計算機視覺中對象檢測技術綜述
2021-06-28 05:27:18陳文云覃煥昌
科學與信息化 2021年17期
陳文云 覃煥昌
百色學院 信息工程學院 廣西 百色 533000
引言
近三十年來,隨著反向傳播算法的發明[1]、卷積神經網絡技術的問世[2-4]、計算機運算速度和存儲技術不斷深化,推動計算機視覺技術水平不斷提高,對象檢測技術是其最基礎、最重要、最具挑戰性的技術之一。對象檢測技術是圖像識別和理解的關鍵技術,其通過對圖片中的各區域、各層特征的提取,通過機器學習檢測出圖片中各對象及其位置和關聯。
對象檢測技術[5]首先選定圖像中某一特定位置,然后對該區域圖像進行識別、分類,反復進行可以找出圖像中所有對象及其位置,再對各對象的關聯性進行分析,以完成對整張圖像的理解。其已廣泛地應用于日常生活中,譬如人臉檢測與識別[6-7],行人檢測[8],醫學上的人體骨架檢測[9],圖像分類[10-11],人類行為分析[12]和自動駕駛[13-14]等。
1 傳統對象檢測技術
傳統的對象檢測技術由區域推薦、特征提取和對象分類等部分組成。
1.1 區域推薦
不同對象在圖像中出現的位置不同、大小以及比例也不同,用不同大小和不同尺寸比例的候選滑動窗口去掃描圖像是必要的,從而篩選出最佳的區域推薦。巨量的窮舉候選滑動窗口會消耗大量的計算資源,同時會帶來冗余候選窗口。如果過少的候選滑動窗口數量,可能找不到最佳滑動窗口。
1.2 特征提取
為了識別滑動窗口中的對象,必須對窗口中能代表圖像的結構特征進行提取,對這些特征的表示是通過模擬外部刺激在大腦神經元中產生的激勵[20]來完成的。常采用的先進特征提取技術有:比例無關的特征變換[20],方向梯度直方圖HOG[21],哈爾特征Haar-like[22]等。但現實應用中對象的外觀、光照條件和背景的巨大差異,通過人工找到一個完美的、適合所有場景、所有對象的特征是極其困難的。
1.3 分類
在提取的特征的基礎上,需要找到一個強有力的分類器來區分在滑動窗口中的對象歸屬某一特定種類,常采用的分類器有:支持向量機SVM[23],AdaBoost[24],DPM[25]等。
傳統的對象檢測技術以滑動窗口為基礎,生成冗余低效的、人工定義的、淺層局部的特征描述和淺層學習模型為主要特征,無法獲取圖像中對象的深層次特征并完成深層學習,很快就遇到了識別率提升的瓶頸[15]。深層神經網絡DNN[11,26]通過自動提取和學習深層特征,打破了這一僵局,實現各層級特征自動提取,取消人工特征定義[27]。
2 新型對象檢測技術
新型對象檢測技術能在圖像中定位、識別特定的一個或多個已知對象。定位可以通過邊框(bounding box)來表示,識別就是對邊框中對象進行分類。根據其技術特點可將其分為兩類:第一種技術是基于區域推薦的對象檢測,與傳統的圖像理解技術類似,首先進行區域推薦,再將推薦區域的圖像進行識別和分類,典型代表有R-CNN[15],fast R-CNN[16],faster R-CNN[17],SPP-net[28],R-FCN[29],FPN[30]等,與傳統技術主要區別是取消了特征的人工定義;第二種技術是基于回歸的對象檢測,它將對象檢測與分類識別過程視為回歸問題,采用統一的框架一并完成,這類框架主要有YOLO[18],SSD[19],YOLOv2[31],DSSD[32]等。
2.1 基于區域推薦的對象檢測
基于區域推薦的對象檢測技術與人腦觀察物體的過程類似,先粗略掃描整個物體的概貌,再仔細關注感興趣的區域RoI。這類框架主要有如下幾種:
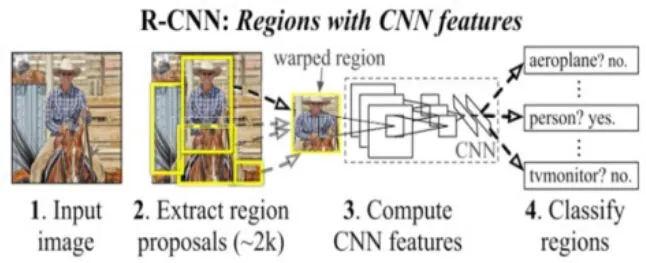
圖1 R-CNN信息流圖
R-CNN:通過采用選擇搜索算法[33]來快速提供精確的推薦區域,并在推薦區域中應用CNN提取深層次的高維(4096維)特征表示,然后利用線性SVM分類器對區域特征打分,最后在貪婪非最大抑制算法作用下對邊框BoundingBox進行回歸,從而得到最優的邊框[15],從而識別出圖片中所有對象及其邊框。對比結果顯示該框架比當時mAP最好結果提高了30%左右,其信息流圖如圖1所示。
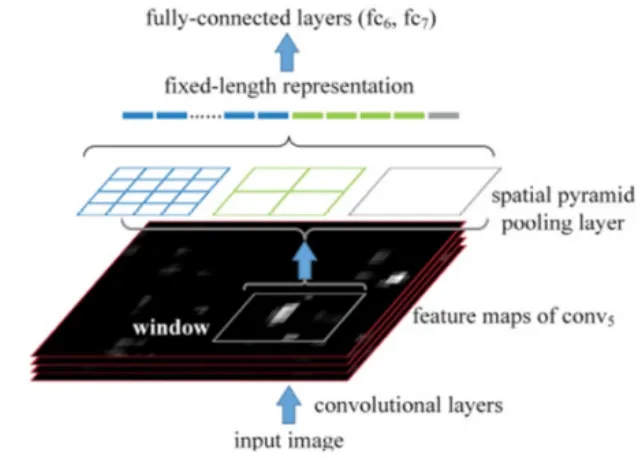
圖2 SPP-net架構
SPP-net:所有CNN最后都需要全連接層來匯總所有特征圖中的特征信息,而全連接層只會接收固定大小的輸入,故在R-CNN模型中需要對推薦區域進行裁剪,從而會導致邊框的不準確。為此,空間金字塔匹配SPM算法[34-35]被用于在卷積層和全連接層之間構建空間金字塔池化層SPP[28],從而生成全連接層所需要的輸入特征尺寸大小。其提高邊框預測的準確率的同時,還能提高對象檢測的效率,架構如圖2所示
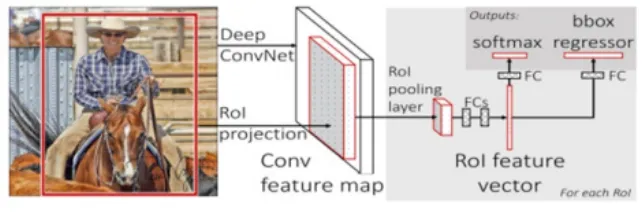
圖3 Fast R-CNN架構
Fast R-CNN:盡管SPP層能提高R-CNN的精度和效率,但是它還是采用單一管道、串行、多任務方式來完成所有處理,導致額外的內存花銷而且SPP的網絡微調算法不能影響到之前的卷積層。Fast R-CNN通過簡化SPP層為一層,并在全連接層后引入了兩個孿生的分別處理分類和邊框回歸的輸出層,并將所有參數進行端到端多任務損失優化[16],進而進一步提高對象檢測和分類的精度和效率,其架構如圖3所示。
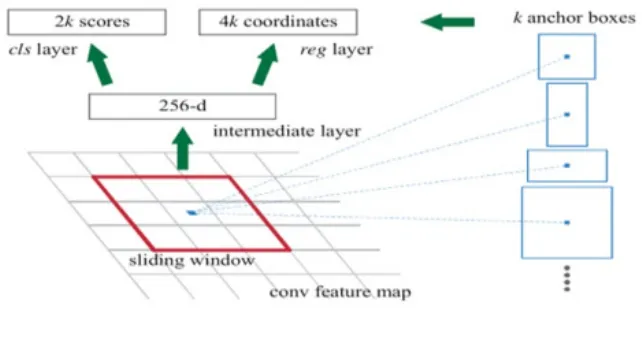
圖4 RPN的架構
Faster R-CNN: 主要創新是采用了區域推薦網絡RPN[17,36],RPN通過向對象檢測網絡分享全圖像的卷積特征圖來為其實現特征提取共享計算,幾乎無成本的去掉了Fast R-CNN中耗時的區域推薦處理;引入k個錨框分別對應k個區域推薦,每個錨框與RPN中滑動的小網絡進行卷積產生每個推薦的低維特征,以供邊框分類和回歸。RPN的架構圖如圖4所示。
R-FCN[29]:不同于faster R-CNN在于,其在最后一個卷積層就基于k*k固定大小網格為每類生成k2個得分列表,后續的RoI池化層、分類器和邊框回歸器都基于這個得分表來進行對象檢測。FPN[30]提取各個層級(由下至上、由上至下和直接互聯)的特征,在不犧牲速度和存儲空間的前提下,可用于訓練各種大小的圖片。Mask R-CNN[37]將faster R-CNN技術擴展至對象分割,在并行的分類和邊框回歸的基礎上增加了一個新分支:分割線掩碼。
2.2 基于回歸的對象檢測技術
基于回歸的對象檢測技術只需一步就能根據輸入圖片計算出所有對象的邊框及其類別。這類技術主要有:
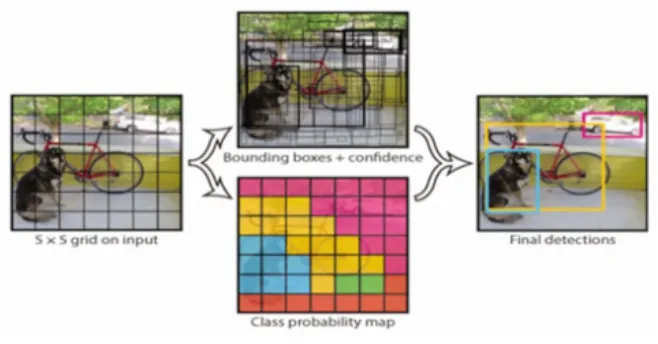
圖5 YOLO的對象檢測信息流圖
YOLO[18]:將對象檢測設計為一個回歸問題,對邊框和類別概率同時回歸,只用一個神經網絡和一次評價就可以從輸入圖像直接預測出邊框和類別。YOLO將輸入圖像分割成S*S個網格,每個網格只負責檢測中心落在其中的對象,預測B個邊框和相應的置信得分(),此外每個網格還要給出一組所有類別的條件類別概率()。根據邊框的置信得分和網格的條件類別概率,就可以計算出每個邊框的類別置信得分:

其信息流圖如圖5所示。
由此看出YOLO在一個模型中同時考慮了邊框類別、邊框的位置和大小,很容易進行端到端的損失優化,從而提高了效率、運算速度和預測精度。基本型YOLO處理速度可達45fps,fast YOLO處理幀率為155fps。引入塊歸一化、高分辨率分類器、錨框、維數聚類、細粒度特征、直接位置預測和多尺度訓練等新技術的YOLO稱為YOLOv2。
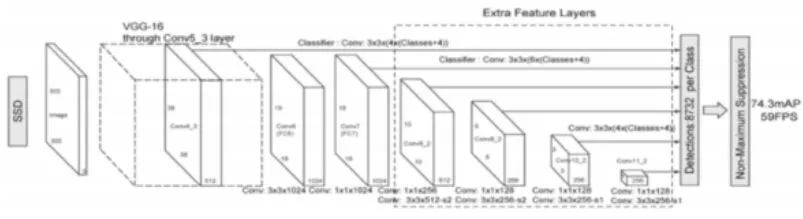
圖6 SSD的網絡架構
SSD[19]:是在受到錨框、區域推薦網RPN和多尺度表示技術的啟發下提出的,為了解決其他技術在檢測小尺寸對象時碰到的困難。它以VGG16的網絡結構為基礎,在后面增加了幾個特征層來預測不同尺度和比例的對象的偏移量機器置信得分,從而使對象檢測時融合了不同分辨率的特征圖中的預測信息,而非基于單一分辨率的特征圖,最后在非最大抑制算法的作用下得到最佳對象預測結果。其架構圖如圖6。
2.3 性能比較

Faster R-CNN YOLO SSD速度(fps) 7 45 59 mAP(%) 63.4 73.2 74.3
通過比較SSD、YOLO和faster R-CNN在PASCAL VOC和Microsoft COCO數據集的測試表現,得到如左表結果,結果表明SSD無論在速度(59fps),或是精度(74.3%)都是目前最好的對象檢測技術。
3 后續工作展望
對象識別技術近些雖然年取得了突飛猛進的發展,但仍然還有很多問題亟待攻克。其一,小尺寸對象(尤其是在局部遮擋情況下)的識別;其二,如何減少人工介入(打標簽等),提高對象檢測的自主化;其三,如何提高對象檢測的速度實現實時化,尤其對大尺寸圖片;其四,如何實現三維對象的檢測,甚至視頻對象檢測。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
