高速車聯網場景下分簇式無線聯邦學習算法
2021-07-02 08:54:12王家瑞譚國平周思源
計算機應用 2021年6期
王家瑞,譚國平*,周思源
(1.河海大學計算機與信息學院 南京 211100;2.江蘇智能交通及智能駕駛研究院南京 210019)
(?通信作者:gptan@hhu.edu.cn)
0 引言
隨著5G 技術的發展,物聯網逐漸成為5G 時代的研究熱點。車聯網作為物聯網中一個有潛力的研究分支,有望成為智能交通系統中的重要的數據傳輸與控制平臺。車聯網是一種移動自組網絡,可以有效地改善道路安全問題和駕駛者的駕乘環境。支撐這一功能的是用戶及其車輛所帶來的大量數據,但是車聯網的規模巨大、所用無線信道較為開放缺乏保密性、車輛的運動軌跡容易被跟蹤預測,這都使用戶的安全隱私容易泄露。不法分子可能通過截取用戶廣播的信息、預測車輛軌跡等方式竊取同戶的數據隱私,一旦車聯網系統暴露了任何車輛或用戶的隱私信息,將在很長一段時間內難以被公眾廣泛地接受。因此,用戶的隱私安全問題逐漸成為限制車輛及用戶參與數據提供程度的主要因素。為加強對用戶隱私的保護,除差分隱私保護理論[1]、k匿名[2]等常用的隱私保護方法外,近幾年,文獻[3-7]中也提出了許多解決方案。與此同時,2016 年谷歌提出了一種基于用戶隱私保護的學習框架——聯邦學習[8-10],其主要的特征是數據提供方的數據均保留在本地,沒有進行數據傳輸,從源頭上抑制了數據隱私的泄露。通過聯邦學習,車聯網系統可以在保護用戶隱私不被泄露的條件下,使用大量用戶數據進行模型訓練。
現行的許多關于分布式聯邦學習系統的研究[11-14]的用戶拓撲通常為星型拓撲。但星型拓撲大多針對小范圍的隨機用戶,并沒有充分考慮車聯網場景下車輛隨道路分布的特殊性及其對聯邦學習訓練效果的影響,為此本文提出了一種分布式的分簇式聯邦學習算法。從文獻[15-16]中可以得知,目前車聯網的發展存在以下兩方面挑戰:一方面,車聯網場景下用戶分布往往更為分散,采用單參數服務端進行用戶的模型數據匯總、更新往往需要更長的時間;另一方面,用戶距離參數服務端較遠,用戶所需的總功率相對較大。通過設計用戶的分簇方案可以選擇用戶端總功率較小的分簇方式進行訓練,從而對用戶端進行功率控制。
1 高速路車聯網模型
1.1 高速公路車輛分布模型
如圖1 所示,模型建立在雙向四車道的高速公路上,路段長度為L,單車道寬為W,圓點表示車輛。在道路中間每隔距離i設置一個路側元(Road Side Unit,RSU),用于完成用戶模型的接收匯總與更新。
在車用無線通信技術的長期演進計劃(Long Term Evolution-Vehicle to everything,LTE-V2X)系統級仿真中,設計車輛撒點及運動的內容包括五項:車輛數量、撒點方式、車速、行車方向、轉向模型[17]。其中車輛數量N的計算式如下:

其中:P為車速;T為駕駛員安全反應時間。在上述模型的基礎上,將在四條車道上隨機撒點,使車輛散布于每條車道的中線上,并保證車輛之間的間距大于安全跟車距離l。
1.2 無線傳輸模型
考慮到RSU 的發射功率可以滿足數據的有效發送,而移動車輛的發射功率有限,假設RSU 將數據下傳至簇內用戶的下行信道及RSU 之間的信道均為無損信道,用戶上傳模型數據至RSU的信道為衰落信道。
在用戶端進行上行模型數據傳輸時,采用模擬的方法進行傳輸,第i次迭代時,RSU接收到的信號yi(t)可表示為:
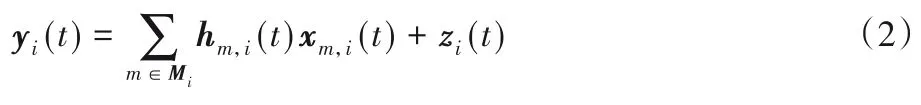
其中:Mi為第i次迭代時當前簇內用戶的集合;hm,i(t)~CN(0,)為第m個設備在第i次模型迭代時與RSU之間的瑞利信道,zi(t)~CN(0,)為加性高斯白噪聲;xm,i(t)為t時刻第m個設備在第i次模型迭代完成后所需發送的信息。可以將xm,i(t)用式(3)表示:

其中:gm,i(t)為第i次迭代時的模型梯度值;αm,i(t)表示功率控制向量。為滿足發射功率的限制,該功率控制向量的表達式如下:
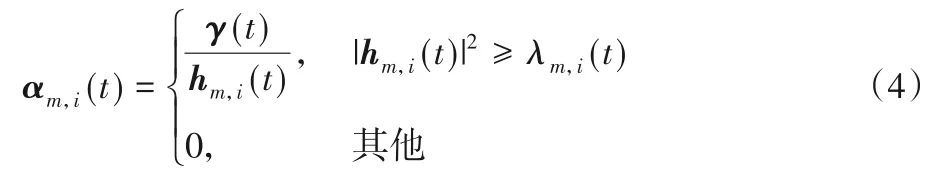
其中,γ(t),λm,i(t)∈R,為功率控制參數,調控λm,i(t)與γ(t)的值,可以使αm,i(t)滿足功率限制條件。
結合式(4),可以將RSU接收信號重新表達為:
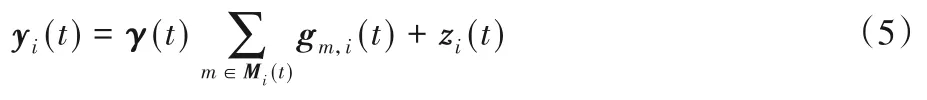
假設信號需要傳輸的距離為d,考慮大尺度衰落,可以重新得到此時RSU處接收到的信號表達式:
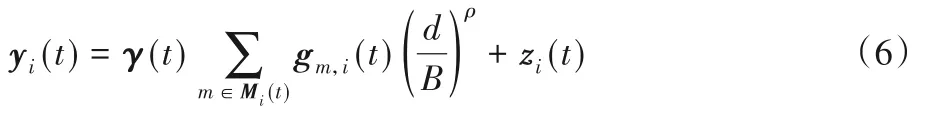
其中:B為與信號頻率等條件相關的常數;ρ為信號距離衰落因子,控制信號衰落的幅度。
1.3 控制參數
由式(4)可知,可以通過調整λ的值來控制有效傳輸模型數據的數量,以完成對數據丟包情況的模擬。定義有效數據傳輸率β為有效傳輸的數據包數量J占模型數據完整傳輸時所需傳輸數據包數量H的比值,即:

它可以作為有效傳輸概率的估計,即:

其中f(z)為瑞利分布的概率密度:

其中δ為方差,由此,可以得到:

1.4 損失函數
第k個用戶端處訓練模型的損失函數可表示為:
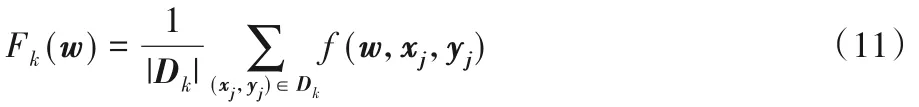
其中:Dk表示在第k個用戶處收集到的本地數據集;f(w,xi,yi)表示模型w基于訓練集樣本xi及其對應標簽yi的誤差損失函數。同時,一簇內的總體模型損失函數F(w)可以表示為如下形式:

其中,K為該簇內參與模型訓練的用戶總數。
2 分簇式無線聯邦學習算法
2.1 整體系統流程
圖2 為整體系統框圖,后續實驗也將據此進行相關仿真。在一次迭代中,當一簇用戶的模型更新完成后,其模型將作為下一簇用戶的初始模型進行訓練,這種方式與傳統聯邦學習中模型值取平均的做法不同,但這也是針對分簇式聯邦學習方法進行的一種嘗試。

圖2 C-WFLA流程Fig.2 Flow chart of C-WFLA
2.2 分簇算法
在每次隨機撒點完成后,將根據個用戶的車輛位置進行分簇,把模型中的N個用戶分為C簇,控制用戶端在上傳數據時不要離RSU 過遠,具體的分簇方法基于二分k-means 的思路,流程如下:
1)計算N個用戶位置坐標的質心。
2)選擇距離1)中質心最近的RSU作為初始中心點。
3)隨機選取2 個用戶位置做中心點,并由此將剩余用戶分為兩簇。
4)選取步驟3)中未選擇的用戶點,分別計算其與步驟3)中選取兩中心點歐氏距離的平方,并使其歸于數值較小的一方,該用戶點加入后,重新計算該簇用戶位置坐標的質心。
5)重復步驟4)直至所有點分簇完成,選擇距離兩簇質心最近的RSU作為該簇的中心點。
6)分別計算兩簇內用戶點與中心點距離的平方和,選擇數值較大的一簇重復步驟3)~4)直至模型內的總簇數達到設定值。
3 實驗與結果分析
3.1 實驗參數
在實驗仿真中,圖1 中示意的高速公路的長度L定為1 000 m,單條道路寬定為7.5 m。
設置車輛數量時,取車輛速度P為120 km/h,駕駛員安全反應時間T取6 s,安全跟車距離l取20 m,確保同一車道兩車間距大于20 m,根據式(1),可得N=20。因此,在每次迭代時將模擬生成20輛車的位置,以進行分簇。
本次實驗,以數字手寫體識別的模型訓練為例,展示訓練效果,優化器選擇隨機梯度下降(Stochastic Gradient Descent,SGD),訓練集大小r取5 000,經預實驗迭代次數i取150,學習率lr選擇如式(13):
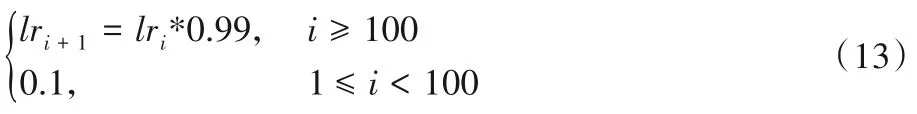
基于每次迭代整體的效率與速度,分簇過少會使整體用戶的發射功率增加,分簇過多會導致單次迭代內的訓練區域較多,系統整體訓練時間較長,因此選擇將20 個用戶分為3簇。
根據圖2 介紹的流程,接下來通過一次仿真案例的執行情況,具體展示分簇算法運行結果細節:
1)根據用戶位置,20個用戶端的初始分簇情況如下:
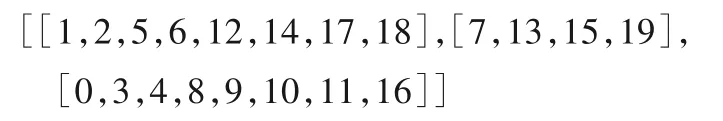
其中,數字0~19 為用戶端的標號,在分配訓練集圖片時,將給0 號、1 號用戶端分配5 000 張數字“0”的圖片,以此類推18號、19號用戶端將獲得5 000張數字“9”的圖片。
2)在根據β值的大小做好功率控制的情況下,通過當前簇內用戶([1,2,5,6,12,14,17,18])的數據集進行模型學習,并通過RSU 將匯總、更新后的模型參數傳至下一簇([7,13,15,19]),并作為下一簇用戶模型訓練的初始模型。
3)重復2)中的操作,直至3簇用戶均訓練完成,第一次迭代結束。
4)在下一輪迭代開始之前,系統將重新生成用戶的位置信息,并重新進行分簇。
5)重復2)~3)中的操作,直至迭代150 次,模型損失值基本收斂,訓練完成。
3.2 結果分析
圖3 為β值取20%、40%、60%、80%、100%時,模型經過150 輪迭代,傳統聯邦學習(集中式)、分簇式聯邦學習(分布式)兩種訓練方式下,模型損失函數的變化。
從圖3 可以看出:在β大于等于40%時,兩種訓練方式下的模型收斂值、收斂速度相近,但分簇式訓練在模型收斂時的損失函數波動變大。當β值繼續降低到20%時,傳統聯邦學習的收斂值劇增,整體模型訓練效果變差。

圖3 不同β值下的損失函數變化Fig.3 Change of loss function under different β values
表1為模型經過150輪迭代后,兩種訓練方式下損失函數的收斂值。
從表1 中可以看出:β高于40%時,分簇式聯邦學習訓練后的模型收斂值略高于傳統聯邦學習;而當β值降低至20%,分簇式聯邦學習的模型收斂值卻更低,這說明在β值較低,即信道狀態較差或者發射功率受限較大時,分簇式訓練有著更好的抵抗性,因此獲得了更好的模型訓練效果。
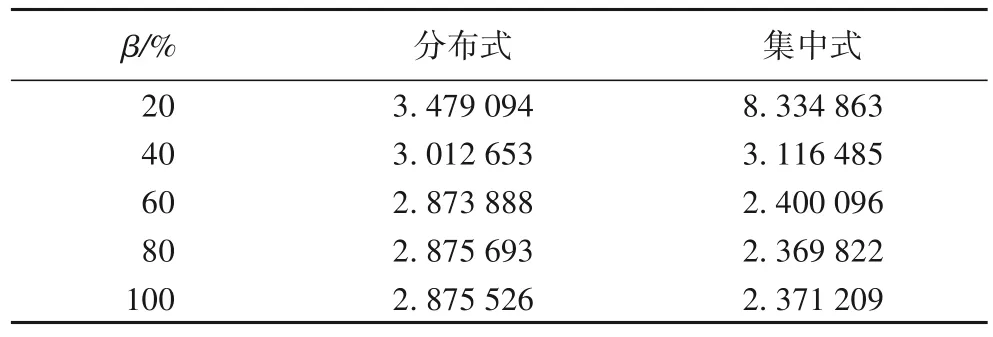
表1 兩種訓練方式下模型收斂值對比Tab.1 Comparison of model convergence values under two training methods
對傳統聯邦學習模式在不同β值下的收斂情況進行了橫向對比,如圖4所示。在圖4中可以觀察到,β值為100%、80%時曲線基本重合,當β值低于40%時,模型損失函數出現了類似門限效應的情況,隨著β值的減小,損失函數的收斂值迅速變大,而分簇式聯邦學習訓練出的模型并沒有出現類似情況。
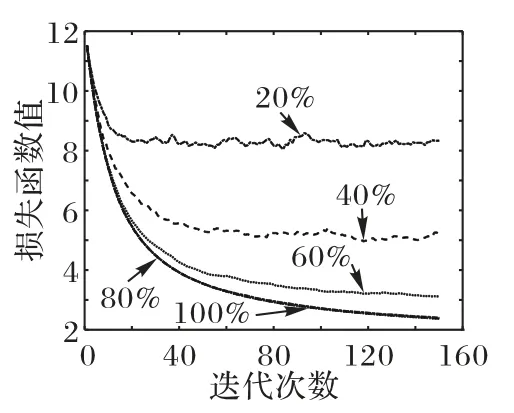
圖4 傳統聯邦學習在訓練時的損失函數值Fig.4 Loss function values during training of traditional federated learning
這一現象,推測可能是隨機拓撲網絡的隨機性產生的效果:
1)從模型參數的角度分析:假設有利于模型訓練的關鍵參數位置基本不變,在隨機網絡引入之前,在通過功率控制進行模擬丟包后,關鍵位置的模型參數可能會丟失,從而導致模型不能正常收斂。而在分簇式聯邦學習中,用戶被分為了多簇,在每一次的迭代中,模型需要進行多次接力更新才能完成,而根據式(6)可知,聯邦學習只關注模型更新時,所有用戶發送的梯度矢量平均值。由于分簇式聯邦學習的每一簇用戶在上傳模型數據時都需要進行一次功率控制,從概率上講,模型中關鍵位置參數全部丟失的可能性相對減小,取而代之的是該位置上的參數值變小,這一變化提高了其模型數據在丟包較多的情況下,訓練后模型的整體效果。
2)分簇式聯邦學習在每次迭代時,用戶的位置與用戶的分組方式發生了改變,這相當于在模型訓練的過程中引入了一定的隨機性,從而優化了整體模型訓練的效果,而也正是由于這種隨機性的引入使模型收斂時會出現一定的波動。
4 結語
針對基于高速公路模型的車聯網場景,本文提出了一種分布式的分簇式無線聯邦學習算法(C-WFLA)。通過仿真實驗對該算法的訓練性能進行的分析可知,本文提出的分簇式訓練方式能有效應對無線系統中的數據丟包狀況,即在相應的丟包率低于一定的閾值時,本文提出的分布式算法依然能夠取得較好的訓練效果。但本文所提出的算法還存在很多問題值得探討:1)目前只考慮了數字手寫體識別模型訓練,對一些更復雜的模型有待實驗驗證;2)對于無線信道的仿真還不夠實際,沒有考慮多徑效應、多普勒效應等實際情況;3)對模型隨機性的考慮還不夠完備,分簇方法也還有待優化;4)在諸如城市道路、鄉村道路等不同車聯網模型下的訓練效果還有待驗證。以上問題都將是我們后續的重點研討方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
