基于時間序列的體育產業數據精準挖掘模型構建
2021-06-24 10:59:16王杰
赤峰學院學報·自然科學版 2021年4期
王杰


摘 要:為了提高體育產業數據精準挖掘和量化分析能力,本文提出基于時間序列的體育產業數據精準挖掘模型構建方法。采用全局穩態特征融合方法實現對體育產業數據分布式時間序列模型構建,采用統計量化融合分析方法實現體育產業數據特征量化空間轉換,通過模糊解析控制方法,挖掘體育產業數據的關聯分布熵。采用輸出增益穩態分析方法,構建體育產業數據挖掘的線性解析參數分析模型,采用二乘規劃和線性融合方法,實現對體育產業數據挖掘的內源融合和參數控制,結合模糊聚類實現對體育產業數據的統計特征線性聚類處理。結合稀疏性的特征匹配調度模型,構建體育產業數據挖掘的時間融合序列,通過時間序列重構,實現對體育產業數據的精準挖掘。仿真結果表明,采用該方法進行體育產業數據挖掘的精準度較高,特征匹配度較高,降低了體育產業數據挖掘的擾動誤差。
關鍵詞:時間序列;體育產業;數據;精準挖掘;數據聚類
中圖分類號:TP391 ?文獻標識碼:A ?文章編號:1673-260X(2021)04-0029-04
0 引言
隨著體育產業融合式發展,在信息化環境下實現對體育產業的進一步結構化融合調度,構建體育產業的大數據融合和特征性挖掘模型,根據體育產業的信息分布,結合統計分析和融合調度方法,建立體育產業數據精準挖掘模型,提高體育產業的大數據共享和信息調度能力,從而提升體育產業的結構化融合發展能力,相關的體育產業數據精準挖掘模型研究在體育產業的優化升級和融合方面具有重要意義[1]。
對體育產業數據精準挖掘模型研究是建立在對體育產業大數據鏈特征分析基礎上,通過大數據鏈分析和特征優化重組,建立體育產業數據的特征鏈結構分析模型,通過空間信息融合和量化特征解析控制,建立符合體育產業發展需求的綠色產業鏈[2],在大數據和云平臺分析環境下,實現體育產業數據精準挖掘模型設計,提高體育產業數據精準挖掘能力。在傳統方法中,對體育產業數據精準挖掘模型設計方法主要有向量回歸分析方法、空間信息融合方法、統計分析方法和模糊度檢測方法等,構建體育產業數據挖掘的統計分析模型,結合回歸分析,實現對體育產業數據精準挖掘,但傳統方法進行體育產業數據挖掘的精準度不高[3-5]。針對傳統方法存在的弊端,本文提出基于時間序列的體育產業數據精準挖掘模型構建方法。首先采用全局穩態特征融合方法實現對體育產業數據分布式時間序列模型構建,采用統計量化融合分析方法實現體育產業數據特征量化空間轉換,通過模糊解析控制方法,挖掘體育產業數據的關聯分布熵。采用輸出增益穩態分析方法,然后構建體育產業數據挖掘的線性解析參數分析模型,采用二乘規劃和線性融合方法,實現對體育產業數據挖掘的內源融合和參數控制,結合模糊聚類實現對體育產業數據的統計特征線性聚類處理。結合稀疏性的特征匹配調度模型,構建體育產業數據挖掘的時間融合序列,通過時間序列重構,實現對體育產業數據的精準挖掘。最后進行仿真測試分析,展示了本文方法在提高體育產業數據精準挖掘能力方面的優越性能。
1 體育產業數據空間分布結構和統計量化融合分析
1.1 體育產業數據空間分布結構
為了實現基于時間序列的體育產業數據精準挖掘模型構建,采用全局穩態特征融合方法實現對體育產業數據分布式時間序列模型構建,結合兩個體育產業數據存儲中心節點引出的屬性組,構建體育產業數據的底層數據模塊,結合語義本體融合[6],構建體育產業數據空間分布結構模型,如圖1所示。
在圖1所示的體育產業數據空間分布結構模型中,采用空間分布結構特征匹配方法[7],得到體育產業數據空間分布的兼容性特征分布概念集為:
根據上述分析,得到體育產業數據空間分布結構模型,結合大數據融合,實現對體育產業數據空間分布結構重組和數據挖掘。
1.2 體育產業數據的統計量化融合分析
采用統計量化融合分析方法實現體育產業數據特征量化空間轉換,通過模糊解析控制方法,挖掘體育產業數據的關聯分布熵?啄,得到體育產業數據的關聯評價的深度學習模型為:
2 體育產業數據精準挖掘模型優化
2.1 體育產業數據挖掘的線性解析
采用輸出增益穩態分析方法,構建體育產業數據挖掘的線性解析參數分析模型,采用二乘規劃和線性融合方法,得出概念圖CR的中心參數,通過聯合參數識別,實現對體育產業數據挖掘的內源融合和參數控制[10],得到體育產業數據挖掘的相似度計算公式可定義如下:
提取體育產業數據的語義本體特征量,構建體育產業數據挖掘的線性規劃模型,得到體育產業數據挖掘的模糊閾值控制參數。根據兩個概念與的語義相似度分布,得到節點i,從頂級概念類別中,利用最大擴充相容分布,根據內源融合控制,實現體育產業數據挖掘的線性解析[12]。
2.2 體育產業數據挖掘優化輸出
結合模糊聚類實現對體育產業數據的統計特征線性聚類處理。結合稀疏性的特征匹配調度模型,構建體育產業數據挖掘的時間融合序列,建立體育產業數據回歸分析模型,結合模糊信息融合特征提取的方法,得到體育產業數據挖掘的最短路徑尋優控制模型為:
綜上分析,結合稀疏性的特征匹配調度模型,構建體育產業數據挖掘的時間融合序列,通過時間序列重構,實現對體育產業數據的精準挖掘,實現流程如圖2所示。
3 實驗測試分析
為了驗證本文方法在實現體育產業數據挖掘精準挖掘中的應用性能,采用SPSS和Visual C++ 進行仿真測試分析,設定遞歸分析的迭代次數為240,相似度分布系數為0.18,語義相似度為0.89,樣本數為7,各組樣本的體育產業數據測試集和訓練集的匹配系數見表1。
根據上述參數設定,設定測試指標,實現體育產業數據的精準挖掘的性能分析,測試指標分為體育產業數據挖掘的可靠度百分差為:
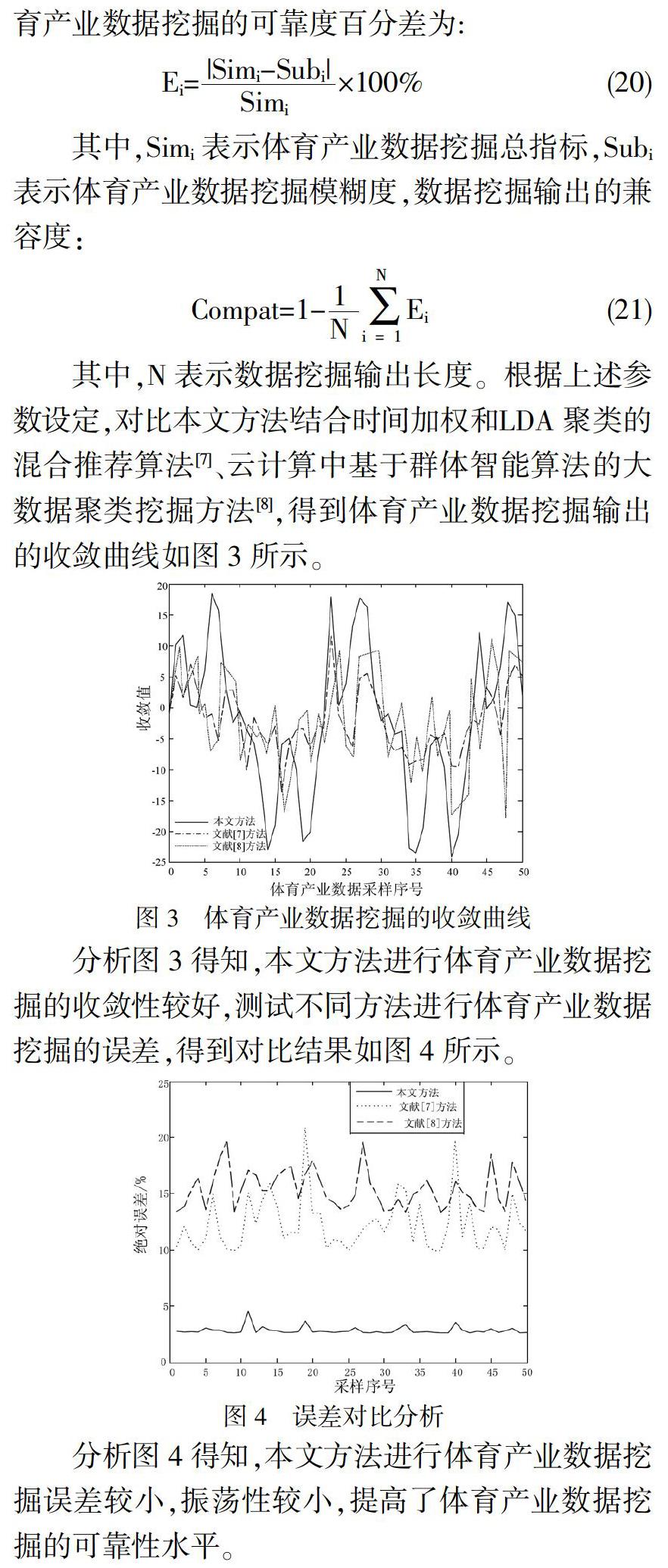
其中,N表示數據挖掘輸出長度。根據上述參數設定,對比本文方法]結合時間加權和LDA聚類的混合推薦算法[7]、云計算中基于群體智能算法的大數據聚類挖掘方法[8],得到體育產業數據挖掘輸出的收斂曲線如圖3所示。
分析圖3得知,本文方法進行體育產業數據挖掘的收斂性較好,測試不同方法進行體育產業數據挖掘的誤差,得到對比結果如圖4所示。
分析圖4得知,本文方法進行體育產業數據挖掘誤差較小,振蕩性較小,提高了體育產業數據挖掘的可靠性水平。
4 結語
建立體育產業數據精準挖掘模型,提高體育產業的大數據共享和信息調度能力,從而提升體育產業的結構化融合發展能力。本文提出基于時間序列的體育產業數據精準挖掘模型構建方法。構建體育產業數據的底層數據模塊,結合語義本體融合,實現對體育產業數據空間分布結構重組和數據挖掘。采用二乘規劃和線性融合方法,根據內源融合控制,實現體育產業數據挖掘的線性解析。通過時間序列重構,實現對體育產業數據的精準挖掘。研究得知,本文方法對體育產業數據挖掘的誤差較低,性能較好。
參考文獻:
〔1〕胡甜甜,但雅波,胡杰,等.基于注意力機制的Bi-LSTM結合CRF的新聞命名實體識別及其情感分類[J].計算機應用,2020,40(07):1879-1883.
〔2〕劉璟.中文命名實體識別方法研究[J].電腦知識與技術,2019,15(09):179-180.
〔3〕馮貴蘭,李正楠,周文剛.大數據分析技術在網絡領域中的研究綜述[J].計算機科學,2019,46(06):1-20.
〔4〕田保軍,劉爽,房建東.融合主題信息和卷積神經網絡的混合推薦算法[J].計算機應用,2020,40(07):1901-1907.
〔5〕SHU J, SHEN X, LIU H,et al. A content-based recommendation algorithm for learning resources[J]. Multimedia Systems,2018, 24(02):163-173.
〔6〕KARABADJI N E I,BELDJOUDI S,SERIDI H,et al. Improving memory-based user collaborative filtering with evolutionary multi-objective optimization[J]. Expert Systems with Applications,2018, 98:153-165.
〔7〕程磊,高茂庭.結合時間加權和LDA聚類的混合推薦算法[J].計算機工程與應用,2019,55(11):160-166.
〔8〕唐新宇,張新政,趙月愛.云計算中基于群體智能算法的大數據聚類挖掘[J].重慶理工大學學報(自然科學),2019,33(04):128-133+167.
〔9〕劉久彪.空間數據庫反向最近鄰聚類方法[J].吉林大學學報(理學版),2019,57(02):387-392.
〔10〕王亮,冶繼民.整合DBSCAN和改進SMOTE的過采樣算法[J].計算機工程與應用,2020,56(18):111-118.
〔11〕于超,王璐,程道文.基于本體的教育資源語義檢索系統研究[J].吉林大學學報(信息科學版),2018,36(02):207-212.
〔12〕楊志明,王來奇,王泳.深度學習算法在問句意圖分類中的應用研究[J].計算機工程與應用,2019,55(10):154-160.
