知識圖譜研究綜述
2021-06-24 10:59:16劉燕賈志杰閆利華鄒妍
赤峰學院學報·自然科學版 2021年4期
劉燕 賈志杰 閆利華 鄒妍

摘 要:知識圖譜將知識庫以一種圖譜的形式展現出來,使知識具有可解釋性、可推理性,從而使機器具備認知能力,是人工智能的重要基石。本文對知識圖譜構建的關鍵技術、工具以及應用進行了綜述,并且對知識圖譜未來的研究方向做出展望。
關鍵詞:知識圖譜;實體抽取;知識融合
中圖分類號:TP391 ?文獻標識碼:A ?文章編號:1673-260X(2021)04-0033-04
1 知識圖譜概念及主要應用
知識圖譜[1](Knowledge Graph)本質上是一種大規模語義網絡,它包含了各種各樣的實體、概念以及實體之間的語義關系,是大數據時代知識表示的重要方式之一。2012年google發布了基于知識圖譜的搜索引擎產品,由于知識圖譜將知識以一種直觀、可視化的方式展現出來,并且可以建立碎片化的數據的關聯,因此,知識圖譜成為語義搜索、問答系統、推薦系統等領域的研究熱點[2]。
語義搜索可以利用知識圖譜準確地捕捉用戶的搜索意圖,進而用基于知識圖譜中的知識解決傳統搜索中遇到自然語言輸入帶來的表達多樣性、歧義性問題,通過實體鏈接實現知識與文檔的混合檢索。Google、百度和搜狗等搜索引擎公司通過構建Knowledge Graph、知心和知立方改進搜索質量。
問答系統是信息服務的高級形式,基于知識圖譜的問答系統能夠讓計算機以精準的自然語言自動回答用戶提出的問題。北京大學構建了基于開放領域知識圖譜的自然語言問答(QA)系統-gAnswer,用戶通過自然語言輸入,經過一系列的轉化能直接得到最終答案。
個性化推薦系統是所有面向用戶的互聯網產品的核心技術,在大量商品中,猜測用戶的興趣,給用戶推薦一個小規模的商品集合,知識圖譜為推薦系統提供了額外的輔助信息來源,可以提高推薦系統的精度。易趣正在構建其產品知識圖譜,從而給出產品的定位和吸引買家的因素[3]。
2 知識圖譜的主要特征
知識圖譜利用圖的形式展現數據實體的關系,數據通常以三元組RDF
知識圖譜是一個空間的概念,使知識具有可視化的展示,能夠直觀地看到實體之間的關系,通常具有以下幾個特征。
2.1 知識圖譜可以直觀地表示實體之間的關系
如圖1所示,展示了民政救助知識圖譜中“救助人”和“救助原因”“救助金額”實體之間的關系,將民政部門救助情況直觀地展示出來。
2.2 知識圖譜使知識具有可擴展性
隨著時間變化,可以在知識圖譜中增加新的知識節點(實體),新的知識結構和知識內容能夠累積成一個完整的知識結構,在圖1中還可以抽取救助人的家庭成員、收入等信息,使知識圖譜更完備。
2.3 知識圖譜使知識具有可推理性
知識圖譜中大多數的關系是缺失的,基于已有的三元組關系,知識圖譜還可以推導出新的關系,可以進一步實現知識發現。例如在知識圖譜中存在<老虎,科,貓科>,<貓科,目,食肉目>這樣的關系,可以推導出<老虎,目,食肉目>這樣的關系。
2.4 知識圖譜使知識具有可解釋性
由于知識圖譜具有可推理性,使得知識具有可解釋性,尤其是在推薦系統的應用,能為用戶推薦需要的商品,還能解釋推薦的原因。
2.5 知識圖譜的數據存儲形式可以提高檢索速度
知識圖譜所采用的知識存儲方式,在知識查詢的過程中可以提高查詢速度和效率,尤其是隨著數據量的增多和關聯深度的增加,更能展現知識圖譜的數據查詢和分析的優勢。
3 知識圖譜構建的主要技術
知識圖譜主要分為知識圖譜構建和知識圖譜應用兩個部分,其中知識圖譜的構建是關鍵,基本流程和主要技術為模型設計、知識抽取、知識融合、知識存儲和管理。
3.1 模型設計
知識圖譜的邏輯結構主要分為模式層和數據層,模式層在數據層之上,是知識圖譜的核心,模式層存儲的是經過提煉的知識,用本體表示,本體(ontology)的本質是概念模型,表達的是概念及概念之間的關系[5]。通常知識圖譜的模式層采用本體庫來管理,主要的本體庫有WordNet、DBpedia、Cys等,可以借助本體庫對公理、規則和約束條件的支持能力來規范實體的類型以及實體之間的關系類型。例如,高血壓、糖尿病等實體在本體庫中歸類為病癥,發燒、咳嗽歸類為癥狀,在本體庫中的規則約束病癥和癥狀之間的聯系。比較流行的本體編輯工具是Protégé,用戶只需要在概念層次上進行本體的模型構建,比較靈活,但缺乏對中文的支持。
3.2 知識抽取
知識抽取是在海量、多源異構的數據中抽取出實體和關系,對結構化和半結構化的數據可以通過專門的工具進行抽取,對于非結構化的數據進行實體抽取通常有三種方法。
3.2.1 基于詞典和規則的方法
基于詞典和規則的實體抽取方法需要通過人工定義命名詞典、實體抽取規則模板,從文中抽取出三元組信息。例如,在醫療領域知識抽取過程中我們可以定義這樣的規則:X+謂語+疾病(X作為實體可能是疾病、藥品、癥狀),將這個規則保存在信息庫,對于要抽取的文本經過處理后和信息庫的規則進行匹配,基于以上規則,對于“高血壓引起腦出血、腦梗等疾病”的描述,可以抽取出<高血壓,引起,腦出血>這樣的三元組信息。這種方法的缺點是需要依靠大量的人工標注和制定規則,對于不同的應用領域,需要專家重新標注詞典和定義規則,效率低、可移植性差,但準確性較高。
3.2.2 基于統計的機器學習的方法
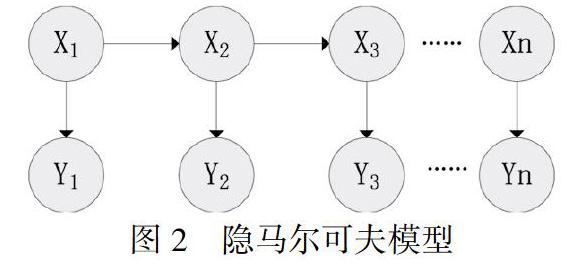
基于統計模型的方法通過對已經標注語料采用統計方法進行訓練,并保存訓練模型,從訓練語料中挖掘出特征,對于要抽取的文本調用模板獲取命名實體。主要模型有隱馬爾可夫模型、條件馬爾可夫模型、最大熵模型、條件隨機場模型,這些模型都是將命名實體作為序列標注問題處理。例如,隱馬爾可夫模型[6]就是在給定模型下,從一定的觀察序列X選取一個最優的標記序列Y,使得P(Y|X)的概率最大,如圖2所示。
3.2.3 基于深度學習的方法
深度學習方法將文本詞向量作為輸入,通過深度神經網絡學習模型實現端到端的命名實體識別,不再依賴人工定義的特征,這種方法的遷移學習能力強,但由于網絡模型繁多,對參數設置依賴大,模型可解釋性較差。目前,采用深度學習的模型有BiLSTM、CNN、RNN、BiLSTM-CRF等。
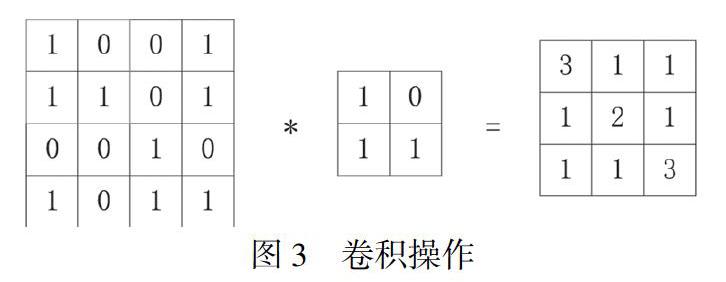
CNN(卷積神經網絡模型)分為卷積層、池化層和全連接層,卷積層的輸入是一個M×N的矩陣,N代表的是詞向量的維度,M代表的是詞的個數,例如,一句話中有5個詞,每個詞是10維的詞向量,那么輸入就是一個5×10的矩陣。卷積操作是指卷積核在輸入張量上按步長進行左右上下滑動,每一步的滑動卷積核與張量重疊部分的元素按位相乘后求和[7]。通常一個卷積核用來抽取一個特征,一般用多個卷積核抽取多種特征,卷積層的輸出結果為特征圖,一個卷積核對應一個特征圖,如圖3所示。池化層主要是對卷積結果進行池化操作,降低卷積操作的數據量。全連接層對卷積層和池化層提取的特征進行分類。
3.3 知識融合
知識融合是構建不同數據源獲取的知識之間的關聯,在構建知識圖譜之前,首先需要消除來自多個不同數據源知識的歧義,以及進行知識的統一表達等,然后才能將實體鏈接到知識庫中的實體上,對于知識庫中沒有的知識補全到知識庫中。通常知識融合的方法有基于聚類的實體消歧和基于實體鏈接的命名實體消歧。
基于聚類的實體消歧不給定目標實體列表,以聚類的方式對實體指稱項進行消歧。方法是對每個實體指稱抽取其特征(上下文的詞,實體,概念),組成特征向量,然后利用向量的余弦相似度進行比較,將指稱項聚類到與之最相近的實體指稱項集合中[8]。
基于實體鏈接的命名實體消歧給定目標實體列表,對于待消歧的實體根據上下文信息通過打分的方式獲取分數最高的實體作為目標實體。例如,中關村的蘋果不錯,蘋果是水果蘋果還是蘋果電腦?通過計算相關度(中關村,水果蘋果)=0.1,相關度(中關村、電腦蘋果)=0.7進行實體消歧。
3.4 知識存儲和管理
3.4.1 基于鄰接表的存儲方式
知識圖譜中的知識以三元組的形式表示,在抽取完實體、關系后,將三元組的知識存儲在數據庫中,基于鄰接表的存儲方式的典型是gStore[9],這種方式將每個實體點的鄰接表轉化成一個二進制位串,將二進制位串按照知識圖譜中的實體之間的關系連接起來。查詢的時候將查詢的子圖也按照這種方式轉化成一個二進制位串的形式,那么,知識圖譜的查詢就變成了子圖匹配的問題。gStore采用的查詢語言為SPARQL查詢語言。
3.4.2 基于圖數據庫的存儲方式
圖數據庫是基于圖模型,對圖數據進行存儲、操作和訪問的一項技術,與關系型數據庫相比,圖數據庫在處理關聯數據時展現出高性能、靈活、敏捷的優勢[10]。典型的圖數據庫是Neo4j[11],Neo4j底層以圖的方式把用戶定義的節點和關系存儲起來,通過這種方式,實現從某個節點開始,利用節點與節點之間的關系,找出另外的節點之間的關系。Neo4j的查詢語言為Cypher查詢語言。
3.4.3 基于分布式的知識圖譜存儲
由于知識圖譜的數據規模不斷擴大,為了應對大規模知識圖譜的存儲和管理,將知識圖譜采用分布式的存儲方式,一種是利用現有的云存儲平臺和云平臺上成熟的任務處理模式處理知識圖譜的任務,稱為基于云平臺的分布式知識圖譜存儲方法;另一種根據知識圖譜的查詢要求,將知識圖譜數據按照一定的方法進行劃分,形成不同的分片,分別存儲這些分片,稱為基于數據劃分的分布式知識圖譜存儲方法,采用這種方法面臨的問題就是如何對數據進行劃分,使得知識圖譜查詢速度最快。
4 知識圖譜未來研究方向
4.1 大規模知識圖譜的自動化構建
由于知識圖譜在不同認知領域的廣泛應用,要求能從大規模非結構化內容中自動構建知識圖譜。目前,自動化構建知識圖譜有四大技術重點:如何自動化地從結構化數據庫映射為知識圖譜并做知識融合;如何通過小樣本學習和領域知識遷移的技術減少人工標注成本;如何從非結構化文本中做篇章級的事件抽取和多事件關聯;基于深度學習的知識表示在各個構建的環節的應用。
4.2 時序性知識圖譜的構建
目前,知識圖譜中展現的實體或者是概念的關系都是靜態的,事實不隨時間的變化而變化,對知識圖譜的時序動態研究比較少,然而,在大數據背景下,能夠實現數據的實時采集,事實通常具有時效性,靜態的知識圖譜難以適應對數據準確性要求較高的業務。例如,在知識圖譜中實體的數量、實體之間的關系或者是實體的屬性值會實時變化,如果簡單的通過對圖數據庫進行delete和insert操作實現,會大大影響知識圖譜的性能,那么如何構建具有時序性的知識圖譜成為研究方向之一。
5 結束語
知識圖譜提供了一種新的知識表示、存儲、管理方式,使機器能夠理解知識,進行知識推理,在很多領域得到了廣泛應用,未來,知識圖的研究也會越來越受到重視。本文介紹了知識圖譜的應用、構建以及未來研究方向,目前知識圖譜的應用領域相對較小,下一步我們要在大規模知識圖譜的自動化構技術和時序性知識圖譜的構建做深入研究,提高知識圖譜在其他領域的應用水平。
參考文獻:
〔1〕漆桂林,高桓,吳天星.知識圖譜研究進展[J].情報工程,2017,3(01):4-25.
〔2〕黃恒琪,于娟,廖曉.知識圖譜研究綜述[J].計算機系統應用,2019,28(6):1-12.
〔3〕G.Gini.Industry-scale knowledge graphs: lessons and challenges[J].Communication of the ACM,2019,62(08):36-43.
〔4〕Yan Liu, Yan Zou,Lihua Yan,Zhijie Jia,Visualization Research of People's Livelihood Service Data based on Knowledge Graph[C].2020 IEEE International Conference on Information Technology,Big Data and Artificial Intelligence(ICIBA).IEEE,2020.
〔5〕鄧志鴻,唐世渭,張銘,等.Ontology研究綜述[J].北京大學學報,2002,38(05):731-737.
〔6〕趙琳瑛.基于隱馬爾可夫模型的中文實體識別研究[D].西安:西安電子科技大學,2008.
〔7〕霍振朗.基于深度學習的命名實體識別研究[D].廣州:華南理工大學,2018.
〔8〕范鵬程,沈英漢,許洪波,程學旗.融合實體知識描述的實體聯合消歧方法[J].中文信息學報,2020, 35(07):42-49.
〔9〕王鑫,鄒磊,王朝坤.知識圖譜數據管理研究綜述[J].軟件學報,2019,30(07):2139-2174.
〔10〕Kurt Cagle.Graph Databases Go Mainstream[J/OL].https://www.forbes.com/sites/cognitiveworl d/2019/07/18/graph-databases-go-mainstream/#32d93bd0179d,2019-07-18.
〔11〕Zou Y, Liu Y. The Implementation Knowledge Graph of Air Crash Data based on Neo4j*[C]// 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC). IEEE, 2020.
