nèi)容是否與配資相關(guān).
(5) 文本特征.為了實(shí)現(xiàn)擴(kuò)大宣傳、增強(qiáng)網(wǎng)站影響力的目的,配資網(wǎng)站會(huì)發(fā)布大量與配資相關(guān)的內(nèi)容,其文本特征與正常網(wǎng)站存在較大差異,這是無(wú)法偽裝的,這些差異恰恰可以作為判斷該網(wǎng)站是否是配資網(wǎng)站的重要依據(jù).
在多數(shù)情況下,和網(wǎng)站頁(yè)面中其它位置的文本信息相比,網(wǎng)站標(biāo)題的文本信息能夠更好地概括網(wǎng)站的主題內(nèi)容. 配資網(wǎng)站往往會(huì)通過(guò)在標(biāo)題中使用“配資”、“操盤”、“股票”、“平臺(tái)”等關(guān)鍵詞來(lái)吸引和欺騙用戶. 除標(biāo)題外,頁(yè)面中的文本信息經(jīng)常含有“配資”、“杠桿”、“策略”、“實(shí)盤”、“開(kāi)戶”、“操盤”、“新手”和“交易”等關(guān)鍵詞. 因此,是否出現(xiàn)以上關(guān)鍵詞,統(tǒng)計(jì)關(guān)鍵詞出現(xiàn)的個(gè)數(shù),以及在眾多關(guān)鍵詞中出現(xiàn)的幾個(gè)組合關(guān)鍵詞的個(gè)數(shù)等特征將用來(lái)判斷網(wǎng)站是否為配資網(wǎng)站.
同時(shí),頁(yè)面內(nèi)容中是否包含“客戶端下載”、“客服”、“公司信息”、“推廣頁(yè)面”和“關(guān)于我們”,這些文本內(nèi)容也是能有效區(qū)分配資網(wǎng)站和非配資網(wǎng)站的文本特征.
2.3 檢測(cè)模型算法
人工神經(jīng)網(wǎng)絡(luò)雖然已經(jīng)被研究了70多年[17-18],但隨著一些研究人員的開(kāi)創(chuàng)性工作,它們開(kāi)始被廣泛應(yīng)用在解決數(shù)據(jù)挖掘問(wèn)題上. 在擁有足夠的計(jì)算資源和訓(xùn)練數(shù)據(jù)的情況下,多層人工神經(jīng)結(jié)構(gòu)可以學(xué)習(xí)復(fù)雜的非線性函數(shù)映射. 對(duì)于分類任務(wù),更高層次的表示放大了輸入的各個(gè)方面,這些方面對(duì)于識(shí)別和抑制無(wú)關(guān)的變化非常重要.
神經(jīng)網(wǎng)絡(luò)分類器可以簡(jiǎn)化為三層結(jié)構(gòu):輸入層、多個(gè)隱藏層和輸出層. 本文選擇的多層神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)如圖3所示. 輸入層的每個(gè)神經(jīng)元代表一個(gè)特征,首先隨機(jī)初始化權(quán)值,權(quán)值向量可以被認(rèn)為是一個(gè)向量到另一個(gè)向量上的投影,或者是兩個(gè)向量之間相似度的度量. 然后利用梯度下降調(diào)整參數(shù)使誤差最小化. 學(xué)習(xí)過(guò)程包括連續(xù)多次向前和向后傳遞. 在前向傳播中,通過(guò)多個(gè)非線性隱藏層將輸入轉(zhuǎn)發(fā)到輸出,并最終將計(jì)算出的輸出與對(duì)應(yīng)輸入的實(shí)際輸出進(jìn)行比較. 在反向傳播中,相對(duì)于參數(shù)的誤差導(dǎo)數(shù)被反向傳播以調(diào)整權(quán)值,以使輸出中的誤差最小化. 這一過(guò)程將持續(xù)多次,直到在模型預(yù)測(cè)中獲得了預(yù)期的改進(jìn). 如果Xi為輸入,fi為第i層的非線性激活函數(shù),第i層的輸出可以表示為
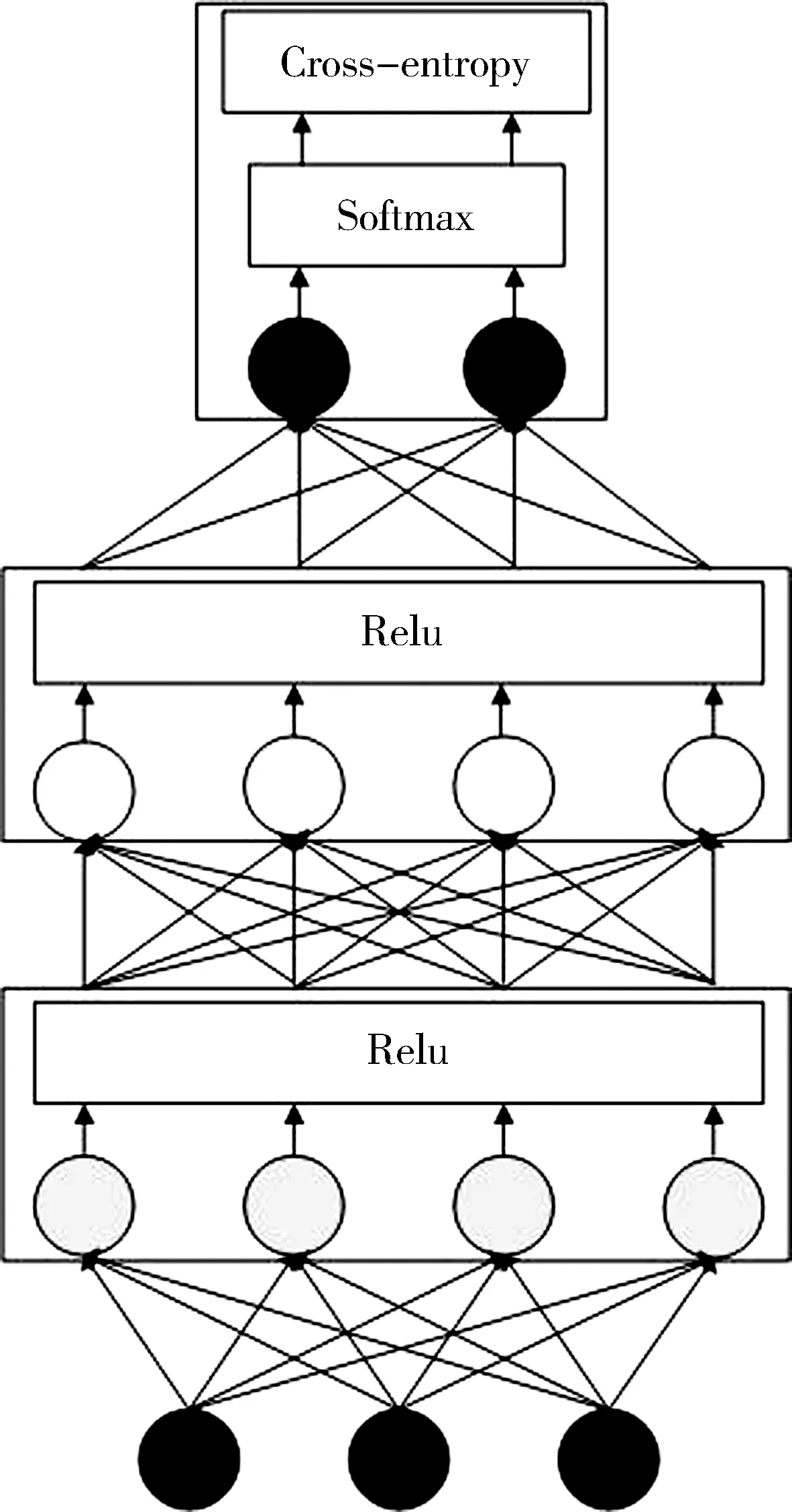
圖3 多層神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)圖
Xi+1=fi(WiXi+bi)
(1)
其中,Xi+1為下一層的輸入;Wi和bi是連接層與層之間的參數(shù). 在反向傳播中,這些參數(shù)可以更新為
Wnew=W-η?E/?W
(2)
bnew=b-η?E/?b
(3)
其中,Wnew和bnew分別是W和b更新后的參數(shù);E為損失函數(shù);η為學(xué)習(xí)率.
本文模型中隱藏層使用的是ReLU激活函數(shù),輸出層使用的是Softmax激活函數(shù),選擇的損失函數(shù)是categorical_crossentroy(分類交叉熵),交叉熵?fù)p失只考慮樣本的標(biāo)記類別,而不考慮標(biāo)記類別之外的其他類別,其損失函數(shù)可以表示為式(4)所示.
(4)
其中,L表示樣本的交叉熵?fù)p失;yi為樣本被正確分類的輸出;yj為樣本y從類別1到類別n的輸出. 每次對(duì)損失進(jìn)行計(jì)算后,會(huì)根據(jù)損失對(duì)模型中的參數(shù)進(jìn)行更新,對(duì)模型中參數(shù)進(jìn)行更新的過(guò)程就是學(xué)習(xí)的過(guò)程.
3 實(shí)驗(yàn)結(jié)果與分析
3.1 實(shí)驗(yàn)數(shù)據(jù)及環(huán)境
為了對(duì)模型進(jìn)行充分驗(yàn)證,本文分別采集了1 200個(gè)配資網(wǎng)站(正樣本)并進(jìn)行了手工驗(yàn)證,3 000個(gè)其他類型網(wǎng)站(負(fù)樣本). 為了使負(fù)樣本能充分覆蓋除配資網(wǎng)站外的網(wǎng)站類型,先通過(guò)CommonCrawl可信網(wǎng)站平臺(tái)選取了5×104個(gè)目標(biāo)網(wǎng)站,使用2.2中第五點(diǎn)文本特征中包含的多個(gè)文本關(guān)鍵詞組合,剔除目標(biāo)網(wǎng)站中不存在這些關(guān)鍵詞的網(wǎng)站,并結(jié)合人工篩查,最終選擇了3 000個(gè)目標(biāo)網(wǎng)站作為訓(xùn)練數(shù)據(jù)集. 實(shí)驗(yàn)采用了十折交叉驗(yàn)證方法對(duì)模型進(jìn)行評(píng)估. 本模型實(shí)驗(yàn)環(huán)境為單臺(tái)PC機(jī),Intel酷睿i7處理器,16 G內(nèi)存. 神經(jīng)網(wǎng)絡(luò)采用Python語(yǔ)言的scikit-learn[19]和keras框架進(jìn)行實(shí)現(xiàn).
3.2 實(shí)驗(yàn)指標(biāo)
實(shí)驗(yàn)評(píng)估指標(biāo)可以通過(guò)以下4種類型表示:(1) 真陽(yáng)性(TP),數(shù)據(jù)標(biāo)簽為配資網(wǎng)站,并且模型識(shí)別結(jié)果也為配資網(wǎng)站的數(shù)據(jù)類型;(2) 假陽(yáng)性(FP),數(shù)據(jù)標(biāo)簽為非配資網(wǎng)站,并且模型識(shí)別結(jié)果為配資網(wǎng)站的數(shù)據(jù)類型,即誤報(bào);(3) 真陰性(TN),數(shù)據(jù)標(biāo)簽為非配資網(wǎng)站,并且模型識(shí)別結(jié)果為非配資網(wǎng)站的數(shù)據(jù)類型;(4) 假陰性(FN),數(shù)據(jù)標(biāo)簽為配資網(wǎng)站,并且模型識(shí)別結(jié)果為非配資網(wǎng)站的數(shù)據(jù)類型,即漏報(bào).
使用準(zhǔn)確率(Accuracy)、召回率(Recall)、精確率(Precision)和調(diào)和平均數(shù)(F1)作為模型性能的基本評(píng)估指標(biāo),這些指標(biāo)的計(jì)算方式分別為式(5~8).
(5)
(6)
(7)
(8)
3.3 實(shí)驗(yàn)步驟
為了驗(yàn)證模型的效果,使用Python對(duì)第二章中配資網(wǎng)站識(shí)別模型進(jìn)行了實(shí)現(xiàn),并設(shè)計(jì)多個(gè)對(duì)比實(shí)驗(yàn),進(jìn)行了如下的實(shí)驗(yàn)步驟.
步驟1將原始數(shù)據(jù)集劃分兩組,數(shù)據(jù)組1用于模型的訓(xùn)練,數(shù)據(jù)組2用于模型的實(shí)驗(yàn)評(píng)估.
步驟2使用Keras實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練和模型評(píng)估代碼,通過(guò)畫(huà)圖的方式展現(xiàn)不同的訓(xùn)練輪數(shù),記錄模型效果變化.
步驟3實(shí)現(xiàn)傳統(tǒng)機(jī)器學(xué)習(xí)模型訓(xùn)練和模型評(píng)估代碼,通過(guò)圖像、表格等方式,記錄不同的參數(shù)下模型的效果,以獲取該模型的最佳效果.
步驟4使用準(zhǔn)確率、精確率、召回率、ROC曲線等評(píng)估指標(biāo),觀察不同模型的評(píng)估結(jié)果.
本文模型的一些參數(shù)選擇包括,優(yōu)化函數(shù)為Adam[20],訓(xùn)練模型評(píng)估指標(biāo)使用準(zhǔn)確率,epochs為15,batch_size為32. 使用to_categorical來(lái)實(shí)現(xiàn)輸出正負(fù)樣本概率,訓(xùn)練過(guò)程中對(duì)上述參數(shù)值,以及決策樹(shù)的深度、最大最小葉參數(shù)、支持向量機(jī)中的核函數(shù)、懲罰系數(shù)、K-鄰近的鄰居個(gè)數(shù)等參數(shù)進(jìn)行調(diào)整,包括修改參數(shù)的大小,選用不同的參數(shù)值,最終根據(jù)模型的分類效果選擇最佳的參數(shù).
3.4 實(shí)驗(yàn)結(jié)果
對(duì)比決策樹(shù)(Decision Tree,DT)、支持向量機(jī)(Support Vector Machine,SVM)、K-鄰近(k-Nearest Neighbor,KNN)和深度神經(jīng)網(wǎng)絡(luò)的實(shí)驗(yàn)結(jié)果,本文設(shè)計(jì)的深度神經(jīng)網(wǎng)絡(luò)模型在準(zhǔn)確率、召回率、精確率等方面都優(yōu)于以上傳統(tǒng)機(jī)器學(xué)習(xí)算法. 在準(zhǔn)確率方面,深度神經(jīng)網(wǎng)絡(luò)達(dá)到95.9%,并且精確率高達(dá)98.7%,傳統(tǒng)機(jī)器學(xué)習(xí)算法中決策樹(shù)是表現(xiàn)最差的,支持向量機(jī)優(yōu)于其通過(guò)構(gòu)建超平面能滿足高維度數(shù)據(jù)的二分類,其各種指標(biāo)表現(xiàn)僅次于深度神經(jīng)網(wǎng)絡(luò),F(xiàn)1值為0.942. 4種算法的詳細(xì)評(píng)估數(shù)據(jù)見(jiàn)表1. 工作特征曲線見(jiàn)圖4.
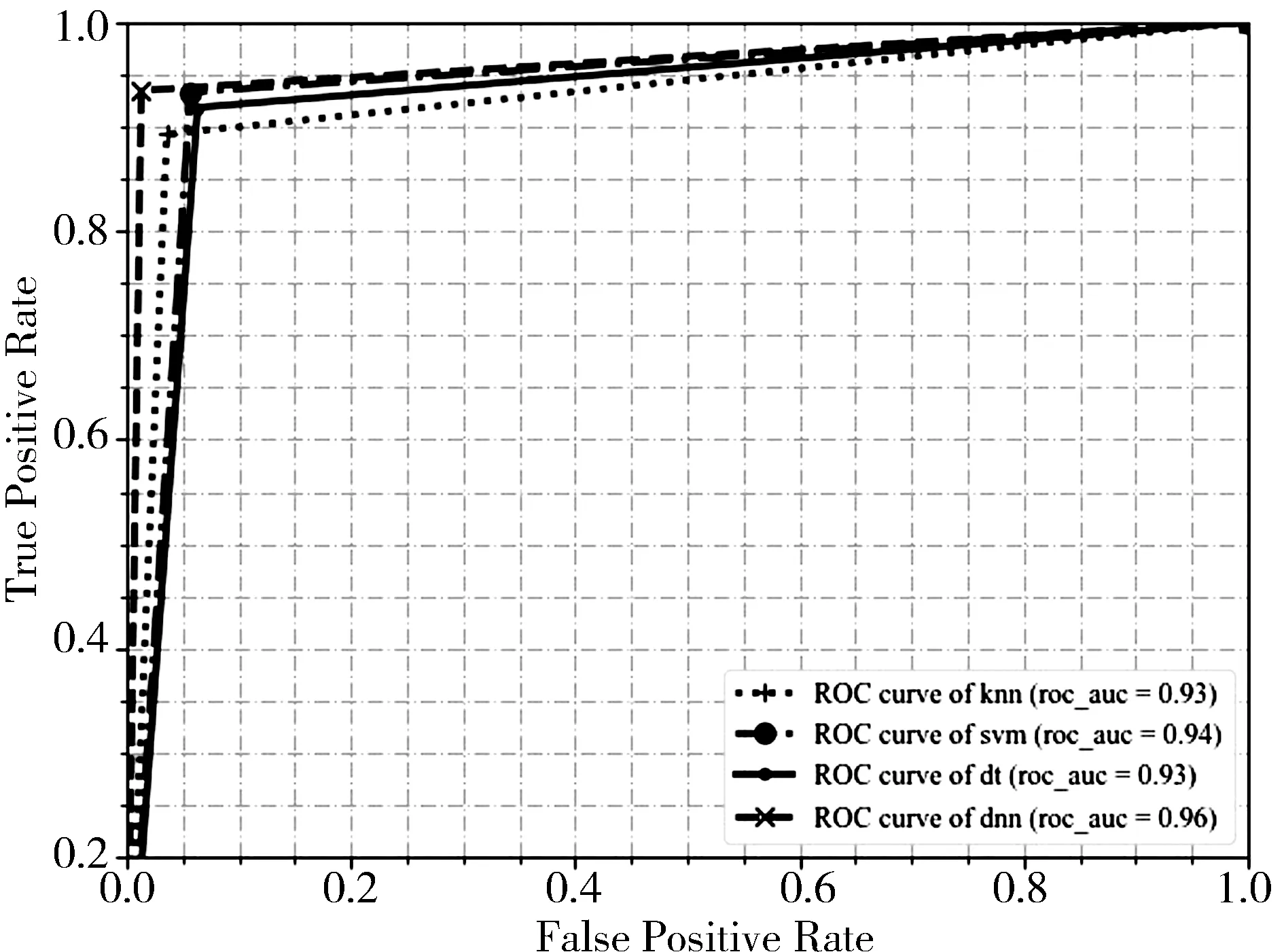
圖4 4種算法的ROC曲線Fig.4 ROC of four algorithms
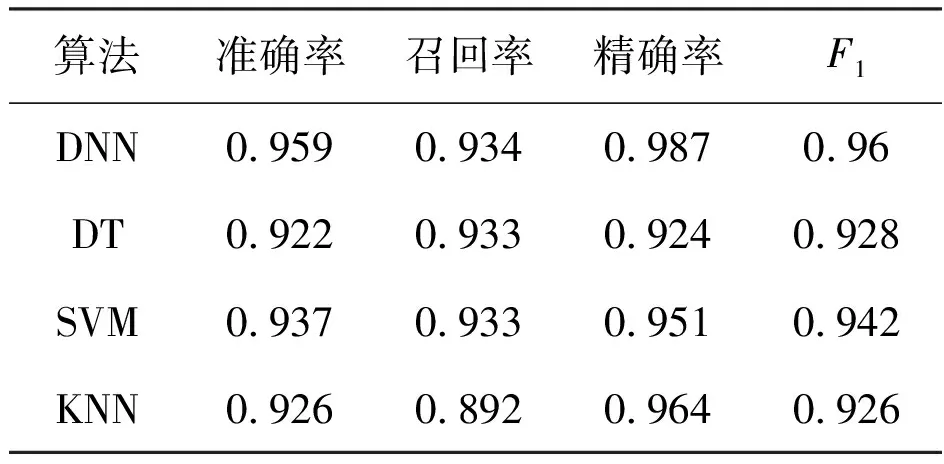
表1 實(shí)驗(yàn)環(huán)境配置4種算法性能對(duì)比
4 結(jié) 論
傳統(tǒng)的網(wǎng)站識(shí)別模型在配資網(wǎng)站的識(shí)別上效果不佳,不能滿足對(duì)配資網(wǎng)站的準(zhǔn)確識(shí)別. 為此,本文設(shè)計(jì)了一種基于深度神經(jīng)網(wǎng)絡(luò)的配資網(wǎng)站識(shí)別模型. 本方法從多個(gè)維度選取區(qū)別配資網(wǎng)站和其他類別網(wǎng)站的關(guān)鍵特征,采用深度神經(jīng)網(wǎng)絡(luò)構(gòu)造分類器用于配資網(wǎng)站識(shí)別. 為了驗(yàn)證該方法的有效性,與傳統(tǒng)的一些機(jī)器學(xué)習(xí)算法進(jìn)行了比較,本文方法識(shí)別準(zhǔn)確率接近96%,精確率達(dá)到了98.7%,均優(yōu)于其他模型. 實(shí)驗(yàn)結(jié)果表明,本文提出的配資網(wǎng)站識(shí)別模型能有效識(shí)別配資網(wǎng)站.
雖然本文模型擁有不錯(cuò)的檢測(cè)效果,但是仍存在不足. 基于網(wǎng)站頁(yè)面內(nèi)容的特征在本次實(shí)驗(yàn)中占有很大比例,但配資網(wǎng)站可以通過(guò)在網(wǎng)頁(yè)中添加干擾內(nèi)容來(lái)影響模型的識(shí)別效果. 因此本文下一步的研究是如何針對(duì)這種對(duì)抗,繼續(xù)提高識(shí)別準(zhǔn)確率以及方法的穩(wěn)定性.
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
