融合分類和情境偏好的矩陣分解電影推薦算法
2021-06-21 10:30:06王文鈴虞慧群范貴生
華東理工大學學報(自然科學版) 2021年3期
王文鈴, 虞慧群, 范貴生,2
(1. 華東理工大學計算機科學與工程系,上海 200237;2. 上海市計算機軟件測評重點實驗室,上海 201112)
近年來互聯網技術的飛速發展,帶動了視頻網站的興起,不論是觀影人數還是人們投入到電影產業中的消費,都在不斷地增長。目前大部分網站的電影推薦都是基于用戶觀看電影的歷史紀錄,通過歷史紀錄來分析用戶的觀影偏好來進行推薦。然而,用戶對電影的喜好也受到情境信息的影響,如年齡、當地天氣、外界環境等。在電影推薦領域,將情境信息融入到傳統的推薦算法中,將會提供更加精確的推薦結果,算法也會更加靈活。
國內外很多學者對情境感知推薦進行了深入的研究。Baltrunas等[1]將情境信息融入推薦系統,提出了CAMF(Context-Aware Matrix Factorization)推薦模型,在傳統的矩陣分解中融入了情境偏置。蘭艷等[2]提出了一種改進的時間加權協同過濾算法。陳星等[3]嘗試將情境感知應用到智能家居中。CAKIR等將協同過濾與關聯性規則挖掘應用在電子商務中[4]。以上對情境感知推薦系統的研究都取得了一定的成果,但也存在著不同情境信息對同一個項目的影響權重沒有分開考慮的問題。同時,通過矩陣分解算法得到的推薦結果也存在著可解釋性差的問題。
為了解決上述問題,本文提出了一種混合推薦算法CAMF-CM(Context-Aware Matrix Factorization-Classification Model)。將用戶和項目的情境信息數據輸入到決策樹模型中,以此來獲得用戶特征信息和電影特征信息,得到用戶在給定情境信息下的觀影傾向,再將其與改進了情境權重的CAMF算法結合,進一步加強推薦的準確性。因為矩陣分解算法具有良好的擴展性,并且可以一定程度上緩解數據稀疏問題,所以選取矩陣分解算法作為基礎[5]。在LDOS-COMODA數據集上進行了相關的數據預處理,然后以平均絕對誤差(MAE)為評價指標并設計了相關實驗。實驗結果表明,本文提出的CAMFCM算法能夠有效地降低預測誤差,改善推薦結果的質量。
1 情境感知推薦算法
1.1 基本矩陣分解算法
矩陣分解算法在推薦領域已有廣泛的應用,其思想是將數據集中的用戶評分矩陣R∈Rn×m分解成用戶隱性特征矩陣P∈Rn×f和項目隱性特征矩陣Q∈Rm×f,且滿足

將用戶u的特征向量用pu表示,評分項目i的特征向量用qi表示,那么使用矩陣分解算法計算得出的向用戶u推薦物品i的推薦分數可以表示為

為了找到式(2)中的特征向量pu、qi,也為了衡量矩陣分解的好壞,需要規定一個損失函數如下:
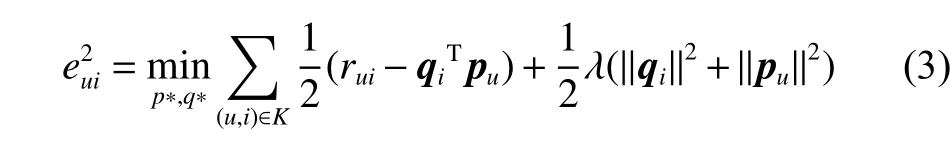
其中:K為已有評分記錄的(u,i)對集合;rui為用戶u對項目i的真實評分; λ (‖qi‖2+‖pu‖2) 為防止過擬合的正則化項; λ 為正則化系數。損失函數是為了計算平方項損失,需要達到的目標是使每一個元素(非缺失值)的e(i,j)的總和最小[6]。
1.2 Baseline預測算法
情境感知是一種能將用戶和項目的情境信息進行綜合考慮的技術[7]。傳統的協同過濾算法需要計算用戶和項目的相似度[8],在Baseline算法中,需要引入用戶的全局偏置,記為bu。同理,也要引入項目的全局偏置,記為bi。Baseline算法的評分預測公式如下:

其中:μ為該項目評分的平均值。為了計算bi、bu,需要引入目標函數,計算公式如下:
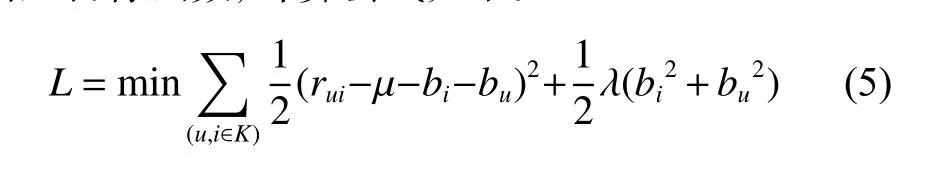
1.3 CAMF算法
CAMF預測模型[1]中設定每個情境信息對項目的影響權重相同。該預測模型中引入了情境偏置的概念,記為bc,作為情境因素對某個項目的影響。
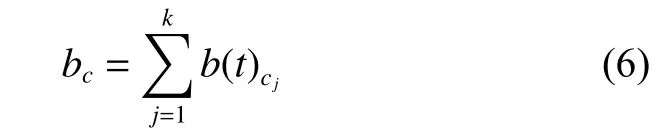
其中:t為項目所屬類別;cj為情境要素,共包含k個情景要素;b(t)cj表示情境要素cj對t類別影視項目的影響。將情境偏置與傳統的矩陣分解算法結合,得到融合了情境偏置的評分預測公式如下:
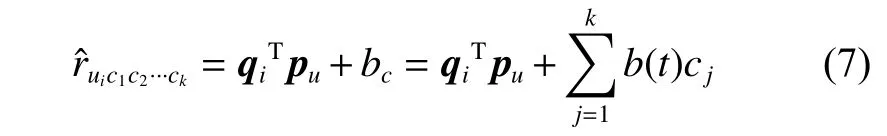
其 中:r?uic1c2···ck表示用 戶u在 情 境信 息c1,c2,···,ck下對影視項目i的預測評分。將該融入情境偏置的評分預測融入矩陣分解中,得到融合了情境信息的目標函數:
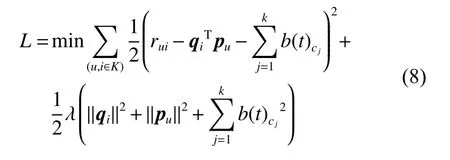
2 融入分類模型的混合推薦算法
2.1 決策樹分類模型
推薦系統可以識別可能引起用戶興趣的項目,或預測用戶對電影等項目的評分[9],將分類算法與其結合,可以進一步提高推薦的準確率。目前常用的分類算法有決策樹算法、貝葉斯算法[10]、k-近鄰算法和支持向量機算法,本文采用決策樹算法。本文將LDOS-COMODA數據集中的日期、地點、情緒、狀態、時間、天氣等情境信息作為特征集,將電影的風格、年代、類型作為訓練標簽,通過決策樹模型進行訓練,得到基于情境數據下的用戶和項目的隱性特征向量,以及用戶在特定情境下的觀影傾向。
2.2 改進的CAMF算法
情境信息是用來描述用戶所處環境的如位置、時間、應用系統等信息[11]。CAMF算法設定每個情境信息對項目的影響權重相同,但每個情境信息對用戶的影響權重應該不同,有些用戶更容易受到特定情境信息的影響,例如天氣和觀影日期,對其他情境信息則并不太在意。因此,需要對情境信息設定各自的權重。本文從LDOS-COMODA數據集中選取了12個情境信息進行實驗,對每個情境信息設定其權重gj,則修改后的情境偏置公式為
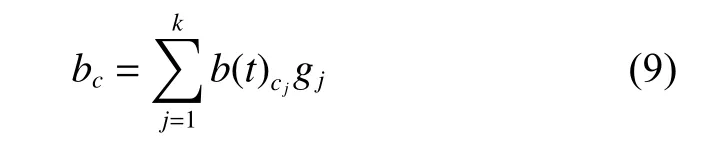
特定情境信息的權重值gj通過實驗確定,信息增益作為衡量信息對決策的影響性的重要方法,將其應用在情境權重的計算中,對數據集中的情境信息分別計算其信息增益,結果取平均值,計算得出的不同情境信息的情境權重如表1所示。
為了進一步提高推薦的靈活性,將Baseline算法中用戶和項目的全局偏置bi、bu引入改進后的CAMF算法的評分預測函數中,加入全局偏置后的預測公式如下:
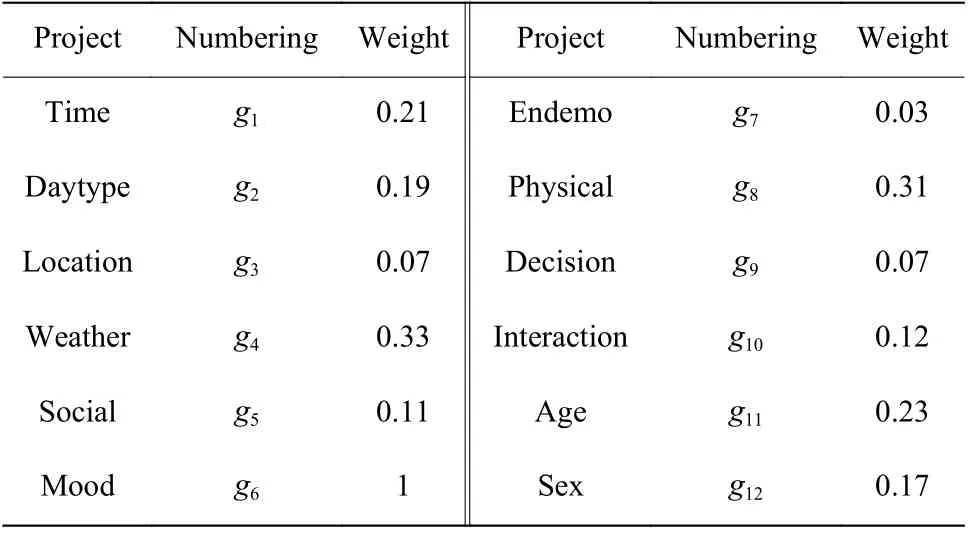
表1 情境權重描述Table 1 Description of context weights

2.3 CAMF-CM混合推薦算法
CAMF-CM是結合了改進的CAMF算法和決策樹算法的混合推薦算法。其算法流程如圖1所示。
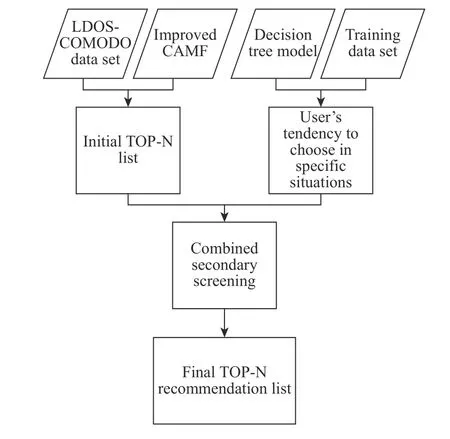
圖1 CAMF-CM推薦模型算法流程Fig. 1 Flow chart of CAMF-CM recommendation model algorithm
首先,使用改進后的CAMF算法得到初始的推薦列表,該列表為包含了所有電影類型的推薦列表。情境感知推薦的問題之一是如何獲取用戶的情境信息[12],因為初始推薦列表中可能包含了用戶在給定情境下并不感興趣的電影類型。因而需要使用決策樹模型對數據集進行訓練,得出用戶在特定情境下的觀影傾向后對初始推薦列表進行篩選。CAMFCM混合推薦算法的計算流程如下:
算法1 混合推薦算法CAMF-CM
輸入:用戶電影評級矩陣R,用戶特征矩陣P,電影特征矩陣Q,用戶數量M,電影數量N,用戶情境因素數量F1,電影特征標簽數量F2,包含了用戶對電影實際評分Ri的評分矩陣F3。
輸出:MAE
計算流程:
開始:
(1)依據Bsaeline算法,計算用戶全局偏置bi,電影項目全局偏置bu。
(2)計算用戶特征向量pu,電影特征的隱藏向量qi。
(3)計算情境偏置,使用改進的CAMF算法,根據公式(10)計算評估分數Pi,并生成TOP-N推薦列表。
(4)使用決策樹算法對情境數據集LDOSCOMODA進行特征標簽訓練,得到用戶在給定情境下的電影偏好。
(5)根據第3步得到的TOP-N推薦結果,集合決策樹模型得到的用戶在給定情境下的選擇傾向,對TOP-N列表進行再次篩選,得到最終TOP-N推薦列表。
(6)算法效率驗證。采用10折交叉驗證法,分別計算協同過濾算法基本矩陣分解算法、Baseline預測算法和CAMF-CM混合算法的MAE并進行比較,得到最終結果。
結束
CAMF-CM混合推薦算法將改進后的CAMF算法所生成的初始推薦列表,結合分類模型訓練得出的用戶在特定情境下的觀影傾向進行二次篩選,得到最終的推薦列表。目前情境感知推薦系統的應用領域日益廣泛,但在情境要素的選擇問題、情境信息的兼容方法問題等方面還需進一步研究[13]。
3 實驗結果與分析
3.1 數據集和數據預處理
本文所使用的數據集為LDOS-COMODA電影數據集,該數據集除了包含用戶對電影的評分信息外也包含了情境信息,詳細數據分布如表2所示。

表2 LDOS-COMODA電影評分數據集描述Table 2 LDOS-COMODA movie rating data set description
目前被廣泛使用的預測模型算法有決策樹和隨機森林,該兩種預測模型往往能夠得到較好的預測效果[14],本文選用決策樹模型。從LDOS-COMODA數 據 集 中 選 取 包 含Time、Daytype、Location、Weather、Social、Mood、Endemo、Physical、Decision、Interaction,Age和Sex這12個情境信息作為參數進行實驗。先對數據進行預處理,設定情境信息的值均為正整數,若有缺失值,用該項情境信息已有數據中的眾數進行填充。處理后的情境數據集內容描述如表3所示。

表3 情境要素描述Table 3 Description of context elements
實驗環境:Windows 10操作系統,16 GB內存,Intel(R) Core(TM) i7-8700k CPU 3.70 GHz,編程語言采用Python3。
3.2 評價指標
情境感知推薦系統可以通過用戶和項目的情境信息進行推薦[15],平均絕對誤差(Mean Absolute Error,MAE)和均方根誤差(Root Mean Squared Error,RMSE)是RS (Recommendation System)領域常用的預測準確度的評估標準。本文采用MAE作為算法的評價指標,它表示預測值和觀測值之間絕對誤差的平均值,計算公式如下:
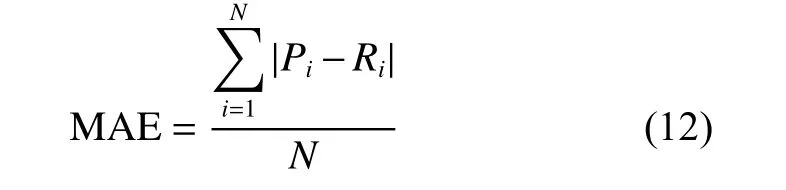
其中:N為測試集大小;Pi為預測評分;Ri為實際評分。MAE值越小,準確度越高,推薦質量越高。
3.3 實驗結果與分析
為了得到精確的結果,采用10折交叉驗證的方法進行實驗。實驗過程中,將數據集分為10份,根據不同的算法進行不同的配置。采用協同過濾算法進行實驗時,取9份作為訓練集,1份作為測試集。采用基本矩陣分解算法、Baseline預測算法和CAMFCM混合推薦算法進行實驗時,取8份作為訓練集,1份作為測試集,1份作為驗證集。每次實驗結束后將樣本進行輪換,使用MAE作為評價指標。
3.3.1 基于用戶的協同過濾算法 對于協同過濾算法,將近鄰數量k設置為5 ~ 50,取間隔為5,觀察MAE的變化曲線,如圖2所示。由圖2可知,MAE在0.96 ~ 0.98間波動,當k=30時,MAE取得極小值,約為0.959,此時推薦效果最好。
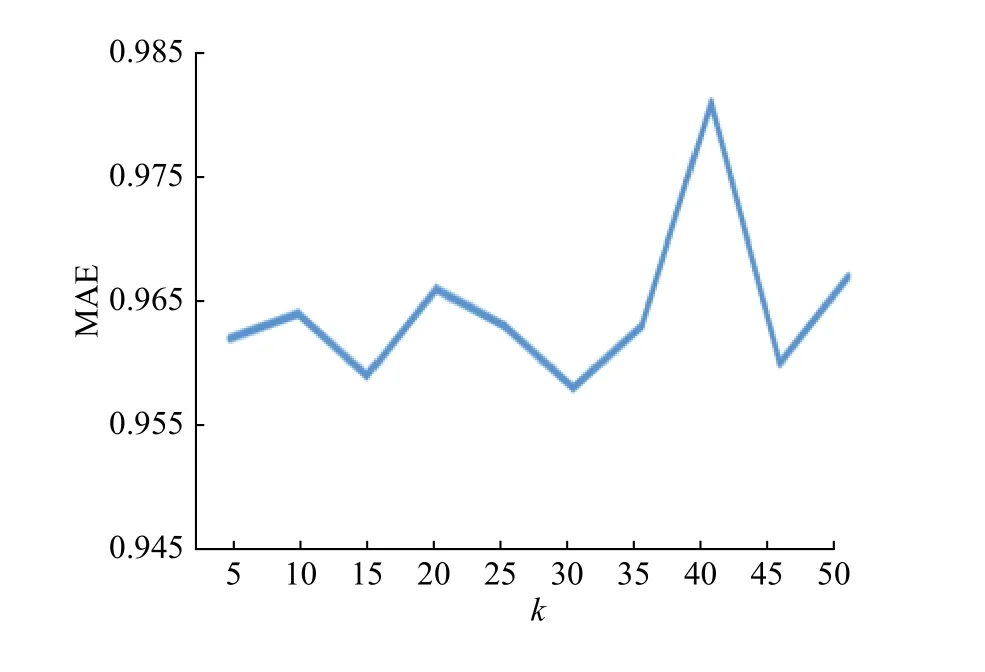
圖2 基于用戶的協同過濾算法的MAEFig. 2 MAE of user-based collaborative filtering algorithm
3.3.2 基本矩陣分解算法 對于基本矩陣分解算法,設定正則化系數λ和學習率 γ 的取值為0.01 ~ 0.05,取0.01作為間隔進行實驗。迭代數設置為100次,向量維度為10,實驗結果如圖3所示。可見當λ=0.03、γ=0.01時,MAE取得極小值,約為1.95,此時推薦效果最好。
3.3.3 Baseline預測算法 對于Baseline預測算法,同樣設定正則化系數λ和學習率 γ 的取值為0.01 ~0.05,取0.01作為間隔進行實驗。迭代數設置為100次,向量維度為10,實驗結果如圖4所示。由圖4可見,當λ=0.03且 γ =0.04 時,MAE取得極小值,約為0.806,此時推薦效果最好。
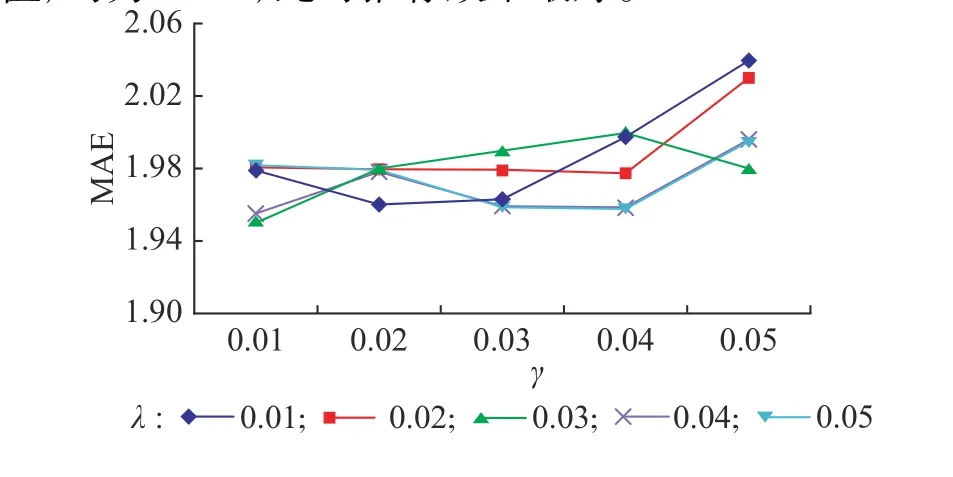
圖3 基本矩陣分解算法的MAEFig. 3 MAE of basic matrix factorization algorithm
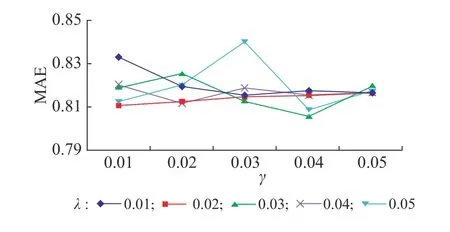
圖4 Baseline預測算法的MAEFig. 4 MAE of baseline prediction algorithm
3.3.4 CAMF-CM推薦算法 在CAMF-CM混合算法中,分類模型采用決策樹模型進行訓練,改進的CAMF算法中設定正則化系數λ和學習率 γ 的取值同樣為0.01~0.05,取0.01作為間隔進行實驗。迭代數設置為100次,向量維度為10,CAMF-CM混合模型在λ取0.04且 γ =0.01 時,MAE最小,約為0.747,實驗結果如圖5所示。
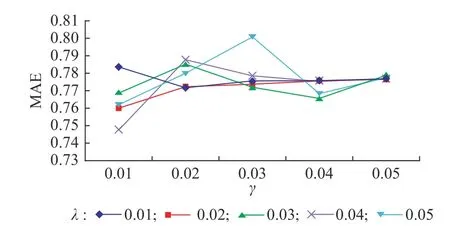
圖5 CAMF-CM算法的MAEFig. 5 MAE of CAMF-CM algorithm
各種算法的MAE對比結果如圖6所示。與其他3種算法相比,CAMF-CM混合算法的MAE最小,推薦結果更加精確。
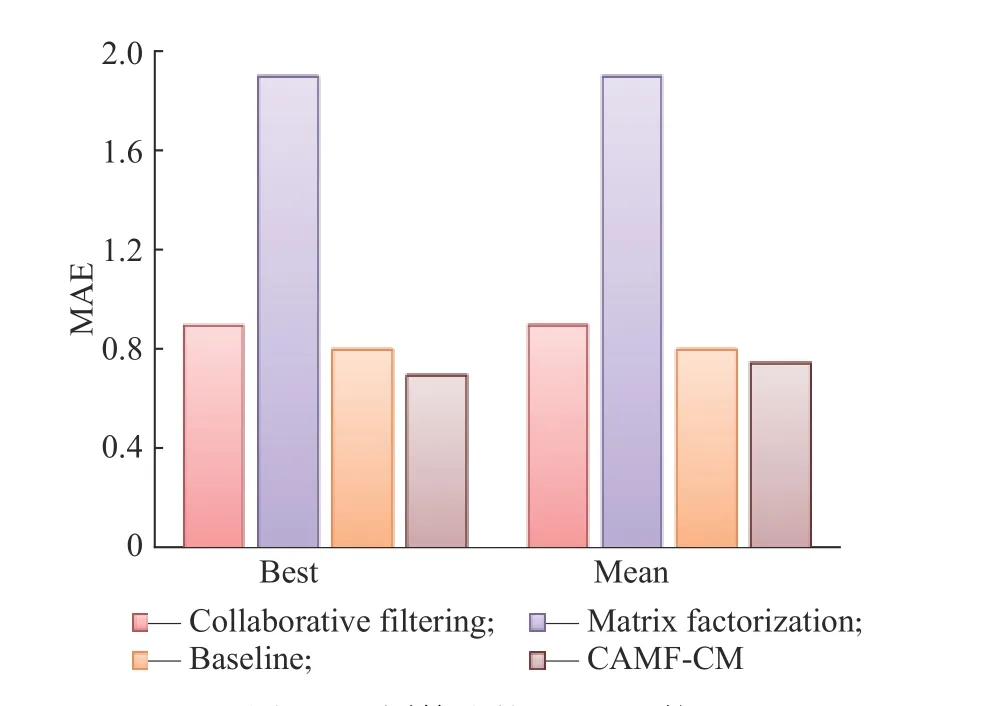
圖6 不同算法的MAE比較Fig. 6 MAE of different algorithms
4 結束語
推薦系統如果能夠將情境信息納入考慮,就能提高推薦的準確率。本文提出了一種融合了矩陣分解算法和分類模型的混合推薦算法,實驗結果表明,該混合算法相較于基于用戶的協同過濾算法、基本矩陣分解算法和Baseline預測算法有著更高的準確率。本文提出的混合推薦算法還有進一步優化的空間,算法所使用的分類模型只使用了電影的類別、年份、總評分等標簽信息,并且也沒有對用戶對電影評分的合理性進行分析。在之后的研究中,可以對用戶對電影的評分進行預處理,去掉數據集中不合理的評分,并且在矩陣分解算法的目標函數中,對每一個情境信息的合理權重進行進一步的分析,使情境權重能夠根據用戶自身評分特征進行變化。此外,還可以在算法上進行一些其他的優化,例如添加評分用戶個人的信用權重,對同一電影在不同時期的評分進行分析處理等。
猜你喜歡
福建中學數學(2023年5期)2024-01-25 17:41:36
中學生數理化·中考版(2022年10期)2022-11-10 09:37:46
中華手工(2017年2期)2017-06-06 23:00:31
護士進修雜志(2017年3期)2017-02-14 07:19:35
商用汽車(2016年11期)2016-12-19 01:20:16
小學生作文(中高年級適用)(2016年3期)2016-11-11 06:30:23
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
