基于深度學習的OCT圖像視網膜積液自動分割
2021-07-09 08:43:00江旻珊
光學儀器 2021年3期
魏 靜,江旻珊,茅 前
(上海理工大學 光電信息與計算機工程學院,上海 200093)
引 言
糖尿病性黃斑水腫(dabetic macular edema,DME)是血視網膜屏障破損導致黃斑區液體積聚的一種眼底疾病,是糖尿病患者視力損傷的重要原因[1]。DME患者若未及時得到診斷和治療,會導致不可逆的視力損傷。DME的主要治療方式是向玻璃體內注射抗血管皮生長因子(anti-VEGF)來抑制異常的新生血管生長,但是患者的個體注射方案需要醫生根據積液的類型和區域大小來決定。視網膜積液根據積聚位置分為視網膜內積液(intraretinal fluid,IRF)和視網膜下積液(subretinal fluid,SRF)。光學相干斷層掃描(optical coherence tomography,OCT)是一種無輻射非侵入的成像技術,能提供清晰的視網膜橫截面圖像。眼科醫生通過觀察DME患者的視網膜OCT圖像中的積液類型和積液區域大小判斷病變情況,但不能準確地量化積液并據此制定治療方案。然而,手動分割視網膜積液在人力和時間上都是一個巨大的挑戰。自動準確量化OCT圖像中的IRF和SRF可以大大提高醫生的診斷和治療效率,因此,一種能夠自動分割積液區域的算法對于臨床診斷尤為重要。
近些年,很多自動分割OCT視網膜積液的方法被提出,主要分為傳統圖像分割和機器學習兩類。王杰等[2]通過模糊水平集識別B 掃描和C 掃描上的流體區域邊界,組合邊界生成視網膜積液的3D分割,并在10只患有DME的眼睛上對算法進行了評估,該方法需要預先分割視網膜層并對分割結果進行手動校正。Chiu等[3]提出了一種基于核回歸的機器學習方法對視網膜層進行分類,再結合圖論和動態編程的框架識別準確的視網膜層和液體位置,在10名患者的OCT圖像上進行了驗證,但是這種方法并沒有區別視網膜內積液和下積液。Montuoro等[4]使用隨機森林分類器結合圖論同時分割視網膜層和流體區域,然后利用二者的相互作用提取各種基于上下文的特征改善分割結果。傳統圖像分割算法和機器學習都依賴于復雜的數學計算和連續的迭代優化,處理圖像時間較長。
近幾年,深度學習技術不斷發展,尤其是卷積神經網絡廣泛應用于醫學圖像分割領域。Schlegl等[5]提出了一個編碼-解碼的卷積神經網絡用于檢測和量化黃斑疾病的IRF和SRF,在IRF上取得了良好的性能。Roy等[6]開發了ReLayNet同時分割7個視網膜層各流體區域,而沒有區分積液類型。Lu等[7]應用圖分割算法預先分割內界膜和布魯赫膜,使用U-net網絡自動分割OCT圖像中的IRF、SRF。根據已發表的文獻,大多數分割多類視網膜積液的方法都需要聯合視網膜層分割或使用兩級網絡,但是錯誤的層分割或上一級網絡也會對最終的分割結果造成影響。
本文提出一種改進的U-net神經網絡Res-SE Unet來自動識別視網膜OCT圖像中的IRF和SRF區域。用Res-SE Block替代U-net的標準卷積層,殘差可以減少梯度消失的問題而SE塊可以學習更有效的殘差特征,提高網絡的分割精度。本文方法不依賴視網膜層的分割或者上一級網絡,減少了錯誤的層分割或上一級網絡訓練結果的影響,并縮短了算法處理時間。
1 材料與方法
1.1 圖像預處理
本文使用了來自加州大學圣地亞分校的Kermany數據集[8],該數據集使用Spectralis(海德堡)成像系統采集,包含了37 205張脈絡膜新生血管(CNV),11 348張糖尿病黃斑水腫(DME)、8 616張玻璃膜疣(Drusen)、26 315張正常(Normal)視網膜OCT圖像。本文提出的網絡目標是從DME的OCT圖像中同時檢測和量化IRF和SRF,從 DME類別中抽取了80張含有IRF和SRF的OCT圖像作為實驗樣本,由兩名眼科專家獨立標注病變區域輪廓如圖1所示,紅色輪廓表示IRF區域,黃色表示SRF區域。當出現明顯不一致標注或由于圖像質量問題較難標注時,從數據集中排除此實驗樣本。

圖1 手動標注的OCT圖像Fig.1 OCT image with manual annotation
如圖2(a) 所示,IRF和SRF限制在視網膜內界膜(ILM)和布魯赫膜(Bruch’s membrane)之間,因此,利用視網膜區域與背景的灰度差異對感興趣區域進行提取,結果如圖2(b) 所示。增大積液區域所占像素比例,一定程度上減少背景與積液不均衡對分割結果的影響。OCT圖像基于相干光干涉的原理成像,掃描對象亞分辨率的不同會引起反射波隨機干擾產生斑點噪聲,影響網絡的特征提取。為了解決這一問題,采用雙邊濾波算法來去除噪聲,此算法在抑制散斑噪聲的同時還可以保持圖片邊緣,圖2(c) 顯示了去噪后的OCT圖像。Kermany數據集中OCT圖像分辨率不同,將圖像統一調整為256×256作為網絡輸入。將OCT圖像和標簽圖作為實驗樣本按7:3的比例隨機劃分為訓練集和測試集,訓練集用于訓練和驗證網絡模型,測試集用于評估網絡性能,訓練集和測試集的樣本互斥。深度學習的訓練需要大量數據,而我們的樣本數量不足以支撐,且人工標注耗費大量時間,所以本文采用數據增強的技術,通過隨機旋轉,上下平移和圖像翻轉等30倍擴充訓練集圖像數量,減小網絡訓練過程中的過擬合問題,提高分割準確度。

圖2 OCT圖像預處理步驟Fig.2 The pre-processing of OCT image
1.2 網絡結構
1.2.1 Res-SE Block
Res-SE Block由殘差連接和SE塊組成。殘差連接已被證明是在深層次網絡學習特征時克服梯度消失問題的有效方式[9]。2017年,Hu等[10]提出SENet(squeeze-and-excitation networks)獲得了ImageNet挑戰賽冠軍,網絡結構單元SE塊在特征通道維度上加入Attention機制,通過損失函數學習各維度的權重,根據各維度的重要程度學習殘差特征。Res-SE Block的結構如圖3所示,Xl經過兩次卷積操作得到大小為H×W×C的特征圖Xr,通過全局平均池化轉換為 1 ×1×C的特征信息,每個二維特征通道的轉換公式為

圖3 Res-SE BlockFig.3 Res-SE Block

式中:Fsq(·) 表示擠壓操作;xc表示Xr第c維度上的特征圖;H、W分別表示特征圖的長和寬;uc表示經擠壓后得到的特征值;h、w分別表示特征圖上某一點的橫坐標和縱坐標。
經兩次全連接層和RELU激活函數學習各個特征通道之間的相關性,通過Sigmoid函數將特征間的相關性進行歸一化,得到各特征通道的權重,通過權重與對應的特征通道相乘進行特征重標定

式中:Fex(·) 表示激勵操作;W1和W2表示兩個全連接層;Xc表示Xr第c維度上的特征圖;Vc表示該特征圖通過激勵操作得到的權重。
將SE塊嵌入殘差連接,根據重要程度對不同維度的殘差特征進行提升或抑制,提高網絡學習能力:

式中:Xl表示Res-SE Block的輸入;X表示Xl經過SE塊的變換結果;Xl+1表示Res-SE Block的輸出結果。
1.2.2 Res-SE Unet
2015年,Ronneberge等[11]提出了U-net網絡用于醫學圖像的語義分割,由具有相同卷積數量的收縮路徑和擴展路徑對稱組成,收縮路徑包括四個下采樣層提取圖像語義信息,擴展路徑包括四個上采樣層還原圖像尺寸重建圖像。U-net神經網絡首次提出跳躍連接將下采樣層和上采樣層的特征融合,多尺度融合使底層的細節信息能夠補充高層相對抽象的語義信息,提高分割精度。
Res-SE Unet神經網絡使用Res-SE Block 代替U-Net 神經網絡的標準卷積模塊,學習重要特征,網絡結構如圖4所示。相比于標準 U-net 神經網絡,本模型的最大通道數為 512,減少網絡參數數量,同時保持較好的泛化能力。本模型收縮路徑和擴展路徑中的單元數量與標準U-net相同,每一個收縮單元包括一個Res-SE Block提取圖像特征和一個下采樣層,下采樣層采用2×2的最大池化,特征圖尺寸減小一半;每一個擴展單元包括一個Res-SE Block和一個上采樣層,上采樣采用轉置卷積,特征圖尺寸擴大2倍,通過拼接方式與收縮路徑中對應的特征融合。在最后一層,網絡采用通道數為3的3×3的卷積層,壓縮擴展路徑輸出的特征圖維度,3個通道分別對應IRF、SRF和背景。網絡還使用Softmax激活函數將最后一層的輸出歸一化,取每個像素的最大概率對應的通道作為分類結果。

圖4 Res-SE Unet 網絡結構Fig.4 Res-SE Unet architecture
1.2.3 損失函數
視網膜積液分割是通過神經網絡將OCT圖像的像素分為背景、IRF、SRF三類。將圖片的像素看作分類樣本,積液類別的樣本數量較少,為了使神經網絡學習時更加關注IRF和SRF的特征,賦予樣本較少的類別較大的權重,提高網絡對積液的分割性能。每個類別的權重為

式中:wi為每個類別的權重;Ni為圖中每個類別的像素總數。
本文使用加權多類損失函數,該損失函數由Dice損失函數和交叉熵損失函數結合共同優化模型。Dice損失函數和交叉熵損失函數公式分別為


最終,加權損失函數為

式中 λ1和 λ2分別表示Dice損失和交叉熵損失在總損失中的比例。
1.3 訓練過程
本研究的運行環境為NVIDIA cuDNN7.5、CUDA10.0、Python 3.7、Anaconda3,硬件配置為RTX 2080Ti GPU,256 GB容量的硬盤,深度學習的框架為tensorflow。神經網絡通過訓練數據學習各層權重并通過驗證數據驗證模型性能選擇最優模型,每一輪學習從訓練集中隨機抽取80%訓練模型,剩余20%用于驗證模型,提高模型學習能力。分批輸入數據減少訓練時間。本研究采用Adadelta優化方法對網絡參數進行優化,使用式(7)提出的加權聯合損失函數判斷網絡模型的訓練過程。根據訓練結果調整參數,損失函數的 λ1和 λ2分別設置為0.3和0.7,設置訓練批大小為6,訓練數據集迭代100輪。
1.4 統計方法
為了定量評估本文算法的分割性能,采用Dice系數和IoU系數作為評價指標,通過計算神經網絡預測和專家標注之間的區域相似性衡量IRF和SRF分割的準確性。
Dice系數的計算式為
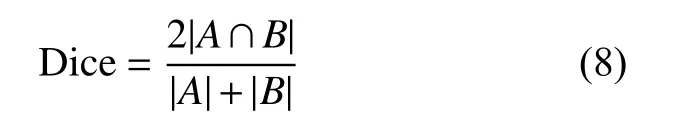
IoU的計算式為

式中:A為積液的真實標注圖;B為預測的分割結果。
本文對IRF和SRF的分割效果進行獨立評估,將非指定類型的流體區域視為背景。
2 結 果
2.1 實驗結果分析
利用本文模型在20張包含IRF和SRF的OCT B掃描圖像上進行測試評估,計算每張圖像與預測結果的Dice系數和IoU。圖5箱線圖顯示了測試集圖像IRF的Dice系數分布情況,網絡對IRF分割的Dice系數最高達到了0.90,SRF的Dice系數最高達到了0.96。Dice系數的分布也較為集中,這表明網絡在一般情況下對流體都能進行有效的分割。表1顯示了我們的方法在整個測試集中的平均表現,IRF的Dice系數為0.84,IoU系數為0.72;SRF的Dice系數為0.86,IoU系數為0.74。

表1 測試集積液分割評估結果Tab.1 Evaluation of the fluid segmentation results for test OCT image

圖5 Dice系數箱線圖Fig.5 Boxplot of Dice coefficient
本文還比較了Res-SE Unet與U-net[7]、基于膨脹卷積的分支殘差U-net(BRUNet)[12]、使用補丁的含有兩個額外最大池化操作的PaEX-Unet[13]。表2描述了四種網絡自動分割IRF和SRF的Dice系數,Res-SE Unet相比于其他網絡,IRF和SRF的Dice系數都有一定程度上的提高,這表明該網絡可以更加有效地分割OCT圖像中的流體區域。這主要是由于Res-SE Unet利用殘差連接,在一定程度上減小了特征信息在傳播時的損失,同時SE塊提高了圖像有用特征的權重,提升了模型的分割性能。

表2 不同網絡在測試集上的Dice系數比較Tab.2 Comparison of Dice coefficients between different networks on test dataset
圖6展示了本文模型對測試集內一些OCT圖像的分割效果。第一行是DME患者的OCT圖像,第二行是專家手動標注的標簽圖,第三行是網絡對積液區域的預測結果,其中白色區域表示IRF,紅色區域表示SRF。第一列至第三列顯示了一種簡單情況,OCT圖像中表現出明顯的黃斑囊樣水腫或漿液性視網膜脫離時,我們的方法表現出了良好的性能;第三列和第四列顯示了OCT圖像信噪比相對較低時的分割結果,圖像對比度較低,流體邊界不明顯導致分割效果較差,但是網絡基本可以檢測到流體位置;第五列顯示了測試集中IRF分割效果最差的情況,這種情況主要是由于一些IRF區域面積過小,網絡對這些區域的識別能力較低,或是流體與視網膜組織中的陰影區域難以區分,專家未標注的陰影區域也被網絡標記為IRF。

圖6 測試集中IRF 和SRF的分割示例Fig.6 Example segmentations of IRF and SRF from the test set
3 結 論
本文中提出了U-net改進網絡Res-SE Unet,用于自動分割視網膜OCT圖像中的IRF和SRF區域。所提出的網絡使用Res-SE Block替代Unet中的卷積層,更加有效地學習圖片的特征信息。為了減小圖片中背景與流體區域不平衡的問題,在訓練之前先進行圖像剪裁,去除大部分背景,在訓練中還使用加權損失函數優化模型,增加IRF和SRF的權重,提高積液分割的準確度。我們的網絡在測試集中取得了良好的分割效果,測試樣本中IRF的Dice系數和IoU平均值達到了0.84和0.72;SRF的Dice系數和IoU平均值達到了0.86和0.74。Res-SE Unet可以較為快速準確識別IRF和SRF,有助于眼科醫生根據病情調整治療方案。基于深度學習檢測和分割DME中的積液需要大量圖像數據用于模型訓練,但由于分割目標限制,Kermany數據集中DME組同時含有IRF和SRF的樣本數量較少,限制了模型訓練效果。隨著未來公開可用的DME OCT圖像數量增加,所提出的網絡的分割性能也會進一步提高。我們的網絡對小區域的流體分割還需要進一步的提升,在未來的工作中,將繼續研究損失函數減小目標與背景不平衡對分割結果的影響,在網絡結構中加入生成對抗網絡模型,增加特征圖像的數量,提高網絡的分割性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
